中文醫學知識圖譜研究及應用進展
2022-10-16 05:50:42范媛媛李忠民
計算機與生活 2022年10期
范媛媛,李忠民
中南大學 生命科學學院,長沙410013
受語義網(semantic web)概念的啟發,Google公司于2012 年提出了知識圖譜(knowledge graph,KG),目的是為了提高搜索引擎的效率和精確度,提供更好的搜索質量和用戶體驗。隨后,這一概念得到了傳播并廣泛應用于電商、金融、教育和醫療等行業中,推動人工智能從感知智能向認知智能跨越。知識圖譜是一種用圖模型來描述知識和建模世界萬物之間的關聯關系的技術方法,它吸收了本體和語義網在知識組織和表達方面的理念,以符號形式描述物理世界中的概念及其相互關系,使得知識更易于在計算機之間和計算機與人之間交換、流通和加工。目前,國內外已經涌現出一大批通用知識圖譜,如DBpedia、Freebase、Yago、CN-DBpedia、Zhishi.me以及OpenKG等都很有代表性。由于通用知識圖譜具有規模大、領域寬、知識廣、技術成熟等特點,在綜合性搜索引擎和常識性智能問答方面已經得到了廣泛應用。因此,研究人員將目光逐漸聚焦到領域知識圖譜的構建及應用上。
在衛生信息化進程不斷深入、醫學數據規模指數增長的背景下,知識圖譜作為機器認識世界的基石,無疑會在醫學人工智能的實現上發揮重要的作用。早期與醫學知識圖譜相關的研究成果已有許多,國外有一體化醫學語言系統(unified medical language system,UMLS)、醫學系統命名法-臨床術語(systematized nomenclature of medicine-clinical terms,SNOMED-CT)和生物醫學領域語義數據集成平臺(linked life data)等,國內則有中文一體化醫學語言系統(Chinese unified medical language system,CUMLS)、中醫藥學語言系統(traditional Chinese medicine language system,TCMLS)等。有關醫學知識圖譜近期的研究成果如何,筆者對近五年的綜述文獻進行了梳理,發現國外學者比較關注知識圖譜構建技術的發展,傾向于將基因組學的內容也納入醫學知識圖譜中,側重知識圖譜在用藥推薦、新藥發現等方面的應用。國內學者通常從知識圖譜架構、技術及在醫療服務中的應用場景等方面展開綜述,也有學者用文獻計量學的方法探討了中文醫學知識圖譜研究熱點的變化。縱觀現有的綜述文獻,少有學者關注通用技術在中文醫學知識圖譜構建方面的研究進展,也少有學者對中文醫學知識圖譜已有的研究和應用成果進行系統梳理。因此,本研究將從以下三方面對中文醫學知識圖譜的研究現狀進行綜述:(1)對醫學知識圖譜構建的關鍵技術進行梳理,發現新的技術進展以及難點;(2)從醫學本體構建、全科醫學知識圖譜構建和單病種醫學知識圖譜構建三方面對中文醫學知識圖譜已有的研究成果進行總結,以便學者尋找新的研究方向;(3)對中文醫學知識圖譜已有的應用成果進行梳理,并探討未來新的應用場景。
在CNKI、PubMed、WOS、Elsevier 以及谷歌學術等數據庫中,采用“知識圖譜(knowledge graph)”“知識表示(knowledge representation)”“知識抽取(knowledge extraction)”“知識融合(knowledge fusion)”“知識推理(knowledge reasoning)”與“醫學(medicine)”“醫療(medical)”“疾病(disease)”進行組配檢索,文獻類型選擇非綜述,時間跨度限近五年,同時利用追溯法對重要文獻的引文進行擴展檢索,共檢索出472篇文獻。對外文文獻進行初步的整理和歸納后,發現除英文之外還有針對印尼語、阿拉伯語、瑞典語和西班牙語等語種的醫學命名實體識別研究,但未涉及醫學知識圖譜構建及應用。因此本文僅保留代表知識圖譜技術進展的經典文獻以及相關度較高的醫學知識圖譜中英文文獻進行綜述。
