人工智能的法律風險和解決途徑
2022-08-10 10:07:00蔡曉淇付嘉偉田笑宇
法制博覽 2022年24期
蔡曉淇 付嘉偉 田笑宇
東北大學文法學院,遼寧 沈陽 110169
當今社會,人工智能技術高速發展,伴隨著人工智能技術不斷市場化、產品化、普及化,它將漸進地改變人們的生活,也將改變傳統社會的各行各業。但是,萬物皆有兩面性,人工智能技術也是一把雙刃劍,它造福社會,提高整體社會的勞動效率,便捷人們的生活;伴隨著其智能程度的上升,未來可能難以被人類所掌控,會造成許多風險。我們應該正視其好與壞,也應該未雨綢繆,關注它的變化,適時而變,促進其朝向好的方向發展。綜上,我們的當務之急就是要對人工智能進行合理可行、高效的風險評測、防控以及未來用法律的手段去解決它的風險。
一、人工智能技術的法律風險的定義
根據《巴塞爾新資本協議》,法律風險是一種特殊類型的操作風險,包括但不限于因監管措施和民商事糾紛解決而產生的罰款或懲罰性賠償所帶來的風險敞口。在本文章中人工智能技術法律風險的定義為:人工智能技術在飛速發展中,由于弱人工智能在逐漸向強人工智能、超人工智能進化,從而讓人工智能技術徘徊于法律邊界周圍更有甚者超出法律邊界而造成的一系列法律問題,這其中包含著人工智能法律風險發生的可能性及危險性,也包含著這種法律風險導致的不確定性后果。
二、人工智能技術的法律風險的主要形式
(一)侵權責任風險
人工智能技術為了提升自身的發展速度并與此同時不斷完善自己,盡可能減少自身可能產生的錯誤,將人工智能技術市場化、產品化是必由之路。但是,在其市場化、產品化、普及化的過程中,它侵權責任的法律風險則隨之而來,其中有人工智能技術產品自身質量不合格而侵權,也有在使用者層面造成的不當使用而侵權。不同的方式促使著我們必須對其侵權而造成的法律風險進行進一步的分類以便更好地預防。(見表1)

表1 人工智能技術的法律風險的主要形式
1.難以確定人工智能的法律地位
目前我國民法對民事主體的界定為:有獨立的名義,獨立的意志,獨立的財產,包括自然人、法人和其他社會組織。顯然根據民法的定義,人工智能產品不算是民事主體。但是由于人工智能技術有自我學習的特性,會在不斷學習中產生自己的獨立行為,進而難以控制、難以判斷、難以預測。基于此種特性,一個問題擺在我們面前:一旦人工智能產品侵害他人權益時,是否可以用現有的法律地位將其類比為獨立的民事主體,從而承擔應該承擔的侵權責任?
2.難以確定人工智能侵權行為
我國《民法典》規定侵權責任的一般構成要件,即:(1)違法行為;(2)損害事實;(3)因果關系;(4)主觀過錯[1]。因為人工智能的法律地位目前尚未有一個明確的答案,也就不能明確人工智能侵權主體。同時人工智能可以通過后天的不斷學習,擁有獨立決策、獨立行為的能力,不能判斷其行為的初衷,這也就很難看出是否其行為受到算法設置者的干預。據《民法典》,只擁有違法行為和損害事實,并不能判斷其因果關系和主觀過錯的情況,是不能輕易追究其侵權責任的,也就存在著相對應的法律風險。
3.難以確定人工智能的歸責原則
《民法典》規定的過錯責任以侵權人存在主觀過錯為前提要件[2]。如今,沒有法律承認人工智能可以作為侵權人,即人工智能并未擁有法律意義上的主體地位,所以即使人工智能侵害他人權益也很難套用哪套過錯的責任法案來懲罰人工智能。沒有相對應人工智能的法律規則來審判也是目前的法律風險。
(二)個人信息與個人隱私泄露風險
1.個人信息和隱私數據的不正當收集風險
在現在的大數據時代,人工智能正在不斷地以不正當的手段收集每個上網人的信息和隱私。過去,我們主要通過注冊個人賬戶來以主動的方式被互聯網收集個人信息和隱私數據,現在人工智能的生活化發展讓我們的個人隱私更輕而易舉地被獲取,更甚者是在我們并不在意甚至毫不知情的情況下,人工智能就將我們個人的信息和隱私數據收取了。就像:自動駕駛汽車技術,它從某種程度上可以作為人工智能收集我們的移動地點的工具,這使得私家車這一本為很私人的空間,變成無論去哪里都會被記錄下來的“筆記本”。[3]
2.個人信息和隱私數據的泄露擴散風險
2012年云存儲公司Dropbox泄露幾千萬用戶郵箱賬號信息;2016年全國30個省份約270名的艾滋病患者信息泄露受到不法分子打來的騷擾電話[4]。許多例子告訴我們,我們的個人信息并不安全,也沒有相關的法律來切實地保護我們的利益。這樣的隱私數據都會被大范圍的泄露,我們又如何去談論隱私權呢?我們又怎么去保護我們的個人信息和個人隱私不被泄露呢?
