一種融合用戶相似性與評分距離的個性化推薦算法
2022-10-10 01:23:18蘇湛,黃忠,艾均
軟件工程 2022年10期
蘇 湛,黃 忠,艾 均
(上海理工大學光電信息與計算機工程學院,上海 200093)
1 引言(Introduction)
隨著互聯網技術的廣泛應用,在網上“遨游”的人們時時刻刻都在生產出大量的數據,人類從信息匱乏變成信息過載。海量數據使消費者很難找到自己最感興趣的信息,而互聯網上的商家也需要一種技術來幫助他們找到真正對產品感興趣的潛在消費者。尤其是當下新型冠狀病毒肺炎疫情促使人們越發依賴互聯網進行消費、學習和交流,從而進一步加劇了這一問題。
能夠解決這一問題的個性化推薦算法具有重要的應用價值,設計恰當的模型去理解用戶偏好,預測用戶行為,對人工智能和機器學習理論的進一步發展也具有重要的推動作用,因此個性化推薦算法在相關領域得到了廣泛的研究。亞馬遜、Facebook、京東、淘寶等公司都擁有自己的個性化推薦系統和算法,此外包括電影、音樂推薦等細分領域對個性化推薦算法的應用也同樣廣泛。
本文通過研究用戶間共同評分相似性對潛在用戶進行篩選,使用篩選之后的鄰居集合預測目標的評分,然后按照預測結果生成推薦列表,在有效的數據集上驗證算法的有效性。
2 相關工作(Related work)
2.1 推薦系統分類和問題
根據領域內的一般理解,個性化推薦算法可以分為四種主要類型:基于內容的推薦算法、協同過濾推薦算法、基于知識的推薦算法和混合推薦算法。
第一類,基于內容(Content-based)的個性化推薦算法用物品的描述性屬性來進行有針對性的推薦。“內容”指的就是對物品特征的描述,表示內容特征的標簽就是這一類推薦算法的一種常見計算形式。例如,當一個用戶對“史詩”類型電影常常給予高評價時,帶有“史詩”標簽的新電影就可以推薦給該用戶。算法會基于用戶歷史數據判斷出用戶對這一內容標簽的偏好概率,并計算任意一個帶有該標簽的電影被該用戶喜歡或不喜歡的可能性,例如通過比較兩個偏好的樸素貝葉斯概率大小就是一種預測用戶對該電影偏好的常見方法。
第二類,基于記憶(Memory-based)的協同過濾(Collaborative Filtering,CF)算法和基于模型(Model-based)的協同過濾算法是協同過濾算法的兩個子類型。基于記憶的協同過濾算法,無論是基于物品還是基于用戶,都基于相似的個體表現出相似的評分模式行為,相似的對象更容易獲得相似的評分這樣的假設。例如,要預測一個目標用戶對某個電影的評分,如果能夠找到一組和這個用戶具有高度相似歷史評分的用戶群體(通常被稱為鄰居用戶),因為這些鄰居用戶歷史上的評分和目標用戶高度相似,那么鄰居用戶對目標物品的評分可以很自然地作為目標用戶對該物品評分的參考數據。這類個性化推薦算法在預測中綜合考慮用戶評分均值差異和用戶之間相關性差異來得到最終的預測結果。