1 知識圖譜構建的關鍵技術
知識圖譜的構建指通過從大量的結構化或非結構化的數據中提取出實體、關系、屬性等元素繪制成圖譜,并選擇合理高效的方式進行存儲。根據知識圖譜的邏輯結構可將知識圖譜劃分為兩個層次:模式層和數據層。模式層存儲的是用于規范實體、屬性和關系,經過提煉的知識,通常借助本體庫來管理,指導數據層的構建;數據層存儲的則是以三元組為基本表達單元的一系列具體事實。正是由于這一邏輯結構,知識圖譜衍生出了自頂向下和自底向上兩種構建方式,前者常用于領域知識圖譜的構建,后者常用于通用知識圖譜的構建。
無論何種知識圖譜構建方式,都涉及知識表示、知識抽取、知識融合以及知識推理這些關鍵技術,即需要首先確定知識表示模型,然后對不同來源的數據選擇不同的手段進行知識抽取,利用知識融合和知識推理技術提升知識圖譜的質量,最后根據具體的應用場景設計不同的知識訪問與知識呈現方式。具體流程如圖1 所示。本文從知識圖譜的全生命周期出發,對知識圖譜關鍵技術的研究進行分析。
1.1 知識表示
知識表示是對現實世界的一種抽象表達,知識必須經過合理的表示才能被計算機處理。從圖1可以看到,知識表示主要有符號表示和向量表示兩種形式。

圖1 知識圖譜構建流程Fig.1 Construction process of knowledge graph
以符號邏輯為基礎的知識表示方法主要包括產生式表示法、框架表示法、語義網絡表示法等,由于這幾種方法都缺少嚴格的語義理論模型和形式化的語義定義,Baader等提出了描述邏輯語言以提升知識表示的能力,進而滿足復雜程度更高的推理需要。在Tim Berners-Lee提出語義網概念后,業界需要一套標準語言來描述Web的各種信息。W3C就以描述邏輯為基礎提出了資源描述框架(resource description framework,RDF)、RDF 模式(resource description framework schema,RDFS)和網絡本體語言(Web ontology language,OWL)來規范互聯網中的知識表示,使信息可以被計算機應用程序讀取并理解。
由于符號化的表示無法滿足計算的需要,向量化表示很快成為了知識表示的主流形式,即將語義信息表示為稠密、低維、實值向量,通過計算習得自然語言中的復雜語義模式,以解決知識圖譜面臨的計算效率低和結構稀疏等問題。自Word2vec問世以來,以深度學習為代表的知識表示學習(knowledge graph representation learning,KRL)研究獲得廣泛關注。在Word2Vec 的啟發下,Bordes 等提出了翻譯模型TransE,許多學者在這一經典模型上進行研究和改進,先后提出了TransH、TransD、TransR和TransG等基于復雜關系建模的知識表示模型。國外有學者對不同的知識表示模型在生物醫學領域的應用進行了研究,在關系抽取和鏈接預測任務中,利用TransE 進行嵌入表示的效果都優于其他常用的知識表示模型。隨著知識表示和知識外延的擴充,越來越多的知識表示模型不斷被提出,如Deep-Walk、Node2Vec以及SDNE(structural deep network embedding)等。
