一種增強的多粒度特征融合語義匹配模型
2022-08-02 01:40:38尚福華蔣毅文曹茂俊
計算機技術與發展 2022年7期
尚福華,蔣毅文,曹茂俊
(東北石油大學 計算機與信息技術學院,黑龍江 大慶 163318)
0 引 言
文本語義匹配是目前自然語言處理領域中一個重要的任務分支,也是自然語言處理中重要的研究方向和研究熱點,在信息檢索、問答系統、機器翻譯等任務中起到了核心作用。
正因為語義匹配的重要性,國內外許多學者都在語義匹配上作了許多研究。傳統的匹配模型主要基于人工提取的特征以及基于統計機器學習的方法,如BM25模型、PLS、SMT模型、WTM模型等。這些模型主要解決文本表層的匹配問題[1],但難以捕捉文本所表達的深層含義。隨著神經網絡的火熱發展,人們發現基于深度學習的模型在語義匹配任務中取得了更好的效果。因此關于語義匹配的研究熱點已逐漸轉移到深度學習語義匹配模型。龐亮等人[2]將目前的基于深度學習的語義匹配模型分為三種,第一種是基于單語義文檔表達的,主要將待匹配的兩個文本通過深度學習的方式表達成兩個向量,再通過計算兩個向量之間的相似度便可得到匹配度。如ARC-I、DSSM模型。第二種是基于多語義文檔表達的,綜合考慮文本的局部性表達(詞粒度信息、短語粒度信息)和全局性表達(句粒度信息),通過這樣多層級多粒度的匹配可以很好地彌補基于單語義文檔表達的深度學習模型在壓縮整個句子過程中的信息損失,而達到更好的效果。如MultiGranCNN、MV-LSTM等。第三種則是直接建模匹配模式的。這種模型從多角度提取文本間的深層交互信息,并認為對文本間的交互學習應該早于文本的表示學習之前,一方面是為了避免損失信息,另一方面通過這種方式能夠得到更豐富的語義表示,利于后面的學習。典型模型有ARC-II、ABCNN、BiMPM、ESIM、DIIN等。Pair-CNN模型是文獻[3]所提出的,利用CNN完成短文本的匹配任務。ABCNN[4]則是在此基礎上加入注意力機制形成的。文獻提出雙向多視角匹配模型BIMPM[5]模型,對比了多種不同注意力機制的匹配策略。ESIM[6]模型本身是用于自然語言推理任務,但稍加改造后就能用于文本匹配等任務。
目前這些模型表現優異,但仍存在一定的不足。首先,這些模型大多是以詞作為語義單元并基于靜態詞向量(Word2Vec、GloVe等)來獲取句子表示,對于英語來說,它的最小語義單元是單詞,因此適用于這樣的方法。而中文語言顯然更加復雜,中文分詞、語義信息等要素直接影響了語義匹配的效果,而漢語中單個字也承載著一定的語義[7],因此只考慮詞作為語義單元不一定能取得更好的效果,需要考慮多種語義單元在句子建模中的作用。