融合信任圈和移動模式的位置預測框架
2022-10-12 04:16:12魏盛杰
重慶理工大學學報(自然科學) 2022年8期
魏盛杰,王 鑫,戴 勁,韓 楠
(1.四川音樂學院 實驗藝術學院, 成都 610021;2.成都信息工程大學 軟件工程學院, 成都 610225;3.四川音樂學院 美術學院, 成都 610021;4.成都信息工程大學 管理學院, 成都 610103)
0 引言
基于位置信息的社交網絡(location based social network,LBSN)在瞬息萬變的時代中應運而生,得益于智能移動設備的廣泛普及與移動定位技術的飛速發展,個體用戶的位置信息數據比以往任何時候都更容易獲取。眾多基于位置的社交網絡(簡稱位置社交網絡)平臺,如:Foursquare、Facebook Places以及微信、美團、大眾點評等,它們將用戶的線上活動與線下生活建立聯系,有效地將現實生活與虛擬世界結合在一起,打破了存在于物理世界與網絡世界之間的信息鴻溝。
由于簽到數據集包含了豐富的信息,現階段有越來越多的研究者利用簽到數據來預測用戶的下一個簽到點。傳統的研究主要是利用用戶的個體移動模式來預測下一簽到位置,僅僅考慮歷史簽到記錄的預測模型性能是有局限性的,它的弊端在于沒有綜合考慮用戶的移動模式以及用戶的社會信任關系這兩類影響因子,缺乏考慮位置屬性與用戶特征之間的關聯性。
在部分情況下,用戶的社交關系在一定程度上會對用戶的時空行為構成影響[1],例如,當用戶與信任度高的朋友在餐廳共進晚餐的時候,下一步計劃更大概率會采取該朋友提出的建議,并且長期處于同一社交圈內,不同用戶之間的興趣愛好會逐漸統一化。生物的移動模式通常會受到個體屬性以及群體屬性的影響,即用戶的移動行為并不是固定不變,而是會隨著環境變化而變化[2]。本文研究目標旨在開發一個有效的位置預測框架,綜合考慮用戶的信任圈以及移動模式來精準預測用戶的下一個簽到位置。
本文針對預測用戶下一個簽到位置問題提出了一種融合信任圈和移動模式的位置預測框架FTM(a location prediction framework based on trust circle and mobility pattern)。具體來說,該框架分為2個模塊:① 信任圈模塊;② 移動模式模塊。本文首先介紹了基于位置社交網絡的綜合研究。其次,本文利用信任關系對個體的影響挖掘出一種新型社會關系,接著根據用戶簽到模式表現出的周期性提出了直接訪問模式及多元訪問模式。最后,本文在真實數據集上評估了模型的性能。實驗結果證明,本文提出的模型可以很好地預測用戶下一個簽到位置。
綜上所述,本文的主要貢獻包括:
1) 基于位置社交網絡利用用戶的新型社交關系和移動模式預測下一個簽到位置。
2) 提出了信任圈的新概念,將信任圈按照不同群體劃分為三類社交關系,對用戶時空行為的影響進行建模。
3) 將移動模式拆分為直接訪問模式及多元訪問模式,對不同訪問模式造成的影響進行建模。
4) 在大規模真實數據集上評估了FTM預測框架,實驗在準確率以及魯棒性上都優于其他代表性方法。
1 相關工作
作為異構網絡中的典型代表,位置社交網絡中蘊藏著十分復雜的結構,位置社交網絡信息層次如圖1所示,主要可以分為4層。
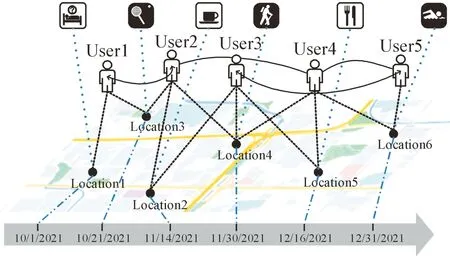
圖1 位置社交網絡信息層次圖
