邊界感知的實時語義分割網絡
2022-09-06 11:08:50霍占強賈海洋喬應旭
計算機工程與應用 2022年17期
霍占強,賈海洋,喬應旭,雒 芬,陳 瑋
河南理工大學 計算機科學與技術學院,河南 焦作 454003
語義分割是一個基本且具有挑戰性的計算機視覺分類任務,其主要目的是為圖像中的每個像素標注預定義的高級語義類別標簽[1-2],屬于像素密集型的分類任務,其可視化如圖1所示。實時語義分割具有廣闊的應用前景,例如醫學圖像分割、人機交互、汽車的自動駕駛[3-5]、視頻監控等領域。

圖1 邊界分割可視化展示Fig.1 Visualization of boundary segmentation
基于手工設計的傳統語義分割方法主要分為五類:(1)閾值法[6],試圖將圖像分為兩個區域,目標區域和背景區域;(2)聚類法[7],基于顏色、梯度等像素特征或相對距離的相似度度量為每一個像素分配一個類別;(3)邊緣檢測法[8],利用邊界幫助圖像進行分割;(4)圖論法[9],將每個像素視為頂點,將像素之間的連線視為邊,用邊的權重度量其相似度;(5)條件隨機場法[10],將這一種用于標記和分割數據的概率框架應用于圖像分割。
近些年,深度學習方法在計算機視覺領域發展迅速,基于深度卷積神經網絡的語義分割方法與基于手工設計的語義分割方法相比性能上取得顯著的提升。Long 等[11]在2015 年提出一種全卷積網絡(fully convolutional networks,FCN)的語義分割模型,首次成功應用卷積神經網絡解決像素級的語義分割問題,使用全卷積層替代圖像分類網絡的全連接層來解決輸入圖像分辨率固定的問題,在網絡末端采用上采樣操作恢復到原始分辨率。然而FCN 輸出特征圖感受野較小,會導致無法很好地分割不同尺度的物體。為了解決該問題,Chen 等[12]在2018 年提出了DeepLabv3+網絡,設計了一種空洞空間金字塔池化模塊(atrous spatial pyramid pooling,ASPP),并行地使用多個不同膨脹率的卷積核對單一分辨率的輸出特征圖進行處理來得到不同大小的感受野區域,從而能夠有效地分割不同尺寸的物體并捕獲多尺度的語義邊界區域信息。Yu等[13]在2020年提出基于語義分支和細節分支構成的雙分支實時語義分割網絡BiSeNetV2,基于輕量級的骨干網絡通過融合低層的細節信息和高層的語義信息來補償精度的損失。語義分支利用深度可分離卷積構成的深層次網絡來負責提取高級別的語義信息,從而提高模型的推理速度。細節分支利用淺層次的卷積網絡以保留低層的細節信息。Yin 等[14]在2020 年提出Disentangled Non-local 通過解耦標準的Non-local模塊得到不同的視覺線索,白化的成對項用于學習區域內關系,一元項用于學習顯著的邊界特征。Fan 等[15]在2021 年提出Rethinking BiSeNet通過重新設計網絡架構將空間邊界信息的學習集成到低層級部分,同時設計短期密集連接模塊(short-term dense concatenate,STDC),通過融合連續若干個不同感受野的卷積核來彌補語義分支感受野的不足,從而有效地提取語義邊界區域特征。Zhu 等[16]在2021 年提出一種新的統計紋理學習網絡(learning statistical texture),通過設計一種新的量化和計數算子以統計的方式描述紋理信息,從而有效地利用低層紋理特征來保持語義分割的精確邊界。現有的模型由于細節分支和語義分支缺乏特殊的邊界設計,使得邊界信息被統一處理導致物體邊界分割不準確。
