基于優(yōu)化混合模型的航空發(fā)動機剩余壽命預測方法
2022-09-25 08:43:22劉月峰張小燕郭威邊浩東何瀅婕
計算機應用 2022年9期
劉月峰,張小燕,郭威,邊浩東,何瀅婕
(內(nèi)蒙古科技大學信息工程學院,內(nèi)蒙古包頭 014010)
0 引言
預測和健康管理(Prognostics and Health Management,PHM)系統(tǒng)能夠為設備的故障預測提供重要依據(jù),剩余使用壽命(Remaining Useful Life,RUL)預測作為PHM 的重要組成部分,對于維護設備的正常運行至關重要。通過準確的RUL 預測,可以提前設計維護方案來保持設備的正常工作狀態(tài),避免突發(fā)事故造成的巨大經(jīng)濟損失。通常將RUL 的預測方法大致分為基于模型的方法[1]、數(shù)據(jù)驅(qū)動方法[2]和混合方法[3]三類。基于模型的方法,通常需要構(gòu)建數(shù)學模型來描述設備的退化過程,但隨著工業(yè)的迅速發(fā)展,機械系統(tǒng)復雜程度越來越高,設備相互之間的聯(lián)系也日趨復雜,建立準確的模型變得不太現(xiàn)實,并且基于模型的設計方法其靈活性以及可移植性較差。混合方法是基于模型與數(shù)據(jù)驅(qū)動方法的結(jié)合體,想要同時利用兩個方法的優(yōu)勢且規(guī)避其缺點依然存在較大的挑戰(zhàn)。因此,使用數(shù)據(jù)驅(qū)動方法來預測RUL 受到越來越多學者的關注。數(shù)據(jù)驅(qū)動方法經(jīng)常用于預測系統(tǒng)的RUL,其預測結(jié)果能很好地表現(xiàn)設備健康狀況,其中,特征集的有效構(gòu)造是影響數(shù)據(jù)驅(qū)動方法效果的關鍵因素之一。當前主流的傳感器選擇策略包括:刪除值為恒定的傳感器數(shù)據(jù),選擇剩余數(shù)據(jù)組成新的數(shù)據(jù)集[4-8];依據(jù)相關系數(shù)選擇傳感器數(shù)據(jù)[9-10];使用單調(diào)性、可預測性以及趨勢性來選擇有代表性的傳感器數(shù)據(jù)[11];通過分析單調(diào)性和相關性來實現(xiàn)傳感器的選擇[12-13]。選取合適的傳感器數(shù)據(jù)后,相應方法的選擇也決定了最終的預測效果。在數(shù)據(jù)驅(qū)動方法中,很多機器學習方法在RUL 預測中有不錯的表現(xiàn):Ompusunggu 等[14]提出利用卡爾曼濾波(Kalman Filter,KF)進行自動變速器離合器RUL 預測;Javed 等[15]使用極限學習機(Extreme Learning Machine,ELM)來預測鋰電池的RUL;Wu 等[16]使用隨機森林(Random Forest,RF)方法用于診斷發(fā)動機轉(zhuǎn)子的故障情況。目前,深度學習方法也被廣泛用于處理狀態(tài)監(jiān)測數(shù)據(jù)以預測工業(yè)系統(tǒng)的RUL,其中,長短期記憶(Long Short-Term Memory,LSTM)網(wǎng)絡利用3 個控制門來傳遞長期時序特征信息。Wu 等[17]使用香草LSTM 預測發(fā)動機的RUL;李京峰等[18]利用LSTM 與深度置信網(wǎng)絡(Deep Belief Network,DBN)的組合用于預測航空發(fā)動機的RUL。卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network,CNN)擁有很強的學習能力,能夠很好地提取數(shù)據(jù)局部特征,如Li 等[19]首次使用多層CNN 用于預測軸承的RUL。雙向長短期記憶(Bidirectional Long Short-Term Memory,Bi-LSTM)網(wǎng)絡是LSTM 的進一步優(yōu)化,利用雙層反向的LSTM 來對時序數(shù)據(jù)進行處理,獲得更多有用的提取特征。