多級本地化差分隱私算法推薦框架
2022-09-03 10:30:08王瀚儀李效光畢文卿陳亞虹李鳳華牛犇
通信學(xué)報 2022年8期
王瀚儀,李效光,畢文卿,陳亞虹,李鳳華,牛犇
(1.中國科學(xué)院信息工程研究所,北京 100093;2.中國科學(xué)院大學(xué)網(wǎng)絡(luò)空間安全學(xué)院,北京 100049;3.西安電子科技大學(xué)網(wǎng)絡(luò)與信息安全學(xué)院,陜西 西安 710071)
0 引言
隨著移動通信技術(shù)的發(fā)展,數(shù)據(jù)的重要性越來越突出,服務(wù)商試圖通過分析用戶的數(shù)據(jù)為用戶提供更加個性化的優(yōu)質(zhì)服務(wù)。然而,隨著互聯(lián)網(wǎng)用戶隱私保護意識的覺醒,以及多個國家相繼出臺隱私保護法案帶來的雙重壓力,如何在保護用戶隱私信息的前提下采集數(shù)據(jù)成為各大互聯(lián)網(wǎng)服務(wù)商刻不容緩的任務(wù)。在學(xué)術(shù)界和工業(yè)界的共同推動下,本地化差分隱私(LDP,local differential privacy)技術(shù)逐漸成為保護用戶隱私數(shù)據(jù)的重要技術(shù)手段之一。LDP 借助其嚴(yán)格的數(shù)學(xué)定義,在不需要可信第三方參與的情形下,抵御任意背景知識的攻擊者,并且通過隱私預(yù)算參數(shù),量化了算法隱私保護的強度,充分滿足了被采集用戶對隱私信息保護的需求;同時,LDP 還能夠在用戶數(shù)據(jù)量充足的條件下,保證統(tǒng)計分析結(jié)果的可用性。
LDP 技術(shù)的研究眾多,各類統(tǒng)計分析任務(wù)下的LDP 技術(shù)層出不窮,然而參與統(tǒng)計分析任務(wù)的用戶均需要采用相同的LDP 保護機制,選取相同的隱私預(yù)算參數(shù),忽略了用戶動態(tài)變化的資源環(huán)境與不同用戶對資源、隱私的個性化需求。
面對現(xiàn)實中移動終端資源的動態(tài)變化與限制,以及用戶對個性化的追求,單一的隱私保護算法不足以支撐用戶的需求。例如,打車服務(wù)商想通過頻繁采集用戶位置打卡信息來選取合適的打車等候站點。一方面,用戶不想泄露自己的位置信息,因此服務(wù)商在信息采集過程中需要為用戶提供隱私保護;另一方面,服務(wù)商希望得到一個比較準(zhǔn)確的統(tǒng)計結(jié)果,因此常用LDP 算法解決這類問題。盡管LDP 有很多不同的機制,但是現(xiàn)有方案中所有用戶必須采用相同的LDP 機制,服務(wù)商才能夠計算出較為準(zhǔn)確的結(jié)果,這種方案固化帶來的問題是一旦用戶設(shè)備資源受限,則會使結(jié)果不準(zhǔn)確或者無法采集該用戶的信息。例如,某用戶手機電量不足,若和其他用戶一樣選擇電量消耗較大的機制,手機很可能直接由于電量耗盡而關(guān)機,無法執(zhí)行任務(wù)也無法正常通信;若所有用戶都選擇電量消耗較小的機制,考慮到消耗小的機制往往可用性較差,因此服務(wù)商計算結(jié)果的可用性就會急劇降低。
為了權(quán)衡用戶對資源、隱私的偏好以及服務(wù)商對可用性的需求,本文設(shè)計了多級LDP 算法推薦框架,考慮到服務(wù)商對統(tǒng)計結(jié)果可用性的要求以及用戶對資源、隱私的個性化需求,通過多級管理為不同用戶推薦不同的但適合當(dāng)前自身資源環(huán)境的LDP 算法,實現(xiàn)多用戶差異化隱私保護。進一步,將框架應(yīng)用至位置服務(wù)中的位置興趣點(PoI,point of interest)頻數(shù)統(tǒng)計任務(wù)中,改進LDP 算法以保證統(tǒng)計結(jié)果的可用性,設(shè)計協(xié)同機制保護用戶的隱私偏好。
本文主要的貢獻如下。
1)設(shè)計一個多級LDP 算法推薦框架,解決LDP 技術(shù)忽略用戶之間差異的問題。從隱私信息全生命周期保護的角度出發(fā),分5 個步驟對用戶信息進行保護。充分考慮用戶對資源、隱私的個性化需求以及服務(wù)商對統(tǒng)計結(jié)果的可用性要求,通過服務(wù)商和用戶對LDP 算法進行選取,既保證了服務(wù)商對用戶的管理,又不限制用戶的個性化需求。
