信噪比自適應Turbo自編碼器信道編譯碼技術
2022-07-18 08:57:52胡啟蕾許佳龍鐘章隊
無線電通信技術 2022年4期
關鍵詞:模型
胡啟蕾,許佳龍,李 倫,鐘章隊,3,艾 渤,4,陳 為,5*
(1.北京交通大學 軌道交通控制與安全國家重點實驗室,北京100044;2.中興通訊股份有限公司,廣東 深圳518057;3.寬帶移動信息通信鐵路行業重點實驗室,北京100044;4.智慧高鐵系統前沿科學中心,北京100044;5.北京市高速鐵路寬帶移動通信工程技術研究中心,北京100044)
0 引言
信道編碼通過對信源壓縮后的信息序列添加校驗和冗余,提高傳輸的可靠性。香農信道編碼定理指出當信道傳輸率不超過信道容量時,采用合適的信道編碼方法,可以實現無差錯傳輸。經過不斷的努力和探索,研究者們相繼提出了漢明碼[1]、卷積碼[2]、Turbo碼[3]、LDPC碼[4]和Polar碼[5]等信道編碼,以期能夠接近香農理論限。漢明碼[1]是第一個實用的差錯編碼方案。卷積碼[2]充分利用各個信息塊之間的相關性,在維特比譯碼算法提出后,卷積碼在通信系統得到了極為廣泛的應用。Turbo碼[3]和LDPC碼[4]可以接近香農限,而Polar碼[5]則是唯一被證明能達到香農限的編碼方法。在傳統的通信系統信道編譯碼算法設計中,首先通過優化編碼器的某些數學特性(如最小碼距)設計編碼方案,然后根據最大后驗概率(Maximum a Posteriori,MAP)原則得到最小化誤碼率時的譯碼算法。然而傳統的信道編譯碼算法設計存在以下問題:譯碼器是在加性高斯白噪聲(Additive White Gaussian Noise,AWGN)下設計的,當實際信道模型不為AWGN時,所設計的譯碼算法并不能達到最優性能。其次,只有在編碼長度無限長時,才能保證信道編碼的性能是最優的。實際中待編碼的信息序列并非無限長,因此需要在中短碼長上優化編碼方法。此外,如何降低信道編譯碼算法的復雜度和誤碼率也是需要優化的。
深度學習(Deep Learning,DL)作為一種基于神經網絡的數據驅動方法,已經在計算機視覺、自然語言處理等領域表現出卓越的性能。受此啟發,通信研究者嘗試使用深度學習解決無線通信的物理層問題[6],如信道編譯碼[7-8]、信道估計[9-10]、信道狀態信息反饋[11]和信號檢測[12-14]。現有基于DL的譯碼技術已對優化譯碼性能的問題進行了研究。文獻[15]提出了一種基于循環神經網絡(Recurrent Neural Network,RNN)結構的信道譯碼方法,該方法可以譯碼卷積碼和Turbo碼,在AWGN信道下達到接近最優的性能。文獻[16]提出一種以置信傳播(Belief Propagation,BP)算法為基礎的迭代BP-CNN譯碼算法,利用卷積神經網絡(Convolutional Neural Network,CNN)學習真實噪聲與估計噪聲之間的誤差。實驗表明,在噪聲相關性較強時,提出的BP-CNN譯碼算法的性能優于BP算法。此外,由于CNN的高效性,BP-CNN結構也具有更低的譯碼復雜度。
