面向圖像語義分割的生成對抗網絡模型
2022-08-24 11:18:56竇育民徐廣偉黃晶晶蔡凡凡
無線互聯科技 2022年12期
竇育民,徐廣偉,黃晶晶,蔡凡凡
(1.新鄉醫學院 管理學院,河南 新鄉 453000;2.中國電子科技集團公司第三十研究所,四川 成都 610041)
0 引言
隨著多媒體和網絡技術的快速發展,越來越多的信息以圖像的形式呈現并廣泛應用于醫學、通信、工農業生產、航天、教育、軍事等多個領域。在智能空間視域下有效地組織、查詢與瀏覽大規模的圖像資源已成為迫切需要解決的問題。智能空間可看作是物理世界和信息空間的融合,目的是建立一個以人為中心的計算和通信能力的空間, 讓計算機參與從未涉及的計算行為活動, 讓用戶能與計算機系統發生交互,隨時隨地獲得人性化服務[1-3]。
圖像語義標注是基于內容圖像檢索技術的關鍵環節[4],是一個將現代計算機和機器學習技術應用于傳統人文研究的新型跨學科研究領域,基于圖像的機器學習方法為傳統人文社科研究提供新的研究思路[4-7]。其中大數據的科學發展對人文科學研究有積極的推動作用,現有統計模式識別方法可以發現海量數據中的潛在信息,在總結模式規律方面有出色表現。因此,近年來數字人文研究逐漸成為信息科學、人文社會科學、人工智能等眾多學科的研究熱點。
語義分割是當今計算機視覺領域的關鍵問題之一。宏觀上,語義分割是一項高層次的任務,為實現場景的完整理解鋪平道路。場景理解是一個核心的計算機視覺問題,其中包括自動駕駛、機器人的自動感知、智能監控、人機交互、增強現實等。近年來,隨著深度學習的普及,許多語義分割問題采用深層次的結構解決,最常見的是卷積神經網絡,在精度上遠超其他方法。
語義分割是一項視覺場景理解任務,即一個密集的標記問題,目的是預測輸入圖像中每個像素所屬的類別標簽。卷積神經網絡(CNN)方法是現今最流行的方法,在2009年和2013年,Grangier[9]等人與Farabet[10]等人分別利用CNN完成了這項任務。遵循不同的CNN卷積網絡架構,其共同特點是把圖像分割任務轉化為像素標簽變量的分類任務。
場景理解問題的關鍵是對圖像進行自動語義標注。語義標注的實質是通過對圖像視覺特征的分析提取高層語義用于表示圖像的含義,從而在圖像低層特征和高層語義之間建立聯系,解決低層特征和高層語義間的“鴻溝”問題。其主要思想是從大量圖像樣本中自動學習語義概念模型,并以此標注新的圖像。
1 GAN的基礎架構的闡述
生成對抗網絡(Generative Adversarial Networks,GAN)是一種生成式模型,模型學習的是聯合概率分布P(X,Y) ,學習任務是得到屬性為X且類別為Y時的聯合概率。根據零和博弈原理,一方的收益必然意味著另一方的損失,博弈各方的收益和損失相加總和永遠為“零”,雙方不存在合作的可能。在零和博弈中,把目標設為讓對方的最大收益最小化,以使己方達到最優解。
1.1 GAN的條件形式的分割框架
利用一個基于生成對抗網絡的條件生成式模型[11-13],在原模型基礎上,輸入額外的數據作為條件,修改生成器和判別器。在圖像分割數據集上,以分割掩模圖類別標簽為條件,用來場景區域的多類別學習,在輸入圖像相應區域生成圖像場景理解的描述標簽。
