面向書畫著錄的文獻循證與時空關聯構建研究*
2022-10-10 03:52:50高勁松付家煒
大學圖書館學報 2022年5期
□高勁松 付家煒
1 引言
書畫著錄(Catalogue Literature of Calligraphy and Painting)是對中國古代書法、繪畫作品進行目錄性著述的專門文獻,在書畫研究中具有述流傳、記傳記、分派別、辨真偽等多種功能[1]。在古代書畫作品大量散佚、真偽相雜的今日,歷代書畫著錄對于研究古代書畫藝術特征和鑒別傳世作品真偽具有重要參考價值。近年來,云計算、大數據、物聯網等技術的發展催生了數字人文浪潮,為人文學科引入了新的思維模式和研究范式。數字人文的“大帳篷效應”促進了歷史、文學、藝術等人文研究領域的交叉融合,書畫著錄研究作為涉及多個學科的交叉領域,在數字人文興起的背景下有必要引入跨學科的研究視角,通過對人文研究方法與數字分析技術的有機整合,進一步開發書畫著錄潛在的隱性知識價值,從而更好地滿足專業人士與社會公眾對書畫著錄知識的利用需求。
文獻循證是圖情學科對數字人文研究的重要方法論貢獻。循證研究即“基于證據的研究”,強調任何結論都需要從客觀證據中得出,通過建立體系化的原則、流程和方法以保障研究結論的客觀性和科學性。文獻循證是“基于文獻的循證研究”,其實質是以文獻材料中的客觀事實和結論為證據,圍繞研究問題形成一定的證據鏈,進而通過關系推導尋找可靠結論的過程[2]。傳統目錄學、版本學、校勘學中的文獻考據活動對于研究者的經驗和能力具有較高要求[3],而在數字技術的支持下,文獻循證的證據來源不再局限于需要人工鑒別、翻閱的實體文獻,還可擴展至文獻資料中可被機器處理的各種事實知識,循證實踐的應用場景大大擴展。在數字人文興起的背景下,相關研究者依托人文數據基礎設施,對面向文獻事實知識的證據鏈構建和循證分析實踐進行了探索[4]。例如在南海歷史文獻研究中探索文獻循證方法的數字化應用[5-6];在分析古籍文獻循證需求基礎上提出基于文本可視化的古籍循證流程框架[7];在歷史人物研究中應用文獻循證思想,通過量化分析和關聯挖掘構建人物關系網絡圖譜[8];在古籍資源建模研究中圍繞文獻循證的具體需求,構建面向異構資源融合的中文古籍數據模型[9]。
時空分析是利用地理編碼方法將原始信息在一定地理空間中進行時空關聯和可視化表達的研究方法[10]。時空分析將多種地理信息技術引入人文社會科學領域,運用定量、比較、計量等方法研究歷史、社會、自然等多要素關聯,現已成為數字人文的基本研究范式之一[11]。隨著時空分析在數字人文中應用的深入,如何實現時空關聯構建的范式化、流程化,成為相關領域研究者需要關注的問題。時空關聯構建是利用語義本體、自然語言處理、知識圖譜等技術在同一時空基準上對不同尺度的地理數據進行相互關聯,將不同的地理要素構成一個整體以實現更全面的關系表達的過程[12-14],其在數字人文研究中的價值在于能夠厘清各種時間、空間表述的定義、格式及關系,揭示各類要素及其屬性在時空變化中所呈現的規律[15-16]。目前,人文研究領域已在時空關聯構建方面進行了一定探索,例如通過對文化記憶載體時空屬性和關聯的形式化編碼以實現面向文化記憶領域的時空數據建模[17];通過整合社會網絡分析、文本結構分析、古地名提取等方法以滿足古地圖知識組織研究中的時空關聯分析需求[18];通過定義包含屬性、事件、過程、狀態的非物質文化遺產(以下簡稱非遺)時空關聯描述模型,以開展非遺時空演化的量化分析研究[19]。
