辨證論治思想指導下的中醫主題詞自動標引模型構建
2022-08-02 03:32:42張異卓周璐孫燕鄭豐杰徐鳳芹李宇航
中國中醫藥信息雜志 2022年8期
關鍵詞:模型
張異卓,周璐,孫燕,鄭豐杰,徐鳳芹,李宇航
1.北京中醫藥大學中醫學院,北京 100029;2.中國中醫科學院西苑醫院,北京 100091
主題詞標引運用計算機技術對解析的文獻進行管理,將解析的數據內容冠以恰當標識。通過對電子病歷進行主題詞標引,將病歷中的詞語與主題詞表中具有相同內涵的詞匯相對應,達成統一的文字表述,從而為系統挖掘中醫辨證論治規律及智能化處理奠定數據基礎。由于中醫詞語中包含大量“理法方藥”信息,因此,中醫電子病歷需要在辨證論治思想指導下完成主題詞標引。
隨著中醫電子病歷的普及,實踐工作對自動標引技術提出了一定需求。本研究團隊在以往研究的基礎上,采用基于雙向編碼表示(bidirectional encoder representation from transformers,BERT)的語言處理模型與Sigmoid輸出函數結合,在辨證論治思想指導下構建中醫主題詞自動標引模型,以期幫助研究人員更加高效、精準地完成中醫主題詞標引任務,并為相關研究提供數據與方法學參考。
1 資料與方法
1.1 數據來源
建模數據來源于中國中醫科學院“名醫名家傳承”項目管理平臺。該平臺的名老中醫藥專家經驗信息數據庫收錄了60余位名老中醫的臨床醫案、經驗方、學術思想及臨床經驗,且采用結構化模式進行數據采集,保證了數據的規范性。本研究收集其中22位名老中醫的電子病歷,共計3 252份。
1.2 病歷篩選標準
納入標準:①參照《人力資源社會保障部、國家衛生計生委、國家中醫藥局關于評選國醫大師、全國名中醫的通知》評定為國醫大師或全國名中醫的病歷;②屬于中醫內科疾病范疇的病歷;③病歷收集時間為2019年12月—2020年12月;④疾病、癥狀、證候、治法、處方等中醫“理法方藥”信息記錄完整。
排除標準:①中醫“理法方藥”信息記錄不明確者;②病歷數據重復者。
1.3 數據標引
1.3.1 標引原則
本研究所用主題詞表參照《醫學主題詞表》(Medical Subject Headings,MeSH)的結構建立,并在以往研究基礎上,以《傷寒論》“觀其脈證,知犯何逆,隨證治之”的辨證論治思想為指導,經專家論證確定中醫主題詞標引三原則。①含義趨同原則:即原始詞與標引的中醫主題詞含義趨同。