基于XGBoost算法的上市公司財務報表舞弊識別研究
2022-08-09 06:16:10吳貞如
計算機時代 2022年8期
吳貞如
(南京審計大學信息工程學院,江蘇 南京 211815)
0 引言
財務報表是反映公司財務狀況、經(jīng)營業(yè)績以及可持續(xù)發(fā)展情況的結構性描述,是投資者、股東、債權人、公司員工以及其他利益相關者決策的主要的參考文件。目前,財務報表的真實性主要依賴于管理者的道德標準、財務報表的穩(wěn)健審計以及審計師出具的審計報告和意見。但是,大多數(shù)財務報表舞弊是在管理層意識到或同意的情況下實施的。近年來,國際資本市場的一體化和經(jīng)濟模式的復雜化給新興市場投資帶來巨大的商業(yè)挑戰(zhàn),操縱財務報表以逃避本國稅收或?qū)①Y本轉(zhuǎn)移到海外的動機和機會持續(xù)增加。相關文獻研究表明,當前財務報表舞弊現(xiàn)象十分嚴重:犯罪分子越來越擅于規(guī)避監(jiān)管機制,舞弊行為越來越復雜。此外,根據(jù)美國注冊舞弊審查員協(xié)會發(fā)布的《2020 年全球職務舞弊與濫用職權調(diào)查報告》數(shù)據(jù),雖然財務報表舞弊的發(fā)生頻率低于資產(chǎn)挪用和腐敗等因素,但是造成的經(jīng)濟損失卻遠高于其他舞弊,嚴重損害了資本市場的可持續(xù)發(fā)展。因此,識別財務報表舞弊行為,對維護投資者的利益和保障資本市場的可持續(xù)發(fā)展具有重要意義。
隨著計算機技術的高速發(fā)展,各領域進入大數(shù)據(jù)和人工智能時代,機器學習因為能夠快速有效地處理大量數(shù)據(jù)被廣泛應用。基于機器學習算法構建財務報表舞弊行為識別模型能夠改善傳統(tǒng)財務報表舞弊識別方法過度依賴人力的不足。因此,本研究基于機器學習中的XGBoost 算法構建財務報表舞弊識別模型,提高財務報表使用者對潛在舞弊的意識,識別財務報表舞弊行為,減少因財務報表舞弊行為造成的損失,維護資本市場的可持續(xù)發(fā)展。
1 研究現(xiàn)狀
