基于啟發(fā)式強(qiáng)化學(xué)習(xí)的移動機(jī)器人路徑規(guī)劃算法研究
2022-07-23 15:51:40潘國倩周新志
現(xiàn)代計算機(jī) 2022年10期
潘國倩,周新志
(四川大學(xué)電子信息學(xué)院,成都 610065)
0 引言
路徑規(guī)劃是移動機(jī)器人完成各種任務(wù)的必要前提,也是其進(jìn)入現(xiàn)實生活的重要環(huán)節(jié),還是研究智能機(jī)器人的重要組成部分,其主要目的就是要在機(jī)器人的運行環(huán)境中找到一條從起點到終點的無碰撞路徑。根據(jù)機(jī)器人對環(huán)境的已知程度,目前的路徑規(guī)劃方法可以分為環(huán)境已知的全局路徑規(guī)劃和環(huán)境未知的局部路徑規(guī)劃,如人工勢場法、模糊邏輯算法、蟻群算法、粒子群算法、神經(jīng)網(wǎng)絡(luò)算法等。由于移動機(jī)器人在實際應(yīng)用中需要應(yīng)對一些突發(fā)情況,因此有必要引入一種自學(xué)習(xí)的機(jī)制使得機(jī)器人能夠通過學(xué)習(xí)來實現(xiàn)自主避障。
強(qiáng)化學(xué)習(xí)是一種基于“試錯”方式的學(xué)習(xí)算法,機(jī)器人通過不斷嘗試動作來與環(huán)境進(jìn)行交互,獲得環(huán)境反饋的“獎勵”,進(jìn)而選擇最佳動作規(guī)劃路徑。其不僅通過結(jié)合神經(jīng)網(wǎng)絡(luò)、智能控制及運籌學(xué)等算法或理論知識在理論和應(yīng)用方面發(fā)展迅速,而且也被越來越多地運用在機(jī)器人的自動控制、運動以及智能調(diào)度等領(lǐng)域,在人工智能方面成為了學(xué)者們研究的熱點。其中,Q-learning算法是目前使用最為廣泛的強(qiáng)化學(xué)習(xí)算法。Q-learning算法被應(yīng)用于機(jī)器人路徑規(guī)劃時,由于其不具先驗知識,一般會直接將Q值表初始化為全零的矩陣,故往往存在學(xué)習(xí)時間長、收斂速度慢等問題。目前,已有研究來解決此類問題,文獻(xiàn)[7]使用人工勢能場虛擬化環(huán)境,并通過勢能值引入先驗知識初始化Q值,進(jìn)而提高Q-learning算法的收斂速度;文獻(xiàn)[8]結(jié)合人工勢場法,通過重新定義機(jī)器人的動作及步長來改進(jìn)Q-learning算法,提高了算法收斂速度;文獻(xiàn)[9]提出部分的Q學(xué)習(xí)概念,使用花授粉算法改善Q-learning算法的初始化,加快Q-learning算法的學(xué)習(xí);文獻(xiàn)[10]在傳統(tǒng)的Q-learning算法基礎(chǔ)上增加一層學(xué)習(xí),使得機(jī)器人能夠提前了解環(huán)境,進(jìn)而加快路徑規(guī)劃效率;文獻(xiàn)[11]為了加快Q-learning的學(xué)習(xí)速度,提出了一種集成學(xué)習(xí)策略;文獻(xiàn)[12]限制了狀態(tài)數(shù),進(jìn)而通過減小Q值表的大小提高了算法尋優(yōu)速度;文獻(xiàn)[13]研究了連續(xù)的報酬函數(shù),使得機(jī)器人采取的每個動作都能獲得相應(yīng)的報酬,提高算法的學(xué)習(xí)效率。