本原則以“觀其脈證”為指導,根據望、聞、問、切四診合參方法審查描述中醫臨床詞語的文字組成,分析其中醫含義,標引為含義趨同的中醫主題詞,以保障標引的主題詞與原始詞傳遞相同的信息。②方向一致原則:即原始詞與標引的主題詞提示相同的辨證論治方向。本原則以“知犯何逆”為指導,把握病機、治法、治則等主題詞的辨證論治方向,從而確保主題詞標引后,主題詞傳遞的辨證論治方向不發生偏離。③可替換原則:即原始詞與標引的主題詞之間相互替換不會影響辨證論治的思維過程。本原則以“隨證治之”為指導,確立診斷、治法、方藥,突顯辨證論治各環節環環相扣,以體現理-法-方-藥的鏈式關系。
1.3.2 標引方法
依據《中醫學主題詞表》(北京中醫藥大學中醫信息學研究中心提供),對收集的癥狀和證候進行主題詞標引,如“肚子脹”標引為“腹脹”,“大便稀不成形”標引為“便溏”,如原始詞對應多個主題詞則以逗號為分隔符分開標注。由2名具有執業醫師資格的科研人員對病歷進行逐條標注,由2名熟練掌握《中醫學主題詞表》的中醫專家對標引結果進行雙盲復核,不一致處提請第三位中醫專家復核,并經討論達成一致。
1.4 數據集劃分
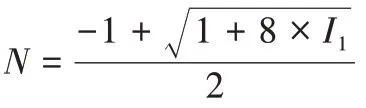
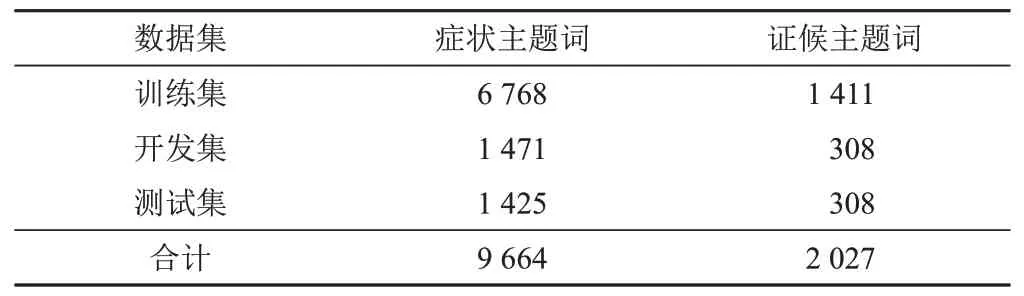
表1 各數據集標引的主題詞數量
1.5 模型設計
BERT模型是一種被用于文本分類、文本信息提取、文本翻譯等多種語言處理任務的人工智能模型,在多項處理任務中取得突破性進展,展現出優于既往模型的優勢。該模型可以通過對給定文本的學習,將文本中的詞語以數學向量即詞向量的形式表示。以向量表示詞語的方式,使詞語具有方向性和位置性。通過余弦(Cosine)距離公式對詞向量之間的距離進行計算,2個詞語之間的詞向量距離越近,表示二者關聯越緊密。
病、癥、證、方、藥之間形成相關聯的知識結構,使用BERT模型對具有“理法方藥”結構的辨證論治知識進行學習,可使相關內容形成緊密的聯系,詞語具有特定的指向性,從而使所得模型在進行中醫主題詞標引時具有更好的效果。BERT模型對中醫“理法方藥”的學習示例見圖1A,輸入數據為疾病、癥狀、中醫辨證診斷、治法、處方數據,訓練模型對詞語的編碼能力。在此基礎上,進一步學習中醫主題詞標引,將每個主題詞中的詞語作為標簽,對原始詞與主題詞之間的映射關系進行學習。該學習過程示例見圖1B,輸入數據病歷中的原始詞,輸出標引詞。
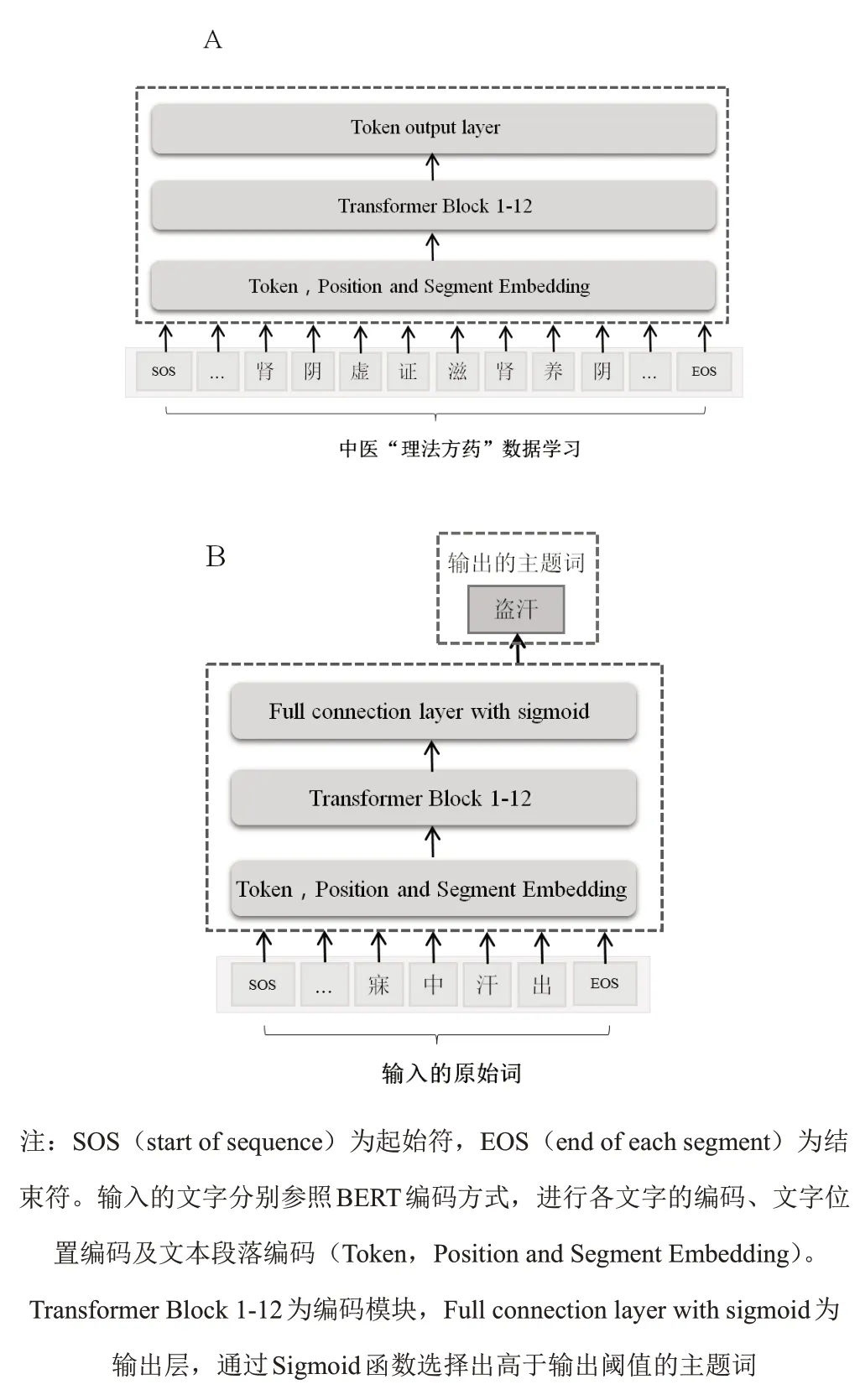