針對上述存在的問題,本文提出一種高效的邊界感知實時語義分割網絡(boundary-aware segmentation network,BASeNet)。網絡的創新設計主要包括:(1)為了提取更具有鑒別性的邊界特征,本文設計邊界感知學習機制。該機制通過將不同方向的位置信息整合到細節邊界中有效促進全局空間坐標信息和細節邊界特征之間的交互;(2)針對不同物體復雜的幾何結構,設計輕量級區域自適應模塊來產生多樣化采樣方案,通過稀疏、密集、自適應組合的策略增強網絡對復雜語義邊界區域的建模能力;(3)設計高效的獨特空洞空間金字塔池化模塊,通過融合策略重新衡量多分支池中不同大小相鄰像素的貢獻,強化語義邊界區域和細節邊界特征的重要性。
1 邊界感知的實時語義分割方法
1.1 網絡結構
為了提高實時語義分割網絡的性能以及邊界感知能力,本文提出了邊界感知的實時語義分割網絡BASeNet。
BASeNet網絡主要分為語義分支(semantic branch)和細節分支(detail branch)。BASeNet 是在BiSeNetV2網絡架構的基礎上進行改進的。首先,語義分支設計輕量級區域自適應模塊LRA(lightweight region adaptive)有助于充分利用語義邊界信息。其次,細節分支添加邊界感知的學習機制模塊(boundary-aware,BA)有助于利用細節邊界信息。最后,模型末尾添加高效的空洞空間金字塔池化模塊EDASPP(efficient distinctive atrous spatial pyramid pooling)進一步地增強語義和細節邊界特征,BASeNe網絡結構如圖2所示。

圖2 BASeNet網絡結構Fig.2 Structure of BASeNet network
本文提出BASeNet 網絡詳細信息如表1 所示。其中Dopr 表示細節分支操作單元,Ds 表示細節分支下采樣的步長,Sopr 表示語義分支操作單元,Ss 表示語義分支下采樣的步長。
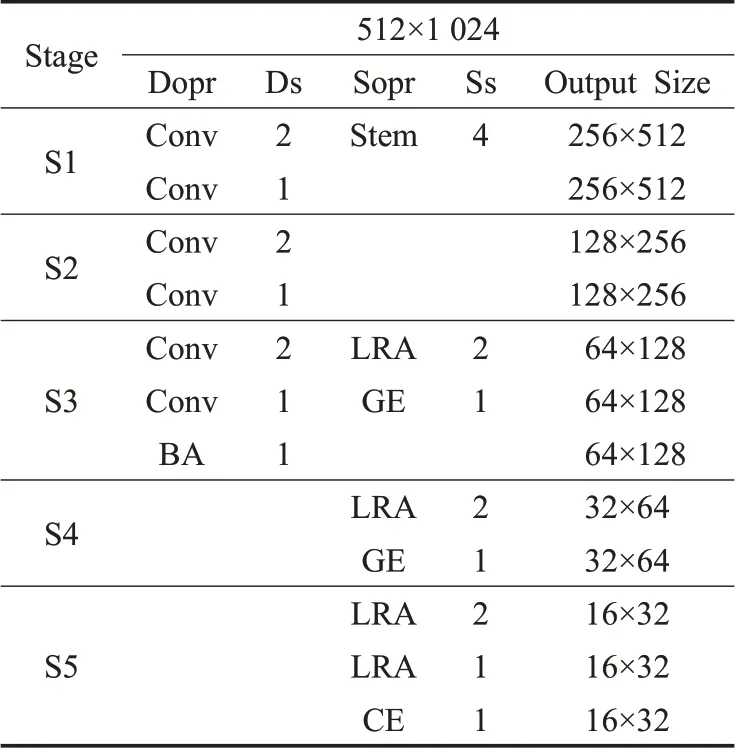
表1 BASeNet網絡架構Table 1 Architecture of BASeNet network
相比于BiSeNetV2,BASeNet 主要采取以下三方面優化:(1)細節分支中的S1~S3仍然保留,使輸出分辨率降至輸入1/8,新增BA模塊用于提取細節邊界特征和精確的位置坐標信息。(2)語義分支中Stem(stem block)[13]和CE(context embedding block)[13]模塊仍保留,將S3~S5 第一個聚集擴展層模塊(gather-and-expansion layer,GE)[13]更換為LRA(步長為2)模塊用于降采樣操作,S5中的第二個GE模塊替換為LRA(步長為1)模塊,保辨率不變。(3)新增的EDASPP 模塊用于提取顯著性的語義邊界區域信息和細節邊界特征。
1.2 邊界感知學習機制
由于BiSeNetV2 網絡的邊界和紋理特征是統一處理,從而導致細節分支對細節邊界信息利用可能不充分。為了提取細節分支的邊界視覺線索和定位精確位置信息,受到Disentangled Non-local[14]中一元項(unary non-local,unary NL)和協調注意力(coordinate attention,CA)[17]的啟發,本文提出邊界感知學習機制模塊BA,其結構如圖3所示。
