深度學(xué)習(xí)下的目標(biāo)跟蹤綜述*
2022-08-09 06:16:06陳浩東蔣鑫張桓瑋
計(jì)算機(jī)時(shí)代 2022年8期
陳浩東,蔣鑫,張桓瑋
(南京理工大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院,江蘇 南京 210094)
0 引言
基于視頻的目標(biāo)跟蹤是在得到視頻序列中目標(biāo)初始狀態(tài)的情況下,預(yù)測(cè)后續(xù)序列中目標(biāo)的大小、位置和方向等狀態(tài)信息。視覺跟蹤技術(shù)無(wú)論是在軍用還是民用領(lǐng)域都具有重要的研究意義和廣闊的應(yīng)用前景。
本文主要內(nèi)容如圖1所示,主要貢獻(xiàn)如下:
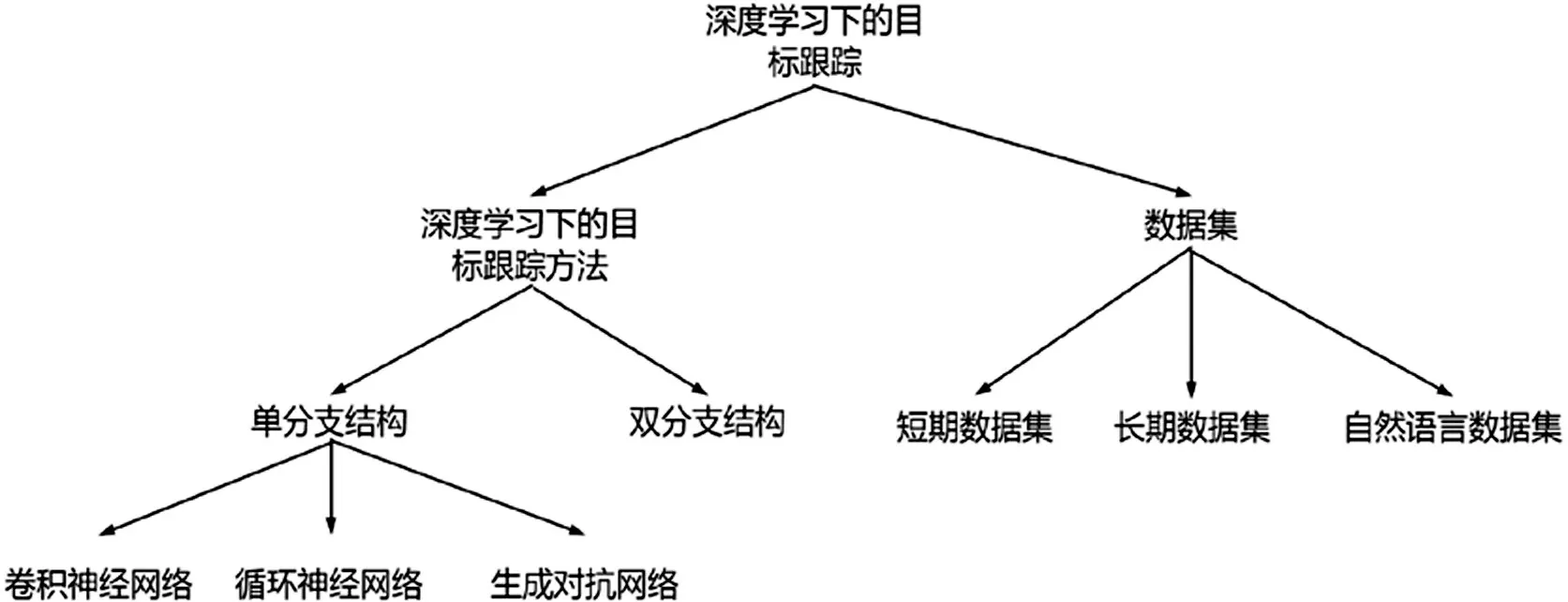
圖1 深度學(xué)習(xí)下的目標(biāo)跟蹤方法
⑴以深度學(xué)習(xí)下目標(biāo)跟蹤方法的網(wǎng)絡(luò)結(jié)構(gòu)為出發(fā)點(diǎn),對(duì)基于卷積神經(jīng)網(wǎng)絡(luò)、基于循環(huán)神經(jīng)網(wǎng)絡(luò)、基于對(duì)抗生成網(wǎng)絡(luò)和基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤方法的發(fā)展進(jìn)行了總結(jié)。
⑵對(duì)常用的數(shù)據(jù)集進(jìn)行的對(duì)比和分析,作為研究工作中選擇數(shù)據(jù)集的一個(gè)參考。
⑶總結(jié)了目前目標(biāo)跟蹤領(lǐng)域存在的問題,展望了視覺目標(biāo)跟蹤技術(shù)的發(fā)展趨勢(shì)。
1 目標(biāo)跟蹤方法
1.1 單分支網(wǎng)絡(luò)
1.1.1 卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)(CNN)方法在計(jì)算機(jī)在計(jì)算機(jī)視覺領(lǐng)域取得突破后,一系列基于CNN 的方法被提出,它們的研究動(dòng)機(jī)可以歸為以下幾點(diǎn)。
使用大數(shù)據(jù)預(yù)訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò):MDNet和UCT,它們使用ResNet等深度卷積網(wǎng)絡(luò)提取圖像特征。
融合多層深度圖像特征:Wang 等人在FCNT 中發(fā)現(xiàn)頂層的特征包含更多的語(yǔ)義信息可以用作檢測(cè)器,較低層攜帶更多判別信息,可以更好的將目標(biāo)與具有相似外觀的干擾物區(qū)分開來。基于以上發(fā)現(xiàn),Wang等人提出了融合多層深層圖像特征的FCNT。
