隨機森林與支持向量機在預測烏魯木齊農村老年人養老服務需求的應用研究*
2022-09-14 09:58:12新疆醫科大學護理學院830011
中國衛生統計 2022年3期
新疆醫科大學護理學院(830011)
樊瓊玲 張雪蓮 楊 菲 曹雪梅 朱紅梅 由淑萍△
【提 要】 目的 探討隨機森林(random forest,RF)和支持向量機(support vector machine,SVM)算法在農村老年人養老需求服務預測中的應用價值。方法 運用分層整群抽樣對烏魯木齊1652名農村老年人進行問卷調查,采用RF算法和SVM算法構建模型預測農村老年人的日常生活照料、醫療保健服務、精神慰藉服務和休閑娛樂服務等四類養老服務需求,通過準確率、特異度、召回率和ROC曲線進行模型評估。結果 日常生活照料、精神慰藉服務需求中RF模型ROC曲線下面積更大;醫療保健服務需求中SVM模型的ROC曲線下的面積更大;休閑娛樂服務需求中兩個模型的ROC曲線下面積相等。結論 RF算法和SVM算法構建的老年人養老服務需求預測模型,各有其優勢,在養老事業的精準預測工作中有一定的價值。
《2019年國民經濟和社會發展統計公報》提示,我國老年人數量已超過2.5億,約占我國總人口18.1%[1]。2015年到2050年,我國老年人口將持續增長,至2050年老年人口預計達4.98億[2]。隨著我國老齡化加劇和經濟發展,老年人的養老服務需求越來越大,養老服務需求種類也越來越多樣化。對未來不同類別養老服務的需求和趨勢進行分析,對促進養老事業的精細化管理、有效解決養老服務的民生問題具有重要意義。目前,我國對老年人養老需求預測的關注度不足,尚未發現適合模型。近年來,機器學習在經濟、醫療等行業中展現了深度數據挖掘、資源配置等優勢[3-4]。隨機森林(random forest,RF)、支持向量機(supprt vector machine,SVM)等機器學習算法能否在構建老年人養老服務需求預測模型中具有較好的性能尚未知。因此,本研究基于烏魯木齊農村老年人的養老服務調查數據,探索RF算法和SVM算法在烏魯木齊農村老年人養老服務需求預測中的應用價值。
對象與方法
1.研究對象
2019年1月至2020年6月,采用分層整群抽樣方法,第1階段:隨機抽取烏魯木齊縣為調研區域;第2階段:烏魯木齊縣下轄三鎮三鄉,根據各鄉鎮人口比例,在各層內隨機抽取具有代表性的行政村,每個鎮各抽取7~8個村,每個鄉各抽取3~4個村,一共抽取36個村;第3階段:在每個抽中的行政村內,按照簡單隨機抽樣抽取≥60歲的常住老年人40~50人。共計發放1700份問卷,回收有效問卷1652份,有效回收率97.2%。
