高維縱向數(shù)據(jù)的亞組識(shí)別方法及應(yīng)用
2022-10-11 13:30:48吉洋瑩
段 謙,吉洋瑩,黃 磊
(西南交通大學(xué) 數(shù)學(xué)學(xué)院, 成都 611756)
0 引言
亞組識(shí)別常用于精準(zhǔn)醫(yī)療[1]或精準(zhǔn)營(yíng)銷(xiāo)[2],根據(jù)個(gè)體之間的異質(zhì)性,針對(duì)不同亞組的個(gè)體采取特異性的方案,從而提高總體的治療效果或營(yíng)銷(xiāo)收益。因此,在進(jìn)行統(tǒng)計(jì)推斷和決策之前,先正確識(shí)別亞組是十分有必要的。常用的亞組識(shí)別參數(shù)劃分的方法有貝葉斯方法[3]、分類與回歸樹(shù)[4]等。然而,在大數(shù)據(jù)的背景下,遞歸分割方法具有通用性和更強(qiáng)的計(jì)算效率,使得一系列非參數(shù)方法流行起來(lái),這類方法包括針對(duì)患者分層的預(yù)后特征所提出的PRIM方法[5]、適用于臨床藥物開(kāi)發(fā)所提出的sequential-batting方法[6]、基于最大似然估計(jì)原理所提出的MOB方法[7]等。亞組識(shí)別方法的原理是如果某些個(gè)體屬于同一亞組,則協(xié)變量對(duì)同一亞組的預(yù)期效應(yīng)是相同的。為了更好地對(duì)群體進(jìn)行亞組識(shí)別,目前已有二值分割[8]、同時(shí)分組劃分和特征選擇[9]、分層聚類[10]等方法。有關(guān)亞組識(shí)別方法的詳細(xì)文獻(xiàn)綜述,可以參閱Lipkovich等[11]的文章。由于每個(gè)個(gè)體中有大量的測(cè)量數(shù)據(jù),因此可以將每個(gè)個(gè)體中的數(shù)據(jù)視為一個(gè)獨(dú)特的亞組,并擬合一個(gè)適合這個(gè)亞組的模型。與傳統(tǒng)的總體模型相比,該建模方法允許不同亞組間模型的協(xié)變量系數(shù)發(fā)生變化。將在高維縱向數(shù)據(jù)的背景下構(gòu)建一種亞組識(shí)別的方法。在詳細(xì)介紹此亞組識(shí)別方法前,先介紹一下縱向數(shù)據(jù)和高維變量篩選。
縱向數(shù)據(jù)[12]是按照時(shí)間的推移對(duì)一系列的個(gè)體進(jìn)行重復(fù)多次測(cè)量獲得的兼?zhèn)錂M截面數(shù)據(jù)特性和時(shí)間序列特性的一類數(shù)據(jù)。縱向數(shù)據(jù)可分析個(gè)體的響應(yīng)變量隨時(shí)間變化的趨勢(shì),也可橫向?qū)Ρ葌€(gè)體之間的差異。根據(jù)研究課題內(nèi)重復(fù)測(cè)量的次數(shù),縱向數(shù)據(jù)可以分為不定期測(cè)量的且測(cè)量次數(shù)有限的稀疏縱向數(shù)據(jù)[13]和定期測(cè)量且測(cè)量次數(shù)趨于無(wú)窮的密集縱向數(shù)據(jù)[14]。現(xiàn)有文獻(xiàn)詳細(xì)地探究了縱向數(shù)據(jù)的統(tǒng)計(jì)方法,常見(jiàn)的有參數(shù)方法、非參數(shù)方法以及半?yún)?shù)方法。Liang等[15]基于擬似然的思想提出了廣義估計(jì)方程的方法,且驗(yàn)證了該方法運(yùn)用到實(shí)際縱向數(shù)據(jù)分析的問(wèn)題中是有效的;趙明濤等[16]研究了縱向數(shù)據(jù)的單指標(biāo)模型的參數(shù)估計(jì)方法;李劭珉等[17]利用指數(shù)平方損失函數(shù)對(duì)縱向數(shù)據(jù)模型構(gòu)建了一種穩(wěn)健的估計(jì)法;Li等[18]提出了基于B樣條基的同質(zhì)劃分方法對(duì)縱向數(shù)據(jù)進(jìn)行了研究。隨著大數(shù)據(jù)技術(shù)的發(fā)展,縱向數(shù)據(jù)也越來(lái)越容易收集到高維的協(xié)變量,因此對(duì)縱向數(shù)據(jù)進(jìn)行回歸建模時(shí),也有必要考慮高維協(xié)變量的篩選。
