基于分解的自適應(yīng)鄰域替換策略的特征選擇算法
2022-08-04 05:40:06馬璐,蘇華
長(zhǎng)春師范大學(xué)學(xué)報(bào) 2022年6期
馬 璐,蘇 華
(天津工業(yè)大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,天津 300387)
0 引言
如今各種技術(shù)飛速發(fā)展,數(shù)據(jù)呈爆發(fā)式增長(zhǎng),數(shù)據(jù)集中通常存在很多無(wú)關(guān)特征和冗余特征,這會(huì)降低數(shù)據(jù)精度。特征選擇是提高特征數(shù)據(jù)集質(zhì)量最有效的方法之一。對(duì)于一個(gè)分類問(wèn)題來(lái)說(shuō),特征選擇的目的是提取具有高識(shí)別能力的小部分特征子集[1]。然而,由于特征之間具有復(fù)雜的相互作用,隨著特征數(shù)量的增加,搜索空間呈指數(shù)增長(zhǎng),特征選擇越來(lái)越具有挑戰(zhàn)性。
目前已有很多優(yōu)秀的多目標(biāo)優(yōu)化方法被提出,例如,DEB等[2]提出的非支配排序遺傳算法NSGA-II,ZITZLER等[3]提出的增強(qiáng)Pareto進(jìn)化算法SPEA2,ZHANG等[4]提出的基于分解的多目標(biāo)優(yōu)化算法MOEA/D。各類算法在解決不同類型的特征選擇問(wèn)題上有著不同的特點(diǎn)和優(yōu)勢(shì)。相比之下,MOEA/D算法可以將復(fù)雜的多目標(biāo)優(yōu)化問(wèn)題分解為多個(gè)子問(wèn)題來(lái)求解,具有更好的搜索能力。
傳統(tǒng)的MOEA/D算法通過(guò)計(jì)算所有權(quán)重向量之間的Euclidean距離給每個(gè)子問(wèn)題劃分對(duì)應(yīng)的鄰域,利用鄰域內(nèi)其他的子問(wèn)題來(lái)完成協(xié)同進(jìn)化[5]。但是在進(jìn)化過(guò)程中,使用固定規(guī)模的鄰域會(huì)使種群進(jìn)化緩慢,從而影響分類性能。因此,為了確保早期搜索階段的種群多樣性,并使搜索將重點(diǎn)放在后期的開(kāi)發(fā)上,本文提出了一個(gè)基于分解的自適應(yīng)鄰域替換策略(Adaptive Replacement,AR),在種群進(jìn)化的不同時(shí)期,動(dòng)態(tài)地為種群提供不同規(guī)模的鄰域,以平衡種群的多樣性和收斂性,提高進(jìn)化效率,得到更優(yōu)秀的特征子集。
1 相關(guān)工作
1.1 相關(guān)定義