2.資料收集
調查問卷參考茍曉玲[5]的《安州區居家養老服務問卷調查表》并自行修訂而成《烏魯木齊農村居民養老服務問卷調查表》,問卷的第一部分為一般資料(包括年齡、性別、民族、文化程度、婚姻狀況、子女個數、子女關愛情況、居住狀況、月收入水平、自評自理能力和身體健康狀況);第二部分為養老服務需求(包括日常生活照料、醫療保健服務、精神慰藉服務、休閑娛樂服務等4項)。經檢驗,該問卷克朗巴赫值為0.87,具有較好的信度。
3.調查方法
經統一培訓的調查小組包括5名學生,1名少數民族翻譯,以面對面訪談法進行調查。收集問卷的人員按照統一的指導語向老年人解釋題目。調查結束當天每小組對當天問卷進行復核,剔除有漏項、錯項及邏輯性錯誤問卷,討論當天調查中的問題,總結相應解決方案,控制調查員偏倚。
4.統計分析
采用Python 3.7軟件和scikit-learn機器學習包進行分析。本研究將1652個樣本集分為兩部分:訓練集70%(1156人)和測試集30%(496人)。具體建模過程如下:
(1)進行數據預處理:根據統計學知識,對數據進行標準化處理,自變量賦值見表1。
(2)RF模型構建:經過網格搜索后確定最優算法模型,樹的棵數ntree設置為200,最大深度為6層,計算每個節點的基尼不純度(Gini impurity)和子節點的基尼不純度的下降,作為各自變量的重要性得分并進行排序。
(3)SVM模型構建:分別比較了四種核函數,線性核函數,多項式核函數,gamma取值分別為0.5和0.1的高斯核函數(徑向基函數),經過網格搜索比較后,選取預測結果更佳的 gamma 值為0.5的高斯核函數,作為SVM模型的核函數。
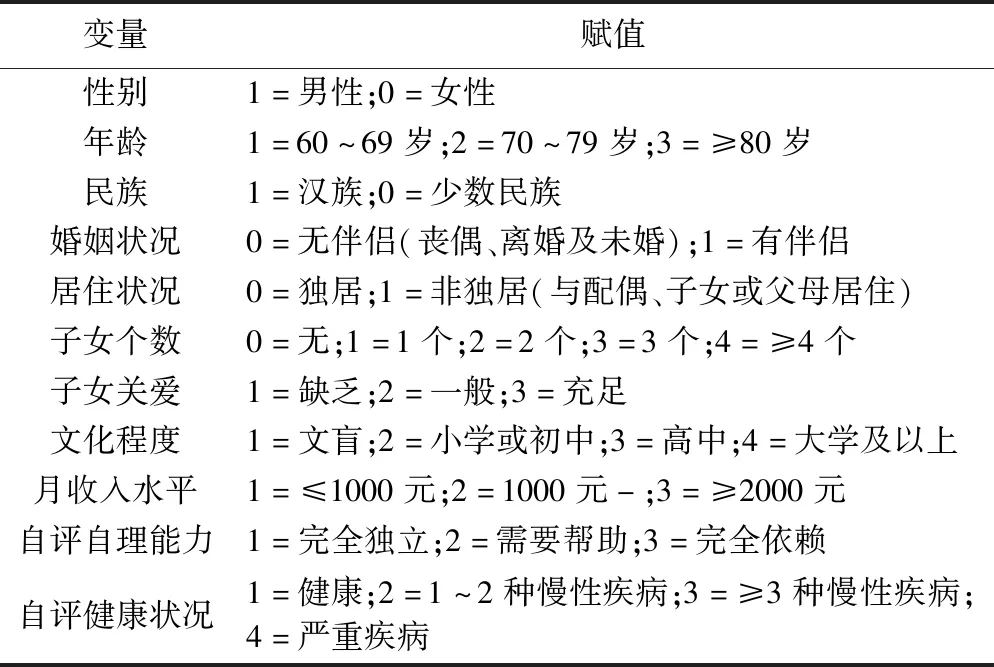
表1 賦值表
(4)模型的評估與比較:采用三個機器學習的常用指標,包括準確率、特異度和召回率,基于測試集數據對RF和SVM模型對老年人各項養老需求的預測效果進行了評價。還應用ROC曲線和曲線下面積AUC值對模型的效果再進行評價。
結 果
1.一般資料
入選研究對象共計1652例,平均年齡為(67.3±10.7)歲,包含男性797例,占48.2%,女性855例,占51.8%;漢族607例,占36.7%,少數民族1045例,占63.3%。