Hamal和Senvar認為財務報表舞弊識別需要復雜的分析工具和技術,而不是審計師所采用的傳統(tǒng)方法。財務報表舞弊識別是一個典型二分類問題。作為人工智能的重要分支,機器學習是解決分類問題最前沿的方法和技術。Gupta 和Mehta通過實驗證明使用機器學習算法構建的財務報表舞弊識別模型比傳統(tǒng)的方法具有更高的準確性。相比于傳統(tǒng)的統(tǒng)計方法,基于機器學習算法不但可以處理大量數(shù)據(jù)進行更準確的分類和預測,而且不需要像傳統(tǒng)的統(tǒng)計方法進行假設,可以更有效地處理非線性問題。
近年來,諸多學者基于機器學習方法構建財務報表舞弊識別模型,并從不同的角度,使用不同的方法進行研究。Chyan-Long分別使用人工神經(jīng)網(wǎng)絡和支持向量機篩選出重要的財務變量和非財務變量,然后使用分類回歸樹、卡方自動交互檢測器、C5.0 和快速無偏高效統(tǒng)計樹等四種決策樹進行分類,通過實驗證明用人工神經(jīng)網(wǎng)絡篩選并用分類回歸樹處理變量構建的財務報表舞弊識別模型準確率最高。Yao等人分別采用逐步回歸和主成分分析降低變量維度,使用支持向量機、分類與回歸樹、反向傳播神經(jīng)網(wǎng)絡、邏輯回歸、貝葉斯分類器六種機器學習方法識別財務報表舞弊行為,通過實驗表明基于逐步回歸和支持向量機融合方法構建財務報表舞弊識別模型的準確率最高。黃志剛等人使用邏輯回歸前向步進的方法篩選出敏感指標并構建整體舞弊敏感指標集輸入到樸素貝葉斯、隨機森林、K 鄰近算法、支持向量機等機器學習算法中,并發(fā)現(xiàn)隨機森林、支持向量機在識別上市公司財務報表舞弊行為的準確率都超過了80%。
2 研究方法
2.1 數(shù)據(jù)采集
本研究使用的數(shù)據(jù)來源于中國股票市場與會計研究(CSMAR)數(shù)據(jù)庫中的2011-2020年深滬A股上市公司年度財務報表,其中選取了283個舞弊財務報表,共涉及126 家上市公司。為控制外部環(huán)境和行業(yè)因素,本研究在選取非舞弊樣本時參照兩個準則:一是舞弊樣本數(shù)據(jù)和非舞弊樣本數(shù)據(jù)涉及的上市公司屬于同一個行業(yè),二是舞弊樣本數(shù)據(jù)和非舞弊樣本數(shù)據(jù)來自同一個年度。按照這兩個準則,并以1:2 的匹配比例選取252 家上市公司共566 個非舞弊財務報表。最終,本研究選取849 個財務報表作為財務報表舞弊識別模型的檢測樣本,共涉及378 家上市公司。樣本行業(yè)類型匯總和樣本年份分布情況如表1和圖1所示。