伴隨著數字人文研究范式的日益成熟,相關研究呈現層次更深、領域更專、粒度更細的發展趨勢,不僅在供給側對人文數據基礎設施的建設水平提出了更高要求,也在需求側呼喚新技術條件下人文研究方法的遷移迭代。在時空分析成為數字人文基本研究范式之一的背景下,將文獻循證方法應用于書畫著錄的時空關聯構建研究,能夠更好地滿足相關領域對書畫作品歷史傳承知識的需求。
2 書畫著錄的時空語義描述與概念分層注釋
2.1 書畫著錄時空語義描述模型
書畫著錄真實地反映了歷代書畫作品的面貌,對揭示作品的歷史傳承具有重要價值。但是由于書畫著錄結構、內容的特殊性,將現有的古籍元數據標準應用于其時空關聯構建時,存在時空屬性揭示不足、領域描述需求難以適配等問題。因此在開展書畫著錄文獻循證時,須針對其結構和內容特征構建專門的時空語義描述模型。本文以圖1所示《江帆山市圖》著錄為例,對書畫著錄的結構和內容進行分析。在文獻結構上,書畫著錄涉及后世記錄的作品題名、創作年代、保管地點等外部要素,裝幀、用紙、技法、尺寸等物理要素,以及題跋、印鑒等反映作品歷史傳承過程的時空要素。在文獻內容上,書畫著錄可以理解為著錄者基于自身認知和著錄體例,對書畫作品內容、形制所進行的半結構化描述,這一過程與現代圖像學中對視覺藝術作品進行內、外部詮釋的圖像志研究具有相似性[20-21]。換言之,書畫著錄中的著錄條目亦可被理解為一種“文本態圖像”,因此在書畫著錄時空語義描述模型構建中,有必要引入面向人文藝術圖像的語義描述方法。
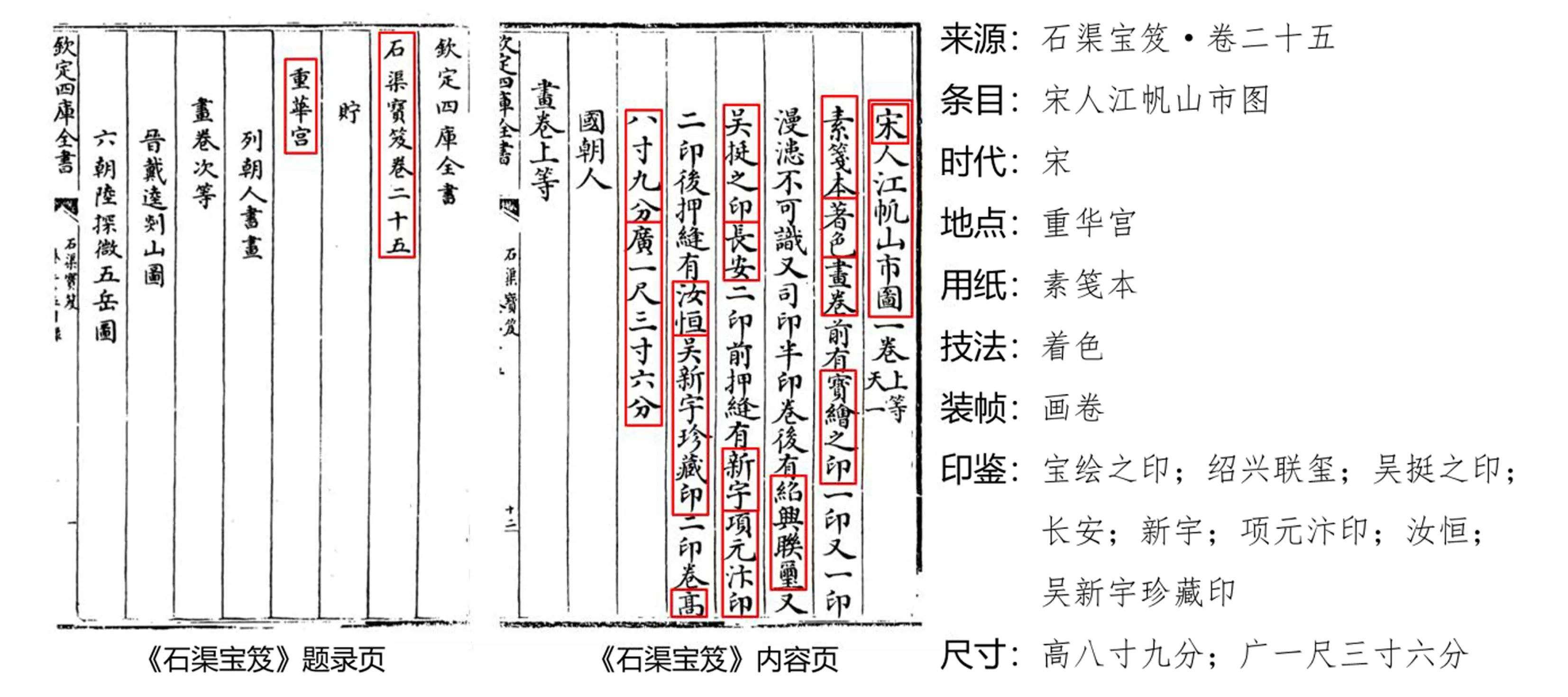
圖1 書畫著錄的結構與內容示例
目前,將視覺藝術領域的圖像學理論應用于人文圖像語義描述的研究已有先例,例如王曉光(Wang X)等參考歐文·潘諾夫斯基(Panofsky E)的圖像學理論構建了面向敦煌壁畫數字圖像的深度語義描述框架[22-23];曾子明等針對數字人文領域的用戶認知需求,在借鑒薩拉·沙特福德(Shatford S)的圖像分層描述理論基礎上提出了面向歷史照片的語義描述模型[24-25];朱學芳等基于對非遺圖像用戶的認知層次分析,應用Panofsky-Shatford模型構建了面向非遺領域的數字圖像描述框架[26]。Panofsky-Shatford模型是圖像學領域的重要理論,Panofsky模型主要通過前圖像志(Pre-iconography)、圖像志(Iconography)、圖像學(Iconology)的三層模型實現圖像內容描述,Panofsky-Shatford模型在前者基礎上進行擴展,將圖像內容劃分為通用概念、具體概念和抽象概念3個層次,每個層次又與人物、事物、時間、地點4個維度分別對應。本文在Panofsky-Shatford模型基礎上結合書畫著錄的結構與內容特征,提出如表1所示的時空語義描述模型。
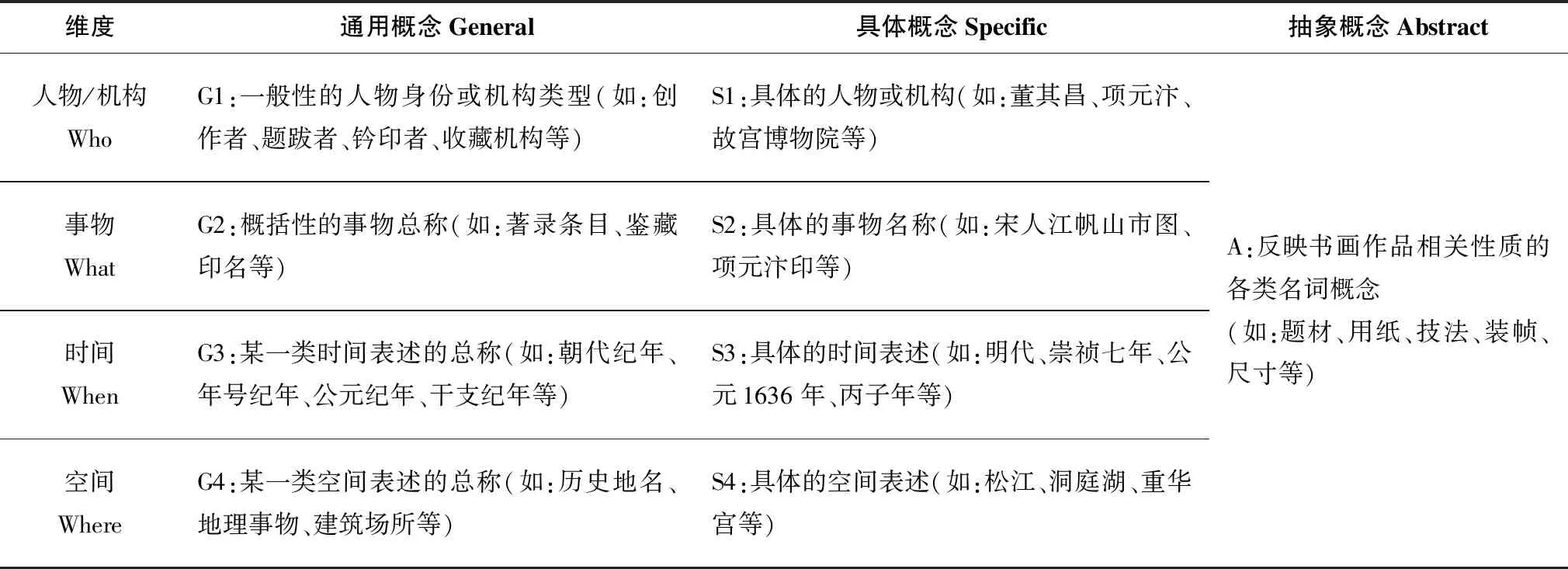
