基于DeepLabv3+的高分辨率遙感影像建筑物自動提取
2022-08-08 12:39:12于明洋張文焯陳肖嫻劉耀輝
測繪工程 2022年4期
于明洋,張文焯,陳肖嫻,劉耀輝,2
(1.山東建筑大學 測繪地理信息學院,濟南 250101; 2.河北省地震動力學重點實驗室, 河北 三河 065201)
基于高分辨率遙感影像的建筑物自動提取對災害預警與處理、城市發展與規劃、智慧城市建設等意義重大[1]。近年來,隨著遙感影像分辨率的提高,使得建筑物的光譜特征更加明顯,為提取的信息建筑物提供更加豐富的語義、紋理特征,同時也會導致干擾和冗余信息的增加,建筑物高精度自動提取是一項具有挑戰性的研究。早期的建筑物提取方法大多利用手工提取的特征作為判斷依據,包括基于邊緣檢測的方法[2]和基于影像特征的方法[3]。李巍岳等[4]利用數學形態學對Sobel算子檢測的輪廓進行修正,提高建筑物提取的準確率。王丹[5]將Canny算子與區域分割、區域生長相結合,有效提取建筑物的邊緣信息。林雨準等[6]基于影像的光譜、形狀等特征,引入多尺度分割、形態學建筑物指數的思想進行建筑物的分級提取。Huang等[7]通過構建多尺度城市復雜指數整合不同窗口的多尺度信息,進行不同場景下的建筑物幾何特征的提取。此外,諸如支持向量機SVM[8]、boosting[9]、隨機森林[10]和條件隨機場(CRF)[11]等優秀的機器學習分類器也被用于建筑物的提取。以上方法很大程度上依賴于特征選取和參數選擇,在實際應用中有一定的局限性。
隨著計算機算力的快速發展及可用數據源的增加,深度學習技術,特別是卷積神經網絡(Convolutional Neural Networks, CNN)已經成為自然語言處理、語義分割等領域的強大工具。CNN可以從輸入的圖片信息中自動學習語義信息,并通過順序連接的卷積層得到輸出結果。相比于傳統的機器學習方法,深度學習這種自我特征學習能力可以解決更為復雜的問題。