此外靜態詞向量一旦訓練完成,相同的詞的向量表示是不會再隨語境變化而變化的,因此這一類詞向量難以解決一詞多義問題[8],且不能表征詞性等語法特征。因此如何獲得更準確的句子嵌入表示仍是現在的研究重點。其次,模型在交互時往往都是在詞級別上進行交互,如ESIM模型在提取文本的交互特征時只是基于詞進行注意力交互,未能挖掘文本更深層的交互信息。而句子是具有一定的層級關系的,如果忽略了語言顆粒度對句子建模的影響,那么得到的交互信息也是不充分的。最后,一些模型通過使用多種注意力機制來提升模型效果,如BIMPM采用了四種注意力匹配策略來提取更多的信息,但是對于多種交互結果往往只是采用簡單的concat方式。對于如何正確組合優化多種注意力信息考慮甚少。
針對以上問題,該文提出一種增強的多粒度特征融合語義匹配模型EMGFM。主要工作如下:
(1)為避免由于中文詞邊界模糊而帶來的影響,同時考慮中文中單個字所包含的語義信息,該文將字向量與詞向量進行混合使用,在字向量的獲得上,利用BERT模型強大的語義表達能力獲取中文字符向量,從而更好地表征字符的多義性,而詞向量選用Word2Vec進行獲取。最后將兩種向量進行拼接得到增強的字符向量。(2)為解決只考慮詞交互帶來的交互特征單一問題,對文本的不同的粒度(字、詞、句)進行注意力交互特征提取,因為不同粒度的信息提取關注重點各有不同,為了綜合利用多種方法,最大程度上完全提取信息,設計了一種融合多種交互信息的方法。該方法利用注意力思想衡量每種交互信息的重要性,而且不會因為直接連接導致向量維度過高,可以有效減少模型計算的復雜性。并通過原始信息與融合后的信息進行點乘相減等操作來構造差異性,以達到語義增強的效果。(3)針對語義匹配提出了增強的多粒度特征融合語義匹配模型,實驗結果表明,提出的方法能有效提升問句語義匹配的準確性。
1 增強的多粒度特征融合語義匹配模型
1.1 問題定義與分析
給定待匹配樣本Sample={H,T,similarity},其中H、T為待匹配的兩個短文本,similarity為兩個文本之間的相似度,一般為0或者1。當similarity=1時表示兩個文本語義相似,similarity=0則反之。該文的目標就是訓練一個語義匹配模型M,使得對任意的兩個句子,M能夠合理給出其相似度的評判。
1.2 模型結構
整個模型結構如圖1所示,模型主要包含編碼層、交互層、語義組合層、輸出層4個主要部分。
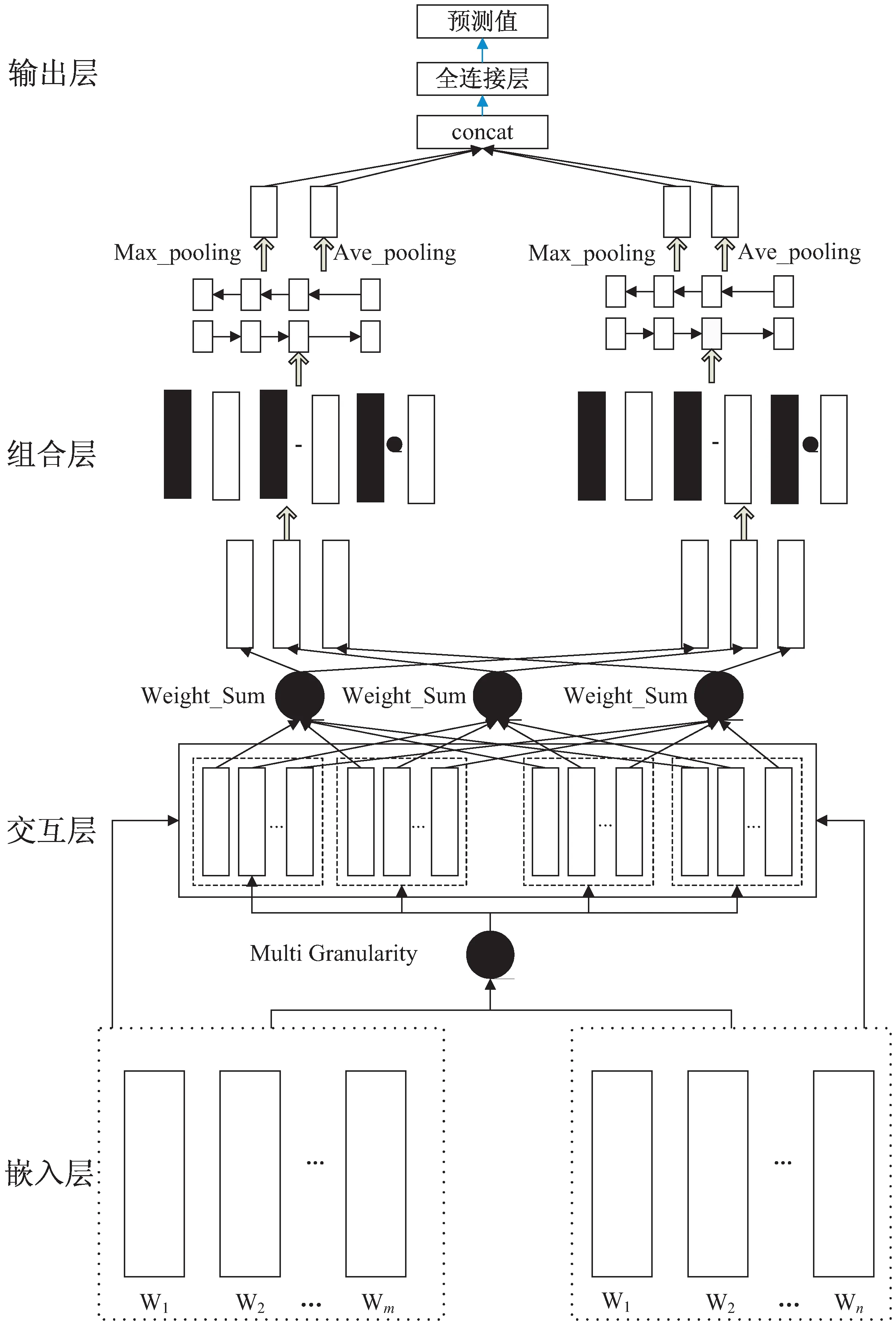
圖1 模型結構
首先在嵌入層將待匹配的兩段文本轉換為文本向量,在交互層利用可分解注意力機制,從三種粒度(字、詞、句)分別計算兩段文本的注意力權重,從而得到兩段文本在不同粒度下的注意力加權表示。然后對不同粒度下的注意力加權表示進行融合,并利用原始信息對其進行信息增強,最后經過平均池化和最大池化處理后傳入一個多層感知機進行輸出。
