亞洲2型糖尿病發病風險預測模型的系統評價
2022-10-14 23:44:06賀婷袁麗楊小玲葉子溦李饒古艷
中國全科醫學 2022年34期
賀婷,袁麗,楊小玲,葉子溦,李饒,古艷
2型糖尿病(T2DM)是患病人數最多的糖尿病類型,隨著病程進展容易引起各種并發癥,是導致失明、腎功能衰竭、心臟病發作、卒中和死亡的主要原因[1]。國際糖尿病聯盟發布的第九版“全球糖尿病地圖”數據顯示,2019年全球約有5.37億成人糖尿病患者,糖尿病患病率達10.5%,其中約90%為T2DM[2]。過去十年,亞洲人群糖尿病患病率大幅上升,中國和印度是全球糖尿病患者人數最多的兩個國家,亞洲糖尿病的患病總人數占世界糖尿病患病人數的55%[2-3]。研究結果顯示,有超過50%的糖尿病患者未得到及時診斷和治療,T2DM的診斷延遲不僅會使個體醫療保健支出大幅度增長、疾病負擔加重,還可能增加其出現嚴重并發癥,甚至死亡的風險[4-5]。基于T2DM發病風險預測模型的預測結果,醫務人員可早期發現未得到診斷的T2DM患者,以及T2DM高危人群,并通過采取針對性、個體化的預防/干預策略,降低T2DM發病概率/減緩病情進展。在過去的幾十年里,國內外研究者開發了多種基于亞洲人群的預測模型來預測其T2DM發病風險,然而研究者對模型的構建策略報告不夠明確,大多數預測模型使用受限,預測效果仍有待深入驗證。本研究通過系統性地分析、評價亞洲T2DM發病風險預測模型的開發過程和效能,旨在為T2DM發病風險預測模型的選擇和深度開發提供依據與參考。本研究已在PROSPERO登記注冊并審核通過,注冊號為CRD42021244563。
1 資料與方法
1.1 文獻納入和排除標準 納入標準:(1)研究對象為亞洲人群且基線時無糖尿病;(2)研究內容為T2DM發病風險預測模型(不包括診斷模型),并且研究描述了模型的建立、驗證和評價過程;(3)研究類型為隊列研究;(4)英文文獻。排除標準:(1)細胞、分子及基因水平研究;(2)觀察對象為兒童/青少年/特定患病人群(如肥胖、高血壓患者)的研究;(3)預測結果包括T2DM,但不限于T2DM(如心血管疾病)的研究;(4)未采用回歸法(如神經網絡或決策樹)構建預測模型的研究;(5)對既往開發的模型進行驗證的研究;(6)國際會議摘要、二次研究;(7)模型包含的預測因子數<2;(8)重復發表的文獻。
1.2 文獻檢索策略 于2021年4月,計算機檢索PubMed、EmBase、the Cochrane Library獲取有關亞洲T2DM發病風險預測模型的研究,檢索時限均為建庫至2021-04-01。此外,追溯納入文獻的參考文獻,以補充獲取相關文獻。檢索詞包括:type 2 diabetes mellitus、ketosis-resistant diabetes mellitus、non-insulin-dependent diabetes mellitus、stable diabetes mellitus、NIDDM、slowonset diabetes mellitus、adult-onset diabetes mellitus、prediction model、risk stratification model、risk factor score、risk score、risk assessment、algorithm。 以 the Cochrane Library為例,具體檢索策略請掃描本文二維碼獲取。