諸多學者利用VGGNet[12]、GoogleNet[13]、ResNet[14]等CNN模型進行相關研究,效果優于傳統的機器學習方法。然而,CNN網絡的全連接層會將特征圖處理為固定長度的輸出向量,并以數值描述的形式進行結果輸出[15],所以適合于圖像級的分析和回歸任務,但并不適合于建筑物提取的這類語義分割任務。
2015年,Long提出全卷積網絡(Fully Convolutional Network, FCN)進行語義級別的分類。FCN在卷積層后連接上采樣層對特征圖進行處理,可以在最大程度上保留原始影像的空間信息[16],隨后涌現了一批以FCN為基礎架構的語義分割網絡。Ronneberger等[17]提出具有對稱編碼結構的UNet方法,UNet方法通過跳躍連接的方法來融合圖像的多尺度信息,提高圖像分割精度。Badrinarayanan等[18]提出的SegNet方法設計卷積配合池化的編碼器和反卷積加上采樣的解碼器,從而提升邊緣刻畫度并且減少訓練的參數。DeconvNet[19]在每一個卷積和反卷積層后都連接批歸一化層(Batch Normalization, BN),同時在上采樣前采用全連接層(Fully Connected Layers,FC)作為中介,增強了對類別的區分。Chen等[20-22]提出的DeepLab模型用概率圖模型優化分割結果,同時在卷積操作中設置擴張率擴大感受野[23-24]。DeepLabv3+作為該系列模型的最新改進,使用更深的網絡。DeepLabv3+設計融合層特征和高層特征的編碼-解碼結構(Encoder-Decoder),獲取更加豐富的影像特征圖。同時,在空洞空間金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)中加入了BN層,更高效從多個尺度聚合影像語義信息。此外,DeepLabv3+在ASPP和Decoder中都應用深度可分離卷積簡化模型參數并提高計算效率[22]。作為Google公司標志性的分割模型之一,在Cityscapes等數據集上有著良好的分割效果和精度優勢,但是較少在影像建筑物分割場景中使用。