圖1由下至上依次為時間信息層、地理信息層、社交信息層以及文本信息層,每一層包含了多個節點(例如時間節點、位置節點和用戶節點等),位置網絡將多種不同類型的節點相互連接起來,構成了多元的關聯關系(例如User1和User2之間的社交關聯以及User1和Location1之間的簽到關聯),從而可以更精準地分析用戶的行為和特征。從圖1中可以發現:User1與User2分享位于Location1的簽到信息,不僅交換了地理層面的簽到信息,還額外產生了時間層面信息、文本層面信息以及社交層面信息,多個層面的上下文信息會在潛移默化中影響到User2下一步位置的選擇。位置社交網絡將不同層面的信息關聯起來,可以精準快速地挖掘用戶的潛在興趣、用戶的行動規律以及不同用戶之間的社交關系等內在信息。因此,利用大量的簽到數據為基于位置服務的研究提供了新的技術思路,如預測用戶的下一個簽到位置、POI推薦、城市計算等[3-4]。
當前,位置預測已經成為基于位置社交網絡的主要研究任務之一。位置預測指的是利用用戶在位置社交網絡中的歷史簽到記錄,捕捉用戶移動的規律性,進而對用戶下一個可能訪問的興趣點進行預測。考慮到位置社交網絡中上下文信息的多樣性以及人類移動模式的特異性,具有不同特性的人群通常其規律性并不能完全吻合。因此,在滿足用戶個性化需求的情況下來挖掘用戶移動方式的規律性已經成為改善用戶生活質量以及提高位置服務市場效率的重要環節。
目前針對位置社交網絡中位置預測的研究主要集中在以下3個方面:
1) 基于序列模式的位置預測。按照時間順序將用戶所有的歷史簽到點記錄作為一個序列,通過計算某一地點在該序列中出現的頻率并且挖掘它與相鄰地點之間潛在關系來進行位置預測。
2) 基于時間動態性的位置預測。通常情況下,用戶在簽到時會附帶時間戳信息。通過挖掘用戶簽到行為時呈現出的周期模式,分析地理位置變遷與時間推移的高相關性來進行位置預測。
3) 基于社交關聯性的位置預測。采用用戶好友的簽到歷史記錄推斷用戶的簽到行為偏好,將時空關系和社交關系緊密結合在一起來進行位置預測。
在基于序列模式的位置預測研究方面,Yin等[5]提出了簽到最高頻次模型,該模型主要應用于僅收集到簽到歷史記錄但沒有上下文信息的情況,通過計算下一個的簽到位置在歷史記錄中出現的頻率來計算該位置在下一次出現的概率。在此基礎上,Gambs等[6]提出了K階馬爾可夫模型,該模型將下次簽到之前的K個簽到序列作為簽到上下文,然后計算簽到歷史記錄中上下文序列出現的頻率作為下一個簽到位置的概率。為了避免在歷史記錄中找不到簽到上下文序列的情況,動態改變K的大小,當K=0時,該模型退化成簽到最高頻次模型。
在基于時間動態性的位置預測研究方面,Gao等[7]提出利用用戶簽到數據中體現的時間周期性進行建模,對用戶將來簽到的位置進行預測。Valverde-rebaza等[8]對時間周期性進行了拓展,基于用戶活動的循環模式提出了一種應用于簽到位置預測的通用型時間框架,該框架主要采用混合高斯模型來描述用戶在簽到位置的時間周期性特點。
在基于社交關聯性的位置預測研究方面,Li等[9]提出了基于序列的社交可移動模型,該模型通過分析好友簽到行為模式來推斷用戶的簽到行為偏好,并且結合時空信息,計算好友簽到序列對用戶當前簽到可能性的大小,從而預測用戶下一個訪問的位置。
基于位置社交網絡的位置預測已經取得一些研究成果,但是預測的準確率無法滿足用戶的需求,如何更加全面地考慮和混合多源異構信息是需要進一步研究的問題[10-11]。本文所提框架的創新性在于不僅考慮了信任圈的影響,并且在此基礎上加入不同移動模式對位置預測的影響,與已有工作相比,本文提出的框架考慮更為全面,預測結果更加精準。
2 問題表述與模型
2.1 信任圈的特征
通過分析流行位置社交網絡,如Gowalla數據,用戶的簽到行為可以分為以下2種情況:第一種是用戶只身一人的簽到行為,另一種是用戶與某一社會關系同時出現的簽到行為。與用戶在同一位置簽到的人群可以分為信任朋友、地理鄰居以及陌生人這三類群體。基于此,本文提出了信任圈的概念,并按照不同群體劃分出三類社交關系,為了更好地解釋信任圈對用戶產生的影響,下面分別對以下三類社交關系的特征進行詳細描述。


