基于Adaboost算法的不平衡數(shù)據(jù)集分類效果研究
2022-08-04 05:34:28董慶偉
長春師范大學(xué)學(xué)報(bào) 2022年6期
關(guān)鍵詞:分類
董慶偉
(閩南理工學(xué)院信息管理學(xué)院,福建 石獅 362700)
0 引言
分類問題在實(shí)際生活中常見,分類算法的種類也特別多,但由于大多數(shù)的分類算法在分類過程中都是針對相對平衡的數(shù)據(jù)集進(jìn)行分類,對于數(shù)據(jù)集不平衡的少類樣本沒有重點(diǎn)考慮,所以會(huì)導(dǎo)致少類樣本分類準(zhǔn)確率低的現(xiàn)象[1]。而在現(xiàn)實(shí)生活中,可能會(huì)更需要少類樣本分類,比如一萬個(gè)人中只有幾個(gè)人患某一罕見疾病,這時(shí)候就需要重點(diǎn)分類出這幾個(gè)樣本。因此,需要針對少類樣本的特性改善算法,提高不平衡數(shù)據(jù)集的分類準(zhǔn)確率[2]。處理不平衡數(shù)據(jù)集的分類問題、提高少數(shù)類的分類正確率成為當(dāng)前分類算法設(shè)計(jì)的研究熱點(diǎn)[3]。本文針對不平衡數(shù)據(jù)集分類過程中產(chǎn)生的不平衡性問題,嘗試使用采樣技術(shù)與傳統(tǒng)分類算法相結(jié)合的方法,解決不平衡數(shù)據(jù)集的分類過程中產(chǎn)生的問題。首先使用過采樣等技術(shù)對數(shù)據(jù)集進(jìn)行預(yù)處理,產(chǎn)生新的訓(xùn)練樣本,在一定程度上解決分類樣本的分布不平衡性問題;其次確定基本分類器,采用Adaboost算法對分類器進(jìn)行學(