Al-Dulaimi 等[4]通過將一維卷積神經(jīng)網(wǎng)絡(One-Dimensional Convolutional Neural Network,1D-CNN)和LSTM 以及Bi-LSTM 組合用于預測渦輪風扇發(fā)動機的RUL;Liu 等[20]將Bi-LSTM 和CNN 進行合理組合用于預測發(fā)動機的RUL。時序卷積網(wǎng)絡(Temporal Convolutional Network,TCN)是一種特殊的卷積神經(jīng)網(wǎng)絡也被用于預測發(fā)動機RUL,利用因果卷積、擴張卷積以及殘差連接來提取特征。朱霖等[21]利用遺傳算法和時序卷積網(wǎng)絡的組合來預測渦扇發(fā)動機RUL。這些網(wǎng)絡的共同特點是都將重點放在最后一個時間步上,但是也許在其他時間步中學習的特征也會對最終的RUL 預測有不同程度的貢獻。因此,將不同權重分配給不同時間步下各種特征就顯得尤為重要。目前,注意力機制能夠很好地解決這一問題,即為不同特征提供不同的注意力權重,這使得注意力機制受到學者的廣泛關注。Liu等[22]提出注意力機制直接加權輸入特征,使得網(wǎng)絡在訓練中動態(tài)地將注意力放在那些重要特征上;Jiang 等[23]將注意力機制與時間卷積網(wǎng)絡結(jié)合用于預測渦輪發(fā)動機的RUL,時間卷積網(wǎng)絡的輸出作為注意力機制的輸入可以更好地加權關鍵特征;Das 等[24]將注意力機制與深度LSTM 相結(jié)合用于預測發(fā)動機的RUL,運用注意力機制來權衡較早的時間步長用于RUL 預測。
綜上所述,本文提出了一種優(yōu)化混合模型來預測航空發(fā)動機的RUL,采用融合多路徑特征預測RUL 的思想,選擇三種不同的路徑提取特征:第一,將原始數(shù)據(jù)的均值和趨勢系數(shù)輸入全連接網(wǎng)絡獲得第1 條路徑的提取特征;第二,原始數(shù)據(jù)經(jīng)過Bi-LSTM 學習,Bi-LSTM 輸出數(shù)據(jù)再經(jīng)過注意力機制給予重要輸出特征更大的權重,獲得第2 條路徑的提取特征;第三,將注意力機制直接作用于輸入數(shù)據(jù),加權特征再輸入CNN 與Bi-LSTM 中,使得CNN 與Bi-LSTM 模型訓練過程中把注意力集中在重要特征上,獲得第3 條路徑的提取特征。將以上輸出特征融合在一起作為輸入傳給全連接網(wǎng)絡用于預測航空發(fā)動機的RUL。所提方法通過商用模塊化航空推進系統(tǒng)仿真(Company-Modular Aero-Propulsion System Simulation,C-MAPSS)數(shù)據(jù)集進行驗證,同其他RUL 預測方法相比具有較高的準確性。本文的主要貢獻包括:
1)提出了基于優(yōu)化混合模型框架,前置注意力機制作用于輸入數(shù)據(jù),經(jīng)過CNN 與Bi-LSTM 可以學習更重要特征。注意力機制置于Bi-LSTM 之后可以更好地關注網(wǎng)絡輸出的關鍵特征,以獲得更多有效特征。
2)C-MAPSS 數(shù)據(jù)集擁有多種傳感器的測量數(shù)據(jù),從數(shù)據(jù)集中選取不同傳感器的數(shù)據(jù)可能對RUL 預測產(chǎn)生較大的影響,所以本文從不同角度選擇傳感器數(shù)據(jù),探究其對模型預測的影響程度。
3)使用C-MAPSS 數(shù)據(jù)集來評估本文方法的有效性,結(jié)果顯示,該方法比其他方法具有較高的RUL 預測性能。
1 優(yōu)化混合模型的RUL預測方法
