基于協同過濾的專業學習指導平臺建設研究
2022-07-12 14:03:32趙秀梅趙宗昌袁衛華劉云嬌
計算機應用與軟件 2022年6期
趙秀梅 趙宗昌 袁衛華 劉云嬌
1(山東建筑大學計算機科學與技術學院 山東 濟南 250101) 2(山東大學附屬中學 山東 濟南 250199) 3(山大地緯軟件股份有限公司 山東 濟南 250101)
0 引 言
現今,為培養適應社會發展和地方經濟需求的多元化的應用型創新人才,眾多本科院校逐步實施“以學生為本”的學分制,允許學生根據自己的興趣安排個人修學計劃。然而,很多低年級學生不了解當前企業的具體需求及其發展趨勢,學習缺乏方向性;沒有充分了解各種關鍵技能與課程的關系、課程對基礎能力的需求,學習計劃缺乏完備性和條理性。此外,多數地方院校所實施的“專業教師指導機制”因專業教師時間和精力有限,存在著“對人才需求分析不足、信息獲取時間長、指導力度受限”的問題。目前大量研究者利用各種推薦算法,根據選課歷史記錄挖掘學生興趣點,進行課程推薦,提高學生選課效率。然而,這些研究通常不能有效反映人才需求/專業技能與課程之間、課程與課程之間的關系,不能使學生很好地了解專業學習整體框架、各種技能修學途徑、就業及發展前景等。對于興趣不明確、選課記錄少的低年級學生推薦效率低、指導力度小。因此,本文研究并確立了“基于協同過濾的專業學習指導平臺”,通過“專業技能需求分析、課程與技能關聯關系分析、學習指導與推薦”三個不同層次的校企協同分析,構建企業人才需求、技能、課程之間的加權關聯關系,并能根據學生修課情況估計學生專業技能水平,同時結合學生興趣,提供多種基于協同過濾的雙向查詢與修學計劃推薦服務,并以圖形化輸出提升系統的友好性。
1 課程推薦技術現狀
為了提高選課效率、滿足學生個性化學習的需求,眾多研究者將各種個性化推薦技術應用到選課系統。個性化推薦技術根據用戶的興趣特點和需求,向用戶推薦可能感興趣的信息、產品等。傳統的推薦方法主要包括協同過濾、基于內容的推薦方法和混合推薦方法[1]。其中協同過濾應用最為廣泛,其基本思想是:根據用戶對項目的評分數據,計算目標用戶(項目)與其他用戶(項目)的相似度,從而根據相鄰用戶(項目)為目標用戶完成推薦[2]。文獻[2-11]以協同過濾技術為基礎為用戶提供課程/學習資源推薦。同時,為提高推薦效果,文獻[2]使用標簽技術和關聯規則算法發掘用戶可能感興趣的知識內容,文獻[3]對課程和學生進行加權處理,文獻[7]綜合應用學生屬性和課程特征,文獻[8]在Hadoop平臺上使用MapReduce算法來加快系統整體運行速度,文獻[9]增加了標簽和評分預測機制;為解決數據稀疏和冷啟動問題,文獻[5]在充分利用用戶注冊信息的基礎上增加了預測填充機制,文獻[6]融合了基于內容的推薦,文獻[10]對用戶興趣和課程建模并完善用戶-課程評分矩陣;文獻[4]通過課程進階關系確保用戶課程知識結構的健壯性。