特征選擇是指從一個(gè)數(shù)據(jù)集中選擇一組最優(yōu)特征的過(guò)程[6]。相比于單目標(biāo),多目標(biāo)特征選擇可以很好地權(quán)衡多個(gè)相互沖突的目標(biāo),如降低特征數(shù)量和分類錯(cuò)誤率[7]。通過(guò)多目標(biāo)優(yōu)化技術(shù)利用進(jìn)化算法,同時(shí)優(yōu)化兩個(gè)目標(biāo),最終可以得到一組多目標(biāo)最優(yōu)解。再通過(guò)進(jìn)一步分析,選擇出特征數(shù)量較少且分類錯(cuò)誤率相對(duì)較低的特征子集[8]。
本文將特征數(shù)量f1和分類錯(cuò)誤率f2作為兩個(gè)優(yōu)化目標(biāo),研究多目標(biāo)特征選擇問(wèn)題,定義如下:
minF(x)=[f1(x),f2(x)],
(1)

(2)
(3)
在式(2)中,f1表示特征集合M中被選中的特征個(gè)數(shù)。
在式(3)中,P和N表示真實(shí)樣本是否屬于某個(gè)類別,T和F表示預(yù)測(cè)結(jié)果,該樣本的觀察和預(yù)測(cè)結(jié)果一致為T,否則為F,該計(jì)算值f2就是分類錯(cuò)誤率。
1.2 算法思想
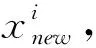
對(duì)于一個(gè)解x,如果子問(wèn)題j滿足以下條件,則稱子問(wèn)題j是最適合x(chóng)的子問(wèn)題:
(4)
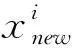
為了簡(jiǎn)單起見(jiàn),替換策略并不限制被新解所取代的解的數(shù)量,所有的Tr相鄰解都有可能被相同的新解所取代,因此,Tr是控制收斂性和多樣性平衡的一個(gè)關(guān)鍵參數(shù)。在不同的進(jìn)化階段需要不同的Tr值。在種群進(jìn)化的早期搜索階段,應(yīng)設(shè)置一個(gè)較小的Tr值,以保持良好的種群多樣性;但在種群進(jìn)化后期,應(yīng)設(shè)置一個(gè)較大的Tr值,以提高種群收斂速度。因此,應(yīng)在種群進(jìn)化期間增加Tr值,本文采用如下方式來(lái)增加Tr值。
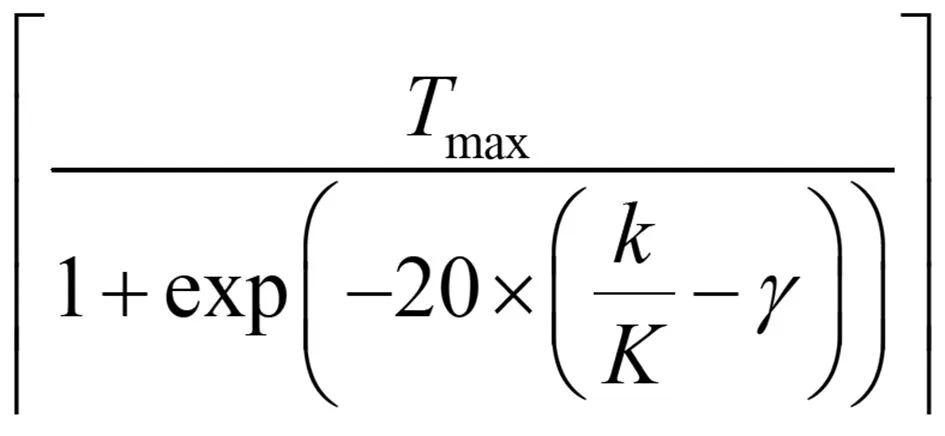
(5)
其中,「·?是上限函數(shù),Tmax是Tr的最大值,k是當(dāng)前代數(shù),K是最大代數(shù),γ是一個(gè)控制參數(shù),γ∈[0,1),確定Tr隨著搜索的進(jìn)行而增加的方式。
2 基于分解的自適應(yīng)鄰域替換策略
基于分解的自適應(yīng)鄰域替換策略(MOEA/D-AR)的特征選擇算法執(zhí)行過(guò)程如下:
輸入:原始數(shù)據(jù)集OTD;種群規(guī)模N;均勻分布的權(quán)重向量W={λ1,…,λN};鄰域大小T,變異概率Pm,交叉概率Pc;最大迭代代數(shù)Maxgen;種群規(guī)模pop;
輸出:非支配特征子集的特征數(shù)和分類錯(cuò)誤率;
Step1 初始化;
Step1.1 計(jì)算任意兩個(gè)權(quán)重向量之間的Euclidean距離,為每個(gè)權(quán)重向量選出最近的T個(gè)權(quán)重向量作為其初始鄰域。設(shè)B(i)={i1,i2,…,iT},i=1,2,…,N,其中,λi1,λi2,…,λiT是距離λi最近的T個(gè)權(quán)重向量;
Step1.2 初始化種群P,并計(jì)算初始個(gè)體xi的函數(shù)值Fi(f1,f2);
Step1.3 初始化理想點(diǎn)Z*={min(f1),min(f2)};
Step2 更新:fori=1 toN,do
Step2.1 在每代更新之前計(jì)算每代的選擇鄰域Bm(i),計(jì)算替換鄰域Tr值,計(jì)算Br(i);
Step2.2 繁殖:從Bm(i)中隨機(jī)選擇兩個(gè)鄰居xk,xl,通過(guò)遺傳算子由xk,xl進(jìn)行交叉變異生成新解;
Step2.3 修正:應(yīng)用問(wèn)題特定的啟發(fā)式的改進(jìn)策略作用于y生成y′;
Step2.4 更新Z*:若Zj Step2.5 更新解:采用更新函數(shù)更新Z*,Br(i),y,P,W; Step3 停止判斷:當(dāng)達(dá)到最大迭代次數(shù)時(shí),則輸出Pareto非支配解,否則返回Step2繼續(xù)執(zhí)行; Step4 選擇PF(Pareto Front)中合適的非支配解作為特征子集; Step5 計(jì)算特征子集中個(gè)體的特征數(shù)和分類錯(cuò)誤率并作為結(jié)果返回。 本文在UCI machine learning repository[12]中選取了表1所示的5個(gè)數(shù)據(jù)集。并將所提出的MOEA/D-AR算法分別與如下3種著名的多目標(biāo)算法進(jìn)行了比較:標(biāo)準(zhǔn)的MOEA/D[4]、NSGA-II[2]、SPEA2[3]。在測(cè)試中,所有算法都采用十折交叉驗(yàn)證的KNN[13]計(jì)算訓(xùn)練集的分類誤差率。然后在測(cè)試集上對(duì)進(jìn)化的特征子集進(jìn)行評(píng)估,以獲得其測(cè)試精度。KNN中的近鄰數(shù)設(shè)為5,以避免出現(xiàn)冗余的實(shí)例,同時(shí)保持其效率。最大迭代次數(shù)為20次,種群大小為50,閾值θ設(shè)置為0.6,用來(lái)決定特征是否被選中。所有的算法都在測(cè)試中獨(dú)立運(yùn)行30次,然后在測(cè)試集上對(duì)進(jìn)化的特征子集進(jìn)行評(píng)估,以獲得其測(cè)試精度。 