基于DNN-HMM的佤語語音聲學建模*
2022-08-09 06:16:14賈嘉敏潘文林
計算機時代 2022年8期
關鍵詞:模型
賈嘉敏,程 振,潘文林,王 欣
(1.云南民族大學數學與計算機科學學院,云南 昆明 650500;2.云南民族大學電氣信息工程學院)
0 引言
語言是人類彼此傳遞信息最便捷的工具,更是文化傳承的重要載體。漢語和少數民族語言作為中華民族的文化基石,更是中華民族最為重要的符號象征。隨著經濟的發展和各民族文化的不斷融合,對少數民族語言文化遺產的傳承與保護愈加體現出無可替代的重要性;其中對于跨中緬邊境的少數民族——佤族,為維護邊境穩定、增強國家認同,對其語言的傳承保護則更凸顯重要。相比于語言資源較為豐富的藏語、維吾爾族語等語種,佤語由于缺乏有聲語檔及語料庫資源的建設,其語音識別研究還處于起步階段。
目前,對于佤語的語音識別研究工作中,陳紹雄等在HTK 平臺上實現非特定人的佤語孤立詞語音識別,建立訓練HMM 模型驗證其可行性;和麗華等使用基于多窗譜估計譜減法和能熵比法的語音端點檢測復合算法對佤語語音進行仿真實驗,其準確率為82%;王翠等利用傅里葉變換將佤語轉換為對應的語譜圖信息,將AlexNet 模型用于佤語語譜圖識別,其識別精度達96%。楊建香基于ResNet網絡的佤語語音語譜圖識別率達90.2%,證明其模型系統具有良好的魯棒性。這些工作都獲得了相當不錯的成果,但是這些工作主要是以孤立詞的語譜圖為識別單元進行分類研究,這樣就存在明顯的缺陷,即以孤立詞為識別單元,隨著語料庫規模的不斷擴大,新詞也會不斷出現,在佤語語音識別系統中可能會出現較多的未登錄詞(out of vocabulary,OOV)問題,所以建立覆蓋佤語中所有孤立詞的發音詞典具有一定的難度。同時以數量規模龐大的孤立詞為識別單元的話,模型的復雜度會隨之更高,進而影響模型的識別性能。所以,結合佤語的語音特點,可將孤立詞分解為更小的音素結構,其中佤語僅有214個音素。若以音素作為佤語語音識別系統的識別單元,隨著語料庫規模的擴大,識別單元的數量并不會再增加,可有效解決未登錄詞的問題。故本文在結合佤語語音特點的基礎上,設計基于音素的佤語語音聲學模型。
結合佤語語音的結構特點,本文選取音素作為佤語語音的識別單元,構建深度神經網絡-隱馬爾科夫模型(DNN-HMM)的佤語聲學模型。為提高佤語語音特征的區分度并減少說話人口音對聲學建模的影響,采用線性判別分析(Linear discriminant analysis,LDA)、最大似然線性變換(Maximum likelihood linear transformation,MLLT)和說話人自適應訓練(speaker adaptive training,SAT)對模型輸入的語音特征進行優化訓練,從而提高佤語聲學模型的魯棒性。
1 模型介紹
1.1 深層神經網絡