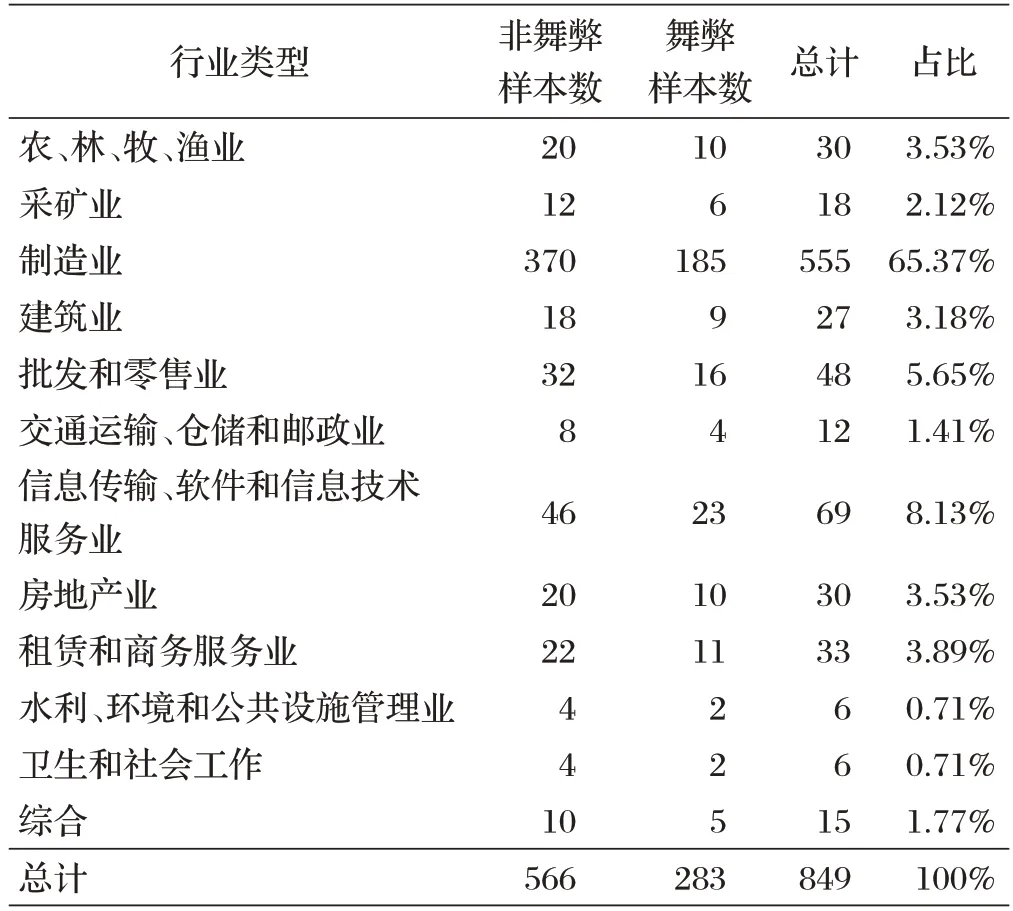
表1 樣本行業(yè)類型匯總
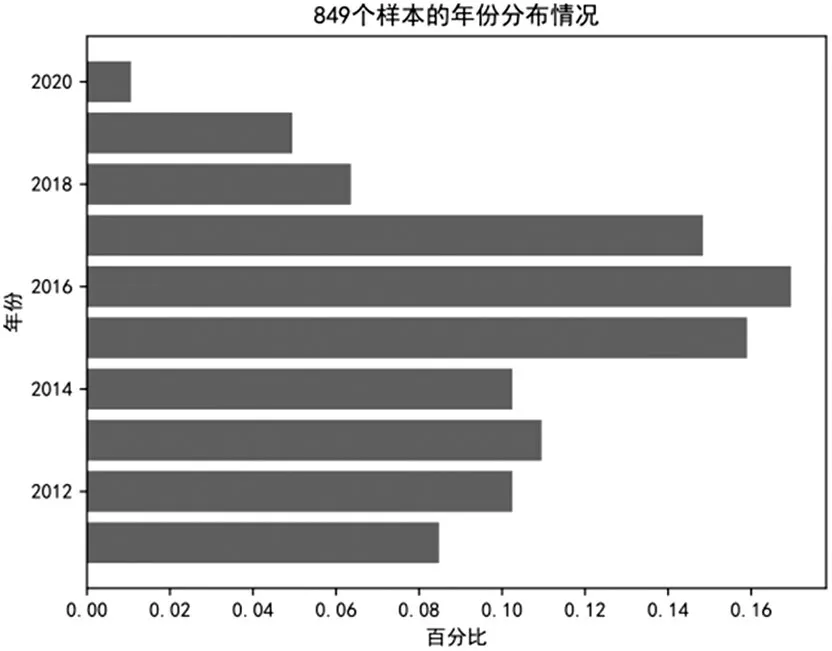
圖1 樣本年份分布情況
從表1 可以看出,制造業(yè)上市公司涉及財務報表舞弊最多,占比超過50%。從圖1 可以看出,2015~2017年期間,財務報表舞弊發(fā)生的頻率偏高。
2.2 變量選取
2.2.1 變量初選
為提高模型預測的準確率,選擇合適的財務舞弊識別指標十分關鍵。因此,在現(xiàn)有的研究基礎上,基于五個維度,即償債能力、經(jīng)營能力、盈利能力、發(fā)展能力和治理結構,本研究初步選取26個用于衡量財務報表舞弊的指標,分別由22 個財務變量和4 個非財務變量組成,如表2所示。

表2 初選變量
2.2.2 變量篩選模型
信息值(IV)可以評價變量對目標影響程度的指標,即衡量變量的預測能力。信息值的計算是基于證據(jù)權重(WOE),一種通過分組處理原始變量的編碼形式。對于第i組,證據(jù)權重的計算如下。

其中(x|X)是分組后本組財報舞弊樣本數(shù)占總財報舞弊樣本數(shù)的比例;(y|Y)是分組后本組財報非舞弊樣本數(shù)占總財報非舞弊樣本數(shù)的比例。因此,證據(jù)權重越大,財報舞弊樣本數(shù)量越多。信息值是通過證據(jù)權重的加權求和計算得來的,其計算如下。
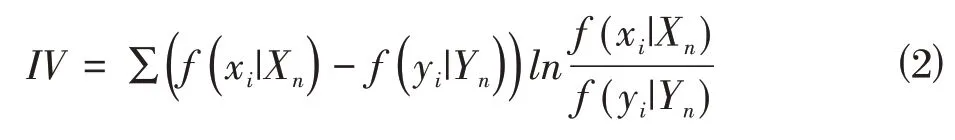
由公式⑵可知,信息值為非負數(shù)。變量的信息值越大,表明該變量對目標分類的預測能力越強。因此,本研究引入信息值構建財務舞弊指標篩選模型,各個初選指標的信息值如圖2所示。
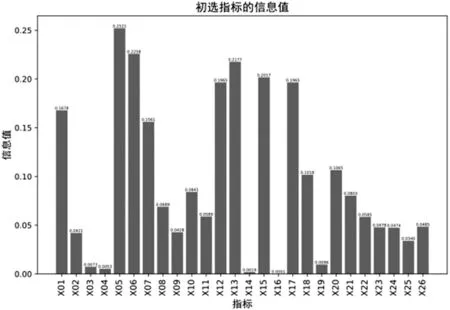
圖2 財務舞弊識別初選指標信息值
