基于K-means優化的SOM神經網絡算法的視頻推薦系統
2022-10-10 01:23:16付麗梅
軟件工程 2022年10期
關鍵詞:實驗
付麗梅
(大連東軟信息學院軟件工程系,遼寧 大連 116023)
1 引言(Introduction)
智能手機的高速發展使各種小視頻成為人們生活中的重要娛樂手段,隨之而來的視頻推薦已成為當前視頻應用的一個關鍵問題。當前視頻推薦的精度和速度都還有一定的提升空間,可通過對SOM算法的研究改進視頻推薦系統的精度和速度。目前SOM神經網絡的研究方向主要有以下幾種:(1)基于動態確定結構和網絡數目的改進。為了擺脫傳統SOM模型需要提前給定結構和網絡單元數目的限制,科研人員提出在訓練過程中動態確定網絡形狀和數目的解決方案。(2)基于匹配神經元策略的改進。該研究方向中比較著名的研究算法有SOFM-CV、SOFM-C、DSOM等,其改進方向為修改神經元的競爭方式或競爭過程,或者在競爭過程中添加其他參數和限制條件等,以防止競爭單元層中出現“始終不能獲勝”的結果。(3)最后一種就是用其他算法來組合SOM算法,其中比較有代表性的是提出把SOM和粗糙集進行組合的RSOM算法;科研人員提出使用自適應共振理論模型和SOM組合對文檔進行聚類;另有科研人員使用了多層感知器(Multilayer Perceptron,MLP)和SOM結合來進行語音識別。本文使用K-means算法對SOM神經網絡算法進行改進,并應用到視頻搜索推薦系統中,該推薦系統分為爬蟲、算法實現、可視化三個模塊。
2 算法概述(Algorithm overview)
2.1 SOM算法
SOM是一種自組織特征映射聚類算法,它包括輸入層和競爭層(也叫輸出層)兩部分。訓練過程采用競爭的方式,競爭層在接收到輸入層的樣本數據后,計算樣本與神經元自身的權向量,與樣本最近的神經元為最佳匹配單元,接著更新最佳匹配單元的權值,同時和最佳匹配單元臨近的點也根據它們距最佳匹配單元的距離適當更新參數,這個過程迭代反復直至收斂。
2.2 K-means算法
K-means算法是一種無監督的聚類算法,其思想如下:將給定的樣本集按照樣本之間的距離大小劃分為個簇,劃分時要讓簇內部點的排列盡量緊密,簇與簇的間距相對要盡量大。K-means算法的值一般是根據對數據的先驗經驗來選擇,若先驗知識不足,也可通過交叉比對選擇。個質心的選擇可以采用隨機方式,質心的初始位置會極大地影響最終的聚類結果及運行時間,質心之間的距離不應太近,否則會影響聚類效果。
2.3 K-means改進的SOM算法
SOM算法作為一種無監督的學習算法,它的訓練過程不是很穩定,如果有一個如同K-means算法的穩定訓練過程,就可以大大提升工作效率。SOM算法的訓練過程需要刷新初始值較小的神經元,和K-means算法選定質心的方式有著相似之處,只不過一個是在輸入層之前選定,一個是在訓練過程之中選定。本文綜合兩種算法對視頻推薦算法進行優化。