2.RF模型的影響因素重要性排序
四類養老服務影響因素的重要性排序如圖1所示。各類養老服務需求中評分較高的前3項分別為:日常生活照料需求為自評自理能力、年齡、自評健康狀況;醫療保健服務需求為自評健康狀況、自評自理能力、年齡;精神慰藉服務為子女關愛、子女個數、婚姻狀況;休閑娛樂服務為自評自理能力、每月收入水平、文化程度。
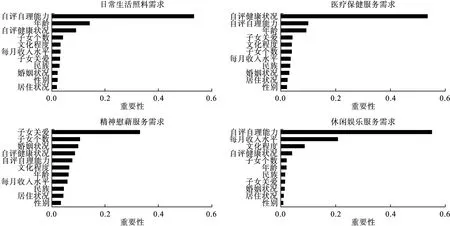
圖1 RF模型中四類養老服務需求的影響因素重要性排序
3.RF模型及SVM模型的預測結果
采用Python的scikit-learn庫中RF模塊,構建RF模型,通過gamma 值為0.5的高斯核函數建立模型,將養老服務需求的選擇結果作為因變量,其他變量為自變量。RF模型及SVM模型預測結果可見表2。
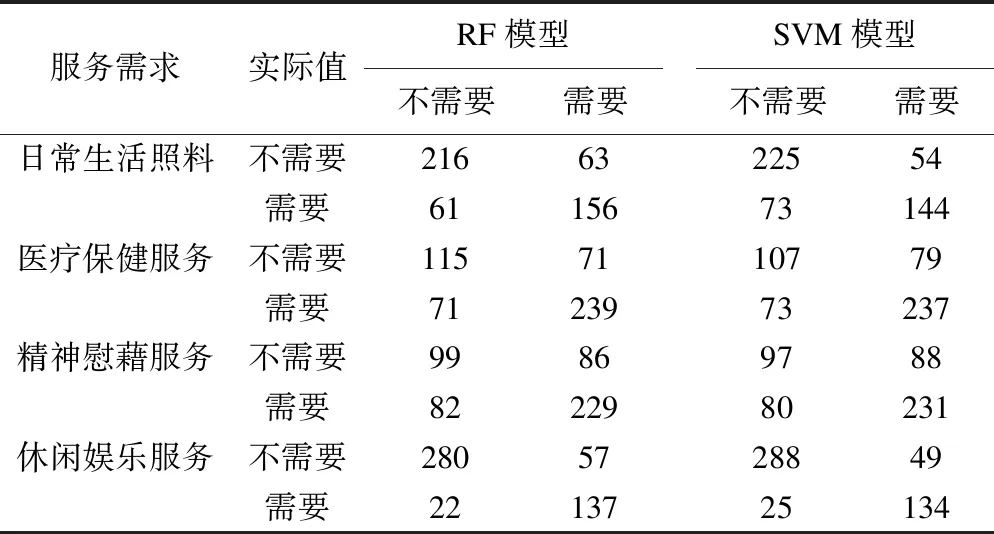
表2 測試集中RF和SVM模型分類預測結果
4.兩個模型的評估與比較
RF模型和SVM模型的準確率、特異度和召回率見表3。在日常生活照料、醫療保健需求、精神慰藉服務需求中,RF模型的AUC值分別為0.75、0.69、0.64,SVM模型的AUC值分別為0.74、0.67、0.63,RF模型的預測效果稍優于SVM模型;在休閑娛樂服務需求中,兩模型的AUC值均為0.85,其預測效果相近,見圖2。
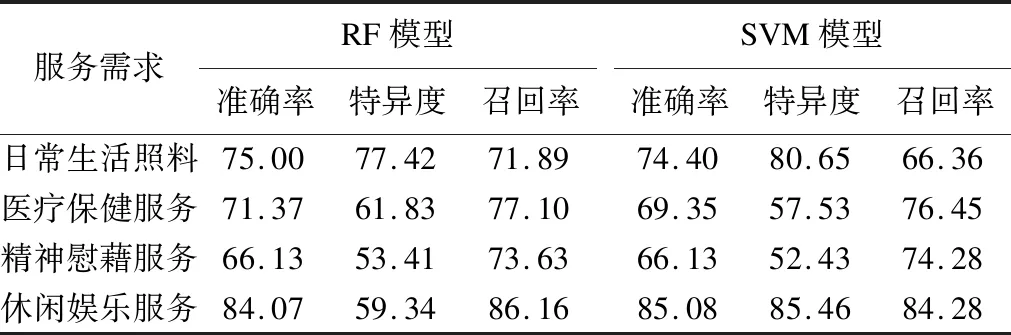
表3 RF模型和SVM模型的準確率、特異度和召回率(%)
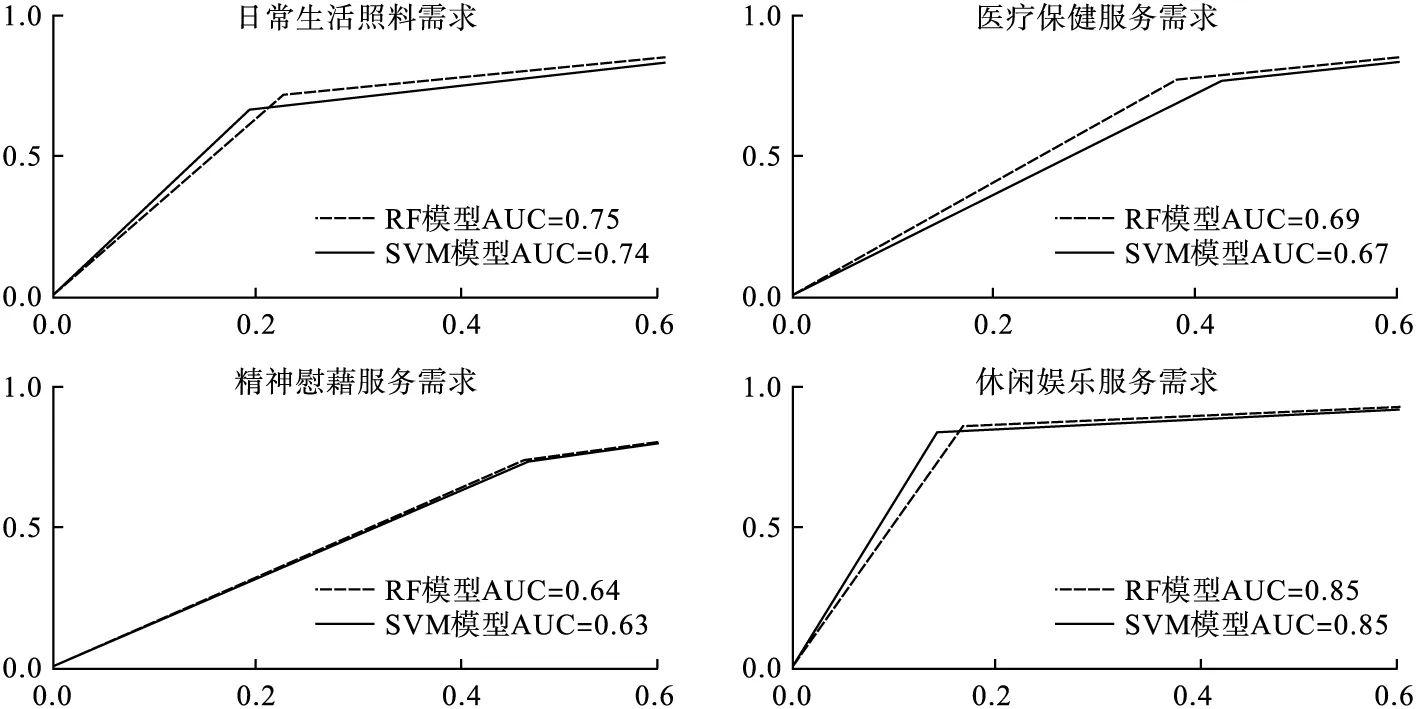
圖2 四類養老服務需求預測的ROC曲線圖
討 論
隨著老齡化加劇,建設養老產業、精準預測養老需求已是我國重要民生問題。基于科學模型算法得出的老年人養老服務需求預測,可更好地對養老服務的建設和推廣提供依據,促進相關配套政策和設施的制定。
目前,我國的老年人養老服務需求預測側重于對失能老年人的養老服務需求或護理需求。周元鵬等[6]通過比例測算法,結合日常生活活動能力,計算不同年齡、不同功能障礙等級的老年人口比例來預測居家養老服務的需求規模。鄉汝浩等[7]通過國際人口預測軟件PADIS-INT預測老齡化進程,以失能率為基礎,結合失能老人的入住意愿和我國實際情況,對未來醫養結合養老服務需求進行預測。于歡[8]通過灰色理論模型以老年殘疾人居家養老總數與各項需求百分比的成績計算出各項預測需求總人數。由于老年人口總量預測的影響因素眾多,各因素間關系復雜,幾個指標難以完全解釋清楚,且老年人口數據具有歷史不完整、信息不全等特點,傳統預測模型無法較好地實現對養老服務需求的預測。