表1 書畫著錄時空語義描述模型
表1的模型包含3個概念層次和4個語義維度,其中Who維度、What維度分別用于表示書畫著錄中的各類人物、事物,When維度用于描述書畫著錄中各種時間表述,并在通用時間概念基礎上擴展了朝代、年號、干支等中國古代特有紀年方式,Where維度用于描述書畫著錄中各類空間表述。模型中,G類字段表示通用或泛指性概念,S類字段表示具體或專指性概念,A類字段用于表示書畫作品的題材、用紙、技法、裝幀、尺寸等抽象概念信息。
2.2 書畫著錄概念分層注釋模型
古代書畫作品是承載文化記憶的媒介資料,其衍生的圖文聲像數據則是以數字形式重組和傳播的文化記憶資源[27]。媒介資料作為文化記憶的載體,具有整體性、延續性和系統性的普遍特征。在書畫領域,媒介資料的整體性體現在書畫作品自身蘊含的直接信息、書畫著錄記載的間接信息以及古今書畫賞評鑒定活動所產生的他者信息之間存在對照、引述、印證等多維關聯;其連續性體現在書畫作品在內容表達、作品創作、題跋鈐印、修復裝裱的過程中形成了“三度時空”的層次分野[28];其系統性則體現在書畫作品及其相關文獻著述所承載的主、客觀知識間存在廣泛的事理邏輯關聯,且這種內容載體關聯在歷史文化變遷中不斷固化和豐富。
基于上述分析,本文沿用Panofsky-Shatford模型的概念分層描述思想,引入媒介關聯性和時空連續性作為分層依據,面向書畫著錄的內容與載體關聯,定義書畫內容(Content)、書畫創作(Produce)、書畫流轉(Transfer)三個概念層次,提出如表2所示的二維分層注釋模型。模型遵循表1的語義劃分維度,定義人物、事物、時間、空間4種概念類型,在此基礎上對書畫著錄的概念層次進行注釋,以實現對同一類型下不同文本的分層處理。例如《江帆山市圖》著錄中,將“素箋本”注釋為“Thing.Produce”,將“項元汴印”注釋為“Thing.Transfer”,由此可在時空層次上對兩個事物概念(Thing)進行區分。
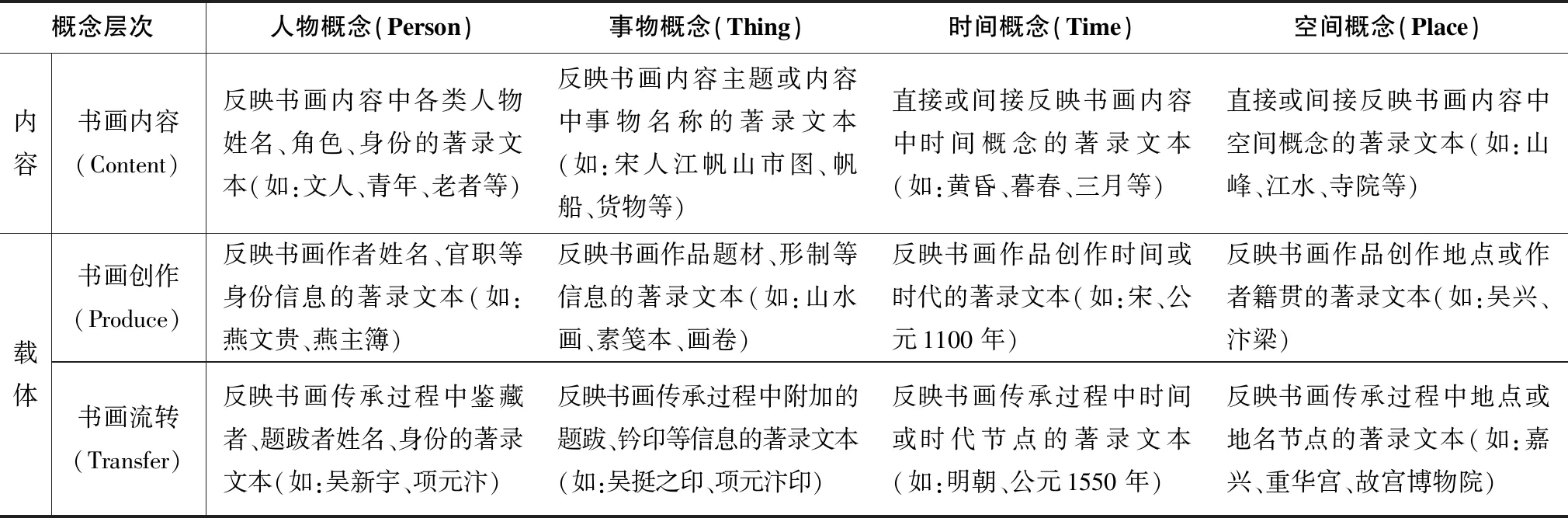
表2 書畫著錄概念分層注釋模型
3 面向書畫著錄的文獻循證與時空關聯構建過程
事實知識是文獻循證的基礎,文獻循證實踐需要對大量事實知識進行結構化存儲,并通過推理和一致性檢驗以構建“事實證據鏈”。在新技術條件下,面向書畫著錄的文獻循證與時空關聯構建可歸納為如圖2所示的過程模型:首先,利用數字化文本標注工具從書畫著錄中抽取實體并通過本體建模實現其關系組織;其次,引入歷史人物傳記、歷史紀年表、歷史地名表等可以互相佐證的數據源(以下簡稱互證數據源)對標注實體進行語義對齊和一致性檢驗,并通過多輪實體匹配過程揭示標注實體的時空語義關聯;再次,利用語義知識庫進行書畫著錄時空關聯證據鏈的持久化保存,實現文獻循證數據存儲和文獻循證過程揭示。
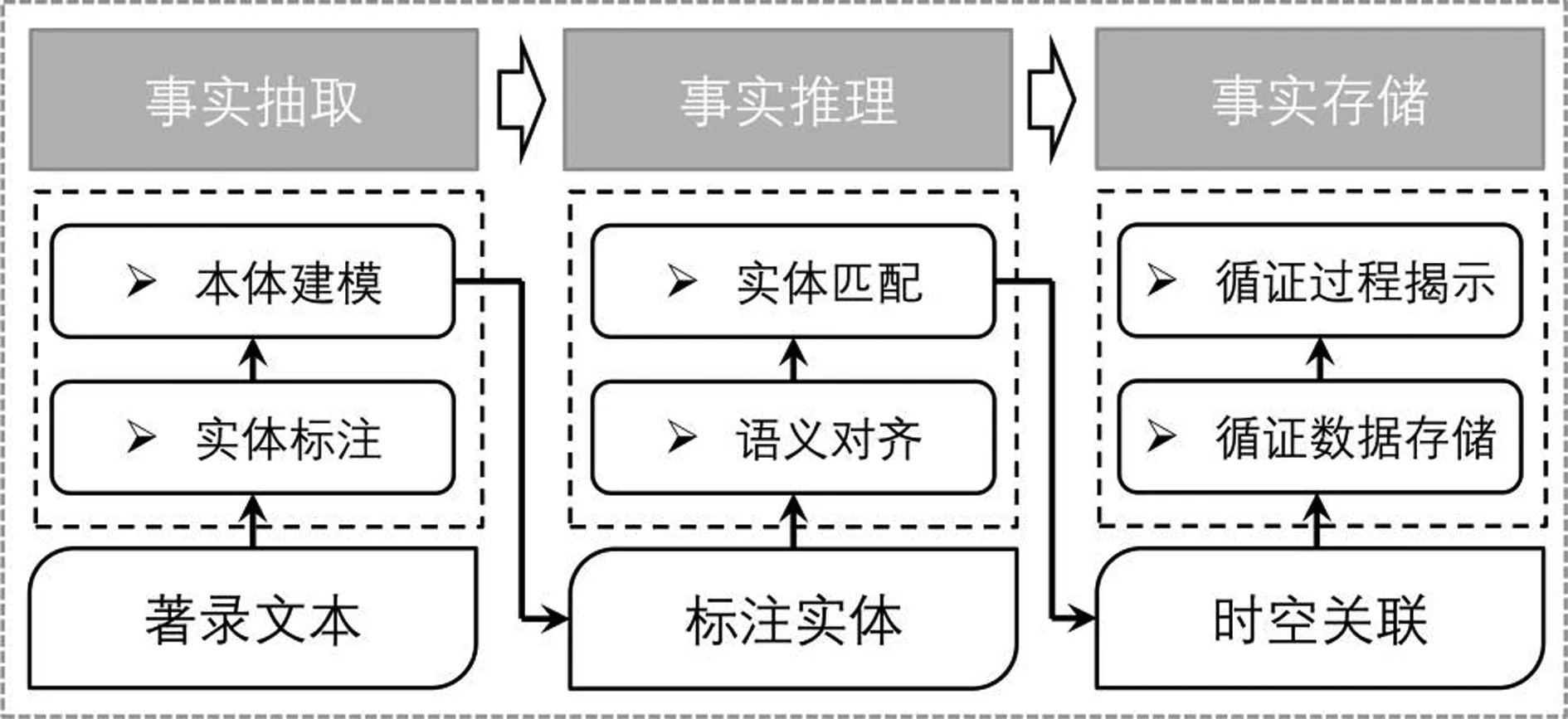
圖2 面向書畫著錄的文獻循證與時空關聯構建過程
3.1 基于文本標注的書畫著錄事實抽取