模型的協(xié)變量過(guò)多,或者說(shuō)數(shù)據(jù)的維度過(guò)高就會(huì)產(chǎn)生多重共線性或者偽相關(guān)問(wèn)題,并導(dǎo)致參數(shù)估計(jì)量的方差過(guò)大以及響應(yīng)變量預(yù)測(cè)值的方差過(guò)大,且在擬合高維模型時(shí)需要強(qiáng)大的計(jì)算量,費(fèi)時(shí)費(fèi)力。統(tǒng)計(jì)學(xué)者們通過(guò)引入懲罰估計(jì)方法對(duì)此類問(wèn)題進(jìn)行系數(shù)收縮建模,如景甜甜等[19]利用主成分對(duì)肌電信號(hào)特征參數(shù)進(jìn)行降維,摒棄冗余信息;林倩瑜[20]結(jié)合特征壓縮方法對(duì)分類輸出的云服務(wù)組合大數(shù)據(jù)進(jìn)行降維處理;還有l(wèi)asso[21]以及elastic-net[22]等廣為人知的統(tǒng)計(jì)學(xué)習(xí)方法,但是這些方法都不具有oracle性質(zhì),即不具備模型選擇的相合性和參數(shù)估計(jì)的漸近正態(tài)性;在此基礎(chǔ)上,F(xiàn)an等[23]提出了SCAD(smoothly clipped absolute deviation)方法,Zhang[24]提出了極大極小凹懲罰(minimax concave penalty)方法,簡(jiǎn)稱MCP方法。這些懲罰估計(jì)方法不僅可以剔除不重要的協(xié)變量,還可以提高計(jì)算效率,最終獲得更穩(wěn)健的預(yù)測(cè)模型。其中MCP已經(jīng)成為對(duì)高維數(shù)據(jù)進(jìn)行變量選擇的一種流行工具。該方法能有效地篩選出不重要的協(xié)變量,從而獲得一個(gè)更簡(jiǎn)約的模型。除此之外,它還能減少過(guò)度擬合的可能性,并使建模過(guò)程不那么耗費(fèi)算力。與lasso等方法相比,MCP方法更能產(chǎn)生稀疏的模型,并獲得參數(shù)的無(wú)偏估計(jì)。因此將采用MCP對(duì)高維縱向數(shù)據(jù)的亞組識(shí)別問(wèn)題進(jìn)行變量選擇。到目前為止,高維縱向數(shù)據(jù)的亞組識(shí)別并沒(méi)有得到徹底的研究,也沒(méi)有完整的解決方案。
綜上所述,將針對(duì)高維縱向數(shù)據(jù)進(jìn)行建模分析,將變量選擇方法與亞組識(shí)別方法相結(jié)合,即將MCP方法引入到同質(zhì)劃分中,再通過(guò)二值分割的方法對(duì)回歸系數(shù)之間的變點(diǎn)進(jìn)行自動(dòng)識(shí)別,系統(tǒng)地構(gòu)建了一套關(guān)于高維縱向數(shù)據(jù)的亞組識(shí)別方法。該方法的步驟大致如下:首先對(duì)每個(gè)個(gè)體進(jìn)行建模,通過(guò)MCP來(lái)獲得回歸參數(shù)的初始估計(jì);然后利用二值分割的同質(zhì)劃分法來(lái)識(shí)別回歸系數(shù)的變點(diǎn),獲取被識(shí)別的亞組結(jié)構(gòu);最后,在每個(gè)已識(shí)別的亞組上重新構(gòu)建模型,并再次利用MCP來(lái)剔除不重要的協(xié)變量,最終得到更可靠的回歸系數(shù)的估計(jì)值。
剩余部分安排如下:在第1節(jié)建立亞組模型,并基于MCP法構(gòu)建了一種詳細(xì)的亞組識(shí)別方法;第2節(jié)將通過(guò)統(tǒng)計(jì)模擬試驗(yàn)來(lái)評(píng)估所構(gòu)建的亞組識(shí)別方法的性能;第3節(jié)通過(guò)所構(gòu)建的亞組識(shí)別方法對(duì)國(guó)內(nèi)各地區(qū)生產(chǎn)總值和產(chǎn)業(yè)結(jié)構(gòu)進(jìn)行建模,以驗(yàn)證所構(gòu)建方法的適用性和可行性;第4節(jié)對(duì)全文進(jìn)行了簡(jiǎn)單的總結(jié)。
1 亞組模型和方法
下面將對(duì)亞組模型及其參數(shù)估計(jì)和亞組識(shí)別進(jìn)行討論。
1.1 亞組模型