圖1 BERT模型進行“理法方藥”與主題詞標引學習過程示例
1.6 模型構建
從電子病歷中提取疾病、癥狀、證候、治法、處方等“理法方藥”數據,以BERT 的掩碼語言模型(mask language model,MLM)學習法,對“理法方藥”數據進行學習,在此基礎上以Sigmoid作為輸出函數,進行主題詞標引的學習,通過學習癥狀、證候記錄與中醫主題詞之間的映射,構建中醫主題詞自動標引模型,即TCM-BERT-Sigmoid模型。
本研究使用2種對照模型:①基于雙向長短時記憶(bidirectional long short-term memory,Bi-LSTM)神經網絡與Sigmoid函數的中醫主題詞自動標引模型,即Bi-LSTM-Sigmoid模型。②未對中醫“理法方藥”數據進行學習,僅基于BERT與Sigmoid函數的中醫主題詞自動標引模型,即BERT-Sigmoid模型。
設置 TCM-BERT-Sigmoid 和 BERT-Sigmoid 模型訓練樣本為每批次16個,優化器為Adam,學習率(learning rate,LR,神經網絡訓練過程中的超參數,用以控制參數更新速度)從0.000 2、0.000 3、0.000 5中選取,根據不同取值在開發集上的表現,選取表現最佳的數值。其余參數使用BERT默認設置。
設置Bi-LSTM-Sigmoid 模型訓練樣本為每批次256個,初始化權重為-0.05~0.05隨機均勻分布,詞向量維度為300,優化器為Adam。模型的LR從0.01、0.03、0.05 中選取,神經元失活比例(dropout rate,DR,神經網絡每層中隨機丟棄的神經元占整層神經元的比率。在每一輪訓練中讓一些神經元隨機失活,從而讓每一個神經元都有機會得到更高效的學習,以減輕神經網絡的過擬合)從0.3、0.5中選取,LSTM的記憶單元數量(memory cell,MC)從128、256、512中選取。根據不同取值在開發集上的表現,選取表現最佳的數值。
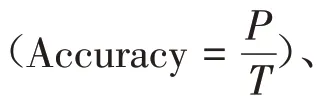
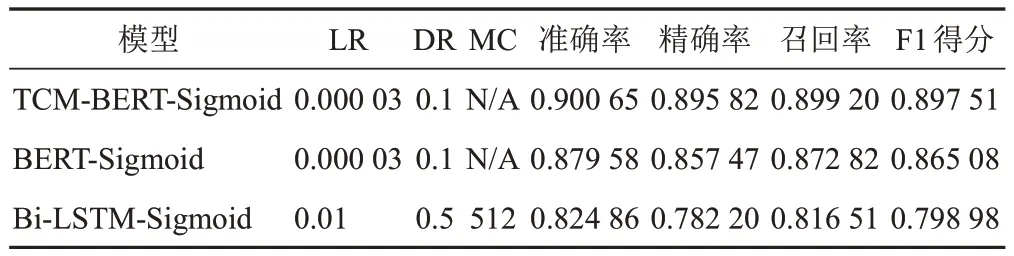
表2 對癥狀的不同中醫主題詞自動標引模型建模參數及開發集指標
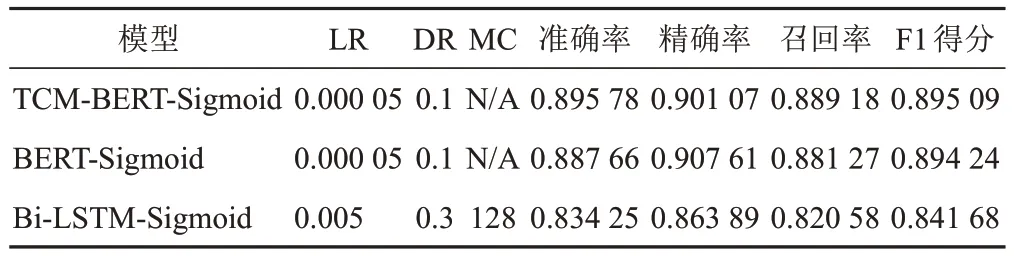
表3 對證候的不同中醫主題詞自動標引模型建模參數及開發集指標
2 結果
2.1 模型測試結果
