引入類別關鍵詞的樸素貝葉斯林業文本分類
2022-09-16 01:30:44郭肇毅
樂山師范學院學報 2022年8期
郭肇毅
(樂山師范學院 電子信息與人工智能學院,四川 樂山 614000)
0 引言
移動互聯網的飛速發展,使得現在網絡上的文本數量越來越多,對這些文本進行有效的分類,有助于用戶快速挖掘出自己所需要的信息,而且,文本分類可以用于垃圾郵件過濾[1]、情感分析[2]、網絡輿情監測[3]等自然語言處理的常見任務中,是目前的一個研究熱點之一。
我國林業在信息化的發展過程當中,出現了很多涉及林業的網站、信息系統等,涌現出了各類的林業文本信息,對這些文本的分類,如果僅僅依靠人工,是一件十分低效的事情。因此,在建設各類涉及林業的網站、信息系統時,引入人工智能的模型,不僅能夠節約大量的人工,而且也能極大地加快林業信息化的進程。
1 研究現狀
文本分類的方法主要分為兩類:一類是基于知識工程的方法,一類是基于機器學習的各種模型的方法。使用機器學習的各種模型的方法是目前的主流方法,在這方面已經有很多學者對此進行了研究。
有研究者提出在文本分類任務中引入樸素貝葉斯的方法[4]。近年來,有學者提出了一種基于Bert 和知識圖譜融合的模型的方法來解決文本分類的任務[5]。2019 年,又有研究人員提出了一種XLNet 模型的方來進行文本分類,該方法通過對輸入的文本序列進行重新的排列、以及組合的方式,使得模型可以進行上下文的兩個方向上的學習,并且,又避免了Bert 中的兩個階段的學習數據分布不統一的問題[6]。此外,又有科研人員提出了ALBERT 模型,來對Bert 模型進行改進,提升其性能[7]。隨著LSTM 模型的提出,有研究人員采取LSTM-TextCNN 相結合的方式進行文本分類[8]。
對于特定的行業領域,例如,林業文本的分類,目前的專門的研究還較少,但也有研究人員提出用通過使用LM 優化模糊神經網絡模型的方法來進行文本分類[9]。但是,總的說來,這方面的研究還不太成熟。
縱觀這些機器學習的模型,若是比較復雜的神經網絡類的模型,分類效果確實不錯,但是其耗費的時間、硬件資源等都十分巨大,對于某些單位而言,很多時候不需要那么精準的分類,看重的是綜合的成本,使用樸素貝葉斯模型來進行分類,既能獲得較高的分類精準度,所花費的成本也不高,是一個比較合適的選擇。而在原始的樸素貝葉斯模型基礎上,根據特定的領域的分類任務,例如,林業文本,引入每種林業文本類別中的高頻關鍵詞的因素,可以在不額外增加成本的基礎上,進一步提高文本分類的精準程度,是十分有意義的。
具體地,例如,對于一個林業文本,如果其中出現得有“旅游”“自駕”等字樣,那么,可以認為這個林業文本很可能屬于一篇關于林業旅游方面的文本。因此,在用原始的樸素貝葉斯對文本進行分類的基礎上,在考慮這些關鍵詞的因素,能夠使得分類的效果更精準,而且也沒有額外增加成本,是一個不錯的選擇。
2 相關工作