xué)習(xí)訓(xùn)練[4],并輸入測試集進(jìn)行測試,統(tǒng)計(jì)分類結(jié)果并加以分析(包括準(zhǔn)確率和錯(cuò)誤率);最后采用多組數(shù)據(jù)進(jìn)行測試,驗(yàn)證此次設(shè)計(jì)的可行性。
1 Adaboost算法原理與分類方法
1.1 不平衡數(shù)據(jù)集
不平衡數(shù)據(jù)集又稱非平衡數(shù)據(jù)集。在一個(gè)待分類的樣本中,數(shù)量較小的一類樣本稱為少類樣本或正類樣本,而分布數(shù)量較多的那一類樣本稱為多類樣本或負(fù)類樣本[5]。不平衡數(shù)據(jù)集因?yàn)樽陨順颖痉诸惒黄胶獾奶攸c(diǎn),在分類過程中會(huì)帶來許多問題和難點(diǎn)。
1.2 Adaboost算法
Adaboost算法的思想是:通過改變權(quán)值來對基本分類器進(jìn)行訓(xùn)練和學(xué)習(xí),然后把多個(gè)分類器算法的核心內(nèi)容通過改變樣本的權(quán)重值來實(shí)現(xiàn),對于分類正確的樣本就減小權(quán)值,對于分類錯(cuò)誤的樣本則增加權(quán)值[1],這樣能在下一次分類過程中著重對分類錯(cuò)誤的樣本進(jìn)行分類;將重新分配過權(quán)值新訓(xùn)練集送到下層分類器進(jìn)行新的訓(xùn)練,得到更加精確的分類效果;把每次訓(xùn)練得到的分類器根據(jù)一定的原則進(jìn)行組合,形成一個(gè)新的強(qiáng)分類器,作為最后的決策分類器。總體來說,Adaboost算法就是把分類重點(diǎn)放在那些難以分類的樣本上面,從根本上解決少類樣本的分類難題,提高整體的分類效果。算法整體流程如圖1所示。
