漢語閱讀障礙的研究熱點與前沿趨勢
——基于CiteSpace的可視化分析
2022-10-13 08:30:10董筱雯申仁洪
現代特殊教育 2022年10期
董筱雯 申仁洪
(重慶師范大學 教育科學學院 重慶 401331)
一、研究背景
閱讀是充分參與社會活動時所需要的基本技能[1],但閱讀障礙則是一個神經生理學領域定義的獨特學習障礙,其特征是無法正確或流利地辨認詞匯,拼寫解碼信息能力差[2]。20世紀80年代前,大多數研究關注的是英語的語音缺陷,中文這一表意文字中的閱讀障礙自1992年后才引起心理學、認知神經學的關注[3]。按照美國的分類,閱讀障礙可以分為獲取性閱讀障礙和發展性閱讀障礙[4]。前者通常是由腦損傷或病變所引起的;而后者則并非因智力、生活環境、教育條件或某種神經障礙等因素造成,其閱讀表現比正常人明顯落后[5]。如無單獨說明,下文中所指閱讀障礙均為發展性閱讀障礙。有研究表明,閱讀障礙發生在學齡期的概率為5%—10%[6],通常容易被誤認為是智力低下、發育遲緩,并因此對兒童正常發展產生不利影響。經過30多年的發展,閱讀障礙逐漸成為特殊教育學、語言學、認知神經學關注的熱點話題。為了準確掌握漢語閱讀障礙的研究熱點及前沿趨勢,本文采用CiteSpace軟件對近20年來CNKI平臺上與漢語閱讀障礙有關的文獻進行系統梳理,并進行知識圖譜量化分析,旨在為漢語閱讀障礙的教育和干預提供科學依據。
二、研究設計
(一)研究工具
本研究使用了CiteSpace知識可視化軟件系統。該軟件系統由美國德雷克塞爾學院陳超美教授研發,適用于從科研文獻中檢索和可視化當前科學技術發展的新趨向。該工具的主要作用是簡化對知識領域文獻中重要論文的搜索,以便在可視化網絡中搜索視覺上的顯著特征,如地標節點、中心節點和樞軸節點[7-8]。
(二)數據來源
本研究的文章數據取自中文學術期刊網絡出版總庫(CNKI)期刊數據庫文獻全文數據。在高級搜索中,以“閱讀障礙”或“閱讀困難”或“讀寫缺陷”或“讀寫障礙”或“誦讀困難”或“閱讀不良”或“閱讀能力低下”和“漢語”為關鍵字展開搜索,設置時間跨度為2001—2021年,剔除關鍵詞索引、編寫術語、學術報告、與主題無關的(如“圖書館服務”等)文章,得出有效論文共396篇。將論文導出至CiteSpace讀出所需要的Refworks格式并經過轉碼處理,最后獲取論文研究的樣本信息庫。檢索時間為2022年4月28日。
三、研究結果
(一)基本情況分析
1.發文量隨年代分布情況
根據檢索結果繪制折線圖1。總體來看,近20年漢語閱讀障礙相關文章始終呈波動上升趨勢,其中2019年發文量最多,表明閱讀障礙從2002年起逐漸引起研究者的重視。

圖1 發文量隨年代變化圖
2.高產機構及核心作者群