此外還有研究者應用關聯規則數據發掘[12-13]、潛在因子關系矩陣[14]、課程知識圖譜[15]等技術來提高個性化課程推薦的效率。
但是,這些已有研究成果不能清晰地展示知識點、課程、專業能力與企業人才需求之間的關聯關系,不能使學生全面了解專業技能及其就業前景,也就不能使學生很好地理解系統推薦結果對能力培養的作用,不利于更好地激發學生的學習興趣;同時,在學生不能明確把握自己的學習興趣、沒有開始學習專業課或已修專業課數量少而所在專業又存在多個學習方向時,推薦效率明顯降低。為此,本文研究并確立了具有圖形化接口,全面考慮“課程、專業技能與人才需求”關聯關系,并提供多種雙向查詢推薦服務的“基于協同過濾的專業學習指導平臺”。
2 基于協同過濾的專業學習指導平臺架構
基于協同過濾的專業學習指導平臺充分利用企業的專家分析、技能培訓、員工評價記錄和人才需求信息等資源,通過“線上線下”校企雙向協同,實現具有專業技能需求分析、課程與技能關聯關系分析、學習指導與推薦三個層次的專業學習指導。該平臺的層次模型如圖1所示。
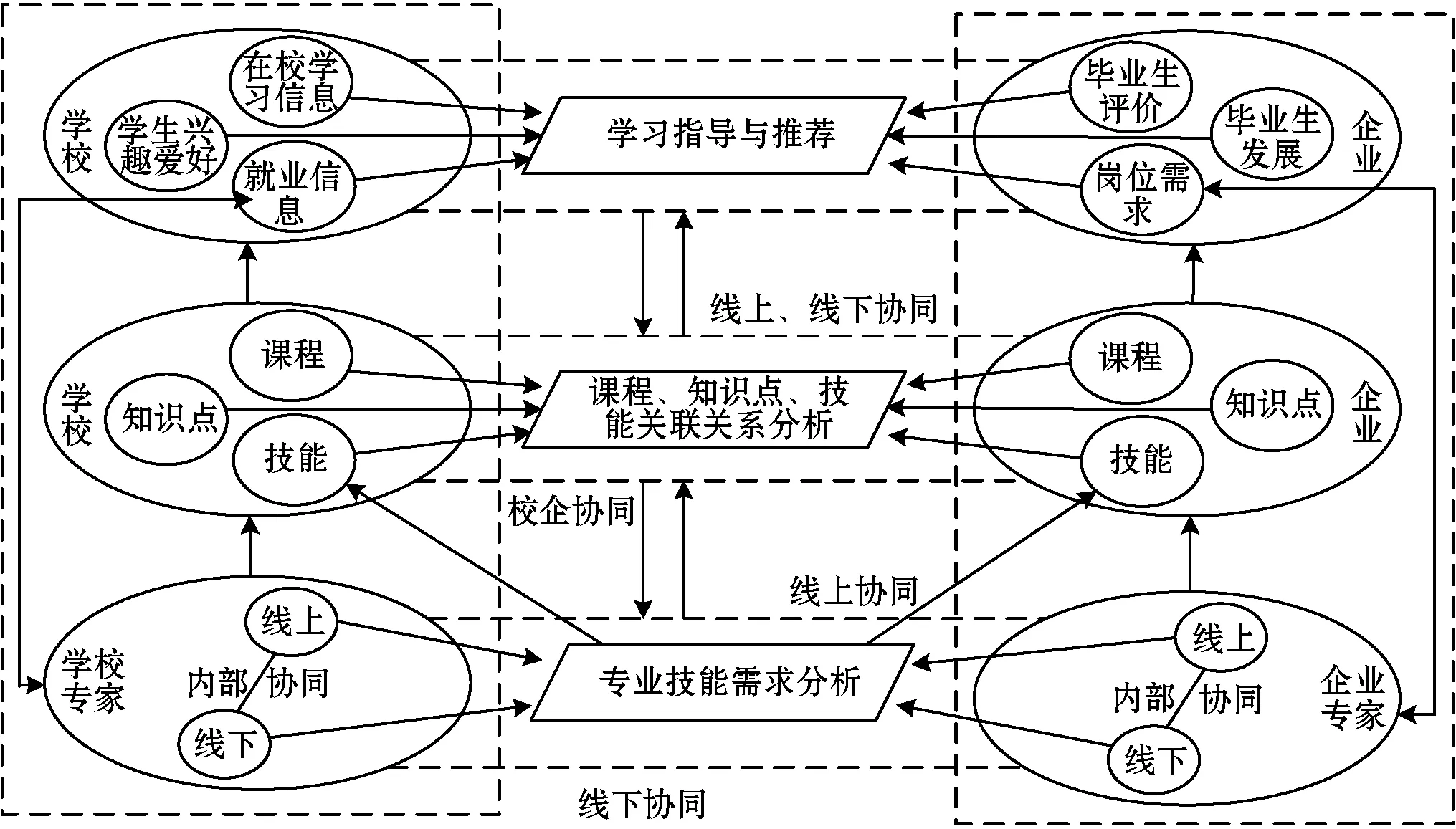
圖1 基于協同過濾的專業學習指導平臺層次模型
2.1 專業技能需求分析層
專業技能需求分析層是基于協同過濾的專業學習指導平臺的基礎層,學校需要安排專門的指導教師與企業專家協同完成“線上線下”專業技能需求分析,并實現定期更新,具體如圖2所示。學校線下指導教師需要帶領團隊,對相關行業企業進行廣泛調研,并與企業專家進行線下溝通,了解企業對專業技能的需求,了解企業專家對人才需求趨勢的預測,細致了解相關技能對重要知識點的基本要求,匯總并整理相關信息,形成基礎數據。之后,由線上指導教師針對本專業特色,對基礎數據做進一步的篩選和細化。錄入平臺系統后,由企業線上專家進行協同確認,形成最終的專業技能需求報告。

圖2 專業技能需求分析
2.2 課程與技能關聯關系分析層
在課程與技能關聯關系分析層中,學校專業指導教師細化專業培養方案的目標技能,梳理校內專業課程(含集中實踐教學環節)開設情況以及所包含的知識點,確立校內培養的技能常規集合(即TS)和關鍵知識點集合(即KS)。同時,分析專業技能需求報告,獲取技能需求集合(即TI)和關鍵知識點需求集合(即KI),比較二者與TS和KS集合的差異,確立技能差異集合(即TD=TI-TS)和知識點差異集合(即KD=KI-KS)。