基于Stacking 模型融合的網絡異常事件監測
2022-09-16 01:30:44張建東劉才銘
樂山師范學院學報 2022年8期
張建東,劉才銘,李 勤
(樂山師范學院 a.電子信息與人工智能學院;b.網絡安全智能檢測與評估實驗室,四川 樂山 614000)
0 引言
互聯網的發展有助于創造一個更加方便文明的社會,互聯網已經成為人們日常生活中必不可少的一部分。然而它也帶來了很多問題,比如竊取用戶隱私數據、惡意軟件、拒絕服務、垃圾郵件以及網絡攻擊。其中網絡攻擊已成為互聯網上最大的問題,造成前所未有的經濟損失。
最近幾年,人工智能技術已經在自然語言處理和圖像處理方面獲得廣泛的應用。使用機器學習解決計算機網絡領域的問題變得非常有前途。使用機器學習技術解決網絡場景里面的復雜問題,比如使用機器學習技術訓練模型來監測網絡系統的性能、識別錯誤配置和網絡攻擊[1-5]。
目前主要使用的方法有基于樹的網絡攻擊事件檢測方法[6],比較XGBoost 方法與其他分類器,如AdaBoost、樸素貝葉斯、MLP 和K-Nearest Neighbors(KNN)來解決多分類問題和二分類問題。XGBoost 不僅獲得了更高的精度,而且執行效率更高,實驗結果表明,基于樹的模型能取得更好的結果。混合監督學習集成模型[7],使用幾個極端梯度提升算法。XGBoost 和LightGBM 首先單獨處理從原始數據抽取出來的組合特征子集,再把輸出結果取均值。不同的模型使用不同的超參數設置以及不同的特征子集。通過組合獨立的高性能梯度提升算法,在競賽中獲得的較高的準確率。使用LightGBM 算法[8]和XGBoost 算法[9],在異常事件檢測中都獲得了較高的準確率。
以上提到的方法要么使用單一的算法,要么使用兩種算法的組合,我們提出的方法是使用多種最新的集成學習算法的組合,通過Stacking 模型融合來對網絡事件進行檢測,實驗結果表明本文提出的方法比單一的機器學習方法有更高的準確率。
為了提高機器學習算法的效率及準確率,我們對數據集進行了預處理、創建新特征,對部分特征進行了組合,處理后的數據集極大的提升了異常網絡事件檢測的準確率。
1 相關工作
集成學習通過構建多個模型來完成學習任務。它的工作原理是訓練多個模型,各自獨立地學習并做出預測。這些預測結果再用某種策略將他們結合起來,一般會優于單個分類器做出的預測。
機器學習有兩個核心任務;一個是解決欠擬合問題,通過boosting 算法逐步增強;另一個是解決過擬合問題,可以通過bagging(Bootstrap Aggregation)采樣學習。只要基分類器的表現不是太差,集成學習的結果一定是優于單分類器的。我們采用的基學習器都使用集成學習算法,分別是XGBoost、CatBoost、RandomForest 和LightGBM。
1.1 XGBoost
Boosting 用于有監督的機器學習,通過將一組弱分類器組合成一個強分類器來建立模型,提高分類預測精度,可以非常有效地減少預測偏差。梯度提升(GB,Gradient Boosting) 是boosting 的擴展,也是通過一定方法將弱分類器融合,提升為強分類器。梯度提升決策樹(GBDT,Gradient Boosting Decision Tree)是決策樹的集成模型,將損失函數梯度下降的方向作為優化的目標。XGBoost 是GBDT 的改進,GBDT 在優化時只用到一階導數,XGBoost 在每一輪學習中,對損失函數進行二階泰勒展開,使用一階和二階導數進行優化。在各種數據科學競賽中,XGBoost 成為競賽者們奪冠的利器。