針對知識表示學習在中文醫學數據上的應用,國內學者也進行了研究。Zhao等在其研究中使用TransE 模型對中文電子病歷中的醫學實體進行分布式表示,實驗結果表明向量表示確實有利于挖掘醫學知識之間的關系,并有利于推理計算。Li等還基于TransH 模型提出了一種將知識三元組的不確定性引入到翻譯學習算法中的增強模型PrTransH,并利用該模型學習中文疾病實體的嵌入向量,對從電子病歷中抽取到的疾病實體進行聚類,完成了實體排序任務,實驗證明該模型在中文表示學習方面優于TransH。沈思等以中文腫瘤期刊全文為研究對象,用主題詞嵌入表示模型(topic word embedding,TWE)進行詞向量和主題向量的詞嵌入表示,然后基于孿生神經網絡模型進行相似度計算,實驗結果表明嵌入主題層面的語義信息有利于挖掘中文醫學文本中的關聯知識。
與國外研究相比,中文醫學知識表示的研究大多采用單一模型,缺乏對不同模型的對比研究,也未見針對中文醫學知識表示的新模型提出。但現有的研究也證實了知識表示學習能有效提升計算機對中文醫學文本的處理能力,未來仍值得深入研究。
1.2 知識抽取
知識抽取是實現自動化構建知識圖譜的重要技術,其目的在于從不同來源、不同結構的數據中進行知識提取并存入知識圖譜中。由圖1 可以看出,知識抽取包括了實體抽取、關系抽取和屬性抽取,其中實體抽取和關系抽取最為關鍵。
實體抽取又稱命名實體識別,常用的方法有基于詞典及規則的方法、基于統計模型的方法和基于深度學習的方法。基于詞典及規則的方法需要事先編制詞典或制定規則,雖精確度高,但召回率低。基于統計模型的方法則過分依賴人工標注語料的質量。由于缺乏中文標注語料,現有研究多在國外的公開語料GENIA 和BioCreative 大賽的語料庫上進行。基于深度學習的方法直接以文本中的詞向量作為輸入,可以有效地減少模型對人工標注數據的依賴,目前在命名實體識別方面的研究較多。
由于上述三種方法均存在一定的局限性,就有學者對混合實體抽取方法進行了探索。栗偉等提出了機器學習與規則結合的方法對醫學實體進行抽取,以中文電子病歷為數據集進行實驗,取得了不錯的結果。2016 年,Lample等開創性地提出了長短期記憶網絡(long short-term memory,LSTM)與條件隨機場(conditional random fields,CRF)模型相結合的實體抽取方法,并在實驗中取得了與傳統統計方法最好結果相近的結果,很快這種模型就成為了學界研究的熱點。國內許多學者在此模型的基礎上結合不同的詞向量預訓練模型進行中文醫學實體識別工作都取得了較好的結果。在不同的預訓練模型中,基于Transformer 的雙向編碼器表示模型(bidirectional encoder representations from transformers,BERT)能很好地處理中文醫學文本中常見的一詞多義問題,因此BERT-BiLSTM-CRF 模型在中文醫學實體識別中得到了更廣泛的應用。當學界聚焦于基于深度學習的實體抽取時,Ramachandran等提出了基于詞典和深度學習混合的命名實體識別方法。他們在研究中構建了醫學詞典,依據詞典對文本進行標注,用標注數據訓練深度學習模型,再用詞典驗證模型識別的結果。利用該混合方法進行生物醫學文獻命名實體識別,準確率比基線模型提升了約0.15。