文中提出一種遙感圖像建筑物自動提取架構,以DeepLabv3+為網絡,利用公開建筑物數據集(WHU Building Dataset)[25]進行建筑物提取研究,并與其他算法包括機器學習方法(SVM、K-Means、KNN、CART)和深度學習模型(U-Net、SegNet、PSPNet)進行精度對比,為高分辨率遙感影像建筑物高精度的自動提取提供借鑒。
1 研究方法
1.1 建筑物自動提取架構設計
文中研究的建筑物自動提取架構,主要包括數據處理、模型訓練和建筑物自動提取3部分,流程圖如圖1所示。
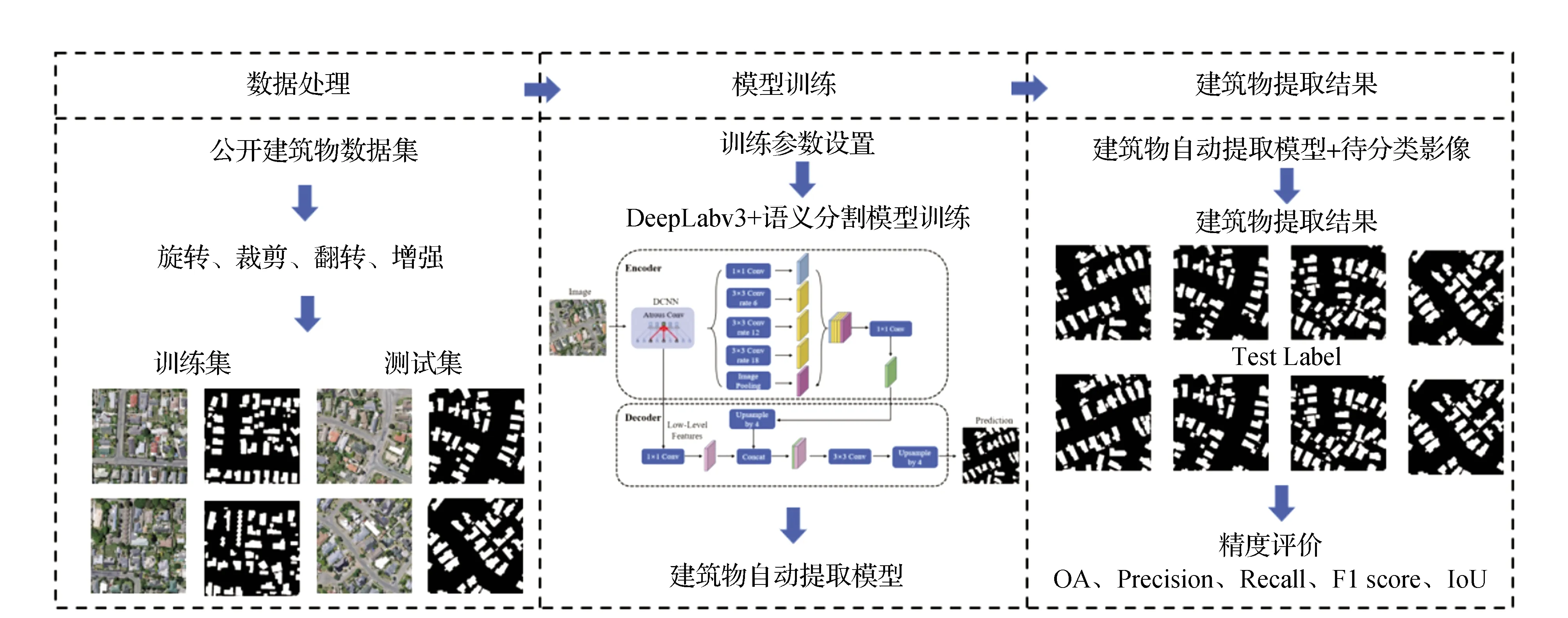
圖1 建筑物自動提取架構流程
1.2 DeepLabv3+網絡架構
DeepLabv3+利用DCNN+ASPP進行影像特征提取,得到經過DCNN的低層特征圖和經過ASPP的高層特征圖,搭配連接高-低特征圖的Decoder部分通過concat函數融合高、低層特征信息,得到特征高級且語義豐富的特征圖,經過上采樣恢復特征圖大小得到建筑物分類結果。ASPP與Decoder的結合可以在捕獲多尺度信息的基礎上有效融合低層與高層信息,提高圖像分割精度[26]。其網絡結構如圖2所示。
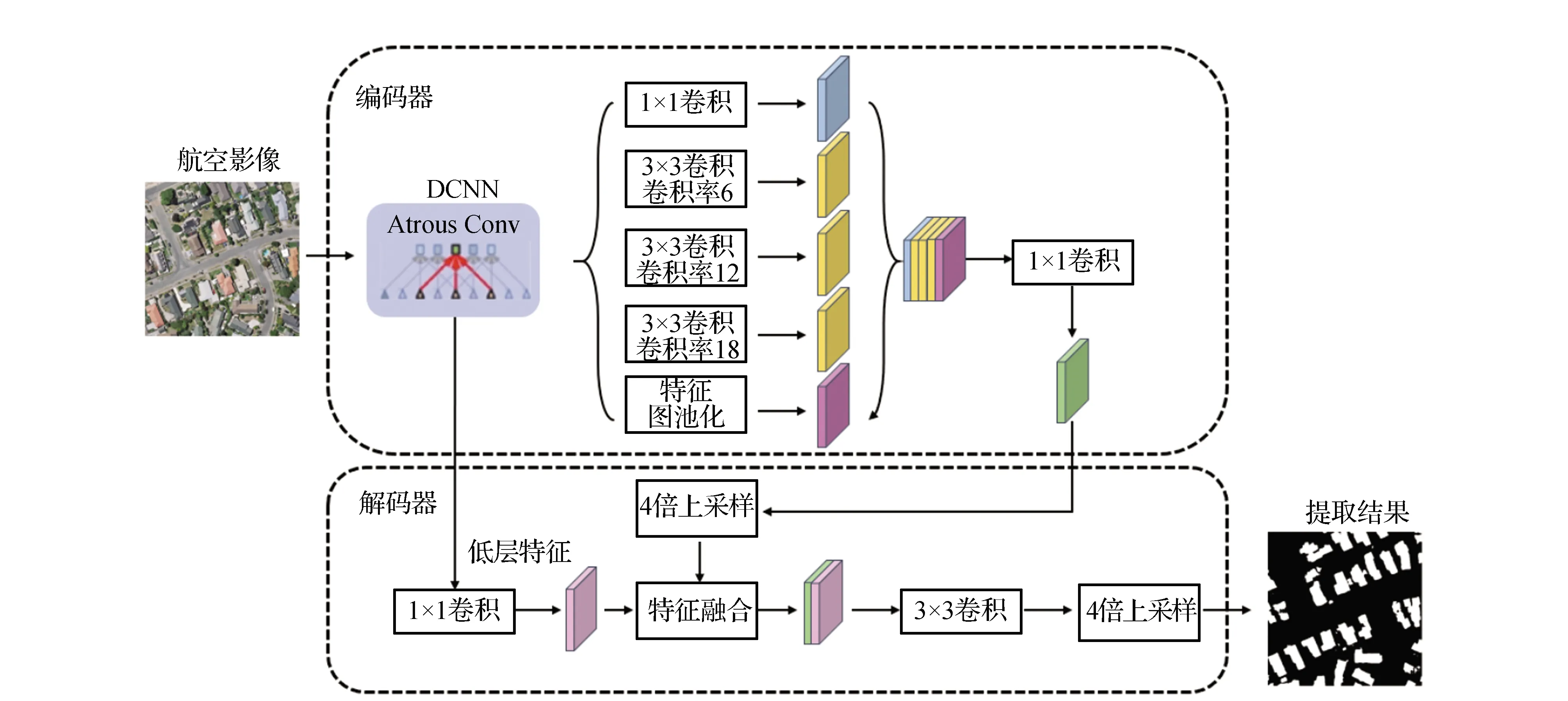
圖2 DeepLabv3+模型結構
Encoder中為了獲得空間分辨率更高的特征圖,選用帶空洞卷積(Atrous Convolution)的DCNN作為特征提取網絡,空洞卷積原理如圖3所示。通過設置空洞卷積中不同的比率(rate)得到低層特征圖和高層特征圖。其中空洞卷積是在原始卷積模塊基礎上進行一定的擴展,可以在相同的計算成本和參數量的前提下獲得更大的視覺感受野。經DCNN得到的低層特征圖直接進入Decoder,而高層特征圖通過ASPP進行處理。ASPP由4個具有不同比率的空洞卷積以及一個全局池化(Image Pooling)組成,通過融合多尺度信息提高分割精度。