另一方面,基于模型的協同過濾個性化推薦算法包括聚類模型、距離模型、最大熵模型、矩陣分解模型和相似性網絡模型等多種類型的設計方案。基于模型的協同過濾算法同樣需要預測目標用戶和社區用戶的評分數據,但這類推薦算法通常先構造描述推薦系統的某種模型,并訓練獲得這些模型的必要參數,然后基于這些訓練獲得的參數來對未知評分進行預測。矩陣分解模型本質上擬合平均矩陣中高度相關的那些用戶評分,通過分解來對評分矩陣降維,抽象出用戶特征矩陣和物品特征矩陣。在這一過程中,那個不易被擬合的評分被適當忽略。
第三類,基于知識的個性化推薦算法有兩種常見形式,包括基于約束條件的推薦算法和基于案例的推薦算法。在實際生活中,很多商品的消費行為常常是頻度很低的,如房屋、汽車、珠寶等,肯定不能像書籍、電影或外賣一樣被用戶高頻度消費和評價。一方面,因為這些物品的價格更高;另一方面,一個用戶的評價對另一個用戶的參考價值也相對更低。因此,基于知識的個性化推薦系統需要將已知的物品數據基于專家知識進行建模和抽象,抽象結果數值作為知識系統存儲,并在用戶提出自己需求的時候,通過約束條件疊加進行篩選和推薦,或者基于案例篩選并通過參數條件的替換進行推薦。
第四類,混合推薦算法則綜合上述多種不同類型的推薦算法,力求獲得更好的推薦性能,或者滿足不同條件下的推薦需求,其混合方案包括加權型、切換型、交叉型、特征組合型、瀑布型、特征增強型和元級型等混合推薦策略。
盡管針對推薦系統已經涌現了很多研究并應用比較廣泛,但仍有一些挑戰吸引著相關領域的科學家,例如冷啟動問題、數據稀疏性問題、算法的可擴展性、預測的準確性、運行時間和推薦多樣性。
冷啟動指的是加入系統的新用戶和新物品在沒有評價數據等關鍵信息條件下的推薦問題;數據稀疏性則是指用戶或物品評價評分數據量不足造成的推薦不準確或不適當問題;算法的可擴展性既包括算法訓練、預測時間復雜度,也包括算法學習之后需要存儲的模型相關數據大小代表的空間復雜度;預測的準確性則可以從推薦算法對評分的預測誤差數值大小、對用戶喜歡和不喜歡兩種偏好評價的預測準確性或推薦列表是否能將用戶喜歡的物品排在前列這三種情況進行度量;推薦多樣性則考查推薦的物品列表中,各種物品的特征差異大小,一般情況下一個推薦列表中的物品相似性越低,物品流行度越多樣,推薦算法的多樣性就越好。