書畫著錄事實抽取是對著錄文本中的語義實體進行識別、標記并生成結構化數據集的過程。傳統文獻循證實踐中主要通過“細讀”實現文獻事實抽取,即運用不同字形、字體、顏色、形狀的標記對紙質文獻中的人物、事物、時間、地點等實體進行標注[29]。在新技術條件下,面向數字人文的文本標注工具在實現數字化細讀的同時可兼顧標注數據的管理組織,降低了文本標注的專業技術門檻,提升了相關方法在人文研究中的適用性[30-31]。本文在引入數字化文本標注工具的基礎上,提出面向書畫著錄的事實抽取流程,包含實體標注和本體建模兩個關鍵環節,如圖3所示。
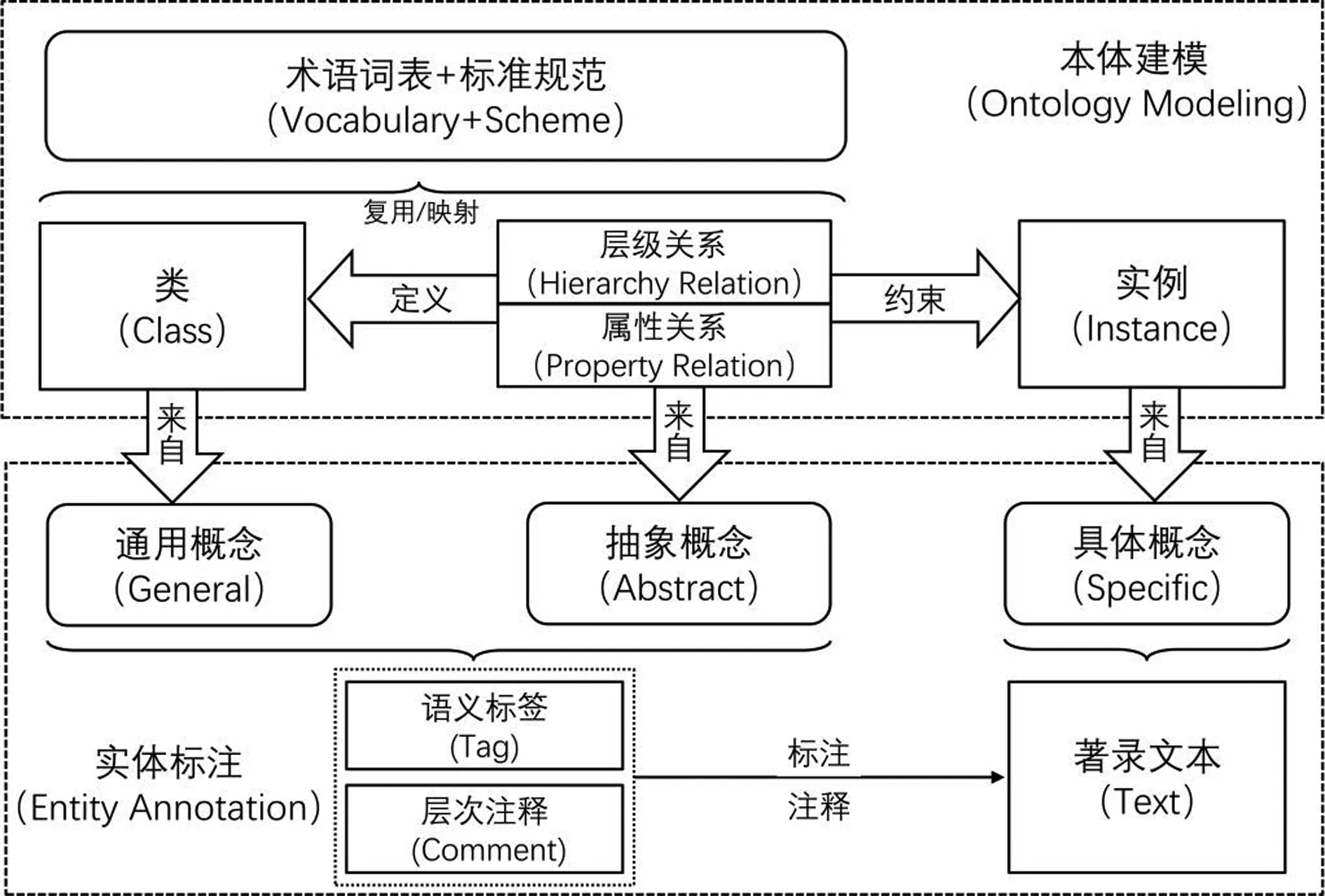
圖3 基于文本標注的書畫著錄事實抽取流程
首先,遵循書畫著錄時空語義描述模型定義語義標簽,并完成標簽集構建。語義標簽主要來源于模型中的通用概念和抽象概念,由字段類型和標簽名稱組合構成,例如“G1.創作者”。其次,將書畫著錄中的語義實體與時空語義描述模型中的概念定義進行匹配,并通過標注工具將著錄文本轉換為對應標簽下的標注實體。再次,面向標注數據進行書畫著錄本體建模,在復用已有術語詞表或標準規范的基礎上,依據時空語義描述模型對本體類和本體屬性進行定義,并通過屬性約束實現標注實體的概念界定和關系揭示。其中本體類、層次關系、屬性關系主要來源于時空語義描述模型中的通用概念和抽象概念,本體實例則主要來源于書畫著錄的標注實體。在此基礎上,為了反映著錄文本的概念層次,在創建本體實例時中需復用RDFS詞表的rdfs:comment屬性,以存儲其概念層次注釋信息,例如“Thing.Content”“Person.Produce”等。
3.2 基于實體匹配的書畫著錄事實推理
書畫著錄事實推理是將標注實體與各種互證數據源進行對齊,再通過實體匹配揭示各型實體的時空屬性和語義關系,進而建立時空關聯的過程。在數字人文實踐中,相關研究者主要通過面向特定領域的時空數據建模,以實現實體的時空屬性定義和時空關系揭示。而在書畫著錄領域,受制于書畫著錄的文種體裁特性和歷史文本的措辭用語特征,直接反映時空語義的實體關系往往相對稀疏,僅依賴時空數據建模難以有效揭示書畫著錄中人物、題跋、鑒藏印等非時空實體所隱含的潛在時空語義。因此,本文引入基于實體匹配的書畫著錄事實推理過程,如圖4所示。
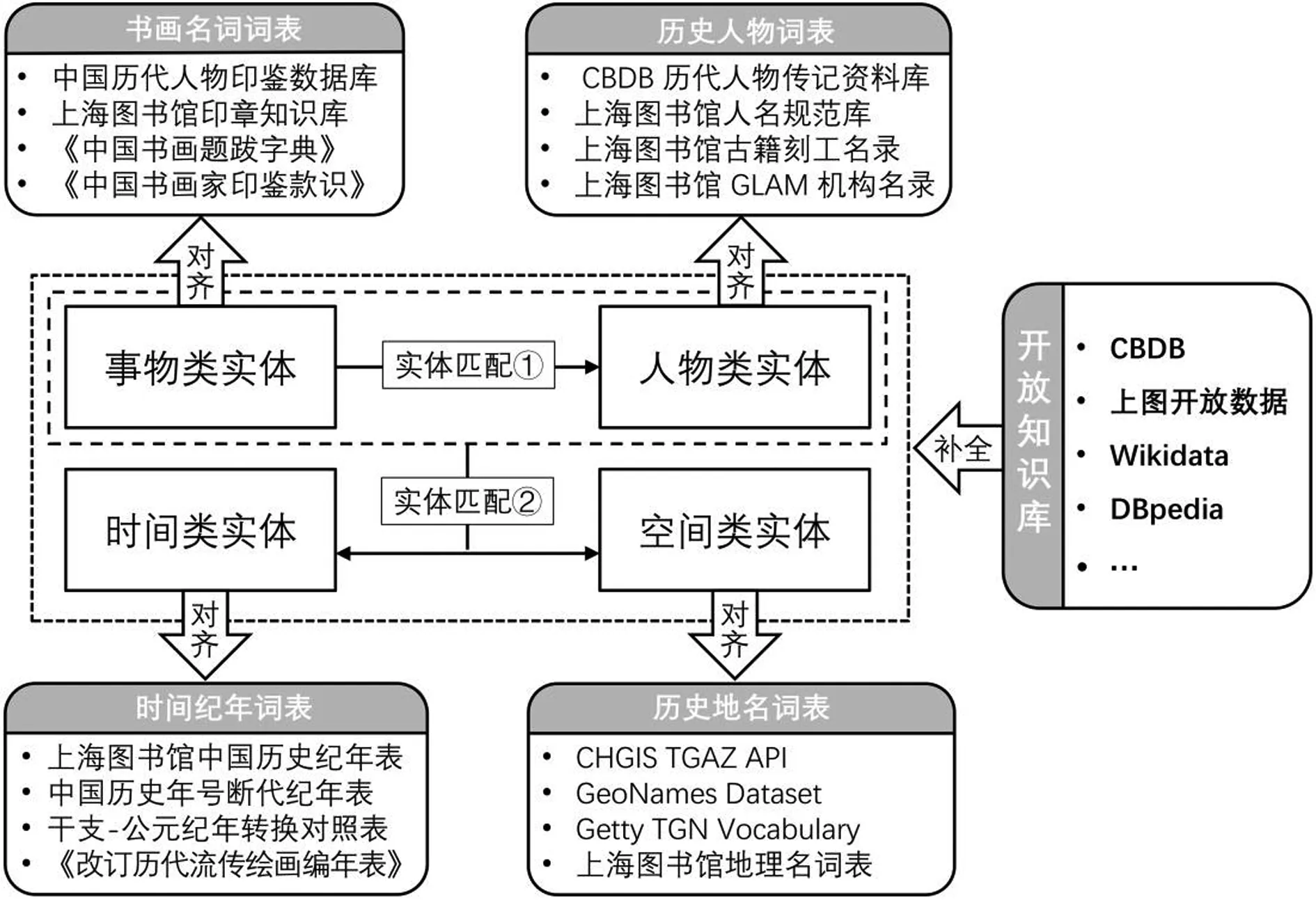
圖4 基于實體匹配的書畫著錄事實推理流程
首先,依據書畫著錄標注實體所屬維度與其他互證數據源進行語義對齊。分別針對人物、事物、時間、空間維度選取歷史人物詞表、書畫名詞表、歷史紀年表、歷史地名表等作為互證數據源;通過標注實體與互證資料的語義對齊實現概念消歧、缺省屬性補全和關系修正。其次,在事物類實體與人物類實體間進行實體匹配,通過工具書查閱、數據庫檢索等途徑將題跋、鑒藏印等事物實體與書畫創作者、題跋者、鑒藏者等特定的人物實體建立關聯,形成“事物→人物”的關聯關系,作為進一步揭示其時空關聯的中介。再次,在非時空類實體與時空類實體間進行實體匹配,其核心是以人物為線索,通過揭示歷史人物的籍貫、生卒年限、生平軌跡等時空信息以構建“事物→人物→時空”的時空關聯鏈條。此外,在標注實體與互證數據源的對齊、匹配過程中,需通過文獻考證和邏輯推斷將標注實體與外部開放數據集或知識庫中的實體建立映射,通過引入外部實體以對書畫著錄時空關聯證據鏈進行補全,同時提升證據鏈與外部數據網絡的互操作性。