學校專業指導教師在企業專家的協同下,充分利用企業的師資和培訓資源,確立彌補技能、知識點差異的具體方法,如:新開選修課、慕課、企業講座/培訓、第二課堂、學生自學等,并將其中可控方式(如前三種)納入專業培養體系,作為獨立課程,或者作為特殊輔助課程。在學校政策允許的情況下,建立特殊輔助課程與專業課程之間的學分置換關系,以激發學生學習特殊輔助課程的積極性。對于不可控方式,也應盡可能多地為學生集中提供可用學習資源。
根據專業技能需求完善專業教學環節的同時,分析知識點間、課程(含特殊輔助課程)間、知識點與課程間的關聯(如前驅后繼、包含等關系),分析知識點、課程與專業技能之間的關聯,建立相應的關聯關系庫,并確立該關聯關系庫的查詢規則,以實現根據目前技能查找需要選修的課程/知識點、根據當前課程或知識點查找其前驅或后繼對象的基本功能。具體如圖3所示。

圖3 知識點、課程與技能關聯關系分析
2.3 學習指導與推薦層
學習指導與推薦層是基于協同過濾的專業學習指導平臺的用戶接口層,主要完成對下層關聯關系庫和查詢規則的升級,并在協同過濾技術的基礎上,利用近鄰查找與分析完成雙向查詢,從而為用戶提供多種修學計劃推薦服務,并實現推薦、分析結果的圖形化輸出。具體如圖4所示。

圖4 學習指導與推薦
該層在對用戶提供服務之前,需要依據學校所積累的學生在校學習信息、就業信息,連同關聯聯系庫,確定各課程對所關聯技能的加權值。而該加權值的確定通常有兩類方法。
1) 由專業指導教師仔細研究知識點、課程與專業技能之間的關聯關系,梳理專業培養方案,研究課程對所關聯專業技能的學時分配,研究學生培養的實際效果,并結合專業指導教師自身的學生培養經驗,設定各課程對所關聯專業技能的加權值。
2) 借助各種統計分析算法,如因子分析等,根據相關歷史記錄,確立課程與算法中關鍵因素之間的關系,確立算法中關鍵因素與專業技能之間的關系,進而確立課程對專業技能的加權值。
兩類方法中,前者對專業指導教師經驗的依賴性較強,而后者則需要大量學生在校學習信息和就業信息的支持。在完成課程對專業技能的加權值的設定后,升級關聯關系庫,形成本層所需要的加權關聯關系庫,同時對查詢規則進行升級,以便于提供基于協同過濾的雙向查詢推薦服務。
除基本的知識點、課程與專業技能關聯關系查詢外,雙向查詢推薦服務在協同過濾技術的基礎上,查詢加權關聯關系庫,實現各種修學計劃的推薦服務,其中比較典型的有:
1) 根據學生感興趣的企業崗位或目標專業技能進行修學計劃推薦。若由學生直接選擇所感興趣的目標技能,則查找并列舉對目標技能要求強度超過閾值的就業崗位,作為目標崗位。否則,將學生感興趣的企業崗位作為目標崗位,將目標崗位所需要的要求強度超過閾值的專業技能作為目標技能。查找在目標崗位上工作的畢業生,計算此類畢業生在校學習期間目標技能值的平均值,以此作為用戶目標技能的期望值,查找K近鄰(畢業生)信息。以專業培養方案中必修課設定和選課基本要求為約束條件,以K近鄰的修學計劃為篩選補充依據,以目標技能為終點,雙向檢索加權關聯關系庫,完成修學計劃推薦。
2) 查詢顯示常見的完整的修學計劃。讀取畢業生就業崗位信息,按照其所需要的專業技能及其要求強度進行聚類,選取每一類的中心崗位。以中心崗位為目標崗位,以中心崗位所需要的要求強度超過閾值的專業技能為目標技能,按照與第1)類服務類似的方法,完成每一類就業崗位修學計劃的推薦。
3) 根據學生當前已修課程集合(記為SA)和目標技能進行修學計劃推薦。計算該學生的當前能力值TSA,查找對目標技能(其確立與第1)類服務相同)要求強度超過閾值的就業崗位作為目標崗位。查找在目標崗位上工作的畢業生,計算此類畢業生通過SA課程所獲得的能力值,以TSA為目標,查找K近鄰信息。以專業培養方案中必修課設定和選課基本要求為約束條件,以K近鄰的修學計劃為篩選補充依據,以SA課程為起點,以目標技能為終點,雙向檢索加權關聯關系庫,完成后繼修學計劃的推薦。
4) 根據學生SA課程推薦后繼修學計劃。計算該學生當前的單項/綜合能力值,將值最大的單項能力/綜合能力記為T_M,其值記為Tmax。計算畢業生通過SA課程所獲得的T_M能力的值,以Tmax為目標,查找K近鄰信息。以專業培養方案中必修課設定和選課基本要求為約束條件,以K近鄰的修學計劃為篩選補充依據,以學生SA課程為起點,完成后繼修學計劃的推薦。
其中,1)、2)兩種服務主要適用于剛入學的新生,使其能初步了解在校學習的整體情況以及各種目標技能的修學途徑。以上各種服務還可以向學生提供K近鄰的后繼學習統計分析、就業去向分析、發展狀況分析等,使學生全面了解學習內容、修學線索、就業及發展前景等信息,從而提供更細致地學習指導與推薦。
為了提高系統的友好度,學習指導與推薦層還提供圖形化輸出接口,以簡潔圖形或圖表的形式輸出所查詢的各種關聯關系、所薦的修學計劃和各種分析結果。
3 平臺建設與應用
本文以本校網絡工程專業為核心進行了基于協同過濾的專業學習指導平臺的建設。
3.1 專業技能需求分析與加權關聯關系分析