定義3:共現關系(co-occurrence relation)。將位置社交網絡中在同一位置簽到的用戶定義為共現關系,并用符號Rc表示與用戶有共同簽到記錄的社交關系的集合。
圖2為三類社交關系在累計簽到數增加情況下的共現率分布變化圖。其中,x軸表示已統計到的用戶簽到數,y軸表示共現的概率。

圖2 信任圈的共現分布曲線
從圖中可以發現,在已統計到的簽到集中,1 500次累計簽到數內每類社交關系的共現概率都在30%以內;隨著累計簽到數量的增加,共現率也會增加,并且最終趨于穩定。主要有以下3個原因導致這種趨勢:① 用戶將POI分享給其社交關系導致共現行為;② 用戶在使用簽到程序的初期缺少歷史記錄導致起始階段的共現率較低;③ 隨著時間的推移,簽到數據逐漸完整,社交關系也逐漸穩定,共現率最終呈現平穩的狀態。
2.2 移動模式的特征
為了模擬信任圈的影響,本文同樣分析了Gowalla數據集上用戶的簽到模式。文獻[12]研究表明,人類的簽到模式主要以日模式和周模式表現出周期性的循環,即一天和一周代表人類活動的主要循環周期。因此,本文的分析沿用了這種時間周期模式,利用日模式和周模式在結構上的相似性挖掘具有代表性的用戶移動模式。本文將一天按照小時進行“切片”,將用戶所有的簽到記錄按照時間順序投影到24個片段內,并且對每一個小時內的簽到頻率進行統計,從而得到了日模式下的用戶簽到頻率圖[13],如圖3所示。
從圖3可以發現,用戶的簽到主要集中在早上8點至晚上8點之間,并且1 d中的簽到高峰期出現在晚上7點左右。本文將每天的簽到記錄按照日期順序投影到1周內,得到了圖4所示的周模式用戶簽到頻率圖。
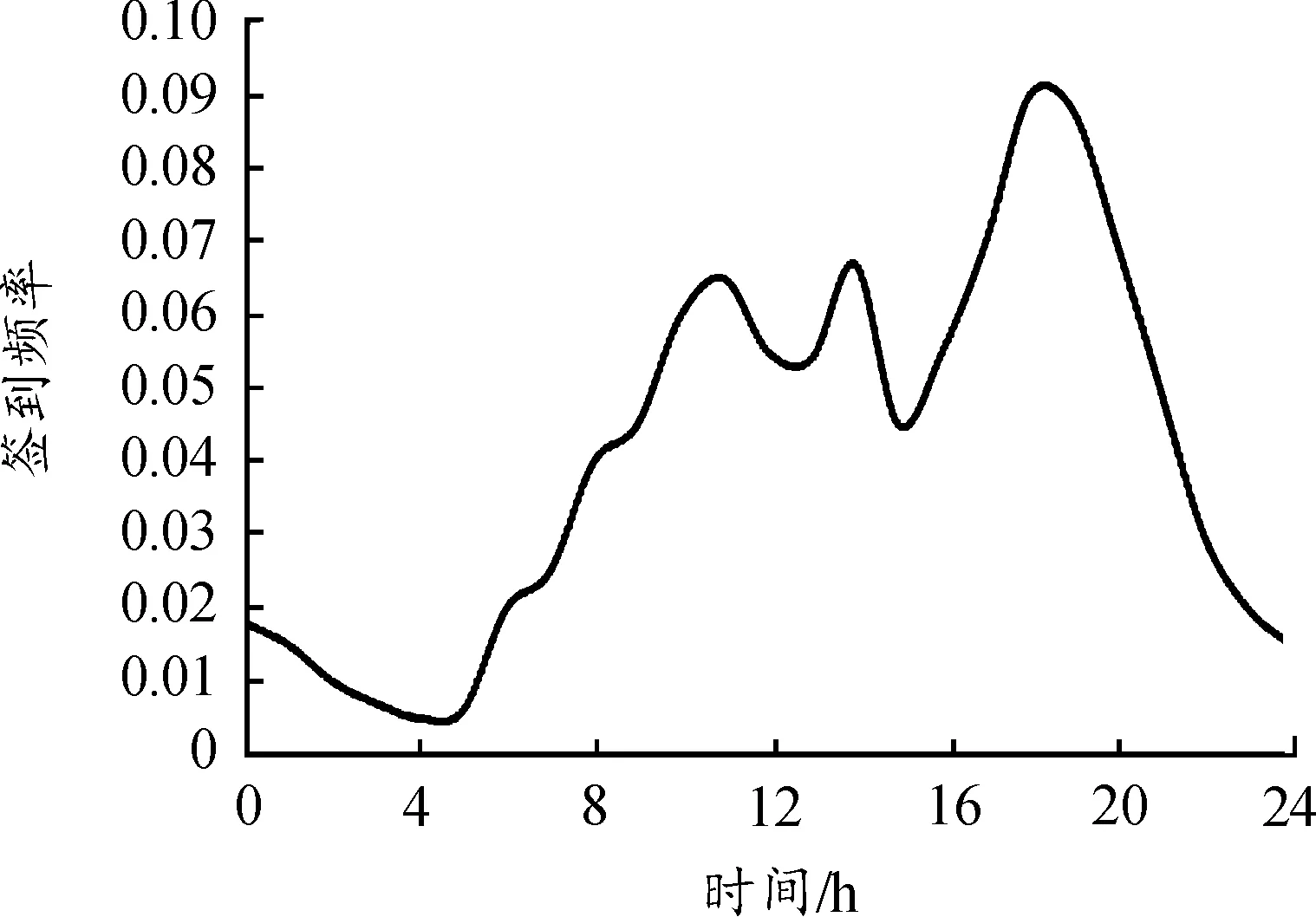
圖3 日模式用戶簽到頻率曲線