本文提出了一種優(yōu)化混合方法來預測航空發(fā)動機的RUL,該模型由3 個并行路徑組成,如圖1 所示。第一條路徑,提取原始數(shù)據(jù)的均值和趨勢系數(shù),提取特征輸入全連接網(wǎng)絡;第二條路徑,原始數(shù)據(jù)經(jīng)過Bi-LSTM 網(wǎng)絡學習,然后將注意力機制作用于Bi-LSTM 輸出數(shù)據(jù),能夠從大量提取特征中加權關鍵特征;第三條路徑,注意力機制作用于原始傳感器數(shù)據(jù),對原始數(shù)據(jù)進行特征加權,加權處理的特征再經(jīng)過CNN 和Bi-LSTM,學習數(shù)據(jù)的局部特征和長期依賴性。通過3 條并行路徑分別處理原始數(shù)據(jù)獲得特征的不同表現(xiàn)形式,將3 條路徑的輸出特征經(jīng)過concatenate 函數(shù)進行特征融合后輸入至全連接網(wǎng)絡進一步預測航空發(fā)動機的RUL。

圖1 模型結(jié)構(gòu)Fig.1 Model structure
1.1 全連接網(wǎng)絡與手工特征提取
本文提取了原始傳感器數(shù)據(jù)的手工特征(Handcrafted Features),具體包括數(shù)據(jù)的均值和趨勢系數(shù),并將獲得的數(shù)據(jù)經(jīng)過全連接網(wǎng)絡可以提取更多的抽象特征。平均值能夠表示傳感器數(shù)據(jù)的大小,相應的趨勢系數(shù)則表示傳感器數(shù)據(jù)的退化趨勢,并且提取特征的優(yōu)勢已經(jīng)在文獻[25-26]上得到驗證,能夠為RUL 預測提供幫助,以提高網(wǎng)絡的預測精度,如圖2 所示。
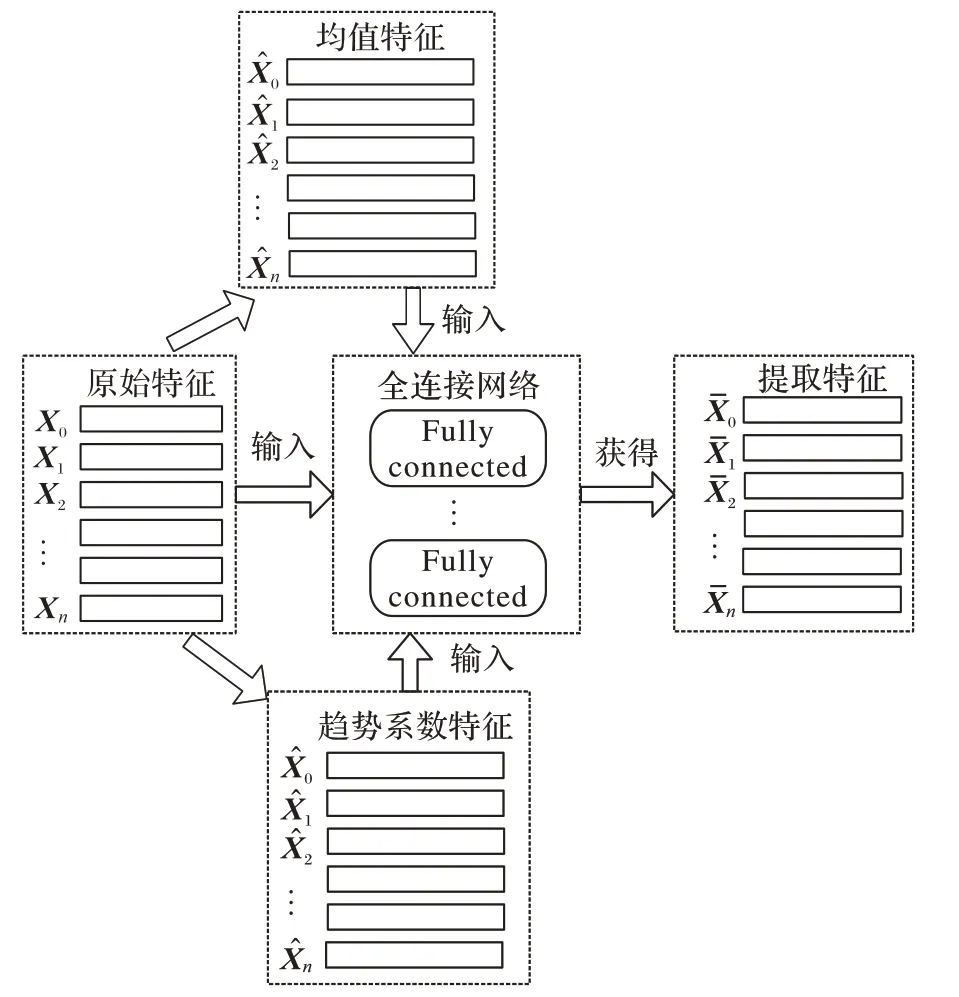
圖2 特征提取示意圖Fig.2 Schematic diagram of feature extraction
1.2 Bi-LSTM與后置注意力機制
將原始特征經(jīng)過歸一化和滑動時間窗處理后傳入Bi-LSTM 進行初步的特征學習,Bi-LSTM 獲得的提取特征作為注意力機制的輸入數(shù)據(jù),注意力機制可以為網(wǎng)絡輸出的重要特征分配更大的權重,有助于提高RUL 預測的準確性,具體流程如圖3 所示。
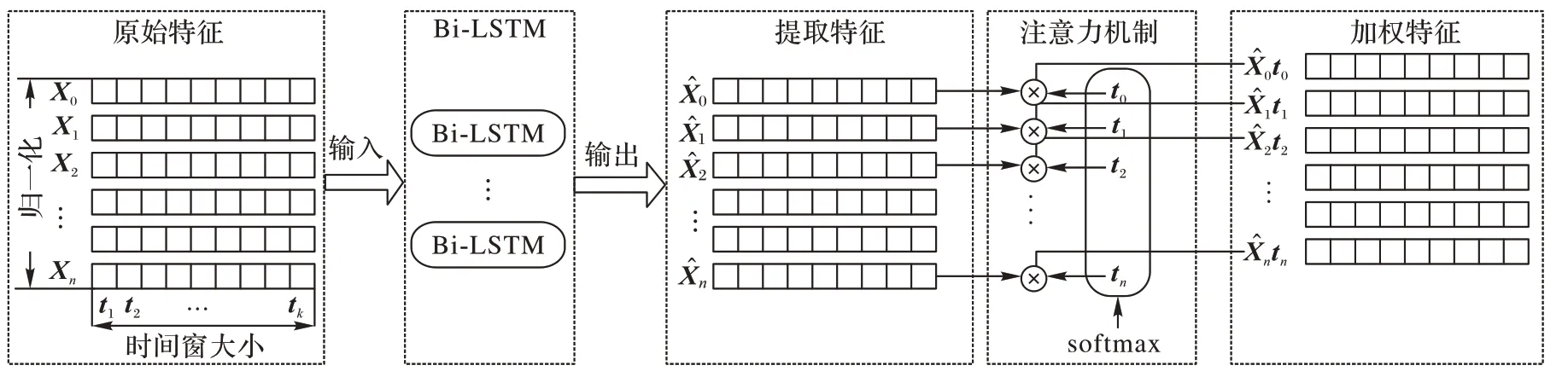
圖3 Bi-LSTM與后置注意力機制Fig.3 Bi-LSTM and post-attention mechanism
為了最大化利用輸入數(shù)據(jù),學習特征的雙向長期依賴關系,本文使用Bi-LSTM 網(wǎng)絡進行特征學習,Bi-LSTM 在傳統(tǒng)的LSTM 基礎之上被提出,已經(jīng)在很多領域被證明比單向的LSTM 更具有優(yōu)勢,例如:自然語言處理和語音識別等。Bi-LSTM 包括兩層LSTM 且兩層的信息傳遞方向相反(正方向和反方向),最終的輸出序列是兩層結(jié)果的結(jié)合。在時刻t處,Bi-LSTM 模型計算正反兩個方向的值(和),最終的輸出hb是兩個值的結(jié)合。由于前向傳播與反向傳播的表達公式相同,所以只表示了前向傳播過程的公式以及最終的輸出結(jié)果,具體由式(1)~(7)所示:

注意力機制的提出是受人類視覺的啟發(fā),在圖像信息處理過程中,人會有選擇地注意信息中的某些區(qū)域,對圖像的不同區(qū)域給予不同的重視程度,即不同區(qū)域分配的權重不同。目前,注意力機制被廣泛應用于許多領域,如自然語言處理和時間序列預測等。
為了更準確地預測航空發(fā)動機的RUL,本文引入注意力機制為不同時間步長的特征分配不一樣的權重,將更大的權重分配給重要特征。一個數(shù)據(jù)樣本通過Bi-LSTM 網(wǎng)絡獲得的特征表達為F=,T 表示進行轉(zhuǎn)置運算。基于注意力機制,在時間步長i輸出特征的重要性表達為:

其中:W和b分別用于表示權重以及偏置,Ui代表特征的得分函數(shù),計算特征的得分后,對其使用softmax 函數(shù)實現(xiàn)歸一化,表達式如下所示:
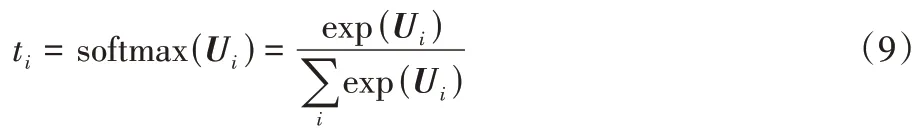
最終通過注意力輸出的特征表示為:

其中:B={t1,t2,…,td},?代表乘法運算。
1.3 前置注意力機制與CNN和Bi-LSTM