2)將框架落地到PoI 頻數(shù)統(tǒng)計場景中,并將框架具體化。選擇4 種典型頻數(shù)LDP 算法,考慮電量、流量2 個資源因素以及算法的可用性,為用戶推薦當(dāng)前環(huán)境下的最優(yōu)LDP 算法。通過對LDP 機制進行改進,使不同用戶即使采用不同的機制,仍能保證服務(wù)商計算出的統(tǒng)計結(jié)果為真實結(jié)果的無偏估計。在此基礎(chǔ)上,設(shè)計開銷較小的用戶協(xié)同機制,保護用戶的隱私需求。
3)實驗結(jié)果表明,本文方案能夠使資源自適應(yīng)地為用戶推薦個性化的LDP 算法,并且能夠保證統(tǒng)計結(jié)果的可用性。
1 相關(guān)工作
差分隱私(DP,differential privacy)[1]是一個具有嚴(yán)格數(shù)學(xué)定義的隱私保護概念,即任意一條記錄的增加或刪除都不會影響查詢結(jié)果,也就避免了讓攻擊者了解更多的信息。基于此,學(xué)者們提出了多種差分隱私保護技術(shù)。Dwork 等[2]提出了Laplace機制,針對連續(xù)的數(shù)值型查詢結(jié)果添加服從Laplace的噪聲。Mcsherry 等[3]針對非數(shù)值型數(shù)據(jù)的查詢結(jié)果提出了指數(shù)機制,以一定概率從結(jié)果集合中選擇一個結(jié)果輸出。
標(biāo)準(zhǔn)的DP 通過可信的數(shù)據(jù)中心收集用戶數(shù)據(jù),并發(fā)布滿足差分隱私的用戶數(shù)據(jù)統(tǒng)計分析結(jié)果。然而在實際應(yīng)用中,很難找到完全可信的數(shù)據(jù)中心,由此LDP 應(yīng)運而生,其能夠在用戶端執(zhí)行滿足差分隱私的保護機制,同時保證統(tǒng)計結(jié)果的準(zhǔn)確性。按照服務(wù)商的數(shù)據(jù)統(tǒng)計分析的任務(wù)類型不同,LDP 機制主要可以劃分為三類[4]:頻數(shù)統(tǒng)計任務(wù)[5-10]、均值統(tǒng)計任務(wù)[11-12]和復(fù)雜任務(wù)[13-14]。還有一些工作對DP概念中的隱私預(yù)算進行研究,例如在LDP 中為不同用戶分配不同的隱私預(yù)算,或探討如何為DP 算法選擇合適的隱私預(yù)算。
1.1 頻數(shù)統(tǒng)計任務(wù)下的LDP
有多種LDP 機制被設(shè)計用來求取用戶的頻數(shù)結(jié)果,如統(tǒng)計某個年齡段的用戶數(shù)。這些機制或不對數(shù)據(jù)進行編碼處理[5-6],或采用二進制向量[7]、hash 函數(shù)[7,15]、矩陣轉(zhuǎn)換[8]等手段對用戶數(shù)據(jù)進行編碼,并對編碼數(shù)據(jù)或原始數(shù)據(jù)擾動后發(fā)送給服務(wù)商,服務(wù)商再對數(shù)據(jù)進行校準(zhǔn)、聚合,得到頻數(shù)估計結(jié)果。Google 團隊提出了Rappor 算法[16],應(yīng)用隨機應(yīng)答(RR,randomized response)擾動機制,使服務(wù)商能夠在隱藏用戶字段的前提下,從用戶處獲得字段頻數(shù)的統(tǒng)計結(jié)果。
除此之外,還擴展出許多新型頻數(shù)統(tǒng)計任務(wù),例如頻繁項集挖掘[9]、針對key-value 類型數(shù)據(jù)的頻數(shù)估計[10]等。Ye 等[10]提出PrivKV 算法,能夠在滿足LDP 的條件下對key-value 數(shù)據(jù)進行保護,并且保留key 和value 之間的關(guān)聯(lián)關(guān)系;為了提高結(jié)果的準(zhǔn)確度,Ye 等在此基礎(chǔ)上改進算法,對PrivKV進行多次迭代,為了減少網(wǎng)絡(luò)時延,進一步將多次迭代優(yōu)化為虛擬迭代,減少了用戶的參與。
1.2 均值統(tǒng)計任務(wù)下的LDP