(三)勞動者就業風險
在現在的自然界,能夠比人類更強的也就只能是未來的人工智能科技了。當真正的強人工智能時代到來之時,人類的各行各業也將經歷一次人工智能侵入的大洗牌,人工智能大批量、高質量地涌入勞動力市場必將占據大量勞動力席位,使得勞動力市場的結構大變,從而減少大量原有的工作崗位,引發勞動者大批量失業。
三、人工智能技術的法律風險的解決途徑
(一)侵權責任風險的解決途徑
當我們想要給人工智能侵權行為進行責任劃分時,由于人工智能的智能程度不同決定著其是否能擁有法律意義上的主體地位,就必須針對這進行分類討論、區別對待。
1.弱人工智能:此類人工智能產品只會一味地按照設定好的算法運算,只是輔助人類工作的工具,沒有自主的意識,在這樣的前提條件下,弱人工智能沒有條件去具備法律意義上的主體地位,“也就是說,人類對人工智能的態度還處于人工智能薄弱的階段。大數據雖然在發揮作用,但本質上仍處于工具化階段,與傳統產品并無區別”[5]。正因為這樣,即使這樣的人工智能產品造成了侵權行為,它的設計者、研發者也并不應該承擔相應的責任,而應該判定是否與使用者有關。若有,則使用者承擔主要責任;若無,這應該追究生產方與銷售方的責任。此時各方應遵守“誰的行為誰承擔”的原則。
2.強人工智能和超人工智能:人工智能產品可以通過大量數據的分析、處理與學習,擁有獨立決策、獨立行為的能力,擁有獨立的自我思維和意識。擁有智慧的前提使得其脫離了單純的“物”的范疇。此類人工智能產品應當獲得法律主體地位。此時的區別則是,相比超人工智能,強人工智能的主體地位相對較低。強人工智能侵權時,設計者和研發者負主要責任,使用者更像是“監護人”起到監管的職責。若使用者并無過錯則無需承擔責任。而超人工智能,應具備完全的法律地位,此時對于使用者來說,二者相互獨立。追究過錯時應當追究設計、研發人員,讓他們與人工智能產品共同承擔侵權責任。
(二)個人信息與個人隱私泄露風險的解決途徑
1.明確個人信息與個人隱私的保護范圍
在《民法典》中對隱私權和個人信息的內容分別給予了詳細的規定。個人信息和個人隱私并未被等同,而是對個人信息的定義加以擴展,將這樣的定義明確,能輔助我們更好地保護個人隱私,我們更應該明確它們受保護的范圍。
2.完善個人信息與個人隱私保護的法律體系
如今我們國家并未建立起完善健全的保護個人信息和個人隱私的法律體系。近十年來,國家才一點點地加強對公民個人信息和隱私權保護的重視。國家應該針對時勢,出臺一部針對新時代人工智能等高科技竊取公民個人信息和隱私的劣跡行為。而制定在相關法律中應當著重注意以下方面:完善用戶同意機制[6],即在使用公眾信息目的正當且必要的大前提下,充分告知公眾相關信息使用和用途并得到公眾個人的自愿同意。這也就要求數據控制者必須經過數據擁有者的本人同意才能夠處理其信息。這樣設置能夠給予用戶更多的權利,如知情權、拒絕權等,減少個人信息與個人隱私的泄露風險。
3.提高個人對于自身信息和個人隱私的掌控能力