深層神經網絡(Deep Neural Networks,DNN)是經典的前饋神經網絡之一,主要由輸入層、隱藏層和輸出層三部分構成,DNN的結構如圖1所示。其中,輸入層為輸入的語音聲學特征,中間的隱藏層為多層感知器,其中相鄰層的神經單元以全連接的方式傳送信息,層與層之間的參數則通過誤差反向傳播(Back Propagation,BP)算法進行優化調整。輸出層是一個線性的分類器,使用Softmax 函數對激活值進行歸一化處理,得到聲學的輸出特征和每個神經元對應的概率。由于DNN 擁有更多層的非線性變換器,使其在處理語音聲學特征方面,對語音等復雜信號建模的能力則更強大,優勢更顯著。
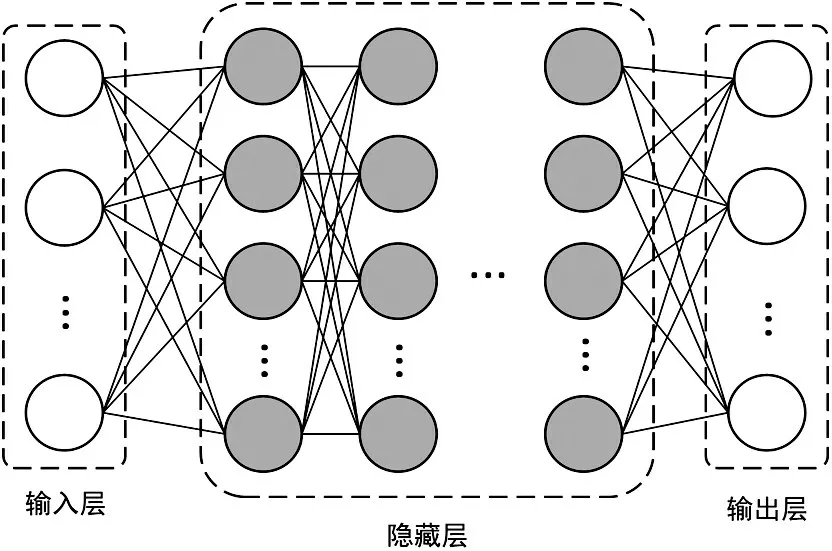
圖1 DNN網絡結構
1.2 DNN-HMM聲學模型
聲學模型是語音識別中最核心的部分,對最終的識別效果起著非常重要的作用。相較于傳統的GMM-HMM 聲學模型,DNN-HMM 模型使用DNN替換GMM 對輸入語音信號的觀測概率進行建模,將相鄰的若干幀進行拼接得到包含更多信息的輸入向量,更有利于利用語音相鄰幀之間的結構信息。并且在訓練過程中DNN會采用隨機優化算法,使得到的聲學模型更精確,更有利于提高語音識別的性能。因此,本文將采用DNN-HMM作為佤語語音識別的聲學模型。
在佤語聲學模型訓練時,由于DNN-HMM 所需的每個孤立詞的音素標記是由GMM-HMM 做強制對齊時得到的,因此在進行DNN-HMM 聲學模型構建時,首先需訓練得到GMM-HMM 模型。而且由于DNNHMM 與GMM-HMM 使用同樣的HMM 模型,所以可將已經訓練好的GMM-HMM 模型中的HMM 遷移到DNN-HMM 模型中的HMM。
DNN-HMM 模型使用內嵌的維特比算法進行訓練,使用40 維的FBank 特征作為基于DNN-HMM 的佤語聲學模型的輸入,標注的音素信息為期望輸出,利用之前訓練好的GMM-HMM 模型,通過強制對齊給每一幀打上HMM 狀態標簽,然后依此標簽訓練DNN 模型參數,得到DNN 模型的softmax 輸出,即HMM 模型對應的觀測概率。但由于DNN 只能給出觀測值輸入到DNN 輸出層之后在每個節點上的后驗概率(q|o),故通過貝葉斯定理進行轉換,得到觀測概率(o|q):
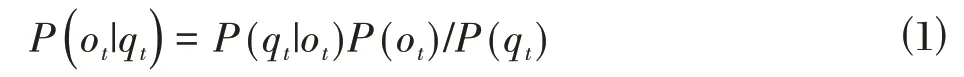
其中,o為輸入語音特征,q為所有三音素狀態的集合,(o)為觀測概率,(q)為各狀態的先驗概率。至此,便完成了基于DNN-HMM 的佤語語音識別聲學模型的構建。一個M隱層的DNN-HMM 結構如圖2所示。
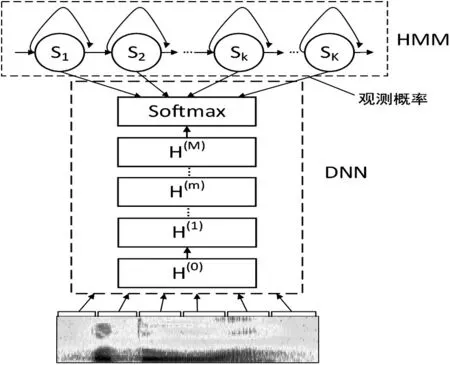
圖2 DNN-HMM模型結構圖
2 佤語語料庫與識別基元的選擇
語音語料庫作為整個語音識別系統的基礎,對于最終的識別性能和識別率具有極其重要的的作用。本文使用的語料庫為在錄音棚由二男二女錄制的1000 個孤立詞(每個詞錄制五遍)共計20000 條語音數據。重復朗讀多遍的目的是使每個音素和三音素出現的次數增多,從而保證每種聲學模型的健壯性。共生成包含214個音素的20000條佤語語音語料。
在本實驗中,設置采樣頻率為16000Hz,采樣精度為16位,聲道為單聲道。對于錄音文件的命名規定為:說話人id_語音id_錄制遍數id.wav。例如:PFA_45_01.wav 表示女性人員(People_Female)中的第一個人(A)錄制第45 條語料的第一遍錄音,PMB_254_04.wav 表示男性人員(People_Man)中的第二個人(B)錄制第254條語料的第四遍錄音。錄制完成后,以人員編號為文件夾分別存放每人的錄音。