Ez~pz(z)[log(1-D(G(z|y)))]
(1)
其中,D:判別器;G:生成器;z:隨機噪聲;data:訓練數據;y:條件輸入。
條件GAN[12-13]在GAN的基礎上增加條件進行的對抗模型。條件GAN的模型結構包括兩個神經網絡,分別是生成器Generator和判別器Discriminator,Discriminator通過對Generator的評判提升模型的鑒別能力,Generator通過對Discriminator的欺騙提升模型的生成能力。其中生成器的目標是學習樣本的數據分布,從而具備生成欺騙判別器樣本的能力;判別器的目標是判斷輸入樣本真偽的概率。這里使用生成器和判別器都由多層感知機實現,整個網絡可以用交替優化生成器和判別器的方式優化目標函數,通過反向傳播算法獲得目標函數更新梯度。
1.2 模型總覽
在生成器和判別器中分別輸入相同條件y,CGAN的網絡相對于原始GAN網絡沒有變化。隨機變量通過輸入生成器網絡產生分布,利用判別器與真實分布進行不斷比較,最終得到與真實分布相似的分布[11-13]。
1.2.1 生成器網絡
U-net 網絡結構最早由 Ronneberger[10]等發表于2015年的MICCAI,逐漸成為大多數醫療影像語義分割的研究基礎。U-net網絡使用全卷積網絡,是一個端到端的分割網絡,包括收縮路徑和擴張路徑兩部分,并且為了防止梯度消失和梯度爆炸引入了跳躍連接的方法(見圖1)。卷積過程中為了減少輸出的離群點,卷積后還加入了BatchNormal,并激活ReLU。整個過程通過圖像特征編碼和解碼完成像素級圖像分割任務。
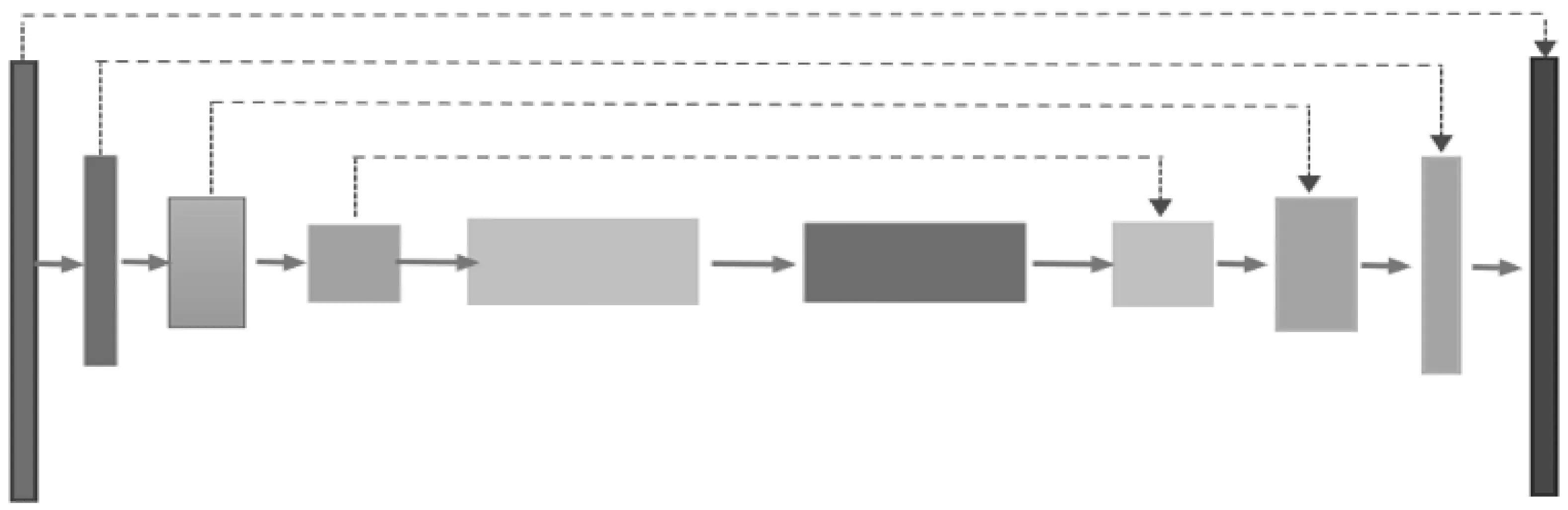
圖1 Unet網絡
在模型收縮路徑的編碼模塊中,使用可分離卷積和點卷積結構替換兩層卷積層[11],由于該結構采用的雙分支結構,融合了不同深度的特征信息,因此提取特征比簡單地疊加卷積層更有效。在下采樣階段采用步長為2的卷積層代替池化層,減少了下采樣過程中信息的損失。在模型對編碼后的特征圖擴張路徑進行的解碼模塊中,上采樣操作使用反卷積,結合跳躍連接的特征圖可有效減少上采樣過程中的信息損失。
生成器是U型網絡,擴張路徑通過跳躍連接串聯對應層進行,通過隨機噪聲作為輸入訓練成生成器模型。
1.2.2 判別器網絡
判別器使用深度神經網絡,可根據需要設計網絡深度,這里設置為5次卷積(見圖2)。第1層輸入圖像為自然圖像和掩膜圖像,分別為3通道,疊加送入網絡;前4次卷積每一層步長stride設置為 2,padding 為1,第5次卷積前再在特征圖左面和上面分別增加一行和一列,再進行一次卷積。除了第1層沒進行規范化外,后面每層對特征數據進行了規范化操作(見表1),實例規范化函數處理過后,再用LeakyRelu激活函數[12-13]。

表1 判別器網絡模型參數

圖2 判別器網絡
由于條件GAN捕獲的是圖像的結構信息,在目標函數后增加正則項L1函數捕獲圖像的低頻信息進行補充。
L1(G)=Ex,y,z[‖y-G(x,z)‖1]
(2)