3.3 基于圖數據庫的書畫著錄事實存儲
書畫著錄事實存儲是通過構建語義知識庫對文獻循證的事實數據、互證數據和推理過程進行表示和存儲并形成“事實證據鏈”的過程。在書畫著錄時空關聯構建中,事實存儲不僅要實現對原始數據、互證數據的有序組織,還需對書畫著錄的文獻循證過程進行描述和揭示,從而適應知識利用過程中的多場景需求。圖數據庫是領域知識圖譜構建的重要支撐技術,與傳統關系型數據庫相比,圖數據庫通過相互連接的節點和邊實現知識表示,在存儲文獻循證數據、反映文獻循證過程時具有顯著優勢。本文基于圖數據庫技術構建書畫著錄文獻循證數據的事實存儲框架,如圖5所示。
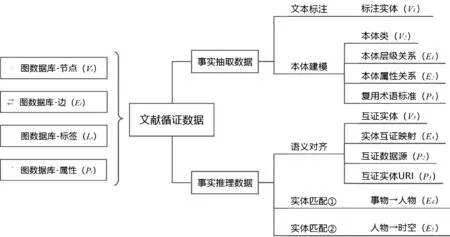
圖5 基于圖數據庫的書畫著錄事實存儲框架
首先,定義圖數據庫模型G=〈Vi,Ei〉,其中Vi為圖數據庫的節點(vertex)集合,Ei為反映節間關系的邊(edge)集合。Vi=〈Li,Pi〉,其中Li即節點標簽(label),用于表示節點的類型;Pi即屬性(property),用于表示一類節點所具有的性質。Ei=〈Li,subject,object〉,其中Li表示邊所描述的關系類型,subject和object分別表示邊所連接的頭尾節點。其次,將文獻循證過程中生成的標注實體(V1)、本體類(V2)、互證實體(V3)分別通過圖數據庫的節點(Vi)進行表示,并利用節點標簽(Li)對實體類型進行區分。再次,將本體模型的層級關系(E1)、屬性關系(E2),語義對齊生成的實體互證映射(E3)以及“事物→人物→時空”的實體匹配記錄(E4,E5)作為圖數據庫的邊(Ei)進行存儲。最后,通過定義圖數據庫的節點屬性(Pi),完成對概念層次注釋(P1)、復用術語標準(P2)、互證數據源(P3)以及互證實體URI(P4)等文本型數據的表示和存儲。
4 案例實驗:以《石渠寶笈》書畫著錄為例
《石渠寶笈·初編》(以下簡稱為石渠寶笈)是清代官修的內府書畫集成,被視為中國古代書畫著錄的集大成者。該書共四十四卷,對清故宮收藏的書畫作品進行了全面著錄,詳細記載了書畫作品的形制、題跋、款識等細節,在書畫研究領域頗具史料價值。石渠寶笈原書體量巨大、領域背景復雜,本文以故宮博物院編著的工具書《故宮博物院藏石渠寶笈精粹》為依據[32],借鑒其作品收錄列表確定實驗數據采集范圍;并以殆知閣古代文獻數字化項目為數據源[33],對實驗所需著錄條目進行查詢、獲取,形成總計9865字的原始語料。
4.1 《石渠寶笈》書畫著錄的事實抽取
(1)著錄文本的語義標簽集構建。本實驗依據書畫著錄時空語義描述模型分析石渠寶笈原始語料的內容、文種結構,構建如表3所示的語義標簽集,并以《洛神賦圖卷》著錄為例對各標簽定義進行說明,表中“「」”內為石渠寶笈的著錄原文片段,“【】”內為語義標簽所對應的標注對象。
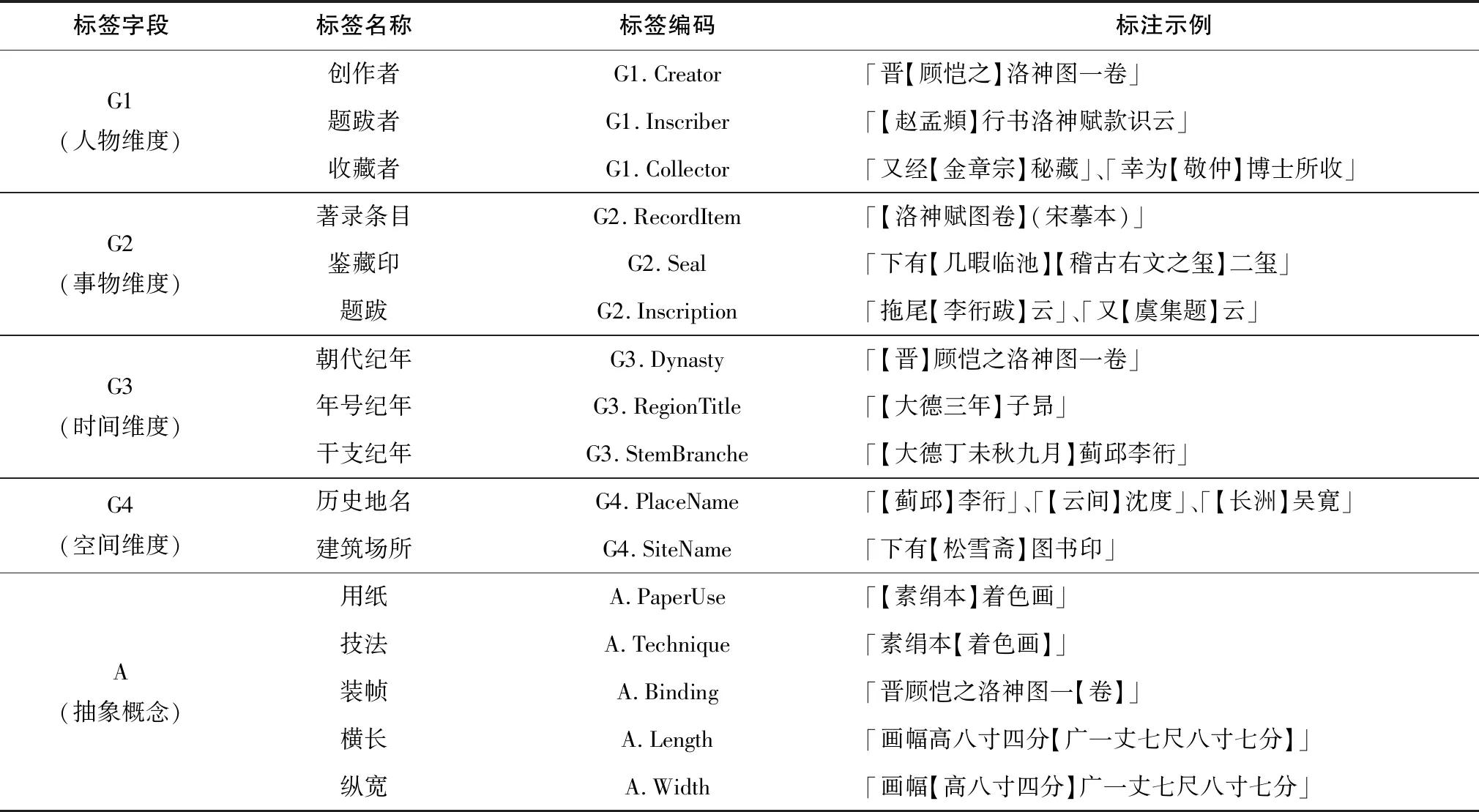
表3 《石渠寶笈》書畫著錄語義標簽集