傳統信道編碼基于AWGN信道進行設計以簡化設計難度。而當實際通信信道不為AWGN信道時[17],信道編碼的性能難以保證。其次,實際通信中編碼長度有限,針對無限碼長下設計的編碼方案性能并非最優。在譯碼端,一旦編碼方法已經確定,算法所能達到的最優性能接近MAP算法的性能。因此,考慮到譯碼的性能受到信道編碼方案的影響,聯合編譯碼器設計能夠獲得更多的性能增益。O′Shea等人將通信系統視為一個端到端的重構任務,在文獻[18]中提出使用自編碼器的網絡結構來共同設計編碼器和譯碼器。當編碼器和譯碼器在相同的信噪比(Signal-to-Noise Ratio,SNR)下訓練時,所提出的基于自編碼器的(7,4)碼編譯碼性能可達到(7,4)漢明碼采用最大似然譯碼(Maximum Likelihood Decoding,MLD)的性能。此外,Xu等人在文獻[19]中比較了自編碼器和漢明碼的性能,在真實的衰落信道下,所提出的自編碼器的性能與漢明碼采用MLD性能相近。在復雜的通信場景下,信道模型難以用數學模型精確描述[20]。Raj等人在信道狀態信息(Channel State Information,CSI)未知的情況下,提出一種端到端通信系統的優化方法[21]。在無法準確估計瞬時信道傳輸的情況下,Ye等人在文獻[22]中使用生成對抗神經網絡(Generative Adversarial Network,GAN)來學習信道生成模型,結果表明,所提出的端到端編譯碼結構在AWGN信道、Rayleigh信道和頻率選擇性衰落信道中,該方法與傳統方法相比可以達到類似或更好的性能。此外,文獻[23]中提出了一種基于神經網絡互信息估計器,在固定譯碼器的情況下,該估計器以達到最大互信息為目標去學習信道特征進而優化編碼器。Jiang等人在文獻[24]中提出了一個基于CNN的端到端信道編譯碼系統Turbo Autoencoder(TurboAE),該方法評估了中短碼長(碼長為100 bit)的TurboAE的性能,在-1~1 dB下,TurboAE的誤碼率低于Turbo碼的誤碼率;在1~4 dB時,TurboAE的誤碼率與Turbo碼的誤碼率相近。
然而,為了使訓練好的TurboAE模型充分發揮其優勢,在測試時需要匹配對應的信道狀態,例如,在信道SNR為1 dB時訓練的系統網絡模型,在信道SNR為1 dB下傳輸信息,其性能才最好。在實際通信系統中,信道SNR并不是恒定的,這意味著TurboAE需要在一段SNR范圍內進行訓練并儲存多個模型,不僅增加了訓練的時間復雜性,也增加了系統模型存儲量。本文設計了一個基于DL的端到端信道編譯碼系統,該系統可以在一段SNR范圍內進行訓練和測試,在僅用一個模型的情況下,就可以達到在單個SNR下訓練的最優性能。
1 系統模型