運行CiteSpace 5.8.R3,設定時間跨度為2001—2021年,時間切片為1 year,節點類別為institution,通過選擇purning sliced networks方法完成剪枝操作,對其他參數保持默認設定,可以得出節點數為196、連線數為0、時間密度為0的機構共現網絡技術知識點圖像(圖2)。其中北京師范大學心理學院和華中科技大學同濟醫學院節點比較大,而節點間的連接數為零,說明各組織內部基本缺乏聯絡和協同,這在一定程度上也影響了我國對于閱讀障礙研究的擴大領域發展。從發文機構來看(表1),幾所重點師范大學和醫學院都在漢語閱讀障礙的研究上取得了相對豐富的成果。

表1 核心機構及發文量統計

圖2 機構共現網絡知識圖譜
返回CiteSpace界面,把節點類型選為author,其他設置不變,可以得到一個節點數為405、連線數為682、密度為0.0083的作者共現網絡知識圖譜,如圖3所示。其中節點最大的中國學者是吳漢榮,宋然然、劉翔平、白學軍、畢鴻燕等人節點稍小,靜進、譚珂、趙婧等人節點較小。因為學者間交往和協作較多,在知識圖譜中產生了若干個作者子網絡結構,比較重要的是以吳漢榮為首的作者網絡結構、以白學軍為主的作者網絡結構、以靜進為主的作者網絡結構和以宋然然為主的作者網絡結構。另外幾個高產作者間連線也較多,主要體現為學者宋然然、吳漢榮、靜進、李秀紅等人之間有著較多的學術交流和聯系;周圍相對獨立的作者網絡團較小,如舒華和李虹、莫雷和金花、王曉辰和李清等;周圍擁有較多獨立節點的作者,如趙微、熊建萍、周路平等,說明我國部分研究者在對漢語閱讀障礙的研究上溝通協作意識雖然強烈,但這些交流大都存在于一直合作的作者之間,與其他學者之間的交流較少,還有待進一步加強。

圖3 作者共現網絡知識圖譜
(二)研究熱點分析
運行CiteSpace,除設置的結點類型為keyword外,其他均不變,獲得一個節點數為367、連線數為727、密度為0.0108的關鍵詞共現網絡圖譜,如圖4所示。字體的大小代表出現頻率的高低。

圖4 關鍵詞共現網絡圖譜
由圖4可知,閱讀障礙、兒童、語音意識、漢語、眼動、語素意識、閱讀困難、語音加工、工作記憶、快速命名、閱讀能力、字形、小學生、語音缺陷、認知等為出現頻率相對較高的詞匯。可以看出,對漢語閱讀障礙的研究主要集中在“認知領域”。在此基礎上,通過選擇“LLR對數似然算法”,并選擇數量排在前10位的類別,獲取漢語閱讀障礙的關鍵詞聚類分析法知識圖譜。這些聚類大致分為“閱讀障礙”“兒童”“漢語”“眼動”“閱讀困難”“工作記憶”“語音缺陷”“字形”“音位知曉”“語素意識”10個聚類。
在關鍵詞聚類分析法網絡知識圖譜的基礎上,通過選擇“Cluster Explorer”可以得出對數似然率(聚類標記詞選擇計算法之一),得出排名前10的關鍵詞共現網絡聚類表(表2)。

表2 關鍵詞共現網絡聚類表
結合表2和圖4可以看出,各聚類之間存在交叉重疊現象。經過歸納總結,可將漢語閱讀障礙研究熱點歸納為“認知加工研究”“干預性對策”“腦機制研究”“篩選標準”四個次領域。