(2)著錄文本的實體標注。本實驗選取“碼庫斯(MARKUS)古籍標注平臺[34]”進行著錄文本的實體標注,其界面如圖6所示。首先依據語義標簽集定義,在MARKUS中對標簽的顏色、格式、編碼進行設置。其次利用MARKUS的實體關系標注功能,對著錄文本中人物、事物、時空等實體關系進行初步組織,為本體建模提供依據。再次將實體標注數據以結構化格式(CSV)導出,共包含492個標注實體,其中人物類實體(G1字段)99個、事物類實體(G2字段)226個、時間類實體(G3字段)50個、空間類實體(G4字段)19個、抽象類實體(A字段)98個。
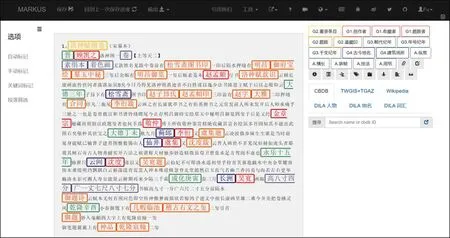
圖6 MARKUS文本標注界面
(3)著錄文本的本體建模。本實驗以表3的語義標簽集為基礎,在復用已有術語詞表和標準規范的基礎上,構建石渠寶笈著錄本體概念模型,如圖7所示。由圖7可知,該本體復用了FOAF、CIDOC-CRM、Dublin Core Terms、OWL-Time等術語標準,使用“zhulu”前綴表示本體命名空間,通過定義子類關系以揭示各個本體類之間的概念層級,通過定義對象屬性以表示本體類之間的語義關系。對象屬性中,“hasRecord”用于表示著錄條目類與其他標注實體之間的對應關系,“EntityMatch_1”用于表示事物類實體和人物類實體之間的推理關系,“EntityMatch_2”用于表示人物類實體與時空實體間的推理關系。對于標注數據中反映著錄文本概念層次的注釋信息,以及反映用紙、技法等抽象概念的標注實體,則作為各個本體類的數據屬性以文本形式存儲。
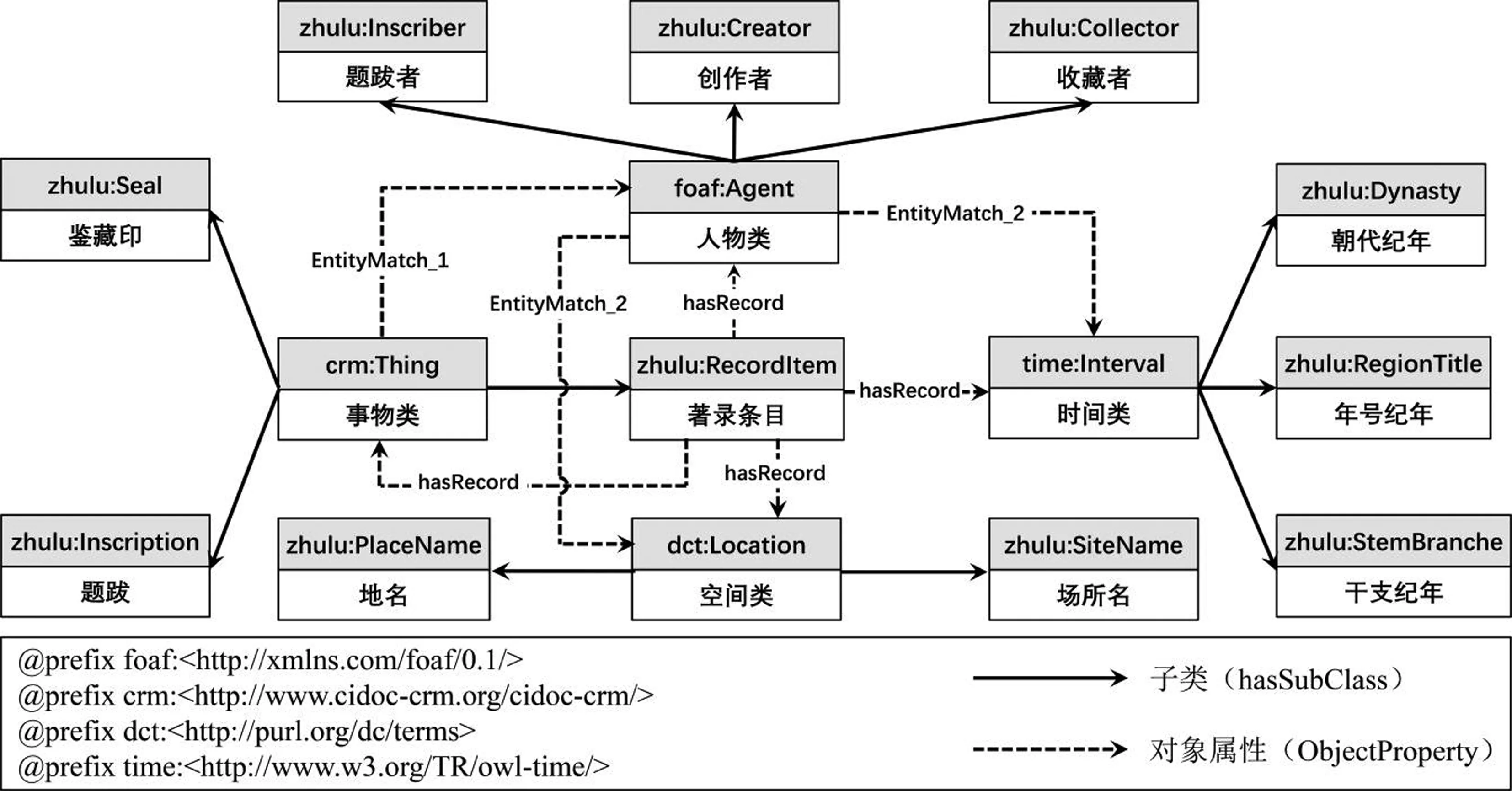
圖7 《石渠寶笈》著錄本體概念模型
4.2 石渠寶笈標注實體的事實推理
(1)標注實體的語義對齊。本實驗分別從人物、事物、時間、空間維度選取標注實體的互證資料來源,具體包括:中國歷代人物傳記資料庫(CBDB)[35]、中國歷史地理信息系統(CHGIS)[36]、浙江圖書館歷代印鑒數據庫[37]以及上海圖書館發布的歷史人名規范庫、中國歷史紀年表、地理名詞表[38]。基于上述互證數據源對492個標注實體進行語義對齊,引入外部互證實體128個,建立對齊關系134條。語義對齊過程如下:人物類實體分別通過歷史人名規范庫和CBDB資料庫進行檢索,獲取對應的互證實體和URI標識,并實現同名消歧。事物類實體主要與歷代印鑒數據庫進行對齊,通過印章釋文檢索鑒藏印主人身份和ID標識。時間類實體按朝代、年號、干支等紀年方式分別計算其對應的公元紀年,并在中國歷史紀年表中獲取對應的互證實體和URI標識。空間類實體中,地名實體通過CHGIS TGAZ API檢索歷史地名[39],再通過地理名詞表獲取對應的規范地名實體和URI標識。場所實體在考證其所在地名稱后,參照地名實體進行語義對齊。