文本分類的流程大體上可以分為文本的預處理、文本的特征表示和分類器的構建。具體過程如圖1 所示:
2.1 文本的預處理
因為中文不像英文,單詞與單詞都有天然的空格進行分隔,所以在文本的預處理階段,需要對中文文本進行分詞。目前市面上已經有很成熟的分詞工具可供使用,例如,斯坦福的分詞工具,中科院的分詞工具等。這里采用的是中科院的分詞工具。同時,中文中存在很多沒有實在意義的“的”“了”等助詞,這類詞叫做停用詞,去掉這類詞,對于文本本身的意思沒有任何影響,目前市面上也有很多不同版本的停用詞庫,這里采用的是百度的停用詞庫。
2.2 文本的特征表示
一篇文本是無法真正意義上被計算機理解的,就需要用文本的某些特征來表征這篇文本。這里采用的是用文本中的具有區分度的高頻詞來表征一篇文本。所用到的算法是tf-idf 算法[10]。tf-idf 算法的公式如式(1)(2)所示:

簡單而言,tf-idf 選出的是具有區分度的高頻詞,例如,假如一篇文本出現了很多次“桂花”“買賣”這兩個詞,但若語料庫中的其他文檔中也出現了很多次“買賣”這個詞,但是這些其他文檔中極少出現“桂花”這個詞,那么,對于那篇文本而言,“桂花”才是一個具有文本區分度的高頻詞,而“買賣”不是。所以,tf-idf選出的就是諸如“桂花”這類具有文檔區分度的高頻詞,而不是隨便一個高頻詞就選出來。
2.3 構建分類器
采用的是用樸素貝葉斯的算法思想,通過訓練語料構建分類器,然后隨后進行分類效果的測評。貝葉斯的公式如式(3)所示:
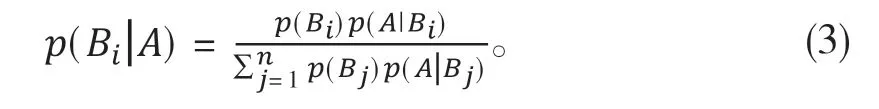
當貝葉斯公式用于文本分類時的原理大體如下:


3 引入類別關鍵詞的樸素貝葉斯
文章主要在原始的樸素貝葉斯算法的基礎上,引入類別關鍵詞的因素,從而提高分類的精準度。
對于一篇林業文本,在用樸素貝葉斯進行相應計算的基礎上,引入類別關鍵詞的因素,從而提高分類的精準度。例如,對于一個林業文本,如果其中有某方面文本的標志性字樣,那么,可以認為這個林業文本很可能屬于一篇那個特定方面的文本。因此,在用原始的樸素貝葉斯對文本進行分類的基礎上,在考慮這些關鍵詞的因素,能夠使得分類的效果更精準,而且也沒有額外增加成本,是一個不錯的選擇。
具體而言,如式(16)所示:
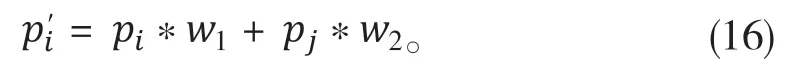
上式中,是要進行類別判定時的最終概率值,是原始樸素貝葉斯計算出的概率值,是根據經驗給類別關鍵詞設定的一個概率值,和是權重值,二者的和為1,且要比大。
為解決數據稀疏性問題,平滑技術采用加1平滑。
4 具體實驗
4.1 實驗數據
實驗采用的文本數據來源于網絡,有4 個類別,分別是“花木商情”“林業科技”“林業旅游”和“林業資源管理”。訓練語料有1016 篇,4 個類別分別占的數目為96、374、84 和462。測試語料共有255 篇,4 個類別分別占的數目為24、94、21 和116。
