基于手部關鍵點檢測的手勢識別研究
2022-08-12 01:53:30王森寶楊晉驍王子昂李世堯秦娟石艷梅
電腦與電信 2022年5期
王森寶 楊晉驍 王子昂 李世堯 秦娟 石艷梅
(天津理工大學集成電路科學與工程學院,天津 300384)
1 引言
手勢可以表達豐富的含義,廣泛應用于人們日常生活中,隨著機器學習的不斷發展,巧妙利用多媒體機器學習模型應用框架并對其識別算法進行改進是現在手勢識別的一個大趨勢。手勢識別在現代社會中具有廣泛應用,對于AR特效,可以進行短視頻、直播等娛樂交互場景,基于指尖點檢測和指骨關鍵點檢測,可實現手部特效、空間作畫等多種創意玩法,豐富交互體驗;在手勢進行自定義識別的過程中,根據手部骨節坐標信息,可靈活定義業務場景中需要用到的手勢,例如面向智能家電、可穿戴等硬件設備的操控類手勢,面向內容審核場景的特殊手勢等。
在傳統方法中,手勢識別算法通常依賴硬件設備或者基于視覺方法進行識別[1]。Jayashree Pansare 等人創新性地采用網絡攝像機進行實時手勢識別[2],潘志庚等人提出了基于Kinect 和膚色檢測算法結合的手勢識別系統[3],譚臺哲等人采用深度信息與膚色信息結合的方法[4],減少了硬件設備的影響,并且具有更高的魯棒性。此外,James Rwigema等人提出的一種差分進化方法來優化參數[5],但以上基于傳統模型的識別方法或多或少都有著受環境影響大、精度不夠高、識別速度慢等弊端。
針對以上問題,本文基于魯棒預測控制的方法,使用手部關鍵點檢測迭代改進算法,可以盡可能減少復雜環境的影響并實現具有較高精度的快速檢測。該方法采集包括指尖、各節指骨連接處等22個特征點的信息,其中包括精準定位手部的21個主要骨節點描述指尖、各節指骨的坐標信息,以及1個特征點標記圖像采集獲取人手畫面的背景點。通過在標準數據集與自制數據集上進行測試,該算法提高了有效性和精準度。
2 基本原理
2.1 目標選定
在整個識別過程中需要對攝像頭所捕捉到的區域進行信息的提取,只有提取到正確的信息才能進一步判斷,并獲得輸出結果。信息的提取需要確定候選區域。對于候選區域的產生本文采用的方法是選擇性搜索[6]。
2.2 降噪處理
在圖像處理的過程中,當獲取到的手勢信息轉換成可用計算機處理的數字圖像時,其手勢圖像在生成、傳輸或變換過程中會受到各種因素的干擾和影響,其畫質將會因噪聲而在不同程度上出現畸變[7],因此需要先對圖像進行預處理。預處理是對圖像做一些諸如降維、降噪的操作,主要是為后續處理提供一個大小合適的、盡可能去除無用信息的圖像。本文對噪聲的處理是使用魯棒預測控制,進行魯棒預測控制會大幅提高其精準度[8],降低噪聲對獲取圖像的影響,就可以增加部分關鍵點難以檢測出來的手勢圖像,擴充識別手勢庫。
