基于隨機森林的集成學習入侵檢測方法
2022-08-31 00:54:38盛展陳琳
電腦知識與技術 2022年19期
關鍵詞:機器學習
盛展 陳琳

摘要:為解決網絡入侵檢測效果不佳的問題,提出一種基于隨機森林的集成學習入侵檢測方法。通過K-means和SMOTE處理數據集獲得相關度高的平衡數據子集,隨機森林選擇出最優的特征子集,基于樹的集成學習方法分類結果。本文采用CICIDS2017數據集進行本文方法可行性的研究,結果表明本文提出的方法相比傳統的單一機器學習方法具備更高的檢測精度和更低的時間開銷。
關鍵詞:隨機森林;集成學習;入侵檢測;機器學習
中圖分類號:TP18? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)19-0087-02
1引言
隨著機器學習在入侵檢測的應用,國內外的學者對此進行了大量的研究。如使用KNN[1]、決策樹[2]、隨機森林[3]算法等傳統機器學習算法解決網絡入侵中的異常行為,判斷其中的攻擊特點進行預防和識別。但是傳統的機器學習算法都存在一些缺點:檢測精度低、運行速度慢等問題。文獻[4]提出結合過濾式特征選擇的入侵檢測方法,該方法速度快、計算復雜度低,可以擴展到更高維的數據集。文獻[5]融合特征識別異常行為,通過自回歸模型對網絡流量分類,雖然速度快但是模型精度不夠、容易過擬合。混合不同的特征選擇方案,能有效地解決各個特征選擇的缺點。文獻[6]結合混合過濾式和嵌入式的特征選擇結合集成學習時間開銷更少取得的效果更好,解決傳統特征選擇和機器學習時間精確的弊端。文獻[7]結合混合特征選擇和集成選擇克服了混合特征選擇和單一機器學習算法檢測精度問題和魯棒性低的問題,但由于數據集的不平衡對結果產生一定影響。
綜上所述,針對網絡入侵檢測高維數據集檢測效果不佳的問題,通過提出的隨機森林特征選擇和集成學習方案,相比于傳統機器學習方案,提高了分類檢測的效率,達到了更好的檢測精度。
2網絡入侵檢測模型
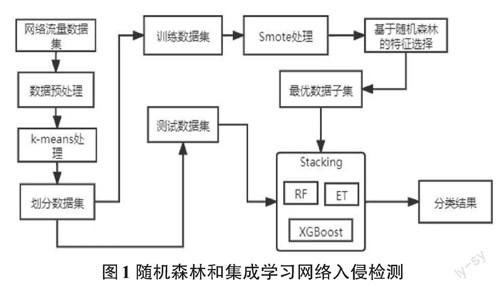
本文網絡入侵檢測模型具體如圖1所示,分為三個階段:數據預處理、特征選擇和集成學習。
2.1數據預處理階段
利用標簽編碼器對網絡流量數據集進行編碼,將分類特征轉換為數字特征,以支持ML算法的輸入。然后利用Z-score算法對網絡數據集進行歸一化后使用K-means聚類抽樣算法對大樣本數據集進行抽樣處理,對數據樣本進行劃分為訓練集和測試集,測試樣本比例為30%。
2.2 混合特征選擇算法
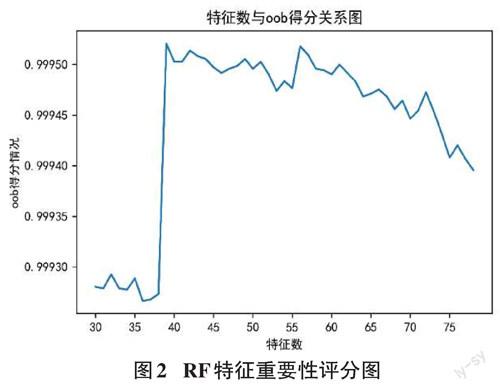
處理好的訓練集使用SMOTE過采樣平衡數據樣本,根據Gini系數和OOB袋外樣本評價指標以去除無關特征。將結果通過隨機森林算法的Gini系數得到初始特征權重比例系數。再通過OOB袋外誤錯率的評價指標,判斷選擇特征的可靠性,得到特征子集。對重要的特征或者被忽略的特征OOB袋外樣本誤錯率,能直觀地反映出該特征的重要性程度具體特征權重如圖2所示,選擇最佳的特征為39。
Smote算法基本思想是改變數據集的平衡性來保持數據分類方法的性能,即通過增加少數類的數據與多數類的數據樣本進行平衡。
[Xnew=X+rand (0,1)*Mi-X,i=1,2,…,N]? ? [(1)]
Gini系數初步評估樣本中各個特征之間的權重關系,并排序特征權重得到初始排序特征集。OOB袋外樣本誤錯率根據每棵決策樹都有一部分的特征沒有納入訓練過程中,將這部分沒納入訓練過程中產生的樣本誤差,叫作袋外樣本誤錯率,用來最終評估特征以獲得最優特征子集。
2.3 集成學習
本文采用基于樹結構集成學習,分為兩層結構。第一層基學習器使用集成學習的ET樹、RF、XGBoost作為本文的基學習器。隨機森林(RF)是選擇決策樹投票率最高的類作為分類結果。極限樹(ET)通過處理數據集的不同子集生成的隨機決策樹集合。XGBoost是通過使用梯度下降法,組合多個決策樹來提高速度和性能。第二層選擇基學習器中精確精度最高的樹模型作為元學習器。通過樹模型訓練的數據,并通過十折交叉驗證貝葉斯優化算法[8]對各個樹模型進行優化操作。在訓練集上實現10倍交叉驗證,以評估模型在新數據集上的性能。選擇上述機器學習算法的原因在于大多數樹結構ML模型使用集成學習,因此它們通常比其他單一模型(如KNN)表現出更好的性能。