將原始數(shù)據(jù)輸入注意力機制可以給予數(shù)據(jù)中關鍵特征更大的權重,輸出的加權數(shù)據(jù)傳入到CNN 中提取數(shù)據(jù)的局部特征,再將數(shù)據(jù)傳輸?shù)紹i-LSTM 網(wǎng)絡中學習數(shù)據(jù)之間的長期依賴關系。前置注意力機制能夠使得CNN 與Bi-LSTM 網(wǎng)絡在訓練過程中動態(tài)地將更多注意力集中在更重要的特征上,從而使得網(wǎng)絡學習的特征是具有代表性的,輸出的結(jié)果能夠很好地表示輸入數(shù)據(jù)特征,為下一步RUL 的準確預測提供了堅實的基礎,具體流程如圖4 所示。
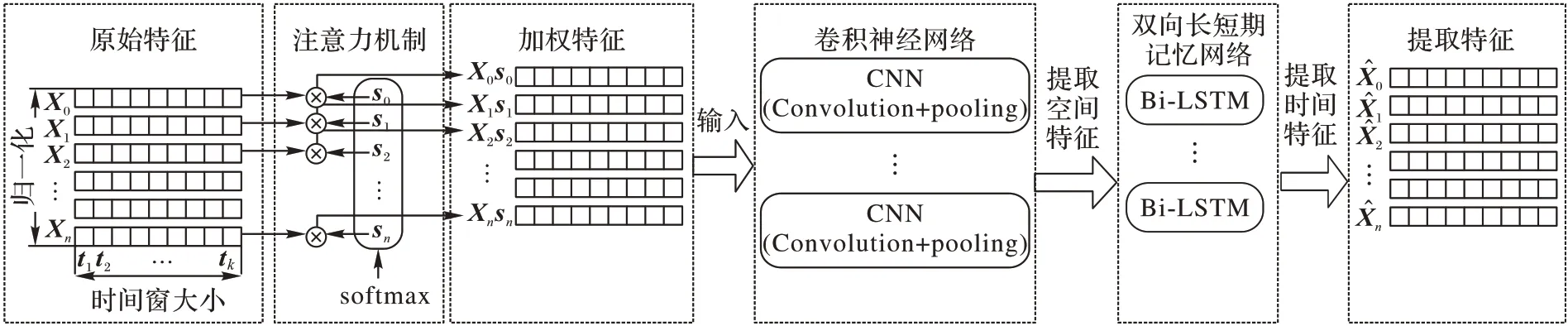
圖4 前置注意力機制與CNN+Bi-LSTMFig.4 Pre-attention mechanism and CNN+Bi-LSTM
由于輸入數(shù)據(jù)的信息量巨大,如果每個數(shù)據(jù)在網(wǎng)絡中擁有相同的重視程度,模型對數(shù)據(jù)的學習效果會受到制約。為了能給預測模型提供更多重要的輸入特征,提出了使用注意力機制進行原始特征加權,對不同特征給予不同的權重,在大量的輸入數(shù)據(jù)中聚焦學習關鍵的數(shù)據(jù),減少對其他數(shù)據(jù)的學習,能解決網(wǎng)絡信息過載導致學習效率下降的問題,幫助提高模型RUL 的預測準確性。一個數(shù)據(jù)樣本的輸入特征表示為X={X1,X2,…,Xd}T,T 表示轉(zhuǎn)置運算。基于注意力機制,在時間步長i原始數(shù)據(jù)Xi的重要程度表達為:

其中:W和b分別用于表示權重以及偏置,φ(·)能夠代表特征的得分函數(shù),獲得Xi特征的得分后,對其使用softmax 函數(shù)實現(xiàn)歸一化,表達式如下所示:
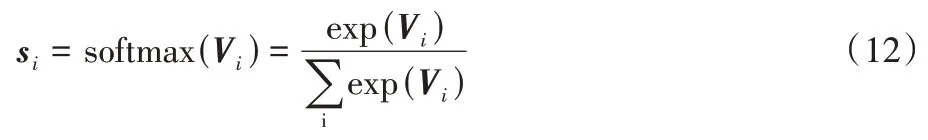
最終通過注意力輸出的特征表示為:

其中:C={s1,s2,…,sd},?代表乘法運算。
CNN 最先被應用于圖像處理領域,近些年也被廣泛用于處理時序問題。在本模型中,CNN 置于注意力機制之后提取數(shù)據(jù)的空間特征,該網(wǎng)絡中分別包含了卷積層和池化層,其中,卷積層中利用多個過濾器提取數(shù)據(jù)的空間特征,池化層的作用在于選擇最重要的信息。在卷積層中,輸入的數(shù)據(jù)通過與過濾器卷積來生成包含許多局部特征的特征圖。卷積之后得到的特征圖繼續(xù)經(jīng)過池化層執(zhí)行下采樣,模型中池化層采用最大池化。經(jīng)過CNN 學習后,為了捕獲特征之間的雙向長時間依賴性,Bi-LSTM 被用于池化層之后進一步學習數(shù)據(jù),使用Bi-LSTM 的作用是能夠處理兩個方向的時間序列,作為正向的信息流LSTM 可以進行預測,而反向的LSTM能使預測更加平滑。
2 實驗研究與結(jié)果討論
2.1 數(shù)據(jù)集描述
本文使用由美國國家航空航天局(National Aeronautics and Space Administration,NASA)提供的航空發(fā)動機仿真公開數(shù)據(jù)集來評估方法的有效性,其中,C-MAPSS 數(shù)據(jù)集包含4 個子集,每個子集包含訓練和測試集,訓練集的傳感器測量值記錄運行開始時間到最終故障整個過程,在測試集中僅記錄到故障發(fā)生以前的持續(xù)時間。RUL 文件記錄了測試集中的真實RUL,用于評估預測RUL 方法的準確性。4 個數(shù)據(jù)集中包含兩種故障模式,F(xiàn)D001 和FD002 是由高壓壓縮機(High Pressure Compressor,HPC)引起退化,而FD003 和FD004 由于HPC 和風扇作用引起退化。每個數(shù)據(jù)集共有26列,分別包括1 列發(fā)動機號、1 列循環(huán)數(shù)、3 列操作條件以及21 列傳感器測量數(shù)據(jù),具體描述見表1。