第一,“認知加工研究”領域,包括“認知”“語言認知”“語素意識”“工作記憶”“快速命名”“語音意識”“語義加工”“執行功能”“音位知曉”等關鍵詞。研究者已經積累了大量的證據,指出閱讀障礙問題的根源是一些認識語言能力的問題,如語音缺陷、詞素缺乏、快速命名、口語詞匯等問題,其中語音意識問題是最主要的認識問題。語音意識指的是認識并控制口語詞匯發音規律過程的能力[9]。Connie等人用長期的縱向研究,證實了語音意識加工能力強弱和閱讀技能之間具有雙向的關系,語音意識的強弱在一定程度上可以預測人們未來的閱讀成果[10-11]。語素意識則主要反映字形和意義之間的關系,指兒童識別、區分、理解和操作語言中最小的音義結合體的能力[12]。近年來更多研究開始轉向語素意識對于閱讀的重要作用。舒華等人曾對從北京市2所學校中選出的被試進行認知意識測試(主要包含語音認知意識測試、語素認知意識測試和命名速度測驗)和閱讀測驗。結果發現,語素意識是具有最大預測性的認知變量,有76%的認讀障礙兒童表現出了語素意識缺陷[13]。除語音意識和詞素意識這兩個元語言學意識以外,快速命名在對詞匯的辨識方面也是漢字閱讀困難的良好指標[14],在漢語閱讀中的重要性隨著年級的升高而增加,且使用文字刺激的快速命名任務比使用非文字刺激的快速命名任務更能預測漢語閱讀的表現[15]。
第二,“干預性對策”領域,包括“干預研究”“早期干預”“成因研究”“語音訓練”“對比研究”“閱讀能力”“閱讀發展”等關鍵詞。結合閱讀障礙兒童的身心發展特點和國內外已有的研究結論,可將干預措施分為教學類干預和認知干預。教學類干預包括計算機輔助和教學設計。關于計算機輔助干預,國內相關文獻較少,一般多為臺灣地區學者使用。該方法指運用電子化教材、繪本及多媒體設備對閱讀障礙進行干預。蔡昌諭也曾使用“電腦多媒體漢字部件教學系統”,將多媒體呈現通過部件組字的過程加以干預,效果顯著[16]。教學設計指采用自己或學者設計的教學程序在教學環境中進行干預,如交互式教學、故事結構法、字詞結構教學等[17]。眾多研究結果已經證明,早期的教育干預方法對有閱讀失敗風險兒童閱讀技能的發展和結果都有程度不同的積極影響,至少可以顯著降低閱讀障礙的發生率。認知干預可分為語言學和非語言學干預,包括語音、語素、正字法意識干預和視覺加工、聽覺加工、工作記憶、閱讀強化干預。以上干預方法都有學者進行相關研究,證實了其對朗讀正確率、流暢性、同時性加工方面有顯著提高及維持作用[18]。但由于被試數量普遍較少,故推廣性都不大,未來還有待增強實證研究。
第三,“腦機制研究”領域,包括“眼跳”“外源性”“內源性”“事件相關電位”“成分模型”等關鍵詞。隨著腦成像技術的發展,閱讀障礙的研究開始轉向腦部機能,包括腦電和腦功能[19]。相關學者采用事件相關電位(event-related potential,以下簡稱ERP),發現閱讀障礙兒童的上升時間和音高變化過程與正常兒童不一致,這表明閱讀障礙患者的快速聽覺處理缺陷可能與注意機制有關。在一些兒童中,同時發生了閱讀障礙與非語言成分的加工問題[20]。