信息值大于0.03 為具有預測能力的指標。因此,本研究最終選取了21個指標:流動比率(X01)、速動比率(X02)、存貨周轉(zhuǎn)率(X05)、應付賬款周轉(zhuǎn)率(X06)、應收賬款周轉(zhuǎn)率(X07)、應收賬款與收入比(X08)、總資產(chǎn)周轉(zhuǎn)率(X09)、存貨與收入比(X10)、股東權益周轉(zhuǎn)率(X11)、資產(chǎn)報酬率(X12)、投入資本回報率(X13)、總資產(chǎn)凈利潤率(X15)、長期資本收益率(X17)、總資產(chǎn)增長率(X18)、營業(yè)總收入增長率(X20)、營業(yè)總成本增長率(X21)、每股凈資產(chǎn)增長率(X22)、獨立董事所占比例(X23)、董事會持股比例(X24)、監(jiān)事會持股比例(X25)、十大股東持股比例(X26)。
2.3 XGBoost算法
XGBoost 算法基于梯度提升樹算法,在目標函數(shù)中增添了正則化項,可以降低模型的復雜度,避免過擬合,其目標函數(shù)如公式⑶和公式⑷所示:
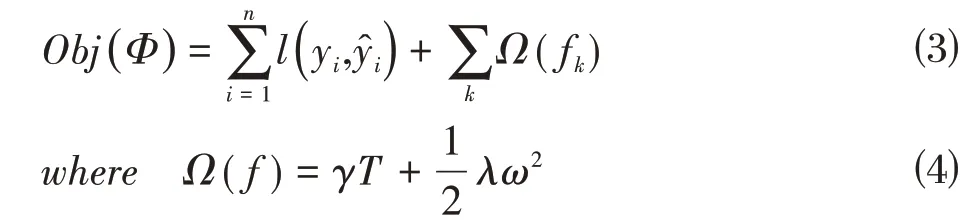
XGBoost算法在目標函數(shù)的求解過程中進行迭代操作以及二階泰勒展開,如公式⑸所示,提高了求解速度和模型的訓練速度。
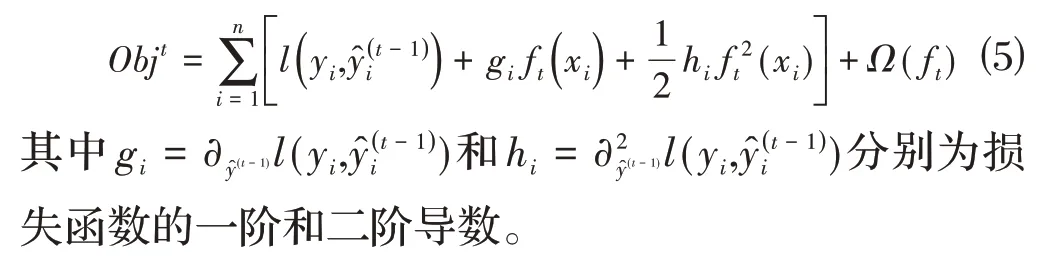
XGBoost 算法提前對特征值進行排序,然后保存為塊結構,所以能夠最大化地確定分割點的標準。此外,為滿足數(shù)據(jù)處理后的特征值是稀疏的情形,XGBoost 算法對缺失值設置一個確定的引流,進而大幅度地提高算法的效率。
2.4 模型構建
本次研究共抽樣849 個數(shù)據(jù)樣本,涉及378 家上市公司,并通過指標篩選模型確定了21 個指標,其中包括17 個財務變量和4 個非財務變量。經(jīng)過數(shù)據(jù)歸一化,使用五折交叉驗證方法將樣本數(shù)據(jù)分為訓練集和測試集,并采用XGBoost 算法作為分類器構建財務報表舞弊識別模型。研究設計流程如圖3所示。
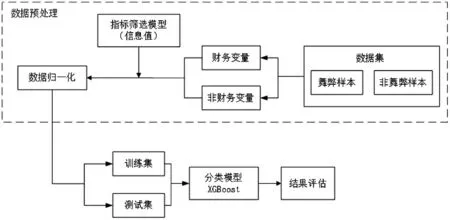
圖3 研究設計流程
3 實驗與分析
3.1 模型參數(shù)設置
利用網(wǎng)格搜索對XGBoost設置參數(shù)如表3所示。