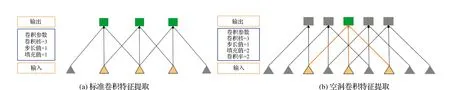
圖3 空洞卷積原理
在Decoder中,高層特征首先經過4倍雙線性內插上采樣(Upsample by 4)并與經過1×1卷積運算后的低層特征進行融合,然后經過一個3×3的卷積和雙線性插值得到預測結果。DeepLabv3+中的編碼-解碼結構示意圖如圖4所示。
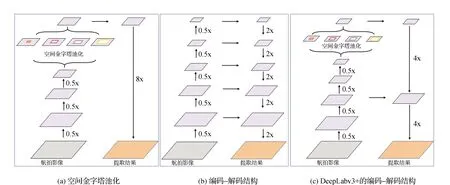
圖4 編碼-解碼結構示意圖
2 實驗數據集及評價指標
2.1 數據集
本研究采用的數據集是WHU Building Dataset[25],數據采集于新西蘭克賴斯特徹奇。WHU數據集空間分辨率為0.3 m,包括8 189幅512像素×512像素的遙感影像,分為訓練集、驗證集和測試集。WHU數據集的原始影像及其對應標簽如圖5所示。

圖5 原始影像及其對應標簽
2.2 數據處理
數據增強方法通過樣本擴充增加訓練樣本避免模型出現過擬合現象。本研究對樣本進行垂直、水平鏡像翻轉以及不同角度的旋轉,如圖6所示。

圖6 旋轉及翻轉后圖像
2.3 硬件配置及參數設置
本實驗基于PyTorch開發框架進行,硬件配置為NVIDIA GeForce RTX 3070。為了更好地利用圖形處理器(GPU)的能力,提高計算效率,將數據集中的圖像隨機裁剪為256像素×256像素。在實驗過程中,通過多次對比試驗,確定最優模型參數:采用Adam優化器;基礎學習率設為1E-4;設置150個epoch;為了克服GPU內存的限制,mini-batch size設為8。DeepLabv3+模型的精度和損失值隨訓練次數的變化如圖7所示。
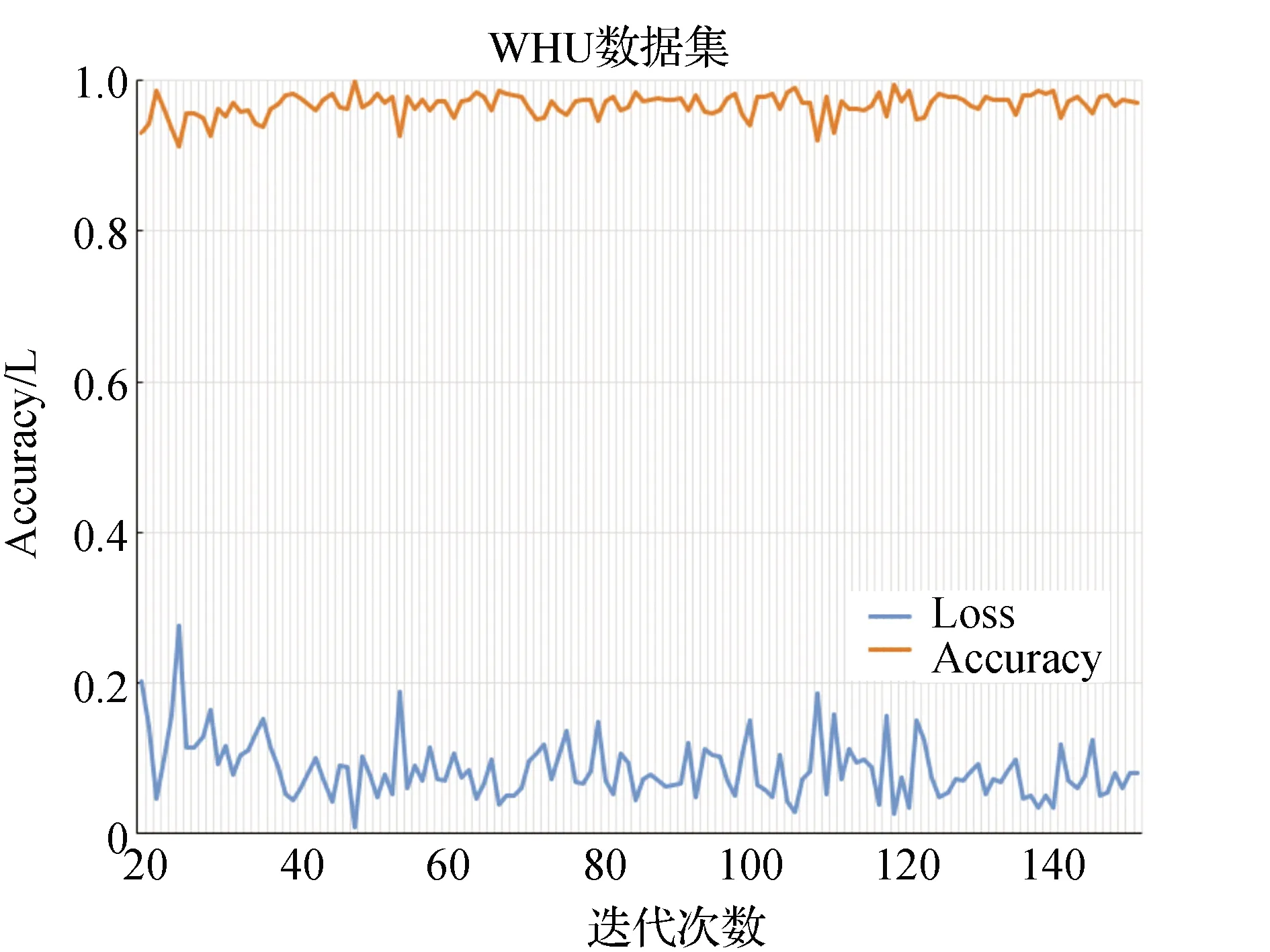