關系抽取一般是在實體抽取完成之后,通過從文本中抽取實體之間的關聯關系,將識別出的一系列離散實體聯系起來。早期的關系抽取方法大多基于模板匹配實現,由領域專家手工編寫模板,從文本中匹配具有特定關系的實體。但由于人工構建的模板數量有限,覆蓋范圍較小,在系統中召回率普遍不高,因此學界開始嘗試采用基于監督學習的關系抽取方法,包括最大熵方法、核函數方法和特征工程方法等,這些方法本質上還是依賴標注數據對統計模型進行訓練從而實現關系抽取。為了能進一步減少模型訓練對標注數據的依賴,基于弱監督學習的關系抽取方法也逐漸成為了學界的一大研究熱點。目前比較有代表性的模型有Ji等提出的基于句子級注意力和實體描述的神經網絡關系抽取模型(attention piecewise convolutional neural networks,APCNNs)以及Feng等基于卷積神經網絡(convolutional neural network,CNN)提出的強化學習關系分類模型(convolutional neural networks reinforcement learning,CNN-RL),還有Carlson等提出的一種基于Bootstrap 算法的半監督學習方法等。
目前中文醫學實體抽取的研究常用基于深度學習的方法。曹春萍等使用BioCreative V 大賽的語料庫與數據庫進行實體關系抽取,針對長文本中存在核心實體關系不精確的問題,提出了雙向簡單循環神經網絡與帶注意力機制的卷積神經網絡相結合的模型,實驗驗證該模型在化學物質與疾病的關系抽取中具有良好表現。丁澤源等利用公開的英文生物醫學標注語料,結合翻譯技術和人工標注方法構建了中文生物醫學實體關系語料,然后使用結合注意力機制的雙向長短期記憶網絡抽取實體間的關系。實驗結果表明,該方法可以準確地從中文文本中抽取生物醫學實體及實體間關系。此外,高峰等在BiGRU-2ATT 模型之上融合了關系發現詞算法,將關系發現詞作為模型的額外特征輸入對診療關系進行抽取,有效提升了模型性能。武小平等根據中文語義中主要以詞而不是字為基本單位的特點,提出了改進的基于全詞掩膜的BERT-CNN 模型。這兩項實驗均提升了中文語料關系抽取的性能,但所用數據集均為學者自主構建,難免影響模型的可移植性。
1.3 知識融合
知識圖譜中的數據由于來源不同常存在異構現象,導致了知識質量的參差不齊。知識融合就是通過映射和匹配使不同來源的知識在同一框架規范下進行整合、消歧和加工。知識融合對提升知識圖譜的質量、知識復用以及實現異構數據源之間的語義互通都具有重要意義。知識融合的主要任務包括實體對齊和實體消歧。
知識在不同的數據源中常出現多元共指現象,實體對齊就是用于解決異構數據中的實體沖突、指向不明等不一致問題。傳統的實體對齊方法主要依賴眾包技術或者利用維基百科的信息框等結構良好的模式進行。由于人工成本較高且難以大規模應用,基于機器學習和深度學習的實體對齊方法的研究很快就在學界興起。決策樹算法很早就被用來解決實體對齊問題,近年仍有學者在此算法上結合知識嵌入進行深入探索。深度學習方面,國內學者李文娜等利用TransE 模型表示實體的結構信息,利用BERT 模型表示實體的語義信息,并據此設計了聯合語義表示模型完成了不同知識庫之間的實體對齊任務。Zhang等提出了一種基于語義和結構嵌入的相關性預測方法(semantic&structure embeddings-based relevancy prediction,S2ERP),該方法在使用BERT 模型獲取實體語義嵌入的同時使用圖卷積網絡(graph convolutional network,GCN)獲取術語庫中實體同義詞和下位詞的結構嵌入,從而完成電子病歷與知識庫之間的實體對齊。