佤語屬南亞語系孟高棉語族佤德語支,沒有聲調,人們說話是一個音節一個音節說的,而每個音節由聲母和韻母組成,其中聲母部分由輔音音素構成,韻母部分則由元音音素構成。因此,音素為佤語語音學中最小的發音單元。根據佤語語音的結構特點,本文將選取音素作為佤語語音的識別單元。佤語語音共計214個音素,包含52個聲母和162個韻母,其中單輔音有36個,復輔音有16 個;單元音78個,復元音84個。
由于佤語聲學模型的設計與佤語的發音特點密切相關,若簡單以單音素作為識別單元則容易忽略每個音素所受左右相鄰音素的影響,不能準確的捕捉到音素的發音細節,本文考慮建立上下文相關的三音素模型,整個訓練過程分為單音素模型的訓練和三音素模型的訓練。
3 實驗
本文實驗在Ubuntu20.04 系統上,采用kaldi 開源語音識別平臺進行訓練與測試,同時配置NVIDIA 的GPU 進行加速。實驗主要是在/kaldi-truck/egs/wayu/s5/下進行。佤語語音識別的具體流程如圖3 所示,本文將重點放在聲學模型的訓練及解碼。
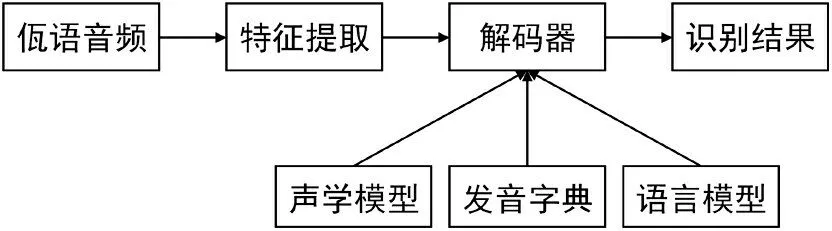
圖3 佤語語音識別流程
3.1 數據準備
本文需識別出完整的佤語孤立詞,對于將被識別的詞,計算機必須有對應的發音規則與標注。為了把詞與其發音一一對應起來,參照《佤漢大詞典》建立語音詞典,生成lexicon.txt、extra_questions.txt、nonsilence_phones.txt、silence_phones.txt 和optional_silence.txt五個文件。對于語音數據,使用kaldi生成聲學模型所需的四個文件:wav.scp、text、utt2spk 和spk2utt。
在佤語聲學模型構建中,為驗證音素為識別單元的有效性,數據集的劃分如下設計:佤語說話者共有4人,選取每個說話人的前900 個詞為訓練集,剩余100個詞為測試集,其中保證前900 個詞覆蓋所需訓練的全部音素。則共計18000 條語料作為模型的訓練集,2000條為測試集。
3.2 佤語語音識別性能評判標準
本文采用詞錯誤率作為佤語語音識別性能的評價標準,其中詞錯誤率的計算方式為:
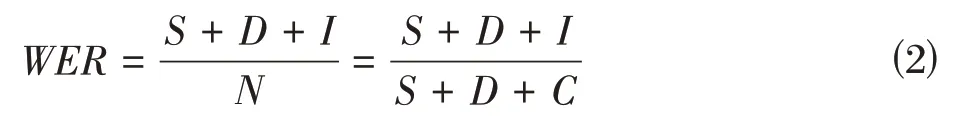
其中,代表被替代詞的數量,代表缺失詞的數量,代表插入詞的數量,代表正確識別的詞的數量,代表語料庫中的總的單詞數。
3.3 基于音素的聲學模型訓練
本文DNN-HMM 模型參數設置為:輸入特征是40維FBank,并且相鄰的幀由11幀窗口連接。DNN模塊由4 個隱藏層組成,每個層有1024 個單元;采用交叉熵的標準訓練,并使用隨機梯度下降(SGD)算法來執行優化。Mini-batch的大小設定為256,初始學習率設定為0.008。具體的聲學模型訓練過程如下。
Step1:對于輸入的佤語語音信號首先開始特征提取,選取MFCC 特征(存儲13 維)作為網絡的輸入,并計算CMVN,存儲每個說話人的均值、方差和幀數。