圖7 精度和損失值隨訓練次數的變化
為了探究文中提出的架構在建筑物自動提取方面的精度優勢,選用SVM、K-Means、KNN、CART 4種傳統的機器學習方法以及U-Net、SegNet、PSPNet 3種典型的語義分割網絡與DeepLabv3+網絡進行對比試驗。在實驗過程中,通過對比分類結果,確定了最佳的模型參數。SVM方法、K-Means方法使用ENVI完成,SVM參數設置如下:Gamma值為0.333,懲罰系數為100,內核類型為Radial Basis Function;K-Means參數設置包括:分類類別為10,改變閾值為5%,最大迭代為1。KNN方法、CART方法使用eCognition完成,KNN參數設置包括:圖像分割方法為Multiresolution Segmentation,分割閾值為20,深度為0,最小樣本數為0,交叉驗證層數為3;CART參數設置與KNN方法保持一致。U-Net、SegNet、PSPNet的訓練參數設置與DeepLabv3+參數保持一致。
2.4 評價指標
1)總體精度(Overall Accuracy, OA),影像中預測正確的建筑物和背景像元占所有像元的比例:
(1)
式中:TP代表提取為建筑物,實際為建筑物的個數;FP代表提取為建筑物,實際為背景的個數;TN代表提取為背景,實際為背景的個數;FN代表提取為背景,實際為建筑物的個數。
2)召回率(Recall),影像中預測正確的建筑物像元占建筑物區域真值像元的比例:
(2)
3)精確度(Precision),影像中預測正確的建筑物像元占所有預測為建筑物像元的比例:
(3)
4)F1得分(F1-score),代表OA和Precision的加權平均值:
(4)
5)交并比(IoU),代表真實值和預測值兩個集合的交集與并集的比值:
(5)
3 結果與討論
3.1 基于像素分類方法結果對比