3實驗分析
3.1實驗環境
硬件使用環境為1.8GhzCPU,軟件使用環境為Python版本為3.7,sklearn版本為0.22。
3.2實驗評估
本文采用多分類常用的微平均和宏平均估各個機器學習算法的性能要求。當數據不平衡時,微平均和宏平均的差異會較大。微平均根據每個類別的指標計算平均值,宏平均根據是先對每一個類別統計各個指標,然后再對所有類別計算算術平均值。
[Micro_Precision =i=1n TPii=1n TPi+FPiMicro_Recall=i=1n TPii=1n TPi+FNiMicroF1=2×MicroPrecsion×MicroRecall micro P+ micro -R]? ? ? ? ?[(2)]
3.3實驗結果分析
本次實驗選擇比較熱門的KNN,SVM,DT,RF,ET,XGBoost、GBDT機器學習與本文提出的算法進行對比,所提出的算法均用貝葉斯優化算法進行優化。
[ Precision i=TPiTPi+FPi, Macro_P= precision in Recall i=TPiTPi+FPi, Macro_R= Recall inMarcoF1=2× Macro_P×Macro_RMacro_P+Macro_R]? ?[ (3)]
本文提出的算法對比傳統機器學習算法precision提高了1%~30%,召回率提高了2.2%~5.1%,F1提高了2.1%~27.6%。時間開銷上有明顯降低。從實驗結果可以看出,本文提出的方法無論在宏平均和微平均評價指標上都能取得比較滿意的效果,證明本方案的有效性和可行性。
4結論
本文針對入侵檢測的檢測效果不佳提出的隨機森林集成學習入侵檢測模型,解決了傳統入侵檢測精確度低、召回率低、時間開銷大的問題。但該模型還有不足:在特征工程階段初步篩選的評價指標單一,可能對初步篩選特征產生一定影響。
參考文獻:
[1] 盧官宇,田秀霞,張悅.結合KNN和優化特征工程的AMI通信入侵檢測研究[J].華電技術,2021,43(2):1-8.
[2] 唐亮,李飛.基于決策樹的車聯網安全態勢預測模型研究[J].計算機科學,2021,48(S1):514-517.
[3] 周杰英,賀鵬飛,邱榮發,等.融合隨機森林和梯度提升樹的入侵檢測研究[J].軟件學報,2021,32(10):3254-3265.
[4] 胡希文,彭艷兵.基于ONE-ESVM的入侵檢測系統[J].電子設計工程,2021,29(20):86-91.
[5] 孫林,趙婧,徐久成,等.基于鄰域粗糙集和帝王蝶優化的特征選擇算法[J].計算機應用,2022,42(5):1355-1366.
[6] 張玲,張建偉,桑永宣,等.基于隨機森林與人工免疫的入侵檢測算法[J].計算機工程,2020,46(8):146-152.
[7] 艾成豪,高建華,黃子杰.混合特征選擇和集成學習驅動的代碼異味檢測[J/OL].計算機工程:1-11[2021-11-03].https://doi.org/10.19678/j.issn.1000-3428.0062165.
[8] 仉文崗,唐理斌,陳福勇,等.基于4種超參數優化算法及隨機森林模型預測TBM掘進速度[J].應用基礎與工程科學學報,2021,29(5):1186-1200.
收稿日期:2022-02-25
作者簡介:盛展(1997—),湖北孝感人,碩士,研究方向:機器學習與人工智能;通訊作者:陳琳(1972—),男,湖北荊州人,博士研究生,教授,研究方向:網絡與通信、信息安全、智慧城市、網絡應用開發等。
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