本文所采用的系統模型如圖1所示。在編碼端,u∈{0,1}n為待編碼的信息序列,其中n為信息序列的長度。在編碼端,在已知的信道信噪比s∈的情況下,信息序列u經過信道編碼后被映射為碼字x∈k,其中k為碼字的長度,信道編碼的碼率為R=n/k。信道編碼的過程可以表示為:

圖1 基于SNR信息的端到端信道編譯碼系統
x=fθ(u,s),
(1)
式中,θ表示編碼器的參數集。令編碼器的輸出x滿足軟功率約束,即(x)=0與(x2)=1。
考慮系統處于獨立同分布(identically and independently distributed,i.i.d.)的AWGN信道下,則譯碼端接收到的信號y∈k可以表示為:
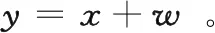
(2)
噪聲w∈k服從高斯分布(0,σ2),其中,σ2為噪聲功率,與信道SNR的關系可以表示為:
(3)
本文提出的方法也適用于瑞利衰落信道。則譯碼端接收到的信號y∈k可以表示為:
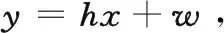
(4)
式中,h表示信道增益。
在沙河的一個小河叉邊,兩個人老遠就聞到一股惡臭,對面的岸邊浮著一具已經泡脹的尸體,沒有衣服,面朝下。湯翠腿一軟,哆哆嗦嗦地癱坐到地上。侯大同沒有猶豫,跳下水,徑直撲到尸體跟前。那情景,完全是奮不顧身的詮釋。蒼蠅散開,侯大同小心地翻轉尸體,不是湯蓮!湯翠心里其實充滿了遺憾。找了這么多天,湯翠身心疲憊,她已經不怕面對姐姐罹難的現實了。
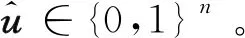
(5)
式中,φ表示譯碼器的參數集。與現代通信系統的模塊化設計結構相比,本文使用的編碼器包含信道編碼模塊和調制模塊的功能,譯碼器包含信道譯碼模塊和解調模塊的功能。
因此,對于基于DL的端到端信道編譯碼系統,當碼長n和碼率R固定時,優化目標是找到使誤差最小化時的編碼器和譯碼器的最優參數集θ*和φ*。該優化問題可以被建模為:
(6)

(7)
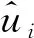
2 Attention-TurboAE結構
Jiang等人在文獻[24]中提出了一個基于一維CNN的端到端信道編譯碼系統TurboAE。在AWGN信道下,該系統在中短碼長(碼長為100 bit)上表現出接近或優于使用Bahl-Cocke-Jelinek-Raviv譯碼算法的Turbo碼的性能。但是,為了使TurboAE在各種信道條件下都能達到最優性能,需要針對不同的信道SNR下訓練不同的TurboAE模型,并在實際的信道SNR下采用相匹配的訓練模型。在實際移動通信系統中,信道復雜多變,信道的SNR難以維持恒定不變,為保證系統的最優性,對于不同的SNR,需要訓練并儲存多個模型,以應對信道的變化,然而,該策略增加了對實際通信設備存儲容量的需求。因此,本文提出一種自適應SNR的端到端信道編譯碼結構Attention-TurboAE,在確保編譯碼性能的同時,大幅減少了模型的存儲容量。