XGBoost 在目標函數里加入了正則化項,用于控制模型的復雜度,為避免過擬合,正則化項一般選擇簡單模型。正則化項里通過樹的葉子節點個數來控制樹的復雜度。正則項降低了模型的方差,使學習出來的模型更加簡單,這也是XGBoost 優于GBDT 的一個特性。XGBoost 在訓練樣本有限,訓練時間短的場景下具有獨特的優勢。
1.2 Catboost
CatBoost 是一種新的boosting 模型,是GBDT算法框架下的一種改進實現。CatBoost 對數據集中的類別特征能更好的表示和處理。在某些場景下比XGBoost 和LightGBM 更好。主要缺點是,對類別特征的處理需要耗費大量的內存和時間,隨機數的設定對模型預測結果也有一定的影響。
1.3 LightGBM
LightGBM(Light Gradient Boosting Machine)是一個實現GBDT 算法的框架,支持分布式訓練,可以處理海量數據,具有更快的訓練速度,同時內存消耗更低。
1.4 RandomForest
隨機森林屬于集成學習中bagging 方法。隨機森林是bagging 與決策樹的組合。用隨機的方式建立一個森林,森林由眾多決策樹組成,每棵決策樹都是沒有關聯的,其輸出的類別是每棵決策樹投票的結果。
隨機森林中基學習器的多樣性不僅來自樣本的隨機性,還來自屬性的隨機性,最終模型的泛化能力通過基學習器之間差異度的增加而進一步提升。
2 Stacking 模型融合
使用模型融合的好處主要有三個:a)單個模型可能會導致泛化能力不佳,使用多個模型可以減少這一風險;b)學習算法可能陷入局部極小,其對應的泛化性能降低;c)某些任務的假設可能不在當前模型的假設空間內,使用單個模型可能無效,結合多個模型可能學的更好的近似。
基學習器的集成方法有均值法,投票法,學習法[10]。針對實驗數據集和輸出結果的特征,本文采用的方法為學習法。
使用的單個算法有基于集成學習的XGBoost、CatBoost、RandomForest、LightGBM 四種高效算法。
Stacking(堆疊)是用于組合來自多個模型的信息以生成新模型的模型融合技術。首先訓練好所有的基模型,然后把基模型的預測結果連接,生成新的數據,作為第二層模型的輸入,用來訓練第二層模型,最終得到預測結果。
通常,堆疊模型(也稱為二級模型)將多種模型按照一定的方式組合在一起,將不同模型的各自優勢發揮出來進而提升模型整體的性能。因此,當基模型差異較大時,堆疊是最有效的。把主流的四種集成學習算法的輸出結果用LogisticsRegression 融合,模型框架如圖1 所示。
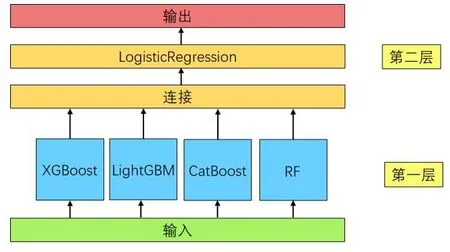
圖1 兩層stacking 模型
3 網絡異常事件檢測
3.1 數據集介紹
數據集為Suspicious Network Event Recognition,數據集是采集自2018.10.1 到2019.3.31,總共6 個月的數據。數據集包含安全警報及其描述性屬性,以遞增的詳細級別發布,直到實際警報之前的安全事件序列。兩個數據集的詳細說明如下:
第一個數據集(Cybersecurity_train)。告警事件數據集,訓練數據集包含63 個特征屬性,一個目標屬性。主要特征包括警告的相關信息,比如客戶端的代碼、IP、IP 分類、開始的時間、事件的源和目標等。