相關(guān)濾波方法:這類方法將模型與相關(guān)濾波方法結(jié)合,發(fā)揮了CNN的特征表征能力和相關(guān)濾波的速度優(yōu)勢(shì)。C-COT將CNN 與相關(guān)濾波結(jié)合后,取得了極大的轟動(dòng),ECO還針對(duì)相關(guān)濾波方法的計(jì)算復(fù)雜度問題進(jìn)行優(yōu)化。
1.1.2 循環(huán)神經(jīng)網(wǎng)絡(luò)
MemTrack引入了可動(dòng)態(tài)更新的動(dòng)態(tài)存儲(chǔ)網(wǎng)絡(luò),由具有注意力機(jī)制的LSTM 控制的外部記憶塊適應(yīng)外觀變化。SANet在模型的學(xué)習(xí)過程中利用RNN結(jié)構(gòu)對(duì)對(duì)象的自結(jié)構(gòu)進(jìn)行編碼,不僅提高了模型區(qū)分類間背景對(duì)象的能力,還提高了類內(nèi)類似干擾項(xiàng)的能力。
1.1.3 生成對(duì)抗網(wǎng)絡(luò)
生成對(duì)抗網(wǎng)絡(luò)(GAN)雖然難以訓(xùn)練和評(píng)估,但還是有基于深度學(xué)習(xí)的方法利用GAN 生成訓(xùn)練樣本VITAL針對(duì)基于檢測(cè)的跟蹤中存在的正樣本過少負(fù)樣本過多的問題,使用GAN來增加特征空間中的正樣本,以捕獲時(shí)間跨度內(nèi)的各種外觀變化。
1.2 雙分支網(wǎng)絡(luò)
雙分支網(wǎng)絡(luò)即孿生網(wǎng)絡(luò),基于孿生網(wǎng)絡(luò)的目標(biāo)跟蹤算法思想是學(xué)習(xí)一個(gè)魯棒的外觀模型,并訓(xùn)練一個(gè)相似度匹配函數(shù),通過相似度匹配函數(shù)尋找到當(dāng)前幀的目標(biāo)區(qū)域。孿生網(wǎng)絡(luò)的研究動(dòng)機(jī)可以劃分為研究判別性目標(biāo)表示和自適應(yīng)目標(biāo)變化兩部分。
1.2.1 判別性目標(biāo)表示
孿生網(wǎng)絡(luò)為了得到更具判別性的深度圖像特征并提升外觀模型的,孿生網(wǎng)絡(luò)采用了以下方法。
⑴采用更深層的神經(jīng)網(wǎng)絡(luò):Zhang 等人提出了SiamDW 算法,通過設(shè)計(jì)一個(gè)殘差結(jié)構(gòu)消除深度網(wǎng)絡(luò)帶來的負(fù)面影響,同時(shí)調(diào)整了主干網(wǎng)絡(luò)的步長(zhǎng)和感受野,將ResNet引入了孿生網(wǎng)絡(luò),在SiamFC上進(jìn)行了實(shí)驗(yàn)驗(yàn)證,取得了較原始模型更優(yōu)異的性能。