圖4 周模式用戶簽到頻率曲線
從圖4可以發現,在周模式下,用戶在工作日的簽到模式相對一致,而周末的簽到頻率相較于工作日有所下降,主要是由于用戶在周末更可能選擇居家休息[14],說明用戶在周末的簽到存在不規律性,本文通過計算周模式的平均簽到頻率來解決周末位置預測相對困難的問題。由于用戶軌跡呈現出周期性的重復,所以本文利用Apriori算法[15]來提取用戶的移動模式。
定義4:個人移動模式(individual mobility pattern)。用戶U的移動模式是根據其簽到路線按照時間順序頻繁訪問的位置序列,其頻率不小于最小支持度Smin。第一步采用基于位置序列的方法挖掘用戶的軌跡序列,第二步從挖掘到的所有頻繁序列中找出最大頻繁子序列以確保具有大片相同片段的子序列是屬于不同時段的。
定義5:群體移動模式(crowedmobilitypattern)。表示所有個人移動模式的集合。由于人們經常遵循相似的運動模式,所以利用可用用戶的軌跡來代表一群人的全局行為是可行的。利用每個用戶的歷史移動軌跡挖掘其移動模式,然后將它們合并以用于下一步的預測。
2.3 問題定義

用戶的下一簽到位置主要受到2個方面的影響:信任圈以及移動模式的影響。因此,將預測用戶下一個簽到位置問題形式化:當已知集合Ct和Ch時,目標是計算出用戶在t時間訪問下一個簽到位置l的概率。基于以上形式化定義,本文將位置預測概率定義為:
P(l)=P(l|Ct,Ch)
(1)
信任圈以及移動模式的影響力可以作為2個獨立的模塊,采取類似于文獻[16]提出的組合方法來計算位置預測概率:
(2)
其中,λ表示一個控制信任圈關系以及個人歷史移動模式的影響權重的常數參數。
2.3.1信任圈的影響力
在本小節中,通過計算信任圈系數來測量三類社交關系對用戶的影響力。利用加權的方法,信任圈的模型可以進一步展開為:
(3)

通過分析圖2,發現3個社交關系的函數曲線類似于S形函數,即:隨著累計簽到數量的增加,用戶之間的共現率隨之增加,并且最終趨于穩定。因此,本文將相關系數θ1、θ2、θ3作為激活函數:
(4)
其中,f1表示k階信任關系中的用戶簽到特征向量,W1表示特征向量f1的權重矩陣,b1表示偏置項。相關系數θ2和θ3的定義如下:
(5)
(6)
其中,f2表示n度鄰近關系中的用戶簽到特征向量,W2表示特征向量f2的權重矩陣,b2表示偏置項。f3表示共現關系中的用戶簽到特征向量,W3表示特征向量f3的權重矩陣,b3表示偏置項。
(7)