(1)
其中εi=(εi1,…,εiTi)′,i=1,…,n是均值為零的多元正態(tài)誤差項(xiàng)。假設(shè)對(duì)于不同的個(gè)體的誤差項(xiàng)是不相關(guān)的,但是εi的元素之間是互相相關(guān)的。
此外,假設(shè)亞組模型的結(jié)構(gòu)為:

(2)

然而,當(dāng)個(gè)體數(shù)量和觀測(cè)次數(shù)相對(duì)較少時(shí),但考慮的協(xié)變量的數(shù)量非常大時(shí),對(duì)回歸系數(shù)的估計(jì)提出了嚴(yán)重的挑戰(zhàn)。因此,不使用傳統(tǒng)的模型(如最小二乘法)來(lái)估計(jì)亞組的回歸系數(shù),而是使用MCP方法進(jìn)行估計(jì)。采用MCP的損失函數(shù)作為亞組識(shí)別的損失函數(shù),有以下優(yōu)勢(shì):該方法不僅降低了協(xié)變量的維數(shù),同時(shí)具有oracle性質(zhì);在某種情況下,可使模型能夠正確的識(shí)別亞組的數(shù)目,且所估計(jì)的回歸系數(shù)具有無(wú)偏性。
1.2 亞組識(shí)別和參數(shù)估計(jì)

步驟1(MCP初估) 對(duì)于每一個(gè)個(gè)體,首先通過(guò)最小化模型的帶MCP懲罰項(xiàng)的平方損失函數(shù)來(lái)估計(jì)回歸系數(shù):
(3)
其中正則化參數(shù)λ≥0,γ>1,φλ,γ為MCP懲罰函數(shù):
閾值算子:

定義Yi=(Yi,1,…,Yi,Ti)′,Xit,0=1,Xi, j=(Xi1, j,…,XiTi, j)′,Xi=(Xi,0,…,Xi,p)。
則目標(biāo)函數(shù)(3)可用矩陣格式表示為:
(4)


對(duì)于任意1≤l1≤l2≤n,定義第一部分τ-l1+1觀測(cè)的均值與最后一部分l2-τ觀測(cè)均值之間的比例差函數(shù)為:
定義δ為閾值,該閾值可以由AIC或BIC選擇,則識(shí)別變點(diǎn)的二值分割算法的步驟如下:
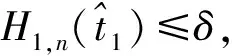


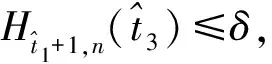

步驟3(分組建模) 使用步驟2中識(shí)別的亞組結(jié)構(gòu),通過(guò)MCP對(duì)每個(gè)亞組構(gòu)建的模型表示為:
(5)
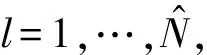

(6)
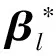
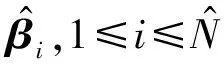
1.3 MPLS-ADMM算法
MCP是一種估計(jì)量稀疏、連續(xù)、無(wú)偏的估計(jì)方法,它通過(guò)構(gòu)造一個(gè)懲罰函數(shù)對(duì)回歸系數(shù)進(jìn)行壓縮,并使得一些回歸系數(shù)為0,來(lái)構(gòu)建一個(gè)簡(jiǎn)單且易于解釋的模型,進(jìn)而達(dá)到變量選擇的目的。其主要思想是在回歸系數(shù)的約束條件下,最小化模型的殘差平方和,從而得到回歸系數(shù)的一個(gè)稀疏估計(jì)。針對(duì)非凸函數(shù)優(yōu)化問(wèn)題,將采用交替方向乘子法[26](the alternating direction method of multipliers,以下簡(jiǎn)稱ADMM算法),作為懲罰函數(shù)來(lái)估計(jì)每次迭代中的更新準(zhǔn)則和停止準(zhǔn)則。ADMM算法結(jié)合了對(duì)偶算法和最小二乘法的優(yōu)點(diǎn),可以在合理的計(jì)算代價(jià)下解決涉及高維數(shù)據(jù)的非光滑和分布式非凸優(yōu)化問(wèn)題,此外,它非常適合處理并行和稀疏優(yōu)化問(wèn)題,特別是統(tǒng)計(jì)學(xué)習(xí)的問(wèn)題。ADMM 算法是一個(gè)分解協(xié)調(diào)求解的過(guò)程,將大的全局問(wèn)題分解成多個(gè)較小、易求解的局部問(wèn)題,并通過(guò)協(xié)調(diào)子問(wèn)題的解來(lái)得到全局問(wèn)題的解。其特點(diǎn)是:多次迭代可收斂到一個(gè)很高的精度,也可以和其他算法組合使用。用ADMM算法求解MCP簡(jiǎn)稱為MPLS-ADMM算法,過(guò)程如下。
針對(duì)目標(biāo)函數(shù)(4),引入一個(gè)輔助變量αi∈Rp,i=1,…,n,目標(biāo)函數(shù)(4)可以寫(xiě)成以下形式:
(7)
其相應(yīng)的增廣拉格朗日函數(shù)是