數據集為不平衡數據集,目標值notified 占比僅為5.8%(2276/39427)。
第二個數據集(Localized_alerts_data)。包含警告事件的更多細節,比如特定的警告類型、代碼,設備廠商、源和目標IP 及端口、時間、嚴重程度、用戶名、通信協議等。表1 為數據集整體概覽。

表1 數據集整體概覽
3.2 數據處理
缺失值處理:根據列的特征采用固定值或平均值來填充缺失值。
創建新特征:Localized 數據集抽取新特征以提供額外的信息,按照alert_ids 分組統計alerttime 的最大值、平均值,severity 的平均值,最大值和最小值,生成新特征。并對特殊的特征進行處理,比如IP 地址和時間。
類別數據的處理:大多是機器學習算法使用數值型數據作為輸入,因此對非數值型的數據采用one-hot 編碼轉換成數值型。
兩個數據集的合并:按照alert_ids 對處理后的兩個數據集進行合并。
3.3 實驗環境
實驗環境:windows10,Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz,內存32G。
工具集:Pyton3,pandas,scikit-learn,Keras 進行特征工程、特征選擇以及算法實現。
評估方法:本文使用AUC、準確率作為實驗性能的評估方法。
AUC:主要用于評價不平衡的二分類算法。由于數據集的目標值是二分類的,因此主要的評估指標為AUC。ROC 曲線的縱軸為TPR(True Positive Rate),橫軸為FPR(False Positive Rate),判斷模型的好壞就是計算ROC曲線下(0,0)到(1,1)的面積AUC(Area Under ROC Curve),面積越大,模型越準確。
準確率:總樣本中預測正確的有幾個正確,是最常見的評價指標。準確率的定義為公式1。
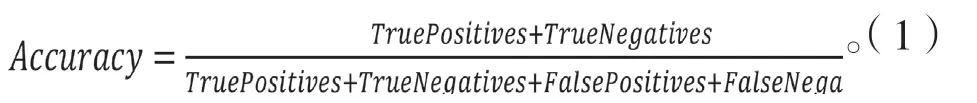
3.4 實驗結果
實驗結果如表2 所示,從表中可以看出4種算法融合模型的AUC最高,準確率比XGBoost稍低,比其他三種算法都高。從表中可以看出單個模型的AUC 全部都低于融合模型的AUC,因為沒有一種算法能適應各種不同的場景,因此嘗試使用不同的算法來實現預測,同時把多個性能較好的算法進行集成可以進一步提升模型預測的準確性。
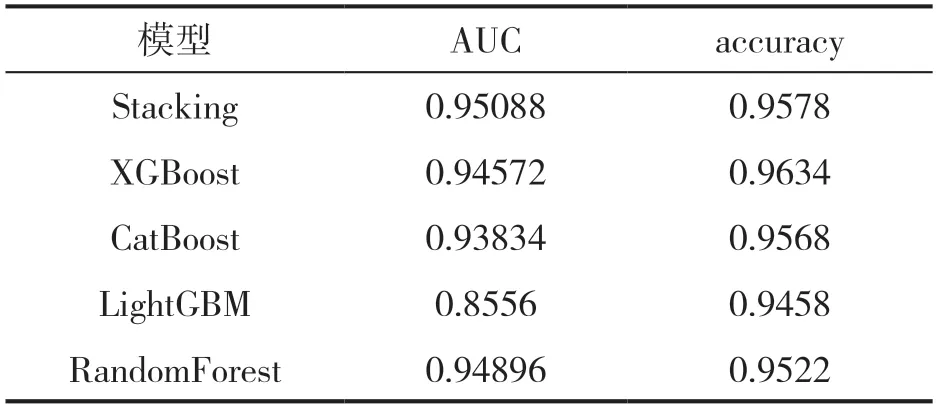
表2 模型的性能對比
4 結論
為了從各種網絡日志中發現異常事件,本文提出一種Stacking 模型融合的方法來檢測異常事件,并在Suspicious Network Event Recognition 數據集上分別使用最新的集成學習算法XGBoost、CatBoost、RandomForest、LightGBM構建了異常檢測模型,用Stacking模型融合,用LogisticsRegression 生成最后的模型,通過實驗對比得出結論如下:
模型融合較單個模型有優勢,模型融合的復雜度不高,結果更加準確。機器學習中模型融合比單個模型的準確率高,泛化能力更強,在實驗場景中效果更好。
在后期工作中將重點研究其他高效集成學習方法及其他模型融合方法,來提高網絡異常事件預測的準確率。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