⑵融合多層深度圖像特征:Fan 等人提出了使用了級(jí)聯(lián)區(qū)域推薦網(wǎng)絡(luò)(RPN)的C-RPN。C-RPN 通過多層RPN 網(wǎng)絡(luò),逐層篩選其中屬于負(fù)樣本的anchor,將模型視為正樣本的anchor 輸入到下一層的RPN 網(wǎng)絡(luò),在復(fù)雜的背景下如存在相似語(yǔ)義障礙物時(shí)能夠取得更加魯棒的表現(xiàn)。
⑶精確的目標(biāo)估計(jì):Zhang 等人提出的Ocean基于像素級(jí)的訓(xùn)練策略:將在真實(shí)邊界框內(nèi)的所有像素視為正樣本,邊界框外視為負(fù)樣本,訓(xùn)練出的回歸網(wǎng)絡(luò)即使目標(biāo)只有一個(gè)小區(qū)域被識(shí)別為前景,也能預(yù)測(cè)目標(biāo)對(duì)象的尺度。
⑷向深度圖像特征施加注意力:Yu等在SiamAttn在目標(biāo)分支和搜索分支中分別做self-attention 操作,實(shí)現(xiàn)對(duì)通道和特殊位置進(jìn)行關(guān)注。在搜索分支和目標(biāo)分支之間進(jìn)行了cross-attention計(jì)算,讓搜索分支學(xué)習(xí)到目標(biāo)信息。此外,類似工作還有TranT和STARK,它們向深度特征施加注意力的方式如表1所示。

表1 目標(biāo)跟蹤方法提出的施加注意力的方法
⑸ 利用性能更強(qiáng)的相似度匹配函數(shù):Chen 等人提出的TransT 通過將原本孿生網(wǎng)絡(luò)跟蹤器的相關(guān)運(yùn)算(如深度互相關(guān))替換成了Transform-er中的attention運(yùn)算,有效地解決了孿生網(wǎng)絡(luò)中相關(guān)性計(jì)算的局部線性匹配問題。此外,類似的工作還有STARK和SiamGAT,它們的相似匹配函數(shù)如表2所示。

表2 目標(biāo)跟蹤方法提出的相似匹配函數(shù)
1.2.2 自適應(yīng)目標(biāo)外觀變化
⑴在線更新方法:Zhang等人提出了UpdateNet,通過訓(xùn)練得到UpdateNet 的參數(shù),將初始模板、上一幀計(jì)算模板和上一次計(jì)算出的模板輸入到網(wǎng)絡(luò)中,得到新的模板,用新的模板進(jìn)行相似性計(jì)算。
⑵將跟蹤視為檢測(cè)任務(wù):Voigtlaender 等人將Faster R-CNN應(yīng)用到目標(biāo)跟蹤上,利用一個(gè)來自第一幀的重檢測(cè)模型和來自歷史幀的重檢測(cè)模型,對(duì)當(dāng)前幀進(jìn)行檢測(cè),以得到最終目標(biāo)位置。
2 數(shù)據(jù)集