期間,對該專業學生就業單位典型代表的專業技能需求進行了調研、匯總分析;對該專業近40門常開專業課(含選修課)和8門集中實踐教學環節(以下統稱為課程)進行了知識點、課程與技能關聯關系分析;整理了2011級-2015級5屆學生的在校學習信息和就業信息。同時,利用因子分析技術對這些數據進行了分析:KMO統計量為0.922,大于最低標準0.5,Bartlett球形檢驗的結果中Sig.項的值為0.000,小于0.05,說明這些數據適合做因子分析;主要成分列表中特征值大于1的前14個主成分的累積貢獻率超過70%,故選前14個公共因子;公因子方差結果中每個指標變量(即課程)的提取值均在0.5以上,且多數接近或超過0.7(如圖5所示),因此所選公因子能較好地反映原始指標變量的大部分信息。根據所得的旋轉成分矩陣對各個公共因子的專業能力含義進行了解釋,進而確立了各課程對各專業能力的加權值,其中,部分公共因子上具有較大載荷的課程及對因子能力的解釋如表1所示。


圖5 主成分列表、公因子方差、旋轉成分矩陣部分內容

表1 部分公共因子對應能力解釋
3.2 關鍵詞
同時,本文開發了相應的平臺系統實現了基于協同過濾的雙向查詢推薦、鄰近分析和圖形化輸出。在K近鄰查找時,所采用的部分定義及公式如下。


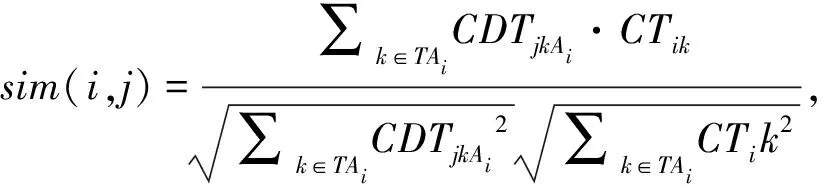
系統中所實現的查詢推薦算法比較典型的如下所示。這些算法的正確執行要求專業培養方案的知識結構是健壯的、無冗余的,即任何課程的先修課程(中學階段的課程除外)仍在同一培養方案中;同一培養方案中,任意兩門專業課程的關鍵知識點的重復率趨于0。
1) 根據學生感興趣的企業崗位或目標專業技能進行修學計劃推薦的算法(偽代碼)。
//IE_Jobs:感興趣的企業崗位/目標崗位列表;WA_Db:加權關聯
//關系庫;
//TP_Skills:目標專業技能列表;TP_SValues:目標專業技能值
//列表;
//TP_Knowledge:目標知識點集合;TP_Courses:目標課程集合
//CA:推薦課程列表;EA:選修課程列表;K_neighbors:K近
//鄰信息列表;
//SR:選課比例/優先值列表,初始值為空;
function search_add_p_courses(CA,ea_max)
//完成選修課ea_max先修課程的查詢確認或添加
{EA_Pc=search_p_courses(WA_Db,ea_max);
//獲取EA_max的先修課程(前驅課)
for (spcinEA_Pc)
if (spcnot inCA)
{將spc添加到CA中;
search_add_p_courses(CA,spc);
}
}
function service1(IE_Jobs,TP_Skills)
//根據學生感興趣的企業崗位或目標專業技能進行修學計劃