(8)


(9)
經(jīng)過(guò)一些代數(shù)的計(jì)算,式(9)中βi的估計(jì)值可以由式(10)獲得:
(10)
其中Ip是一個(gè)p×p的單位矩陣,在實(shí)際解決問(wèn)題中,當(dāng)p>n的時(shí)候,直接計(jì)算線性函數(shù)(10)比較困難,因此將其分解成以下形式:
(11)
同樣的,式(9)中的αi的估計(jì)值可以由式(12)獲得:
(12)
其中:
給定調(diào)節(jié)參數(shù)λ和γ,關(guān)于MPLS-ADMM算法的實(shí)現(xiàn)步驟如算法1所示。
算法1MPLS-ADMM算法

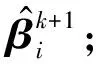


4.檢查停止標(biāo)準(zhǔn);
5.結(jié)束while;


2 模擬研究
本節(jié)通過(guò)設(shè)定多個(gè)模擬模型,運(yùn)用Mento Carlo模擬方法來(lái)驗(yàn)證第1節(jié)中所探究的MPLS-ADMM算法的有效性。在模擬和實(shí)際數(shù)據(jù)分析中,使用BIC[27]準(zhǔn)則來(lái)選擇調(diào)節(jié)參數(shù)δ,ω表示需要估計(jì)的參數(shù)的總個(gè)數(shù),其中BIC定義為
本節(jié)中評(píng)估了不同數(shù)量的個(gè)體和不同數(shù)量的重復(fù)測(cè)量的協(xié)變量選擇、分組、估計(jì)和預(yù)測(cè)的準(zhǔn)確性。考慮以下真實(shí)模型:
(13)
這里i=1,…,n;t=1,…,Ti,個(gè)體水平協(xié)變量
Xit=(Xit,1,…,Xit,p)=(0.1t+Xit,1,…,0.1t+Xit,p)
其中Xit,1,…,Xit,p是相互獨(dú)立同分布的,即服從多元正態(tài)分布,均值為零,協(xié)方差Cov(Xit,d,…,Xit,l)=0.2|d-l|。(εi,1,…,εi,T)′是由標(biāo)準(zhǔn)多元正態(tài)分布產(chǎn)生的。考慮以下模擬的亞組結(jié)構(gòu):
當(dāng)j=0,2,4時(shí),

當(dāng)j=1,3時(shí),

故將所有個(gè)體分為N=4組。本節(jié)考慮以下4種情形,模擬試驗(yàn)參數(shù)如表1所示。

表1 模擬試驗(yàn)參數(shù)
在模擬試驗(yàn)中,假定個(gè)體的數(shù)量為n=40或80。 在不失一般性的情況下,考慮平衡設(shè)計(jì),其中重復(fù)測(cè)量的數(shù)量對(duì)所有個(gè)體都是相等的,Ti=30或60。
為了體現(xiàn)所構(gòu)建的亞組識(shí)別方法的優(yōu)點(diǎn),比較了以下7種方法,如表2所示。

