基于特征注意力機制的RNN-Bi-LSTM船舶軌跡預測
2022-09-28 01:40:32趙程棟莊繼暉程曉鳴李宇航郭東平
廣東海洋大學學報 2022年5期
趙程棟,莊繼暉,程曉鳴,李宇航,郭東平
(海南大學機電工程學院,海南 海口 570228)
關鍵字:AIS信息;循環神經網絡;雙向長短時記憶網絡;特征注意力機制;船舶軌跡預測
各國經濟貿易往來頻繁帶動航運行業蓬勃發展,海上船流量日益遞增、海上交通堵塞、船舶碰撞事故頻發。因此,準確預測船舶航行航線成為國內外學者的研究熱點。船舶自動識別系統(automatic identification system,AIS)提供豐富的船舶行駛信息,主要涉及水上移動通訊服務標識碼(maritime mobile service identify,MMSI)、船只的經緯度、對地航向和對地航速等,有效利用AIS 數據對船舶軌跡預測有重要作用。目前,國內外研究的船舶軌跡預測模型主要有基于物理模型和學習模型。其中,基于物理模型多是通過多組物理方程建模來預測船舶軌跡。姜佰辰等[1]將多項式卡爾曼濾波對船舶運動軌跡進行最優建模獲取未來船舶位置。周艷萍等[2]對基于改進的灰色模型對船舶未來位置進行預測。何靜[3]對卡爾曼濾波物理方程改進以判斷船舶軌跡異常。然而,這些研究考慮動態因素太多,無法建立精確的物理模型,當海上環境變化時,對于船舶軌跡預測效果不理想。隨著機器學習和深度學習發展,利用學習模型建模預測船舶軌跡成為研究熱點。李永等[4]使用長短時記憶網絡(long short term memory,LSTM)對船舶軌跡進行未來位置預測。王研婷[5]在LSTM網絡中加入CNN卷積神經網絡,聯合LSTM 和CNN 共同對AIS 數據進行訓練。Zhang 等[6]基于Bi-LSTM,對數據歸一化處理,提升雙向LSTM 預測結果,該方法對于船舶直線軌跡預測效果好,但對于彎曲軌跡預測效果較差。趙梁濱[7]結合CNN 卷積神經網絡與雙向LSTM,使用船舶歷史軌跡以預測船舶未來航線軌跡,但該方法主要對船舶直線軌跡進行預測,未涉及彎道軌跡預測。因此,為更準確預測船舶直線與彎道軌跡,本研究提出一種結合特征注意力機制的RNN-Bi-LSTM 的船舶軌跡預測模型。通過RNN 權值共享,獲取數據更深層次的特征信息;加入Bi-LSTM 能保存長時間序列信息,提升模型訓練效果;引入特征注意力機制對輸入變量的特征設定不同的權重,解決各輸入變量對最后預測結果關聯效果不一的問題;通過實驗將本研究模型與LSTM,Bi-LSTM 模型進行比較,以驗證本研究模型在直線軌跡預測,單彎道以及連續彎道預測上的優勢。