Step2:接著做語言模型的準備,本文采用的語料以孤立詞為主,故使用基于音素的三元文法(Tri-Gram)模型作為語言模型進行建模,利用SRILM 工具訓練生成phone.3gram.lm。
Step3:然后進行GMM-HMM 聲學模型的訓練,將提取的語音特征作為模型輸入,以單音素作為聲學模型的訓練單元,訓練單音素模型Mono,一共進行40次迭代,每兩次迭代進行一次對齊操作,通過迭代訓練,最后生成模型final.mdl。
Step4:在上一步的基礎上進行三音素模型(Tri1)的訓練,并將數據對齊完成之后,在Tri1模型的基礎上依次進行LDA_MLLT 變換訓練得到模型Tri2,再進行SAT 說話人自適應訓練得到模型Tri3,逐步實現特征參數的優化訓練。
Step5:在Tri3 的基礎上,將GMM 替換為DNN 進行訓練,調整網絡的結構和參數,完成DNN 網絡的訓練,進而實現基于DNN-HMM 佤語聲學模型的構建。
對上述所有得到的模型均做解碼測試(decode),即對每個模型都進行WER 識別評分。其訓練過程如圖4所示。
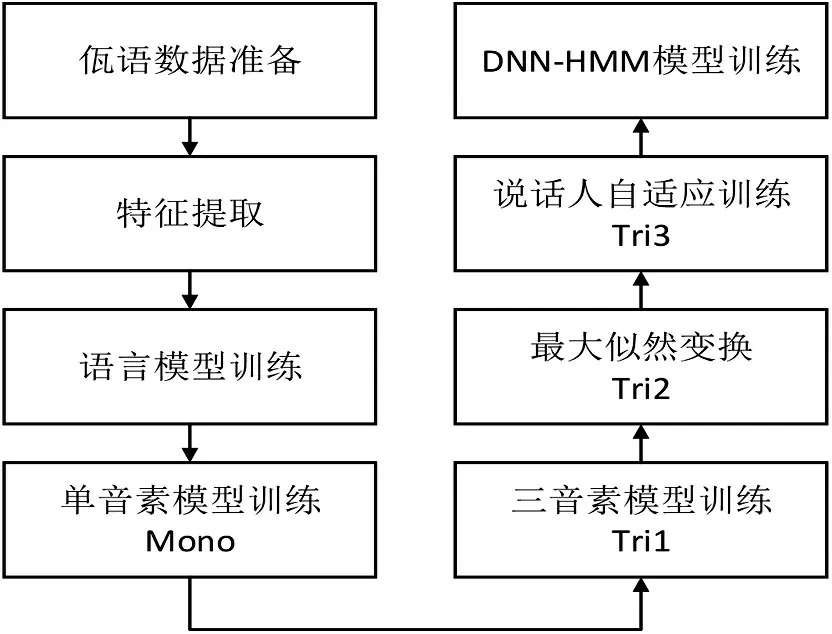
圖4 佤語語音識別模型訓練
3.4 結果分析
3.4.1 不同識別單元對識別性能的影響
為驗證音素作為識別單元的有效性,實驗選取不同的識別單元進行對比實驗,分別以孤立詞和音素作為識別單元。由于實驗數據集以孤立詞為主,不能構建孤立詞的三音子模型,所以以孤立詞的單音子模型和單音素模型(Mono)進行對比實驗,結果如表1所示。從表中可以看出,當孤立詞作為識別單元時,未登錄詞對佤語語音識別性能的影響很大,未登錄詞被系統識別時識別成其他孤立詞,導致詞錯誤率很高。當音素作為識別單元時,詞錯誤率明顯下降,模型識別的性能優勢凸顯。

表1 不同識別單元的識別性能對比
3.4.2 不同聲學模型的對比分析
實驗以音素作為識別單元,嘗試多種聲學模型的優化訓練,并對每種聲學模型分別構建解碼圖,使用decode.sh 以聲學模型和測試數據為輸入計算WER。將DNN-HMM 模型與傳統的基于GMM-HMM 模型的四種聲學模型(Mono、Tri1、Tri2、Tri3)進行實驗對比,比較不同聲學模型的詞錯誤率,結果如表2 所示。從表中可看出,基于DNN-HMM 的聲學模型明顯優于GMM-HMM 模型,詞錯誤率實現29.24%,更適合佤語語音信號的聲學建模。

表2 不同聲學模型的識別性能對比
4 總結
本文針對佤語語音識別聲學模型的構建問題展開研究,提出了基于音素的佤語語音識別的總體框架,建立佤語語料庫,采用FBank語音特征作為聲學模型輸入,利用DNN模型對佤語語音特征進行建模。實驗表明,與GMM-HMM 模型相比,DNN-HMM 更適合聲學建模,詞錯誤率進一步降低,取得了較好的效果。但是,由于目前建立的佤語語料庫規模比較小,識別性能并不夠理想,所以接下來將進一步豐富佤語語音數據規模,擴充佤語句子語料庫,在優化改進聲學模型的同時探究語言模型,以進一步降低佤語詞錯誤率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