最緊迫的問題仍然是提高推薦預測的準確性,為此許多學者提出了改進的相似性計算算法。為了測量相似性,HAWASHIN等人基于用戶興趣設計了一種混合的相似性度量方法。SINGH等人在確定相似性時分別考慮消費者對單個商品相似特征的好惡。AI等人使用相似性來建模用戶-用戶網絡,并將中心性度量作為提高預測準確性的一個因素。通過引入指定的距離函數,MU等人增加了Pearson相似度。JOORABLOO等人提出了一種新的用戶/項目鄰域重新排序方法,該方法考慮了用戶/項目相似性的未來趨勢,如Slope One算法及其變體,將評分差異視為用戶之間的距離,并使用該距離來預測推薦的未知評分。所有這些技術都提高了推薦預測的準確性。
盡管Slope One算法計算過程簡潔,其模型簡單,易于理解,可解釋性強,但它將所有符合條件的用戶都作為鄰居使用,不考慮用戶間的相關性大小,這就導致這一算法在應用中需要緩存大量的鄰居間距離數據作為學習結果。
本文探索的核心科學問題是與預測目標負相關的用戶在基于距離的推薦模型中是否對預測起到正面作用,這些作用有多大;這些潛在的正面作用是否可以適當犧牲來降低預測需要的鄰居,以換取算法可擴展性的提升。
概括地講,本文的研究主要有兩點貢獻。
(1)基于實際數據研究了相關性較低鄰居用戶的推薦的影響,發現負相關和相關性低的鄰居用戶可以在預測中省略,這種省略會給推薦過程中的預測帶來多方面的正面作用;
(2)基于上述發現,本文設計了基于融合用戶相似性與評分距離的個性化推薦算法,該方法成功降低了傳統距離模型算法的空間復雜度,顯著減少了預測時所需的用戶數量,同時還提高了預測準確性、推薦列表排序質量和推薦列表的多樣性。
2.2 用戶相似性度量
基于用戶共同評分物品集合計算的用戶相關性,在推薦系統研究中一般被稱為用戶間的相似性(User Similarity)。以基于記憶的協同過濾推薦算法為例,其核心思想就是通過利用與目標用戶興趣偏好相似的用戶群體的喜好程度來預測和推薦。具體來說就是計算目標用戶與其他所有用戶兩兩之間的相似性,再通過相似性從高到低來選擇必要的個鄰居,最后根據鄰居的評分來對目標用戶進行預測,相似性是這一過程的核心。
因此,推薦系統領域提出了許多方法來解決這個問題,例如皮爾遜相關系數、余弦相似、歐幾里得距離、置信度相似度、均方距離、用戶行為概率、Jaccard、Spearman相關性向量相似度、Bhattacharyya系數及用戶意見傳播等。這些相似性算法各有特點,考慮不同的因素和計算方式來度量用戶間的相似性。
2.3 基于距離模型的協同過濾