1 數據準備
AIS 會采集到大量與船舶軌跡預測關聯大小不一的數據,需挑選出與船舶軌跡預測關聯性大的數據作為實驗輸入。經緯度體現海上船舶具體位置,對地航速是船舶對地行駛速度、對地航向是船舶行駛方向,這三者均對預測船舶位置有顯著影響,故選擇AIS數據中的經緯度、對地航速、對地航向作為模型輸入數據。
2 理論方法
2.1 循環神經網絡
RNN 即循環神經網絡,主要用于對時序問題的預測,能夠挖掘時序數據深層次的信息[8]。當前多被應用于自然語言處理、語言翻譯等問題[9]。RNN結構如圖1所示,包括輸入層、輸出層及隱藏層。其中輸入層記為{ }X0,…,Xi-1,Xi,Xi+1,輸出層記為{O0,…,Oi-1,Oi,Oi+1},隱藏層記為{S0,…,Si-1,Si,Si+1}。U 為輸入層到隱藏層的權重矩陣,V表示隱藏層到輸出層的權重矩陣,W表示隱藏層之間的權重矩陣。在i時刻,由Si-1和當前的Xi作為輸入,得到計算結果Oi為輸出且傳遞給i+1時刻,這樣每一層輸入都能得到上一層的輸出權重。可知RNN 網絡使用相連接的隱藏層,將前一時刻的狀態傳至下一時刻,具備對時序數據的記憶能力[10]。RNN 神經網絡結構見圖1。
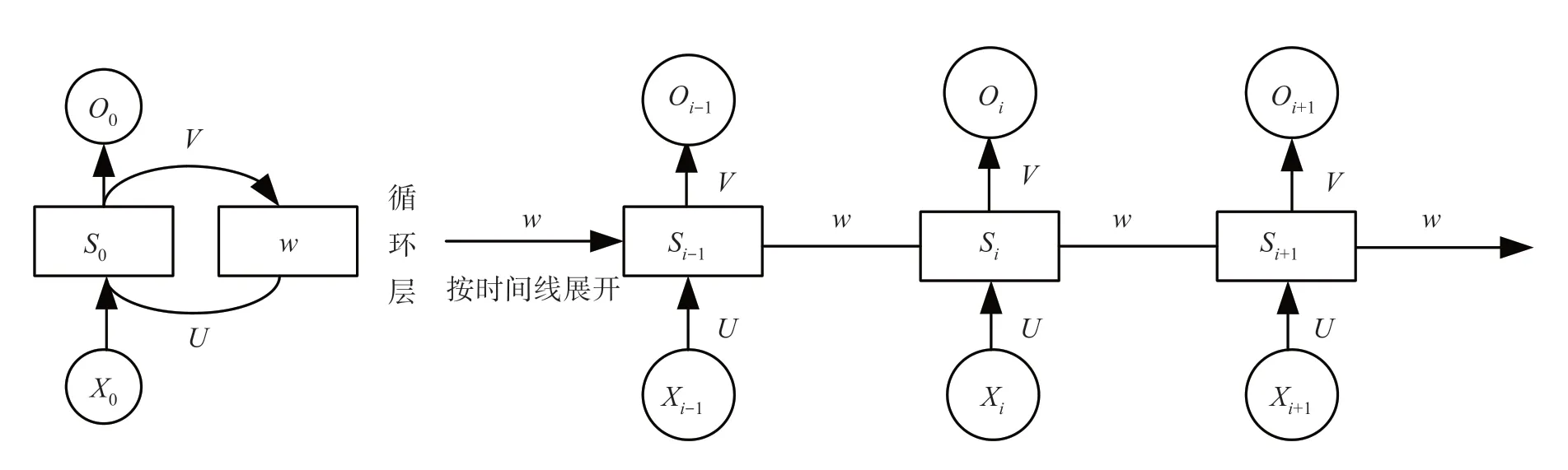
圖1 RNN神經網絡結構Fig.1 RNN neural network structure
2.2 雙向長短時記憶網絡
Bi-LSTM 是對傳統LSTM 的擴展。它由正向迭代LSTM 層和反向迭代LSTM 層組成,兩層都會對輸出產生影響。與單向LSTM 相比,Bi-LSTM利用正向軌跡序列信息和反向軌跡序列信息進行輸入,有利于提高模型預測的精度[11]。因為LSTM 下一時刻的預測值是根據前面多個歷史時刻的輸入預測得到的,并且在提取數據特征時可能丟失有用信息。而船舶軌跡預測任務受到歷史和未來多個輸入共同影響,尤其在彎道預測中,前后數據突變大,所以使用Bi-LSTM 捕獲歷史和未來幾個時刻的輸入數據可以得到更精確預測結果。展開的雙向LSTM 具體結構如圖3 所示。箭頭表示信息流的方向,變量y1、y2、…、yi是t1到ti的船舶輸入數據,Y1、Y2、…、Yi為相應時刻的最終輸出,A1、A2、…、Ai與B1、B2、…、Bi分別表示LSTM隱藏狀態在不同時間的前向和后向迭代,W1、W2、…、W5是權重參與每一層的計算。正向迭代LSTM 的隱藏更新狀態Ai(公式1),反迭代LSTM 的隱藏更新狀態B(i公式2),最終輸出O(i公式3)。式(1-3)中,f(x)、g(x)、h(x)為不同隱含層中使用的激活函數。Bi-LSTM結構見圖2。