//推薦
{if (IE_Jobsis not empty)
TP_Skills=IE_Jobs所需的要求強度超過閾值的專業技能;
else
IE_Jobs=TP_Skills技能要求強度超過閾值的就業崗位;
TP_Knowledge=search(WA_Db,TP_Skills,null);
//查找企業崗位對目標技能所要求的關鍵知識點——目標知
//識點
TP_Courses=search(WA_Db,null,TP_Knowledge);
//查找包含目標知識點的課程——目標課程
TP_SValues=在IE_Jobs崗位上工作的畢業生的TP_Skills的
每一元素平均值列表;
K_neighbors=search_K_N(IE_Jobs,TP_Skills,TP_SValues);
//對于IE_Jobs崗位上的畢業生的TP_Skills技能,以TP_SValues
//為期望,查找K近鄰
CA=專業培養方案中的必修課程列表(初始值);
TP_EA=TP_Courses中屬于選修的課程列表;
EA=K_neighbors信息中所涉及到的選修課程列表+TP_EA;
for (ssainEA)
if (ssainTP_EA)
SR.add(1+|ssa對目標技能加權值|*
目標崗位對目標技能要求強度的最大值);
else
SR.add(K_neighbors中選修ssa人數/K);
flag=false;
while (flagis false andEAis not empty)
{ea_max=EA中選課比例/優先值最大的課程;
if (CA中選修課學分尚未滿足基本要求)
{if (ea_maxnot inCA)
{將ea_max添加到CA中;
search_add_p_courses(CA,ea_max);
}
刪除EA中的ea_max以及SR中的對應元素;
}
if (CA中選修課學分已滿足基本要求)
flag=true;
}
Grapic_output(WA_Db,CA);
//完成推薦課程及其圖形化輸出
}
2) 根據學生SA課程推薦后繼修學計劃的算法(偽代碼)。
function service4(Student_id,SA,Tflag)
//根據學生SA課程推薦后繼修學計劃
{根據學生已修課程集合SA的成績計算Student_id對應學生當前的各項能力值;
if (Tflag==1)
T_M=Student_id對應學生當前值最大的單項能力;
else
T_M=Student_id對應學生當前的綜合能力標識;
Tmax=Student_id對應學生T_M能力的具體數值;