2.3 手勢識別
手勢識別是整體設計中關鍵的一環,手勢識別的方法有很多種,不同的識別方法所建立的模型不盡相同。相對于常見且較為耗時的神經網絡法[9]以及傳統的模板匹配法[10],本文基于手掌二維定位向量法設計手腕定位方法[11],由于正常人的五指指根以及各個關節處到手掌中心之間的距離基本相等,因而可以手腕為原點,定位手腕為原點坐標,通過各個關節與手腕的角度數學運算,對伸直手指個數進行識別;通過角度運算結果進一步確定是哪根手指伸直或彎曲,由此判定相應的手勢信息。此種方法最大的優點是適用性強,可準確識別出多種手勢。
3 基于關鍵點檢測的手勢識別
手勢圖像識別首先采集圖像,其次確定候選框,進而應用關鍵點進行算法識別。
3.1 圖像獲取
由于檢測圖像中存在的物體具有局部區域相似性(顏色、紋理等),所以適當情況下需要進行區域生長(或合并),可以有效提取圖像中信息。使用攝像頭進行圖像采集,常用的方法有滑動窗口[12]與選擇性搜索。其中滑動窗口法是通過對輸入圖像采用不同大小的窗口進行滑動,并采用非極大值抑制的方法進行篩選的全局性搜索算法。但是在本實驗之中,進行手勢識別具有較高的實時性,滑窗法有局限性,所以在此不適用。而選擇性搜索可為物體檢測算法提供候選區域,其速度快,召回率高。產生初始的分割區域,然后使用相似度計算方法合并一些小的區域。通過不斷地迭代,候選區域列表中的區域越來越大,進而完成候選區域的選擇。本文采用選擇性搜索。其算法的具體流程如圖1所示。

圖1 圖像獲取流程
進行相似度的衡量時,算法主要考慮四種相似性度量,取值都在[0,1],值越大就說明越相似。它們分別是顏色相似性scolour(ri,rj)、紋理相似性stexture(ri,rj)、尺寸相似性ssize(ri,rj)和重疊相似性sfill(ri,rj),合并只能在近鄰的兩個區域間進行,遠離的兩個區域不能合并(其中ri,rj分別是候選區域中各點的橫坐標與縱坐標)。
最終相似度的度量總標準是上述四個度量的組合:
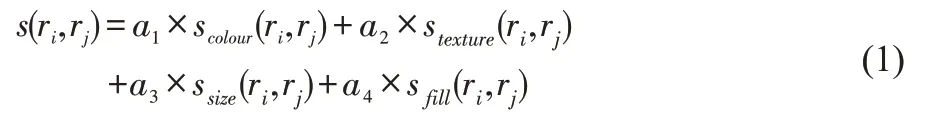
不斷進行區域合并,直至候選區域選擇完畢,獲取候選區域中的圖像。
3.2 基于魯棒預測控制的降噪