3 基于改進S O M 算法的視頻推薦系統實現(Implementation of video recommendation system based on improved SOM algorithm)
3.1 數據采集
數據采集使用爬蟲技術,爬取www.bilibili.com網頁中較火的視頻類數據進行處理后作為實驗數據。爬蟲的編寫采用Python 3.7自帶的urllib模塊,當用戶打開網頁時,瀏覽器根據輸入的地址找到相應的服務器發送請求,服務器收到請求后,解析請求中攜帶的信息并進行響應,最終返回請求結果。urllib模塊模擬用戶的瀏覽過程,發送請求后獲取服務器返回的數據。獲取網頁HTML文件后,使用BeautifulSoup庫解析HTML文件。BeautifulSoup為開發者提供一些Python風格的函數來分析提取HTML文檔中的信息,通過解析HTML篩選出有用的信息導入數據庫以備算法使用。實驗需要的信息包括嗶哩嗶哩視頻彈幕網的視頻播放量、點擊量、評論及彈幕數量等數據,至于視頻的編號(AV)則是通過對URL的拆分處理而得到的。拆分的過程就是利用split函數以“/”為分隔,將字符串切割成列表的形式。
3.2 SOM算法實現
SOM算法的學習過程分為三個部分。首先是競爭,也就是針對輸入的數據集,計算其與數據單元權向量的歐幾里得距離,距離最小的為獲勝神經元,也可通過其他判別函數得出,記為最佳匹配單元。然后是合作,最佳匹配單元決定了興奮的神經元的拓撲鄰域占據的空間位置,是相鄰的神經元合作的基礎。最后要調整權值,興奮的神經元通過對自身權向量的調整,來增加數據集的判別函數值(使用向量間的歐幾里得距離),然后讓神經元對接下來的相似輸入有一個強化的響應。
SOM算法的實現過程可描述為如下幾方面。
(1)初始化。使用權值較小的隨機值進行初始化,并對輸入向量和權值做歸一化處理:
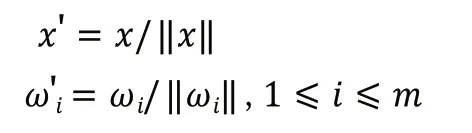

(2)將樣本輸入網絡。計算樣本與權值向量的歐幾里得距離,距離最小的神經元贏得競爭,記為最佳匹配單元。
(3)更新權值。更新獲勝的神經元拓撲鄰域內的神經元,重新歸一化學習后的權值,基本公式如下:

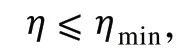
該算法的優點是無須監督,無須提前告知分類數便能自動對輸入模式進行聚類,容錯性強,對異常值和噪聲不敏感。其缺點是在訓練時有些神經元始終不能勝出,導致分類結果不準確,SOM網絡收斂時間較長,運算效率較低。
3.3 K-means算法實現

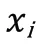