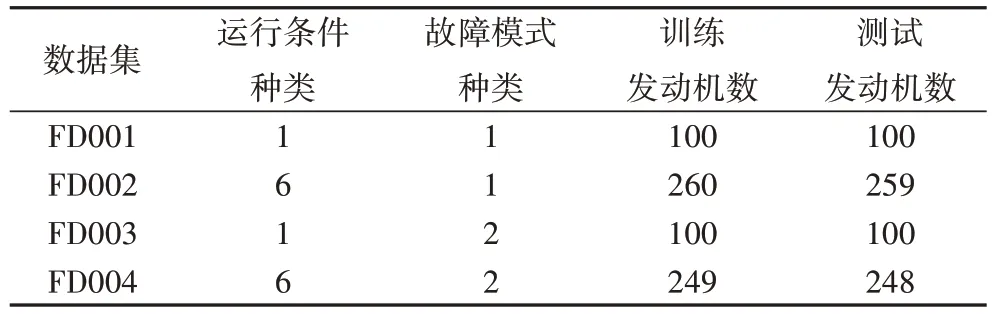
表1 C-MAPSS數(shù)據(jù)集的描述Tab.1 Description of C-MAPSS datasets
2.2 數(shù)據(jù)預處理
本文使用的FD001~FD004 數(shù)據(jù)集,由于傳感器與發(fā)動機的差異導致它們的物理特征各異,為了提升模型預測的精確度以及提高訓練的收斂速度,通常對原始輸入數(shù)據(jù)采取歸一化處理,將原始數(shù)據(jù)的大小歸一化在[0,1]:

2.3 滑動時間窗處理
經(jīng)過數(shù)據(jù)歸一化處理后,將原始數(shù)據(jù)經(jīng)過滑動時間窗(winsize)處理,生成網(wǎng)絡的輸入數(shù)據(jù),經(jīng)過時間窗口處理后的輸入數(shù)據(jù)可以表示為N=[X1,X2,…,Xn],窗口處理沿著時間維度,不同數(shù)據(jù)點之間的相關性對時序問題來說非常重要。為了捕獲這些相關性,使用時間窗口處理能夠?qū)⒍鄠€數(shù)據(jù)的關聯(lián)封裝在滑動窗口中,并且使用滑動窗口對原始數(shù)據(jù)進行處理,能夠?qū)崿F(xiàn)數(shù)據(jù)的擴充。因為設置較短的滑動步幅能夠增加輸入樣本的數(shù)量和降低訓練過擬合的風險,因此本文將滑動步幅L設置為1。為了方便顯示,如圖5 所示將滑動窗口的長度設為2,滑動步幅設為1,在實際情況下,會根據(jù)輸入數(shù)據(jù)來選取適當?shù)臅r間窗長度。一些學者研究表明,時間窗口的長度越大其包含的數(shù)據(jù)信息越多,有助于提高模型的預測性能;但時間窗長度太長,可能會增加模型的復雜性。因此,在選取時間窗長度時會綜合考量。
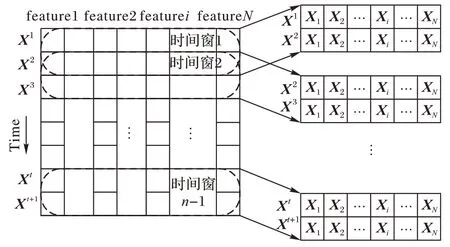
圖5 滑動時間窗口處理Fig.5 Sliding time window processing
2.4 評價指標
本文使用均方根誤差(Root Mean Square Error,RMSE)和得分(Score)函數(shù)兩個指標用于評估模型的RUL 預測性能。指標RMSE 可以用于評估模型RUL 估計的準確性,公式如下所示:

其中:d=RUL預測-RUL真實,RUL預測代表模型估計的RUL 值,RUL真實代表真實的RUL 值,n是測試數(shù)據(jù)的數(shù)量。
另一個廣泛使用的度量指標是不對稱得分函數(shù),它能夠評判模型RUL 的預測性能,不管是早期預測或是后期預測都有相對應的得分表達式。模型最好能夠進行早期預測,即得到的預測RUL 值小于真實RUL 值,這樣能在發(fā)動機發(fā)生故障之前進行維護。公式如下所示:
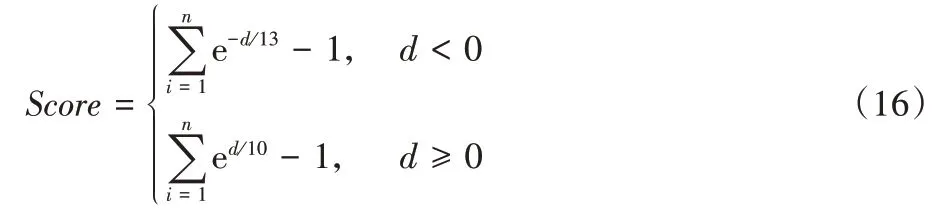
兩個評價指標的具體圖像如圖6 所示。
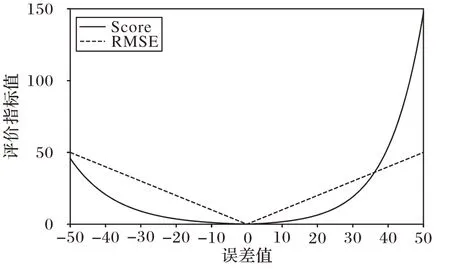
圖6 兩個評價指標的結(jié)果圖Fig.6 Result diagram of two evaluation indicators
2.5 模型的參數(shù)設置
對C-MAPSS 數(shù)據(jù)集經(jīng)過歸一化處理后,輸入的數(shù)據(jù)范圍在[0,1],通過規(guī)范化處理后,將原始數(shù)據(jù)經(jīng)過滑動時間窗處理,生成網(wǎng)絡的輸入數(shù)據(jù),由于數(shù)據(jù)量巨大,因此,選擇小批量(batch size)進行模型訓練。在訓練過程中,將數(shù)據(jù)集分為訓練集和驗證集,選擇20%作為驗證集,80%作為訓練集,為了避免過擬合現(xiàn)象,將dropout 技術應用于模型,如表2 給出了模型參數(shù)詳情。
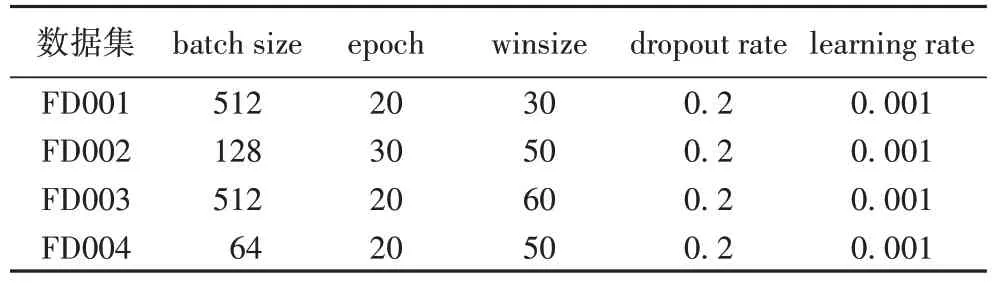