雖然目前已有許多方法被提出來優(yōu)化Qlearning算法,但是移動機(jī)器人尋找最佳路徑依舊是一個值得研究的問題。本文主要針對Qlearning算法進(jìn)行路徑規(guī)劃時所面臨的學(xué)習(xí)效率低、收斂慢的問題,提出一種基于Q-learning算法的啟發(fā)式算法(HQL)。首先根據(jù)移動機(jī)器人在工作環(huán)境中當(dāng)前點和終點的相對位置來選擇當(dāng)前狀態(tài)下的動作集,使機(jī)器人始終朝目標(biāo)點前進(jìn),來提高學(xué)習(xí)速度;然后,在算法中引入啟發(fā)式獎勵機(jī)制,使得機(jī)器人在選擇靠近終點的動作時收獲更多的獎勵,進(jìn)而減少機(jī)器人盲目學(xué)習(xí)。最后在柵格環(huán)境中進(jìn)行仿真實驗,驗證該算法的性能。
1 Q-learning算法
Q-learning算法是Watkins等提出的一種強(qiáng)化學(xué)習(xí)算法,也是時序差分算法中最常用的算法之一。其主要采用異策略評價估值的方法,這種方式也在很大程度上促進(jìn)了Q值的迭代更新。Q-learning算法會根據(jù)機(jī)器人上一次所處的狀態(tài)信息和當(dāng)前學(xué)習(xí)所獲得的獎勵,通過式(1)來不斷地更新自身維護(hù)的Q值表,進(jìn)而當(dāng)Q值表收斂時,機(jī)器人能從中選出最佳的狀態(tài)-動作對,得到最優(yōu)策略。
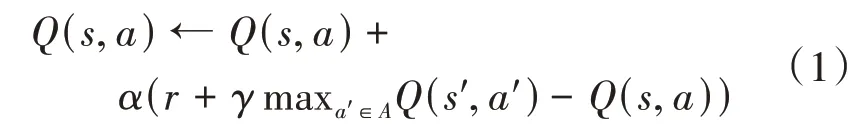
式(1)中,為學(xué)習(xí)率,表示學(xué)習(xí)新知識的程度,取值在0到1之間;是狀態(tài)下采取行動時的獎勵;為折扣率,表示考慮未來獎勵的程度,取值在0到1之間;為下一個狀態(tài),為下一個動作。
2 HQL算法
傳統(tǒng)的Q-learning算法在初始化過程中會將值設(shè)為均等值或隨機(jī)值,也就是說,算法在初始階段屬于盲目學(xué)習(xí),這在一定程度上降低了算法的學(xué)習(xí)效率。同樣地,傳統(tǒng)算法會在固定的動作集中選擇動作,由于算法的動作選擇策略存在一定的隨機(jī)性,因此機(jī)器人會存在冗余學(xué)習(xí),進(jìn)而出現(xiàn)規(guī)劃路徑不佳的情況。針對這些問題,本文在傳統(tǒng)的Q-learning算法的基礎(chǔ)上做出如下兩種改進(jìn),提出了改進(jìn)的Q-learning算法。
2.1 動態(tài)動作集策略
傳統(tǒng)的Q-learning算法的動作集是固定的,一般是上、下、左、右四個動作或是增加四個斜向動作的八個動作。根據(jù)算法的動作選擇策略,機(jī)器人在選擇動作時,存在一定的概率會隨機(jī)選擇動作集中的動作,故機(jī)器人所選的動作可能會使其遠(yuǎn)離終點,進(jìn)而影響機(jī)器人的學(xué)習(xí)效率。鑒于常識,當(dāng)我們出發(fā)去目的地時,一般會有意識地朝著目的地前進(jìn),這樣才會使我們盡快到達(dá)。由此,提出動態(tài)動作集策略,使得機(jī)器人的每一步都能朝著終點前進(jìn)。
動作集選擇策略的主要思想是根據(jù)機(jī)器人當(dāng)前所處的位置與終點的相對位置來給機(jī)器人分配動作集。本文以移動機(jī)器人的終點為參照,將算法的動作集分為如圖1所示的八種情況,然后根據(jù)式(2)判斷,此時機(jī)器人應(yīng)該選擇哪一個動作集。
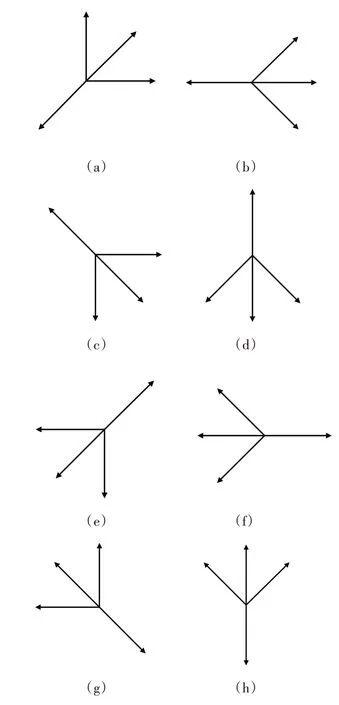
圖1 八種動作集