表2 構(gòu)建的亞組識(shí)別方法
在估計(jì)回歸系數(shù)時(shí),方法1是不考慮聚類效應(yīng)的同質(zhì)性擬合方法,是參數(shù)最少的方法,缺點(diǎn)是它完全忽略了亞組。方法2是一種異質(zhì)性擬合方法,它使用個(gè)體的初始估計(jì)對(duì)βi進(jìn)行估計(jì),但不進(jìn)行變點(diǎn)識(shí)別,這是一種參數(shù)最多的方法。方法3考慮了亞組的識(shí)別,但它對(duì)不同的協(xié)變量進(jìn)行了不恰當(dāng)?shù)幕旌希瑥亩a(chǎn)生的亞組可能不合理。
通過(guò)下列參數(shù)來(lái)評(píng)估這7種方法的協(xié)變量選擇、亞組識(shí)別、估計(jì)和預(yù)測(cè)的性能。對(duì)每個(gè)案例和數(shù)據(jù)模擬200次。Lasso和elastic-net用R包glmnet實(shí)現(xiàn),SCAD和MCP用R包ncvreg實(shí)現(xiàn)。這里的評(píng)估準(zhǔn)則有:
TP:對(duì)模型有貢獻(xiàn)的協(xié)變量個(gè)數(shù);
FP:對(duì)模型沒(méi)有貢獻(xiàn)的協(xié)變量個(gè)數(shù);
N:確定的亞組的組數(shù);
NMI[29]:標(biāo)準(zhǔn)互信息,它是測(cè)量估計(jì)所識(shí)別的亞組結(jié)構(gòu)接近真實(shí)結(jié)構(gòu)的程度,范圍在0~1之間,值越大表明2組之間的相似性越高;假設(shè)P={P1,P2,…}和Q={Q1,Q2,…}是關(guān)于個(gè)體{1,2,…,n}的2個(gè)不相交的組,i和j分別為該2組的亞組總數(shù),則:
其中互信息:
熵:

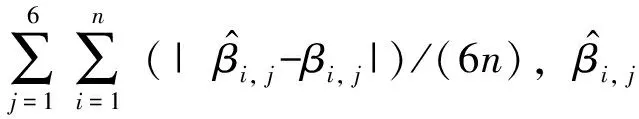
表3為200次數(shù)值模擬不同個(gè)體數(shù)量和不同測(cè)量次數(shù)中的TP和FP的中位數(shù),從表中可知7種方法選擇出的重要協(xié)變量大多為4個(gè),與擬合方法的重要變量的真實(shí)數(shù)量相等;比較了這7種方法,可以發(fā)現(xiàn)方法4產(chǎn)生的FP(無(wú)效變量)值最少。當(dāng)重復(fù)測(cè)量次數(shù)Ti增加時(shí),無(wú)效協(xié)變量的數(shù)量降低。

表3 200次模擬中TP和FP的中位數(shù)
表4為200次數(shù)值模擬運(yùn)行中N和NMI的中位數(shù)。從表4可得,同質(zhì)性擬合方法(1個(gè)單組)和異質(zhì)性擬合方法(n組)都不能識(shí)別個(gè)體的真實(shí)結(jié)構(gòu)。方法3識(shí)別的亞組數(shù)目多于實(shí)際亞組,而方法4和方法5、6、7識(shí)別的亞組數(shù)與實(shí)際亞組數(shù)相當(dāng)接近。同時(shí)NMI接近1,也支持了這個(gè)觀點(diǎn),這表明方法4在識(shí)別亞組方面比方法3具有更好的性能,方法5和方法6也取得了與方法4相似的結(jié)果。隨著重復(fù)測(cè)量次數(shù)Ti的增加,識(shí)別真實(shí)亞組的機(jī)會(huì)也增加。

表4 200次數(shù)值模擬中N和NMI的中位數(shù)
表5為200次模擬中的MSE和BIAS的平均值,方法1相較于其他的亞組識(shí)別方法,估計(jì)和預(yù)測(cè)結(jié)果較差。除方法1外,所有其他方法都能很好地估計(jì)回歸系數(shù),偏差在0.1左右。方法4的偏差值最小,比其他的方法更準(zhǔn)確。隨著重復(fù)測(cè)量次數(shù)Ti的增加,偏差在逐漸變小。