根據魯棒性的定義可知,控制系統由于工作狀況變動、外部干擾以及建模誤差,會產生一定的不確定性,精準性模型很難被獲取到。而基于手勢關鍵點的手勢識別對依據關鍵點而判斷出來的彎曲或伸直狀態是尤為重要的。原算法是將采集的圖像送入手部關鍵點檢測器,以得到許多粗略的關鍵點檢測結果,關鍵點的3D 位置被重新投影到2D 圖片,將其和關鍵點結合可以訓練網絡。由于原方法中噪聲的影響降低了手勢圖像的檢測精確度,故本文采取魯棒預測控制,對訓練網絡進行降噪處理。關于有界噪聲問題[13],外部噪聲的線性不確定系統可表示為:

其中xk是系統狀態,xk∈Rn;uk是系統輸入uk∈Rm;ωk是外部噪聲,ωk∈Rr(其中Rn,Rm,Rr是取值空間)在這里外部噪聲大多來源于周圍環境噪聲,值雖然未知但是這里假定有界。
在整個迭代優化過程中,對其進行優化控制處理[14],本文的優化控制使用Min-max方法[15],考慮了由不確定性引起的“最壞”的情況,如果系統能在這種“最壞”的情況下穩定運行,則對于未來發生的任何一種不確定性,系統仍然可以穩定運行。其計算依據:
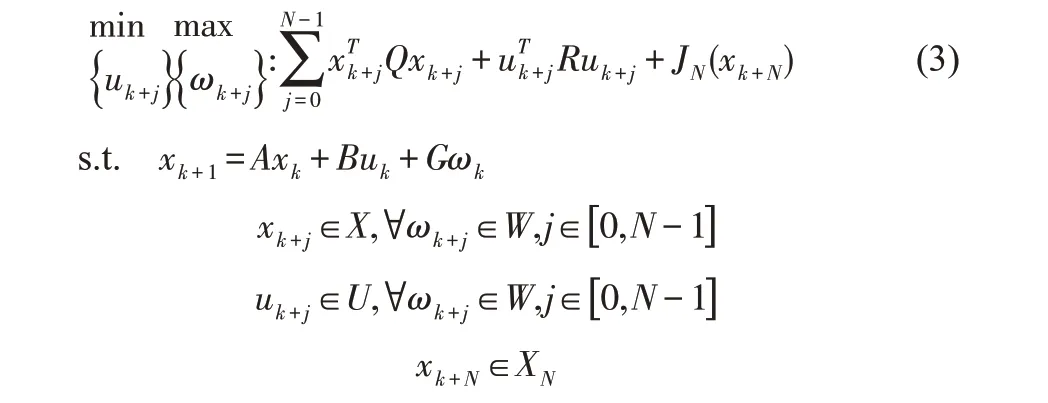
其中xk+N是終端狀態,xk+N∈XN為終端約束條件,JN(xk+N)為終端代價函數,N為預測時域,Q,R分別為相關權重。
可以通過枚舉法得到W的頂點,枚舉法列出所有頂點所要滿足的約束以保證“最壞”情況下約束滿足,但是約束數量會急劇增加,所以在經典控制論中使用閉環回路往往可以實現更好的控制效果[16]。
本文的手勢識別的模型預測采用反饋校正的方法實現閉環回路[17]。反饋的關鍵是利用可測量的系統狀態信息,對原預測系統進行校正。
3.3 手勢分類識別
基于手部關鍵點的手勢分類識別由三個關鍵步驟組成,分別是:獲取二維角度、判斷手指是否彎曲、圖像識別結果輸出。本文以手勢分類識別為主線將其設計的主要思想進行詳細分析,其手勢分類識別的流程如圖2所示。
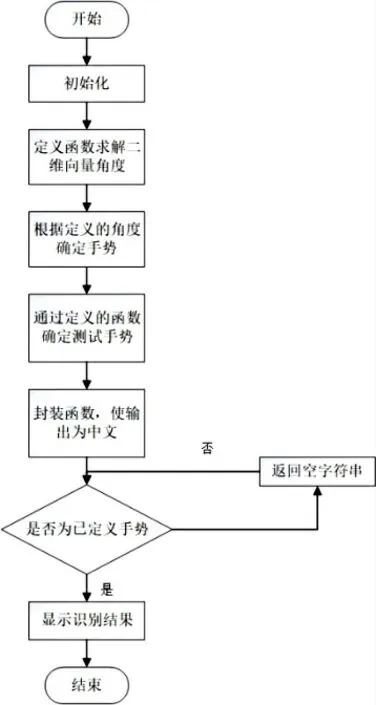
圖2 手勢分類識別流程圖
1962年,Hu首次提出圖像識別的幾何矩理論,并證明了所提出的7個矩對圖像的平移、旋轉和比例變化均保持不變,再根據Hu氏理論,通過各種不同級別的幾何矩的數學組合,得到7個特征量。