(2)標注實體的時空關聯構建。本實驗遵循圖4所示的實體匹配流程,在從外部數據源中引入人物實體19個、時間實體62個、空間實體33個進行補全的基礎上,建立“事物→人物”關聯143組,“人物→時間”關聯110組,“人物→空間”關聯100組。表4以《洛神賦圖卷》著錄中部分實體為例,闡述基于實體匹配的時空關聯構建過程,其中“【 】”表示標注實體,“[ ]”表示經語義對齊或知識庫匹配引入的外部實體,“=>”表示語義對齊,“→”表示推理關系。在“事物→人物”匹配中,依據鑒藏印實體的印章主人ID在印鑒數據庫中檢索相關人物資料,并與人物實體進行匹配,據此在事物實體和人物實體間建立推理關聯。在“人物→時空”匹配中,首先進行基于上下文的實體匹配,將人物實體與著錄上下文中的時空實體建立關聯;其次進行基于人物數據庫的實體匹配,通過互證數據源獲取人物實體的生卒、籍貫等時空信息,以生卒年取均值作為關聯時間實體,以籍貫地名作為關聯空間實體。
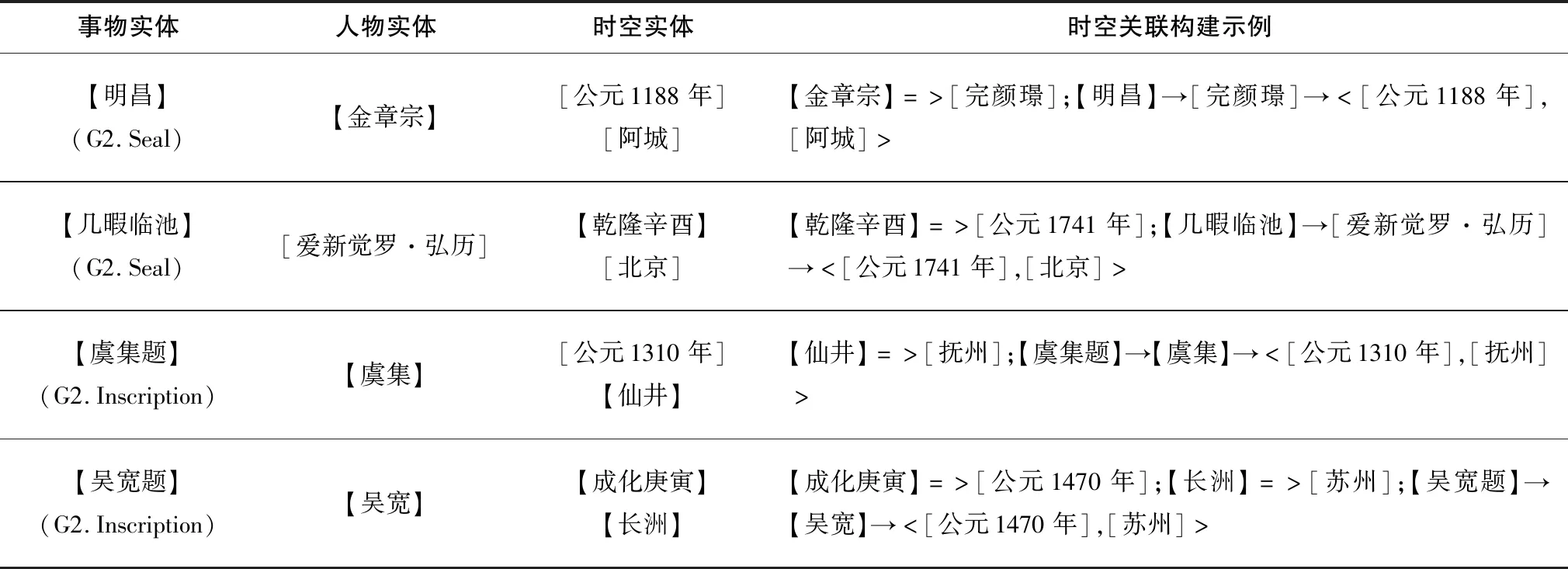
表4 基于實體匹配的石渠寶笈時空關聯構建
4.3 石渠寶笈時空關聯的事實存儲
(1)石渠寶笈文獻循證數據的存儲。本實驗基于Neo4j圖數據庫搭建石渠寶笈文獻循證數據的存儲環境,定義包含3類節點和7類節點關系的圖數據庫模型,如表5、表6所示。遵循該模型將石渠寶笈書畫著錄的文本標注、本體建模、語義對齊、實體匹配數據分別導入圖數據庫管理系統,構建包含636個節點、1410條節點關系、1893項節點屬性的石渠寶笈時空關聯圖數據庫。
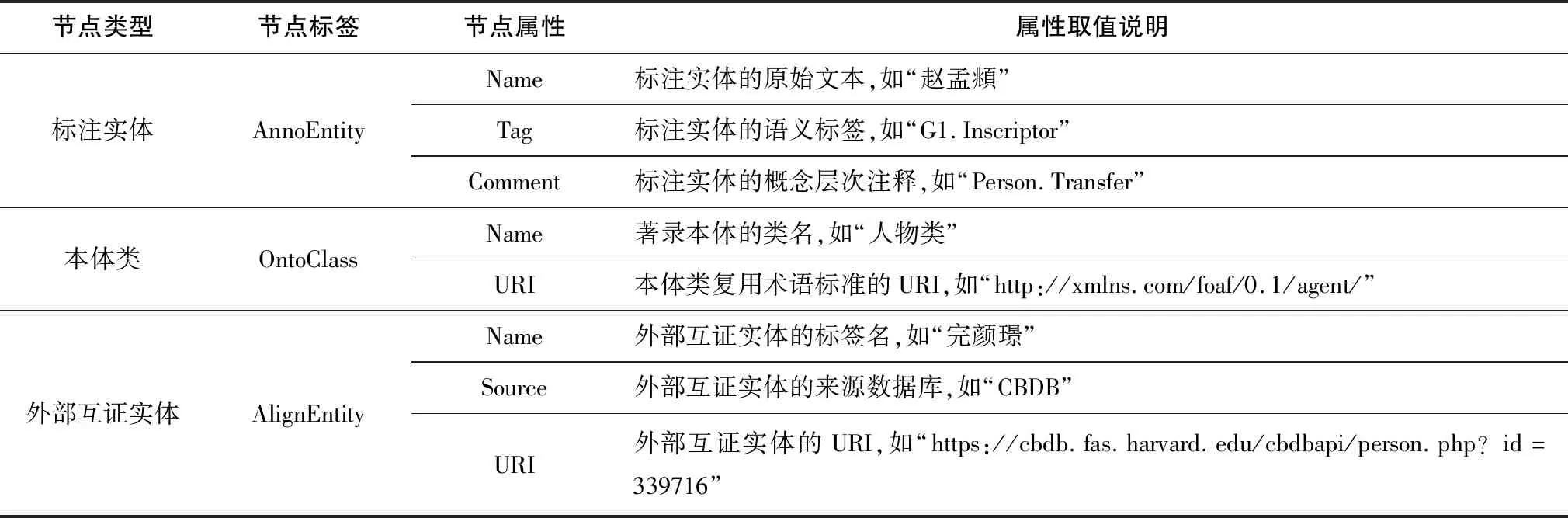
表5 圖數據庫的節點定義
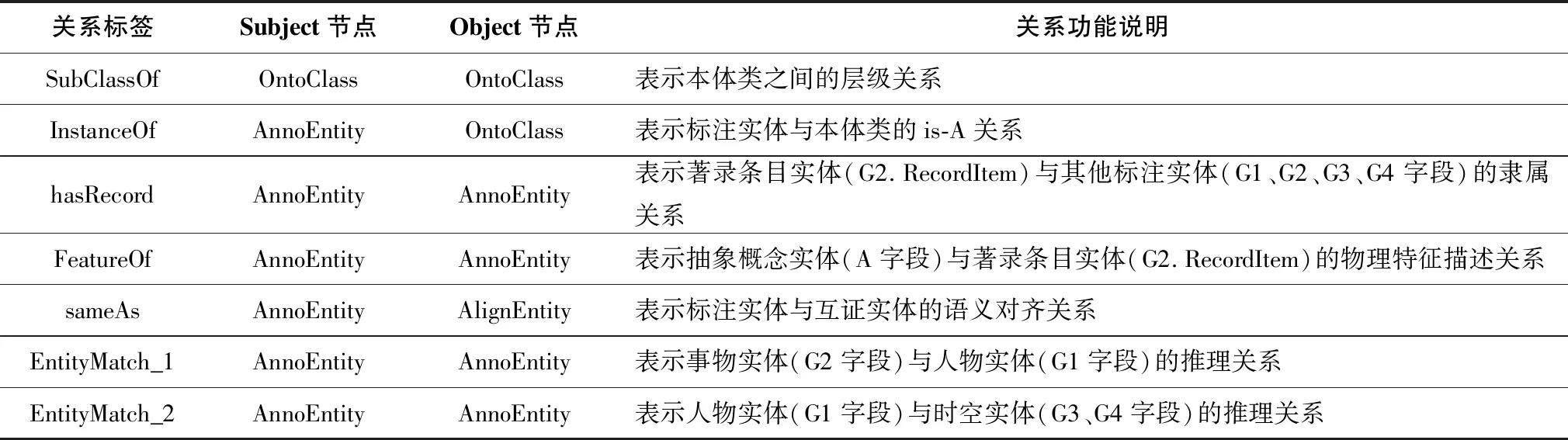
表6 圖數據庫的節點關系定義
(2)石渠寶笈時空關聯的查詢與呈現。本實驗在構建石渠寶笈時空關聯圖數據庫的基礎上,通過Cypher查詢工具進行時空關聯的可視化呈現。圖8以《洛神賦圖卷》為例,通過Cypher語言構建查詢式,輸出該作品的時空傳承概況,查詢式為:“match (m:AnnoEntity{Name:"洛神賦圖卷"})-[:hasRecord]->(n),(n)-[:sameAs]->(o),(o)-[:EntityMatch_2]->(x) with m,n,o,x match (p:AnnoEntity{Name:"洛神賦圖卷"})-[:hasRecord]->(q),(q)-[:EntityMatch_1]->(r),(r)-[:EntityMatch_2]->(y) return m,n,o,x,q,r,y”。由圖8可知,《洛神賦圖卷》時空關聯證據鏈是以標注實體“洛神賦圖卷”為核心的多層環狀結構,自內向外分別是反映著錄文本的標注實體層,通過“事物→人物”匹配(EntityMatch_1)形成的人物關聯層以及通過“人物→時空”匹配(EntityMatch_2)形成的時空關聯層。在圖數據庫框架下,證據鏈中的時空節點分別與公元紀年和現代規范地名進行對齊,反映了特定書畫作品的歷史傳承軌跡;同時,人物、時間、空間節點均通過節點屬性建立了與CBDB或歷史人名規范庫、歷史紀年表、地理名詞表的URI映射,可通過訪問外部開放知識庫中對應的互證實體獲取更多相關資料。
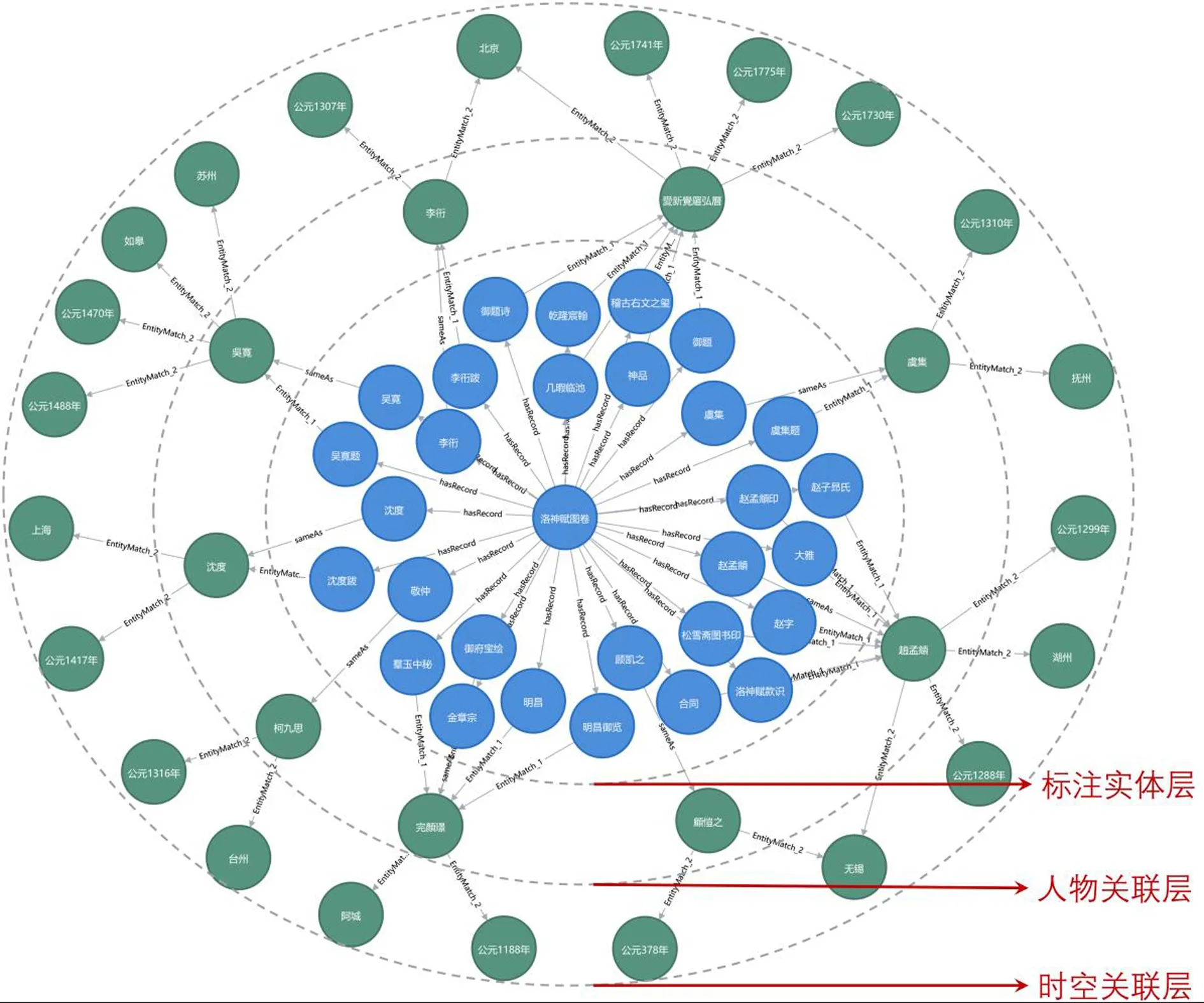
圖8 《洛神賦圖卷》時空關聯證據鏈圖譜