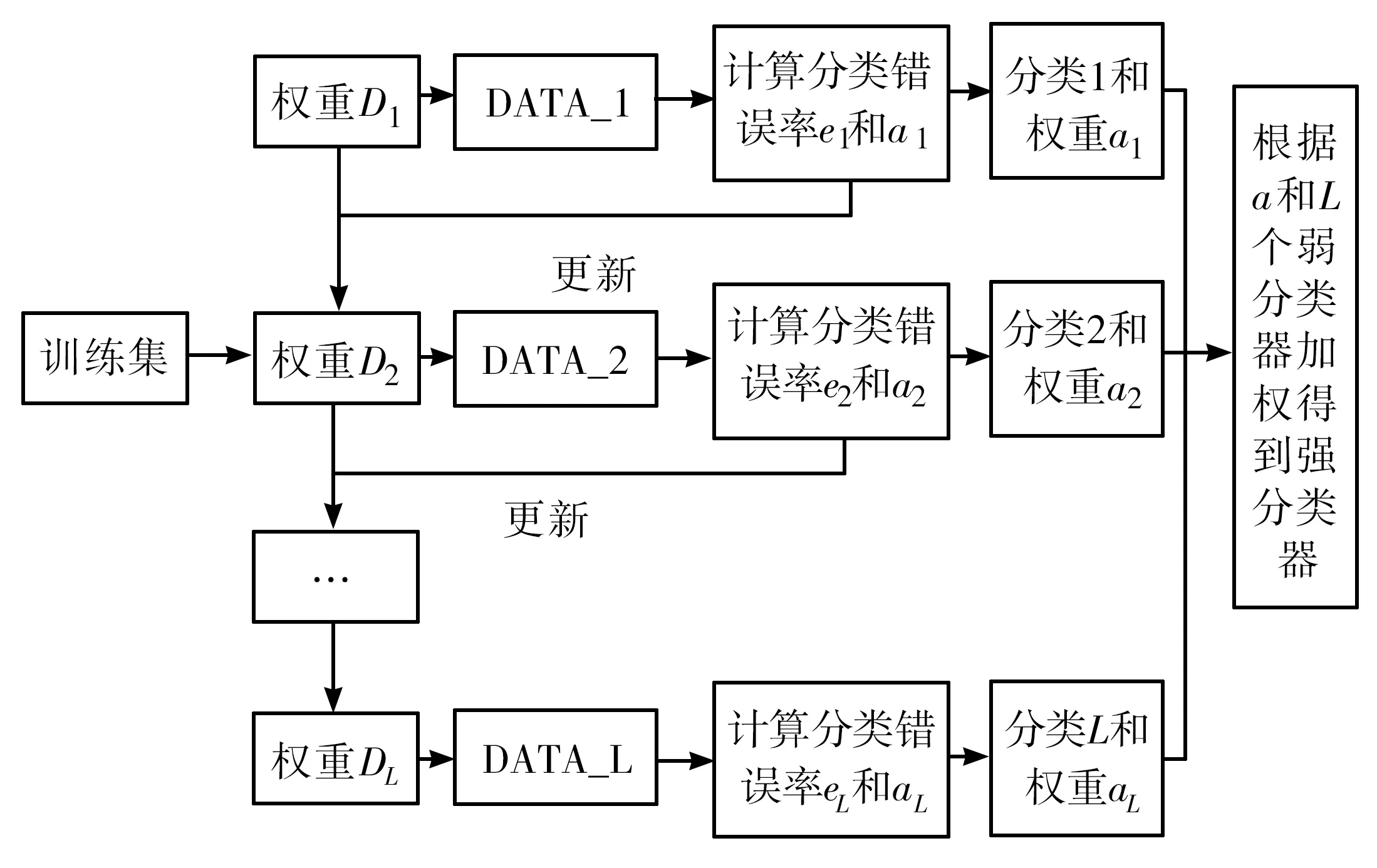
圖1 Adaboost算法整體流程圖
從圖1可以看出,Adaboost算法整個(gè)過程可以分為兩個(gè)部分:第一部分為迭代過程;第二部分為分類器的加權(quán)組合過程。第一步,首先將輸入的訓(xùn)練集樣本權(quán)值設(shè)為1/N,然后用分類器1進(jìn)行分類,得出分類錯(cuò)誤率和分類權(quán)重,根據(jù)得到的分類結(jié)果和錯(cuò)誤率以及權(quán)值a來更新樣本權(quán)值,從而形成新的訓(xùn)練集DATA2;再利用基本分類器2進(jìn)行分類,同上述一樣,再次更新樣本權(quán)值得到若干基本分類器和權(quán)重。第二步就是根據(jù)得到的分類器權(quán)值a進(jìn)行加權(quán)投票,從而組合成一個(gè)強(qiáng)分類器。對不平衡數(shù)據(jù)集進(jìn)行一個(gè)采樣預(yù)處理,通過增加少類樣本的數(shù)量,在一定程度上減緩不平衡數(shù)據(jù)集的不平衡性,然后用基本分類器學(xué)習(xí)算法來處理訓(xùn)練集,構(gòu)建一個(gè)強(qiáng)分類器,再用測試集進(jìn)行測試,得出分類結(jié)果并進(jìn)行分析。
1.3 結(jié)果分析指標(biāo)
1.3.1 精確度
精確度用來衡量一個(gè)數(shù)據(jù)集的總體分類效果,從整體的角度進(jìn)行衡量,更多地適合用于反應(yīng)相對平衡的數(shù)據(jù)集,而不平衡數(shù)據(jù)集的分類不平衡性則很難進(jìn)行分類效果衡量。
(1)