2.1 TurboAE
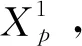
(a) TurboAE編碼器結構
(8)
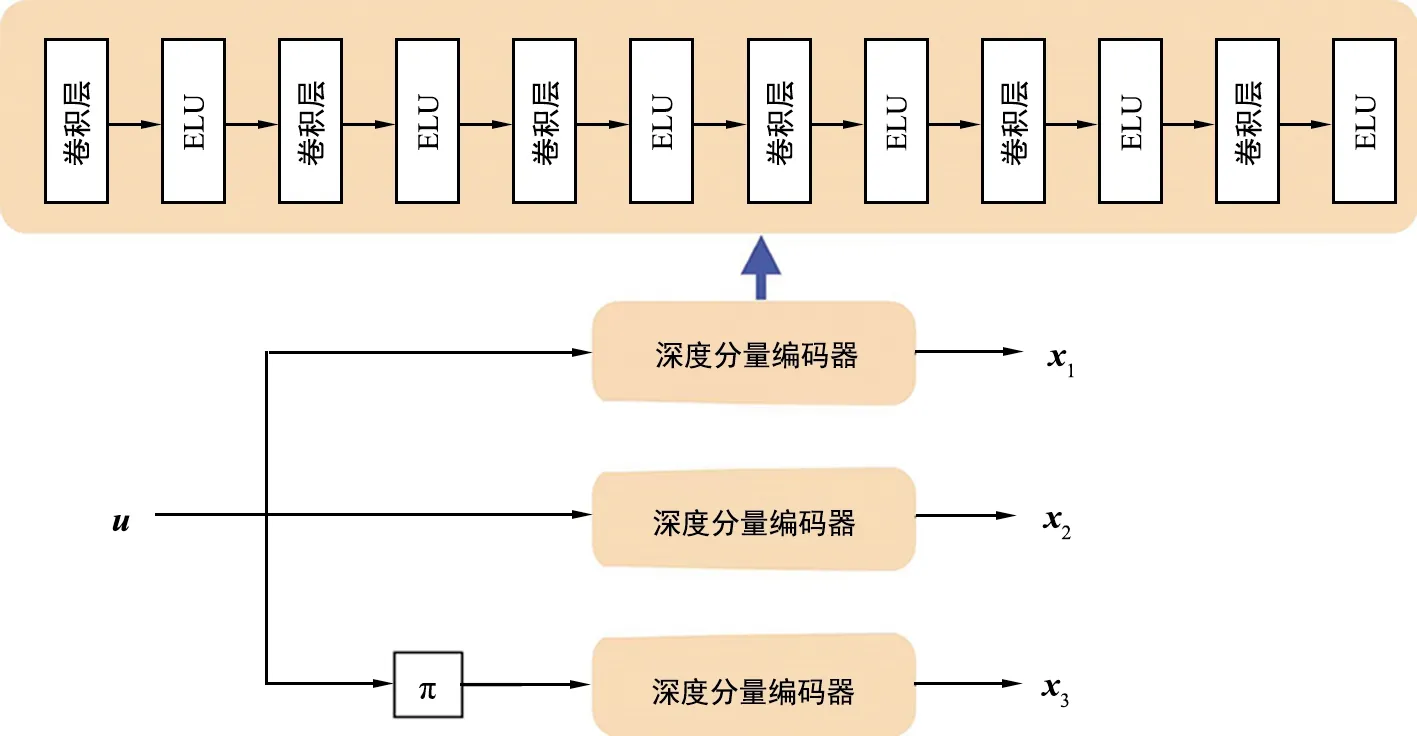
接收機收到帶有噪聲的接收序列后,進行譯碼。類比于TurboAE編碼器的設計,譯碼器采用基于CNN的深度分量譯碼器替代原有Turbo譯碼器中分量譯碼器。卷積層和ELU激活函數迭代5次后,經過一層線性層,構成了深度分量譯碼器,如圖2(b)所示。將接收序列y首先拆分為對應的y1、y2和y3。y1、y2與先驗p(第一次迭代置為0)作為每一次迭代中第一分量譯碼器的輸入,產生后驗q。交織后的y1、y3與交織后的q作為第二分量譯碼器的輸入,產生先驗p。經過去交織操作的p作為下一次迭代的輸入。進行多次迭代后,通過Sigmoid激活函數(如式9所示),將輸出控制在(0,1)范圍內,表示估計的原始信息比特為1的概率。
(9)
為了達到最優性能,TurboAE需要在單個SNR下訓練模型,并在相同的SNR下進行測試。然而,當SNR發生變化時,所訓練的模型不再保證其是最優的。因此,考慮設計一個自適應SNR的編譯碼方法,能夠根據不同的SNR,自適應進行模型的調整,以達到在不同的SNR下,系統性能都是最優的。由于TurboAE優越的性能和良好的設計,本文將TurboAE的編碼器和譯碼器結構作為Attention-TurboAE的基礎編碼器和譯碼器結構,以設計信噪比自適應的Turbo自編碼器信道編譯碼系統。
2.2 基于注意力機制的自適應SNR設計
Xu等人在文獻[24]中提出Attention DJSCC(ADJSCC)結構,將注意力機制引入基于DL的聯合信源信道編碼(DL Based Joint Source Channel Coding,DJSCC)中。在不同的信道SNR下,ADJSCC可以動態調整信源編碼壓縮率和信道編碼率。受此啟發,本文提出基于注意力機制的自適應SNR模塊,用以感知信道SNR的變化。在不同的信道條件下,通過對碼字分配不同的貢獻度,生成與信道條件相匹配的編碼碼字。
基于注意力機制的自適應SNR模塊設計如圖3所示。自適應SNR模塊主要包括三部分:特征提取、貢獻度預測和貢獻度分配。其中,特征提取模塊通過平均池化操作提取特征,引入信道SNR作為特征的一部分。貢獻度預測模塊用以感知信道SNR,學習不同SNR下各個特征圖中通道之間的非線性關系。在實際中,可以達到不同的信道條件下,自適應調整各個特征之間的關系,進而預測出不同的貢獻度。最后,預測的貢獻度與原始特征圖進行運算,完成貢獻度的分配,生成與信道條件相匹配的碼字。
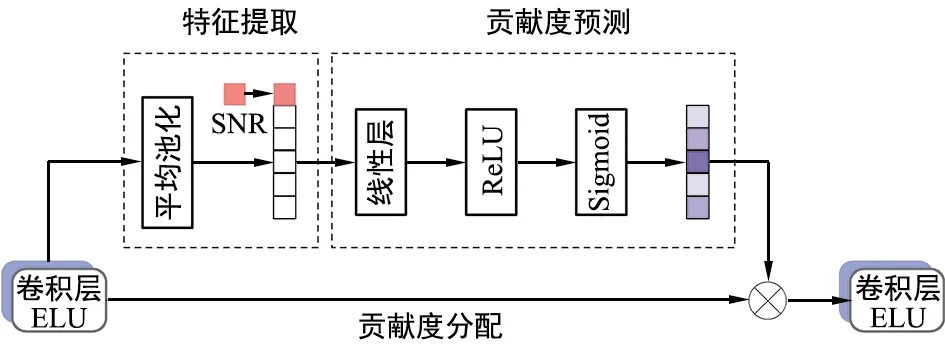
圖3 基于注意力機制的自適應SNR模塊結構
