基于多核CPU的多源異構(gòu)數(shù)據(jù)庫信息快速同步研究
2022-10-13 05:13:26楊波鄧欣王鑫章蕭陽彭程劉緒清
中國信息化 2022年9期
文|楊波 鄧欣 王鑫章 蕭陽 彭程 劉緒清
多源異構(gòu)數(shù)據(jù)庫之間的信息同步對實現(xiàn)網(wǎng)絡(luò)數(shù)據(jù)實時共享具有重要的意義,但是由于多源異構(gòu)數(shù)據(jù)庫信息量龐大,導(dǎo)致數(shù)據(jù)同步處理流程較長,數(shù)據(jù)整合度不高,多源異構(gòu)數(shù)據(jù)庫信息同步速度較慢,針對該問題我們研究了基于多核CPU的多源異構(gòu)數(shù)據(jù)庫信息快速同步方法。以多核CPU并行執(zhí)行任務(wù)的模式為基礎(chǔ),控制處理數(shù)據(jù)的流程和時間。整合多源異構(gòu)數(shù)據(jù),設(shè)計快速同步觸發(fā)模塊,優(yōu)化信息同步速度,以此實現(xiàn)多源異構(gòu)數(shù)據(jù)庫信息快速同步。測試結(jié)果表明,此次研究的數(shù)據(jù)庫信息同步方法所用的平均時間與傳統(tǒng)同步方法相比縮短了7.33s,達到了本次研究的預(yù)期。
互聯(lián)網(wǎng)技術(shù)的飛速發(fā)展及云平臺的普及為社會大眾的日常工作和生活帶來了一定的便利,與此同時大量的網(wǎng)絡(luò)用戶行為產(chǎn)生海量的信息,并且信息的形態(tài)和來源也日漸豐富,導(dǎo)致單一的數(shù)據(jù)模式已經(jīng)不足以全面精確地概括用戶特征。多源異構(gòu)數(shù)據(jù)庫的應(yīng)用,能夠使不同的信息應(yīng)用系統(tǒng)之間建立密切聯(lián)系,一定程度上緩解了因信息孤島問題對互聯(lián)網(wǎng)數(shù)據(jù)處理系統(tǒng)造成的壓力。但由于多源異構(gòu)數(shù)據(jù)本身性質(zhì)差異較大且載體類型較為多樣,數(shù)據(jù)處理過程中融合難度較高,因此在進行數(shù)據(jù)庫信息同步時速度較慢,整體效果不理想,很難在較短時間內(nèi)實現(xiàn)不同系統(tǒng)和設(shè)備間的數(shù)據(jù)移動及共享。為了提高多源異構(gòu)數(shù)據(jù)庫信息同步的速度,業(yè)界學(xué)者及相關(guān)人員研究了不同類型的信息同步方法,但是其應(yīng)用效果均不理想。此次研究在現(xiàn)存的多源異構(gòu)數(shù)據(jù)庫信息同步方法的基礎(chǔ)上,針對傳統(tǒng)方法存在的問題引入多核CPU的處理方法,以期進一步提升多源異構(gòu)數(shù)據(jù)庫信息同步速度。
一、基于多核CPU并行處理數(shù)據(jù)