(3)重新計算每個簇的新質心,新質心為各個簇內所有樣本距離的平均值,若k個質心向量未發生變化,則進行步驟(4);否則,重復步驟(1)—步驟(3),直至最大迭代次數或聚類完成。
(4)重新劃分輸出簇C。
3.4 使用K-means改進SOM算法
SOM算法具有一些缺陷,例如算法運行后期有可能會出現鐘擺效應(即網絡在幾個最佳極值點之間反復跳動),以及不穩定的訓練輸出等,可結合K-means算法的訓練過程來使SOM算法的訓練過程穩定化,并且借用K-means算法的思想來強化SOM算法的效率。
改進的思想大致如下:首先,SOM算法需要隨機選定神經元,隨機性會導致后面的訓練過程不穩定;而K-means是首先選定質心,在訓練過程的穩定性上占有優勢。其次,SOM算法以神經元為中心,使得數據向神經元移動;而K-means算法是通過移動質心的方式來達成對數據類的分簇。綜合這兩種思想,首先觀察數據集的分布狀態判定質心,調用K-means算法的訓練過程將質心移動到分簇的附近,然后將選定得到的質心作為現成的最佳神經元定位拓撲鄰域,使用SOM算法開始聚合。改良后的算法的基本流程如圖1所示。
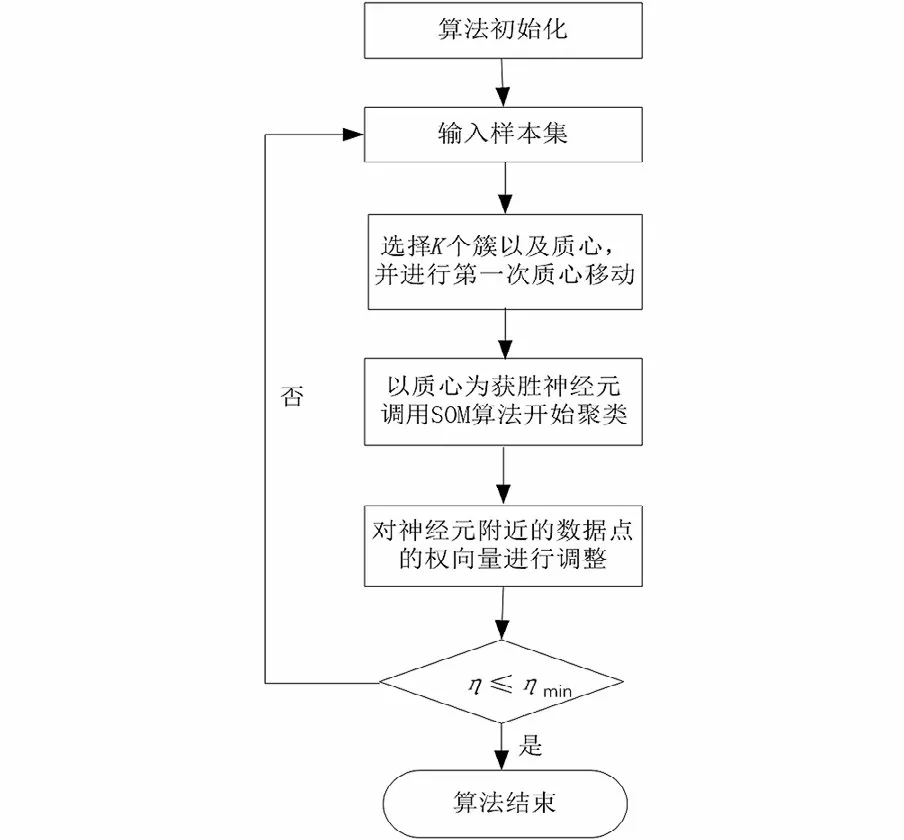
圖1 使用K-means改進SOM算法流程Fig.1 Using K-means to improve SOM algorithm process
改良后的算法雖然以SOM算法為主要運行部分,但是使用K-means算法指定的質心取代了SOM算法需要算法運行選擇的最佳神經元,并且在經過質心選定之后使得質心/最佳神經元更靠近需要聚類的數據簇。該算法的優點是算法簡單,收斂速度快,準確率較高;缺點是初始聚類中心的設定對聚類結果影響較大,聚類種數需要預先給定,而在很多情況下的估計是非常困難的。
3.5 視頻推薦結果可視化
本系統的可視化模塊采用了Django框架進行開發,可視化模塊分為關鍵字搜索和結果顯示兩個頁面。關鍵字搜索頁面在提供自定義搜索的同時,也提供標簽式的定向搜索,即根據用戶選擇的標簽推送出最吻合的視頻,滿足不同類型用戶的需要。結果顯示頁面除了提供視頻的超鏈接之外,還提供該視頻的評分項,計算方法是將點擊數、播放數、評論數、彈幕數等屬性進行歸一化處理后乘以100得出基本評分,方便用戶選擇視頻。本系統采用MySQL數據庫,需要安裝PyMySQL模塊。系統的數據流向如下:啟動爬蟲,對網頁進行數據爬取,經過一個臨時數據存儲模塊處理后進入數據庫,算法在數據庫中提取數據,通過分析后輸出推薦視頻到結果頁顯示。
4 算法實驗結果與對比(Experimental results and comparison of the algorithm)
4.1 算法參數設置實驗
本文對SOM算法單體效率的研究采用修改參數調整效率的方式,大部分參數可以通過學習獲得,能夠手動修改且對運行結果影響較大的是迭代次數及批尺寸(batch_size)。