考慮到信任圈的多元性,本文融合信任圈關系和簽到位置關系來計算相關系數,如式(8)所示。

(8)
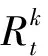
2.3.2用戶移動模式的影響力
用戶移動的模式可以分為兩類:一種是用戶u直接從目標位置lj到侯選位置lk的情況,稱為直接訪問模式,用符號M表示;另一種是用戶u從目標位置lj到侯選位置lk之前還訪問過其他位置的情況,稱為多元訪問模式,用符號M*表示。不同的移動模式在模型中占有不同的權重,因此,利用加權的方法,用戶移動模式模型進一步展開為式(9)。
P(l|Ct)=ηP(l|M)+(1-η)P(l|M*)
(9)
其中,η表示一個控制不同移動模式權重的常數。
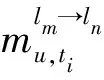
(10)
為了方便計算從位置lx到位置ly之間的移動概率,將觀察到的所有用戶uj在時間ti從當前位置lx到目標位置ly的移動轉換列舉出來,并利用式(11)計算群體移動模式。
(11)
因此,直接訪問模式下的概率模型可以擴展表示為:

(12)
2) 多元訪問模式:由于簽到集中可能存在數據缺失的情況,本文提出了多元移動模式,即用戶u從當前位置lx到目標位置ly的移動過程中額外至少經歷過(n+1)個位置。
給定當前位置ly時,計算在t時刻它作為目標位置的概率,即數據集中所有其他位置在時間t到達位置ly的移動行為的概率,計算公式如下:
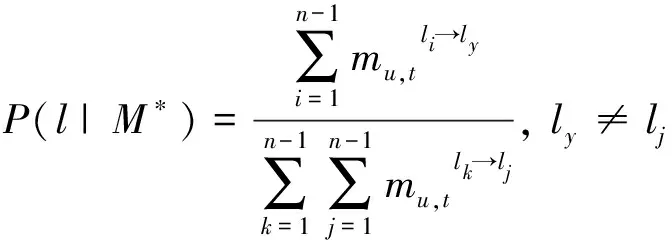
(13)
2.4 融合框架
本文提出了融合信任圈和移動模式的框架FTM用于預測用戶的下一個簽到位置。根據式(2)和(9),框架FTM最終定義為式(14)。

θ3*P(l|Rc))+(1-λ)(η*P(l|M)+
(1-η)*P(l|M*))
(14)
3 實驗結果與分析
本節將介紹實驗環境、數據集、評價指標、基準方法、參數選取與實驗分析。為了驗證提出的FTM框架的性能,本節工作包括:分析了FTM框架中不同因素的影響權重,通過評估其在不同設置的實驗條件下的準確率來確定實驗參數;與其他具有代表性的先進算法對比預測結果的準確率并分析造成差異的原因;通過改變空間閾值來分析FTM框架的魯棒性。
3.1 實驗環境
實驗硬件環境如表1所示。

表1 實驗環境
3.2 數據集介紹
為了評估FTM框架的性能,在公開數據集上進行實驗。由于模型中使用了信任圈模塊,本文使用遞歸神經網絡來計算用戶的家庭位置。為了保證實驗的有效性,實驗中篩選至少包含80條簽到記錄的用戶,并且刪除了不滿20條簽到數據的位置數據。為了避免實驗結果的偶然性,本文根據用戶的簽到時間將數據集劃分為訓練集和測試集,按照時間順序,每個用戶的70%的簽到記錄用于訓練,剩下30%用于測試,實驗數據集參數如表2所示。