多核CPU,即多核處理器,通過在同一塊芯片中植入多個處理器實現(xiàn)數(shù)據(jù)處理系統(tǒng)的高度并行,以此提高處理數(shù)據(jù)的能力和速度。多核CPU的大致架構(gòu)如圖1所示。
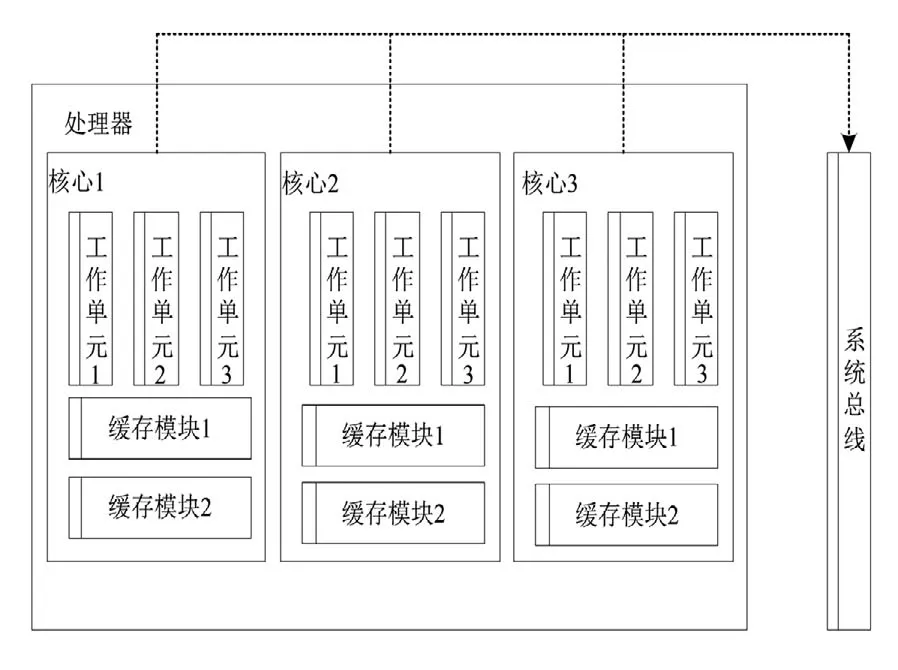
圖1 多核CPU并行運行架構(gòu)圖
從圖1中可以看出,在多核CPU的運行過程中,多個數(shù)據(jù)處理核心之間具有并列執(zhí)行的關(guān)系,CPU先將接收到的任務(wù)指令進行解析并向每個獨立的核心分配任務(wù),核心中的工作單元負責(zé)具體執(zhí)行,并反饋執(zhí)行結(jié)果。在此基礎(chǔ)上可以計算使用多核CPU并行處理數(shù)據(jù)與傳統(tǒng)的串行處理模式之間的加速比:

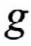
二、 整合多源異構(gòu)數(shù)據(jù)
多源異構(gòu)數(shù)據(jù)庫擁有豐富的數(shù)據(jù)源,其數(shù)據(jù)結(jié)構(gòu)也包含數(shù)字、圖像、影像等多種形式。在對多源異構(gòu)數(shù)據(jù)庫信息進行同步時,龐大且雜亂的信息內(nèi)容極有可能成為降低信息同步速度的主要原因,因此在進行信息同步操作之前,利用去噪算法對數(shù)據(jù)庫中的操作對象進行整合,通過刪減噪聲數(shù)據(jù)精簡需要同步的多源異構(gòu)數(shù)據(jù),從而加快信息同步的速度。利用聚類算法對數(shù)據(jù)對象進行分類和篩選,具體方法如下式:
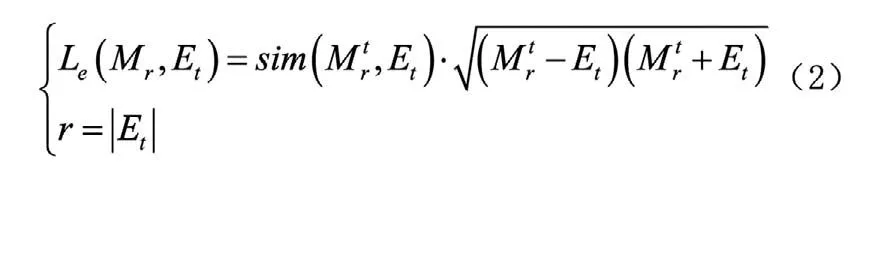
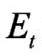

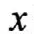
三、設(shè)計快速同步觸發(fā)模塊
設(shè)計快速同步觸發(fā)模塊的核心是在數(shù)據(jù)庫中設(shè)置觸發(fā)器,當(dāng)觸發(fā)器接收到指令時會即刻根據(jù)指令內(nèi)容執(zhí)行操作,并將每一次執(zhí)行的操作指令的數(shù)據(jù)對象寫入觸發(fā)器中的日志表,當(dāng)多源異構(gòu)信息發(fā)生變動時,日志表也會觸發(fā)更改操作,避免同步信息中進行更改指令的重復(fù)操作,以節(jié)省多源異構(gòu)數(shù)據(jù)庫信息同步所需的時間。觸發(fā)模塊的運行流程如圖2所示。
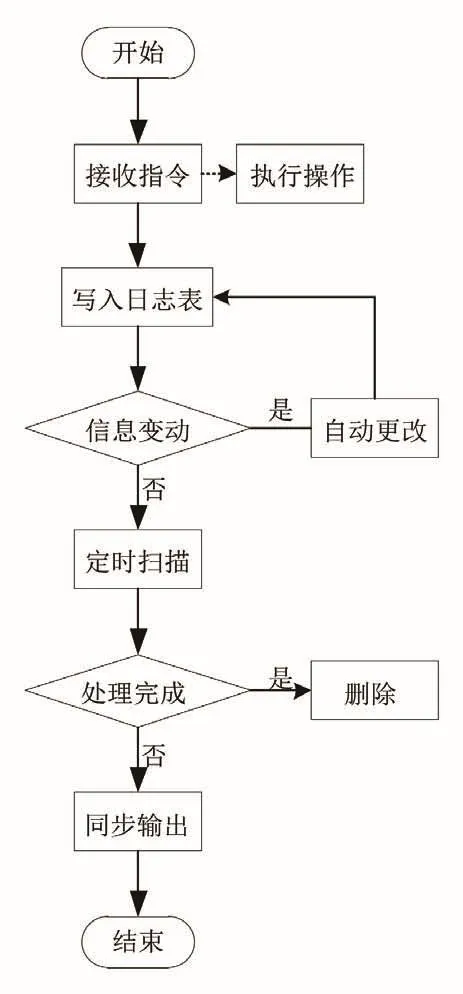
圖2 快速同步觸發(fā)模塊運行流程
本次研究目標(biāo)是加快觸發(fā)模塊運行速度,在其運行流程中加入對數(shù)據(jù)的定時處理程序,定期對日志表進行掃描,刪除已經(jīng)完成同步的信息,減少因重復(fù)同步日志表中的信息內(nèi)容而浪費的時間,進而實現(xiàn)多源異構(gòu)數(shù)據(jù)庫信息的快速同步。