研究腦功能的學者使用功能性磁共振成像(functional magnetic resonance imaging,以下簡稱fMRI)技術對腦部的角回和相關枕葉和顳葉位置之間的功能連通性進行研究,發現閱讀障礙患者和正常人只有在語音處理任務上才表現出不一致[21]。也有學者采用正電子發射斷層掃描(positron emission computed tomography,簡稱PECT)對此連接性作了深入探究。結果顯示,在單字閱讀過程中閱讀障礙患者左側角回與枕葉和顳葉視覺聯想區無流通性,而角回被認為和參與將視覺呈現映射到語言表征中的后語言區(威爾尼克區)有關,因此進一步驗證了閱讀障礙患者語言功能存在缺陷[22]。醫學技術的進步以及之前的實驗結論都揭示出閱讀障礙患者的腦部活動存在異常。
第四,“篩選標準”領域,包括“PASS認知模型”“PASS”“語文學習困難”“檢出率”“家庭閱讀環境”“亞型”等關鍵詞。PASS理論認為,人類智力發展是由計劃、覺醒或注意、同時性加工和繼時性加工三級認知功能體系中的四個加工過程構成[23]。通過梳理文獻得知,我國內地學者普遍采用“智力-閱讀成就差異”鑒別方法,即比較閱讀成績與智力水平之間的差異,若超過規定的程度則被診斷為閱讀障礙。但在篩選時需要先確定兩種因素,一是智力成就,二是閱讀成就得分。研究者們對這兩個因素的標準存在很大爭議,使用不同的智力量表或不同的閱讀測驗會導致分數出現差異[24]。由于“智力-閱讀成就差異”缺乏科學性和確定性,沒有考慮到智商與閱讀成績的不完全相關性,與動態的發展模型相悖,因此一種新的“干預-反應模式”在此基礎上逐漸發展起來[25]。
(三)前沿趨勢分析
研究前沿由科學領域中文獻最近被引用的作品組成,代表該領域的最新狀態,并隨著新舊文章更迭和基礎科學領域的變化而發展。對復雜網絡分析的興趣是提高我們對科學網絡和一般網絡理解的潛在有效途徑。
運行CiteSpace,并在控制面板中選擇Burstness,即可獲取關鍵詞突現圖(圖5)。由圖5可知,2002—2004年間的突現詞“兒童”的爆發力最強,說明在此時間段受到了廣泛的關注;2002—2012年間的突現詞“語音缺陷”的突現周期持續時間最長,為10年。因為突發性具有連續性,所以可以推斷出“閱讀能力”“干預”和“中文閱讀”這三個分支有可能在未來幾年繼續成為研究的前沿熱點,也是學者們可以重點研究的方向。
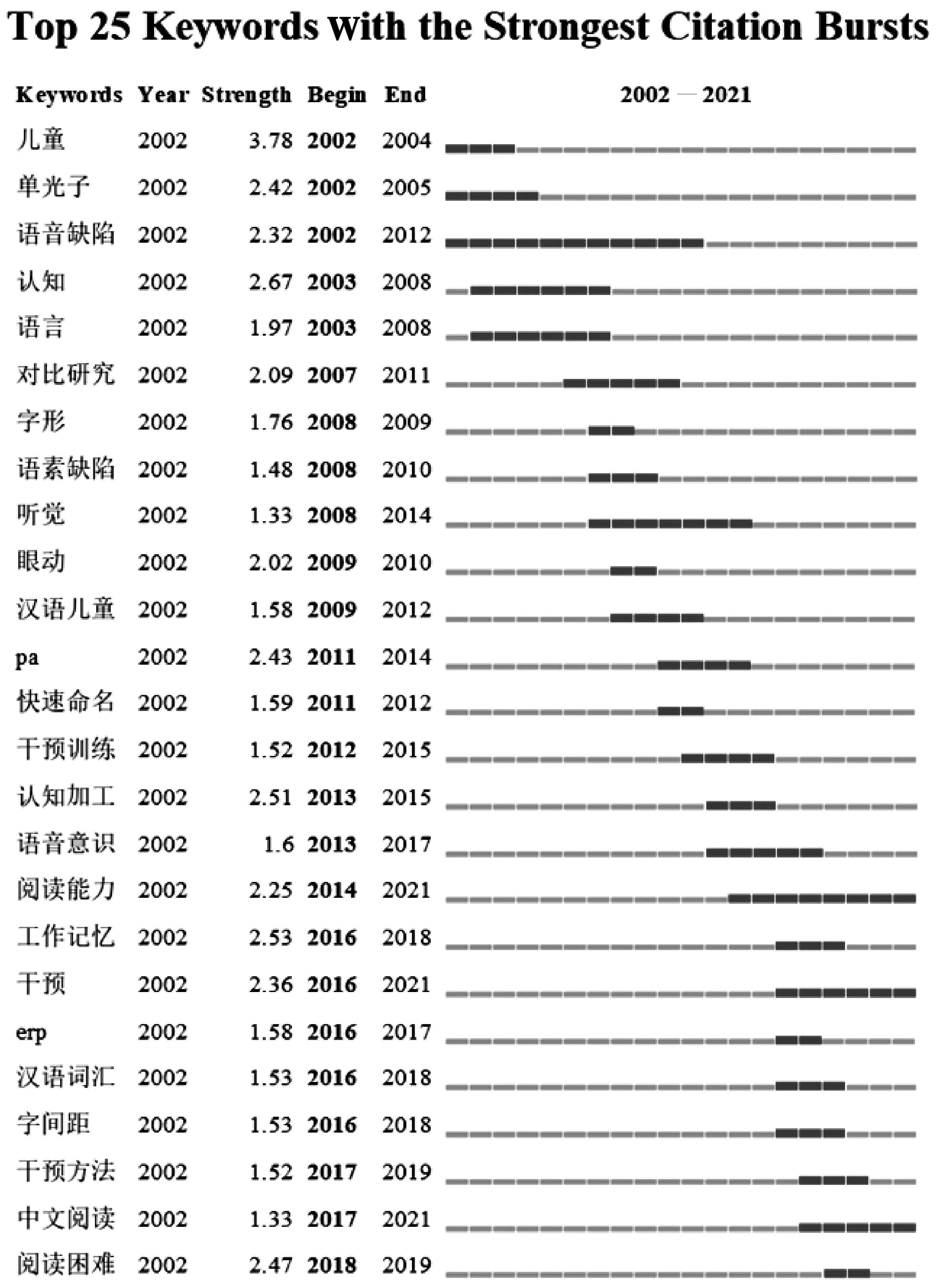
圖5 關鍵詞突現圖
此外,關鍵詞時間線圖譜主要顯示研究前沿和知識庫之間的時間模式,側重于描述聚類之間的關系,也更能體現研究主題隨時間變遷的態勢。時間線視圖由一組作為時間區域的垂直條帶構成,關鍵詞按照日期先后由左至右排序。在layout里選中Timeline View選項,即可獲取關鍵詞時間線圖譜(圖6)。

圖6 關鍵詞時間線圖譜
不同時期的關注點不同。根據時間脈絡和關鍵詞爆發趨勢,可以將閱讀障礙的研究分為早期、中期和后期,以便更好地掌握閱讀障礙的發展動態。