均值統(tǒng)計任務(wù)是求取多個用戶數(shù)據(jù)的均值,如求用戶的平均年齡。針對均值統(tǒng)計任務(wù),最基礎(chǔ)的LDP 機制是利用Laplace 機制[2]分別對用戶數(shù)據(jù)添加噪聲。Duchi 等[11]提出了一種適用于多維數(shù)值型數(shù)據(jù)的LDP 機制,其基本思想是利用隨機響應(yīng)技術(shù),根據(jù)一定的概率分布擾動每個用戶的數(shù)據(jù),同時確保均值統(tǒng)計結(jié)果的無偏估計。然而,Nguyên等[12]指出當(dāng)數(shù)據(jù)維數(shù)為偶數(shù)時,Duchi 等的算法并不能滿足LDP 的定義,并對該算法進行了修正,同時提出了Harmony 算法,滿足與Duchi 等的算法相同的隱私保護強度和可用性,但大大減小了算法的通信量。
Wang 等[17]提出了針對一維數(shù)值型數(shù)據(jù)的PM算法,相對Duchi 等的算法而言,統(tǒng)計結(jié)果有著更小的方差,即更好的可用性,同時實現(xiàn)也更加簡易;進一步地,Wang 等基于Harmony 算法將PM 算法擴展至高維數(shù)據(jù),并設(shè)計HM 算法以處理分類型的數(shù)據(jù)。
1.3 復(fù)雜任務(wù)下的LDP
Yilmaz 等[13]提出利用LDP 算法來訓(xùn)練樸素的貝葉斯分類器,首先將每個用戶的標(biāo)簽和取值轉(zhuǎn)化成一個新的值,然后對該值執(zhí)行LDP 機制下的擾動,在保留標(biāo)簽和取值之間關(guān)系的同時,保護用戶的訓(xùn)練數(shù)據(jù)。Mahawage 等[14]改進已有頻數(shù)統(tǒng)計任務(wù)下的LDP 算法,用于控制卷積神經(jīng)網(wǎng)絡(luò)中的隱私泄露,同時提出效用增強隨機化機制,進一步提高隨機化二進制字符串的可用性。Shin 等[15]將LDP機制應(yīng)用到推薦系統(tǒng)中,在用于矩陣分解的梯度下降算法中給梯度添加噪聲,保護用戶在交互過程中的真實梯度不被服務(wù)商獲取,從而保護用戶的真實屬性以及對應(yīng)評分。進一步地,為了減少開銷,Shin等[15]引入降維技術(shù)并提出基于采樣的二元機制,減小算法的開銷,同時在一定參數(shù)范圍內(nèi)也能保證較好的推薦準(zhǔn)確性。Zhao 等[18]將聯(lián)邦學(xué)習(xí)與LDP 相結(jié)合,提出多種LDP 機制,以在保護用戶隱私、降低通信成本的前提下實現(xiàn)機器學(xué)習(xí)模型。
1.4 個性化的LDP
Chen 等[19]首次提出了個性化本地化差分隱私(PLDP,personalized local differential privacy)的概念,并進一步提出了個性化計數(shù)估計協(xié)議,利用用戶組聚類算法將該協(xié)議應(yīng)用于不同隱私級別的用戶。Nie 等[20]提出了一個框架來優(yōu)化直方圖估計,其中利用個性化隱私下的數(shù)據(jù)回收方案擴大估計的樣本量,并證明該框架具有最優(yōu)效用。Xia 等[21]利用本地化差分隱私技術(shù)執(zhí)行k-means 聚類任務(wù),為了提高結(jié)果的可用性,給二進制數(shù)據(jù)的不同比特位分配了不同的隱私預(yù)算,并考慮到不同用戶具有不同的隱私需求,因此設(shè)計不同用戶參與擾動的比特位不同。Shen 等[22]提出了新的PLDP 概念,改進頻數(shù)統(tǒng)計任務(wù)下的OUE 算法,設(shè)計了多維聯(lián)合分布估計方案,為不同維度的數(shù)據(jù)分配不同的隱私預(yù)算,使其比傳統(tǒng)LDP 具有更好的效能。
1.5 DP 隱私預(yù)算參數(shù)選擇
在差分隱私中,隱私預(yù)算參數(shù)ε表示算法的隱私保護程度,ε越小,保護程度就越高。針對如何選取參數(shù)ε的問題,Naldi 等[23]提出了一種基于區(qū)間估算理論的選擇方法,用置信區(qū)間和置信水平2 個參數(shù)來衡量ε。Shahani 等[24]在給定場景下通過權(quán)衡隱私保護和可用性對ε進行選擇,并給出了ε的一個上界。
綜上,LDP 算法可應(yīng)用在多種任務(wù)場景下,種類眾多,且不同LDP 算法在資源開銷、可用性上各有優(yōu)勢,但不同用戶往往采用相同的LDP 算法。并且,盡管隱私預(yù)算參數(shù)的大小決定了算法的隱私保護強度,但少有工作為不同用戶選取不同的隱私預(yù)算。
2 預(yù)備知識
2.1 本地化差分隱私