圖2 雙向LSTM結構Fig.2 Bidirectional LSTM structure
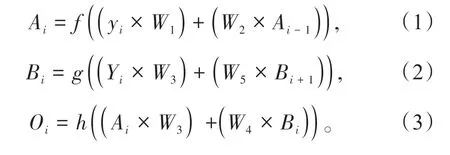
從上述計算可以看出,Bi-LSTM 的特殊結構使其能夠對輸入的時間序列數據進行正向和反向計算,有助于模型學習前后時間數據序列的時空相關信息,這有利于提高模型的預測性能。
2.3 特征注意力機制
注意力機制首先應用于機器視覺方向[5]。近年來,注意力機制被應用于各個方面,它的合理使用能提升模型預測精度。注意力機制相當于人類在眾多視覺信息中對關鍵特征關注權重更大[12]。在深度學習中,注意力機制可以為關鍵特征分配更多的權重,提升模型預測性能。注意力機制分為硬注意和軟注意,硬注意力機制采用直接限制輸入內容的處理方法,在時間序列預測領域并不完全適用[13]。為了突出特定通道的關鍵特征,軟注意力機制利用神經網絡訓練的權重來聚焦于特定通道。在軌跡預測模型中引入注意力機制可以增強輸入數據關鍵特征的影響,提高模型預測效果。本研究使用注意力機制對輸入特征賦予不同的權重。將特征時間序列前一時刻RNN 網絡輸出數據矩陣X1、X2、…、XM作為特征注意力機制的輸入,通過對當前時刻各個特征進行注意權重的計算后得到e1、e2、…、eM,再進行歸一化處理,并根據注意力權重增強或削弱相關輸入信息的表達,將當前時刻得到的權重與對應特征相乘,輸出為b1X1、b2X2、…、bMXM。特征注意力機制見圖3。
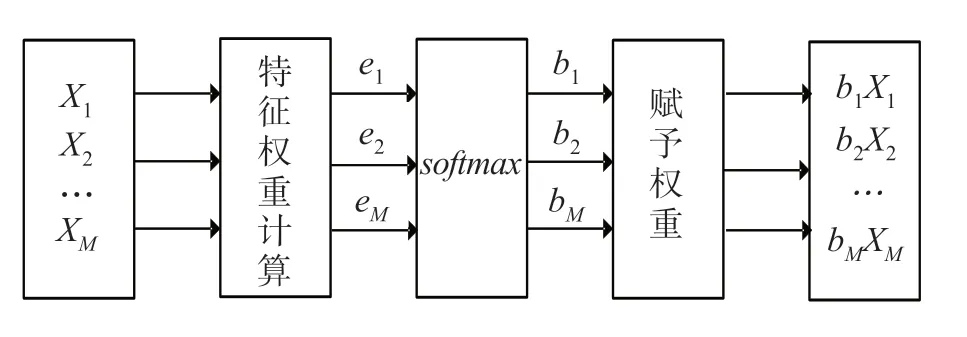
圖3 特征注意力機制Fig.3 Characteristic attention mechanism
2.4 數據歸一化
因輸入數據的數值差別較大,為防止數值較小的數據被數值較大數據影響的情況,采用(Min-Max Normalization)最小最大歸一化,將每個數據映射在[0-1]之間,保證所有數據被神經網絡公平對待,最小最大歸一化轉化方式見式(4)
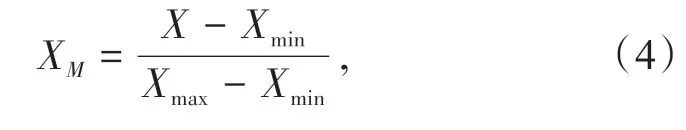
其中,X代表原始數據,XM代表歸一化后數據,Xmin代表數據最小值,Xmax代表數據最大值。
3 AR-Bi-LSTM模型
3.1 模型的輸入和輸出
選擇經緯度(φ,λ)、對地航速(ν)、對地航向(θ)作為模型的輸入數據,單位分別為(°)、m/s、(°),同時對船舶未來經緯度進行預測任務。對于t時刻模型的輸入yt見式(5)

為了減少模型預測時間和增加預測精度,將未來時刻的經緯度作為模型的輸出。對于t+1 時刻模型的輸出pt+1見式(6)