每篇文本用tf-idf 提取出5 個具有區分度的高頻詞作為文本特征詞。
根據4 個類別的特點,根據經驗準備4 個類別關鍵詞列表,例如“林業旅游”關鍵詞列表中就有“旅游”“風景區”等和旅游高度相關的詞。
4.2 實驗過程
實驗的具體過程如圖2 所示:
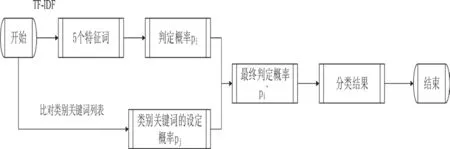
圖2 實驗流程圖
也就是,最初,對文本進行預處理,對比停用詞表去除停用詞,通過tf-idf 找出每篇文檔的5 個特征詞,根據貝葉斯公式進行判定概率的計算。同時,將分詞后的文本中的所有詞匯與類別關鍵詞列表進行比對,根據比對結果計算出另一個判定概率,然后,根據公式(16)計算出最終的判定概率,比較4 個最終的判定概率,最后判定文檔屬于哪個類別。
4.3 性能指標
性能指標采用自然語言處理常用的準確率和召回率,以及二者的綜合評價值F 值作為評價指標。
對于文本分類任務,precision和recall的計算公式如下所示:

4.4 實驗結果
根據(16)式中的公式,根據2-8 準則,選取和分別取80%和20%,以F 值為評價標準,得到的實驗結果分別如下圖所示。其中,圖3 是考慮平滑的情況,圖4 是沒有考慮平滑的情況。
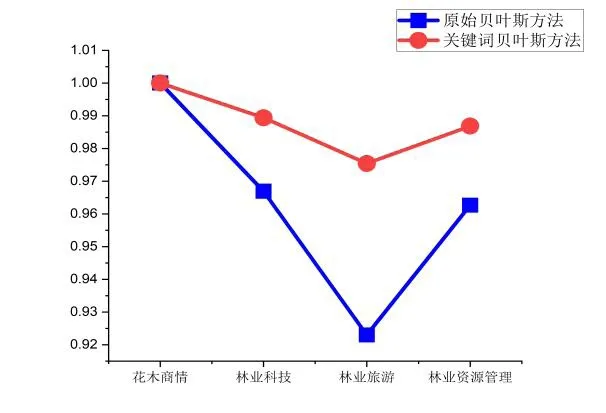
圖3 考慮平滑實驗結果圖
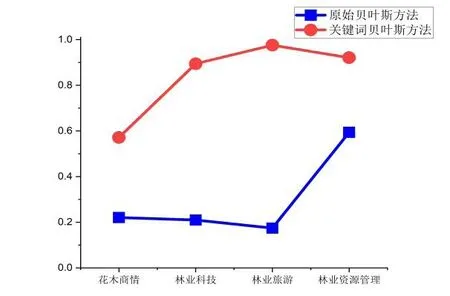
圖4 不考慮平滑實驗結果圖
考慮了平滑的具體的每種文檔的判定結果數如表1 所示:
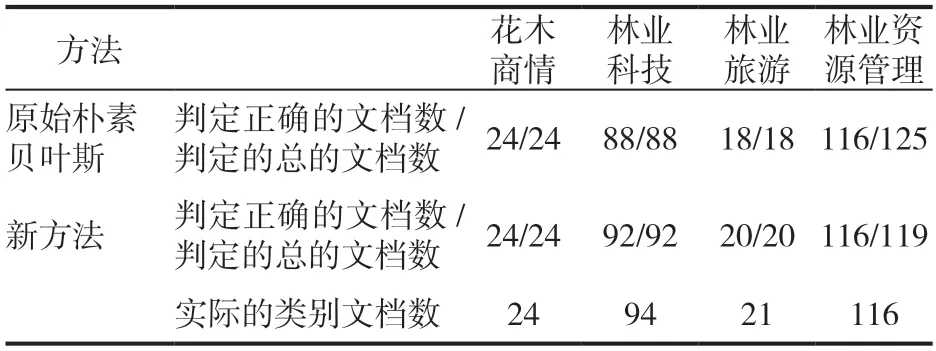
表1 考慮平滑每類文檔的判定結果數
從上述的圖表可以看出,引入了類別關鍵詞因素的樸素貝葉斯的方法在綜合性能上要優于原始的樸素貝葉斯方法,這說明了在用樸素貝葉斯進行文本分類時,引入類別關鍵詞的方法,是有意義的嘗試。特別是不考慮的平滑的情況下,引入了類別關鍵詞因素的方法的優勢更加明顯,說明在不考慮平滑的這種比較簡單粗暴的情況下,引入一些細節性的因素,效果更好。
而沒有考慮平滑的具體的每種文檔的判定結果數如表2 所示:
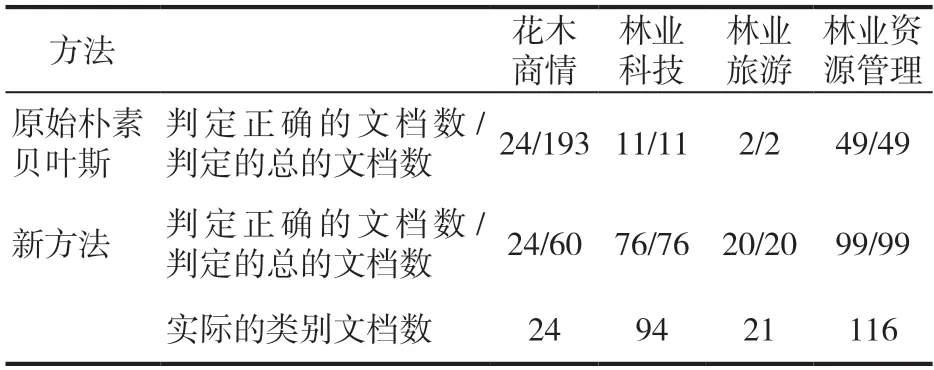
表2 不考慮平滑每類文檔的判定結果數
5 結論和展望
從實驗可以看出,引入了類別關鍵詞因素的樸素貝葉斯方法,相比原始的樸素貝葉斯的方法,效果更好。特別是對于不考慮平滑的這種簡單粗暴的情況,引入了類別關鍵詞因素這些較為細節的因素,實驗結果更好。
從工程應用的角度來看,樸素貝葉斯這類簡單有效的方法已經能夠運用于很多工程實際問題了,對于分類精準度要求不那么高的很多實際工程應用,樸素貝葉斯類的方法已經夠用了,在實際問題中,如果對經濟成本、硬件資源等要求較為苛刻的情況,完全沒有必要使用神經網絡類的模型。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