表1 數(shù)據(jù)集及參數(shù)設(shè)置 本文算法和其他3種算法在各數(shù)據(jù)集上的最優(yōu)非支配解集對(duì)應(yīng)的帕累托前沿如圖1所示。MOEA/D-AR在5個(gè)數(shù)據(jù)集上得到的分類錯(cuò)誤率,不僅明顯優(yōu)于使用全部特征時(shí)的分類錯(cuò)誤率,而且相較于3個(gè)對(duì)比算法, MOEA/D-AR在大多數(shù)情況下都更優(yōu)于其他算法。 (a)Wine (b)Australian (c)Zoo (d)Ionosphere (e)Hill-valley圖1 各算法在不同數(shù)據(jù)集上最優(yōu)非支配解集對(duì)應(yīng)的Pareto前沿 在Wine數(shù)據(jù)集中,MOEA/D-AR算法只需要選取15%的特征數(shù),也就是13個(gè)特征里面選擇了2個(gè)就能達(dá)到比使用全部特征更小的分類錯(cuò)誤率。在Australian中,MOEA/D-AR算法只選取了21%的特征,即14個(gè)特征中選擇了3個(gè),得到的分類錯(cuò)誤率就小于總分類錯(cuò)誤率。在Zoo中,MOEA/D-AR選擇了24%的特征數(shù),即17個(gè)中選擇了4個(gè),就能得到比使用全部特征更小的分類錯(cuò)誤率。在Hill-valley中,MOEA/D-AR只選擇了總特征數(shù)的10%,就使分類錯(cuò)誤率低于使用全部特征時(shí)的分類錯(cuò)誤率。在Ionosphere數(shù)據(jù)集中,MOEA/D的性能略低于NSGA-II,排名第二,選擇了30%的特征,即34個(gè)中選擇了10個(gè),就使分類錯(cuò)誤率低于總分類錯(cuò)誤率,選取的特征數(shù)比排名第一的NAGA-II僅高4%。 表2給出了5種算法在測(cè)試結(jié)果中分類錯(cuò)誤率低于使用所有特征時(shí)的最小特征數(shù)和對(duì)應(yīng)的分類錯(cuò)誤率。由表2可以看出,除了Ionosphere數(shù)據(jù)集,MOEA/D-AR在其他4個(gè)數(shù)據(jù)集中,都能得到更小的特征數(shù)目;且當(dāng)所選取的特征數(shù)目相等時(shí),MOEA/D-AR所選取的特征子集的分類錯(cuò)誤率也更低。研究結(jié)果表明,MOEA/D-AR可以選取出性能更優(yōu)的特征子集。 