1.3 文獻篩選與資料提取 2名研究者獨立篩選文獻、提取資料并交叉核對,若存在分歧,則征求第3方意見。文獻篩選時,首先閱讀文題和摘要(初篩),在排除明顯不相關的文獻后,進一步通讀全文根據納入和排除標準以最終確定是否納入(復篩)。基于預測模型研究偏倚風險及適用性評估的要素和資料提取內容制訂標準化表格[6]。資料提取內容主要包括第一作者、發表年份、國家(地區)、研究類型、研究對象年齡、樣本來源、樣本量(不包含缺失數據)、發生結局事件的患者數、隨訪時長、觀察終點、連續變量處理方法、缺失數據數量及處理方法、建模方法、變量選擇方法、驗模方法、受試者工作特征曲線下面積(AUC)、擬合優度、過度擬合情況、模型包含的預測因子、模型呈現形式、局限性(模型/研究)。
1.4 納入文獻的偏倚風險及適用性評估 由2名研究者獨立采用預測模型偏倚風險評估工具(PROBAST)對納入文獻的偏倚風險和適用性進行嚴格評估,若存在分歧,則征求第3方意見。PROBAST由MOONS等[7]、WOLFF等[8]于2019年推出,包含研究對象(2個問題)、預測因子(3個問題)、結果(6個問題)和數據分析(9個問題)4個領域。每個領域的評估結果分為“低”“高”“不清楚”3個等級。每個問題采用“是/可能是”“可能不是/不是”或“沒有信息”進行回答。若4個領域的偏倚風險評估結果均為“低”,則整體偏倚風險被判斷為“低”;若有≥1個領域的偏倚風險評估結果為“高”,則整體偏倚風險為“高”;若有領域的偏倚風險評估結果為“不清楚”,而其他領域的偏倚風險評估結果均為“低”,則認為整體偏倚風險為“不清楚”。此外,對于模型構建研究,即使所有領域的偏倚風險評估結果均為“低”,若模型未經過外部驗證,則整體偏倚風險仍為“高”。PROBAST主要從前3個領域對適用性進行評價,適用性評價方法與偏倚風險評價方法相似。
1.5 統計學方法 采用描述性分析法對模型的基本特征及納入研究的偏倚風險與適用性評價結果進行總結、分析。
2 結果
2.1 文獻篩選流程及結果 通過檢索得到相關文獻12 550篇,經過逐層篩選,最終納入研究31項[9-39]。文獻篩選流程見圖1。

圖1 文獻篩選流程Figure 1 Literature screening flowchart
2.2 納入文獻的基本特征 納入的31項研究主要來源于中國(n=15)、日本(n=6)和韓國(n=4);17項[9-11,14-18,20-21,26,28,30,34-35,37-38]為前瞻性隊列研究,14項[12-13,19,22-25,27,29,31-33,36,39]為 回 顧 性 隊 列 研究;樣本量(不包含缺失數據)為1 851~366 009,發生結局事件的患者數為144~38 718例。30項[9-10,12-39]研究將空腹血糖(FBG)≥ 7.0 mmol/L作 為觀察終點,12 項[18-20,22,25,30-31,33,35-38]研究將糖化血紅蛋白(HbA1c)≥6.5%作為觀察終點,13項[9,11,14-17,19,25,29,31,34,36,38]研 究 將 餐 后 2 h 血 糖(2 h-PG)≥ 11.1 mmol/L 作為觀察終點,3 項[22,33,36]研究將隨機血糖≥11.0 mmol/L作為觀察終點,見表1。