四、 應(yīng)用研究
(一) 實驗準(zhǔn)備
為測試此次本文所提出的多源異構(gòu)數(shù)據(jù)庫信息快速同步方法在實際應(yīng)用中的效果,選取某數(shù)據(jù)庫K作為實驗對象,利用本次研究的信息同步方法對數(shù)據(jù)庫K中不同類型的信息進行同步操作,對所用的時間進行記錄,對照組為傳統(tǒng)同步方法所用時間,通過兩者對比判斷本文研究的多源異構(gòu)數(shù)據(jù)庫信息快速同步方法是否具有可行性。
(二) 實驗結(jié)果反饋
本次實驗將分別選取數(shù)據(jù)庫K中的字符數(shù)據(jù)及圖像數(shù)據(jù)進行同步操作測試,以規(guī)避數(shù)據(jù)結(jié)構(gòu)類型不同對實驗結(jié)果產(chǎn)生的影響。實驗階段將對選取的多源異構(gòu)數(shù)據(jù)進行十次同步測試,分別記錄實驗組和對照組所用的時間,其具體結(jié)果如表1所示。

表1 數(shù)據(jù)庫信息快速同步測試結(jié)果
觀察表1中的實驗數(shù)據(jù)可以發(fā)現(xiàn),對于字符數(shù)據(jù)的同步,實驗組所用時間均少于9s,對照組時間均大于10s;對圖像數(shù)據(jù)進行信息同步時,實驗組所用時間均不超過11s,對照組時間均超過17s。通過計算得出,在對多源異構(gòu)數(shù)據(jù)庫K進行信息同步實驗測試中,實驗組所用的平均時間為8.8s,對照組所用的平均時間為16.13s,實驗組的平均同步時間較對照組縮短了7.33s,證明本次研究方法的有效性。
五、結(jié)束語
本次研究在明確傳統(tǒng)信息同步方法現(xiàn)存問題的基礎(chǔ)上,有針對性地引入多核CPU并行處理數(shù)據(jù)的技術(shù)和模式,為多源異構(gòu)數(shù)據(jù)庫信息快速同步提供了新的可行方法和途徑。然而,對多源異構(gòu)數(shù)據(jù)進行整合主要依靠去噪處理過程與觸發(fā)模塊,因其數(shù)據(jù)差異性較大,此過程容易出現(xiàn)誤差,從而對數(shù)據(jù)庫信息同步的準(zhǔn)確性產(chǎn)生負面影響。今后可以優(yōu)化去噪處理過程與觸發(fā)模塊,對多源異構(gòu)數(shù)據(jù)進行更為精確的分類和整合,確保其過程準(zhǔn)確性的同時,進一步加快多源異構(gòu)數(shù)據(jù)庫信息同步的速度。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
Coco薇(2016年2期)2016-03-22 02:42:52
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