機器學習技術具備強大的特征識別分類及預測的能力,提供了從不同數據推斷數據項之間重要聯系的可能性[9]。一部分機器學習算法已應用于臨床工作中,已被證明比傳統方法能更準確預測結局[10-11]。RF算法由Leo Breiman[12]于2001年提出,該算法以“袋裝法”整合多棵決策樹,是一種較為實用的集成學習法。與logistic回歸相比,RF算法通過隨機特征選擇了樣本誤差,比單一測試樣本進行擬合的logistic模型結果更有說服力[13]。SVM算法是以統計學理論為基礎,以結構風險最小化為原則,在小樣本條件下擁有較好的推廣和泛化能力[14]。通過核函數,SVM算法可以將線性不可分的數據轉化為線性數據。
RF模型和SVM模型在老年人養老事業預測方面的研究,目前仍較少。吳帥等[15]以RF模型對老年人的居住偏好進行預測表明,老年人的特征數據可以較好地預測其居住偏好。本研究通過構建RF模型和SVM模型,對烏魯木齊農村老年人的日常生活照料、醫療保健服務、精神慰藉服務和休閑娛樂服務四類養老服務需求進行預測并評價兩個模型的性能。結果表明,RF模型和SVM模型各有優勢。因本研究對象為烏魯木齊農村老年人,模型在其他特征人群中是否適用,需進一步求證。
綜上,本研究基于RF算法和SVM算法構建的模型對烏魯木齊農村老年人養老服務需求均有較好的預測能力,各有優勢。實際工作中,我們可結合不同情況,選擇合適模型預測老年人的養老服務需求,為養老事業提供參考。
猜你喜歡
保健醫苑(2022年1期)2022-08-30 08:40:44
保健醫苑(2022年6期)2022-07-08 01:25:16
保健醫苑(2022年4期)2022-05-05 06:11:20
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
基層中醫藥(2018年2期)2018-05-31 08:45:06
海峽姐妹(2018年1期)2018-04-12 06:44:24
民生周刊(2017年19期)2017-10-25 15:47:39
商周刊(2017年9期)2017-08-22 02:57:56