//對于畢業生通過SA課程所獲取的T_M能力,以Tmax為期望,
//查找K近鄰
K_neighbors=search_K_N_4(SA,T_M,Tmax);
EA=K_neighbors信息中所涉及到的SA之外的選修課程列表;
CA=專業培養方案中的必修課程列表(初始值);
for (ssainEA)SR.add(K_neighbors中選修ssa人數/K);
flag=false;
while (flagis false andEAis not empty)
{ea_max=EA中選課比例最大的課程;
if (CA中選修課學分尚未滿足基本要求)
{ if (ea_maxnot inCA)
{ 將ea_max添加到CA中;
search_add_p_courses(CA,ea_max);
}
刪除EA中的ea_max以及SR中的對應元素;
}
if (CA中選修課學分已滿足基本要求)
flag=true;
}
Grapic_output(WA_Db,CA,SA);
}
3.3 系統運行實例
本文平臺系統部分運行實例界面如圖6所示。
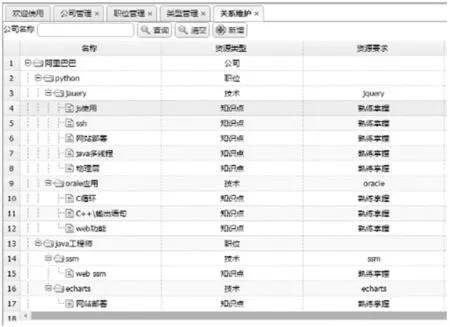
(a) 企業崗位需求維護頁面
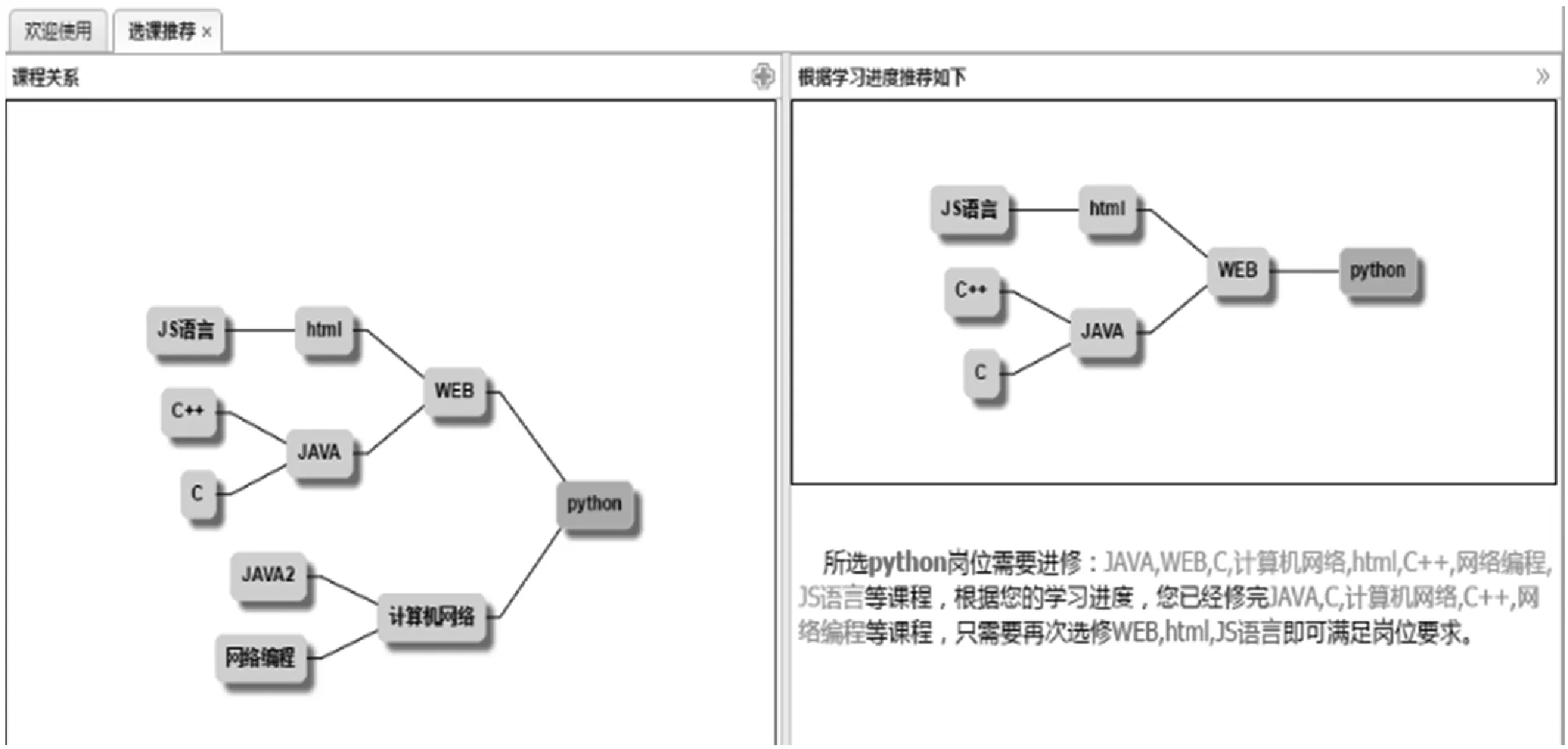
(b) 課程關系及修學推薦頁面圖6 系統運行實例頁面
4 結 語
基于協同過濾的專業學習指導平臺通過“專業技能需求分析、課程與技能關聯關系分析、學習指導與推薦”三個不同層次的模塊,充分利用校企合作,使學生及時了解知識點、課程與專業技能之間的關系和企業崗位需求,可根據學生已修課程情況,結合學生興趣,進行協同過濾、近鄰分析,為學生推薦修學計劃。
猜你喜歡
故事作文·高年級(2023年10期)2023-10-23 11:21:18
當代陜西(2021年17期)2021-11-06 03:21:36
內蒙古教育(2021年20期)2021-03-08 01:09:14
計算機教育(2020年5期)2020-07-24 08:53:38
家庭影院技術(2019年11期)2019-12-09 09:14:30
學苑創造·A版(2018年11期)2018-02-01 06:29:20
中國公路(2017年19期)2018-01-23 03:06:33
學苑創造·A版(2017年6期)2017-06-23 14:10:46
讀者(2017年5期)2017-02-15 18:04:18
Coco薇(2015年11期)2015-11-09 13:03:51