基于距離模型的協同過濾不考慮用戶間的相似性,以Slope One算法為例,該算法是一種基于模型的協同過濾推薦算法,先基于用戶評分計算用戶間的評分距離,其核心思想是根據兩用戶間之前的電影評分采用線性回歸分析方法。假設用戶和之間的評分具有線性關系:=+。在預測時,不用刻意選擇那些相關性高的用戶,所有對目標物品評過分,且與目標用戶有距離的用戶都將被選擇作為鄰居來進行預測。根據計算的兩用戶間評分的偏差值,加上已知用戶評分來計算未知評分。最終的預測結果是所有符合上述條件預測的平均值。
3 算法設計(Algorithm design)
3.1 符號說明

將已知評分數據集分為訓練集trainingSet和測試集testSet。通過訓練集進行學習,基于學習的結果對測試集中的評分進行預測,并考查預測結果和真實結果之間的差異,從而度量算法的性能。
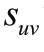
3.2 算法原理
已知用戶、和三人對物品的評分分別為1、2、4.5,對物品的評分分別為3、2.5、1,預測的目標是用戶對物品的評分,而已知r=1.5,r=2。
按照皮爾遜相關系數計算相似性,s=1.0,s=-1.0。按照Slope One算法計算用戶間評分距離,得到=0.25,=-0.5,
從這個例子可以看出,相似性和距離模型對用戶間關系的計算是有明顯差異的。可以對這一差異加以利用,以提升推薦算法的可擴展性和預測性能。
基于上述分析,本研究設計了一種融合用戶相似性與評分距離的個性化推薦算法(Fusion of User Similarity and Distance,FSD)。理論上,該算法既可以應用于用戶間相似性與評分距離的融合,也可以應用于物品間相似性與評分距離的融合。為了簡便起見,本文在討論中僅討論用戶間的相似性和評分距離。
通過觀測上述例子和分析原理可以發現,用戶評分距離不帶有相關性含義,評分距離近的鄰居并不一定比評分距離遠的鄰居更具參考意義。相反,相似性高的用戶在理論上與預測目標更相關,在預測中應該有更高的權重。
因此,FSD假設相似性低的鄰居用戶在距離模型中作用更低。閾值T表示相似性在FSD模型中可以保留鄰居的最小值,通過這一設置,去除一部分權重小的鄰居,再基于距離模型考查預測特征的變化,以決定T合適的取值。
這樣,FSD模型融合了用戶間相似性與距離特征,進行推薦系統的評分預測。
3.3 FSD算法的計算方法
本文設計的FSD使用皮爾遜相關系數,基于評分訓練集計算用戶之間的相似性。一般來說,兩個用戶之間的相似性越大,兩個用戶的評分相關性就越強,該鄰居用戶在預測中的重要性就越高。
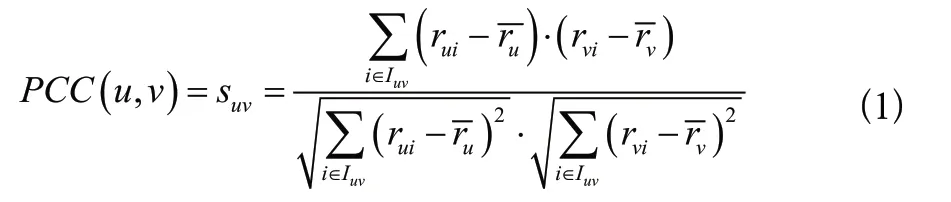
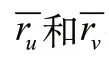
FSD用戶之間的評分距離計算公式定義如下:
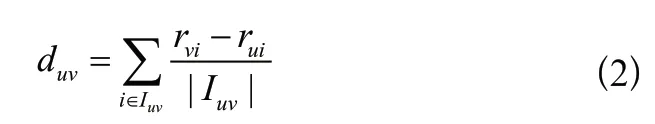

FSD算法根據公式(1)計算用戶之間的相似性,并通過公式(3)過濾用戶,選擇符合條件的用戶作為預測目標的鄰居用戶。
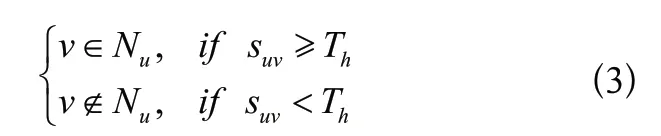
其中,N是用戶選擇的鄰居集, s是用戶和的相似性,T是FSD設定的閾值。
在此基礎上,公式(2)用來計算用戶間的評分距離,公式(4)用來預測未知用戶對物品的評分。
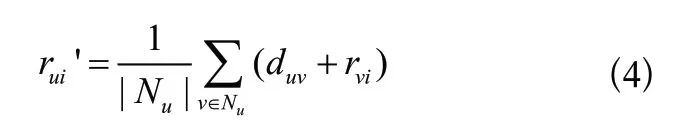
其中,N是用戶的鄰居, d是用戶和對物品的評分距離,||是鄰居的數量。
4 實驗設計(Experimental design)
4.1 實驗數據集
本實驗使用MoviesLens25 M數據集,包括有關電影屬性和用戶評分的信息。該數據集評分分數范圍為0.5—5,評分間隔為0.5,包括162,541 個用戶對62,423 部電影的25,000,095 個評分。本文實驗隨機選擇其中1,000 個用戶對62,423 個電影的146,533 個評分。
為了保證實驗的可靠性,本文采用了十折交叉驗證,在實驗中數據集被隨機分為10 份。每次使用1 份作為測試集,而其他9 組作為訓練集,進行訓練學習和預測檢驗,最終的結果為10 次實驗的平均值。
4.2 基準算法
本文將所提出的FSD算法與原Slope One算法、加權Slope One算法(Weighted Slope One,2013)、信息熵皮爾遜協同過濾(Pearson Entropy,2020)、資源分配協同過濾(RA,2014)、用戶觀點傳播(UOS,2015)、多級協同過濾(MLCF,2016)、用戶行為概率(UBP,2021)等近幾年領域內科學家們設計的經典算法進行比較。
4.3 評價指標
實驗主要考查了設計算法FSD與基準算法間在評分預測誤差、推薦列表排序質量、推薦列表多樣性及算法可擴展性四個方面的性能差異。
本文使用平均絕對誤差(MAE)、均方根誤差(RMSE)來評估算法預測的誤差水平,預測誤差越低,算法對未知評分的預測越準確。采用半衰期效用指數(HLU)、歸一化折扣累積增益(NDCG)來評估推薦結果的排序性能。推薦列表的質量越高,這兩項度量參數的評分越高。
MAE反映了算法預測的用戶評分與用戶實際評分的偏差,RMSE表示算法預測的用戶評分與實際評分之間偏差的均方根值。MAE值表示誤差,RMSE在開方之前將誤差的平方相加,從而增加對絕對值大于1的誤差的懲罰,減小對絕對值小于1的誤差的懲罰,故RMSE對大誤差更敏感。MAE和RMSE值越小,預測結果與實際評分的誤差越小,預測精度越高。實驗中測試集預測目標數量用表示,用戶的預測得分值用r'表示,用戶的實際評分值用 r表示。MAE和RMSE的定義如下:
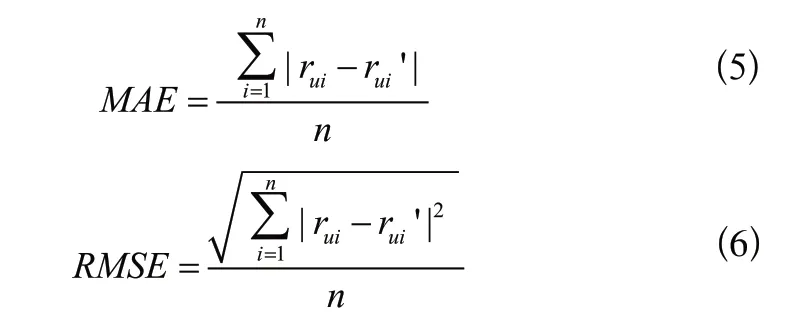
HLU評估用戶真實評分和實際評分之間的差異,以衡量推薦列表對用戶的實用性,其定義如下所示:
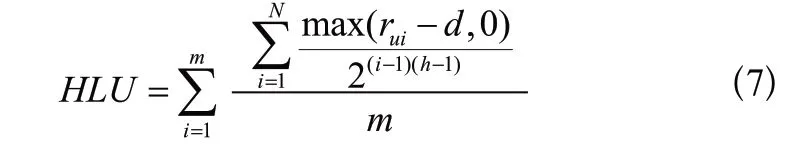
其中,為推薦給每個用戶推薦列表中電影的數量, r為用戶對電影的評分,為訓練集中的平均評分值,為需要提供推薦的用戶數量,為推薦列表的半衰期(本文實驗中的值取2)。HLU的值越大,算法將用戶喜歡的電影排在推薦列表前面的能力越強,系統排序質量越高。
NDCG假設用戶最喜歡的電影在推薦列表中排名第一會更大程度上增加用戶的使用體驗。電影越相關,排名越高,用戶對系統的滿意度就越高,從而節省了用戶的時間,其定義如下:
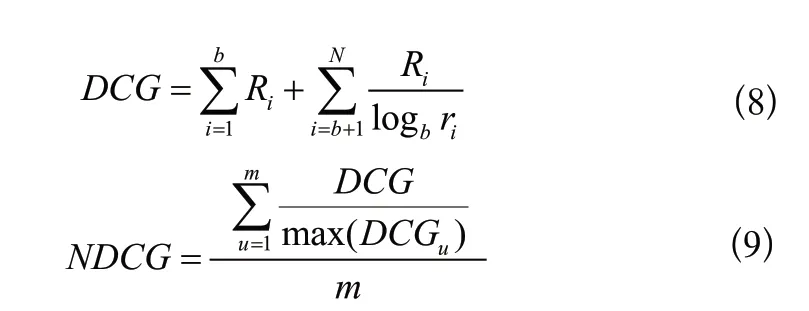
其中,DCG是根據每個用戶的真實評分和預測評分列表計算的; R表示用戶是否喜歡在中排名的電影,R=1表示用戶喜歡該電影,R=0表示用戶不喜歡該電影。本文實驗中將用戶評分高于平均評分的評價看作喜歡,將低于、等于平均評分的評價看作不喜歡。NDCG是DCG的歸一化形式,由公式(9)得出,它將DCG歸一化到0—1。
5 實驗結果與分析(Experimental results and analysis)
依據公式(3),通過給定的相似性閾值篩選距離模型需要的鄰居,圖1中顯示了相似性不同取值下,距離模型評分預測的誤差大小。

圖1 相似性閾值 Th 不同情況下FSD算法的評分預測誤差大小Fig.1 Prediction error of FSD algorithm with different threshold Th
圖1表明,合適的相似性閾值為T=0.0,所提出的FSD具有最佳預測精度,MAE為0.667,RMSE為0.874。此時,距離模型中相似性為負值的鄰居均已經被除去。
圖2中MAE的比較結果表明,當鄰居數大于10時,所有算法的MAE都優于MLCF預測方法。所提出的FSD算法的MAE為0.6997,表明相比之下預測精度次高,僅次于UBP算法。原Slope One算法的MAE為0.7055,相比之下FSD減少了0.8%的誤差。與所有其他算法相比,MAE平均提高了1.5%。
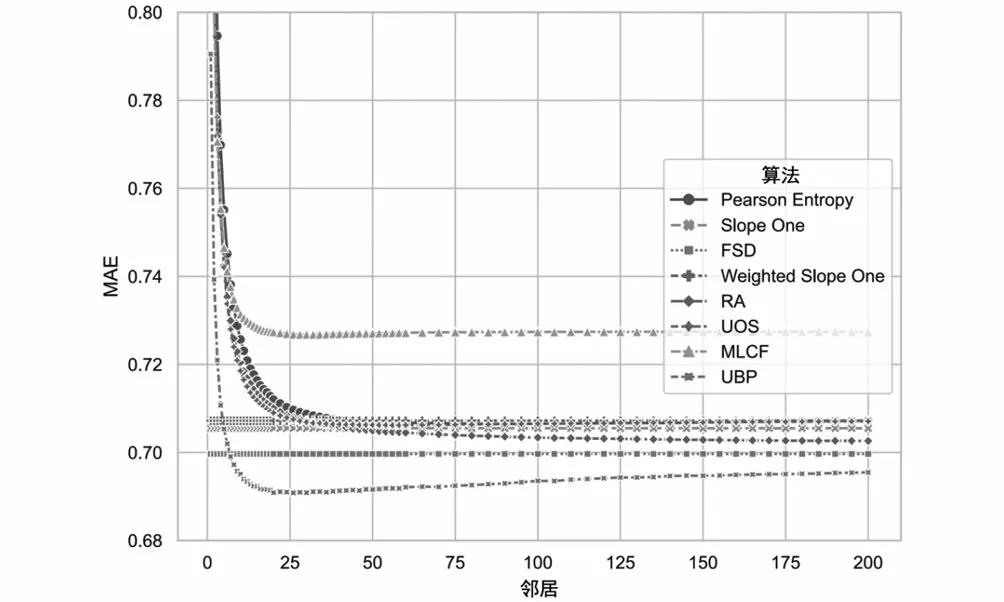
圖2 FSD與其他算法的MAE對比結果Fig.2 MAE comparison result of FSD and other algorithms