定義1一個隨機算法M滿足ε-LDP,當(dāng)且僅當(dāng)對于任意2 條不同記錄t,t′∈Domain(M),以及任意y∈Range(M),都有
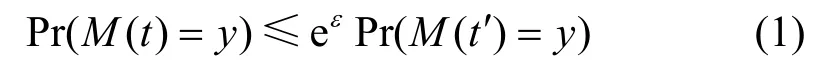
因此,2 個不同的數(shù)據(jù)經(jīng)過隨機算法M擾動后,接收者無法通過收到的數(shù)據(jù)來分辨二者。
2.2 個性化本地化差分隱私
由于不同用戶的隱私需求不同,Chen 等[19]提出PLDP 的概念。PLDP 中包含2 個參數(shù),第一個參數(shù)是安全區(qū)域,即用戶認(rèn)為可以透露的最小區(qū)域τ,例如,該用戶不介意別人知道其所在位置為北京,可以將安全區(qū)域設(shè)置為北京,則用戶希望算法能夠使真實位置與安全區(qū)域內(nèi)的其他位置無法區(qū)分開;第二個參數(shù)是隱私預(yù)算ε,與LDP 中的概念相同,ε表示算法限制攻擊者區(qū)分任意2 個位置的能力大小,ε越小,表示該能力越高,稱(τ,ε)為某特定用戶的隱私規(guī)范。基于此,(τ,ε)-PLDP 的基本概念如下。
定義 2一個隨機算法M對某用戶滿足(τ,ε)-PLDP,當(dāng)且僅當(dāng)對于任意2 個位置t,t′∈τ,以及任意O?Range(M),都有
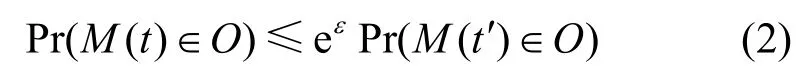
2.3 問題與挑戰(zhàn)
本文旨在解決本地化差分隱私機制各異,但不同用戶往往采用相同的機制和參數(shù),無法根據(jù)用戶當(dāng)前的資源環(huán)境和隱私需求靈活地為用戶提供細粒度的隱私保護的問題。為了實現(xiàn)該目標(biāo),本文需解決以下3 個挑戰(zhàn)。
1)現(xiàn)有LDP 算法為了便于服務(wù)商對擾動后的用戶數(shù)據(jù)進行無偏估計,所有用戶均采用相同的機制和參數(shù)。然而不同LDP 算法在資源開銷、統(tǒng)計分析結(jié)果可用性上各有優(yōu)劣,因此能否結(jié)合不同機制的不同特性,為資源開銷、隱私需求各異且動態(tài)變化的用戶推薦個性化的LDP 算法,并且仍能保證結(jié)果的無偏,是本文面臨的第一個挑戰(zhàn)。2)如何在有限且動態(tài)變化的資源環(huán)境下,為用戶選擇適配當(dāng)前資源環(huán)境的LDP 機制,是本文面臨的第二個挑戰(zhàn)。3)不同用戶對隱私的需求不同,用戶選取的隱私預(yù)算參數(shù)能夠反映用戶對隱私的個性化偏好,若某個用戶對隱私的需求較低,攻擊者可以集中針對該用戶進行攻擊,因此,如何在不泄露該偏好的情況下執(zhí)行方案,是本文面臨的第三個挑戰(zhàn)。
2.4 攻擊模型
本文設(shè)定服務(wù)商和用戶是誠實而好奇的(HBC,honest-but-curious),他們誠實地遵守設(shè)計的方案,但是會試圖根據(jù)已知信息推測其他用戶的更多信息。本文涉及的系統(tǒng)參數(shù)如表1 所示。

表1 系統(tǒng)參數(shù)
3 多級LDP 算法推薦
3.1 算法推薦框架
Li 等[25]提出隱私計算及其框架,該框架從隱私信息全生命周期保護的角度出發(fā),分為隱私信息提取、場景抽象、隱私操作選取、隱私保護方案設(shè)計或選取、隱私保護效果評估5 個步驟。本文基于該框架,設(shè)計了多級LDP 算法推薦框架,分為5 個步驟,圖1 簡要描述了所提框架。
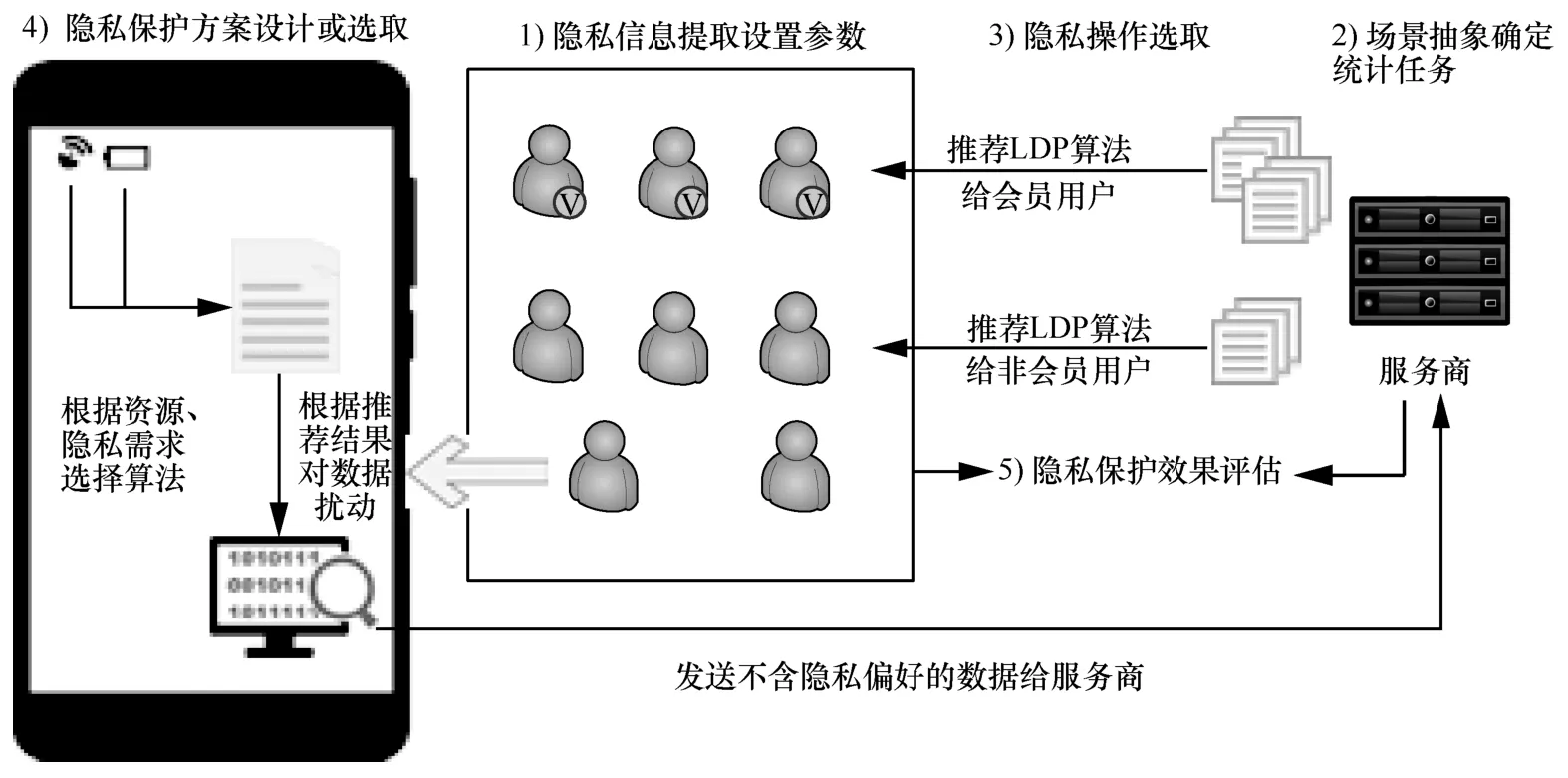
圖1 多級LDP 算法推薦框架
1)隱私信息提取。用戶對服務(wù)商想要采集的信息進行評估,并根據(jù)信息的敏感程度,設(shè)定自己的隱私預(yù)算大小。
2)場景抽象。服務(wù)商通過自身需求確定LDP算法的計算場景,例如,是求取用戶信息的平均值,還是執(zhí)行更復(fù)雜的任務(wù)。
3)隱私操作選取。確定場景后,服務(wù)商確定滿足場景的算法集合ALG;然后,服務(wù)商會根據(jù)用戶的級別,依照策略從所有算法集合ALG 中為每個用戶i選擇一個算法集合 algi?ALG,方便服務(wù)商管控。策略機制可以根據(jù)需求自定義,例如,作為普通用戶 A,服務(wù)商為用戶開放部分算法,即algA?ALG,對資源靈活性要求不高的用戶提供更簡潔的選擇;相反,若用戶B 對資源靈活性要求較高,成為服務(wù)商的會員,那么服務(wù)商會為用戶B 開放所有的算法供用戶選擇,即algB=ALG。