表2 實驗數據集參數
數據集描述如下:
1) Gowalla數據集:該數據集包含3 112名用戶在3 298個地點27 149條附帶時間戳的簽到記錄,其中包括3 776條用戶社會關系記錄。
2) Foursquare數據集:該數據集包含來自923 506名用戶在4 960 482個地點35 289 629次附帶時間戳的簽到記錄,其中包括4 751 635條用戶社會關系記錄。
3.3 評價指標
本文使用預測準確率指標Accuracy來評價模型的性能。計算每個候選位置的概率后,返回排名top-N作為預測的結果。只要用戶的實際簽到位置出現在top-N中就認為預測是準確的[18]。采用Accuracy@N表示不同N取值的預測準確率,在實驗中N的取值為1、5、10。
3.4 基準方法
為了說明FTM框架位置預測的性能,本文引入以下方法進行比較。
1) MFC(mostfrequentcheck-inmodel)模型[19]是預測用戶下一簽到位置的經典指標,該模型將用戶u在位置l簽到的概率定義為位置l出現在用戶u的簽到歷史記錄中的概率。
2) FSM(feature-based supervised model)模型[20]提出了最直接競爭對手的概念,利用一組描述用戶運動模式的時空特征矩陣來預測下一簽到位置,在此基礎上將這些特征組合到監督學習模型中。
3) FPM (feature-based personalized model)模型[3]基于矩陣分解的方法嵌入個性化馬爾可夫鏈。該模型不僅改進了簽到序列中的個性化馬爾可夫鏈,還考慮了在局部區域內用戶移動行為中存在的約束因素。
4) PSMM(periodic social mobility model)模型[21]通過觀察用戶在一天中的某些時間段表現出的強烈周期性行為,計算目標用戶在目標時間內最有可能停留的區域,達到預測用戶下一個簽到位置的效果。
5) PRED(periodic region detection)模型[22]是貝葉斯非參數模型,通過混合地理信息和時間信息建模來發現用戶的周期性流動模式。由于其為非參數的模型,所以不需要關于個體流動性的先驗知識。
3.5 參數選擇
在選擇參數λ和η時,它們的取值在0~1變化,進行了200次實驗,步長增量設置為0.05。
從圖5和圖6中可以發現,當λ=0.25,η=0.75時FTM可以達到最佳性能。參數λ用于控制信任圈模塊的權重,將η固定為0.75,以0.05為步長將參數λ從0增加到1,從圖5中可以發現,當λ=0.25時達到最高準確率。當λ=0.05時,這種情況幾乎只考慮用戶的歷史移動模式,沒有考慮信任圈的影響,實驗結果表明它的準確性不是最佳,進而表明不能僅考慮用戶的歷史移動模式,需要進一步考慮額外的影響因素,個體用戶的時空行為并不是一塵不變的,具體來說需要重視社交關系對用戶判斷產生的影響,當提高信任圈模塊的權重時,模型的準確率會提升;當λ=0.25時,預測準確率最高,模型的預測性能達到最佳,說明它是信任圈和移動模式模塊的最佳權重。

圖5 不同λ值下的預測準確性

圖6 不同η值下的預測準確性
此外,從圖6中可以看出,用戶移動模式模塊具有更高的權重,說明模型在預測中用戶歷史移動模式比信任關系的影響更大;當λ=0.95時,表明過度強調了信任圈的影響,導致預測的準確率最差,說明僅僅考慮信任關系是不足以來預測用戶行為的。參數η用于控制用戶歷史移動模式模塊的影響,將λ固定為0.25,以0.05為步長將參數η從0增加到1。
從圖6中可以發現,當η=0.75時達到最高準確率,這表明直接訪問模式對于挖掘用戶的隱性移動模式有重要的影響。當η=0.15時預測的準確率較低但不為0,證實了考慮多元訪問模式的必要性,即通常情況下用戶的移動模式都屬于直接訪問,但因部分數據集缺失或其他因素導致未能充分挖掘該用戶的移動行為,本文考慮潛在的多元訪問模式有效彌補了這一缺陷。
對于用戶的k階信任關系,本文將k設置成一個可變的參數,分別把k的取值設置為從1~20變化。圖7展示了在k的不同取值下預測準確率的變化,可以觀察到隨著k值的增加,FTM的性能在不同的top-N下減少。因此可以得出結論,信任關系的等級對用戶的選擇有顯而易見的影響,信任等級越高造成的影響越大。
根據文獻[23]可知,個體用戶能與周圍用戶保持穩定的社會關系的理論上限值,即任何人的社交關系都存在上限值。對于用戶的n度鄰近關系,本文將n的取值設置為1~5,因為只有部分社會關系與用戶真正保持緊密聯系,其他社會關系對用戶的影響幾乎可以忽略不計[24]。如圖8所示,FTM的性能隨著參數n取值的增加而減少,這是因為過多的社會關系削弱了親密朋友的影響力,從而降低了預測的準確率。

