基于Scrapy-Redis的分布式爬取當當網圖書數據
2022-10-10 01:23:14胡學軍李嘉誠
軟件工程 2022年10期
關鍵詞:數據庫
胡學軍,李嘉誠
(上海理工大學機械工程系,上海 200082)
1 引言(Introduction)
隨著互聯網技術的蓬勃發展,變化之一就是網絡數據的增長曲線就像指數函數圖像一般,而網絡爬蟲是獲取數據的手段之一。初期單機模式的網絡爬蟲技術將需要抓取的鏈接組成一個隊列,再循環逐個地爬取,直至結束。
分布式爬蟲技術就等同于同時使用多臺單機網絡爬蟲抓取和處理數據,抓取相同頁面信息時,顯著地縮短了時間。隨著爬蟲手段的逐步優化和一次次技術上的迭代,許多大型的互聯網公司(如百度、谷歌等)都研發出了自己的復雜的分布式網絡爬蟲,但是這一類資源是未開放的。目前公開可使用的爬蟲資源,如Scrapy,就是典型的單機模式,此外還有很多類似的爬蟲技術。當然也存在一些爬蟲技術采用的是分布式模式,如Nutch、Igloo等,但是這類系統在實現的過程中是比較復雜的。
本文研究基于Scrapy-Redis框架,設計和實現一個針對當當網圖書信息抓取的分布式系統。
2 基礎理論(Basic theory)
2.1 Scrapy框架組件和工作原理
在網絡爬蟲開發中,Python是使用最廣泛的設計語言,Scrapy則是使用最為簡單和方便的一種。Scrapy框架是基于Twisted開發的,而Twisted是一款使用Python語言實現的基于事件驅動網絡引擎框架。相較于其他網絡爬蟲技術,該框架的優勢在于它是已經封裝好的,同時能夠執行多個任務,且抓取網站內容時速度很快,也能將抓取內容下載到本地,方便使用者使用。
Scrapy框架主要的組件就是作為核心的爬蟲引擎(Scrapy Engine)、負責路由(URL)調度處理的調度器(Scheduler)、在互聯網上下載所需要的數據時使用的下載器(Downloader),以及處理需求定義、頁面解析等使用到的爬蟲(Spider)組件;項目管道(Item Pipeline)組件作為下載下來的數據的加工廠,可以對其進行清除、存儲和驗證等操作;兩個中間件(下載中間件和爬蟲中間件)是連接組件的紐帶。
Scrapy工作流程如圖1所示,URL和下載數據在各組件之間的流走如圖中的箭頭方向所示(圖中編號1—10為數據走向)。
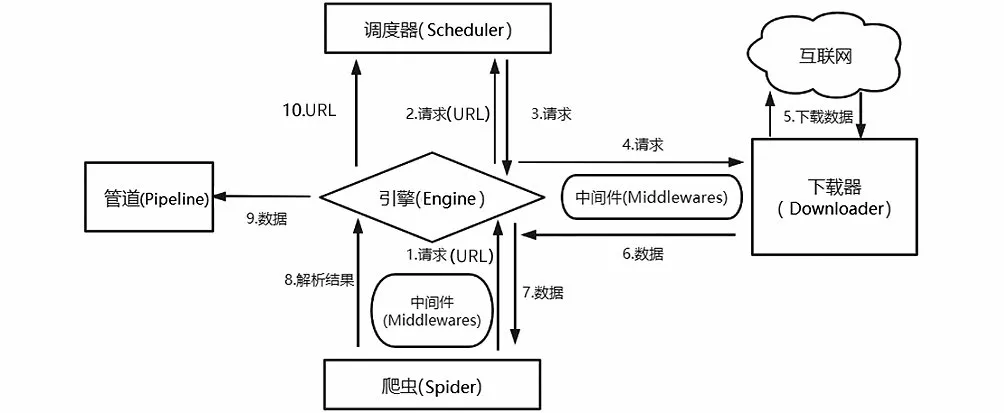
圖1 Scrapy工作流程圖Fig.1 Workflow chart of Scrapy
Scrapy的工作原理可以概括如下:爬蟲先根據初始的需下載的網頁URL到互聯網上下載該網頁數據;在整個下載數據過程中,新的要下載的網頁URL會持續加入Scheduler中的等待下載隊列里;爬蟲按照下載隊列的順序一次抓取網頁,直到下載隊列為空。