SVM,K-Means和DeepLabv3+各分類方法的結果如圖8所示。圖8中的白色、黑色分別為建筑物、背景的預測。基于像素的分類方法(SVM、K-Means)提取結果中有明顯的椒鹽現象,也有許多其他要素被誤分為建筑物。語義分割網絡DeepLabv3+建筑物提取效果較好,大部分建筑物的邊緣部分相對清晰,只是在細節上有著零星斑點。

圖8 基于像素分類方法結果對比
SVM,K-Means和DeepLabv3+的精度指標如表1所示。SVM方法的各項平均精度指標(OA=69.6%;Precision=62.1%;Recall=66.4%;F1 score=63.7%;IoU=45.3%)均高于K-Means方法(OA=57.3%;Precision=34.7%;Recall=48.2%;F1 score=40.2%;IoU=21.6%)。DeepLabv3+精度評價的各項指標遠超于基于像素分類方法的指標,各評價指標均超過89.1%。
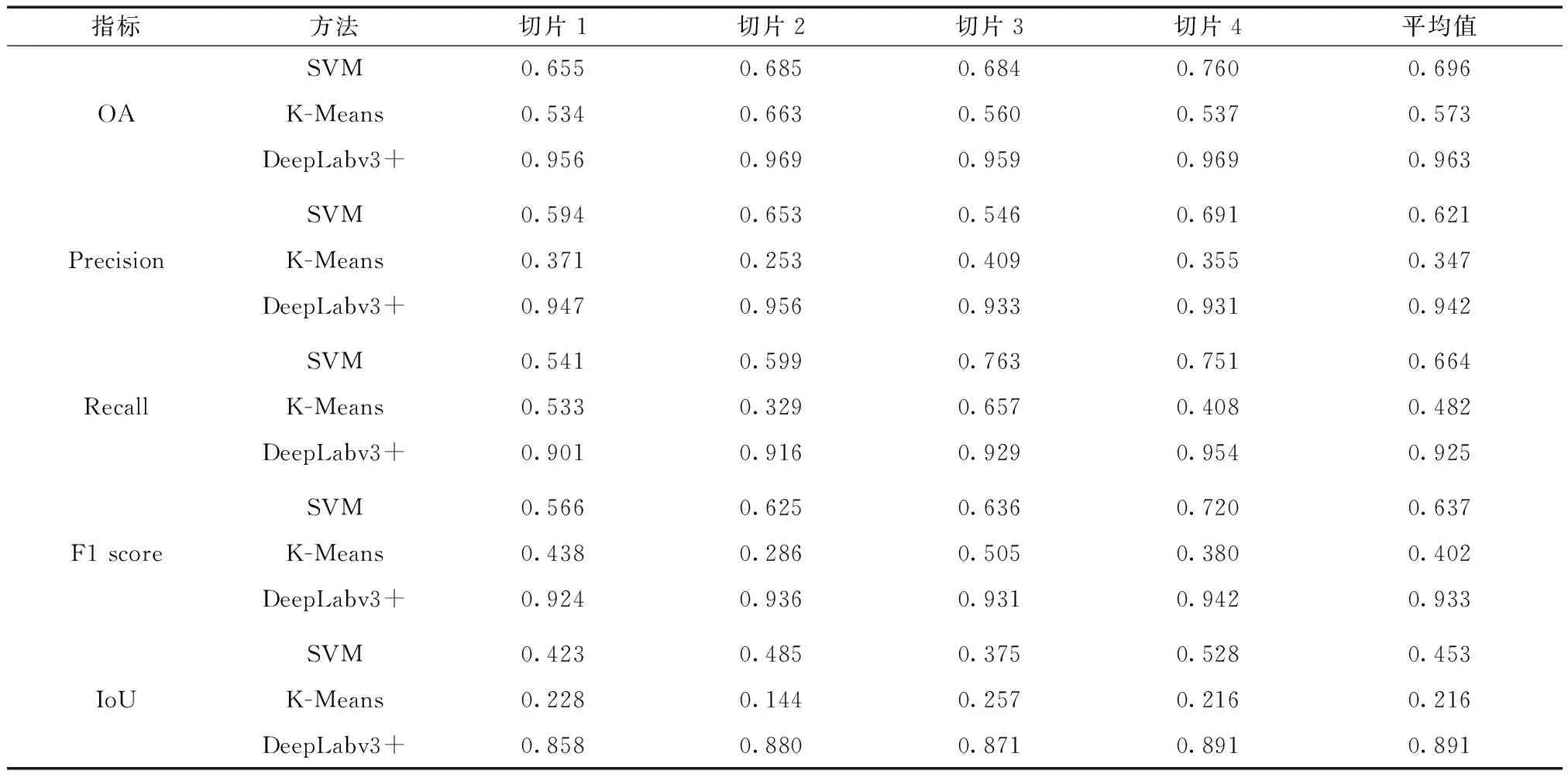
表1 基于像素分類方法精度對比
3.2 面向對象分類方法結果對比
KNN,CART和DeepLabv3+各方法的分類結果如圖9所示。圖9中的白色、黑色分別為建筑物、背景的預測。面向對象的分類方法(KNN、CART)提取建筑物椒鹽問題有所改善,但是建筑物輪廓仍不夠清晰,出現了分類結果連片的情況,同時有大量的誤分、漏分情況。

圖9 面向對象分類方法結果對比
KNN,CART和DeepLabv3+的精度指標如表2所示。KNN方法的各項平均精度指標均高于K-Means方法,KNN方法的OA、Precision、Recall、F1 score、IoU分別比K-Means方法提高6.0%,10.2%,22.4%,10.1%,19.0%。DeepLabv3+相對于KNN和CART方法,各評價指標平均提高25.1%,表明該方法比面向對象方法更適合于建筑物提取任務。
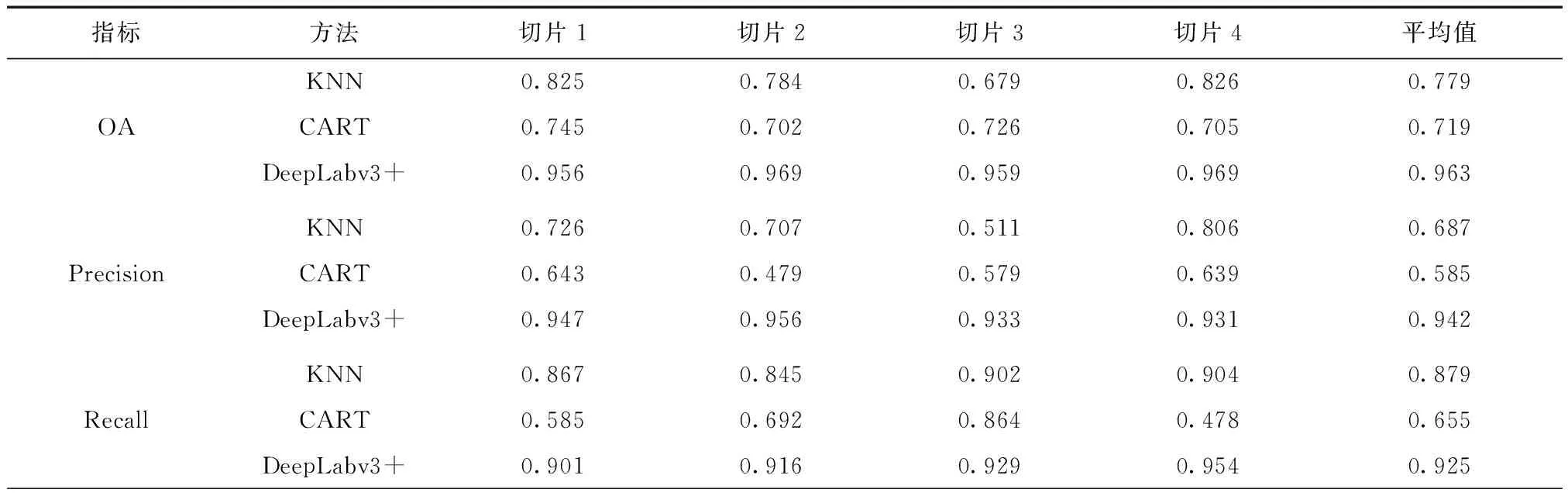