式(2)中,,分別為移動機(jī)器人當(dāng)前位置的橫、縱坐標(biāo),x,y分別為終點的橫、縱坐標(biāo)。機(jī)器人在某一狀態(tài)進(jìn)行學(xué)習(xí)之前,會先將機(jī)器人當(dāng)前坐標(biāo)與終點坐標(biāo)進(jìn)行運算,當(dāng)(xx )*(-y )>0且-x <0時,即d *d >0,d <0,機(jī)器人選擇第一種動作集,即圖1(a)所示動作集進(jìn)行學(xué)習(xí);當(dāng)(-x )*(-y )=0且-x <0時,即d *d =0,d <0,機(jī)器人選擇第二種動作集,即圖1(b)所示動作集;以此類推,式(2)中第3至第8條距離條件依次對應(yīng)圖1(c)至圖1(h)所示的動作集。
2.2 啟發(fā)式獎懲函數(shù)
Q-learning算法是無模型的學(xué)習(xí)算法,存在盲目學(xué)習(xí)的問題。為使機(jī)器人剛開始學(xué)習(xí)的時候就有意識地朝著終點的方向?qū)W習(xí),在一定程度上減少盲目學(xué)習(xí),進(jìn)一步加快算法的學(xué)習(xí)速度,本文從算法的獎懲函數(shù)出發(fā),通過使機(jī)器人采取不同的動作獲得不同的獎勵來指導(dǎo)機(jī)器人學(xué)習(xí)環(huán)境。若機(jī)器人采取的動作使其更接近終點,則獲得更多的獎勵;反之,則獲得的獎勵會減少。
本文中傳統(tǒng)的Q-learning算法獎懲函數(shù)設(shè)置如式(3)所示。

引入啟發(fā)式獎勵后的獎懲函數(shù)設(shè)置如式(4)所示。

其中,r 為Q-learning算法設(shè)置的獎懲函數(shù),,分別為移動機(jī)器人當(dāng)前位置的橫、縱坐標(biāo),x,y分別為終點的橫、縱坐標(biāo)。
2.3 流程設(shè)計
運用HQL算法進(jìn)行路徑規(guī)劃步驟如下:
(1)初始化算法的值表;
(2)判斷機(jī)器人總的學(xué)習(xí)次數(shù)是否小于5000,若是,進(jìn)入(3),若否,則結(jié)束學(xué)習(xí);
(3)初始化狀態(tài);
(4)根據(jù)策略選擇動作集;
(5)從動作集中選出下一步動作并執(zhí)行;
(6)根據(jù)執(zhí)行動作后的狀態(tài)得到相應(yīng)的獎勵r;
(7)根據(jù)式(1)計算并更新值表;
(8)進(jìn)入下一個狀態(tài);
(9)判斷此時機(jī)器人所處的狀態(tài)是否為終點,若是,則返回(2)進(jìn)入下一次學(xué)習(xí),若否,則返回(4)。
3 實驗及結(jié)果分析
本文實驗使用Python進(jìn)行編譯,實驗采用30×30的二維柵格地圖來表示整個環(huán)境信息。其中,左下圓點代表機(jī)器人的起點,右上圓點代表終點,實心方格表示障礙物,白色區(qū)域表示可移動區(qū)域。在仿真實驗中,傳統(tǒng)Q學(xué)習(xí)算法和本文算法學(xué)習(xí)過程中的實驗參數(shù)值設(shè)置如下。折扣因子表示考慮未來獎勵的程度,本文采取一個折中的方式,設(shè)為0.5。同時經(jīng)過多次嘗試與試驗,將嘗試次數(shù)即機(jī)器人總的學(xué)習(xí)次數(shù)設(shè)為5000,學(xué)習(xí)率和探索因子的初始值分別設(shè)為0.8和0.3,使機(jī)器人能夠得到更加充分的學(xué)習(xí)且算法性能更加穩(wěn)定。
