基于深度強化學習的自適應交通信號控制研究
2022-09-01 07:25:42徐建閩周湘鵬首艷芳
重慶交通大學學報(自然科學版) 2022年8期
徐建閩,周湘鵬,首艷芳
(1. 華南理工大學 土木與交通學院,廣東 廣州 510640; 2. 華南理工大學 廣州現代產業技術研究院, 廣東 廣州 510640)
0 引 言
交通信號控制分為定時控制,感應控制和自適應控制,而定時控制和感應控制效率較低,靈活性不強。隨著車聯網和人工智能技術的發展,自適應交通控制逐漸成為了研究熱點。
傳統的自適應交通信號控制方法主要有基于交通流預測的控制方法和基于數學模型的控制方法。郭海鋒等[1]依據歷史交通流量制定了交通狀態-信號周期模板,以預測的交通量為依據調整信號周期和綠信比;徐建閩等[2]先使用K近鄰算法預測短時交通量,然后建立模型求解信號周期,再根據各相位交通狀態、最大綠燈時間確定是否延長相位進行自適應控制。基于交通預測的自適應交通控制算法的控制效果依賴于預測算法的精度且采用的交通信息較為單一,效果有限。目前有多種基于數學模型的自適應控制方法。LI Lubing等[3]使用兩階段法以延誤為優化目標建立優化模型實現隨機需求下的自適應信號控制;Y.LI等[4]采用多目標優化的方法實時優化延誤時間,排隊長度,污染排放。基于數學模型的自適應控制方法結合多種因素對道路信號配時進行分析,但只考慮了當前狀態下的最優控制動作。
強化學習交通控制方法通過探索試錯使信號控制機能作出最大化獎勵值的相位動作以期實現交叉口的最優控制,控制效果往往優于非學習型自適應控制方法。盧守峰等[5]分別對定周期和不定周期模式下的強化學習控制方法進行了研究,并與定時控制方法進行了對比;F.RASHEED等[6]、S.TOUHBI等[7]以排隊長度和當前信號狀態為輸入,并分析了多種自適應控制策略,結果表明,基于深度強化學習的自適應控制方法能取得更低的延誤和排隊長度;A.G.ROAN等[8]使用了一種基于時間差分的強化學習方法,并使用了連續時間馬爾可夫過程進行多路交叉口的信號控制;賴建輝[9]、孫浩等[10]采用高維離散化模型作為輸入,并對強化學習算法進行了改進以研究其收斂性和控制效果。