表2 面向對象分類方法精度對比

續表2
3.3 語義分割網絡結果對比
為了更好地比較UNet、SegNet、PSPNet和DeepLabv3+這4種網絡模型提取建筑物的效果,將提取的建筑物結果進行更加詳細的展示,4種網絡的建筑物提取結果如圖10所示。圖中綠色代表正確提取的建筑物,藍色代表漏檢的建筑物,紅色代表誤檢的建筑物,黑色代表背景。
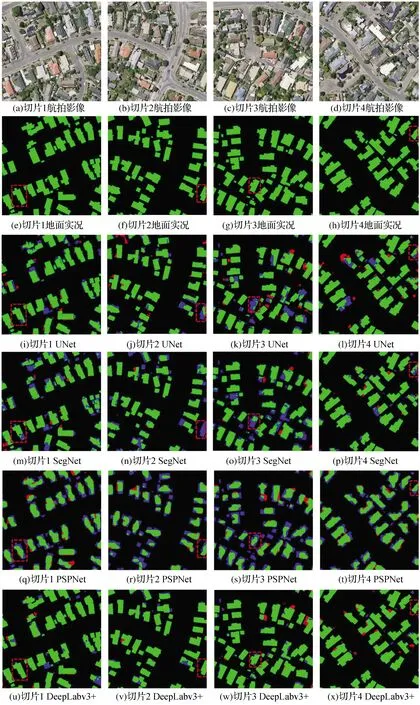
圖10 語義分割網絡結果對比
從整體而言,PSPNet的提取結果中正確提取(綠色)的建筑物最少,漏檢(藍色)的建筑物最多。UNet和SegNet的提取結果中,正確提取(綠色)的建筑物和漏檢(藍色)的建筑物大致相同,但是UNet有更多誤檢(紅色)的建筑物。相比之下,DeepLabv3+的分割結果中漏檢(藍色)和誤檢(紅色)的建筑物明顯少于其他網絡模型,但是由于DeepLabv3+仍選用兩次雙線性插值上采樣來增加特征分辨率以及數據集本身的限制,DeepLabv3+對于少部分建筑物的邊緣易誤分。
從單個建筑物來看,如切片1中的紅框內提取結果所示,UNet、SegNet和PSPNet只提取了小部分,有比較明顯的漏檢情況,而DeepLabv3+提取的相對完整,有清晰的建筑物邊界,基本不存在漏檢的建筑物;如切片2中的紅框內提取結果所示,SegNet完全沒有提取到該建筑物,而PSPNet比UNet提取效果好,但只提取了部分輪廓,DeepLabv3+提取效果最好,提取了完整的建筑物輪廓;如切片3中的紅框內提取結果所示,UNet只提取到了該建筑物的很小一部分輪廓,SegNet提取到了該建筑物的上半部分輪廓,PSPNet提取到了建筑物的中部輪廓,而DeepLabv3+提取比較完整,提取到了完整的建筑物輪廓信息;如切片4中的紅框內提取結果所示,UNet、SegNet和PSPNet提取效果相當,能夠提取大部分建筑物輪廓,而DeepLabv3+效果更好,沒有漏檢和誤檢的情況。