表5 200次數(shù)值模擬中MSE和BIAS的平均值
綜上所述,所提出的方法在變量選擇、亞組識(shí)別、參數(shù)估計(jì)以及各種情況下的預(yù)測(cè)方面效果較好。
3 實(shí)證分析
將亞組識(shí)別的方法應(yīng)用于分析全國(guó)31個(gè)省份的國(guó)內(nèi)生產(chǎn)總值和其產(chǎn)業(yè)結(jié)構(gòu)的關(guān)系。該數(shù)據(jù)集包括31個(gè)省份2005年到2017年的每年國(guó)內(nèi)生產(chǎn)總值(用y表示),共包含了13年的數(shù)據(jù),樣本量共有n=31×13=403個(gè),來(lái)源于國(guó)務(wù)院發(fā)展研究中心信息院。協(xié)變量包括第一產(chǎn)業(yè)(農(nóng)林牧漁業(yè)x1)、第二產(chǎn)業(yè)(工業(yè)x2、建筑業(yè)x3)、第三產(chǎn)業(yè)(交通運(yùn)輸和倉(cāng)儲(chǔ)郵政業(yè)x4、批發(fā)和零售業(yè)x5、住宿和餐飲業(yè)x6、金融業(yè)x7、房地產(chǎn)業(yè)x8)及其兩兩之間的相互作用(單位為億元)。因此,本數(shù)據(jù)總共有36個(gè)協(xié)變量。協(xié)變量分別用x1,…,x36來(lái)表示。
為了避免數(shù)據(jù)出現(xiàn)異方差的現(xiàn)象,采取將數(shù)據(jù)取對(duì)數(shù)的方法,并考慮隨機(jī)因素對(duì)模型的影響,添加隨機(jī)因子ε,則對(duì)每個(gè)省份建模可以得到:
lnyi=βi0+βi1lnxi1+…+βijlnxij+εi
其中i=1,…,31,j=1,…,36。
為了綜合地了解31省份的產(chǎn)業(yè)結(jié)構(gòu)的分布對(duì)國(guó)內(nèi)地區(qū)生產(chǎn)總值的影響,研究了地區(qū)的哪些產(chǎn)業(yè)對(duì)國(guó)內(nèi)生產(chǎn)總值的影響較大,以及每個(gè)產(chǎn)業(yè)對(duì)每個(gè)地區(qū)的國(guó)內(nèi)生產(chǎn)總值的影響是否相等,即地區(qū)之間是否存在亞組。除了采用提出的亞組識(shí)別方法(方法4),也考慮了在模擬試驗(yàn)中提到的識(shí)別地區(qū)之間亞組的各種方法。
MCP迭代的最大次數(shù)設(shè)置為100。通過(guò)十折交叉驗(yàn)證來(lái)選擇懲罰模型的調(diào)優(yōu)參數(shù)。表6給出了確定的亞組數(shù)、亞組模型中選擇的非零協(xié)變量數(shù)以及均方誤差;除此之外,構(gòu)造了一種類似AIC的信息準(zhǔn)則來(lái)驗(yàn)證方法的有效性,將該信息準(zhǔn)則稱作AIC extension for subgroup,以下簡(jiǎn)稱AIC_ES,其值為:
AIC_ES=lnMSE+2w/n
其中w為總的回歸參數(shù)的數(shù)量。
由表6可知,通過(guò)計(jì)算所有方法的AIC_ES,方法4的AIC_ES最小,即本文采用的亞組識(shí)別方法的綜合性能最好。
表7是方法4所確定的6個(gè)亞組的結(jié)果。表8是每個(gè)亞組最終選擇的協(xié)變量和回歸系數(shù)的估計(jì)值。