圖9是對圖數據庫中存儲的文獻循證記錄進行遍歷查詢所生成的石渠寶笈時空關聯證據鏈圖譜,包含457個節點和438條節點關系,查詢式為:“match (m)-[:EntityMatch_1]->(n),(n)-[:EntityMatch_2]->(o) with m,n,o match (p)-[:sameAs]->(q),(q)-[:EntityMatch_2]->(x) return m,n,o,p,q,x”。圖9中,時空關聯證據鏈圖譜的各個節點形成了規模各異的多個團簇(Cluster):其中規模最小的團簇至少包含4個節點,并通過節點關系形成“事物→人物→時空”的基本證據鏈,例如“寄傲→項元汴→〈公元1557年,嘉興〉”;而虛線范圍中以“蘇州”為中心節點,以“公元1481年”“杭州”“愛新覺羅弘歷”等為中介節點的節點群落構成了圖譜中規模最大的團簇(包含212個節點)。由圖9可知,通過對書畫著錄時空關聯進行可視化呈現,能夠對書畫著錄中以著錄條目為基本單位的知識結構進行重組與再現,進而直觀揭示書畫著錄中時間、空間及人物實體的多維度關聯,為揭示古代書畫作品傳承軌跡提供了新的分析視角。
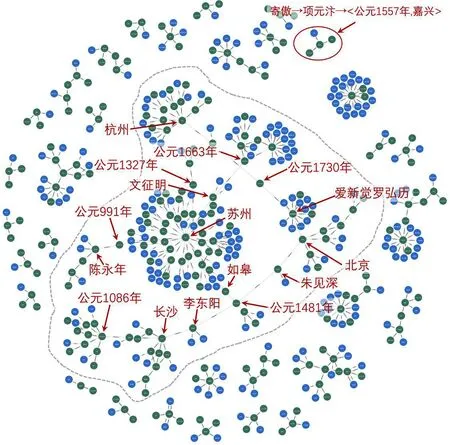
圖9 《石渠寶笈》時空關聯證據鏈圖譜
4.4 實驗結果分析與討論
上述實驗以石渠寶笈書畫著錄為案例,對基于文獻循證方法構建書畫著錄時空關聯的有效性進行檢驗。在數據獲取方面,實驗以石渠寶笈書畫研究領域的權威工具書為依據,合理確定書畫著錄調研范圍,在書畫形制、創作年代、題跋鈐印、流傳地域等方面涵蓋了中國傳世書畫作品的基本分布特征,具有一定的典型性和代表性。實驗在完成石渠寶笈書畫著錄的事實抽取、推理和存儲基礎上,利用圖數據庫可視化工具輸出了石渠寶笈時空證據鏈圖譜,論證了以“事物→人物→時空”為基本單元的事實推理鏈條能夠滿足書畫著錄時空關聯證據鏈的構建需求。
基于對實驗過程與結果的分析,現階段通過文獻循證方法構建書畫著錄時空關聯仍面臨以下不利條件:首先,文獻循證過程中文本標注、語義對齊的自動化程度有待進一步提升。其次,需在圖數據庫框架下引入更加高效的數據查詢與分析技術。再次,需以更加直觀、易用的方式對書畫著錄時空關聯進行可視化、交互式呈現。因此,在未來研究中,一方面需要引入人機結合的文本標注與資料比對機制,以提升事實抽取與推理階段的效率;另一方面需將整體網分析、圖計算、GIS分析等方法引入時空關聯查詢和呈現過程,以豐富時空關聯揭示維度,提升隱性知識挖掘深度。
5 結語
本文重點研究了新技術條件下文獻循證方法在書畫著錄時空關聯構建中的應用模式。圍繞研究目標,首先研究書畫著錄的時空語義描述和概念分層注釋方法,提出面向書畫著錄的文獻循證與時空關聯構建過程,在此基礎上以石渠寶笈書畫著錄為例開展案例實驗。實驗結果表明,本文提出的事實抽取、事實推理與事實存儲相結合的文獻循證過程模型能夠滿足書畫著錄時空關聯證據鏈的構建需求,并支持在時空語義揭示的基礎上匹配多種書畫著錄知識利用場景。在未來研究中,還需進一步提升文獻循證過程的自動化程度,在文本標注、資料比對、圖譜查詢、時空可視化等環節不斷引入技術驅動、人機結合的數據處理機制,為書畫著錄時空關聯數據集的大規模自動構建提供理論和實踐參照。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