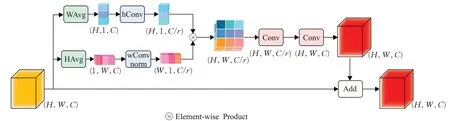
圖3 BA模塊結構Fig.3 Structure of BA module
首先,給定輸入特征圖X,通過沿水平方向的平均池化WAvg和垂直方向的平均池化HAvg生成ZH∈RH×1×C,ZW∈R1×W×C,如公式(1)、(2)所示:

為了減少通道數,ZH、ZW利用hConv和wConv的控制縮放因子r分別得到新的特征圖V∈RH×1×C/r、M1∈R1×W×C/r,如公式(3)、(4)所示:

式中,hConv和wConv表示1×1卷積(Conv)操作,r設置為4。為了計算兩者的關聯性對M1進行歸一化處理,如公式(5)所示:

式中,norm表示L2歸一化,通過對V、M運用矩陣乘法得出的時間復雜度是O(H×W),僅為原來一元項的1/(H×W)。盡管細節分支輸出特征圖的分辨率依舊相對較大,但計算成本相對于一元項已經大幅度的降低,比較適合應用于輕量級的語義分割網絡。為了保持與X形狀一致且重新編碼邊界位置依賴關系,相乘后的矩陣首先進行reshape操作,然后將其和輸入特征圖X相加用于得到矯正后的特征Y,如公式(6)所示:
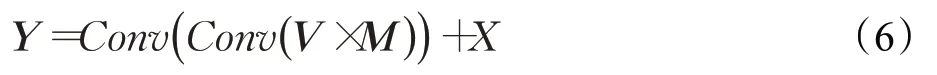
本文提出一種邊界感知學習機制用于充分利用邊界和坐標位置信息。一方面,為了將方向感知和位置敏感的注意力圖作為顯著性邊界的輸入,與一元項通過卷積獲取輸入不同的是,邊界感知模塊是通過沿水平和垂直方向的池化操作實現的。另一方面,為了促進精確的位置信息和鑒別性較強的邊界信息之間相互交流,與協調注意力相加的方式不同的是,邊界感知模塊是通過矩陣相乘的方式實現的。同時,采用轉換函數對注意力圖進行重新編碼,有助于捕獲不同通道之間的相互依賴關系和恢復通道數。此外,邊界感知模塊不僅可以提高模型的推理速度,還可以通過邊界卷積通道和坐標卷積通道之間的相互依賴關系有效處理細節分支中的邊界坐標信息,有助于利用精確的位置信息增強細節分支獲取邊界的能力。
1.3 輕量級區域自適應模塊
對于語義邊界區域特征的提取,通常在編碼器后面使用空間金字塔塊的方法來提取有效的語義邊界區域信息[18-20]。而本文認為獲取語義邊界區域的能力在網絡不同階段是不同的,例如,淺層階段提取細節邊界特征,中間階段提取語義和細節邊界特征,末尾階段提取更豐富的語義邊界區域信息。
為了解決語義邊界區域的問題,受到聚集-擴展層(GE)[13]和金字塔基本塊(pyramid building blocks)[21]的啟發,本文提出輕量級區域自適應模塊LRA,其結構如圖4、5所示。
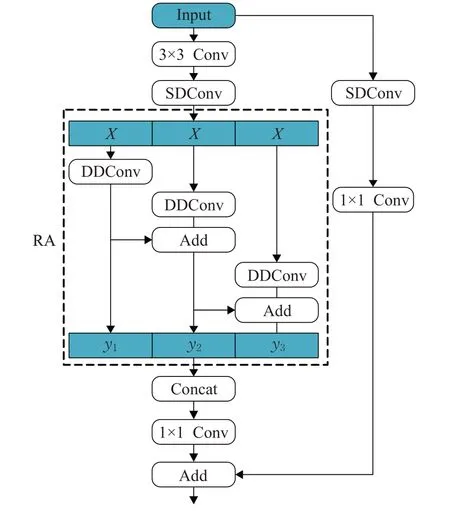
圖4 LRA步長為2結構Fig.4 Structure of LRA whose stride equals two
如圖4 所示,步長為2 的LRA 模塊由擴張卷積、區域自適應模塊RA(region adaptive)和映射層組成。首先,給定輸入維度為C的特征圖,依次經過3×3 Conv、步長為2的3×3卷積(SDConv),得到維度為6C的特征圖X,并分別流入由深度空洞卷積(DDConv)且空洞率全部為1 的區域自適應模塊RA,卷積核的大小從左至右依次是3、5、7,為了加強不同分支間的信息交流,對不同分支間的輸出特征DDConvi(X)進行融合得到yi,第i-1 分支和第i分支的關系,如公式(7)所示:
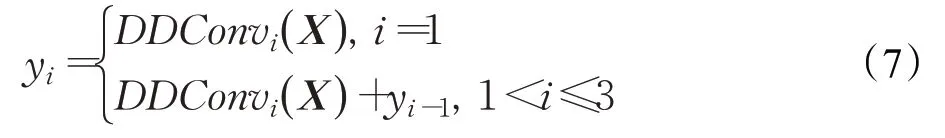
最后,將不同分支得到的yi拼接起來,并通過1×1 Conv將輸出維度降為C。同時,為了維持數值穩定性,采用3×3 SDConv 和1×1 Conv 組成的殘差結構。此外,為了維持分辨率,還設計步長為1的LRA,其殘差結構去掉3×3 SDConv和1×1 Conv,其結構如圖5所示。
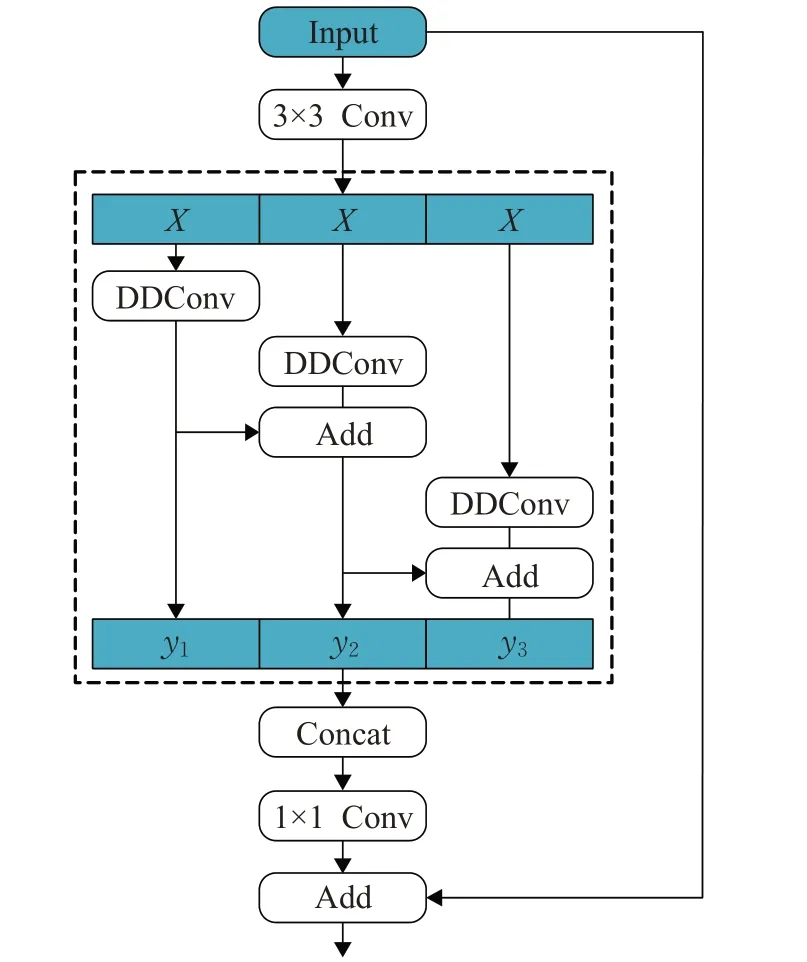
圖5 LRA步長為1結構Fig.5 Structure of LRA whose stride equals one
與金字塔基本塊不同的是,首先,本文將深度卷積替換為深度空洞卷積有助于網絡擴大感受野的學習區域;其次,使用聚集擴展層有助于聚合更多有效的局部特征信息;然后,LRA 模塊批處理歸一化(batch norm,BN)在每個深度空洞卷積后使用有助于提高網絡訓練的穩定性,并使用ReLU函數增加語義邊界區域的非線性;最后,為了充分挖掘不同階段的語義邊界區域特征,LRA在網絡的不同階段,設計不同大小的空洞率有助于網絡學習可變的采樣區域。將LRA模塊插入骨干網絡的不同階段用于增強模型獲取語義邊界區域信息的能力,在網絡的淺層階段插入LRA 用于學習低層次的細節邊界特征。在網絡的中間階段插入LRA用于學習部分語義邊界對象特征,并充分利用語義和細節邊界能力從而提高網絡的性能。在骨干網絡的后端,通過疊加不同空洞率的濾波器使得接受域的學習區域自適應于網絡,獲取更多上下文信息,進一步增強語義邊界區域信息。可變的采樣區域還有助于網絡解決因使用級聯的擴張卷積帶來的“棋盤效應”。
1.4 高效的空洞空間金字塔池化
為了進一步增強語義和細節邊界信息,考慮DASPP(distinctive atrous spatial pyramid pooling)[22]模塊提取語義多尺度特征的優勢。本文設計EDASPP模塊,其結構如圖6 所示,通過少量的參數和單向融合策略,進一步提升分割網絡建模語義邊界區域和細節邊界的能力。
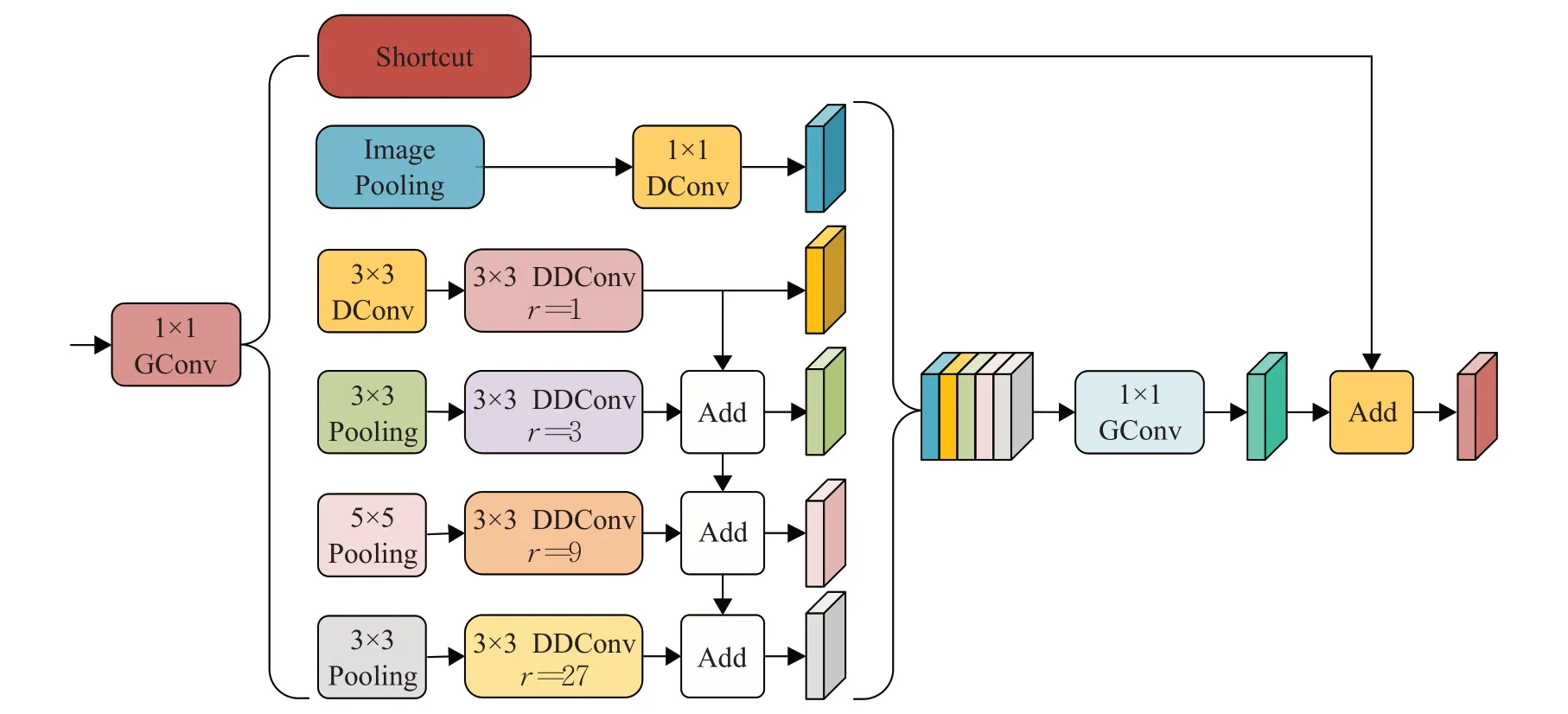
圖6 EDASPP模塊結構Fig.6 Structure of EDASPP module
為了減少計算成本,首先,改進后的EDASPP 模塊的輸入特征圖,經過1×1分組卷積(GConv)將維度降至96維。其次,在并行的卷積分支中,該模塊分別采用3×3深度卷積(DConv)和3×3、5×5、7×7的平均池化。其中3×3 DDConv 在四個分支中對應的空洞率分別為1、3、9、27。然后,為了提高信息的利用率,通過采取單向融合策略得到多級融合特征信息Z。同時,X依次經過圖像級池化、1×1 DConv 后與多級融合特征信息Z拼接。最后,經過1×1 GConv 操作后和輸入特征采取殘差方式得到最終的輸出Y,如公式(8)、(9)、(10)和(11)所示:
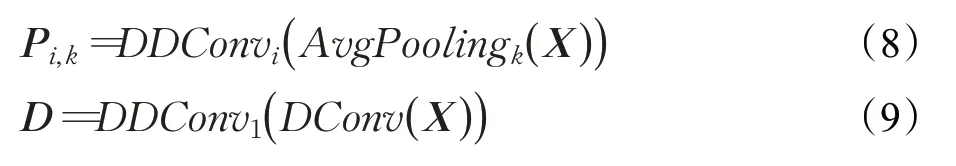
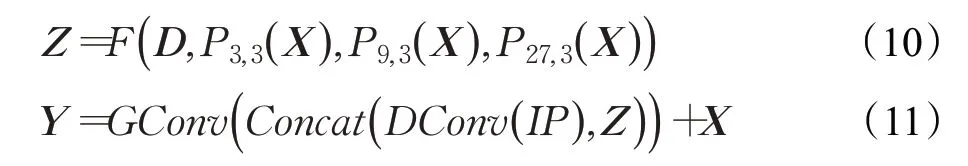
其中,X為經過1×1 GConv后的特征,AvgPoolingi(X)代表大小為k的平均池化操作,k的取值是3、5、7。DDConvi(X)代表空洞率大小是i的深度空洞卷積,i的取值分別是1、3、9、27,D表示特征圖先經過深度卷積后,再經過深度空洞卷積,Pi,k表示先經過平均池化后經過深度空洞卷積的特征圖,F表示單向融合策略,Z為多級融合特征信息,Concat表示特征圖的拼接,IP(X)表示圖像級平均池化,GConv用于恢復信道數,Y為EDASPP輸出特征圖。