根據劃分的測試集進行模型測試,癥狀主題詞標引時不同閾值的輸出結果見圖2,證候主題詞標引時不同閾值的輸出結果見圖3。可見,當TCM-BERTSigmoid與BERT-Sigmoid中醫主題詞自動標引模型的輸出閾值為0.2、Bi-LSTM-Sigmoid中醫主題詞自動標引模型的輸出閾值為0.3時,各模型的精確率、召回率和F1得分更為均衡,測試結果見表4、表5。可見,在對癥狀和證候的主題詞標引中,TCM-BERT-Sigmoid模型的結果均優于對照模型。
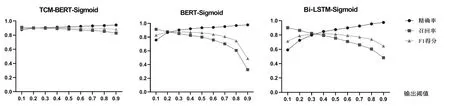
圖2 對癥狀的不同中醫主題詞標引模型在不同輸出閾值下的結果

圖3 對證候的不同中醫主題詞標引模型在不同輸出閾值下的結果
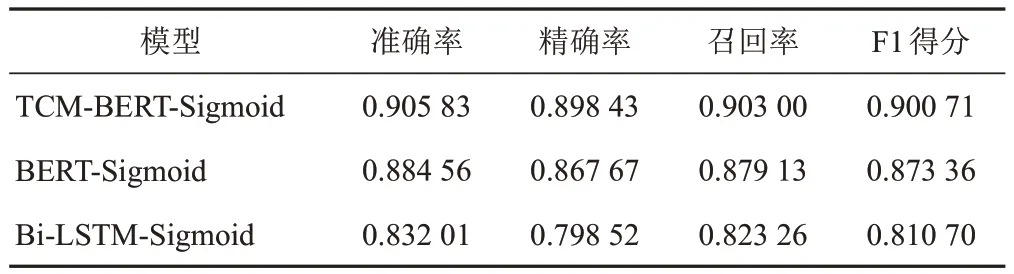
表4 不同中醫主題詞標引模型的癥狀主題詞標引測試結果
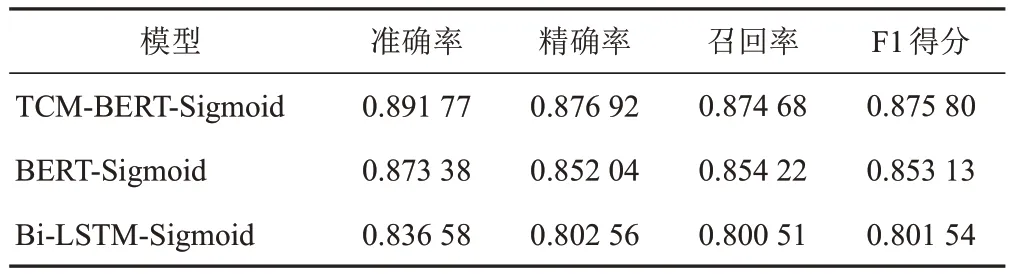
表5 不同中醫主題詞標引模型的證候主題詞標引測試結果
2.2 對應1個主題詞與對應多個主題詞的測試結果
癥狀主題詞標引時,分別對應1個主題詞與對應多個主題詞的測試結果見圖4。可以看出,只對應1個主題詞時的精確率低于召回率,表明模型在輸出正確結果的同時,有時也會將錯誤結果一同輸出,如癥狀為“小便發黃”,模型可能會標引為“尿黃”和“尿濁”,即在正確輸出“尿黃”的同時錯誤輸出了“尿濁”。對應多個主題詞的測試結果顯示,精確率高于召回率,表明在對應多個主題詞的標引中,模型輸出的結果正確但不全面,如癥狀為“苔白有齒痕”,模型可能僅標引為“齒痕舌”,而“白苔”未被標引。從F1得分來看,TCM-BERT-Sigmoid中醫主題詞自動標引模型的表現最優。
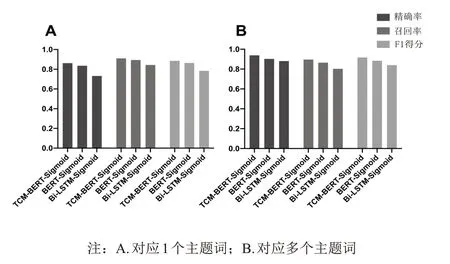
圖4 不同中醫主題詞標引模型癥狀主題詞標引結果
證候主題詞標引時,分別對應1個主題詞與對應多個主題詞的測試結果見圖5。可以看出,當證候只對應1個主題詞時,召回率低,精確率高,表明模型在輸出正確結果時容易發生遺漏現象,即如果模型認為沒有把握輸出正確結果時則選擇不輸出結果。當證候對應多個主題詞時,召回率高,精確率低,表明模型在輸出正確結果的同時,錯誤結果也會一并輸出,如證候為“肺陰不足證”,模型在將其標引為“肺陰虛證”的同時,標引為“腎陰虛證”。但從F1得分來看,TCMBERT-Sigmoid 中醫主題詞自動標引模型的表現仍為最優。