實體對齊解決了同義異名的問題,而實體消歧則用來解決不同知識庫之間實體的同名異義問題。實體消歧的核心思想就是聚類,關鍵在于如何定義實體對象與指稱項之間的相似度。較為常用的一種方法為詞袋模型,將當前實體指稱項周邊的詞構建成特征向量,利用余弦相似度進行比較從而完成聚類。然而這種方法沒有考慮上下文的語義信息,在性能上就會有一定的損失,而后就有學者提出了基于語義上下文相似度的實體消歧方法。現有的研究大多依賴外部知識庫進行實體消歧,如Han 和Zhao選擇以維基百科作為背景知識,將各詞條之間的關聯關系融合進了實體指稱項的相似度計算中,提升了實體消歧的效果。王靜等基于DBpedia 知識庫生成候選實體指稱,再利用概率模型計算實體上下文和實體指稱上下文之間的相似度,選取相似度最大的實體作為目標實體,完成生物醫學領域文獻中的實體消歧并在實驗中取得了83%的準確率。為了減少實體消歧對外部資源的依賴,Duque等開發了一個實體消歧系統,先以PubMed 上下載的文獻摘要為數據源,采用無監督的方法自動構建知識圖譜,然后使用PageRank 算法進行詞義消歧。在深度學習技術方面,Vretinaris等對圖神經網絡(graph neural networks,GNN)模型進行了改進,將來自醫學知識庫的領域知識引入到查詢圖中,并在負采樣過程引入了生成對抗網絡(generative adversarial network,GAN),以避免梯度消失的問題,從而獲得更好的性能,有效解決了醫學領域的實體消歧問題。
知識融合對醫學知識圖譜質量的提升具有重要意義,然而目前中文醫學知識融合的研究相對較少,高效且可擴展性強的中文醫學知識融合算法仍有待深入研究。
1.4 知識推理
知識推理指通過計算從圖譜中已有的實體關系中挖掘出隱含信息。知識圖譜也正是由于具備可推理性而廣泛應用于不同領域的具體業務中。傳統的知識推理方法有基于描述邏輯推理、基于規則推理與基于案例推理等。Bousquet等使用DAML(DARPA agent markup language)+OIL(ontology inference layer)描述邏輯語言對監管活動醫學詞典(medical dictionary for regulatory activities,MedDRA)執行術語推理來改進藥物警戒系統中的信號檢測。Chen等采用基于規則推理的方法開發了糖尿病診斷系統以提供用藥建議。由于案例推理與醫療診斷具有極高的相似性,符合醫學專家求解新問題的思維過程,在醫學領域的應用更為廣泛,國內相關研究也較多。沈亞誠和舒忠梅提出了患者病歷的多元式表示法,并結合歸納索引法與最近鄰法構建了基于病歷的案例推理系統。Ping等提出了基于多重測量值的案例推理方法(multiple measurements case-based reasoning,MMCBR)來建立肝癌復發預測模型,該模型綜合患者在一定時間序列的多個測量指標來進行案例匹配,實驗表明模型性能優于單測量值的案例推理。陳延雪等以醫療領域的突發事件為主體,結合基于規則和基于案例的推理方法構建了醫療應急響應決策支持系統。
隨著知識數量的激增以及復雜程度的不斷加深,傳統知識推理方法表現出了學習能力不足、準確率較低等缺陷,因而基于神經網絡的推理和基于圖的推理很快引起學界的關注。英文醫學知識推理在這方面已有一定的研究積累,相關工作包括利用圖神經網絡預測蛋白質功能,利用卷積神經網絡進行藥物組合預測,判斷患者當前用藥的合理性等。此外,Woensel等研究了如何基于知識圖譜推理出電子病歷中缺失的字段。中文醫學知識推理方面較有代表性的研究有陳德華等將臨床數據的時序特征融入到知識推理中,通過構建基于LSTM 的序列增量學習層,以端到端的方式提取三元組時序特征,實現了對糖尿病時序知識圖譜的鏈接預測,為臨床決策提供更具價值的參考。Gong等提出了一種安全藥物推薦框架,將藥物推薦分解為一個考慮臨床診斷和藥物不良反應的鏈接預測過程,為患者提供最佳的藥物推薦。利用深度學習技術對知識圖譜進行推理計算有利于對知識進行挖掘,以提升知識的利用價值,未來需對深度學習在中文醫學知識推理方面的應用進行深入探索。