表1 納入的亞洲T2DM發病風險預測模型研究的基本信息Table 1 Basic characteristics of included studies on risk prediction models for T2DM in Asian adults
2.3 納入預測模型的基本特征
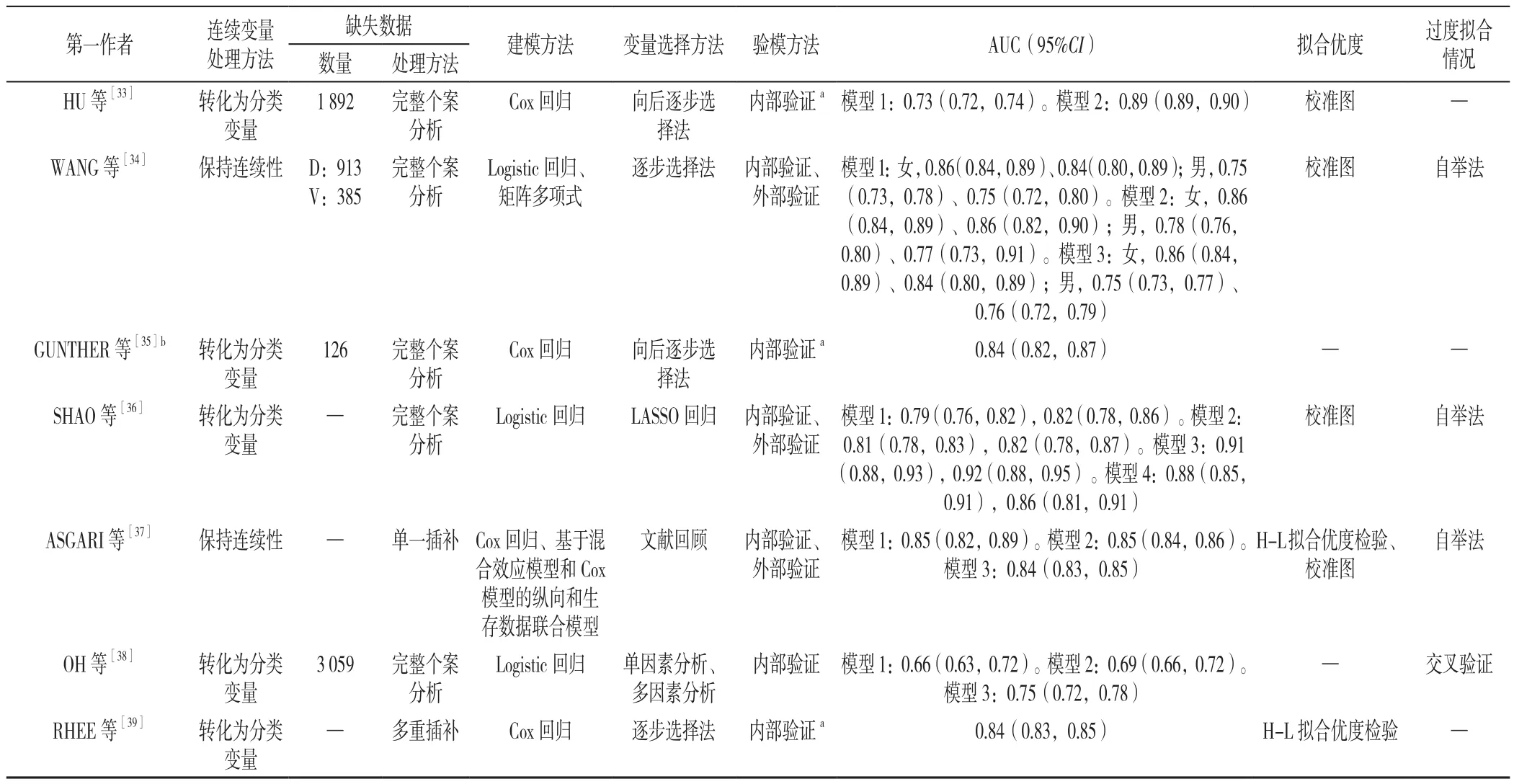
2.3.1 模型的建立與驗證 3項[26,34,37]研究保持了連續變量的連續性,2項[18,31]研究保持了部分連續變量的連續性,26 項[9-17,19-25,27-30,32-33,35-36,38-39]研究將全部連續變量轉化為分類變量。數據缺失及其處理方法方面,3項[14,19,38]研究存在著較為嚴重的數據缺失現象(缺失率>30%),RHEE等[39]采用多重插補法處理缺失值,ASGARI等[37]使用單一插補法對缺失數據進行填補,22 項[9-11,14,17-24,27-30,32-36,38]研究采用了完整個案分析法。納入研究多采用Cox回歸、Logistic回歸建立模型。WANG等[34]在采用Logistic回歸建立模型的同時,建立了矩陣多項式模型;LIU等[24]通過建立亞分布風險模型,避免數據競爭;ASGARI等[37]在采用Cox回歸建立靜態預測模型的同時,建立了基于混合效應模型和Cox模型的縱向和生存數據聯合模型。20 項[10,12-14,16-19,22-23,25,27,29-35,39]研 究 報 告 在 篩 選變 量 時 采 用 了 逐 步 選 擇 法,7 項[9,15,19,21,24,28,38]研 究 采 用 了 單 因 素 分 析,SHAO 等[36]則基于LASSO算法進行變量篩選。4項[11,16,31,34]研 究 建 立 了 基 于 性 別 的 T2DM 發病風險差異化預測模型。模型驗證方面,5 項[9,15,17-18,31]研 究 僅對 模型 進 行了 外 部驗 證,22 項[10-14,16,19-21,23-30,32-33,35,38-39]研 究 僅 對 模 型進行了內部驗證,4項[22,34,36-37]研究采用內部驗證與外部驗證相結合的方法對模型進行了驗證。納入模型的AUC為0.62~0.92,提示模型預測性能 較 好。15 項[10,14,19-21,23-24,26-27,30,32,34,36-38]研究考慮了模型的過度擬合情況,并對其進行了校準,見表2。

表2 亞洲T2MD發病風險預測模型建立和驗證的基本特征Table 2 Basic characteristics of development and validation included risk prediction models for T2DM in Asian adults
2.3.2 模型中的預測因子及其呈現形式 模型包含的預測因子數量為3~24個,預測因子可主要分為人口學因素、體格檢查指標、實驗室檢查指標三類。其中人口學因素以年齡、性別和糖尿病家族史較為常見,體格檢查指標以體質指數(BMI)和腰圍較為常見,而實驗室指標以FBG、HbA1c和三酰甘油(TG)較為常見。模型呈現形式主要以風險評分和風險計算公式為主,3項[23,34,36]研究采用列線圖的方式呈現模型,見表3。