本文提出的自適應SNR模塊連接于卷積層之間。在特征提取模塊中,首先使用全局平均池化操作獲取全局描述特征Gi,操作過程可表示為:
(10)
式中,AVG(·)表示全局平均池化操作,F=[F1,F2,…,Fc]∈n×c為卷積層輸出的特征圖,其中,c為特征圖通道的數量,fi為Fi中的元素。信道信噪比s作為全局描述特征的一部分被引入,產生特征信息G,過程可表示為:
(11)
貢獻度預測模塊P(·)用來預測不同特征的貢獻度。該模塊由兩層線性層組成,第一層線性層連接Relu激活函數,第二層線性層連接Sigmoid激活函數。Sigmoid激活函數使輸出介于0和1之間,表示預測的貢獻度C,其過程可表示為:
(12)
式中,α和β分別表示激活函數Sigmoid和ReLU,w1和b1分別表示第一層線性層的權重和偏差,w2和b2分別表示第二層線性層的權重和偏差。
最后,在貢獻度分配模塊中,將預測的貢獻度與原始特征圖相乘,使模型對不同特征有更多的辨別能力,很好地學習不同信道SNR下特征圖之間的關系。重新分配后的特征圖F′可以表示為:
(13)
將上述自適應SNR模塊應用于TurboAE編碼器和譯碼器中,所得到的Attention-TurboAE結構如圖4所示。

(a) Attention-TurboAE編碼器結構
3 實驗結果
本節通過對TurboAE和Attention-TurboAE進行實驗仿真,以證明注意力機制在自適應信道SNR的信道編譯碼方案中的可行性和有效性。首先,在AWGN信道和瑞利衰落信道下,分別對比Attention-TurboAE和TurboAE的性能。其次,對Attention-TurboAE的擴展性進行了實驗,即將在固定碼長下訓練的模型,在不同碼長上測試。最后,對自適應SNR模塊的作用效果給出了相應的解釋。
實驗在Linux服務器上進行,該服務器包括12個8核Intel(R) Xeon(R) Silver 4110 CPU和16個GTX 1080Ti GPU,每次實驗使用1個GPU。實驗在Python3.6的環境下采用PyTorch 1.0版本。使用初始學習率為0.000 1的Adam優化器來搜索最佳網絡參數。隨機生成100 000個碼長為100的二進制數據樣本作為訓練集,隨機生成100 000個碼長為100的二進制數據樣本作為測試集,訓練800次以保存最佳參數模型。Attention-TurboAE與TurboAE編碼器碼率R都設置為1/3,譯碼器中的迭代次數為6次,特征圖的通道數為100。
3.1 AWGN信道
在AWGN信道下,分別采用圖2所示的TurboAE結構和圖4所示的Attention-TurboAE結構進行實驗。當碼長為100時,在信道SNR為0~4 dB內訓練并測試Attention-TurboAE,在SNR分別為0,1,2,3,4 dB下訓練Turbo模型,并在SNR為0~4 dB范圍內測試,實驗結果如圖5所示。
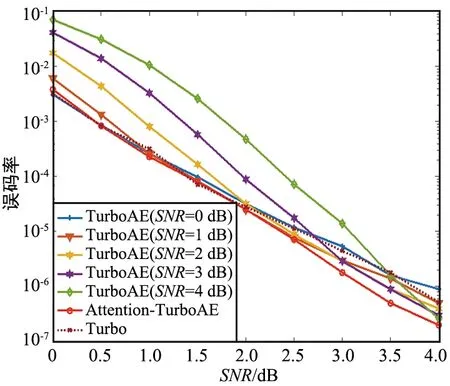