表6 7種方法的非零協(xié)變量、均方誤差和AIC_ES值

表7 方法4的亞組結(jié)果
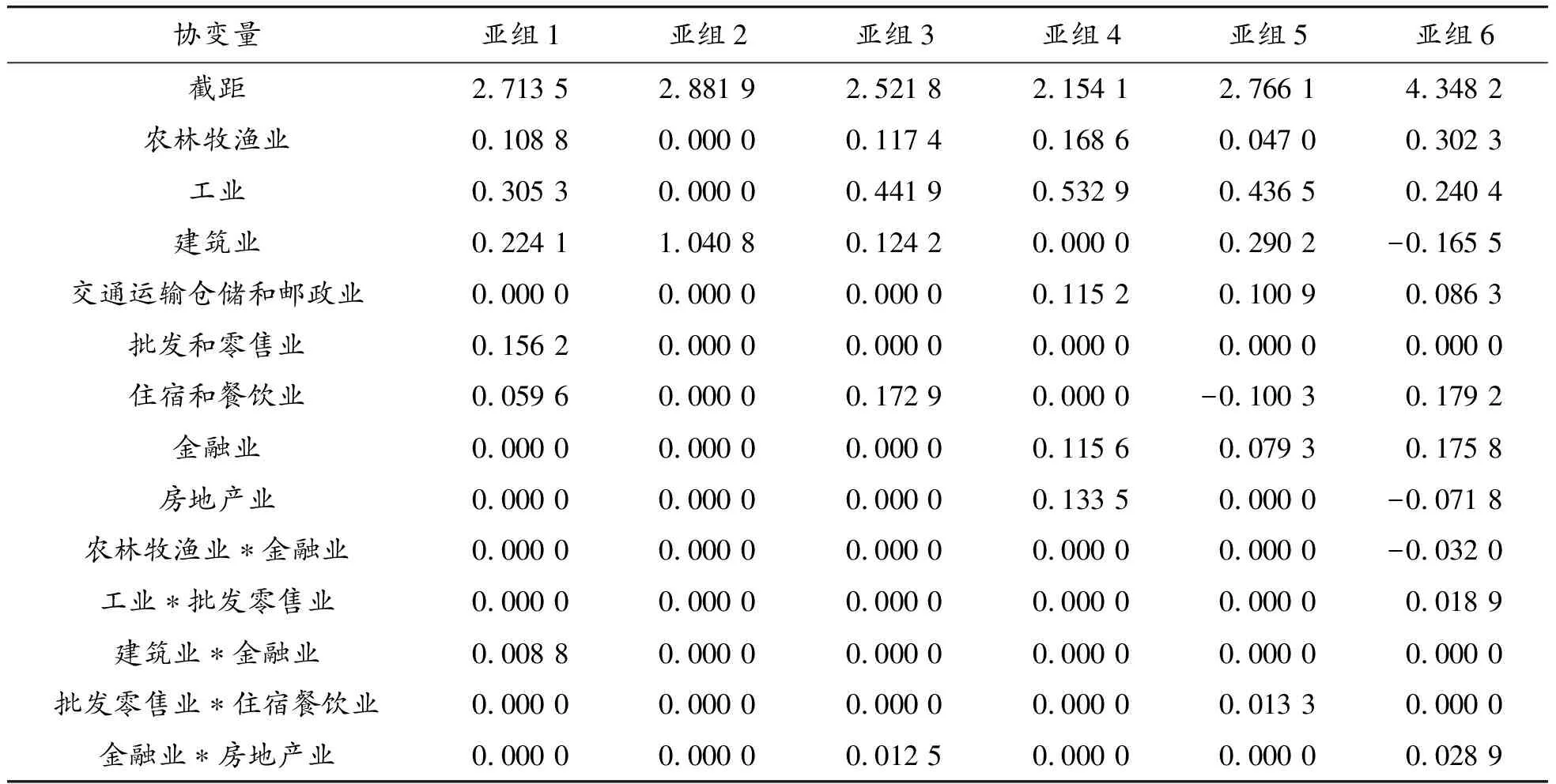
表8 選擇的協(xié)變量和回歸系數(shù)估計(jì)值
從表7和表8可知:① 對(duì)于亞組1,農(nóng)林牧漁業(yè)、工業(yè)、建筑業(yè)、批發(fā)零售業(yè)對(duì)地區(qū)生產(chǎn)總值的影響比較顯著,房地產(chǎn)業(yè)和金融業(yè)的影響最不顯著;比如四川省,由于地形的限制及區(qū)域經(jīng)濟(jì)發(fā)展不均衡,其發(fā)展主要靠農(nóng)業(yè)和工業(yè)支撐,金融業(yè)和房地產(chǎn)業(yè)發(fā)展相對(duì)較弱。② 對(duì)于亞組2,北京和天津的地區(qū)生產(chǎn)總值和建筑業(yè)的關(guān)系比較顯著,其他產(chǎn)業(yè)相對(duì)來(lái)說(shuō)并不顯著;從實(shí)際情況來(lái)看,北京作為我國(guó)首都,在2003年到2017年間發(fā)展迅猛,在經(jīng)歷持續(xù)的舊城改造及新城建設(shè)過(guò)程中,離不開(kāi)建筑業(yè)的大力支持,因此北京的建筑業(yè)對(duì)城市的發(fā)展作出了巨大的貢獻(xiàn),也提供了大量就業(yè)機(jī)會(huì)。③ 對(duì)于亞組3,它的工業(yè)和住宿餐飲業(yè)對(duì)于地區(qū)生產(chǎn)總值的影響比較顯著;比如廣東是一個(gè)工業(yè)大省,第二產(chǎn)業(yè)發(fā)達(dá),各類輕重工業(yè)對(duì)地區(qū)生產(chǎn)總值的影響較大;除此之外,廣東第三產(chǎn)業(yè),即服務(wù)、旅游及餐飲產(chǎn)業(yè)完備,因此廣東的住宿餐飲業(yè)比較發(fā)達(dá)。④ 對(duì)于亞組4,建筑業(yè)、批發(fā)零售業(yè)以及住宿餐飲業(yè)對(duì)地區(qū)生產(chǎn)總值的影響不顯著,其他產(chǎn)業(yè)和地區(qū)生產(chǎn)總值的關(guān)系都比較顯著;如貴州省多山,它的優(yōu)勢(shì)在于土地資源豐富,電力便宜,但是缺乏基礎(chǔ)支柱產(chǎn)業(yè),人才流失嚴(yán)重,地區(qū)相對(duì)貧窮落后,因此貴州的農(nóng)林牧漁業(yè)和工業(yè)對(duì)地區(qū)生產(chǎn)總值的影響較大,但是由于地區(qū)落后,游客較少,住宿餐飲業(yè)相對(duì)不發(fā)達(dá)。⑤ 而亞組5的產(chǎn)業(yè)發(fā)展比較平衡,影響較顯著的產(chǎn)業(yè)當(dāng)屬工業(yè);如山東作為裝備制造業(yè)強(qiáng)省,它最重要的動(dòng)力引擎是從濟(jì)南到青島之間的膠濟(jì)鐵路沿線形成的一條工業(yè)經(jīng)濟(jì)帶,石油、化工、金屬冶煉、機(jī)械等產(chǎn)業(yè)聚集在這里。