此設計使模型參數從70 萬降到了3 萬。單向融合單元充分利用多尺度的語義邊界區域信息提升模型建模語義和細節邊界的能力。圖像級平均池化用于獲取全局上下文信息,對于融合多尺度多階段的骨干網絡是至關重要的,會在實驗部分證明該觀點,快捷連接用于提升網絡訓練的穩定性。
2 實驗結果分析
2.1 實驗設計
Cityscapes[23]評測數據集是最具代表性和重要性的圖像分割數據集基準之一。Cityscapes 數據集包含5 000 張高分辨率的圖片,圖片的內容是城市環境中的駕駛場景,以汽車的角度對這些場景進行語義理解。數據集劃分為2 975 張訓練集圖像,500 張驗證集圖像,1 525 張測試集圖像,分辨率為2 048×1024。根據內容進行劃分,數據集標簽包括30個類別,其中可用于語義分割任務的類別為19個。在實驗中使用精細標注的樣本進行訓練和驗證所提方法的準確度。
CamVid(Cambridge-driving labeled video database)[24]
數據集是第一個具有目標類別語義標簽的視頻集合。數據集提供32 個語義標簽,將每個像素與語義類別之一相關聯。數據是從駕駛汽車的角度拍攝的,駕駛場景增加觀察目標的數量和異質性。
模型實驗采用的深度學習框架是Pytorch,顯卡是GeForce RTX 2080 Ti GPU,CUDA 9.0 和CuDNN v7版本。測試階段使用一個GPU測量前向傳播的推理時間,輸入分辨率的大小為2 048×1024。重復1 000 次取平均值以減少實驗誤差,測量精度指標是平均像素交并比(mIoU),效率是每秒傳輸幀數(FPS)。對于所有數據集中的樣本,使用數據增強策略,包括隨機水平翻轉、隨機縮放、隨機剪切到固定分辨率大小的輸入圖像,隨機尺度包含{0.75,1,1.25,1.5,1.75,2.0}。
2.2 實驗設置及評價指標
訓練是從頭開始,沒有使用預訓練模型,采用隨機梯度下降(SGD)算法優化模型,初始動量為0.9,批處理的大小為8,權重衰減為0.000 5。采取指數學習速率策略,初始學習率乘以設為0.9,初始速率為0.05。iter和max_iter表示當前的迭代次數和迭代次數最大值,對Cityscapes 數據集、CamVid 數據集模型分別訓練了175 000、11 000個周期。
2.3 實驗結果分析
(1)BA模塊的消融實驗
為了驗證BA 模塊的性能,實驗結果如表2 所示。
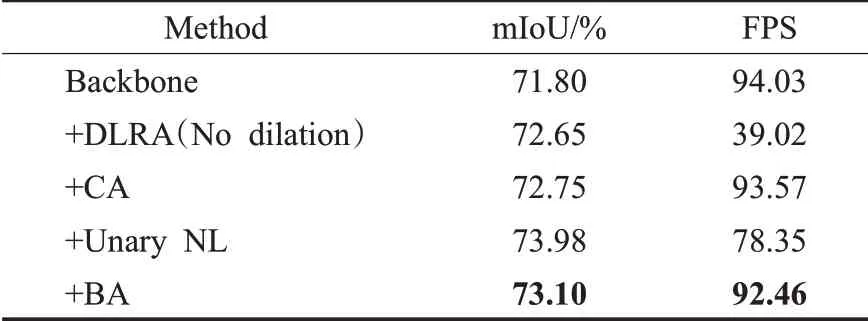
表2 在Cityscapes驗證集驗證不同設置下的性能Table 2 Performance of validation set of Cityscapes with different validation settings
本網絡使用BiSeNetV2 作為基準網絡。DLRA(No dilation)表示細節分支降采樣后串聯不帶空洞率的LRA,CA[17]表示細節分支和協調注意力串聯,Unary NL[14]表示細節分支和一元項串聯,BA表示細節分支與邊界感知學習機制串聯。