為了進一步提高交叉口通行效率,并考慮到動作空間的影響,提出了一種改進的D3QN自適應信號控制方法,使用不定步長動作控制模式同時輸出相位和綠燈時間,分析了在穩定流和隨機流場景下的收斂性和控制效果,有效地降低了交叉口延誤時間和排隊長度。
1 系統模型與算法設計
1.1 強化學習交通控制
強化學習交通控制機以ε-greedy規則探索動作(信號機以概率1-ε使用最大Q值對應的相位動作,以概率ε隨機選擇相位),在不斷的探索與試錯中最大化期望獎勵值為:
(1)
式中:rt為時刻t執行相位動作后得到的獎勵值;信號控制機時刻t得到的獎勵值在時刻τ衰減為γτ-trt,其中γ∈[0,1]為衰減系數,由于城市道路交通的高時間關聯性,γ取值為0.95。
控制機通過策略π選擇相位動作,采用相位動作效用函數表示某一時刻交通狀態s下采取動作a獲得的效用值為:
Qπ(s,a)=Ea~π(s)[r+γVπ(s′)]
(2)
式中:s′為狀態s后可能的狀態;Ea~π(s)為策略π下的累計期望;r為狀態s下采取動作a獲得的獎勵值;Vπ(s′)表示交通控制策略π在交通狀態s′下的價值。
而交通狀態s下的估計價值Vπ(s)可根據式(3)求得:
Vπ(s)=Rs+γ∑Pss′Vπ(s′)
(3)
式中:Pss′為從交通狀態s轉移到交通狀態s′的概率;Rs為狀態s下獲得的即時獎勵,通過Bellman方程不斷迭代以優化信號控制策略π。
1.2 改進的D3QN控制方法
由于在線學習的方法會導致嚴重的交通擁堵,通過離線學習訓練得到的模型進行交通控制。首先生成一個隨機初始化交通控制策略π,將檢測到的交叉口狀態輸入到信號控制策略π,策略π輸出下一相位動作,信號燈執行此相位動作后反饋給智能體一個獎勵值以更新策略π,經過多次迭代最終收斂,獲得最優策略π*。一般情況下信號控制策略可由Q表表示,當交叉口交通狀態很復雜時,使用Q表作出相位動作決策會出現維度爆炸的問題,使用神經網絡擬合相位動作效用函數如DQN(深度Q神經網絡)可解決此問題。神經網絡參數為θ,信號控制機在交通狀態s下使用相位動作a的實際價值為y*,Q(s′,a′;θ)為神經網絡θ在交通狀態s下采取相位動作a的估計值,則有:
(4)
式中:a′為狀態s′下采用的動作。
以最小化時序差分誤差δ優化神經網絡參數θ:
δ=y*-Qπ(s,a)
(5)
Li(θ)=Ea~π(s)(δ2)
(6)
為避免Q值過高的估計,將相位動作選擇和相位動作價值的估計解耦,在Double DQN中估計Q值的計算公式為:
(7)
其中θ和θ-分別為原神經網絡和目標神經網絡。
為保證信號控制算法快速收斂,將狀態-價值對作為兩部分輸出。DQN的輸出是相位動作效用函數的值,輸出層的前一層是全聯接層,而Dueling DQN把全聯接層分成兩股,分別估算交通狀態價值Vπ(s)和當前交通狀態下各相位動作優勢值Aπ(s,a),所以相位動作效用函數為:
Qπ(s,a)=Vπ(s)+Aπ(s,a)
(8)
其中滿足:
(9)
為了解決樣本間的相關性過大的問題,D3QN訓練樣本從經驗池中直接抽取產生,每個樣本被選擇的概率是相等的。但這種采樣方式無法區分樣本的重要性,導致一些重要的信息得不到充分利用,可以通過改進抽樣方法加快算法的訓練效率,采用和樹的方法進行樣本抽取。將時序差分誤差的絕對值|δ|作為優先級值存儲于和樹的葉子節點,然后根據優先級的和與抽樣數獲取抽樣區間數,并在每個區間隨機抽取一個數,從根節點向下搜索對應葉子節點,如此從樣本池抽取到的個體即為訓練樣本。
此外,算法根據ε-greedy策略選擇的動作為策略輸出,信號燈執行完輸出的動作便返回一個獎勵值繼續下一步迭代。為了平衡算法探索與利用之間的關系,筆者采用了一種基于獎勵值序列的自適應探索因子,算法的探索因子依據最近一段連續動作序列獲得的平均獎勵值確定。探索因子ε取值為:
(10)
(11)
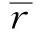
2 強化學習自適應控制策略
為使模型輸入準確地表達交通狀態,輸入狀態向量由兩部分組成。第1部分表示交叉口當前信號燈狀態,為1組one-hot向量。第2部分通過對交叉口各車道進行分段處理以獲得各車道狀態[11]。對于車道x,其長度為l,將其分成k小段,每小段長度為l/k,其中,記車道x第y小段車輛數為ux,y,車道x第y小段的平均車速為vx,y,所以交叉口各車道狀態為(u1,1,v1,1,…,ux,y,vx,y,…,ue,k,ve,k),其中e為交叉口車道數。因此,文中方法狀態向量長度為2ek+|P|,|P|為交叉口相位數。