在人工智能產品化、市場化、普遍化的今天,儲存時間長、收集方式多等詞匯成了個人的信息的標簽,個人的隱私也具有持久性、易得性等特性。為了解決個人信息泄露的問題,可以依靠法律的力量,給予自然人對于自己的個人信息和個人隱私更多的掌控能力,例如:徹底刪除、控制個人信息傳播等。與此同時,當信息所有者在合理合法的前提下行使這種權利,任何人不得干涉與拒絕,這樣可以提高個體對于個人信息和隱私的控制能力和主動防御能力,也可以有效減少人工智能對于個人自身的信息和隱私的控制強度。(見圖1)
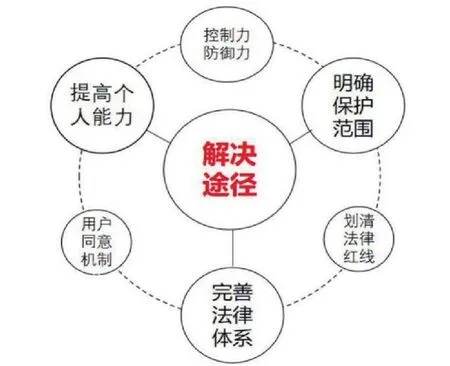
圖1 個人信息與個人隱私泄露風險的解決途徑
(三)勞動者就業風險的解決途徑
人工智能技術不斷涌入勞動力市場,在資本家以利益為前提的視角下,勞動者的劣勢地位會逐漸被放大。故若人工智能大批量、高質量地進入勞動力市場,需要通過法律層面來維護勞動者的利益,著重關心勞動者自身工作的穩定性以及勞動者和資本方的利益和視角的協調。
我們應重塑和諧價值,在從前的勞資關系之中,和諧的價值也僅僅在于不起矛盾,互相體諒,和睦相處。可當人工智能時代到來之后,為了減少人工智能對于勞動者就業方面的法律風險,社會應該重塑出一個新的和諧價值。這個和諧代表著建立勞動者和資本方的協調的利益“命運共同體”。在法律的制定角度,應該將勞動者和資本方當做“和諧”關系的兩端終點,人工智能技術僅僅是二者相互共通、相互合作的工具,給予勞動者足夠的尊重,并不能夠替代勞動者的存在。重塑和諧價值,有助于讓勞資雙方共贏:勞動者通過學習、利用人工智能技術從而更好地服務于資本方,獲得自我價值;資本方可以通過人工智能技術降低成本,更好地獲得勞動者的價值。
四、未來啟示
人工智能的應用對于人類社會是存在于各個方面。例如,日常的信息處理、自動駕駛汽車的進入市場、代替簡單重復勞動的人工智能機器人等。面對這些智能化、創新化的事物,現有的法律體系難以面面俱到,人工智能出現法律風險的可能性很大。這種風險,有人工智能技術對現存法律的挑戰,還有人工智能給社會帶來的不可預測性等。對于我們人類來說,對于人工智能發展的底線就是人工智能的存在應該是服務于人類,當人工智能的行為越過法律的邊界,損傷了人類的利益,那么我們就需要對這種技術進行限制甚至停止使用。
猜你喜歡
法律方法(2022年1期)2022-07-21 09:17:10
西安航空學院學報(2022年2期)2022-07-04 07:45:42
法律方法(2021年3期)2021-03-16 05:57:02
法律方法(2019年3期)2019-09-11 06:27:06
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
南風窗(2016年19期)2016-09-21 16:51:29
南風窗(2016年19期)2016-09-21 04:56:22
山東青年(2016年1期)2016-02-28 14:25:30