表2 分類錯(cuò)誤率低于使用全部特征時(shí)各算法所對(duì)應(yīng)的最小特征數(shù)及分類錯(cuò)誤率 為了避免使用經(jīng)典的MOEA/D算法進(jìn)行特征選擇時(shí),由于鄰域規(guī)模固定而導(dǎo)致種群?jiǎn)适Ф鄻有郧疫M(jìn)化效率低,從而產(chǎn)生過(guò)多冗余數(shù)據(jù)的問(wèn)題,本文提出了一種基于分解的自適應(yīng)鄰域替換策略(MOEA/D-AR)的特征選擇算法,該算法根據(jù)進(jìn)化過(guò)程中鄰域規(guī)模的大小,自適應(yīng)地替換鄰域解,并保證每個(gè)解都對(duì)應(yīng)其最合適的子問(wèn)題。實(shí)驗(yàn)結(jié)果表明,本文提出的算法可以得到特征數(shù)目少且分類錯(cuò)誤率更低的優(yōu)秀特征子集。 同時(shí)該算法也存在一定的缺陷,例如,使用的固定參數(shù)較多,這些參數(shù)大多不可以自主學(xué)習(xí),在一定程度上影響了算法性能。在今后的工作中將對(duì)以上問(wèn)題加以改進(jìn),使這些固定參數(shù)也可以隨著迭代過(guò)程進(jìn)行動(dòng)態(tài)調(diào)整,進(jìn)一步優(yōu)化算法。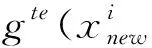

3 實(shí)驗(yàn)結(jié)果與分析
3.1 數(shù)據(jù)集與參數(shù)設(shè)置

3.2 實(shí)驗(yàn)結(jié)果
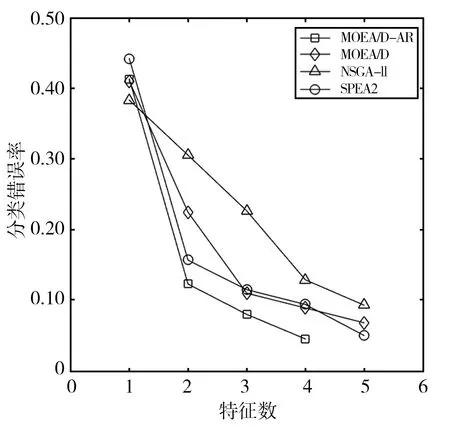
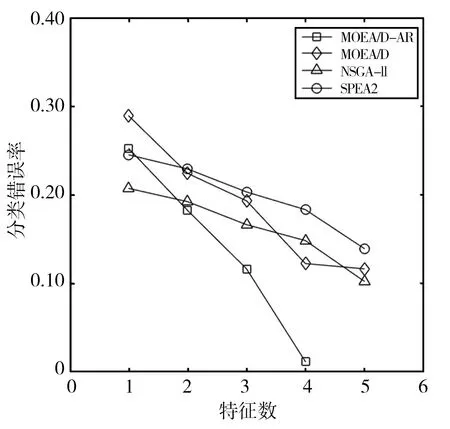

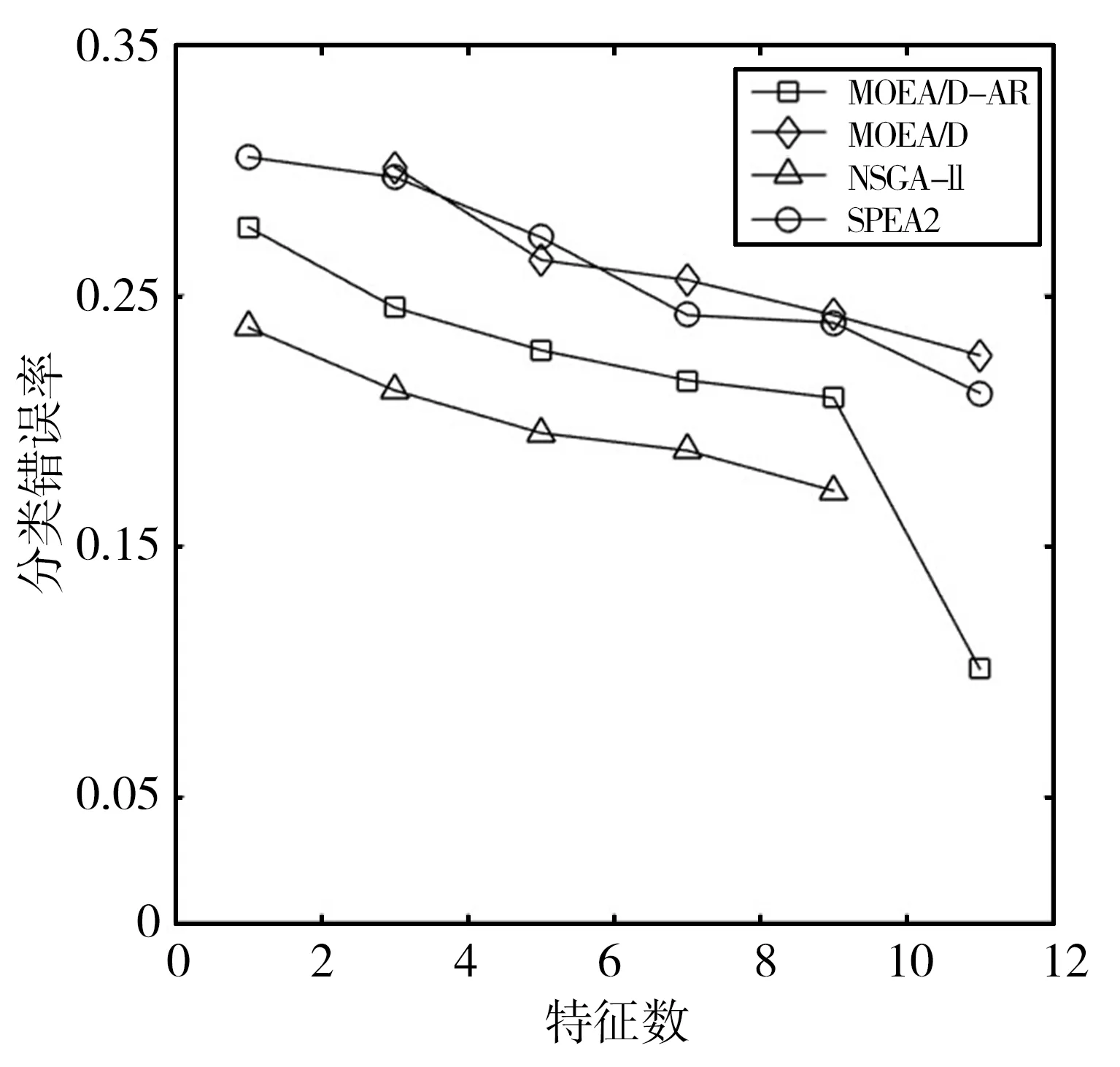
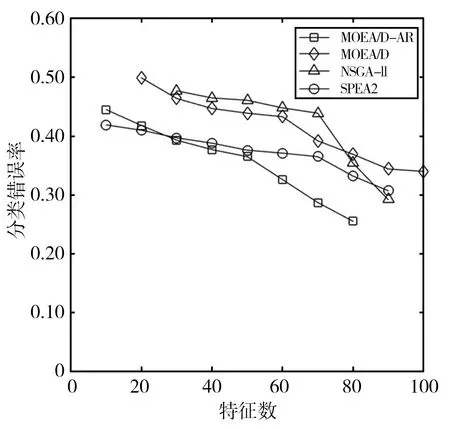

4 結(jié)語(yǔ)
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
 長(zhǎng)春師范大學(xué)學(xué)報(bào)2022年6期
長(zhǎng)春師范大學(xué)學(xué)報(bào)2022年6期
- 長(zhǎng)春師范大學(xué)學(xué)報(bào)的其它文章
- 倉(cāng)儲(chǔ)設(shè)施建設(shè)對(duì)吉林省家庭農(nóng)場(chǎng)融資渠道的影響
- “廣播電視傳播學(xué)”課程思政建設(shè)探索與實(shí)踐
- PDCA循環(huán)法在藥理學(xué)課程教學(xué)改革中的應(yīng)用
- 新時(shí)代專業(yè)認(rèn)證背景下我國(guó)教師資格認(rèn)證改革省思
——基于對(duì)西方國(guó)家職前教師培養(yǎng)及教師資格認(rèn)證的考察 - 4種不同海藻提取物對(duì)人乳腺癌細(xì)胞MCF-7增殖活性的影響
- 不同生境下薺菜種群構(gòu)件生物量分配特征