2.2 網絡爬蟲的分布式架構技術
(1)Scrapy-Redis框架
Scrapy框架并不支持抓取URL在各個爬蟲端之間共享,也就不支持分布式操作。在Scrapy單機爬蟲系統中存在一個由deque模塊實現的本地爬取隊列Queue。這個隊列是依靠Scheduler組件負責維護的,是獨一無二的,并且它具有不被多個Scheduler共享的特性,造成了Scrapy框架不能實現分布式抓取數據。但是Scrapy框架具有易擴展的特點,通過Scrapy-Redis組件引入Redis數據庫代替Scrapy框架的單機內存來存儲待抓取的URL,Redis數據庫自身又有能共享數據庫給多個爬蟲端的特性,這樣就把抓取隊列共享出去了。
Scrapy-Redis架構圖如圖2所示,它是Scrapy框架和Redis數據庫的結合。
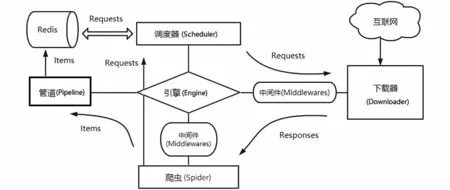
圖2 Scrapy-Redis架構圖Fig.2 Scrapy-Redis architecture diagram
(2)Scrapy-Redis框架爬蟲的主流模式
分布式爬蟲系統架構復雜多變,目前公認的兩種主要分類形式:主從模式和對等模式。
對等模式字面上就可以理解,系統里每一臺計算機都是平等的,它們都要參與爬蟲工作,各自完成自己的任務,互不影響。每臺計算機的任務通過哈希(Hash)函數計算分配。
主從模式是由一臺主機和若干從機組成的,如圖3所示,我們把主機叫作Master節點,把從機叫作Slave節點。主從模式把Redis數據庫搭建在Master上,請求的判重、分配和數據的存儲都交給Master,不執行抓取任務;Slave負責運行爬蟲程序,并把新的請求發送給Master。本文采用的是主從模式。
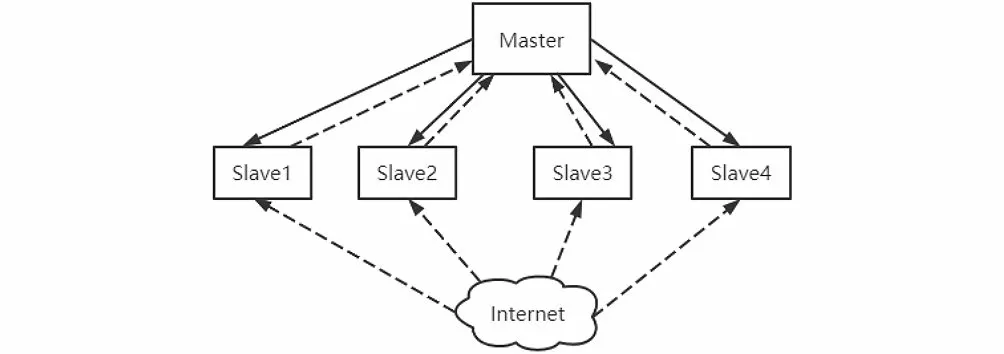
圖3 主從分布式策略Fig.3 Master-Slave distributed strategy
3 布隆過濾器算法(Bloom Filter algorithm)
3.1 基本布隆過濾器原理
巴頓·布隆于1970 年提出了布隆過濾器算法,它可以描述為把所有元素存到一個集合里,然后去比較判斷某一元素是否存在,其實現是依靠Hash函數能夠把一個大的數據集映射到一個小的數據集上。它的優勢就是讓大規模的數據得到壓縮,減少了存儲所消耗的空間,同時查詢時間也比其他算法短。
(1)算法描述
第一步是位數組的定義。布隆過濾器是將數據保存在位數組里,所以首先是位數組定義,然后設位數組長度為,各個位置初始值為0。
第二步是添加元素。假設獨立的Hash函數個數是,布隆過濾器算法把想要添加的元素用Hash函數計算次,得到對應于位數組上的不同位置,將多個不相同的位置設為1,如圖4所示。
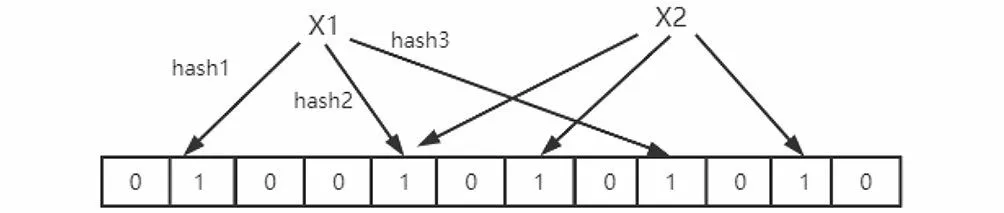