其中,TP為被正確分類的正類樣本數(shù)量;TN為被正確分類的負(fù)類樣本數(shù)量;n+為多類樣本數(shù)量;n-為少類樣本數(shù)量。
1.3.2 準(zhǔn)確率
準(zhǔn)確率是被正確分類的正類樣本數(shù)量與被分為正類樣本數(shù)量的比。
(2)
其中,TP為被正確分類的正類樣本數(shù)量;FP為錯(cuò)誤分類的正類樣本數(shù)量。
1.3.3 召回率
召回率反映的是被正確分類的正類樣本數(shù)量與所有樣本數(shù)量的比。
(3)
其中,TP為被正確分類的正類樣本數(shù)量;FN為錯(cuò)誤分類的正類樣本數(shù)量。
1.3.4 不平衡率
不平衡率是被正確分類的正類樣本數(shù)量與所有樣本數(shù)量的比。
(4)
其中,TP為被正確分類正類樣本數(shù)量;n+為多類樣本數(shù)量;n-為少類樣本數(shù)量。
2 實(shí)驗(yàn)結(jié)果
2.1 實(shí)驗(yàn)數(shù)據(jù)
本文采用Adaboost算法得到實(shí)驗(yàn)數(shù)據(jù),數(shù)據(jù)集包括:第一組數(shù)據(jù)為demo數(shù)據(jù)集,隨機(jī)產(chǎn)生200個(gè)樣本,樣本維度為2;第二組為heart數(shù)據(jù)集,共有100個(gè)樣本,樣本維度為13;第三組為下載的usps數(shù)據(jù)集,共1 000個(gè)樣本,樣本維度為256。分別對以上數(shù)據(jù)進(jìn)行分類測試。
2.2 實(shí)驗(yàn)數(shù)據(jù)測試