由表2可知,加入BA的網絡與骨干網絡相比mIoU從71.80%提升到73.10%,mIoU值提升了1.3個百分點,速度從94.03 降到92.46,降低了約1.57。DLRA(No dilation)與骨干網絡相比mIoU提高了0.85個百分點,盡管精度有略微提升,但速度大幅度下降導致不適用于實時語義分割。BA 與CA[17]相比以相似的分割速度實現更高的分割精度,主要是因為嵌入邊界信息有利于提高坐標位置信息的利用。BA 與Unary NL[14]相比雖然精度略有下降但取得了更快的分割速度,主要是因為使用坐標位置信息提高了邊界的推理速度。基于實驗分析驗證了邊界信息和坐標位置信息對于細節分支的重要性,說明了細節分支不僅僅需要位置依賴關系,更需要學習顯著的邊界信息。
(2)空洞率對LRA性能影響的消融實驗
為了驗證LRA 模塊采取空洞率的性能差異,實驗結果如表3 所示。LRA(No dilation)表示語義分支S5階段全部空洞率為1的LRA,LRA表示語義分支使用帶有空洞率輕量級區域自適應模塊。
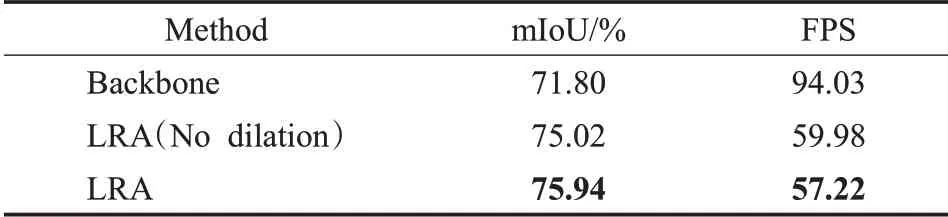
表3 空洞率對模型性能的影響Table 3 Influence of dilation rate on model performance
由表3可知,加入LRA模塊的網絡與骨干網絡相比mIoU從71.80%提升到75.94%,mIoU提高了約4個百分點,表明語義邊界區域特征的重要性。加入LRA 模塊的網絡與加入LRA(No dilation)模塊的網絡相比,在保持相同的推理速度的條件下,mIoU 提高了約0.92 個百分點,表明輕量級區域采樣模塊中空洞率的設計比較合理。LRA 模塊利用可變的采樣區域增強了語義分支對語義邊界區域的建模能力,使輕量級語義分割模型精度得到顯著提升。
(3)EDASPP有效性的消融實驗
為了證明EDASPP 模塊的有效性,實驗結果如表4所示。DASPP 表示基線網絡和DASPP 串聯,EDASPP(No fusion)表示基線網絡和EDASPP 串聯,EDASPP(Cascade)表示將EDASPP中的平均池化的連接方式由并行改為串行,EDASPP(Max)表示在池化層中采用最大值池化,EDASPP(Avg)表示在池化層中采用平均池化。EDASPP默認為EDASPP(Avg)。
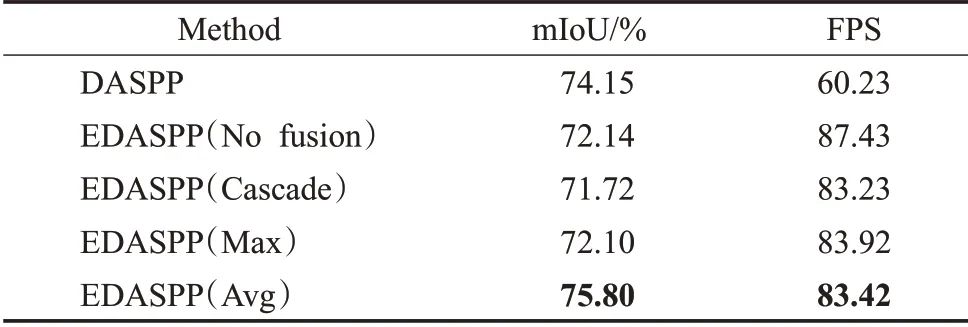
表4 EDASPP與DASPP在Cityscapes驗證集上的性能比較Table 4 Comparison of performance between EDASPP and DASPP on Cityscapes validation set
由表4 可知,加入DASPP 的網絡mIoU 為74.15%,加入EDASPP的網絡為75.80%,可以發現,加入DASPP的網絡精度相對較低,是因為DASPP 每個并行分支后的卷積操作的輸入采取簡單的融合機制未能充分利用更多語義邊界區域信息。與EDASPP(No fusion)相比,EDASPP 獲得了更好的精度,是因為EDASPP 通過單向融合策略能夠有效利用不同尺度的信息提高不同特征圖的信息利用率。與EDASPP(No fusion)相比,EDASPP獲得了更好的精度,是因為EDASPP通過單向融合策略能夠有效利用不同尺度的信息提高不同特征圖的信息利用率,體現了EDASPP 融合模塊的有效性。EDASPP(Cascade)將mIoU 從75.80%(由EDASPP 得到)降低到71.72%,這表明級聯方式會因不斷的池化操作失去更多的信息。而EDASPP 是因為并聯不同尺度邊界信息來獲得每個池化層和卷積層的特征圖信息,使得精度得到顯著提升。EDASPP相比于EDASPP(Max)的mIoU 提高約3.70 個百分點,是因為平均池化會帶有更多的特征信息。實驗表明EDASPP 能夠更有效地利用來自不同分支的邊界語義信息和細節邊界特征。