圖7 不同k值下的預測準確性

圖8 不同n值下的預測準確性
3.6 位置預測準確性對比
表3展示了在不同數據集上的不同算法的預測準確率,可以看出FTM在所有模型中均表現最佳,平均準確率可以達到92.6%以上。

表3 實驗結果
MFC模型雖然提供了較準確的預測,然而,考慮了用戶的信任關系的FTM模型表現出更好的預測結果,尤其是在規模較大的Foursquare數據集上。FSM模型利用了描述用戶運動模式的時空特征矩陣,但準確率相對較低,尤其是在數據集規模較小的Gowalla上。FSM模型比MFC模型的準確率高出約4.2%,但其準確率遠低于FTM模型,原因在于僅考慮用戶的局部特征。PSMM模型的準確率比FTM模型略差,因為其沒有考慮信任圈對用戶的影響,與FPM模型相比,它提高了大約20.6%的準確率。PRED模型綜合考慮了地理信息和時間信息,也表現出較高的預測性能,但缺乏對用戶個體的考慮,所以準確性較低于FTM模型。Gowalla和Foursquare這2個數據集的主要區別在于數據集的規模大小相差較大,所以在規模較小的數據集上,注重考慮局部信息的FPM模型準確率較高,在規模較大的數據集上,考慮多元信息的PRED模型準確率較高,而綜合考慮社交元素和個體因素的FTM模型在不同規模的數據集上性能表現都是最佳的。
從圖9可以更直觀地發現:FTM模型的性能優于其他基準方法,這是因為FTM不僅考慮個體特有的移動模式,還考慮了多元社交信息的影響。具體來說,從圖9(a)發現:由于Gowalla數據集規模較小,更多描述了用戶個人特有的行為,而不能代表人群的通用習慣,對某些用戶的信任圈的了解有限,導致FTM模型中的信任關系模塊不能充分發揮作用,所以模型在Gowalla上表現的性能較低于在Foursquare上的性能。相反,從圖9(b)發現:由于Foursquare數據集融合了更多描述人群規律的特征,適用于預測更廣泛的用戶群體行為規律[25],挖掘到的移動模式序列更具體,因此預測準確率更高。
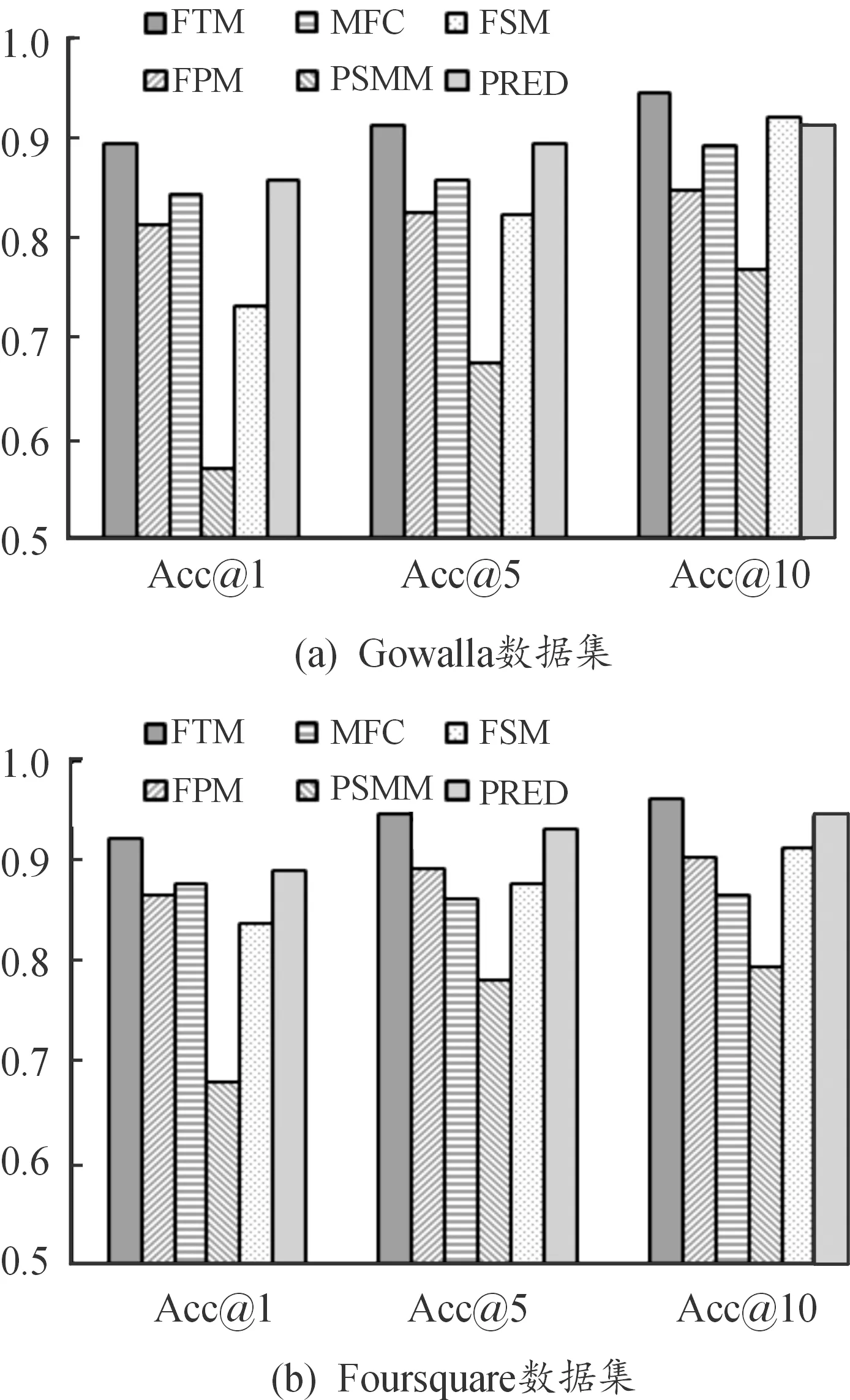
圖9 位置預測率柱狀圖
本文進行了另一組實驗來觀察空間閾值變化對FTM性能的影響[26],將性能表現最好的Accuracy@10作為評價標準。
實驗結果如圖10所示,結果表明大部分模型的準確率隨著空間閾值的增加而增加,FTM預測準確率明顯優于其他算法的同時,表現出了更高的魯棒性。