(1)迭代次數實驗
在這一步中,本文使用了500 個樣本數據,在不影響batch_size的情況下進行改動迭代次數的實驗,實驗使用單一的SOM算法。實驗結果表明,在不修改batch_size的情況下,單純地修改迭代次數對算法的運行效率幾乎沒有影響。
(2)batch_size實驗
batch_size是機器學習算法中一個重要的參數,本實驗以已經完成的組合算法為框架,輸入200 個樣本,通過調整batch_size不斷實驗可以看出,如果batch_size減小,算法在200 次迭代內不能收斂。如果batch_size增大,處理數據的速度會變快,而達到相同精度所需的迭代數量增多。當batch_size增大到一定程度時,會達到運行時間的最優化,但最終的收斂精度會陷入不同的極值。因此,batch_size需要在0—200取舍,本實驗的batch_size定為100。
4.2 K-means改進SOM算法實驗
第一組測試的是運行所需要的時間。實驗限制條件為batch_size100,迭代次數100,只對輸入樣本的個數進行更改。實驗結果為算法的運行時間,如表1所示。
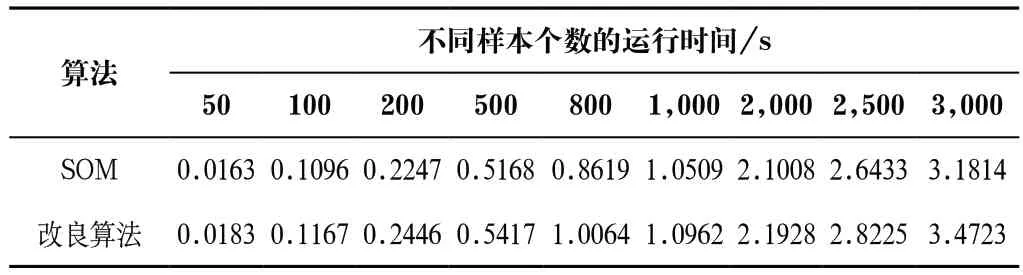
表1 算法運行時間對比Tab.1 Comparison of algorithm running time
由表1可以得出,在限制了迭代次數及batch_size的情況下,改良后的算法在運行時間上要略差于原本的SOM算法,其運行時間比原算法長4%—12%。
第二組實驗測試的是同等運行條件下的運行精度,參考值為輸出關鍵字的精確性。實驗結果為用戶需求的關鍵詞在推薦結果中所含數量占算法推薦數總量的百分比,如表2所示。
由表2可知,在限制了迭代次數及batch_size的情況下,改良算法的運行結果在推薦精度上有了5%—8%的提升,符合視頻推薦應用對精度要求更高的需求。
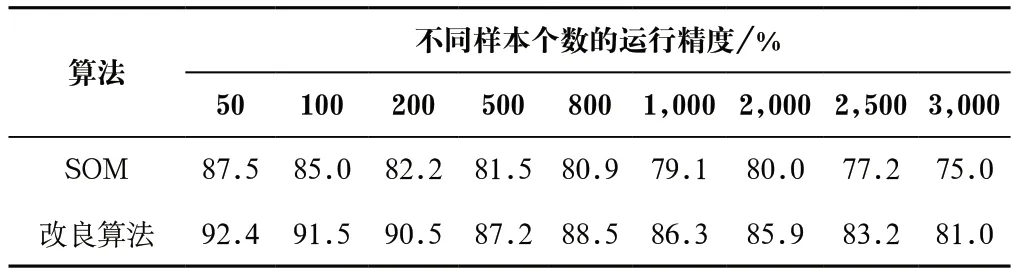
表2 算法運行精度對比Tab.2 Comparison of algorithm running accuracy
5 結論(Conclusion)
SOM和其他算法的組合在很多領域應用效果較好。本文使用SOM和K-means的組合算法來進行視頻推薦,并設計了一個視頻推薦系統,系統由數據采集與處理、算法優化和可視化三部分構成。實驗結果表明,在限制batch_size和迭代次數的情況下,使用K-means優化的SOM算法雖然在運行效率上有所降低,但在運行精度上有了5%—8%的提升,在視頻推薦應用方面,推薦的準確性遠比運行時間更符合實際用戶需求。因此,改良的SOM算法適合應用在視頻推薦系統上。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