(4)EDASPP和LRA結合合理性的消融實驗
為了驗證EDASPP 模塊對LRA 模塊結合的合理性,實驗結果如表5 所示。LRA 與表3 的意義一樣,LRA-Shortcut表示骨干網絡加入LRA和跳遠連接分支,LRA-EDASPP 表示骨干網絡加入LRA 和EDASPP,帶有“√”的表示加入圖像級平均池化(Image Pooling)。
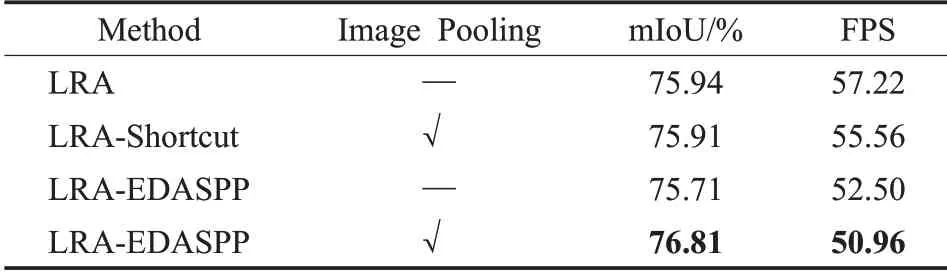
表5 驗證EDASPP與帶有LRA的語義分支結合的合理性Table 5 Testing rationality of combination of EDASPP and semantic branch with LRA
由表5可知,加入帶有Image Pooling的LRA-EDASPP的網絡與只加LRA 的網絡相比mIoU 從75.94%增加到76.81%,mIoU值增加了約0.87個百分點。速度從57.22下降到50.96,下降了約6.26。與只加LRA 的網絡相比帶有Image Pooling的LRA-Shortcut網絡的精度降低了0.03個百分點,速度相似,加入Image Pooling和跳遠連接雖然利用全局上下文語義信息,但由于未能充分利用語義分支模塊多尺度邊界區域信息,導致性能略有下降。不帶Image Pooling 的LRA-EDASPP 的網絡相比帶Image Pooling 的LRA-EDASPP 網絡的精度降低了1.10 個百分點,不帶Image Pooling 的LRA-EDASPP 雖然進一步增加了模型的感受野,但面臨會丟失全局信息的能力。實驗表明EDASPP分支可以有效融合LRA中的語義邊界區域特征和細節邊界特征,驗證了EDASPP與語義分支LRA結合的合理性。
在城市景觀測試集上給出該算法的分割精度和推理速度。數據集輸入圖像為1 024×2 048,首先將輸入的分辨率調整為512×1 024 進行訓練,然后在驗證集和測試集上恢復至原始分辨率評估分割精度。推斷時間是在一個NVIDIA GeForce 2080Ti 卡上進行測試。所提方法和現有方法的比較結果如表6 所示。第一組為非實時方法,包括DeepLabv2[25]、PSPNet[26]。第二組為實時語義分割算法,包括ENet[27]、ERFNet[28]、GUN[29]、BiseNet[30、]ICNet[31、]ESPNetV2[32、]Fast-SCNN[33、]BiSeNetV2[13]。所提方法在Cityscapes 測試集以47.2 FPS 獲得74.9%的mIoU,精度比表6 第二組中大部分實時算法更好,驗證邊界感知方法的有效性。
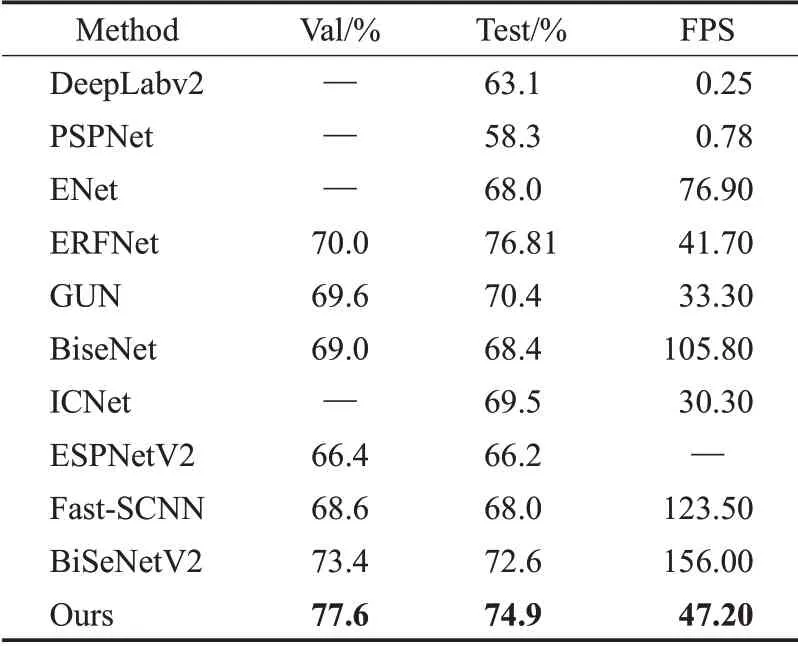
表6 在Cityscapes測試集上與其他方法比較Table 6 Comparison with other methods on Cityscapes test set