研究不同模型建筑物提取精度定量評定結果如表3所示。DeepLabv3+的總體精度、召回率、F1得分、交并比值均最高,UNet的準確度值最高。其中DeepLabv3+的F1得分達到了93.3%,相對UNet提高3.4%,相對SegNet提高6.9%,相對PSPNet提高11.2%;且交并比相對UNet提高5.7%,相對SegNet提高11.3%,相對PSPNet提高17.8%。
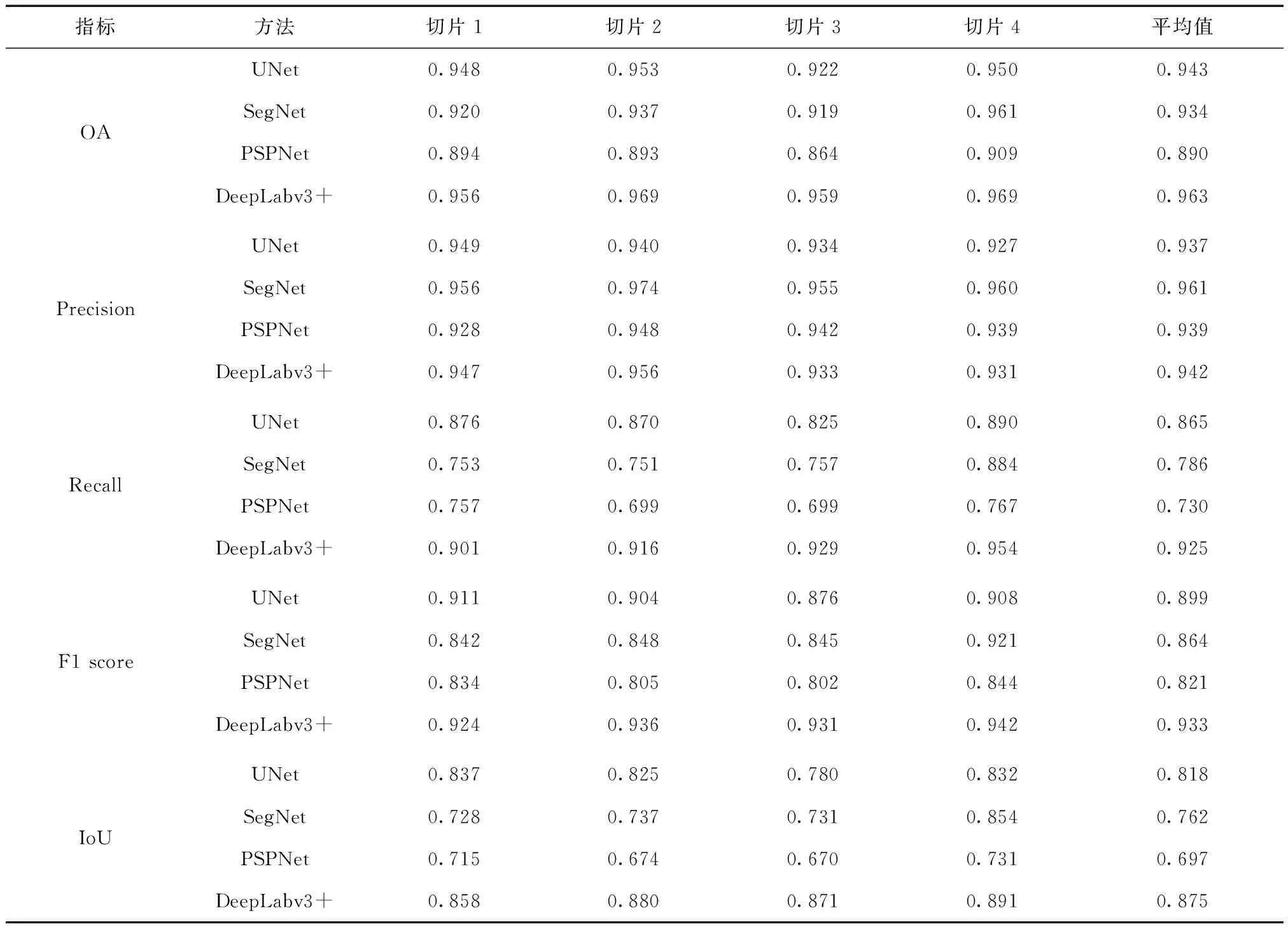
表3 語義分割網絡精度對比
定性分析和定量評價結果表明,文中選用的DeepLabv3+模型采用空洞卷積和空間金字塔池化的Encoder-Decoder結構,建筑物分割效果較好,提取精度有所提升,具備區分建筑物和其它地物的能力。
4 結 論
文中提出一種高分辨率遙感影像建筑物自動提取架構,基于DeepLabv3+網絡,利用WHU數據集進行提取實驗,并與基于像素的分類方法、面向對象的分類方法以及其他語義分割模型進行結果與精度的對比分析,結論如下:
1)基于像素的分類方法(SVM、K-Means)和面向對象的分類方法(KNN、CART)可以實現建筑物的提取,但與本架構的提取效果相比,建筑物提取結果中椒鹽效應明顯,難以得到清晰的建筑物輪廓。與深度學習方法相比,需要大量參數設置,效率較低。
2)利用DeepLabv3+進行高分辨率遙感影像建筑物提取,總體精度為96.3%、召回率為92.5%、F1得分為93.3%、交并比為87.5%,在幾種網絡中表現最優,表明DeepLabv3+在高分辨率遙感影像中的建筑物提取中效果較好,具有較高精度。
今后研究將考慮在模型的解碼器部分增加更多的低層特征來源,并進一步與其他算法相結合,提高建筑物的提取精度,同時選用更多的數據集進行實驗分析。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