圖4 添加元素Fig.4 Adding elements
第三步是查詢元素。將要查詢的元素執行和第二步一樣的操作,通過Hash函數進行映射,也就是計算次,把得到的值對應地放到位數組上。假設這些位置上出現一個0,則可以判斷該元素肯定不在我們要查詢的集合中;如果這些位置全為1,則不能判斷是否在集合中,因為布隆過濾器存在誤判率。
(2)性能分析
布隆過濾器算法使用個相互獨立的Hash函數,逐一地把原始數據集合中的元素映射到數組中。查閱相關文獻了解到,如果存在一個元素S,其被錯誤判斷為屬于該集合的概率如式(1)所示。
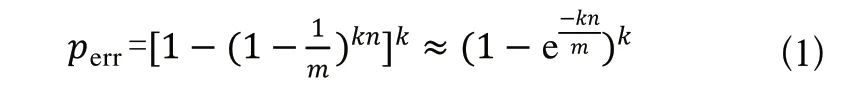
由式(1)可以看出,影響該值大小的三個因素:Hash函數個數、位數組長度和原始數據集合。當原始數據不斷增加時,位數組長度也要和其同步線性增長,才能讓誤判率保持穩定。而Hash函數個數的最優解如式(2)所示。
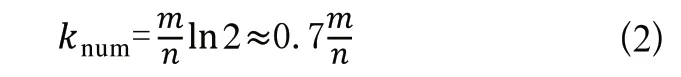
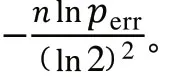
3.2 布隆過濾器算法實現
布隆過濾器算法的代碼實現步驟如下所述。
第一步是初始化位數組,定義一個Init(self,size,HashCount)方法,其中size表示位數組長度,通過導入bitarray對象可以把二進制串轉化為bitarray對象,然后其又能轉化為bytes,實現字符串和二進制之間的轉化;HashCount表示Hash函數的個數。采用集合(set)形式來表示算法對位數組的初始化。
第二步是對查詢元素進行哈希計算,采用的是不同的Hash函數。先導入Murmurhash3,然后把該元素計算次,得到對應的哈希值。
第三步是驗證第二步中要查詢的元素是否存在,利用集合查找方法在位數組中進行查找操作。如果對應的位置上出現0,則認為要查詢的元素不在集合中,執行第四步。
第四步是把URL添加進集合,定義一個add(self,item)方法實現該目標。
4 系統設計和實現(System design and implementation)
4.1 系統流程圖
對當當網的網站結構進行分析,不難發現頁面之間存在“父子”關系。我們把網頁按不同層次進行處理,把頁面內所有的其他鏈接歸類成它的二級頁面鏈接。從首頁開始,逐級對剩下的頁面進行搜索,把符合規則的鏈接加入待抓取隊列中。系統基本流程圖如圖5所示。
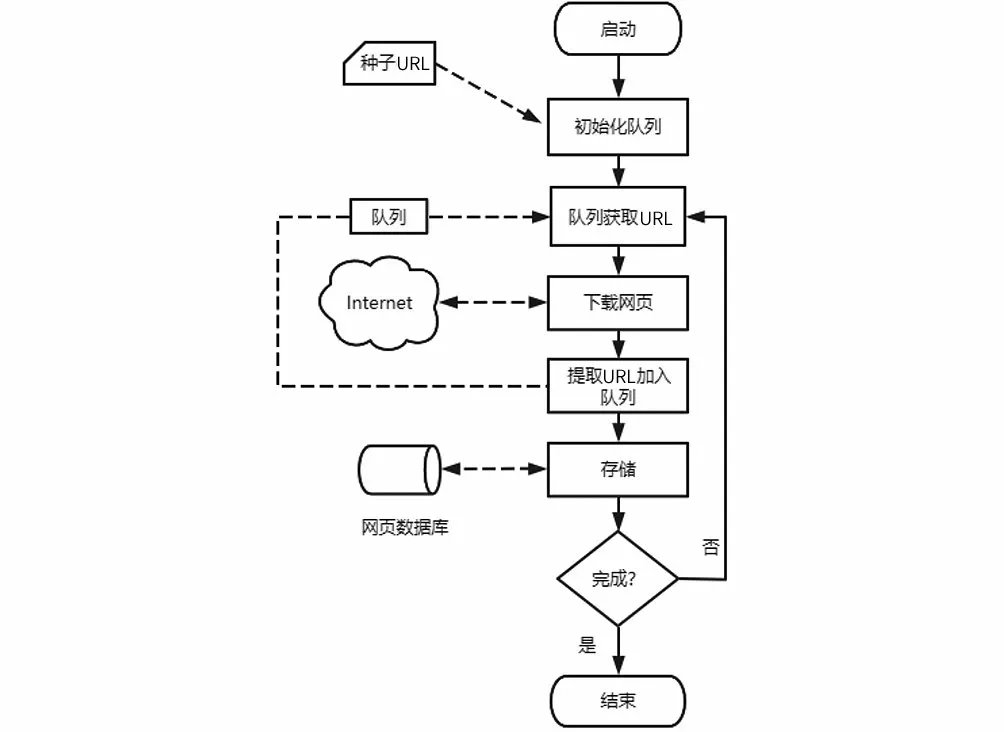
圖5 系統基本流程圖Fig.5 Basic flow chat of the system
4.2 數據庫設計
(1)數據表設計