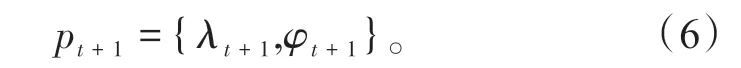
將連續5 個時刻的船舶航行軌跡特征數據y(t-4),…,y(t-1)、y(t)作為模型的輸入,將t+1時刻的航行軌跡數據Yt+1作為輸出。船舶軌跡預測模型的表達式見式(7)
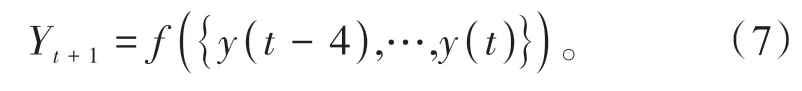
3.2 AR-Bi-LSTM模型框架
RNN 能對時序數據特征提取,但是無法解決長期依賴問題,隨著時序數據的增加,預測精度會變差。而Bi-LSTM 通過合并可更新先前隱藏狀態的內存單元來保留數據間的長期依賴關系[14]。所以將RNN 和Bi-LSTM 結合,能夠解決長期依賴問題,與僅僅使用Bi-LSTM 網絡比較,在RNN 和Bi-LSTM結合中Bi-LSTM 網絡可以接收RNN 模型提取時序數據的特征向量矩陣進行船舶軌跡預測,且Bi-LSTM 能捕獲深層次輸入數據特征。兩者取長補短,提高預測準確性。同時為充分考慮船舶軌跡預測在數據特征上相關性,將特征注意力機制加入模型中,船舶不同的輸入特征對最終結果影響大小不同,因此使用特征注意力機制對輸入特征賦予權重,通過特征注意力機制來修正輸入特征對預測結果的影響,進一步提升預測精度。AR-Bi-LSTM 將RNN、特征注意力機制和Bi-LSTM 串聯。AR-Bi-LSTM 首先搭建一層RNN 來接收船舶航行的各種行駛信息。RNN 包含一個接收變量作為輸入的輸入層,一層隱藏層計算輸入提取輸入數據深層次信息,以及一個將隱藏層計算的矩陣提取到注意力機制模塊的輸出層。通過特征注意力機制模塊,使得輸入特征數據獲得不同的權重。隨后連接一層Bi-LSTM 神經網絡,用來存儲注意力機制模塊提取的表征船舶航行狀態的重要特征信息,捕獲船舶歷史和未來幾個時刻的位置信息,對船舶軌跡進行預測。
AR-Bi-LSTM 模型框架如圖4 所示。實現船舶軌跡預測,首先將歸一化后的數據輸入循環神經網絡,經過隱藏層獲得預測數據矩陣;循環層輸出預測數據矩陣輸入特征注意力機制模塊,對特征權重矯正,得到新的數據矩陣。經過特征注意力機制模塊的數據矩陣輸入到droupt 層,隨機將20%的矩陣元素權重置零,防止模型過擬合,通過droupt層后的數據矩陣作為Bi-LSTM 的輸入數據,通過正向傳遞網絡和反向傳遞網絡訓練樣本數據,經過Adam 優化算法對其進行優化,輸出預測值。最后通過1 個全連接層,得到最終預測數據。
圖4 AR-Bi-LSTM模型框架Fig.4 AR-Bi-LSTM model structure
4 實驗設計
4.1 實驗環境