圖5 AWGN信道下,100碼長訓練并測試時,Attention-TurboAE與TurboAE性能對比
實驗證明,在特定SNR下訓練的TurboAE模型只有在相同的SNR下測試時才能展示出其最佳性能。為了滿足信道編譯碼系統的性能在一段SNR范圍內都能達到最優,需要訓練多個模型,進而導致存儲量的增加。然而對于實際通信來說,系統需要能夠自適應不同的信道條件,產生相匹配的編碼碼字。Attention-TurboAE雖然在一段SNR范圍內進行訓練,卻可以達到TurboAE單個SNR下訓練和測試時的最優性能,大大減少了通信系統的儲存量。此外,實驗設置碼長100、碼率1/3的Turbo碼作對照,實驗結果(圖6)表明Attention-TurboAE在低SNR(0~2 dB)下接近Turbo碼性能,在高SNR(2~4 dB)優于Turbo碼性能。
3.2 瑞利衰落信道
瑞利衰落信道(Rayleigh Fading Channel)模型假設信號通過無線信道之后,其信號幅度是隨機的,并且其包絡服從瑞利分布。考慮信道為瑞利衰落信道時,在100碼長下,對Attention-TurboAE和TurboAE的性能進行對比。采用基于3.1節中在AWGN信道上訓練好的Attention-TurboAE和TurboAE模型進行微調(Fine-tune)。此外,設置瑞利衰落信道下的Turbo碼性能作為對照,實驗結果如圖6所示。Attention-TurboAE在瑞利衰落信道下,也基本可以達到Turbo碼單個SNR下訓練的性能。與Turbo碼相比,Attention-TurboAE在2~4 dB下性能略低。這是因為,Attention-TurboAE是在基于AWGN信道下訓練好的模型進行微調,因此,在較高SNR下,性能比Turbo碼較低。
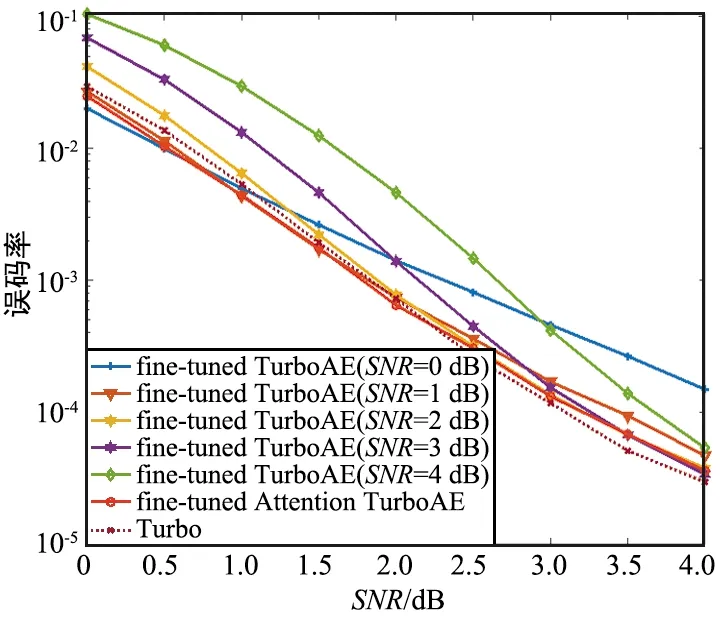
圖6 瑞利衰落信道下,100碼長下訓練時,Attention-TurboAE與Turbo性能對比
3.3 擴展性
當實際系統模型的輸入與訓練模型時的輸入不匹配時,例如,對于一個在特定碼長下訓練的系統,如果輸入碼長發生了變化,我們仍然希望其性能較優。因此,在信道SNR分別為0,1,2,3,4 dB,碼長為100時訓練TurboAE;而在SNR為0~4 dB,碼長分別為50和200進行測試。對于Attention-TurboAE結構,在信道SNR為0~4 dB、碼長為100時進行訓練,并分別在碼長為50和200的情況下進行測試。設置碼長分別為50和200的Turbo碼作為對照實驗。
圖7(a)展示了TurboAE和Attention-TurboAE在碼長為100時訓練,碼長為50時的測試結果;圖7(b)展示了TurboAE和Attention-TurboAE在碼長為100時訓練,碼長為200時的測試結果。實驗結果顯示無論輸入碼長的大小,Attention-TurboAE的性能基本能達到單個SNR下訓練TurboAE的性能。