1.2.1 編碼層
(1)BERT預訓練模型。
BERT是一個語言表征模型(language representation model)[9],基于多層Transform實現,通過Transform結構獲取到字符向量可以充分利用上下文信息,更能表達多義性。因此,選用BERT預訓練模型來獲取文本的字向量表示。
(2)輸入表示。
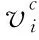
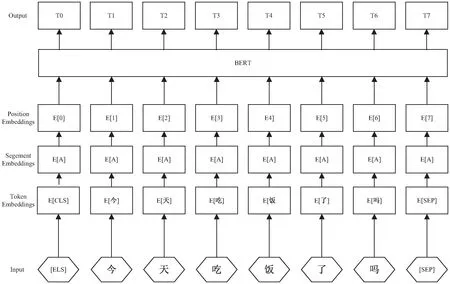
圖2 BERT輸入表示
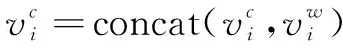
(1)
經過上述操作,最終將輸入的句子A、B嵌入表示為:
(2)
(3)
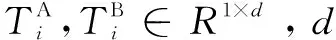
1.2.2 交互層
大量的實驗證明在句子特征提取完成后才進行句子之間的交互,勢必會浪費一些特征信息,而對待匹配的文本先進行交互再進行后續學習會取得更好的效果,并且更豐富的語義交互能為后續網絡學習帶來更多信息,匹配效果更好。如吳少洪等人[10]從不同的方面提取文本更深層的交互信息,取得了不錯的效果。受這些工作的啟發,增加更細粒度的文本交互,旨在獲得更豐富的語義交互信息。
(1)可分解注意力機制。
綜上所述,該文在將特征向量送入后續網絡之前,參考可分解注意力機制[11]的做法,對句子進行不同粒度的對齊,使得句子間的關系特征得以保留。以下先介紹可分解注意力的計算過程:
Step1:首先對句子A、B中的每個詞,通過F函數計算它們的注意力權重矩陣eij,F函數選用的是向量的點積。
(4)
Step2:使用注意力權重矩陣對句子a、b中的每個詞進行注意力加權求和。
(5)
(6)
(2)字粒度的交互。
通過1.2.1的操作即可將輸入的兩個句子A和B各自轉化為m*n的嵌入矩陣EA、EB,其中m為句子的字數,n為字向量的維度。因為BERT是基于字的模型,因此輸出即是每個字的字向量,因此可直接對其進行字粒度的交互,使用上文提及的注意力交互方式可得到關于句子A和B的基于字粒度的交互矩陣CIA、CIB。
(3)短語粒度的交互。
大量實驗證明長短語級別和短語級別的特征對句子的建模十分關鍵,CNN因其獨特的網絡結構在捕捉句子的局部特征上具有天然優勢。參考文獻[12]中的做法,該文在抽取局部特征時兼顧不同數量字組成的短語,選擇二元(two-gram)、三元(tri-gram)進行特征提取。具體做法如下:
Step1:不同長度短語特征提取。