通過對知識圖譜構建的關鍵技術進行梳理,可以發現近年來深度學習方法在醫學知識圖譜構建中的使用得到了學者的廣泛研究,其中知識表示和知識抽取方面的相關研究較多,而知識融合和知識推理方面的研究則較為欠缺。就中文醫學知識圖譜而言,突出的問題在于公開的中文醫學標注語料較少,許多學者在研究中仍使用英文數據集或自行構建數據集,這會因標注數據的差異影響技術的泛化,阻礙技術的深入研究。此外,隨著客觀世界知識量的不斷累積以及知識圖譜規模的不斷擴大,實體間的關系也逐漸趨于復雜,如何提升深度學習模型的算力以及精確度仍是醫學知識圖譜走向應用的一大挑戰,因此深度學習在醫學知識融合與推理方面的研究潛力還有待挖掘。
2 醫學知識圖譜構建
通用知識圖譜知識覆蓋范圍廣且數據量大,通常采用自底向上的方式構建,自動化程度較高。醫學知識圖譜屬于領域知識圖譜,構建的關鍵技術與通用知識圖譜存在共性,但構建流程則有所區別。領域知識圖譜構建的流程如圖2所示,其中模式層對后續領域知識的獲取和組織有著重要的指導意義。
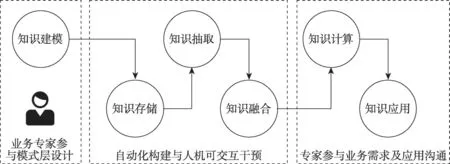
圖2 領域知識圖譜構建流程Fig.2 Construction process of domain knowledge graph
由于醫學領域具有相對完備的知識體系,而且醫學知識具有術語多樣、結構復雜、專業性強且應用場景容錯率低等特點,由醫學專家參與構建的醫學本體對醫學知識圖譜模式層的構建極具參考價值,也對醫學知識圖譜的快速發展起到了很大的促進作用。本文將從醫學本體構建、全科醫學知識圖譜構建和單病種醫學知識圖譜構建三個角度對中文醫學知識圖譜構建的相關工作進行總結。
2.1 醫學本體構建
本體這一概念最早來源于哲學領域,后在知識工程領域作為知識組織的一種形式被廣泛使用。本體指利用基本術語表達領域知識,確定領域內共同認可的概念和概念間的關系,以用于領域內不同主體之間的交流與知識共享的形式化規范說明。目前本體采用國際通用的形式化語言OWL 來規范描述領域的概念及其語義關系,使得這些知識可被人機共同理解,從而解決了人機之間、機器之間信息傳遞和交流的障礙。本體作為一種重要的知識組織方法,為醫學領域的知識圖譜構建工作提供了堅實基礎,生物醫學領域也一直處于本體研究的前列。國外成熟的醫學本體包括SNOMED-CT、基因本體(gene ontology,GO)、疾病本體(disease ontology,DO)和人類表型本體(human phenotype ontology,HPO)等。近年來,仍有不少學者在進行這些權威本體的改良細化研究,也有學者通過參考或復用它們來構建專科疾病本體,如Shepherd等基于SNOMED-CT 構建了一個本體并將其作為邊界對象,以解決照顧慢性病患者的多學科衛生保健小組成員之間的語義互操作鴻溝。國內也有學者對醫學本體構建進行了積極的探索。牟冬梅等基于SNOMED-CT 和形式概念分析構建了甲狀腺疾病本體,并利用該本體對電子病歷進行標注,驗證了其有用性。李曉瑛等復用了UMLS 和SNOMED-CT 中的語義關系,并結合從文獻中獲取的疾病與藥物之間的治療關系,構建了呼吸系統腫瘤本體。任慧玲等構建了中醫疾病本體,并完成了與ICD-11 中文版的語義映射,為中醫疾病分類統計的規范化和標準化奠定了基礎。