本研究模型在個人PC 機上運行,PC 機配置為8G 的運行內存以及i7-6700HQ CPU,PC 機基于Windows 操作系統,軟件為Pycharm2021.2,編程語言使用Python3.7,深度學習框架使用Tensorflow框架。
4.2 模型參數和實驗數據
經過多次實驗調整RNN節點數為32、Bi-LSTM節點數為80 且激活函數為模型tanh 函數時預測效果最佳,所以AR-Bi-LSTM 模型參數選擇:RNN 隱藏層數為1,節點數32,激活函數為tanh 函數;Bi-LSTM 隱藏層數為1,節點數80,學習率0.001,激活函數為tanh 函數;Dense 全連接層數為1,節點數4,激活函數也為tanh 函數。其中LSTM 模型節點數80,學習率為0.001,激活函數為tanh 函數;Dense 全連接層數為1,節點數4,激活函數也為tanh 函數。Bi-LSTM 模型同理。3 個預測模型設置的超參數為adam 優化器,學習率0.001,損失函數為MSE、RMSE,滑窗長度5,訓練集數6 405,批次大小16,Droupt為0.2。
實驗數據來自英國肯特郡(Kent County),水上移動通信業務標識碼(MMSI)209479000,209512000和205689000 的船舶實時數據。選擇了2019 年6 月18 日至2019 年7 月13 日的船舶209479000 數據。總共實驗數據8 009 組,按照80%和20%劃分訓練集和測試集,前6 405 組作為訓練集,后1 604 組作為測試集,將訓練集輸入網絡進行訓練。將船舶209512000和205689000總1 450條數據驗證模型泛化能力。
4.3 評價指標
使用Bi-LSTM 模型、AR-Bi-LSTM 模型和LSTM 模型進行誤差分析時,由于誤差計算是想得知真實點與預測點偏差大小,均方誤差MSE(Mean Square Error)能極佳衡量真實情況與預測結果的誤差情況,且均方根誤差RMSE(Root Mean Square Error)也能體現真實點與預測點的偏移[15],也是一種常用的精度評價指標。評價指標所使用的經緯度單位都為(°)。MSE,RMSE 的數學表達式如式(8)(9)所示,兩種評價指標越小表示模型性能越好。
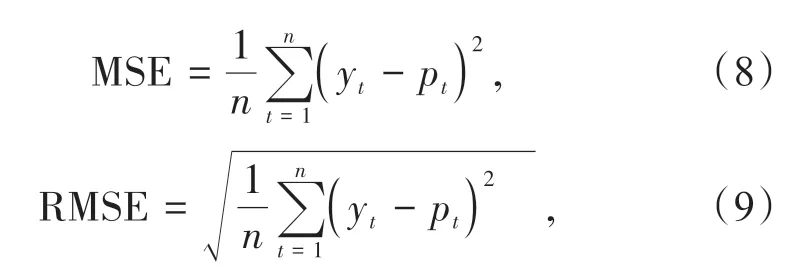
其中,n表示樣本數,yt表示真實值,pt表示預測值。
5 結果與分析
5.1 AR-Bi-LSTM模型預測精度與預測結果