將1.2.1得到的句子嵌入矩陣A、B分別輸入卷積神經網絡進行卷積操作,卷積核的寬度與字嵌入維度一致。為保證卷積操作前后維度保持一致以便于后續網絡學習,對A、B進行零向量填充后再進行卷積,以二元提取特征為例,卷積核的高度設置為2,得到的卷積結果可以表示為:
Two_CA=two_gram_CNN(A)
(7)
Two_CB=two_gram_CNN(B)
(8)
其中,CA∈Rla×1×K,CB∈Rlb×1×K,la、lb分別為句子A、B的長度,K為卷積核的數目。
Step2:提取交互信息。
對Two_CA、Two_CB進行注意力交互計算,分別得到文本A、B關于不同長度短語粒度的特征提取矩陣Two_CA、Two_CB、Tri_CA、Tri_CB。
(4)句子粒度的交互。
注意力機制能突出每個句子語義特征最明顯的部分[13],該文應用注意力機制來捕捉文本的上下文信息特征,最基本的注意力機制主要分為兩種,一種是由Bahdanau[14]提出的加法注意力機制,另外一種是由Luong[15]提出的乘法注意力機制。
該文對編碼層輸出采用Bahdanau提出的加法注意力機制,具體計算主要分為以下三步:
Step1:將query和每個key進行計算得到注意力得分score,以某個時間步輸出ht為例,計算注意力得分at:
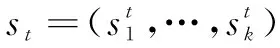
(9)
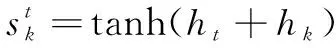
(10)
Step2:使用一個SoftMax函數對這些權重進行歸一化,如下式所示:
(11)
Step3:將權重和相應的鍵值value進行加權求和得到最后的attention,如下式所示:
(12)
目前在NLP研究中,key和value常常都是同一個,即key=value。在文中,key和value取值為編碼層的字向量輸出,通過上述計算得到基于注意力加權的表示SA_A、SA_B,再將SA_A、SA_B經過注意力交互計算即可得到句子A、B關于句子粒度交互的特征矩陣sen_A、sen_B。
1.2.3 組合層
在實際模型中,經常會將不同的特征組合起來一同使用,全面獲取信息,來達到提升模型性能的目的,然而大多數模型在組合不同的語義信息時都使用了簡單的concat方式,使得維度過大,模型計算量變大,無法有效衡量各種語義信息的重要性。該文創新性提出一種融合注意力方法來解決這個問題,具體內容如下文所述:
(1)聚合交互信息。
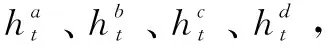
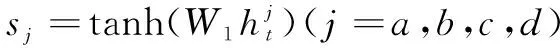