如圖3所示,RMSE也表示推薦系統預測誤差的大小,和MAE相比,RMSE對較大的誤差更敏感。FSD算法的RMSE最小,為0.8749;原始Slope One算法的RMSE次好,為0.8800。FSD將誤差降低了0.51%,相比于其他幾種算法,RMSE平均提高了2.3%。
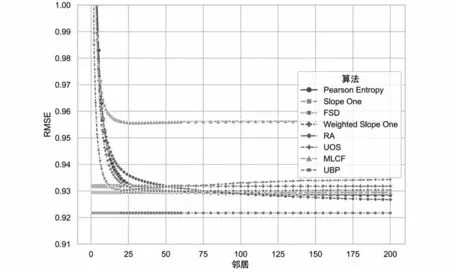
圖3 FSD與其他算法的RMSE對比結果Fig.3 RMSE comparison result of FSD and other algorithms
通過圖2和圖3可以看出,MAE和RMSE中的FSD算法與其他算法相比,具有更小的預測誤差。這說明FSD算法既降低了整體誤差,也降低了較大的預測誤差。
圖4展示了NDCG的比較結果。NDCG體現了推薦列表的排名質量,得數越高越好。FSD算法的最高分是0.7472,比原Slope One算法(其得分為0.7394)高出1%,加權Slope One表現要差些;與其他算法相比,平均提高了3.8%。
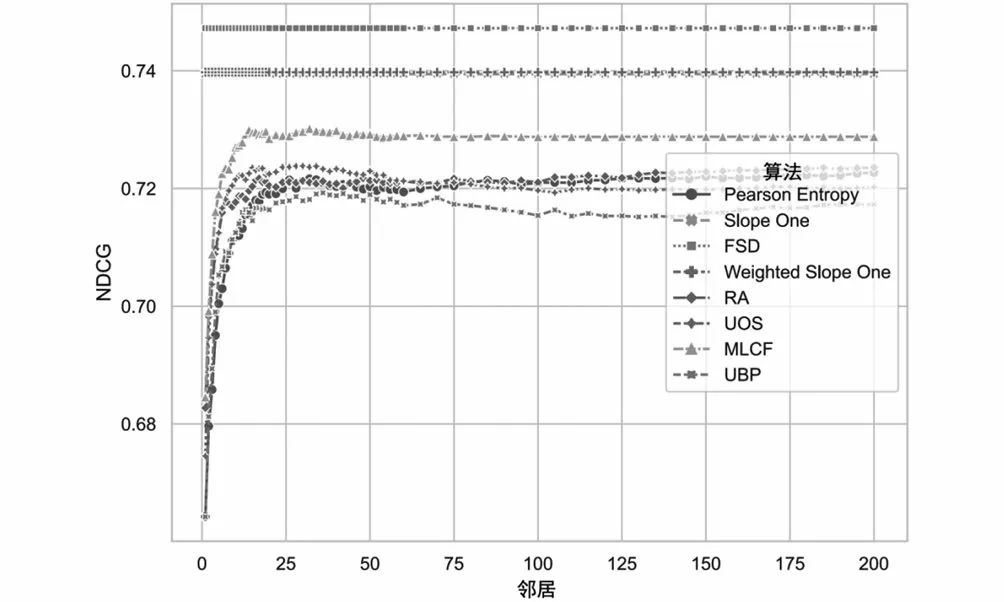
圖4 FSD與其他算法的NDCG對比結果Fig.4 NDCG comparison result of FSD and other algorithms
HLU反映了用戶對推薦列表的興趣程度,如圖5所示,其分數越高,用戶對有限頁面越感興趣。FSD算法的得分為1.0065,原始的Slope One算法得分為0.977,提高了3%;與其他算法相比,平均提高了3.3%。
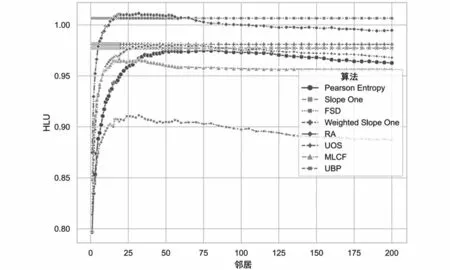
圖5 FSD與其他算法的HLU對比結果Fig.5 HLU comparison result of FSD and other algorithms
通過分析圖4和圖5可知,FSD算法在NDCG方面有更高的值,說明FSD算法的排序能力較好;隨著HLU值中鄰居數的增加,略差于RA算法。但是FSD算法比Slope One等算法提高很多,而且比RA算法預測誤差更小,所以在排序質量指標上有很好的表現,性能也更穩定。
圖6顯示了每個算法在預測過程中對測試集中所有目標使用的平均鄰居數。圖中除FSD和Slope One之外(與Weighted Slope One重合),其他曲線幾乎重合在一起,這些算法選擇的鄰居數量是相同的。由于滿足對目標電影評分條件的用戶數量有限,預測的目標用戶只能接觸到少數符合條件的用戶,因此增長緩慢,即使水平坐標中計劃使用的鄰居數量繼續線性增長。盡管在圖2中預測誤差降低的絕對數值較小,但預測中使用的鄰居數量如圖6所示卻減少很多,這提升了算法的可擴展性。