為了驗證AR-Bi-LSTM模型真實軌跡與預測軌跡之間的誤差,在模型訓練、預測過程中輸入相應的參數,不同參數對模型訓練、預測產生不同影響[16]。通過對模型調整參數,對模型預測性能進行評估,利用測試集對模型預測能力檢驗,來驗證模型預測能力[17]。圖5 為AR-Bi-LSTM 模型是在肯特郡港口下部分測試集中真實軌跡與預測軌跡對比結果,紅色為真實軌跡,藍色為預測軌跡。由圖5可見,AR-Bi-LSTM 模型預測無論對直線還是彎道預測都非常接近真實值,說明AR-Bi-LSTM 模型在船舶軌跡預測方面有較高精度。
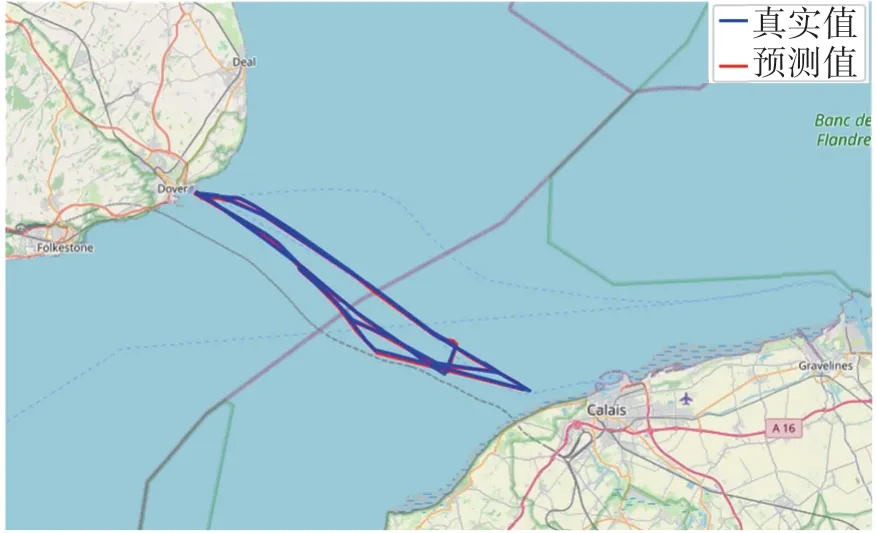
圖5 軌跡預測結果Fig.5 Trajectory prediction results
5.2 不同結構的Bi-LSTM模型預測精度對比
為了確定特征注意力機制和循環神經網絡對預測能力的提升,對比了RNN+Bi-LSTM和Attention+Bi-LSTM 以及AR-Bi-LSTM 模型預測精度。三種模型總體的均方誤差(MSE)和均方根誤差(RMSE),緯度MSE、緯度RMSE、經度MSE 和經度RMSE 如表1。可以看出:AR-Bi-LSTM 的經緯度誤差都在RNN+Bi-LSTM 和Attention+Bi-LSTM之下,體現出循環神經網絡和特征注意力機制對于Bi-LSTM 的預測提升效果較好,說明了模型AR-Bi-LSTM 的穩定性和良好的預測能力。AR-Bi-LSTM、RNN+Bi-LSTM 和Attention+Bi-LSTM的均方誤差和均方根誤差分別為:2.751×10-5、5.245×10-3、5.048×10-4;7.105×10-3、9.579×10-4、3.095×10-2。
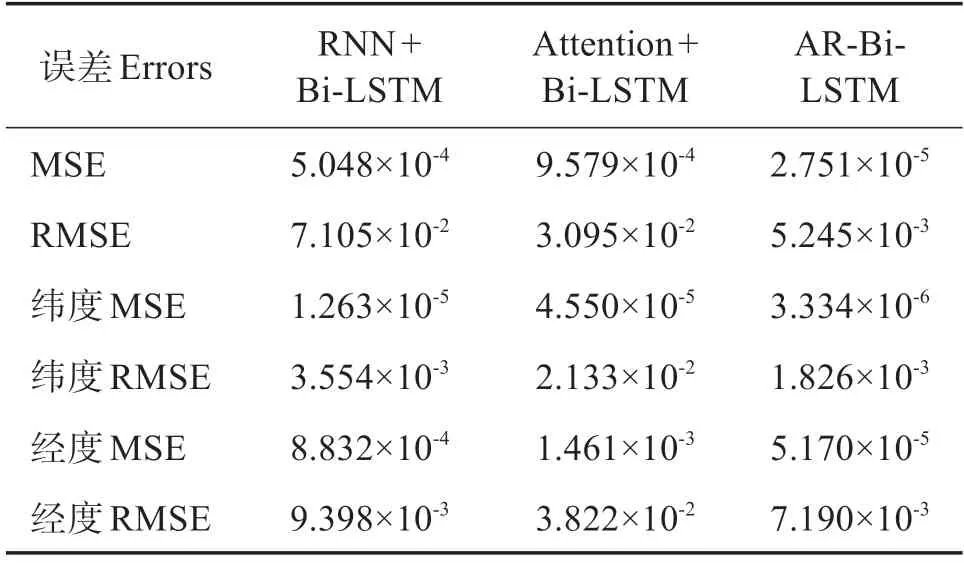
表1 不同結構Bi-LSTM模型對比Table 1 Comparison of Bi-LSTM models of different structures
綜上所述,特征注意力機制和循環神經網絡使得雙向長短時記憶網絡預測能力提升,且優于單獨使用。
5.3 不同模型預測精度對比
為了驗證AR-Bi-LSTM 模型預測精度,本研究將LSTM、Bi-LSTM和AR-Bi-LSTM進行對比實驗。
三種模型的誤差對比見表2,該表對LSTM 和Bi-LSTM 以及AR-Bi-LSTM 模型在總體、緯度、經度的均方誤差和均方根誤差進行對比,可見ARBi-LSTM 模型的MSE、RMSE、緯度MSE、緯 度RMSE、經度MSE、經度RMSE 更低,說明模型在軌跡預測中可以深入捕獲船舶輸入數據信息,特征注意力機制的加入修正了對預測結果影響大的特征信息權重,AR-Bi-LSTM 模型具備最好的預測性能。