表3 XGBoost參數(shù)設置
3.2 實驗結果
模型在訓練過程中會產(chǎn)生樣本記憶,如果訓練集用于測試會導致測試結果偏高,影響模型的性能。因此,本研究采用五折交叉驗證的模型驗證方法,以提高模型的泛化能力。
本研究使用邏輯回歸、支持向量機、隨機森林三種機器學習算法與XGBoost 算法作為財務報表舞弊識別分類器進行了對比,各機器學習算法分類結果如表4所示。
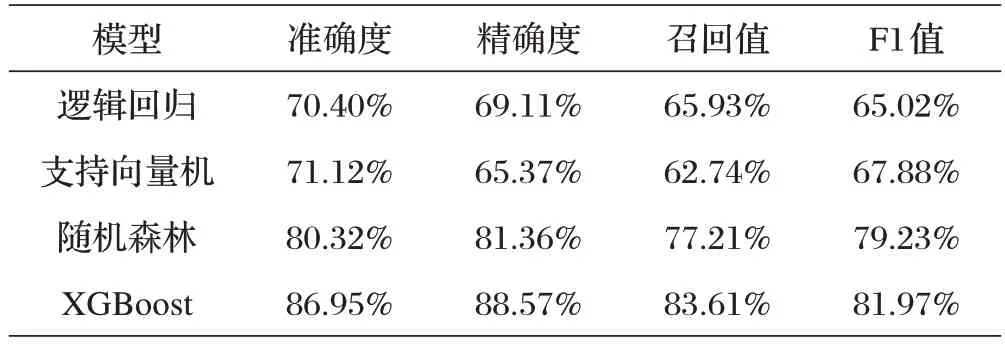
表4 各機器學習算法分類結果評價指標對比
綜合考慮各個評價指標可知,基于XGBoost 算法構建的財務報表舞弊識別模型的預測效果是最好的。
3.3 實驗結果分析
集成學習將多個個體學習器的方差和偏差結合起來,是一個更全面的強監(jiān)督學習算法,能夠獲得更好的性能。所以基于集成學習算法中的隨機森林、XGBoost算法構建的財務報表識別模型的性能顯著高于基于邏輯回歸、支持向量機等個體學習器構建的模型。隨機森林的每個決策樹隨機選擇特征子集,而XGBoost 算法使用貪心算法確定最優(yōu)特征子集,并串行地生成一系列個體學習器,然后使用預測值與真實值之差作為目標函數(shù)來優(yōu)化參數(shù),最終預測值是個體學習器預測值之和。所以,對于不平衡數(shù)據(jù)集,基于XGBoost算法構建的預測模型分類效果更好。
4 結論
本文得出以下結論:①比較多個機器學習算法構建的預測模型,通過實驗證明基于集成學習算法構建的財報舞弊識別模型優(yōu)于個體學習器。②比較同屬于集成學習算法的隨機森林算法和XGBoost算法,通過實驗證明基于XGBoost 算法構建的財報舞弊識別模型的預測能力更佳。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
現(xiàn)代經(jīng)濟信息(2020年34期)2020-06-08 06:02:42
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
遼寧經(jīng)濟(2017年5期)2017-07-12 09:39:47
光學精密工程(2016年6期)2016-11-07 09:07:19