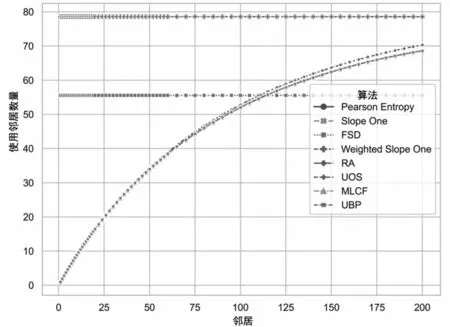
圖6 用于預測的實際鄰居數與算法計劃選擇的鄰居數Fig.6 The actual number of neighbors for prediction and the number of neighbors the algorithm plans to choose
實驗中,FSD算法平均使用55 個鄰居進行預測,優于原Slope One算法的78 個鄰居,其預測時所需鄰居使用量減少了29.49%。這一巨大提升既加快了距離部分的計算速度,也減少了訓練之后需要保存的數據數量(主要是用戶間評分距離數據),通過增加相似性部分的計算和篩選,有效降低了算法的空間復雜度,進而提升了算法的可擴展性。
相同硬件和參數下算法訓練測試所需時間如表1所示。相同條件下每種算法所需的計算時間差異較大,FSD算法在性能整體提升非常明顯的情況下,需要將原Slope One算法的計算時間輕微增加1.9%。
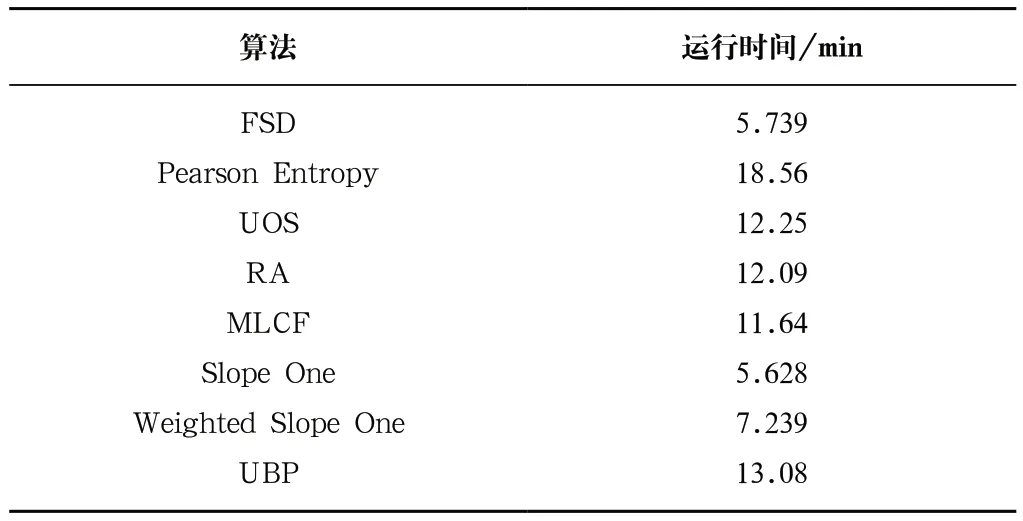
表1 相同硬件和參數下算法訓練與測試所需時間Tab.1 Time required for algorithm training and testing with the same hardware and parameters
6 結論(Conclusion)
本文為了提升距離個性化推薦算法的可擴展性和其他主要性能,將用戶間相似性低于閾值的潛在鄰居從預測目標的鄰居集合中剔除,再利用用戶間評分距離估計目標用戶對未知物品的評分,設計了一種融合用戶相似性與評分距離的個性化推薦算法。
與原距離模型算法相比,所提出的方法不僅在預測過程中所需的鄰居數減少了29.49%,而且預測誤差也降低了,推薦列表排名性能提高了3.8%,有效地提升了距離模型的可擴展性和其他各項主要性能。
研究表明,在推薦系統的預測問題中,通常是通過相似性選擇過濾掉不是很相關的鄰居。雖然相關性較低的鄰居也可以計算出評分距離,但相關性不強,會對預測產生負面影響。與預測目標不夠相似的鄰居用戶對預測造成的弊大于利,應該被丟棄。這種丟棄不僅可以提高算法的可擴展性,還可以提高其預測和推薦性能,應該在未來的研究中得到更多的考慮。
本文的不足之處是預測誤差提升幅度不大,希望能在未來的研究工作中在融合相似性和評分距離的基礎上,進一步擴展算法的性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