表2 參數(shù)設置Tab.2 Parameter setting
由于選取不同大小的時間窗對模型訓練效果有較大影響,因此為整個實驗選擇合適的時間窗很重要。本文根據(jù)最常用的時間窗大小采用對比擇優(yōu)的選取方法,winsize ∈{20,30,40,50,60}。在實驗訓 練的過程 中,F(xiàn)D001~FD004 選取不同時間窗的實驗結(jié)果如圖7 所示。
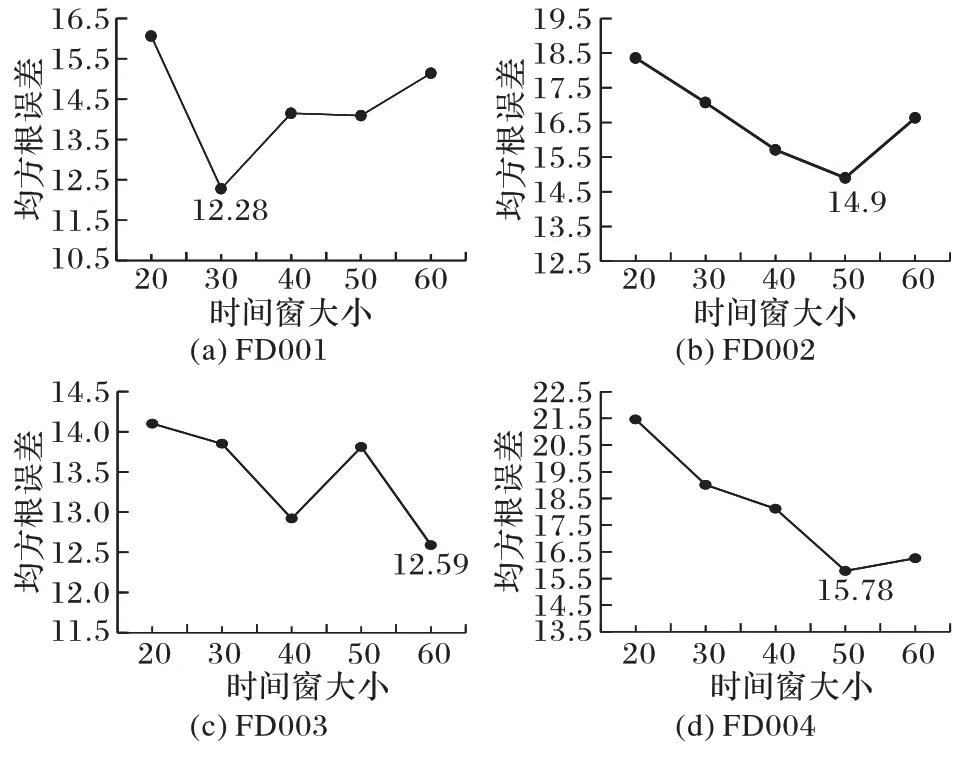
圖7 時間窗大小和RMSE的關系Fig.7 Relationship between time window size and RMSE
2.6 依據(jù)不同角度選取傳感器
學習所有傳感器的測量數(shù)據(jù)會增加模型復雜度,為了減少數(shù)據(jù)量和提高模型學習的準確度,研究者通常會刪除一些傳感器數(shù)據(jù),根據(jù)不同角度選取傳感器數(shù)據(jù)。由于不同數(shù)據(jù)攜帶的信息各異,因此,合理選擇傳感器變得十分重要,它很可能會影響模型學習的準確度。本次實驗刪除值為恒定的傳感器數(shù)據(jù),以傳感器S2、S3、S4、S7、S8、S9、S11、S12、S13、S14、S15、S17、S20 和S21 為數(shù)據(jù)集進行模型訓練,并進行模型參數(shù)的調(diào)整;然后根據(jù)其他三種角度選取傳感器數(shù)據(jù),即依據(jù)相關性、單調(diào)性和相關性的線性組合,以及單調(diào)性、可預測性和趨勢性的線性組合選取傳感器,并通過實驗來驗證選擇不同傳感器對實驗結(jié)果的影響程度。
1)相關性。
文獻[10]通過分析傳感器數(shù)據(jù)的相關性,分別依據(jù)相關性為0%、30%和60%進行劃分,其中,6 個傳感器數(shù)據(jù)的相關性為0%,7 個傳感器數(shù)據(jù)的相關性小于30%,9 個傳感器數(shù)據(jù)的相關性小于60%,具體傳感器的選擇情況如表3所示。

表3 傳感器的選擇結(jié)果Tab.3 Sensor selection results
為了減少本模型預測性能的隨機性,本文進行了多次實驗,并使用RMSE 和Score 的均值作為實驗的最終結(jié)果,實驗結(jié)果如表4 所示。
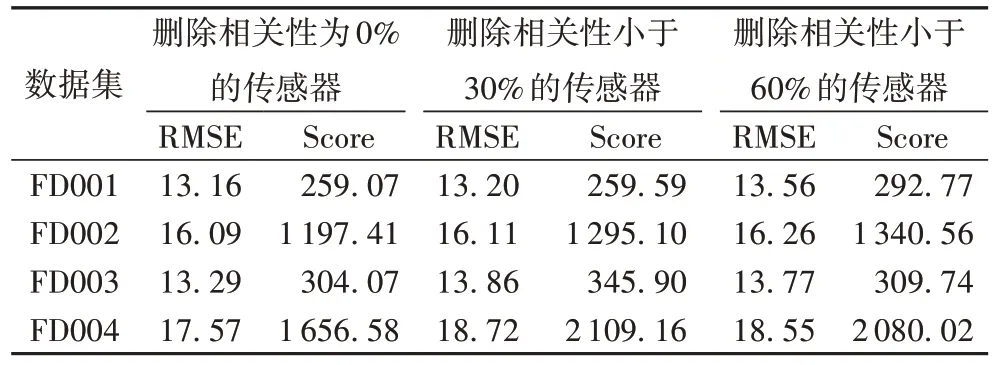
表4 刪除相關性選擇傳感器后的RMSE和Score實驗結(jié)果Tab.4 RMSE and Score experimental results with correlation selected sensors
2)單調(diào)性和相關性的線性組合。
文獻[12-13]通過計算每個傳感器數(shù)據(jù)的單調(diào)性和相關性,將兩者進行線性組合選取其值超過閾值的傳感器,最終選擇傳感器S2、S3、S4、S7、S8、S11、S12、S13、S15、S17、S20 和S21。為了減少模型實驗結(jié)果的隨機性,本文使用RMSE 和Score 多次實驗的平均值作為最終結(jié)果,實驗結(jié)果如表5 所示。
3)單調(diào)性、可預測性和趨勢性的線性組合。
文獻[11]通過使用單調(diào)性、可預測性和趨勢性的3 個指標進行線性組合來選取有意義的傳感器,最終選擇傳感器S2、S3、S4、S7、S11、S12、S15、S17、S20 和S21,實驗結(jié)果如表5所示。
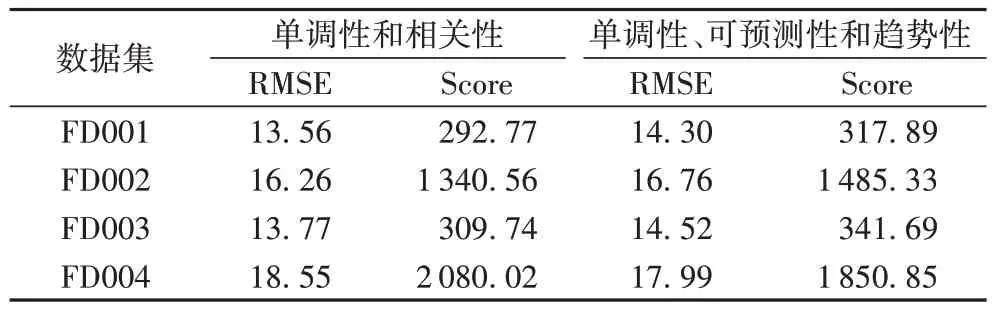
表5 兩種線性組合的RMSE和Score實驗結(jié)果Tab.5 RMSE and Score experimental results of two linear combinations