2.1 強化學習自適應信號控制模式
2.1.1 定周期自適應控制
定周期自適應控制是強化學習自適應控制中的一種模式。該模式計算出最佳周期時間,給定統一的最小綠燈時間和最大綠燈時間,輸入交叉口交通狀態,輸出下一周期的相位方案。定周期控制每隔最佳周期采集一次交通狀態,輸出信號配時方案,但是該模式下動作空間隨著相位的增加而指數級擴大,只適合兩相位的小型交叉口。
2.1.2 固定步長動作控制
給定最小綠燈時間gmin,智能體每隔時間步長Δt對交通狀態進行一次采集作為深度Q神經網絡的輸入,輸出n個動作(對應n個相位)的Q值,選擇最大Q值對應的相位,當選擇的相位與當前運行相位一致時,在當前相位運行時間步長Δt,當選擇的相位與當前運行相位不一致時,運行黃燈時間b秒后在新相位上運行Δt-b秒。然后再次采集環境的狀態值,輸入神經網絡,確定下一時間步長Δt的相位動作。信號機每隔固定時間步長Δt對相位進行一次決策。固定步長動作控制模式中,交通狀態采集間隔受最小綠燈時間gmin約束,Δt滿足約束為:
Δt≥gmin+b
(12)
2.1.3 不定步長動作控制
給定最小綠燈時間gmin,首先根據實用信號周期公式計算最小周期時間為:
(13)
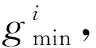
(14)
智能體根據當前輸入的狀態向量輸出下一相位動作at,所以下一相位pt為:
(15)
綠燈時間gpt為:
(16)
在相位pt運行一個綠燈持續時間gpt后,環境將狀態反饋給智能體,獲取下一個相位pt′及綠燈持續時間gpt′。
2.2 獎勵函數
排隊長度是評價交叉口運行效率的一個重要指標,不同于定時控制,在強化學習自適應交通控制中,信號控制機頻繁地切換相位也能降低交叉口的排隊長度,所以在以排隊長度作為獎勵函數時往往需要考慮相位的切換。以各相位對應車道的最大空間占有率之和為優化目標可以解決此問題,降低交叉口各相位的空間占有率等價于路網流量輸入一定的前提下,使交叉口各相位滯留的車輛最少。基于空間占有率的獎勵函數在t時刻得到的獎勵值Rt為:
(17)
其中:
(18)
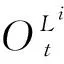
2.3 訓練迭代過程
研究的城市交叉口有4個相位且流量較大,不適合采用定周期自適應控制模式。不定步長動作控制和固定步長動作控制分別對應不同的訓練迭代流程。固定步長動作的訓練迭代流程為:
Step 1總迭代次數為T,初始化當前迭代次數t=0,神經網絡訓練間隔ttrain,目標神經網絡更新間隔ttarget,訓練選取樣本數為batch_size。
Step 2獲取當前交通狀態st,神經網絡輸出各相位對應的Q值,選擇最大Q值對應的相位at。
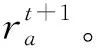
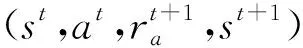
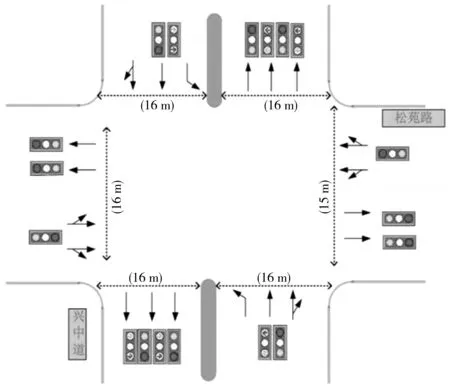
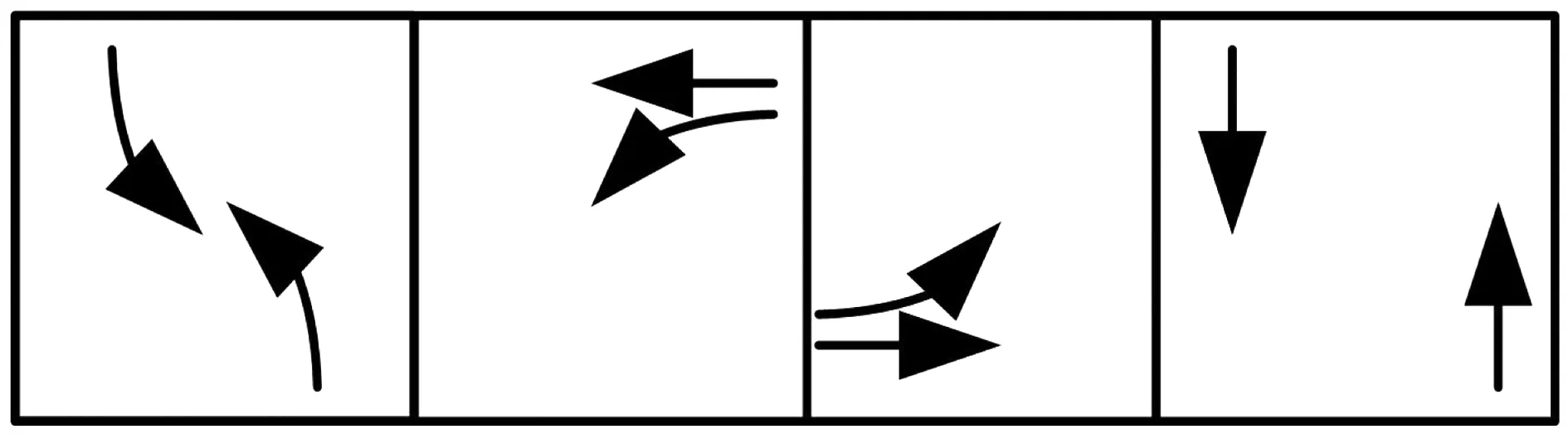
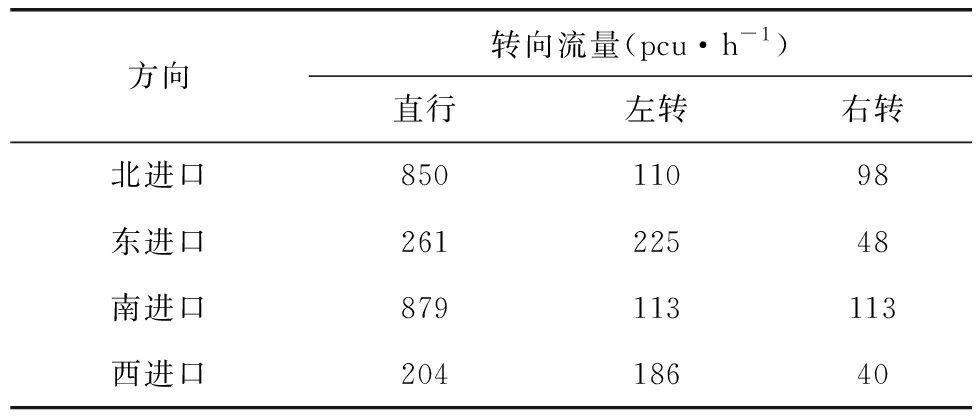
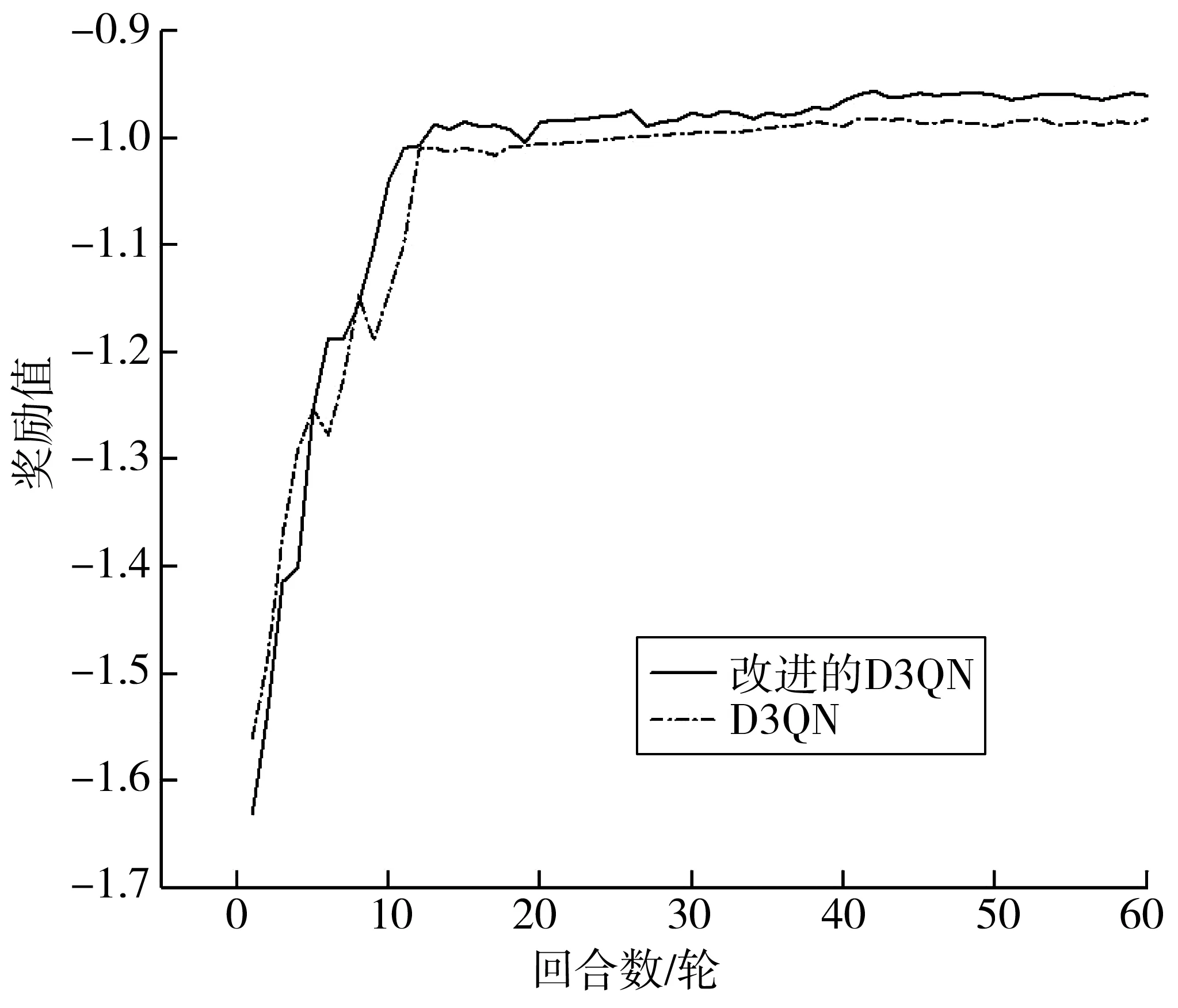
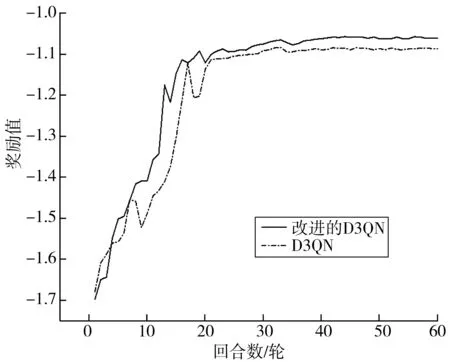
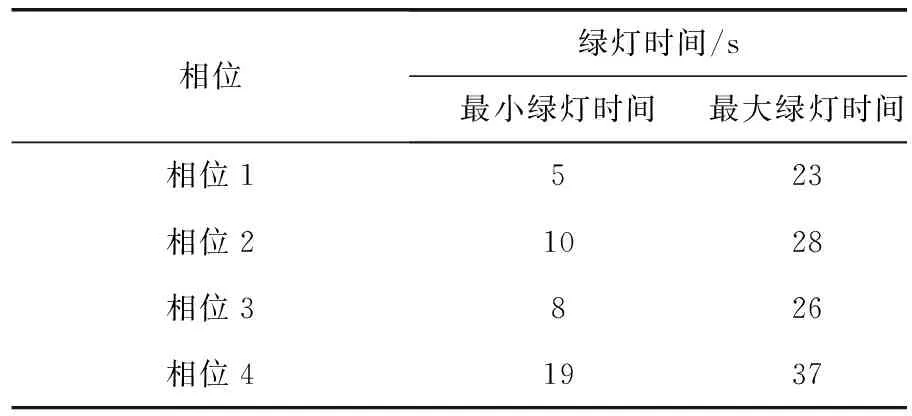
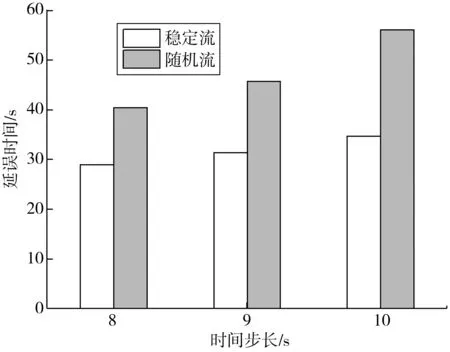
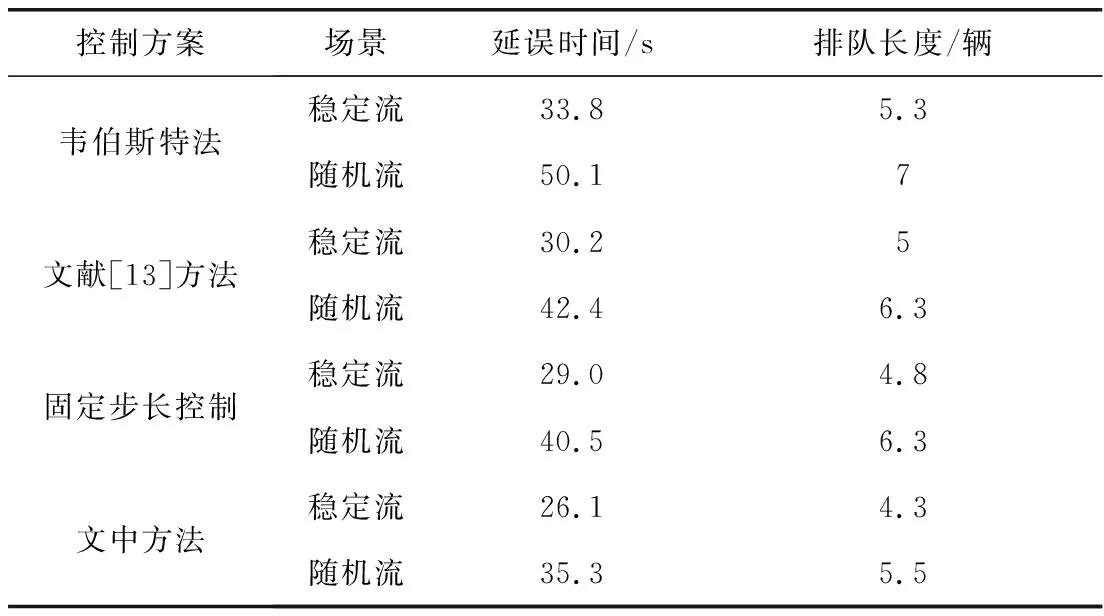
Step 5當t Step 6當t Step 7若t 不定步長動作的訓練迭代流程為: Step 1仿真總時長為M,初始化當前迭代次數t=0,神經網絡訓練間隔ttrain,目標神經網絡更新間隔ttarget。 Step 2獲取當前交通狀態st,神經網絡輸出各相位動作對應的Q值,選擇最大Q值對應的動作at,根據at確定下一相位pt和下一相位綠燈時間gpt。 