Scrapy爬蟲下載數據后,通過Item_Loader機制把解析的數據存放到爬蟲模型Item中,最后使用項目管道模塊存儲數據。如表1所示為數據字典設計。

表1 數據字典設計Tab.1 Data dictionary design
(2)數據存儲
設計完數據字典以后,采用MySQL數據庫來存儲爬取到的數據,在Pipeline.py文件中編寫Scrapy框架和數據庫鏈接的代碼及操作數據庫的SQL語句。實現流程如下所述。
第一步:打開Scrapy和MySQL數據庫的鏈接,使用的是open_spider(self,spider)方法,再賦值存儲數據服務器的地址(host)、MySQL的端口號(port)、MySQL的用戶名(user)、MySQL密碼(password)、自定義數據庫的名稱(name)和字符集(utf8)。
第二步:鏈接Scrapy和MySQL數據庫,引入第三方模塊pymysql實現。
第三步:操作數據庫,定義一個名為process_item(self,item,spider)的方法,通過Insert into語句來實現數據的存入。
第四步:關閉鏈接。
4.3 頁面解析
Scrapy框架支持多種頁面解析工具,本文使用XPath對抓取頁面進行解析,主要代碼如下所述。

4.4 系統測試和運行結果
在測試時,使用一臺主機做Master,兩臺從機做Slave。由Master主機負責URL的調度隊列和協調從機之間的抓取任務,Slave從機負責執行抓取程序,到互聯網上下載頁面數據并存入數據庫。以當當網圖書為例,運行1 小時后,抓取圖書信息18,000余條,主要為圖書的名稱、作者、價格、封面和簡介信息,如圖6所示。
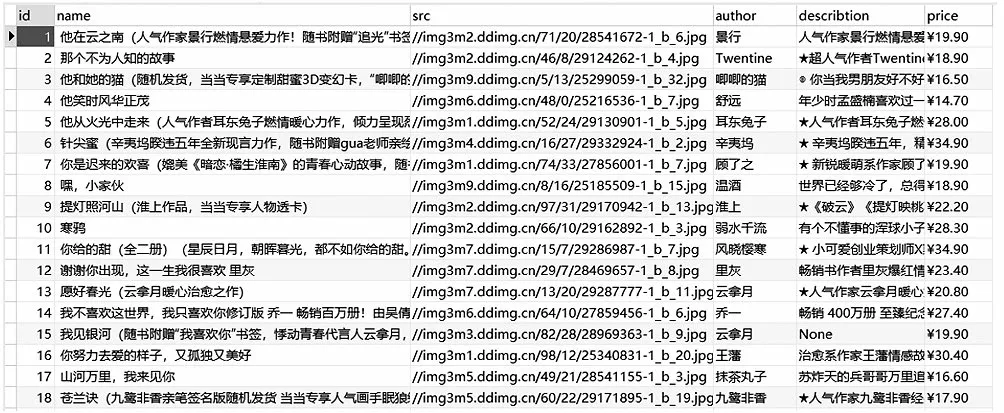
圖6 存儲在MySQL中的圖書相關信息Fig.6 Book information stored in MySQL
5 結論(Conclusion)
互聯網發展帶來網絡數據的大規模增長,網絡爬蟲也需要變得更加迅速、高效,才能達到使用要求,所以對分布式爬蟲的研究具有一定的實用價值。本文從介紹Scrapy框架的組件及其功能入手,講述了數據在組件之間流動的過程,分析了Scrapy-Redis組件實現分布式抓取數據的原理和主流模式。以抓取當當網圖書信息為例,研究了爬行策略、爬蟲設計、解析規則和布隆過濾器算法對抓取URL去重等的設計思路,構建了針對抓取當當網圖書信息的主從式分布網絡爬蟲系統。
但是項目在實際運行過程中出現了令人不滿意的問題:(1)Master主機對爬蟲任務的管理并不理想;(2)布隆過濾器算法相比其他一般算法,在空間利用上更充分,查詢時間也更短,但是誤判率也是其非常明顯的缺點,后續針對布隆過濾器算法URL去重方法,還需要進一步學習。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