前4次卷積每一層步長stride設置為 2,padding 為1,第5次卷積前再在特征圖左面和上面分別增加1行和1列,然后再進行1次卷積。
2 實驗設計與分析
本實驗平臺為windows10+pytorch3.5,CPU:Intel?(R)i7-6700HQ@2.60 GHz;內存大 小: 16 GB;GPU:NVIDIA GeForce GTX960M;顯存大小:4 GB。本實驗對圖像語義分割公共數據集ICCV2009[16]進行實驗驗證,包括715張自然圖像,分別取自LabelMe,MSRC,PASCALVOC,and Geometric Context,與自然圖像匹配的標簽文本文件在對應區域的劃分種類標簽。通過圖像像素矩陣形式表示語義類,包括天空、樹、公路、水、建筑、山,前景目標用自然數分別表示,如人、動物、汽車等,負數表示未知。
本實驗使用其中的*.regions.txt類文件,文件內數字表示圖像中語義類每個像素的矩陣分割掩膜圖。模型整體訓練模型分為判別器和生成器,訓練學習中,這里把*.regions.txt轉換為.img進行。
數據準備:因為數據集的標簽掩膜文件以.txt形式存在,利用以下算法把將其轉換為圖像文件。
轉換算法如下:
im = Image.new("RGB",(x,y)) # 新建圖像文件緩沖區
file = open(files[k])# 打開標簽文本文件
for i in range(0,x):
讀取文件第i行像素數字元素
for j in range(0,y):
根據第j列像素值,賦予對應的顏色
寫入文件緩沖區,保存生成一張標簽掩膜圖像文件。
為了增強模型的泛化性能,減少模型訓練學習中的過擬合問題,同時提升訓練數據的數據量和多樣性,采用常規方法對輸入模型的批量訓練數據進行數據增強。其中有隨機裁剪圖像,同時以圖像x軸和y軸的 0.2倍大小、0.7和0.3比率進行隨機平移、縮放圖像。因需輸入圖像使用相同的數據增強方式,所以對標簽也需做相同的數據增強。
參數設置:訓練使用256×256的自然場景圖像和標簽掩膜圖,設置120個 epochs,平滑系數lr為0.000 2。在訓練開始時,G性能較差,D(G(z))接近0,此時:log(1-D(G(z)))的梯度值較小,log(D(G(z)))的梯度值較大,把G的目標改為最大化logD(G(z)),在早期學習中能提供更強的梯度。
如圖3所示,第1和第4行為自然場景圖像,第2和5行為GAN方法預測的語義分割圖,不同顏色代表不同的對象類,第3和第6行為樣本給出的真值掩膜圖。可看出,預測圖基本能給出圖像場景的區域位置和語義類別,可應用在一些有類似樣本圖像的語義標注中。

圖3 第1,4行實景,第2,5行語義分割預測,第3,6行掩膜
3 結語
現代的影像應用需自動推理相關知識或語義。語義分割作為人工智能感知系統的核心問題,對場景理解的重要性日漸突出。自然場景手工標注相當費時,商業成本高。因此,利用CGAN方法進行自動化的語義分割具有廣闊的應用前景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