隨著目標(biāo)跟蹤領(lǐng)域的發(fā)展,規(guī)模越來越大、場(chǎng)景越來越多的目標(biāo)跟蹤數(shù)據(jù)集被提出,如圖2所示。根據(jù)數(shù)據(jù)集中單個(gè)視頻序列的長(zhǎng)度可分為短期目標(biāo)跟蹤數(shù)據(jù)集和長(zhǎng)期目標(biāo)跟蹤數(shù)據(jù)集。短期目標(biāo)跟蹤數(shù)據(jù)集如OTB2015、VOT2017、UAV123、TrackingNet、GoT-10k等,長(zhǎng)期目標(biāo)跟蹤數(shù)據(jù)集包括LaSoT、OxUvA等。此外,Wang等人提出了自然語(yǔ)言規(guī)范跟蹤的多媒體數(shù)據(jù)集:TNL2K 數(shù)據(jù)集,表3 主要總結(jié)了上述數(shù)據(jù)集的信息。
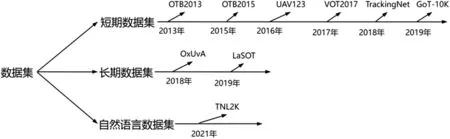
圖2 深度學(xué)習(xí)下數(shù)據(jù)集的發(fā)展
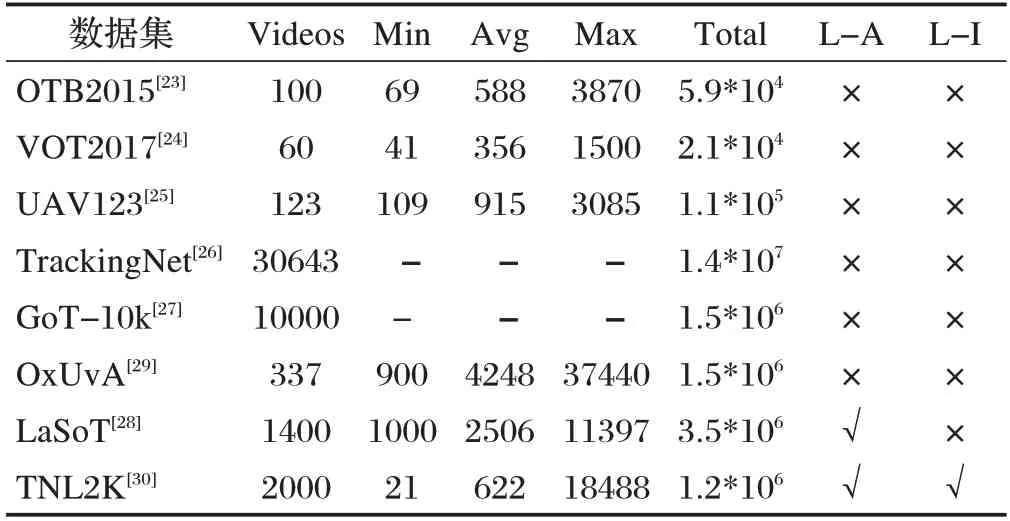
表3 不同數(shù)據(jù)集信息對(duì)比
⑴OTB數(shù)據(jù)集
OTB 數(shù)據(jù)集包含光照變化、目標(biāo)尺度變化、遮擋、目標(biāo)形變等總共11 種視覺屬性,此外還包含25%的灰度圖像。OTB 數(shù)據(jù)集將精確圖、成功圖、魯棒性評(píng)估作為數(shù)據(jù)集對(duì)模型的評(píng)價(jià)指標(biāo)。魯棒性評(píng)估包括一次性評(píng)估、時(shí)間魯棒性評(píng)估和空間魯棒性評(píng)估。
⑵VOT數(shù)據(jù)集
VOT 數(shù)據(jù)集包含相機(jī)移動(dòng)、光照變化、目標(biāo)尺寸變化、目標(biāo)動(dòng)作變化和遮擋等6種視覺屬性。VOT數(shù)據(jù)集的主要評(píng)估指標(biāo)為預(yù)期平均重疊、準(zhǔn)確率和魯棒性。
⑶UAV123數(shù)據(jù)集
UAV123 數(shù)據(jù)集是Mueller 等人在2016 年提出的基于無(wú)人機(jī)視角的低空目標(biāo)跟蹤數(shù)據(jù)集,與OTB,VOT等使用常規(guī)攝像機(jī)拍攝的數(shù)據(jù)集存在本質(zhì)區(qū)別。UAV123 數(shù)據(jù)集包括縱橫比變化、背景干擾、攝像機(jī)移動(dòng)、完全遮擋、光照變化等總共12種視覺屬性。UAV123數(shù)據(jù)集采用與OTB 數(shù)據(jù)集相同的模型評(píng)估策略。
⑷TrackingNet數(shù)據(jù)集
TrackingNet 數(shù)據(jù)集接近真實(shí)世界的目標(biāo)跟蹤任務(wù),密集的數(shù)據(jù)注釋使目標(biāo)跟蹤模型的設(shè)計(jì)能更偏重于挖掘視頻序列中目標(biāo)的運(yùn)動(dòng)信息。TrackingNet 使用OTB 數(shù)據(jù)集中采用的一次評(píng)估策略,并將成功率和精度作為評(píng)估指標(biāo)。