(a) 測試碼長為50
此外,當測試碼長為50時,Attention-TurboAE在1.5~4 dB下的性能優于Turbo碼。對比測試碼長為200時的性能,隨著碼長的增加,Attention-TurboAE的誤碼率越低,例如,在SNR為2 dB下,Attention-TurboAE在測試碼長為200時的誤碼率比測試碼長為50時的誤碼率低。由于測試環境(測試碼長為200)與訓練環境(訓練碼長為100)并不匹配,且Attention-TurboAE是自適應信道SNR的編譯碼系統,并非自適應碼長,因此,在測試碼長為200時,與Turbo碼相比性能略差;且碼長越長,SNR越高時,Turbo碼的性能會越好。
3.4 解釋
為了探索在不同的SNR下,自適應SNR模塊是如何根據不同的信道噪聲影響特征圖中各個通道的貢獻度,實驗基于碼長為100下訓練的Attention-TurboAE模型。首先比較分析了不同信道噪聲下Attention-TurboAE編碼器中第3個自適應SNR模塊產生的貢獻度,結果如圖8所示。可以看出,在訓練和測試碼長都為100時,針對不同的信道SNR,貢獻度是不同的,這意味著對于不同的信道條件,本文所提出的自適應SNR結構將生成不同的編碼碼字。此外,為了分析Attention-TurboAE的擴展性,當訓練碼長為100時,分別在SNR為2 dB下選取測試碼長為50、100、200下第3個自適應SNR模塊的貢獻度,結果如圖9所示。可以發現,對于相同的SNR,不同測試碼長對貢獻度的影響很小,注意力機制只對不同的SNR起作用。通過引入SNR自適應模塊,Attention-TurboAE可以更加關注信道SNR的影響,根據信道條件,為特征圖中不同的通道分配不同的貢獻度。
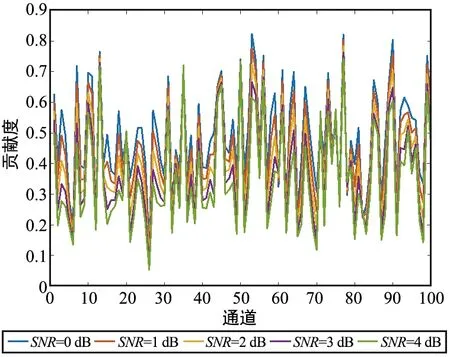
圖8 訓練和測試碼長都為100時,不同SNR下各個通道的貢獻度
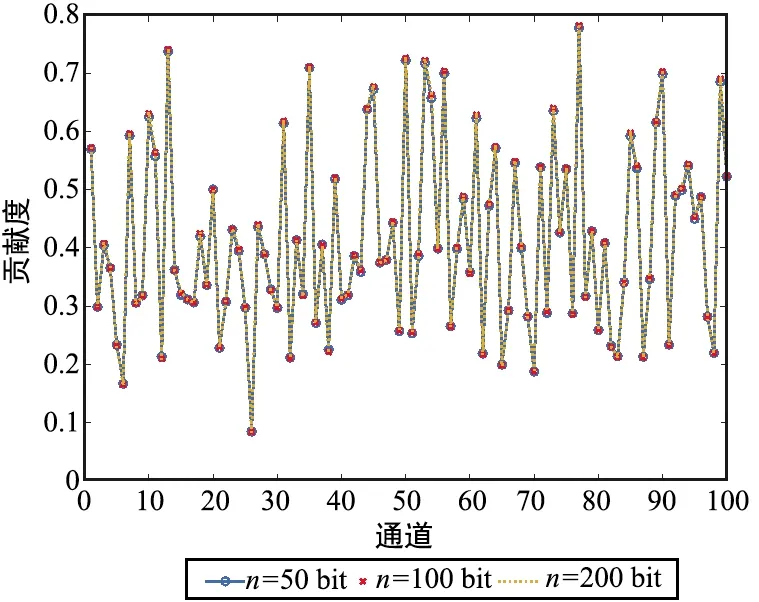
圖9 SNR=2 dB、訓練碼長為100時,不同測試碼長下各個通道的貢獻度
4 結論
本文分析了TurboAE的結構,并通過引入注意力機制提出了信噪比自適應Turbo自編碼器信道編譯碼方案Attention-TurboAE。盡管TurboAE在AWGN信道下比Turbo碼有更好的性能,但在實際部署中,訓練好的模型只有在相匹配的信道條件下才能達到最優性能。通過在信道編譯碼中引入注意力機制,提出的自適應信道SNR結構可以根據不同的信道條件,生成與之匹配的編碼碼字。在一段SNR范圍內訓練的系統模型可以達到在單個SNR下訓練的TurboAE的性能,大大減少了設備端的存儲量。此外,Attention-TurboAE展示出了注意力機制在自適應SNR信道編譯碼系統中的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