⑥對(duì)于亞組6,從表中可以觀察到農(nóng)林牧漁業(yè)、工業(yè)、住宿餐飲業(yè)、金融業(yè)對(duì)地區(qū)生產(chǎn)總值的影響是積極的,而交通運(yùn)輸業(yè)、建筑業(yè)和房地產(chǎn)業(yè)的影響不積極;比如河南,身處內(nèi)陸,有大量的農(nóng)業(yè)人口和強(qiáng)大的工業(yè)能力,但是沒(méi)有沿海優(yōu)越的地理位置,從而造成運(yùn)輸成本的增加,因此河南的生產(chǎn)總值主要受農(nóng)業(yè)和工業(yè)的影響,而交通運(yùn)輸業(yè)對(duì)河南的地區(qū)生產(chǎn)總值影響較小。通過(guò)以上分析,可以得出所提出的亞組識(shí)別方法是合理有效的,且有較好的估計(jì)性能。
4 結(jié)論
構(gòu)建了一種新的高維縱向數(shù)據(jù)的亞組識(shí)別方法。為了克服對(duì)高維縱向數(shù)據(jù)實(shí)現(xiàn)聚類效果的困難,考察了7種不同的方法對(duì)不同的個(gè)體使用不同的系數(shù)來(lái)考慮異質(zhì)性,將MCP方法和二值分割的同質(zhì)劃分方法結(jié)合起來(lái)識(shí)別回歸系數(shù)中的變點(diǎn),獲得被識(shí)別的亞組結(jié)構(gòu)。通過(guò)模擬試驗(yàn),可以直觀觀測(cè)到該方法的協(xié)變量選擇和回歸系數(shù)估計(jì)值較準(zhǔn)確,未知參數(shù)的個(gè)數(shù)較少,并且模型的誤差和偏差比其他的模型更小。這些都表明構(gòu)建的方法在識(shí)別亞組和估計(jì)回歸系數(shù)方面是有效的。此外,通過(guò)綜合分析全國(guó)31省的產(chǎn)業(yè)結(jié)構(gòu)數(shù)據(jù)集,實(shí)證了方法的有效性和適用性,但得到的亞組結(jié)構(gòu)是基于數(shù)據(jù)驅(qū)動(dòng)的結(jié)果,其經(jīng)濟(jì)學(xué)內(nèi)涵還有待進(jìn)一步研究。希望該方法今后可以有效地運(yùn)用于其他縱向或面板經(jīng)濟(jì)數(shù)據(jù)的分析中。
構(gòu)建的方法的性能在一定程度上受δ的選擇所影響。δ的選擇相當(dāng)于變點(diǎn)數(shù)的選擇,采用BIC準(zhǔn)則選擇最優(yōu)δ。通過(guò)模擬研究表明它是一個(gè)可行可信的選擇方法。考慮的是常數(shù)系數(shù)模型。當(dāng)回歸系數(shù)是時(shí)變的,可采用B樣條估計(jì)系數(shù)函數(shù),并使用一些特定的函數(shù)來(lái)度量系數(shù)函數(shù)之間的偏差,證明所提方法可以適用于時(shí)變系數(shù)模型的亞組識(shí)別。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
兒童故事畫(huà)報(bào)(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