4)隱私保護方案設(shè)計或選取。具體細分為如下4 個步驟。
①服務(wù)商預(yù)處理。為了方便用戶對算法進行選取,服務(wù)商需要先進行預(yù)處理,得到各項資源開銷與影響因素之間的關(guān)系;同時從服務(wù)商自身考慮,也需要將算法的可用性納入影響用戶選取LDP算法的因素中,以便增加統(tǒng)計結(jié)果的可用性。考慮o類資源開銷r1,r2,…,ro,設(shè)定影響LDP 算法資源開銷因素有h個,分別為a1,a2,…,ah。利用實驗擬合集合ALG 中每個算法alg 的各類資源開銷與影響因素之間的關(guān)系,1≤j≤o,alg∈ALG;同時,利用LDP 算法結(jié)果的方差來衡量其可用性,因此可以通過理論推導(dǎo)得到算法alg的可用性rvar與相應(yīng)的影響因素之間的關(guān)系,alg∈ALG。
② 用戶具體算法選取。用戶i定義自身對o類資源開銷的權(quán)重0≤w1,w2,…,wo≤1,權(quán)重越高表示對該類資源的消耗越重視。服務(wù)商統(tǒng)一定義對算法可用性的權(quán)重0≤wvar≤1,同時根據(jù)用戶在當(dāng)前狀態(tài)下影響因素與權(quán)重的取值,利用多目標(biāo)決策方法選擇最優(yōu)算法 algopt∈algi。
③LDP 算法擾動。用戶選取本地化差分隱私個性化隱私預(yù)算εi,利用所選算法對用戶的隱私數(shù)據(jù)datai進行擾動得到 resulti=,再將結(jié)果 resulti在隱藏自身隱私預(yù)算εi的前提下進行校準(zhǔn),并發(fā)給服務(wù)商,其中,用戶對隱私保護強度要求越高,選擇的隱私預(yù)算值就越小,具體選取方法可以參考1.5 節(jié)中的相關(guān)工作。
④服務(wù)商結(jié)果整合。服務(wù)商收到用戶的數(shù)據(jù)后對數(shù)據(jù)進行聚合,得到目標(biāo)結(jié)果R。
5)隱私保護效果評估。由于本文對LDP 算法進行推薦,因此可以用實驗的形式來量化分析方案的偏差性和復(fù)雜性[25]。
3.2 基于位置PoI 頻數(shù)統(tǒng)計的LDP 算法推薦
本節(jié)具體考慮位置PoI 頻數(shù)統(tǒng)計場景下對LDP算法的推薦,由于本文側(cè)重點在于如何推薦LDP算法,因此圖1 中的步驟1)、步驟5)在此部分不作研究。本文框架不僅可以用于頻數(shù)統(tǒng)計任務(wù)的LDP算法,還可以用于其他LDP 算法中,但是,一是由于均值統(tǒng)計算法一般不需要校準(zhǔn),不涉及泄露用戶隱私偏好的情況;二是復(fù)雜類型的LDP 算法一般由均值或頻數(shù)統(tǒng)計任務(wù)演化而來,因此本文以頻數(shù)統(tǒng)計的場景為例進行討論。
3.2.1 方案設(shè)置
根據(jù)PLDP 的定義,用戶i根據(jù)自己的需求選定PoI 集合Di?D,則用戶擾動后的結(jié)果均在集合Di內(nèi)。為方便起見,本文給定Di供用戶選擇,即Di∈,其中?D,因此在傳輸Di時,用戶只需要傳輸一個下標(biāo)即可;同時,用戶根據(jù)隱私偏好選擇隱私預(yù)算εi。
本節(jié)選取了4 種單值頻數(shù)統(tǒng)計的LDP 算法作為算法集合,分別是DE(direct encoding)、OUE(optimized unary encoding)、OLH(optimized local hashing)和THE(thresholding with histogram encoding )[7],即ALG={DE,OUE,OLH,THE}。單值頻數(shù)統(tǒng)計[26]是指每個用戶只發(fā)送一個變量取值給數(shù)據(jù)收集者,數(shù)據(jù)收集者根據(jù)所有用戶上傳的取值統(tǒng)計每一個候選值的頻數(shù)結(jié)果,并進行發(fā)布。本節(jié)選取的4 種算法代表了最典型的LDP 頻數(shù)統(tǒng)計算法,4 種算法分別采用了不同的編碼機制,故產(chǎn)生了有差別的資源消耗。下面,簡單介紹這4 種算法,其中假設(shè)用戶選擇的數(shù)據(jù)擾動范圍集合為D,本地化差分隱私預(yù)算為ε。