由于國內還尚未形成權威的醫學術語標準,目前學者大多參考UMLS、SNOMED-CT 以及MeSH(medical subject headings)詞表等國際權威術語構建中文醫學本體。近年來,國內也有機構致力于中文醫學術語標準化的研究并取得了一定成效,如開放醫療與健康聯盟(open medical and healthcare alliance,OMAHA)于2019 年在HiTA 知識服務平臺上發布了“七巧板”醫學術語集;中國醫學科學院醫學信息研究所于2020 年在BioPortal 平臺公開了他們的研究成果——精準醫學本體(precision medicine ontology,PMO),這都為中文醫學領域知識圖譜的構建工作提供了極富價值的參考。
2.2 全科醫學知識圖譜構建
全科醫學知識圖譜旨在搜集各類醫學知識,通常包含大量的疾病、癥狀、檢查、治療、用藥等多方面的實體及語義關系,通過對這些數據進行分析和整合構建成知識圖譜,為醫學領域的智能化發展提供幫助。
開放資源是早期全科醫學知識圖譜構建的主要數據來源,Lin等以公共醫療網站上爬取的數據和醫院的電子臨床數據為數據源,搭建了MED-Ledge系統,該系統可對醫學數據進行有效的處理和分析,并繪制成知識圖譜以支持各種真實的醫療保健應用。劉燕等和魏自強等以垂直性醫療網站中的醫學知識為數據基礎構建了醫療知識圖譜,并對其應用進行了探討。此外,Shi等還利用某城市衛生信息系統中的醫療服務數據構建了一個語義健康知識圖譜,以便從這些離散的醫療文本數據中挖掘有價值的信息,使醫療信息系統中積累的數據得以充分利用。近年來,不斷積累的電子病歷數據也引起了學界的廣泛關注,其中有些學者就利用電子病歷構建了知識圖譜,為臨床決策提供支持。聶莉莉等還以權威的醫學文獻和書籍為數據源,在醫學專家的幫助下梳理了呼吸系統常見疾病及其癥狀之間的關系,以“疾病-癥候-特征”為模型構建了呼吸系統醫療診斷知識圖譜。阮彤等利用上海曙光醫院已有的中醫臨床知識庫作為數據基礎,利用文本信息抽取和關系數據轉換(database to RDF,D2R)等信息技術,通過領域專家構建的模式層將疾病庫、癥狀庫、中草藥庫和方劑庫進行了融合,構建了一個中醫藥知識圖譜。
全科醫學知識圖譜的構建是醫學數據向知識化轉變的重要嘗試,不同渠道的醫學信息的積累也使得全科醫學知識圖譜的規模不斷擴大。目前,中文全科醫學知識圖譜相關研究已有一定的積累,但如何提升數據的質量以滿足醫學具體應用場景的需求仍是亟待解決的關鍵問題。
2.3 單病種醫學知識圖譜構建
由于醫學應用場景對知識精確度要求較高,全科醫學知識圖譜在數據精度方面的缺陷導致了其應用的局限性。近年來許多學者展開了對單病種醫學知識圖譜構建的研究。單病種醫學知識圖譜往往以某一疾病為核心節點,通過梳理該疾病的臨床指南構建某疾病的知識模型,再結合一系列技術手段完成知識圖譜的構建。
目前單病種知識圖譜涉及的疾病種類已經非常豐富,如Weng等提出一種基于語義分析的醫學知識圖譜自動構建框架,并基于此框架利用886 例高血壓患者病歷構建了高血壓知識圖譜。糖尿病知識圖譜的構建也有學者進行了研究。精神疾病方面,Huang等依據UMLS 的概念層級和醫學術語對從科研文獻、臨床指南、維基百科和電子病歷中獲取的抑郁癥相關數據進行了整合,構建了抑郁癥知識圖譜,并開發了相應的系統對圖譜進行管理和更新。馬歡歡則基于癲癇患者的電子病歷構建了癲癇知識圖譜。此外,還有Chai利用某三甲醫院的甲狀腺疾病患者的電子病歷,結合醫院已有的知識庫進行甲狀腺疾病相關實體和關系的抽取,構建了甲狀腺疾病知識圖譜,并采用樣例數據測試了其輔助診斷的可用性。Fang等從電子病歷和醫學網站(尋醫問藥網、百度百科和春雨醫生)中抽取了垂體腺瘤相關信息,在臨床專家的幫助下構建了垂體腺瘤知識圖譜,為臨床決策提供支持。另外,慢性腎臟病、心血管疾病以及近年突發的新冠肺炎,均有學者在其知識圖譜構建及應用方面進行了研究。然而中文的單病種醫學知識圖譜大多針對較常見的疾病,國外已經有學者對罕見病知識圖譜的構建與應用展開了研究,這也是中文醫學知識圖譜未來值得研究的方向。