1.早期(2002—2003年)
在這個時期前,西方很早就開始關注閱讀障礙,閱讀障礙兒童早已成為特殊兒童類型之一。而由于稍顯滯后的科學技術、封閉的環境及落伍的觀念,亞洲各國對閱讀障礙的關注力度明顯不足。我國閱讀障礙分支研究此時基本還是空白。這個時期熱點詞為“兒童”“語音缺陷”“語言”“認知”等,意味著人們開始認識到在使用漢語的兒童中閱讀障礙的客觀存在。人們逐漸意識到語言文字的結構會影響閱讀,并逐漸開始了對閱讀障礙的探索。舒華的研究也證實了漢語兒童的確存在閱讀困難現象[26]。有學者研究證實,男童的閱讀障礙發生率明顯高于女童[27]。
2.中期(2004—2013年)
越來越多的專家學者開始關注這一領域。2006年,吳漢榮編制了《兒童漢語閱讀障礙量表》,為有效鑒別閱讀障礙提供了科學依據[28]。此外,還有學者開始探討閱讀障礙的亞類型和致病因素等[29]。由于心理學的快速發展,研究者開始側重于探討正字法、語素和一些高級神經認知機制的影響。這個時期主要探究閱讀障礙兒童的不同特點,如語言、視覺加工、眼動、識字、記憶、快速命名、感覺統合能力等方面[30-31]。腦研究也從這個時期開始使用ERP和fRMI等研究手段[32]。
3.后期(2014年至今)
各種醫療檢測手段和儀器逐漸成熟,開始有針對性地根據不同特征研究教育或干預措施[33],還伴隨有成熟的基因研究[34]。至今,兒童漢語閱讀能力仍是學者們關注的熱點。同時,還有學者探尋了不同因素對閱讀障礙的影響[35]。
四、不足
(一)診斷和評估工具的不足
根據文獻發現,目前國內還沒有一個確切的診斷評估標準,這對漢語閱讀障礙研究的發展是一個阻礙。閱讀障礙的類型包含很廣,且亞類型眾多,如果沒有統一的診斷評估工具,會使結果缺乏科學性和一致性,也就失去了研究的信效度。因此,后期還需要進一步加強對診斷評估工具的開發。
(二)應用研究落后于基礎研究
中國的兒童閱讀障礙研究起步較西方晚,雖然在成因、干預、亞類型等方面都已積累了一定的研究成果,但大多集中在心理學層面而非特殊教育層面,很多理論研究并不能直接運用在閱讀障礙兒童的教學與干預中,而且應用研究也比較滯后,容易造成理論和實踐的脫節。
以上問題有待在今后的研究中加以改進,從而促進對閱讀障礙的深入探究。這不僅有利于為閱讀障礙者的干預制定有效措施,而且能早日改善他們的生活和學習狀況。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
少兒美術·書法版(2021年11期)2021-10-20 06:23:28
少兒美術·書法版(2021年8期)2021-10-20 06:08:10
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
雜文選刊(2016年7期)2016-08-02 08:39:56
小天使·一年級語數英綜合(2016年6期)2016-05-14 12:21:05