分別使用Adaboost算法和單層決策樹(decision stump)對三組數(shù)據(jù)進(jìn)行測試,測試結(jié)果如表1所示。數(shù)據(jù)不同,其樣本分布不同;數(shù)據(jù)分布的不平衡影響最終的分類準(zhǔn)確率。從表1可以看出,不平衡率越大的數(shù)據(jù)集,分類準(zhǔn)確率越低。本文方法在一定程度上能夠提高分類效果,由于樣本數(shù)量不同,所得到的分類效果也不同。總體來說,測試集和訓(xùn)練集的分類準(zhǔn)確率會(huì)隨著迭代次數(shù)、樣本數(shù)量的增大而提高。從實(shí)驗(yàn)結(jié)果來看,隨著樣本不平衡率的提高,樣本分類準(zhǔn)確率會(huì)相對降低,這是由不平衡數(shù)據(jù)集的不平衡特點(diǎn)所引起的,而本文采用的Adaboost算法在一定程度上能夠減緩樣本不平衡所帶來的問題。

表1 不同樣本得到的分類準(zhǔn)確率統(tǒng)計(jì)結(jié)果
2.3 迭代次數(shù)對Adaboost算法分類的影響
圖2為訓(xùn)練集和測試集錯(cuò)誤率變化圖,其中,y軸代表訓(xùn)練集和測試集的分類錯(cuò)誤率,x軸代表分類器迭代次數(shù)。不同的數(shù)據(jù)集樣本平衡度不同,其得到的測試樣本分類準(zhǔn)確率也不同,而其隨著迭代次數(shù)的變化而變化。隨著迭代次數(shù)的增加,訓(xùn)練集錯(cuò)誤率總體呈逐漸降低趨勢。由于訓(xùn)練集是用來訓(xùn)練分類器學(xué)習(xí)的,所以其準(zhǔn)確率要比測試集的準(zhǔn)確率要高[5]。不僅迭代次數(shù)能夠引起錯(cuò)誤率的變化,同樣地,訓(xùn)練樣本的數(shù)量也影響著最終的分類效果:隨著樣本數(shù)的增加,錯(cuò)誤率將明顯降低。