為了定性分析本網絡的分割效果,本文方法與BiSeNetV2 在Cityscapes 數據集上進行可視化對比,結果如圖7所示。其中圖7(a)為Cityscapes驗證集的輸入圖像,圖7(b)為Cityscapes驗證集對應的真實圖像標簽,圖7(c)為本文算法的分割結果,圖7(d)為BiSeNetV2的分割結果。可以發現,本文邊界分割準確度相比于基礎算法更高,主要分為三種情況,第一,BiSeNetV2相比于原圖會產生多劃分的情況,如圖7第四列的第一行和第二行,會在道路上添加原圖中不存在的人行道,原因是不同的類之間缺乏語義邊界區域信息,而本網絡在語義分支通過充分考慮語義邊界區域特征,有效增強像素之間的語義邊界關系,這樣多劃分的情況就會有效減少。第二,BiSeNetV2相比于原圖會產生人行道之間馬路少劃分的情況,如圖7 第四列的第三行,造成的原因是由于基礎算法沒有充分考慮細節邊界信息,因此會造成邊界劃分不準確的現象。而本網絡通過在細節分支充分利用細節邊界信息,對物體邊界的少劃分提供有效的幫助。第三,BiSeNetV2相比于原圖會出現交叉劃分的情況,如圖7第四列的第四行,人行道之間會混有道路,造成的原因是語義和細節等上下文信息的利用不充分,而本網絡通過增強物體的上下文信息來減少交叉劃分的錯誤現象。由于本文算法充分考慮細節邊界和語義邊界區域的作用,因此增強網絡對于圖像邊界的建模能力。

圖7 Cityscapes數據集可視化結果Fig.7 Visualization result of Cityscapes dataset
為了證明BASeNet的泛化性和高效性,表7顯示了在CamVid 數據集上進行精度和速度結果。在推理階段,訓練集和驗證集的輸入分辨率為960×720。BASeNet 不僅與一些非實時算法SegNet[34]、PSPNet[26]進行了對比,還與實時算法ENet[27]、ICNet[31]、SwiftNet[35]對比,以及最新的BiSeNetV2[13]。BASeNet 的mIoU 達到76.36%,比性能最好的BiSeNetV2[13]網絡增加了3.96 個百分點,驗證了模型的泛化性。

表7 在CamVid測試數據集上與其他方法進行了比較Table 7 Accuracy and speed of proposed method compared with other methods on CamVid test dataset
3 結束語
基于邊界問題的分析,本文提出了一種基于邊界感知的實時語義分割網絡BASeNet。首先,邊界感知學習機制通過不同方向的位置坐標和邊界信息的相互交流來產生低耦合度的細節邊界特征。其次,輕量級區域自適應模塊利用可變的區域采樣方案,通過插入網絡的各個階段來獲取不同效果的語義邊界區域特征使網絡增強了建模復雜語義邊界區域的能力。最后,高效的獨特空洞空間金字塔池化模塊利用重要性不同的采樣值和高效的單向融合策略有助于網絡提取豐富的語義邊界區域信息和空間邊界信息。實驗結果表明,該網絡實現了分割精度和推理速度之間的良好平衡。在后續的研究中,還需要考慮多尺度特征的細節邊界真實標簽的信息用于指導網絡學習。
猜你喜歡
家庭影院技術(2020年10期)2020-12-14 07:53:50
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生優秀作文(低年級)(2018年10期)2018-10-13 01:56:50
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年10期)2016-11-29 19:59:58
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