為了減少數(shù)據(jù)量和獲得更好的實驗結(jié)果,需要根據(jù)不同標準選取傳感器作為網(wǎng)絡的輸入數(shù)據(jù)。由于傳輸給網(wǎng)絡的數(shù)據(jù)不同,導致網(wǎng)絡的學習情況也存在較大差異。從以上實驗可以看出選擇不同傳感器數(shù)據(jù)對最終的結(jié)果會產(chǎn)生較大的影響。因此,合理挑選傳感器變得非常重要。如果依據(jù)相關系數(shù)選擇傳感器,則刪除相關性為0%的傳感器數(shù)據(jù),得到的實驗效果較好,而相比其他選取傳感器的方法,實驗結(jié)果顯示刪除恒定值的傳感器測量數(shù)據(jù),剩余傳感器數(shù)據(jù)組成新的數(shù)據(jù)集獲得的實驗結(jié)果是最優(yōu)的。
2.7 結(jié)果與分析
1)消融實驗。
為了驗證提出模型的有效性,對本文方法進行了消融研究。具體來說,本文將組成模型的3 條路徑分別進行模型訓練,即特征提取與全連接網(wǎng)絡的組合(Path1),Bi-LSTM 與后置注意力機制的組合(Path2)以及前置注意力機制與CNN 和Bi-LSTM 的組合(Path3),分別查看網(wǎng)絡的預測效果,由于模型訓練存在隨機性,因此進行多次實驗獲取平均值。總體來說,特征提取與全連接網(wǎng)絡的組合(Path1)在FD002 和FD004獲得的RMSE 和Score 結(jié)果相較另外兩種網(wǎng)絡組合有更好的表現(xiàn)。最終結(jié)果表明,將3 個路徑輸出特征進行融合輸入全連接網(wǎng)絡來預測RUL 獲得了較好的結(jié)果。消融實驗的結(jié)果如表6 所示。

表6 消融實驗的RMSE和Score結(jié)果Tab.6 RMSE and Score results of ablation experiments
2)同其他方法的比較。
C-MAPSS 數(shù)據(jù)集作為預測RUL 的基準數(shù)據(jù)集,許多方法均使用該數(shù)據(jù)集驗證方法的有效性。將本文方法與其他一些RUL 預測方法進行比較來驗證本文方法的有效性。由于模型預測結(jié)果存在一定的隨機性,進行了多次實驗,獲得RMSE 和Score 的平均結(jié)果。如表7 所示同其他方法相比,本文方法整體獲得了不錯的結(jié)果。從表7 中可以看出,本文方法比受限玻爾茲曼機(Restricted Boltzmann Machine,RBM)+LSTM 組合在FD003 獲得的RMSE 結(jié)果稍差一些,但與其他方法相比,本文方法在所有子集中RMSE 預測精確度均得到了顯著提高,這意味著提出的模型預測航空發(fā)動機RUL 非常接近實際RUL。由于飛機系統(tǒng)對發(fā)動機可靠性的要求很高,較高的RUL 預測準確度意味著能及時進行設備維護,提高飛機系統(tǒng)的安全性。在表7 中,F(xiàn)D003 上使用特征注意的雙向門控循環(huán)單元卷積神經(jīng)網(wǎng)絡(feature-Attention based bidirectional Gated recurrent unit Convolutional Neural Network,AGCNN)獲得的Score 比本文方法有較好的表現(xiàn),混合深度神經(jīng)網(wǎng)絡(Hybrid Deep Neural Network,HDNN)在4 個數(shù)據(jù)集上獲得的Score 均較低;但總體來說本文方法在Score 指標上獲得了更好的結(jié)果,尤其是在FD002 和FD004 數(shù)據(jù)集上預測準確性與其他方法相比有較大提升。實驗結(jié)果證明所提方法在RUL 預測中能夠提供更準確的預測結(jié)果。
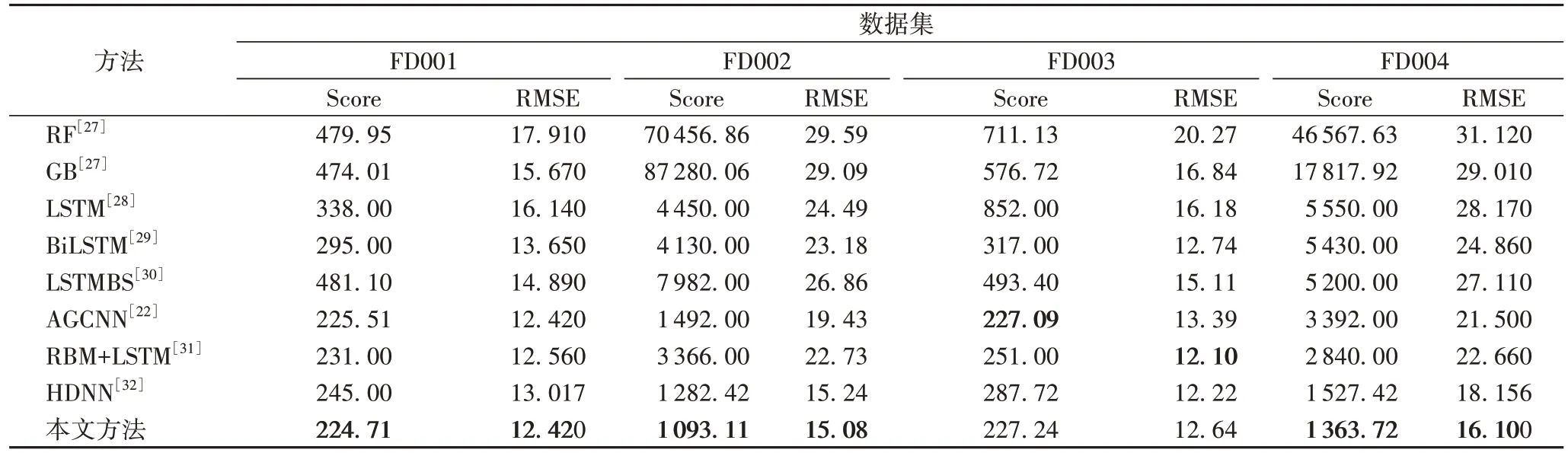
表7 不同方法之間的Score和RMSE比較Tab.7 Comparison of Score and RMSE of different methods