在柵格地圖中對本文所提的改進(jìn)算法與兩種傳統(tǒng)Q-learning算法進(jìn)行驗證,證明本文的改進(jìn)算法在規(guī)劃路徑的長度和學(xué)習(xí)效率方面的優(yōu)勢。圖2(a)、(b)分別為表1中傳統(tǒng)Q-learning算法(QL_0)和本文算法(QL_2)在柵格地圖中生成的最優(yōu)路徑。

表1 學(xué)習(xí)算法在路徑規(guī)劃中的性能比較

圖2 算法規(guī)劃的路徑圖
表1中算法的收斂回合、收斂時間和路徑長度均為30次實驗數(shù)據(jù)的平均值,QL_0算法表示動作集為上、下、左、右的傳統(tǒng)Q-learning算法;QL_1算法表示動作集為上、下、左、右、右上、右下、左上、左下的傳統(tǒng)Q-learning算法;QL_2為本文所提算法。在算法收斂的判斷中,本文主要根據(jù)連續(xù)10次嘗試回合路徑長度標(biāo)準(zhǔn)差小于0.25即視為算法收斂。
從表1可知,將本文所提算法即QL_2與傳統(tǒng)的四個動作的Q-learning算法即QL_0進(jìn)行對比,算法的收斂回合提前了75.8%,收斂時間減少了45.3%,規(guī)劃的最終路徑長度縮短了24.5%。對比QL_1和QL_0可知,僅僅增加算法的動作數(shù),雖然很大程度上縮短規(guī)劃路徑的長度,但是并沒有明顯加快算法的收斂速度。根據(jù)表1的數(shù)據(jù),相較于QL_0和QL_1這兩種傳統(tǒng)學(xué)習(xí)算法,本文所提算法在不增加動作數(shù)的情況下不僅能夠縮短規(guī)劃的路徑長度,同時也能達(dá)到使算法更快收斂的目的。
4 結(jié)語
基于馬爾可夫決策過程的Q-learning算法在路徑規(guī)劃應(yīng)用中一般可以找到到達(dá)終點的路徑,但是其在復(fù)雜環(huán)境下進(jìn)行路徑規(guī)劃時學(xué)習(xí)效率低、收斂速度慢,由此提出了基于Q_learning算法的啟發(fā)式算法(HQL)。首先,學(xué)習(xí)算法是通過選擇每個狀態(tài)下最優(yōu)動作的方式來完成路徑規(guī)劃,每一次的動作選擇都在一定程度上影響機(jī)器人的學(xué)習(xí)效果,故本文從源頭出發(fā),通過控制動作集來使機(jī)器人進(jìn)行更有效的學(xué)習(xí),提高學(xué)習(xí)效率;其次,通過在算法中加入啟發(fā)式獎勵,機(jī)器人的每一個動作都能得到不同的獎勵,使得機(jī)器人能夠朝著終點運動,進(jìn)一步加快其學(xué)習(xí)。最后從仿真實驗結(jié)果可以看出,相較于傳統(tǒng)的學(xué)習(xí)算法,本文所提算法性能更優(yōu)。
猜你喜歡
北京航空航天大學(xué)學(xué)報(2022年6期)2022-07-02 01:59:12
小學(xué)生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
領(lǐng)導(dǎo)決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
制造技術(shù)與機(jī)床(2017年3期)2017-06-23 08:11:21
少年博覽·小學(xué)低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
中國衛(wèi)生(2016年2期)2016-11-12 13:22:16
中國工程咨詢(2016年4期)2016-02-14 07:28:28
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 20:56:37