在識別中主要采用模板匹配法,將輸入圖像與模板(點、曲線或形狀)匹配,并根據匹配相似性進行分類。坐標距離、點集距離等,輪廓邊緣匹配、彈性圖匹配等都可以用于匹配度計算。模板匹配法的優點是在小樣本的情況下速度非常快,對于光照、背景變化的適應性較好,應用范圍廣,但分類精度不高,可以識別手勢的類型有限,適用于小樣本、形狀變化小等情形。
定義了輸入手勢圖像與10 個模板手勢圖像中任一手勢之間的距離DM。

其中,Gi為輸入手勢的7 個矩特征分量,為模板手勢的Hu矩特征分量,ωi為各特征分量的權值,為了調節特征向量中各矩分量數量級的不一致,在實際實驗中取ωi的值為104、1010、1015、1016。DM即為輸入手勢與模板手勢的特征距距離,DM越小表示越接近識別結果,即找到與輸入手勢特征距離最小的模板手勢,那么這個手勢即為識別結果。
3.4 產生二維向量角度
將手部分為21個關鍵點,如圖3所示。定義21個關鍵點進行二維向量的角度計算,并且計算得到大拇指、食指、中指、無名指、小拇指五個手指的角度。
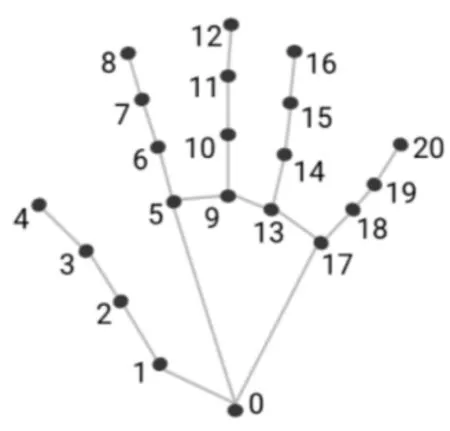
圖3 手部21個關鍵點
其中二維角度計算的具體算法步驟如下:首先設置兩個向量v1,v2并對兩個向量的x,y軸賦予初始值;然后對兩個向量運算后的結果取反余弦弧度值和角度值。再對特定的手指進行相應的維度計算,最后將得到的結果替換第一步中設置的兩個向量的初始值,進行相應的角度求解,從而得到5個手指的相應角度值。
3.5 判斷手指是否彎曲
在識別過程中每一個手指都最多有兩個狀態,也就是彎和直。通過對不同手指是否彎曲進行具體判決,并將五個手指不同的組合方式表達出不同意思。因此,所有可能的情況共計:25=32 種。
經過查閱相關手語資料[18],發現其中有16種組合是絕大多數群體所通用的手勢,經過識別之后在大眾生活中有較高的辨識度,可以進行相對廣泛的應用,表1 列出16 種手勢的中文含義、手指對應彎直狀態。其手勢如圖4所示。
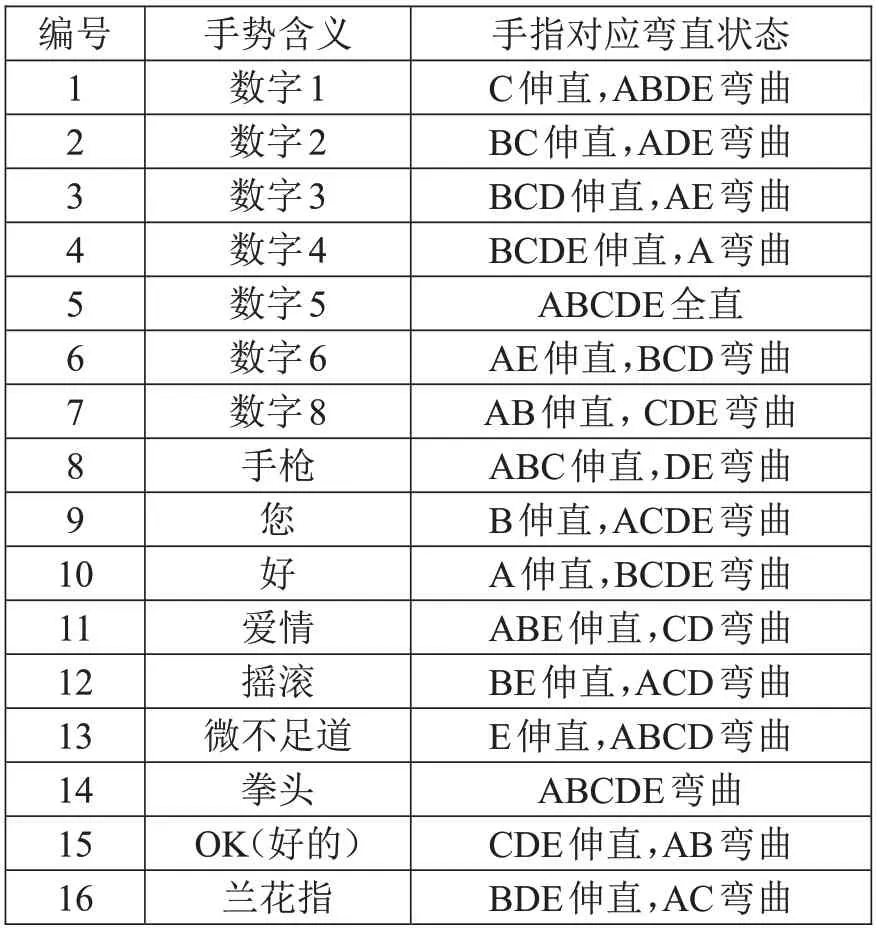
表1 識別手勢匯總表

圖4 手勢識別圖像
判斷是否彎曲,要定義相對應的閾值,超過某個閾值就會判定為改變狀態。
余下16種手指彎直組合,是當前社會中使用不太廣泛、群眾接受度不高的手勢;但是仍然具有識別價值,在人工智能快速發展的背景下,豐富交互體驗顯得尤為重要;在手勢進行自定義識別的過程中,可靈活定義業務場景中需要用到的手勢,并且也可以通過機器認定的某些特性手勢進行一些便捷操作和進程控制。
3.6 圖像識別