本文方案具體分為5 個步驟,分別為服務(wù)商算法集管控、服務(wù)商預(yù)處理、用戶具體算法選取、LDP算法擾動、服務(wù)商結(jié)果整合,具體步驟在3.2.2~3.2.6節(jié)中分別詳細介紹。
3.2.2 服務(wù)商算法集管控
服務(wù)商根據(jù)用戶的級別為用戶推薦不同的算法,在本節(jié)中設(shè)置策略如下:為普通用戶推薦算法DE 和OLH,為會員用戶推薦4 種算法。這里選擇DE 和OLH 是因為DE 在較小時,開銷很小,可用性也不大;OLH 開銷較大,可用性卻相對穩(wěn)定,所以服務(wù)商為用戶提供的算法集可供對靈活性要求不高的用戶使用。記服務(wù)商給用戶i推薦算法集合為algi。
3.2.3 服務(wù)商預(yù)處理


3.2.4 用戶具體算法選取
首先建立用戶對各項資源的權(quán)重,可以根據(jù)用戶偏好主觀地進行設(shè)置,也可以由服務(wù)商建立指導(dǎo)設(shè)置,后期可以根據(jù)用戶需求進行調(diào)整。本節(jié)給出了一種客觀判斷權(quán)重的方案,為用戶提供指導(dǎo):根據(jù)用戶當(dāng)前的剩余電量br(滿電量是100),使用的流量套餐中的剩余流量fr(MB),以及每超出套餐1 MB 需要的價格fp(元),建立用戶本身對電量和流量重視程度的權(quán)重值w1和w2。其中,,當(dāng)手機充電時,用戶不會擔(dān)心電量消耗,因此w1=0;當(dāng)手機連接Wi-Fi 或者剩余流量充足時,用戶不會擔(dān)心流量消耗,因此w2=0;當(dāng)使用流量且剩余流量不足時,令w2=3.33fp(現(xiàn)有流量套餐超出的最高單價為0.3 元/MB)。因此,權(quán)重設(shè)置為

服務(wù)商對可用性的權(quán)重設(shè)置為w3=1。
The Establishment and Structure of the Oirats Karuns of the Upper Three Banners


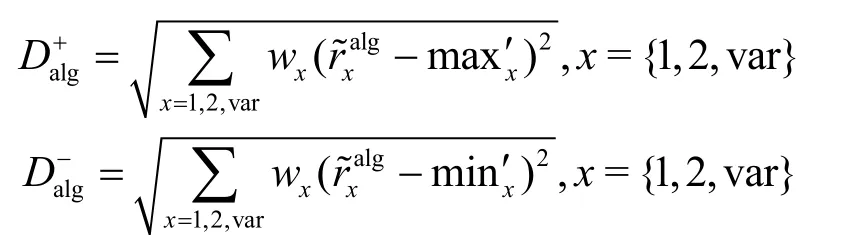
4)推薦算法。評分最高的算法 algopt將作為用戶的推薦結(jié)果。
3.2.5 LDP 算法擾動
用戶使用算法 algopt對原始數(shù)據(jù)dl進行處理。在前述介紹的4 種頻數(shù)統(tǒng)計的LDP 算法中,分別經(jīng)過了在用戶端編碼、擾動和在服務(wù)商端校準(zhǔn)的過程。然而為了保護用戶的隱私預(yù)算εi,需要對原算法進行改進,避免在服務(wù)商端進行校準(zhǔn),為此,本文將校準(zhǔn)過程遷移至用戶端,并設(shè)計后處理算法,防止擾動結(jié)果泄露用戶的隱私偏好。具體操作如下。



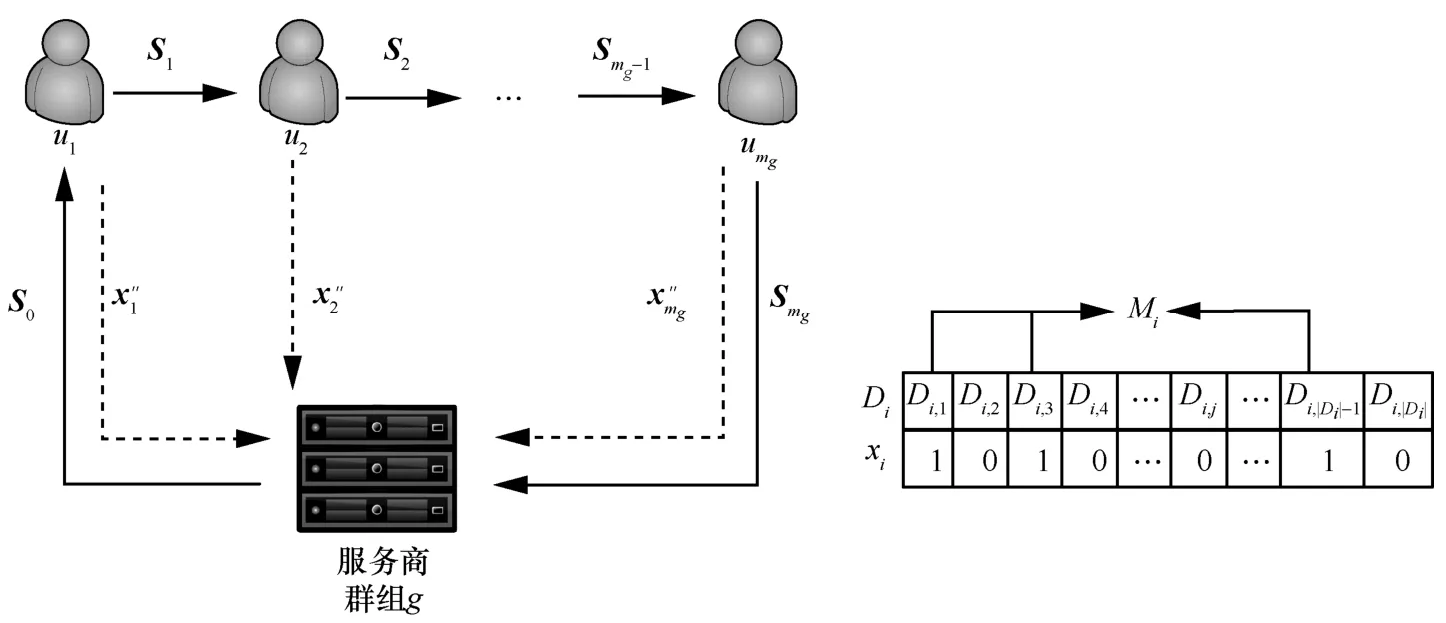
圖2 協(xié)同機制
3.2.6 服務(wù)商結(jié)果整合

3.3 方案證明
定理1本文方案為每個用戶提供了(Di,εi)的個性化本地化差分隱私。
證明由于本地化差分隱私具有后處理的性質(zhì),因此只需證明在3.2.5 節(jié)步驟2)的擾動后,對于?j1,j2∈Di,有Pr(M(j1)=xi)≤eεPr(M(j2)=xi)。

綜上,有 Pr(M(j1)=xi)≤eεPr(M(j2)=xi)不等式成立。證畢。
定理2服務(wù)商對PoIdl的訪問頻數(shù)的統(tǒng)計結(jié)果是真實頻數(shù)統(tǒng)計結(jié)果的無偏估計。
證明真實頻數(shù)統(tǒng)計結(jié)果為
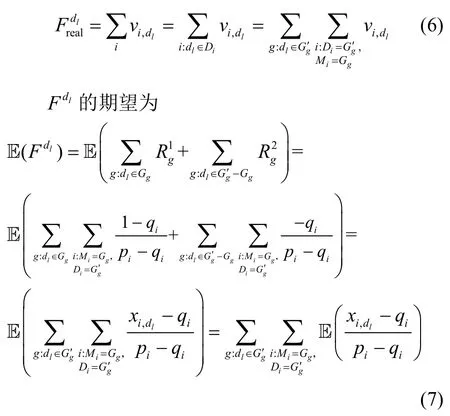
根據(jù)本文算法定義,有
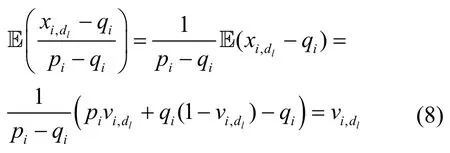
定理3本文方案得到的頻數(shù)估計的方差約為。
證明的方差為
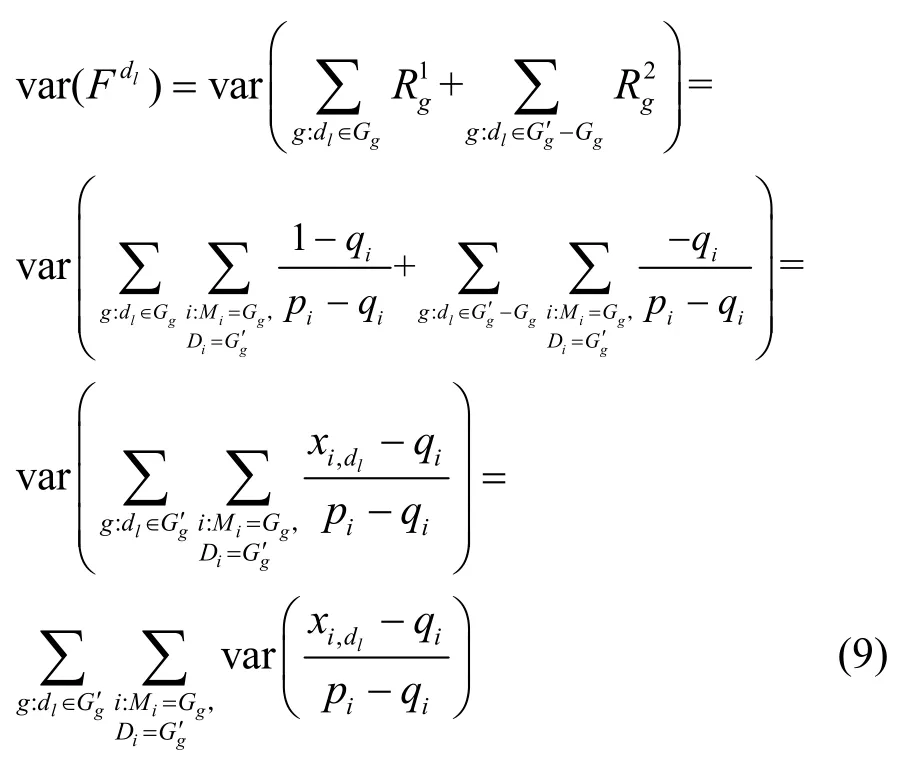
根據(jù)本文算法定義,有

因此有
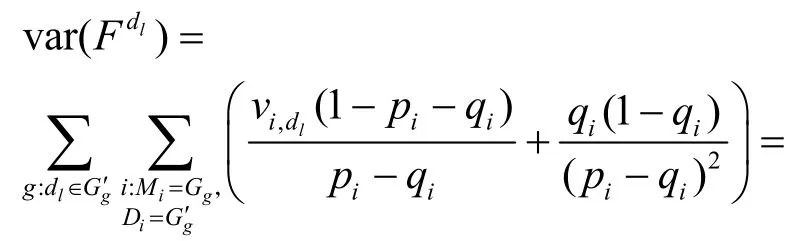

根據(jù)方差公式可以看到,在每個用戶選擇的LDP算法固定的情況下,擾動范圍Di和隱私預(yù)算εi影響了本文方案的可用性。