選取某次實驗結(jié)果,4 個數(shù)據(jù)集的預測RUL 如圖8 所示。對于這4 個數(shù)據(jù)集,預測RUL 與真實RUL 非常匹配,這表明所提方法的可行性。由于FD001 和FD003 數(shù)據(jù)集運行條件單一且發(fā)動機數(shù)量較少,因此FD001 和FD003 的預測性能相比FD002 和FD004 更好。

圖8 航空發(fā)動機RUL預測結(jié)果Fig.8 Aero-engine RUL prediction results
如圖9 展示了本文方法在FD001~FD004 測試集中誤差分布直方圖,橫坐標代表預測RUL 值與真實RUL 值之間的誤差,縱坐標代表相應誤差區(qū)域所對應的發(fā)動機數(shù)量。其中,F(xiàn)D001 和FD003 真實RUL 與預測RUL 的誤差集中在[-20,20],而FD002 和FD004 誤差值集中分布于[-30,30]。依據(jù)表1 可以了解FD002 和FD004 屬于復雜數(shù)據(jù)集,均擁有6 個操作條件,因此模型預測具有更大的挑戰(zhàn)。從式(16)可以看出Score 函數(shù)對模型滯后預測懲罰更大,即預測RUL 與真實RUL 差值大于零且誤差越大獲得的Score 懲罰就越高,從圖中能夠看出所提模型預測RUL 與真實RUL 大于零的誤差區(qū)間較小并且引擎數(shù)量較少,因此獲得了較低的Score 值。
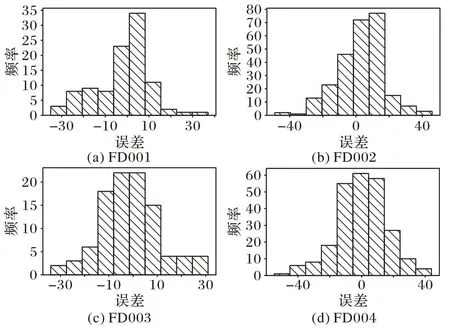
圖9 預測誤差分布直方圖Fig.9 Prediction error distribution histogram
3 結(jié)語
本文提出了一種優(yōu)化混合模型來預測航空發(fā)動機的RUL。由于本模型擁有3 條并行路徑,通過消融實驗分別驗證每條路徑的預測能力,并且說明將3 條路徑進行特征融合對于航空發(fā)動機RUL 預測的有效性。第一條路徑,提取數(shù)據(jù)的均值和趨勢系數(shù)傳入全連接網(wǎng)絡獲得更多抽象特征,經(jīng)過消融實驗表明此路徑在FD002 和FD004 數(shù)據(jù)集上獲得的RUL 預測結(jié)果準確性較高;第二條路徑,將注意力機制作用于Bi-LSTM 網(wǎng)絡之后,為重要的輸出特征加大權重;第三條路徑,前置注意力機制來加權不同時間步下的原始數(shù)據(jù),加權處理的數(shù)據(jù)輸入CNN 和Bi-LSTM 網(wǎng)絡中,實驗結(jié)果顯示此路徑在FD001 和FD003 數(shù)據(jù)集上獲得的RUL 預測結(jié)果準確性較高。將上述3 條并行路徑進行特征融合作為全連接網(wǎng)絡的輸入來預測RUL,最終得到的預測RUL 準確性較高。由于滑動時間窗口大小對RUL 預測非常重要,本文分別探究了選取不同值對模型預測結(jié)果的影響。此外,不同傳感器數(shù)據(jù)攜帶的特征存在差異,可能會導致模型學習效果存在差異,所以本文依據(jù)不同角度選取傳感器進行模型訓練,結(jié)果顯示刪除恒定的傳感器測量數(shù)據(jù),剩余傳感器數(shù)據(jù)組成新的數(shù)據(jù)集獲得的實驗結(jié)果是最好的。本文方法同各種RUL 預測方法進行了比較,使用兩種流行的評價指標進行對比實驗,結(jié)果證明本文方法的RUL 預測準確性較高。雖然本方法獲得了良好的實驗結(jié)果,但仍有進一步優(yōu)化的空間,例如:改善復雜運行條件下方法預測的穩(wěn)定性將是未來的研究方向。目前使用的訓練和測試數(shù)據(jù)均是在相同環(huán)境下獲得的,但如果訓練和測試數(shù)據(jù)是在不同的工作條件下收集的,則可能會降低方法的預測性能。因此,使用遷移學習方法提高模型的預測能力將作為下一步研究方向。利用3 條路徑提取特征,計算量和計算負擔相應會有一定的增加,但是為了獲得更好的預測精度,犧牲了一定的計算量,所以下一步將考慮引入模型壓縮等技術來減少計算量。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