Step 5當前仿真時間m Step 6當前仿真時間m Step 7若當前仿真時間m Sumo是一個開源的、空間上連續、時間上離散的微觀交通仿真軟件[12],使用Sumo對興中大道與松苑路交叉口(交叉口渠化如圖1)的交通信號控制進行研究,該交叉口一共有4個相位(圖2)。交叉口流量見表1。 圖1 交叉口渠化Fig. 1 Channelization of the intersection 圖2 交叉口相位相序Fig. 2 Phase sequence of the intersection 表1 交叉口流量Table 1 Traffic flow of the intersection 表2 超參數設置Table 2 Hyperparameters setting 分別在穩定流和隨機流的場景下進行仿真訓練,一共仿真訓練60回合,每回合仿真運行25 000 s。其中隨機流服從均值為穩定流交通量的二項分布,各車道每秒以相應概率輸入車輛進行仿真。 為驗證文中方法的收斂性,將筆者方法與原D3QN算法進行收斂性對比,圖3為2種算法在穩定流場景下每回合的獎勵值變化,圖4為2種算法在隨機流場景下每回合的獎勵值變化。從圖4和圖5可知,改進的D3QN算法收斂性優于原D3QN算法。 圖3 穩定流下的獎勵值Fig. 3 Rewards under stable flow 圖4 隨機流下的獎勵值Fig. 4 Rewards under stochastic flow 由于已有的強化學習自適應控制方法多采用固定步長動作模式,在強化學習固定步長動作模式中,時間步長Δt不應過長,考慮到最小綠燈時間,分別取Δt為8、9、10 s,仿真結果圖5表明在固定步長動作控制模式中,時間步長Δt為8 s時控制效果最優,更高的交通狀態采集頻率對應更好的信號控制效果。不定步長動作模式各個相位綠燈時間取值范圍如表3。 表3 各相位綠燈時間取值范圍Table 3 Value range of green light time of each phase 圖5 不同時間步長控制延誤時間Fig. 