使用者在鏡頭前擺出相關的手勢后,算法進行檢測,直到失去對手的跟蹤為止,初始狀態識別像素點上的基本信息,之后對原始圖像點的信息進行綜合處理[19]。
計算機讀取輸入的圖像信息,在每個輸入圖像上運行即進行目標檢測,完成畫面捕捉,將捕捉的BGR格式圖像轉換為RGB 格式圖像。從RGB 格式圖像中提取使用者的手勢,與手勢庫中手勢進行對比,將識別結果返回到窗口,完成圖像識別。
在其中要設置手部檢測的最小置信度值,大于這個數值被認為是成功的檢測,默認為0.5;同時還有目標跟蹤模型的最小置信度值,大于這個數值將被視為已成功跟蹤的手部,這里也默認為0.5。這里采用視頻流的方法來進行圖像結果的輸出。
3.7 實驗結果與分析
本次實驗使用的計算機系統是windows10 運行環境使用PyCharm社區版。
通過對10 名實驗者每個手勢進行30 次識別測試,獲得部分手勢識別結果數據,將數據進行統計與分析計算,獲得所定義手勢的平均識別率。手勢識別結果如表2所示。
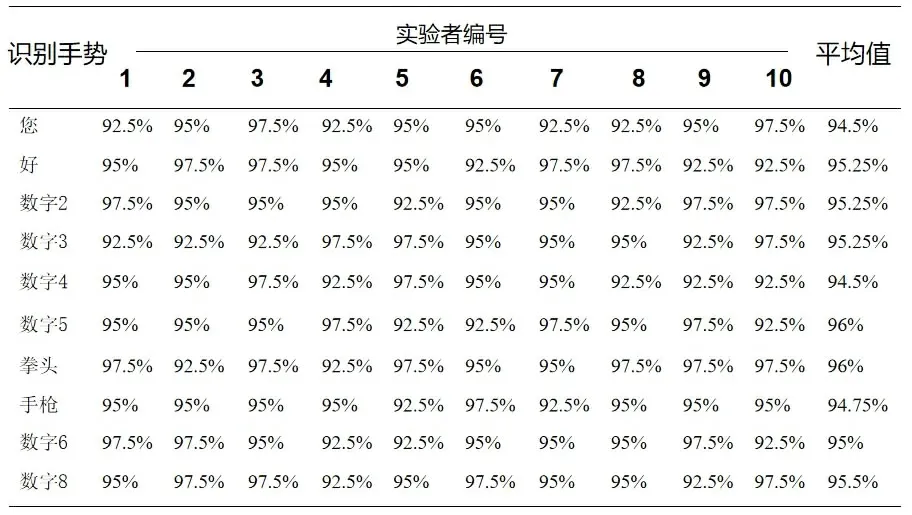
表2 手勢識別結果
文獻[21]基于人體膚色的方法進行的實時手勢識別,在復雜背景下容易跟丟,導致識別不理想。本文所提方法,在實際的環境中手勢識別成功率平均值在94.5%以上,基于手部關鍵點的二維向量角度精準,識別結果可信度高。該方法也存在手勢動作不標準造成識別結果錯誤的缺點。
本文是通過條件判斷組合來實現手勢的定義。在計算手勢角度值時,由于實際的手差異性和角度范圍,導致最終角度計算的誤差,所以無法對手部的細微變化進行檢測。在實驗檢測過程中可能會出現由于角度計算精確度不夠而導致識別錯誤,將會使得多種相近的手勢輸出同樣的結果,從而影響手勢庫的手勢數量,降低了代碼的實用性。
4 結論
本文首先對手勢識別的基本原理進行介紹,之后介紹了手勢識別的基本流程,同時對識別代碼中所涉及的具體手勢進行詳細的介紹。最后通過實驗者進行識別測試實驗,根據實驗數據分析出最終識別效果,以及目前該方法識別失敗的可能原因與局限性。
手勢識別作為機器與人類交互的自然方式,應用廣泛。下一步工作將開展基于深度學習的手勢識別,進一步提高手勢識別的成功率,做硬件移植應用,并在保證成功率的前提下減少高計算成本和運行時間,減少手勢識別的局限性。
猜你喜歡
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
中國衛生(2014年2期)2014-11-12 13:00:16