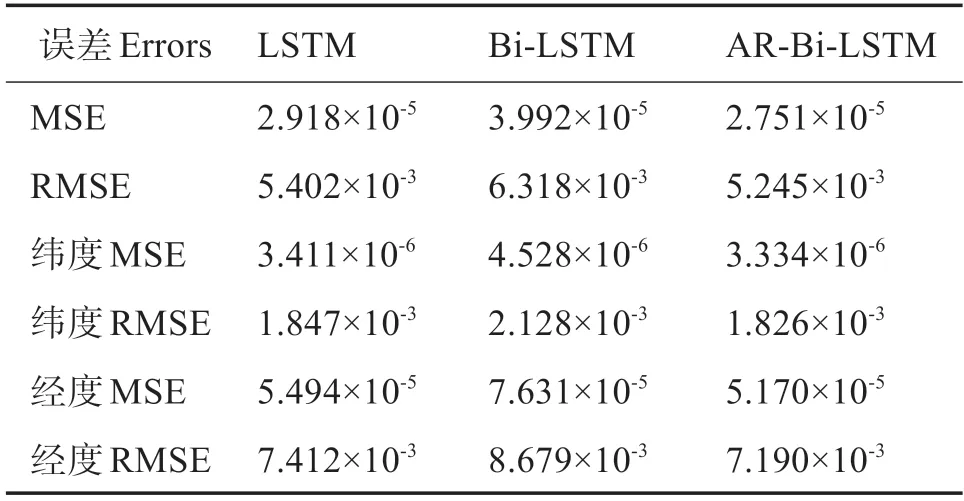
表2 不同模型誤差對比Table 2 Comparison of different model errors
驗證模型AR-Bi-LSTM 的泛化能力,使用船舶209512000 和205689000 數據。LSTM、Bi-LSTM 和AR-Bi-LSTM 模型的泛化能力對比見表3,在船舶209512000 和205689000 的預測中,模型AR-Bi-LSTM 的經緯度均方誤差和均方根誤差比較LSTM模型和Bi-LSTM 最小,說明該模型具備一定的泛化能力,能對往來船舶軌跡進行預測。
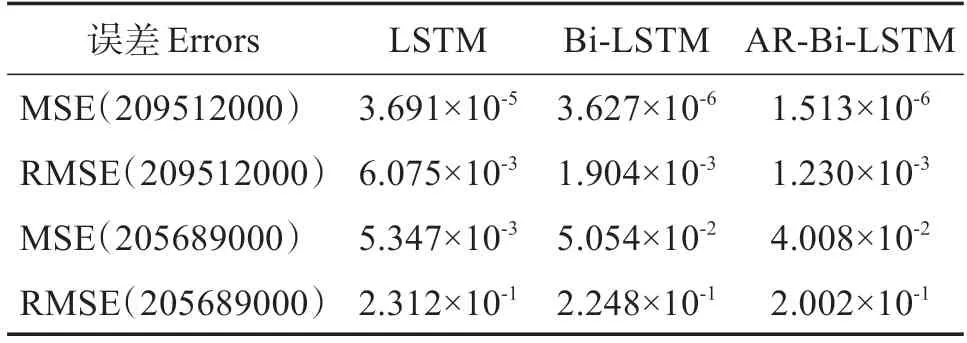
表3 模型泛化能力Table 3 Model generalization ability
綜合圖6—8 是三種模型在直線和單個彎道真實值與預測值的軌跡,表4 為三種LSTM、Bi-LSTM和AR-Bi-LSTM模型在直線和單個彎道誤差對比。

圖6 AR-Bi-LSTM直線和單個彎道預測軌跡Fig.6 AR-Bi-LSTM predict trajectories in straight lines and single curves
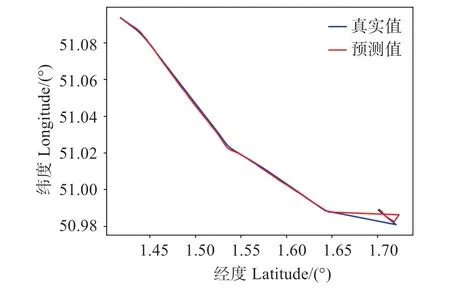
圖7 LSTM直線和單個彎道預測軌跡Fig.7 LSTM predict trajectories in straight lines and single curves
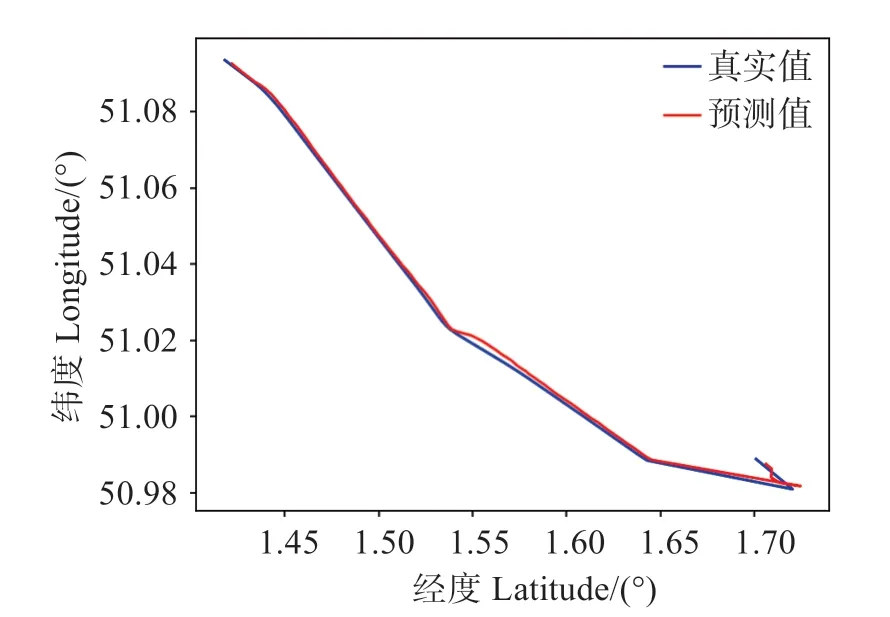
圖8 Bi-LSTM直線和單個彎道預測軌跡Fig.8 Bi-LSTM prediction trajectories in straight lines and single curves
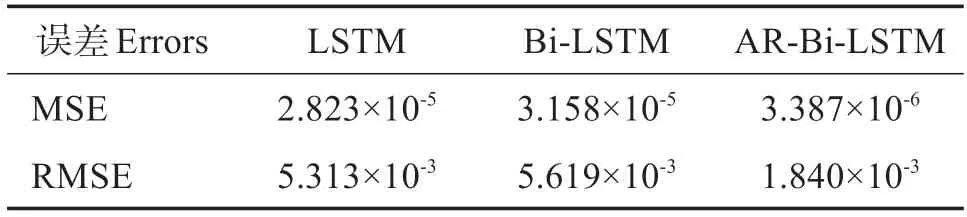
表4 直線和單個彎道預測誤差對比Table 4 Comparison of prediction errors for straight lines and individual corners