4 實驗分析
4.1 實驗設(shè)置
本節(jié)參考文獻[25]提出的隱私保護效果評估,從可用性、復(fù)雜度分析的角度對所設(shè)計方案進行衡量。首先,利用實驗擬合出4 種LDP 算法的資源開銷與影響因素的關(guān)系式,并利用LDP 算法理論上的方差來衡量可用性;其次,將表達式代入方案,并觀察用戶處于不同資源場景時的最優(yōu)算法結(jié)果,證明本文方案的可行性;再次,通過調(diào)節(jié)參數(shù),比較本文方案與常見LDP 算法可用性的差異;最后,從理論和實驗上分析本文方案的復(fù)雜度。
為了簡便起見,假設(shè)服務(wù)商給所有用戶都推薦了LDP 的算法全集ALG,且所有用戶擾動范圍集合Di與隱私預(yù)算εi均相同,簡記為D與ε,令集合D的大小為。固定參與統(tǒng)計的用戶人數(shù)為n=10 000,固定THE 中的參數(shù)θ=1。本文執(zhí)行多次實驗,并對實驗結(jié)果求取平均值。
4.2 LDP 算法的資源擬合關(guān)系
本節(jié)中的測試環(huán)境為:硬件設(shè)備為小米MIX 終端,軟件系統(tǒng)為MIUI 10 9.3.28,運行內(nèi)存為6 GB。
為了擬合電量、流量與影響因子之間的關(guān)系,本節(jié)以ε=4 的情況為例,測試L變化時,執(zhí)行1 000 次改進后的DE、OUE、OLH、THE 在電量和流量上的開銷。
從圖3 和圖4 中可以發(fā)現(xiàn),4 種算法的流量和電量均隨著L的增大而增大,趨近于一條直線,利用最小二乘法擬合出4 種算法的流量和電量與L的關(guān)系式,得到
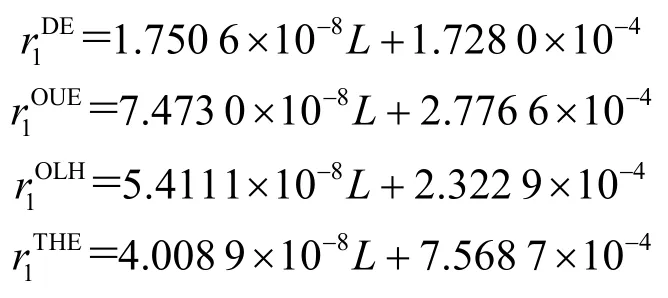
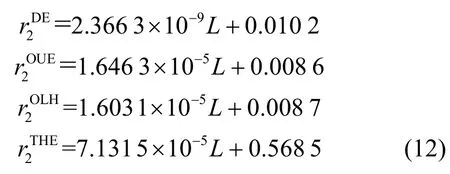
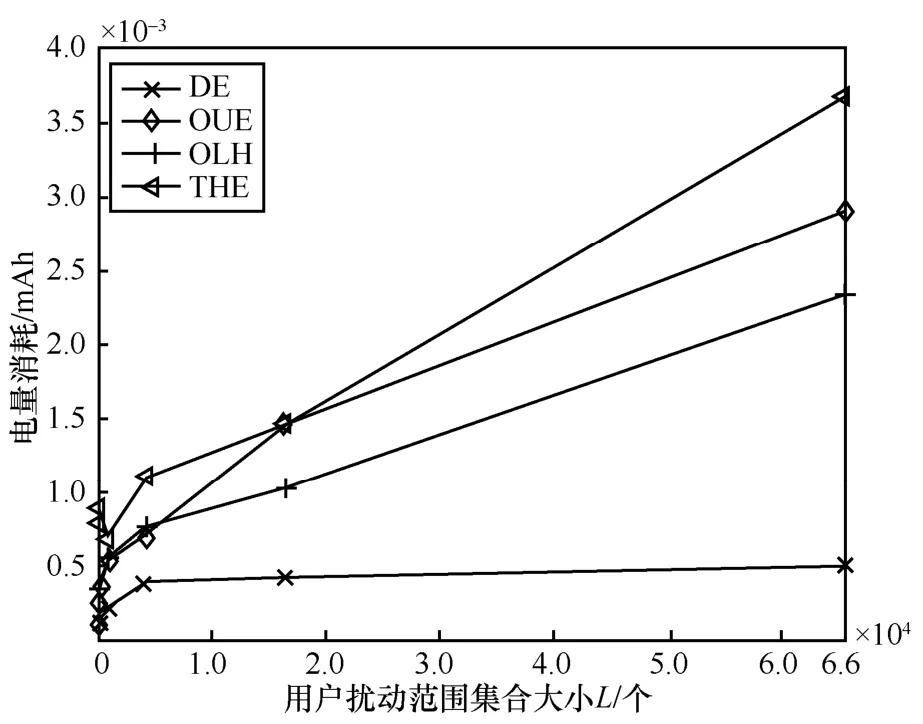
圖3 不同算法電量消耗情況隨L 的變化
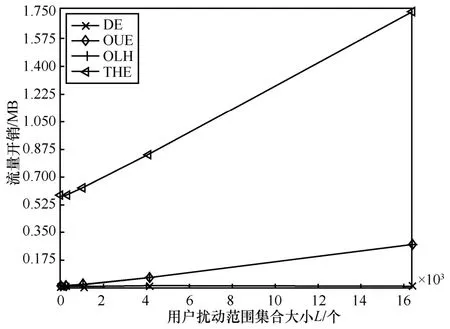
圖4 不同算法流量開銷情況隨L 的變化
對于各種算法的可用性,類似定理3 的證明,當(dāng)ε=4 時,可以得到DE、THE、OUE 和OLH 算法的方差與影響因素的關(guān)系式分別為
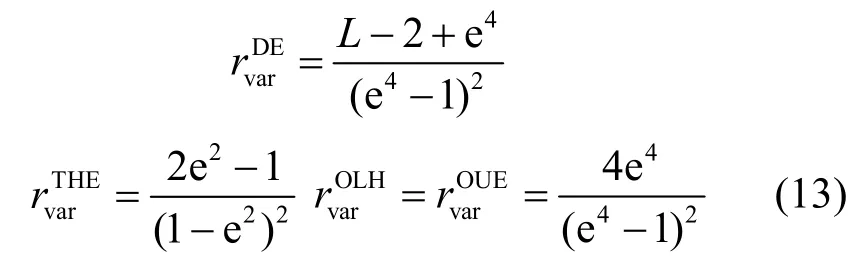
類似地,能得到ε在其他取值下的關(guān)系式,再利用關(guān)系式代入3.2.4 節(jié)的算法選取方案,并觀察用戶在不同狀態(tài)時推薦的最優(yōu)算法,具體結(jié)果如表2所示。

表2 用戶在不同狀態(tài)下的算法推薦
需要說明的是,改進后的THE 算法盡管其可用性比DE 好,但是與其他算法相比開銷較大,不足以成為最優(yōu)算法。因此本文實驗對改進后的THE 算法采用了更高效的傳輸方式,增大其流量開銷,以換取電量開銷的減小,具體傳輸方式為在3.2.5 節(jié)的步驟4)中,用戶要將Mi發(fā)送給服務(wù)商,其他3 種算法會將Mi集合中的多個元素整合成一個字符發(fā)出,而THE 的Mi會以list 的形式發(fā)出,因此THE 的傳輸開銷會更高,但是同時少了整合步驟,因此計算量的消耗會降低,即電量消耗會減小。更新后的THE算法可以視作另一種新型的LDP 算法。由此可以看到,當(dāng)用戶的狀態(tài)發(fā)生變化時,本文方案可以為用戶提供自適應(yīng)的、個性化的算法推薦服務(wù)。
4.3 方案的可用性
本節(jié)采用改進后的DE、OUE、OLH 和THE這4 種算法作為對比方案。考慮在用戶所選擾動范圍集合大小L和隱私預(yù)算ε發(fā)生變化時本文方案與對比方案的可用性。本文利用每個dl的真實頻數(shù)與估計頻數(shù)之間的均方根誤差(RMSE,root mean square error)來衡量方案的可用性。具體計算式為

從式(14)可以看到,可用性越高,RMSE 的值就越小。