表3 亞洲T2MD發病風險預測模型的預測因子、呈現形式及其局限性Table 3 Predictors,presentation and limitations of included risk prediction models for T2DM in Asian adults
2.4 納入文獻的偏倚風險和適用性評價結果
2.4.1 納入文獻的偏倚風險評價結果 納入研究均存在較高的偏倚風險。
2.4.1.1 研究對象領域 4項[10,33-34,36]研究將特定人群,如心血管疾病、癌癥、卒中患者、妊娠者排除在研究對象之外,這可能會對T2DM發病率的準確性造成不利影響,故此4項研究在該領域的偏倚風險評估結果為“高”,其余研究均為“低”,見表4。
2.4.1.2 預測因子領域 XU等[21]和 NANRI等[22]的研究為多中心研究,但各中心對預測因子采用的測量方法有差異;WANG等[23]的研究則未報告預測因子測量相關信息。2項[21-22]研究在該領域的偏倚風險評估結果為“高”,1項[23]研究為“不清楚”,其余研究均為“低”,見表4。
2.4.1.3 結果領域 2項[16,28]研究中,FBG既是T2DM的診斷標準,亦是模型中的預測因子,但此2項研究均未明確基于FBG的模型適用條件。NANRI等[22]、YATSUYA等[30]、HU等[33]的研究中,接受降糖治療的定義及結局變量的測量方法在各中心間有所不同。OH等[38]的研究中,對于葡萄糖耐量試驗和HbA1c數據缺失的個案,僅憑借FBG診斷T2DM,這可能會導致診斷性偏倚。上述 6 項[16,22,28,30,33,38]研究在該領域的偏倚風險評估結果為“高”,其余研究均為“低”,見表4。
(續表2)

(續表3)
2.4.1.4 數據分析領域 除3項[23,27,29]研究在該領域的偏倚風險評估結果為“不清楚”,其余研究均為“高”。10 項[9-10,12,14,16-18,21-22,24]研究在轉化連續變量的過程中未檢驗連續變量間是否存在非線性關系或未對分類變量進行標準的定義,故在相應問題上被評價為“否”。10項[10,14,18,22,25,29,30,35-37]研究未將所有的研究對象納入分析(研究數據多來源于數據庫,或為登記數據),這可能會導致結果出現偏差。采用完整個案分析法處理缺失數據的研究中,4項[9,14,20,24]研究對剔除樣本與納入分析樣本的基本特征進行了組間比較分析,發現差異無統計學意義,該處理方法相對合理;而其余研究在采用完整個案分析法處理缺失數據后,在不確定數據缺失是否完全隨機的情況下,并未對剔除樣本的特征進行分析,可引起偏倚。僅1項[24]研究明確表示考慮了數據競爭問題,在相應問題上被評價 為“ 是 ”。16 項[10-13,15-16,18-19,24,26-27,32,34,35,38]研究由于未報告模型的校準度,或僅以H-L擬合優度檢驗的統計量值和P值反映模型的校準度而未能提供校準圖等因素,在相應問題上被評價為“否/可能否”,見表4。
2.4.2 適用性評價結果 納入模型總體及在各領域上的適用性較好,見表4。