三種模型在單個彎道預測軌跡表現均不如直線軌跡預測,模型AR-Bi-LSTM 在直線和彎道上的預測軌跡與真實軌跡最為吻合且預測誤差更小,尤其在單個彎道彎道預測中,由于前后輸入數據變化較大,AR-Bi-LSTM 能提取深層次輸入數據的特征且能運用歷史和未來時刻數據,所以在突變數據處理上更好,對單個彎道預測效果精度高。而LSTM 和Bi-LSTM在單個彎道的預測軌跡與實際軌跡相差出入較大,在彎道預測上有超出原軌跡預測值,AR-Bi-LSTM相比較LSTM和Bi-LSTM在直線和單個彎道預測效果更好。圖9是三種模型在連續彎道預測軌跡對比,表5為三種模型在連續彎道誤差對比。

圖9 連續彎道預測軌跡對比Fig.9 Comparison of continuous curve prediction trajectories

表5 連續彎道誤差對比Table 5 Continuous corner error comparison
模型LSTM 和模型Bi-LSTM 在連續彎道軌跡的表現均不如模型AR-Bi-LSTM。在連續彎道軌跡中,模型LSTM 和模型Bi-LSTM 在彎道部位開始出現較大偏差且預測軌跡偏離真實軌跡,通過圖9 與表4 可以看出,模型AR-Bi-LSTM 在連續彎道軌跡預測表現都優于后者兩個模型,且軌跡吻合度也更高,均方誤差和均方根誤差誤差更小,連續彎道的相繼兩次數據變化,AR-Bi-LSTM 提取的歷史和未來時刻的時序數據也能很好地對連續突變數據預測,因此在連續彎道預測上吻合度較高。綜上所述,AR-Bi-LSTM 模型在直線、單彎道和連續彎道表現上比模型LSTM 和模型Bi-LSTM 出色,所預測軌跡具有一定參考價值。
6 結論
本研究提出的AR-Bi-LSTM 模型,結合RNN 特征學習能力和Bi-LSTM 對長序時間序列預測能力,建立混合模型RNN-Bi-LSTM,并將特征注意力機制加入混合模型中。本研究模型能夠精確的預測出直線、單個彎道和連續彎道的船舶軌跡,提升了模型多場景下的預測能力,相較于傳統的LSTM 和Bi-LSTM 模型,在經緯度預測精度擁有明顯的提升,且在單個彎道和連續彎道的船舶軌跡預測中預測軌跡更為吻合,有著較高的穩定性,對避免未來船舶交通阻塞、船舶碰撞事件將會起到積極作用。
在未來的船舶軌跡預測研究中應該充分考慮時間與空間特性,探究兩種特性對船舶軌跡預測的影響。本研究提出的混合模型預測精度需要進一步提高,下一步可考慮研究編碼器-解碼器等結構的神經網絡模型在船舶軌跡預測研究中的應用。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:07:40
船舶(2021年4期)2021-09-07 17:32:22
小哥白尼(趣味科學)(2019年10期)2020-01-18 09:16:22
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