(13)
(14)
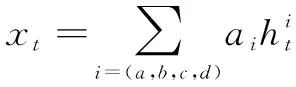
(15)
通過上述計算,得到句子A、B的聚合交互信息表示AG_A、AG_B。
(2)交互信息加強。
得到聚合交互信息表示后,使用下式進行信息增強,目的是為了構造與原有信息的差異性,便于網絡后續學習。
eh_A =[EA,AG_A,EA-AG_A,EA⊙AG_A]
(16)
eh_B =[EB,AG_B,EB-AG_B,EB⊙AG_B]
(17)
其中,EA、EB分別為句子A、B的句嵌入原始矩陣,AG_A、AG_B分別為其聚合交互信息表示,eh_A、eh_B即為AG_A、AG_B經過信息增強后得到的結果。
(3)池化。
該文為最大限度保留上文提取到的特征,綜合使用平均和最大兩種方式來進行池化,并將兩種pooling得到的向量concat起來。池化過程如下式所示:
(18)
(19)
V=[Va,ave,Va,max,Vb,ave,Vb,max]
(20)
其中,Va,i為增強信息經過BILSTM后每個時間步的輸出。
1.2.4 輸出層
通過池化得到的向量經過全連接層作最后分類輸出,其計算公式如下式所示:
(21)
sim(A,B)=argmax(yi)
(22)
其中,yi是模型對應每個分類的輸出值,argmax則是取最大輸出值對應的類別值,sim(A,B)即為兩個句子最終的相似度。
2 實驗設計
2.1 數據集構造
實驗數據來源于CCKS2018評測項目中的微眾銀行客戶問句匹配大賽數據集,共包含182 478個句子對,測試集包含10 000個句子對。若句子對語義信息相同,則對應的標簽為1,否則為0,訓練集樣本實例如表1所示。

表1 部分訓練數據集樣本
2.2 實驗設置
實驗選用的深度網絡框架是tensorflow2.3,字向量模型選用的是BERT模型中預訓練好的bert_zh_L-12_H-768_A-12模型,句子最大允許長度為樣本集中所有樣本的最大長度,batch大小設置為20,epoch設置為15,優化方式為Adam,損失函數選用的是多分類常用的交叉熵損失函數。靜態詞向量模型經由維基百科中文語料(1.42 G)訓練而成,該語料包含342 624個詞,維度為300。實驗選用準確率來衡量模型的性能,準確率的計算如下式:

2.3 模型驗證
為了驗證提出模型的有效性,對照實驗模型采用Siamese-LSTM、Siamese-CNN、ESIM、MatchPyramid。其中各模型最終評測結果如表2所示。

表2 各模型準確率比較
各模型在各批次的損失及準確率變化如圖3、圖4所示。
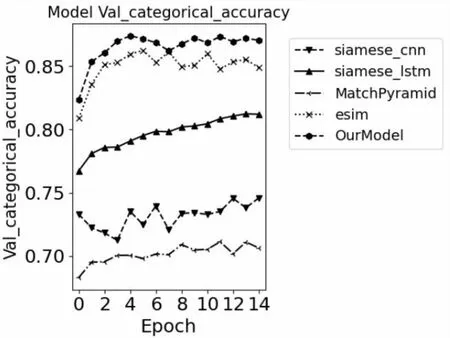