表4 納入文獻偏倚風險及適用性評價結果Table 4 Results of the assessment of risk of bias and applicability of included studies on the risk prediction model of T2DM
3 討論
3.1 亞洲T2DM發病風險預測模型的研究尚處于發展階段 本研究系統檢索了亞洲T2DM發病風險預測模型相關研究,經過逐層篩選,最終納入了31項研究。納入模型的AUC為0.62~0.92,其中12 項[12-14,18,22,25,33-37,39]研 究 開 發 的 40 個 模 型 的AUC>0.8,2 項[18,36]研究中的 2 個模型的 AUC>0.9,提示模型預測性能較好。所有納入的研究均存在高偏倚風險,主要原因為對連續變量的處理不合理、對缺失數據的處理不合理、存在樂觀偏差、忽略了模型的過度擬合問題、未規范地對模型進行評價及缺乏外部驗證等。
3.2 亞洲T2DM發病風險預測模型存在同質化現象 T2DM發病風險預測模型包含的預測因子以年齡、性別、糖尿病家族史、BMI、腰圍、FBG、HbA1c和血脂指標為多見。一方面提示臨床醫務工作者應重視上述指標對T2DM發病的預警作用,加強對其的評估;另一方面也說明T2DM發病風險預測模型存在較為嚴重的同質化問題。探索新的、個性化預測因子可能有助于突破現有發展“瓶頸”,提升模型的預測性能,提高個體化治療水平[40-42]。流行病學研究結果表明,心理因素、飲食習慣、貧困、受教育程度、職業壓力水平、睡眠障礙與T2DM發病高風險相關[43-44]。但由于上述部分指標缺乏統一的評估標準且主觀性較強,少有研究者將其列為候選預測因子或將其納入預測模型。下一步,可探究上述因子對模型預測性能提升的影響。同時考慮到T2DM發病率具有性別與年齡差異[45-46],故也可深入開發基于性別、年齡的T2DM發病風險差異化預測模型。
3.3 亞洲T2DM發病風險預測模型存在高偏倚風險PROBAST是由Cochrane協助組推薦的預測模型研究偏倚風險評估工具。研究均于該工具發布前實施、模型開發過程中應注意的細節問題較多可能是導致偏倚風險較高的原因之一。未來,研究者可按照PROBAST開展T2DM發病風險預測模型的開發與驗證工作,并嚴格遵循多變量預測模型報告規范,進而盡可能地減少研究中存在的偏倚。
3.3.1 連續變量與缺失數據處理 本研究中,83.9%(26/31)的研究對連續變量進行了分類處理,但此方法可能導致重要信息丟失、變量間的關系被破壞及模型預測能力的下降[47]。有研究者認為,對于連續變量,宜保持其連續性,若連續變量間存在非線性關系,可運用分段多項式函數(如樣條函數)處理數據[48]。除了未報告缺失數據處理方法的研究外,91.7%(22/24)的研究采用完整個案分析法處理缺失數據,該方法雖簡單易用,但可能會消減數據特征、降低數據和研究的效力[49]。多重插補、單一插補法的運用能有效降低數據缺失對統計分析、模型穩定性造成的不利影響,提高研究精度和結果可靠性,是合適的數據缺失處理方法[50]。