圖10 不同空間閾值下算法的預測準確率曲線
從圖10(a)可以發現,FTM模型和PRED模型的準確率增加的幅度更大,因為這2種算法都考慮多種影響因素,空間閾值的增大可以挖掘出更豐富的用戶行為信息。相反,FPM和PSMM模型的準確率隨著空間閾值增加而減少,這是因為僅考慮個體的單一影響因素存在局限性,這類算法更適用于預測特定個體的位置。從圖10(b)可以發現,在Foursquare這種規模較大的數據集中,空間閾值的增大對預測準確率的影響更大,因為它允許在更多情境中預測下一個位置。FPM模型受閾值變化的影響尤其明顯,與其他模型不同,該模型的準確率隨著閾值的變化而減少,這是因為僅考慮局部因素導致的結果。同樣,僅使用個體特征的PSMM模型表現不佳,因為該方法無法利用信任關系來彌補空間閾值變化導致的差距。結合圖10可以發現,FTM模型、MFC模型以及FSM模型的準確率都隨著空間閾值的增加而增加,而FTM模型的準確率是最高的,這是因為MFC模型考慮的影響因素較少,僅僅分析簽到序列是不足以準確預測下一個簽到位置的。FSM模型融入了直接競爭對手的概念,但是對其他社交關系的考慮頗為欠缺,導致預測的準確率較低于FTM模型。綜合之前的實驗,FTM在規模大的數據集Foursquare上預測準確率更高,因為用戶的信息更豐富從而挖掘得到的線索越精確。
4 結論
本文提出了一種新的融合信任圈和移動模式的位置預測框架。在信任圈模塊中,考慮了不同信任關系對用戶選擇的影響。在歷史移動模式模塊中,分別考慮了用戶的直接訪問模式和多元訪問模式。在真實數據集上評估了不同模型的性能,實驗結果表明,本文提出的FTM模型在準確率指標方面優于其他算法,并且較其他先進算法表現出更好的魯棒性。未來工作包括:進一步拆分信任圈,從中挖掘其他社交關系對個體的影響并加入到預測模型中,并且在改進移動模式模塊中挖掘用戶多元移動模式的算法,進一步提高預測的準確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