圖3 各模型準確率對比
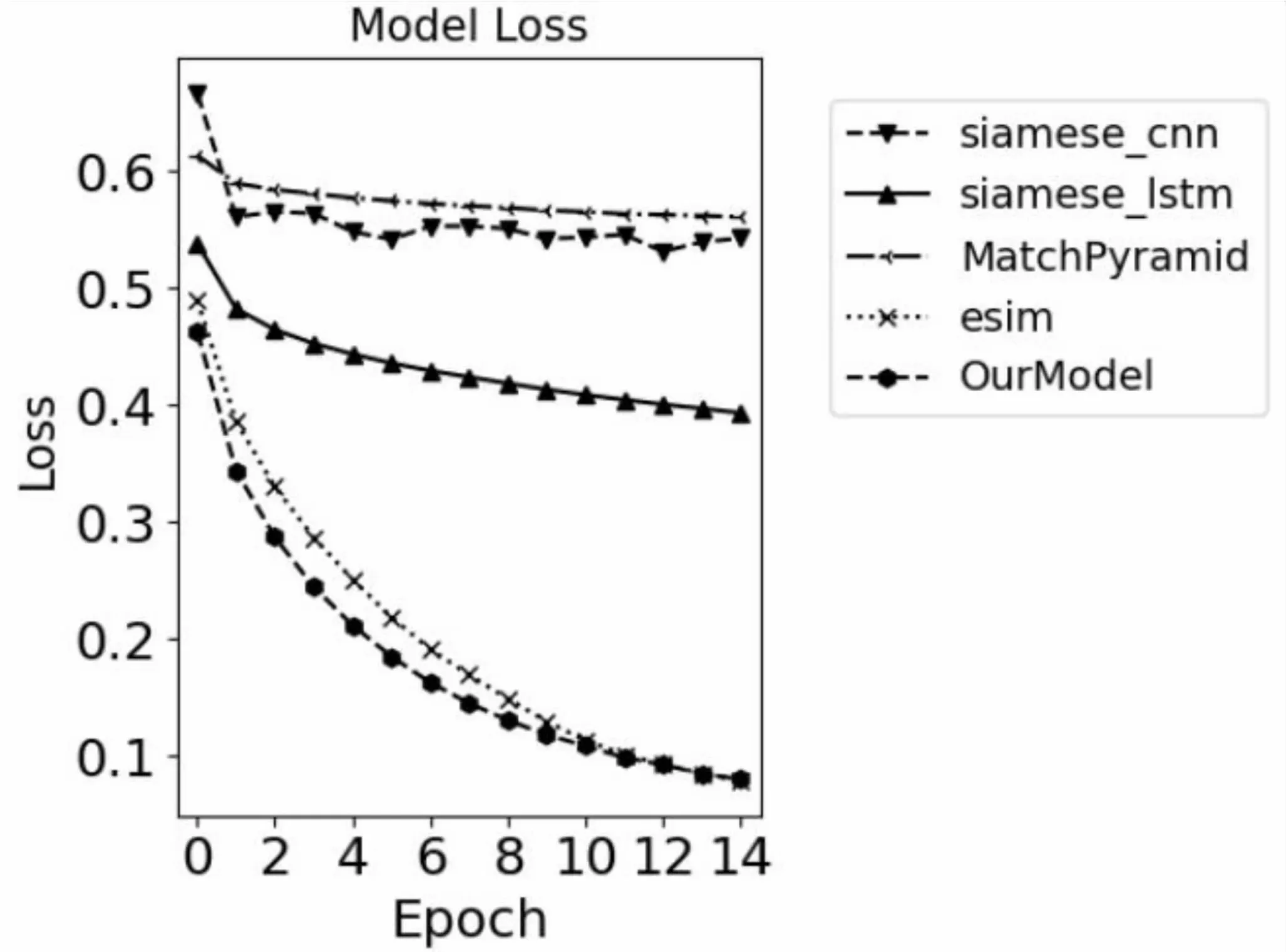
圖4 各模型損失值對比
2.4 實驗結果分析
從表2可以看出,該文提出的模型相較于其他傳統文本匹配模型表現較好,取得了87%的準確率,相較于對比模型中表現最好的ESIM模型大約有2%的提升,其中直接建模匹配的模型要比直接表示型的模型效果要好,這是因為CNN、LSTM等僅從文本本身進行語義建模,而忽略了文本之間的聯系。而基于LSTM的Siamese模型要比基于CNN的Siamese特征提取能力強,這是因為LSTM在文本等序列建模問題上有一定優勢,具有長時記憶功能,能夠捕捉文本的長程依賴。ESIM雖然在語義建模之前進行了注意力的交互以保留一些重要的文本特征值,并在后續中進行局部信息增強等操作來豐富語義信息,但總的來說ESIM只對詞粒度進行了交互,而對中文來說考慮顯然不夠。從顆粒度特征提取來看,無論是CNN、LSTM還是ESIM都只是基于單一特征的提取,而該文提出的模型綜合了多個粒度的交互信息,因而取得了更好的效果。
從圖4可以看出,Siamese-CNN、Siamese-LSTM、MatchPyramid在訓練過程中Loss下降緩慢并逐漸近于平緩,這也導致正確率無法得到有效提升。提出的模型在訓練中的Loss雖然最終和ESIM趨向一致,但是模型在訓練過程中的下降速度上表現出色,在更少的批次就能達到比較好的效果,這也驗證了文中模型結構的優越性。
2.5 模型應用
將提出的模型最終應用于CIFLog大型軟件平臺開發知識問答中,首先建立軟件平臺開發知識圖譜作為問答數據支撐,同時人工構建問句模板庫,然后通過命名實體識別等技術對用戶的問句進行處理后,使用文中模型找到相似度最高的模板以完成答案的檢索。整體效果如圖5、圖6所示。
圖5 用戶進行提問

圖6 模型應用問答效果
3 結束語
針對傳統模型存在的不足提出了相應的改進。探尋了更細的語言顆粒度在中文語義交互中的作用,較好地解決了句子交互特征不充分的缺點。同時在組合層中使用注意力機制和構造差異性方法來對交互信息進行融合增強,在最大程度保留交互特征的同時降低了模型的參數計算量,有效地提升了模型的性能。但是,從模型對語言的適用性來看,實驗是在中文數據集上進行驗證,因此在以后的工作中將嘗試在英文數據集上進行實驗,以驗證模型是否具有普適性。同時,在實際的應用場景如問答中,發現模型的計算時間稍長,這不利于體驗。因此在以后的工作中,也將進一步優化模型的執行效率,同時還需研究更多情形下的細粒度特征抽取方法,以尋求更高性能的語義匹配模型。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