實驗假設(shè)4種算法被用戶選擇作為最終方案的概率是相等的,在該前提下,首先固定ε=4,研究L對方案可用性的影響。圖5 展示了本文方案與其他4 種方案可用性區(qū)別與變化趨勢。為了表現(xiàn)L在不同數(shù)量級下方案的可用性,參考文獻[10],采取指數(shù)型的橫坐標(biāo)進行實驗。從圖5 可以看到,當(dāng)L<26時,DE的可用性優(yōu)勢明顯,但當(dāng)L繼續(xù)增大時,DE 可用性變差。而其他3個對比方案的可用性受L的影響不大,OLH 和OUE 的可用性很接近,維持在30 左右,THE的可用性略微差一些,維持在50 左右。本文方案由于受到DE 的影響,可用性隨著L的增大有所減小,但是好于DE 本身,并且在L<210時可用性甚至優(yōu)于THE。這說明本文方案的可用性中和了LDP 算法集中不同算法的可用性,這是因為獨立的多個隨機變量的和的方差等于變量的方差和。
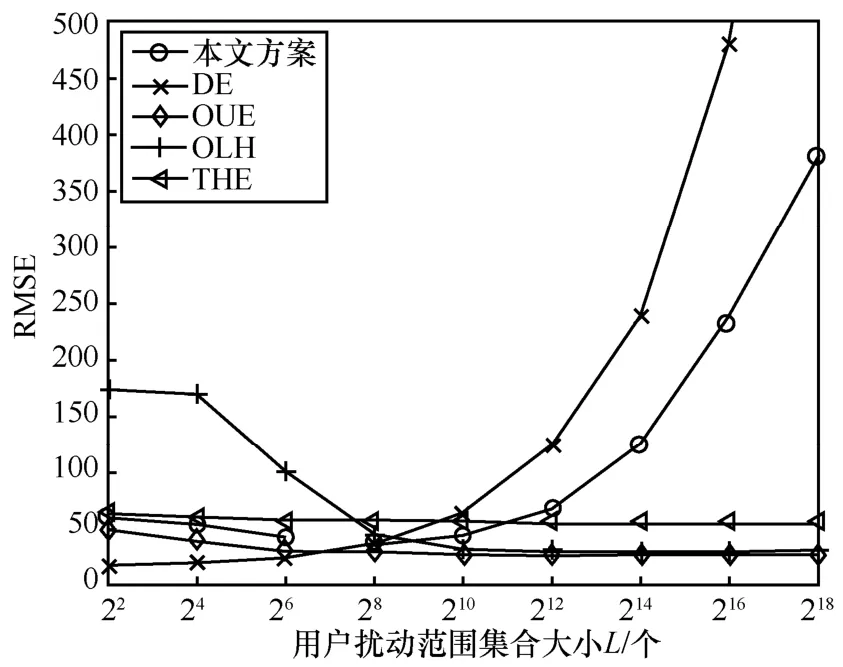
圖5 不同方案在固定ε 下RMSE 的變化
固定L=210,觀察ε對方案可用性的影響,如圖6 所示。從圖6 可以看到,所有方案的可用性都隨著ε的增大而增加。當(dāng)ε較小時,本文方案的可用性要優(yōu)于DE 和OLH 這2 個方案,且隨著ε的增大,本文方案與OLH 和OUE 的可用性逐漸接近,甚至優(yōu)于THE。另外,盡管理論上OUE 與OLH 的可用性是一致的,但是由于在ε較小時,OLH 中參數(shù)很小,即哈希函數(shù)會將1 024 個數(shù)字映射到個數(shù)上,使碰撞較大,從而影響了OLH 的可用性;而當(dāng)ε增大時,這二者的可用性又恢復(fù)了一致。
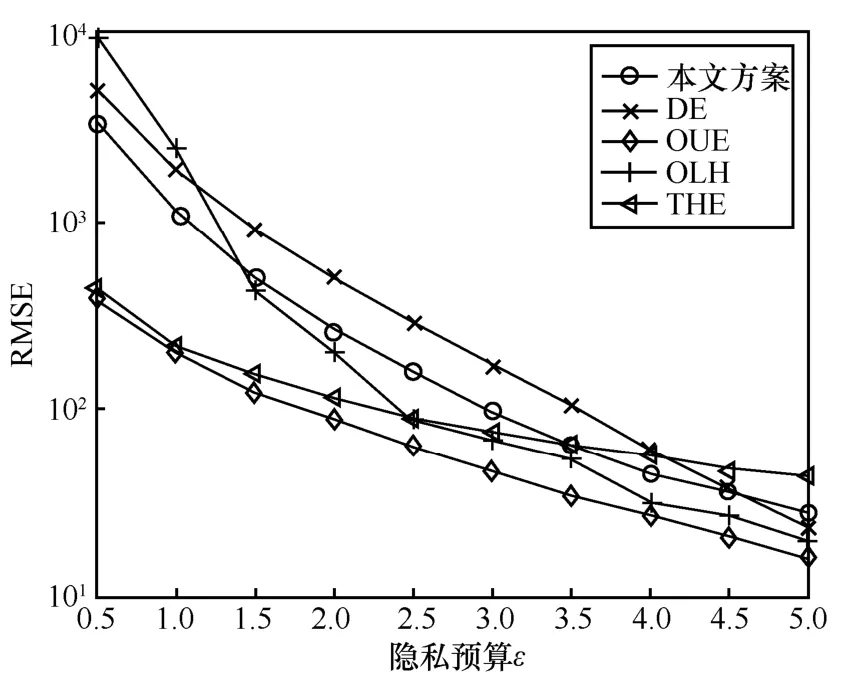
圖6 不同方案在固定L 下RMSE 的變化
綜上所述,本文方案與其他方案相比,在L和ε的變動下,其可用性始終能夠保持較好的狀態(tài)。
4.4 方案的復(fù)雜度
本文在3.2 節(jié)中提出的方案的算法復(fù)雜度與所選擇的算法集合大小有關(guān),當(dāng)算法集合大小固定時,算法復(fù)雜度與用戶所選擾動范圍=L有關(guān)。
具體而言,設(shè)服務(wù)為用戶i推薦了個算法,并且算法的擬合關(guān)系式在用戶資源充足時已由服務(wù)商更新,權(quán)重也已預(yù)計算。因此在本文方案中,每個用戶均執(zhí)行了次加法運算、次乘法運算、次除法運算、次開根運算和2 次隨機運算。用戶選擇不同的擾動算法會有不同的計算開銷:采用DE 算法會進行一次隨機;采用OUE 算法會進行L次隨機;采用OLH 算法會進行L+1 次哈希和一次隨機;采用THE 算法會進行L次隨機和L次加法運算。
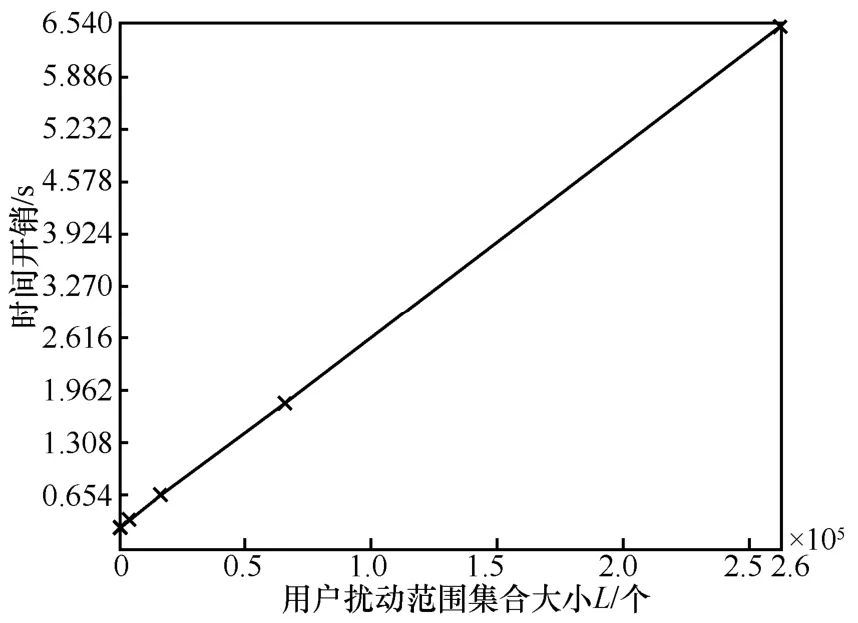
圖7 本文方案的時間開銷隨L 的變化
本文方案共傳輸數(shù)據(jù)Mi、、Di、Si至服務(wù)商,通過實驗測試得出的本文算法每次通信量大小與L的關(guān)系如圖8 所示。從圖8 可以發(fā)現(xiàn),隨著L增大,本文方案的通信量也隨之增加。
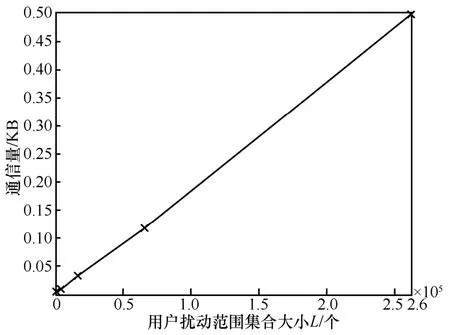
圖8 本文方案的通信量隨L 的變化
5 結(jié)束語
本文設(shè)計了基于LDP 的多級資源自適應(yīng)的算法推薦框架,能夠靈活地為用戶提供資源、隱私個性化的算法推薦。同時,將框架應(yīng)用在位置PoI 頻數(shù)統(tǒng)計任務(wù)的場景下,并在此基礎(chǔ)上對LDP 算法進行改進,使不同用戶能夠選取不同的LDP 機制,且可以設(shè)定不同的隱私需求;考慮到用戶的隱私偏好包含了用戶的敏感信息,因此設(shè)計了后處理機制,防止服務(wù)商推測出用戶的隱私偏好。最后,通過實驗證明了本文方案的可行性、可用性和效率。
猜你喜歡
吉林廣播電視大學(xué)學(xué)報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學(xué)版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數(shù)英綜合(2018年11期)2018-11-23 09:47:26
文苑(2018年21期)2018-11-09 01:23:06
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國衛(wèi)生(2015年9期)2015-11-10 03:11:12
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