此外,由圖2(b)可以看到,分類錯(cuò)誤率并不是一直降低,這是由于Adaboost算法在訓(xùn)練過程中特別容易受到噪聲數(shù)據(jù)和異常數(shù)據(jù)的影響,結(jié)合基本分類器加權(quán)組合的特性,導(dǎo)致迭代過程中錯(cuò)誤率不是一直降低。
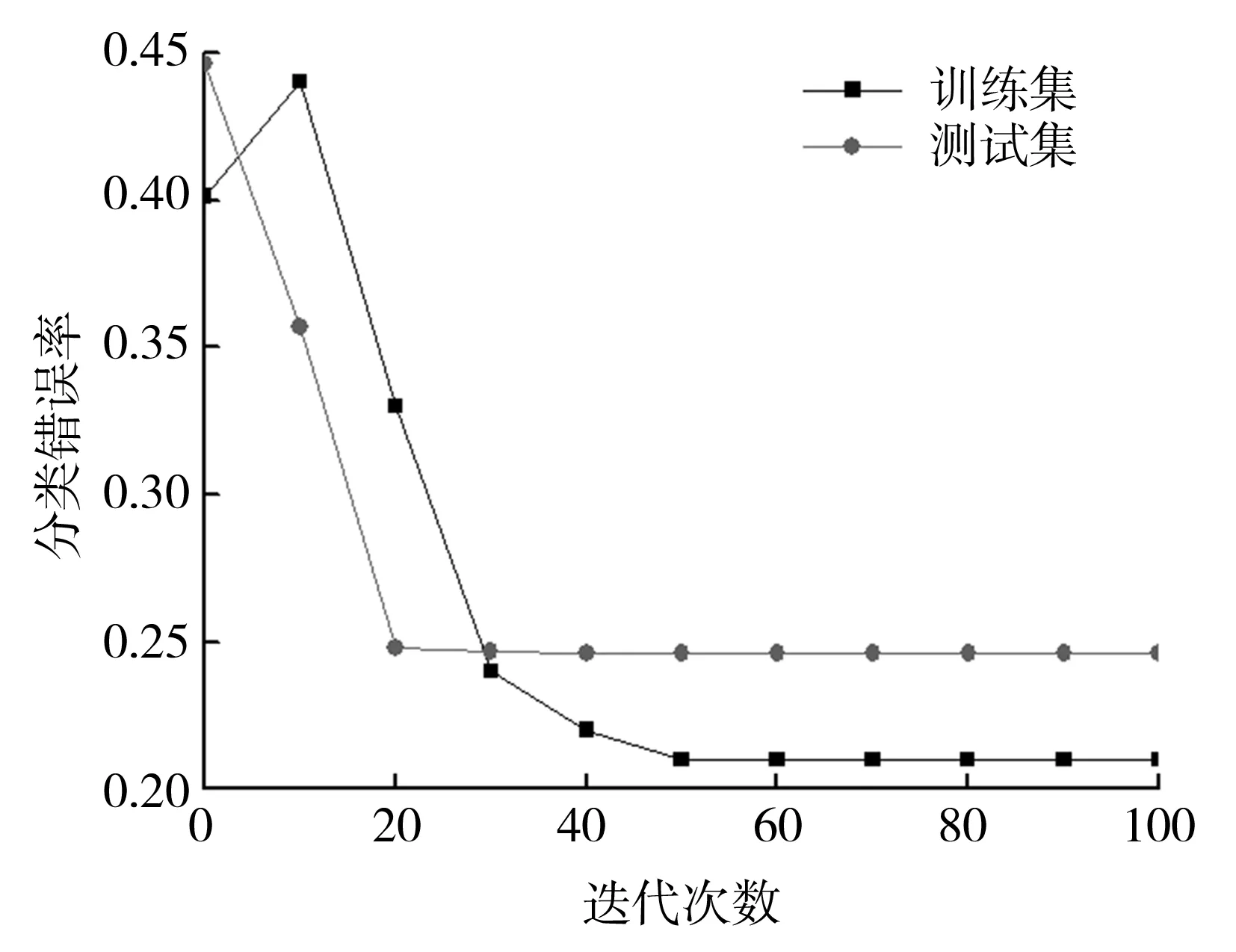
(a)demo數(shù)據(jù)集
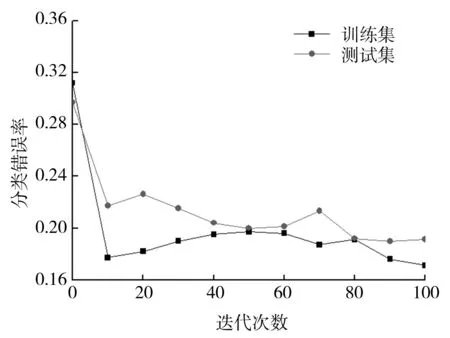
(b)heart數(shù)據(jù)集
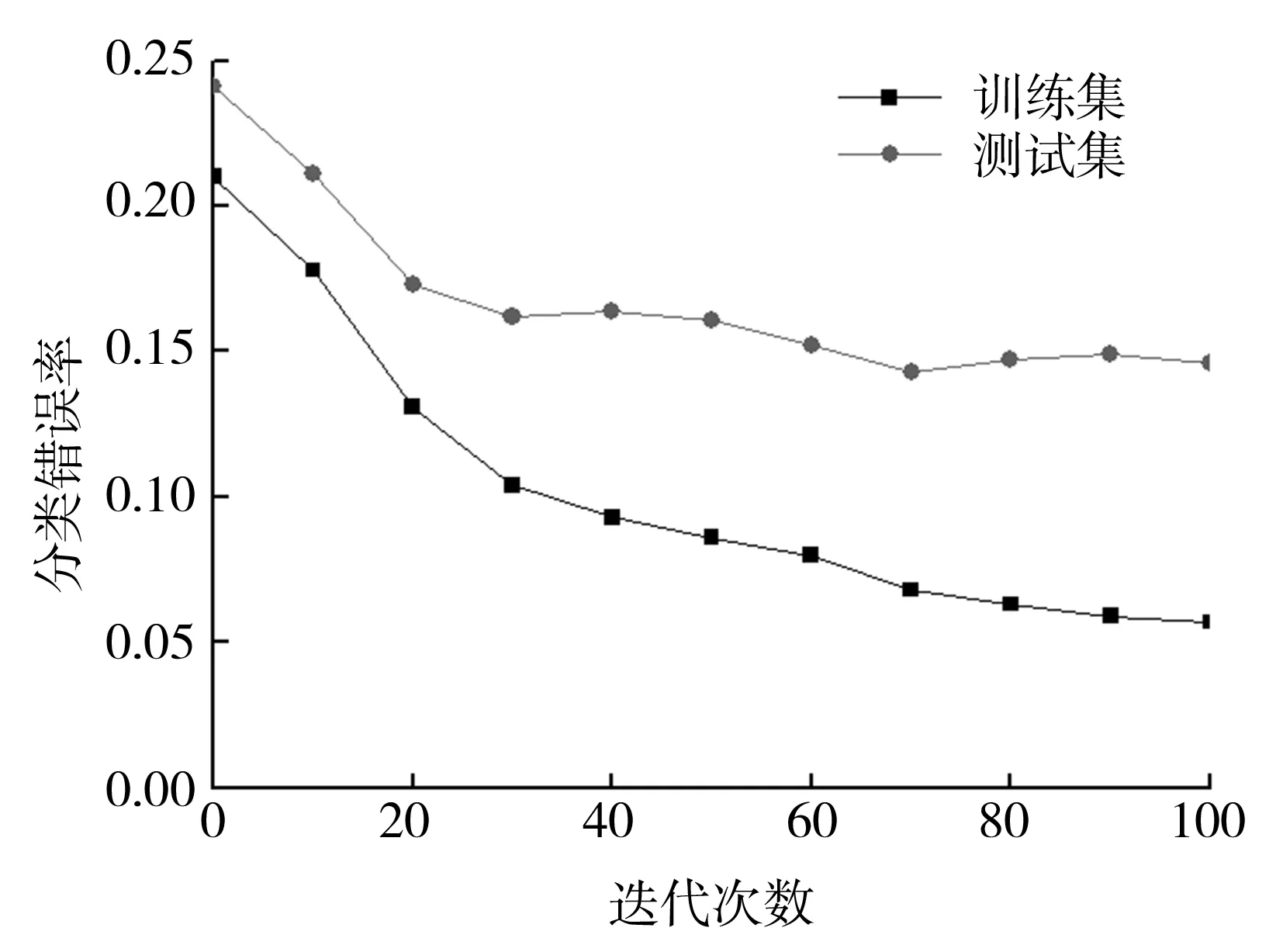
(c)usps數(shù)據(jù)集圖2 訓(xùn)練集和測試集分類錯(cuò)誤率變化圖
3 結(jié)語
本文首先通過SMOTE算法采樣對不平衡數(shù)據(jù)集進(jìn)行一個(gè)預(yù)處理,然后確定采用單層決策樹作為基本分類器,最后進(jìn)行Matlab編程,構(gòu)建Adaboost算法分類器。得到如下結(jié)論:隨著樣本數(shù)的增大,數(shù)據(jù)集的分類準(zhǔn)確率升高;隨著數(shù)據(jù)集不平衡率的增大,分類準(zhǔn)確率會(huì)有所降低,但相較于傳統(tǒng)的單層決策樹算法而言,準(zhǔn)確率有非常明顯的提升,平均分類準(zhǔn)確率在85%以上;隨著迭代次數(shù)的增加,訓(xùn)練集錯(cuò)誤率總體呈逐漸降低趨勢;通過改變正類樣本的權(quán)值,重視對少類樣本的分類,能夠在一定程度上提高整體的分類效果。
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