5 Control delay time with different time steps 為進一步驗證文中方法的效果,將文中方法與韋伯斯特法、固定步長控制、文獻[13]方法進行對比,并使用不同的隨機數種子進行仿真取平均值,采集連續1 h的延誤時間和排隊長度。表4為4種控制方法在穩定流和隨機流場景下的延誤時間和排隊長度,顯然,穩定流場景下的延誤時間和排隊長度均優于隨機流場景。兩種場景中,筆者方法均能獲得最優控制效果,與其他3種方法相比,延誤時間分別平均降低了26.2%、15.2%、11.4%,排隊長度分別平均降低了20.1%、13.3%、11.6%。 表4 控制效果對比Table 4 Comparison of contral effect 提出了一種改進的D3QN自適應交通信號控制方法,使用不定步長動作控制模式同時輸出相位和綠燈時間,構造了以空間占有率為優化目標的獎勵函數。相比于已有方法,文中方法的收斂性得到了提升,延誤時間和排隊長度得到了優化。 此次研究的對象是混合車流在單交叉口的自適應控制,下一步研究可以區域路網為研究對象,綜合自適應控制與綠波協調控制,結合車路協同技術,對路網的交通狀態進行優化并對其進行評價;也可以某一類車輛如公交車輛為研究對象進行公交優先控制以期改善公交信號控制效果,提高城市公共交通運行效率。3 算例分析
3.1 實驗準備
3.2 實驗結果
4 結 語
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16兒童故事畫報(2019年5期)2019-05-26 14:26:14小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49作文評點報·低幼版(2017年7期)2017-03-11 20:49:41Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年7期)2015-08-11 15:03:12少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