OxUvA 中視頻序列的平均時(shí)長(zhǎng)超過2 分鐘,且OxUvA 中超過一半的視頻都包含目標(biāo)消失的情況,貼近真實(shí)世界的情況,對(duì)目標(biāo)跟蹤模型的性能提出了更高的要求。
值得注意的是OxUvA 每30 幀才標(biāo)注1幀,因此,雖然OxUvA數(shù)據(jù)集的數(shù)據(jù)量非常大,但它適合用于模型評(píng)估,而不是用于訓(xùn)練。
GoT-10k 數(shù)據(jù)集總共包含563 種目標(biāo)類別和87種運(yùn)動(dòng)模式。GoT-10k提供了目標(biāo)對(duì)象的可見率,表示目標(biāo)對(duì)象可見的大致比例。可見率為發(fā)展處理遮擋問題的跟蹤方法提供了便利。模型評(píng)估上,Huang 等人選擇具有明確含義且簡(jiǎn)單的指標(biāo):平均重疊和成功率作為數(shù)據(jù)集的評(píng)估指標(biāo)。
LaSoT 包含1400 個(gè)視頻序列,包含70 種目標(biāo)類別,每個(gè)類別包含20 個(gè)視頻序列,減少目標(biāo)類別給目標(biāo)跟蹤模型帶來的影響;每個(gè)視頻序列都包含戶外場(chǎng)景的各種挑戰(zhàn);每個(gè)視頻序列平均長(zhǎng)度超過2500 幀。此外重要的一點(diǎn)在于LaSoT 除傳統(tǒng)的BBox 注釋外,還為每個(gè)視頻序列添加了自然語(yǔ)言注釋,使其能夠用于自然語(yǔ)言輔助目標(biāo)跟蹤任務(wù)。
TNL2K 包含了17種視覺屬性,總計(jì)2000個(gè)視頻。在注釋方式上,每個(gè)視頻使用自然語(yǔ)言注釋,指示了第一幀中目標(biāo)對(duì)象的空間位置、與其他對(duì)象的相對(duì)位置、目標(biāo)屬性和類別,使其能夠用于自然語(yǔ)言規(guī)范目標(biāo)跟蹤任務(wù),并為該視頻中的每一幀注釋一個(gè)邊界框。評(píng)價(jià)指標(biāo)上依舊采用了流行的準(zhǔn)確圖和成功圖。
3 總結(jié)
回顧基于深度學(xué)習(xí)的目標(biāo)跟蹤算法的發(fā)展,很多在目標(biāo)跟蹤上取得成就的技術(shù)都是來自深度學(xué)習(xí)的其他領(lǐng)域的理論,如自然語(yǔ)言、注意力機(jī)制等。如何更好的利用這些已引入的理論以及如何從其他領(lǐng)域引入新的理論,將是基于深度學(xué)習(xí)的目標(biāo)跟蹤算法現(xiàn)在以及未來的研究熱點(diǎn)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年12期)2018-08-26 06:03:48
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