3.3.2 模型的過度擬合和存在的樂觀偏差 模型的不確定性和參數的不確定性可導致模型的過度擬合,連續變量的離散化處理、基于單因素分析的變量篩選方法等可使模型出現樂觀偏差的可能性增高,而兩者(模型的過度擬合、模型出現樂觀偏差)均可致使預測模型的泛化能力下降[51]。本文納入的研究中,48.4%(15/31)的研究考慮了模型的過度擬合問題,這也提示研究人員對模型過度擬合問題及其存在的樂觀偏差重視程度不夠。隨機將數據集拆分為兩個子集并將其中一個子集用于內部驗證,已經被證實為一個不太恰當的測量樂觀偏差的方法[52-53]。今后,在開發T2DM發病風險預測模型時,可使用自舉法、交叉驗證法等對模型擬合進行校驗,校驗時須重復整套建模流程,包括變量轉換、缺失值處理、變量篩選和模型擬合,否則可能無法衡量模型存在的實際樂觀偏差水平[54]。此外,開發動態預測模型也可能是解決模型過度擬合的有效方法,如ASGARI等[37]通過使用縱向數據(即重復測量數據,如FBG)和事件發生時間數據進行聯合建模,使開發的T2DM發病風險預測模型具備了動態性。聯合模型的原則是先定義兩個子模型,即混合效應模型和Cox模型,然后使用其共同的潛在結構將其鏈接起來。下一步,研究者可深入開發基于混合效應模型和Cox模型的縱向和生存數據聯合模型,盡量做到將縱向數據與事件發生時間數據聯合起來進行分析,進而使參數估計的偏差進一步減小,提高統計推斷的效率。
3.3.3 模型驗證與應用 本研究發現,29.0%(9/31)的研究對模型進行了外部驗證(其中4項研究采用內部驗證與外部驗證相結合的方法對模型進行了驗證),大部分模型仍處于內部驗證階段,這使得現有模型的轉化率較低且偏倚風險較高。外部驗證和重新校準有助于增強模型的泛化能力,與開發新模型相比,具有更高的成本效益。醫務工作者可基于本研究結果選取高質量的T2DM發病風險預測模型并對其進行外部驗證(大樣本、多中心數據)后,將其應用于臨床;或通過開展多中心、跨國預測模型構建研究,提高T2DM發病風險預測模型的臨床應用率、轉化率。也可基于電子病歷系統構建自動化的T2DM發病風險預測工具;或將傳統預測工具與計算機技術相結合,如基于網絡的交互式列線圖,使模型可以與電子病歷系統相結合的同時,也可借由網頁在移動設備、個人計算機上呈現,進而:(1)同時滿足醫務人員和社區糖尿病患者對T2DM發病風險預測工具的使用需求;(2)使模型在得到復雜算法支撐的同時,減少人工計算的工作量;(3)使模型更易于理解,用戶使用模型的積極性得以提高。
本文存在一定的局限性。首先,受限于文獻納入與排除標準,本研究納入的文獻可能不夠全面,存在一定的選擇偏倚;其次,由于納入文獻在研究對象及方法上存在明顯的異質性,本研究未對納入研究進行定量分析。
作者貢獻:賀婷負責文章的構思、設計與撰寫,并對文章整體負責,監督管理;賀婷、葉子溦、李饒負責文獻、資料的收集與整理;賀婷、袁麗,楊小玲負責文獻偏倚風險和適用性評估、論文的修訂;賀婷、古艷負責文章的質量控制及審校。
本文無利益沖突。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2022年5期)2022-08-24 02:35:42
中老年保健(2022年1期)2022-08-17 06:14:56
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
中老年保健(2021年5期)2021-08-24 07:07:20
中老年保健(2021年11期)2021-08-22 03:15:16
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