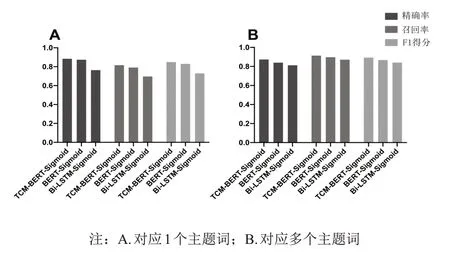
圖5 不同中醫主題詞標引模型證候主題詞標引結果
3 討論
運用計算機技術對中醫電子病歷進行符合“理法方藥”標引,是進行中醫數字資源信息挖掘及智能化處理的前提,對開展中醫辨證論治規律研究具有基礎性意義。近年來,人工智能在醫療領域逐步得到廣泛應用,自然語言處理(NLP)是人工智能重要領域之一,匯聚了眾多文本處理技術,已被廣泛用于臨床記錄的語言翻譯及醫療信息提取等工作。以往研究中,研究人員提出了一些基于NLP的生物醫學領域的歸類模型:如從相似性匹配角度,提出Word2Vec、DNorm、 Jaccard's similar和 BERT-based ranking;從命名實體識別(NER)角度,提出transition-based model和 Bi-LSTM-CNNs-CRF。此外,在建模概念方面,許多從序列生成和文本分類角度構建的模型在NLP任務中也表現出良好的性能和適用性。但上述模型僅適用于一對一的歸類情況,而不適合于一對多的歸類情況。
基于以往研究,本研究通過不同技術的組合,提出了中醫主題詞自動標引模型。其中,得益于BERT模型使用的雙向自編碼技術,使模型具有更為出色的學習能力,基于BERT建立的TCM-BERT-Sigmoid中醫主題詞自動標引模型表現最佳,其精確率、召回率和F1得分均優于基于Bi-LSTM建立的對照模型。
為解決原始詞對應多個主題詞的問題,我們使用BERT 與Sigmoid 函數結合,通過限定輸出閾值的方法,將高于限定閾值的主題詞輸出,高于限定閾值的主題詞恰能與原始詞對應,從而克服了難以處理1個原始詞對應多個主題詞的問題,使模型可以兼顧“一對一”與“一對多”標引情況,因此在中醫主題詞標引任務中具有更廣的適用性,可為中醫數據挖掘及中醫辨證論治規律研究提供有力的工具支持。
本研究為單次實驗,考慮到神經網絡初始化權重的隨機性會導致實驗結果有一定浮動,今后研究應增加實驗次數。此外,本研究構建的中醫主題詞自動標引模型僅針對癥狀和證候主題詞進行研究,雖然取得了良好的實驗結果,但此模型能否適用于其他中醫主題詞如疾病、治法、處方等的自動標引任務,仍需進一步探索。本研究構建的中醫主題詞自動標引模型未與其他僅適用于原始詞與主題詞“一對一”模型進行對比,有待進一步研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