近年來,中文醫學知識圖譜構建的研究成果不斷增加并呈現以下特點:一是圖譜構建的數據來源趨于多樣化,包括科研文獻、臨床指南、醫療百科、電子病歷等;二是圖譜類型從全科醫學知識圖譜發展到單病種醫學知識圖譜,且涉及的疾病種類日益豐富,在應用層面也取得了較好的成果。然而中文醫學知識圖譜的研究仍存在一些難點和挑戰。首先,醫學本體對醫學知識圖譜的構建具有重要的指導意義,然而目前國內尚未形成權威的中文醫學術語,不同研究采用的知識結構并不統一,這阻礙了現有醫學知識圖譜的融合,不利于研究的深入。其次,現有的中文單病種醫學知識圖譜大多針對常見病和多發病,如何利用知識圖譜輔助罕見病的診斷和治療也是未來亟待解決的問題。
3 醫學知識圖譜應用
通用知識圖譜的應用方向在醫學領域大都適用,但醫學知識圖譜也因醫學領域的不同業務而延伸出了更廣泛的應用場景,本文將對醫學知識圖譜在語義搜索、決策支持、智能問答及其他方面的應用進行分析。
3.1 語義搜索
Google 提出知識圖譜時就是用于優化搜索引擎的檢索質量,通過語義關系分析為用戶匹配更精確的檢索結果,并將結果結構化地展示給用戶。
在醫學領域也有許多專用的搜索引擎,美國的在線健康網站Healthline 就是一個基于知識庫的醫學信息搜索引擎,用戶可以利用疾病名稱、癥狀名稱、藥物名稱和治療手段等字段進行檢索,還可以查詢當地的醫院和醫生信息等,涵蓋的醫學信息非常全面。國內主流的醫學搜索引擎有搜狗明醫、尋醫問藥網、春雨醫生、醫脈通等,還有一些客戶端產品,如騰訊醫典、科大訊飛與學習強國聯合推出的訊飛健康平臺等,這些平臺都在使用知識圖譜相關技術來優化其語義搜索功能。
中文醫學知識圖譜在語義搜索方面的應用也有一些代表性的研究:其一為于彤等開發的一個大型語義搜索平臺TCMSearch,該平臺融入了語義視圖和基于領域本體的語義索引,可以為領域專家提供更智能的信息檢索服務;另外一項則是中國中醫科學院的賈李蓉等開發的中醫藥學語言系統,該系統中也使用了包含12 萬余個概念、60 萬余個術語以及127 萬余個語義關系的中醫藥知識圖譜,通過在檢索系統中嵌入“知識卡片”以及一個“知識地圖”展示系統,將中醫領域的概念進行可視化展示。近年來,有學者在搜索的基礎上進行了擴展研究。Wang等開發了一個基于知識的醫學信息檢索系統,不僅從UMLS 中提取信息作為背景知識庫以優化搜索結果,還對該系統在醫學臨床決策和個性推薦等方面的應用進行了研究。劉崇從尋醫問藥網和39 健康網等網站采集數據構建了醫學知識圖譜,并開發了醫療知識搜索系統。該系統可借助知識圖譜理解用戶的意圖,以更直觀、精確的方式返回用戶所需的醫療知識,還能向用戶推薦相關的社區問答鏈接供用戶查閱。
3.2 決策支持
知識圖譜可以實現對各類醫學知識的關聯與整合,通過一定規則的邏輯推理從已有的知識中得出一些新的結論,為用戶制定決策提供支持。目前醫學知識圖譜在臨床診療決策支持、藥物研發決策支持和應急響應決策支持方面均有應用。
國外醫學知識圖譜早期在臨床診療決策支持方面的應用較多,近年來的研究集中在了藥物研發方面,如利用知識圖譜實現藥物重定位或揭示藥物之間的相互作用,為藥物研發提供決策支持。此外,Gentile等利用藥物說明書構建了知識圖譜,通過對藥物說明書進行解析并與知識圖譜進行匹配,能快速識別并標注出新版說明書中變更的字段,為藥物審查人員提供決策支持,提升審查效率。
中文醫學知識圖譜的應用主要還是集中在臨床診療決策支持上,如王昊奮等將其構建的醫學知識圖譜應用于上海林康醫療信息技術有限公司的醫療質量與患者安全輔助監控系統中,檢測抗生素的不合理使用情況。Zhao開發了一個臨床決策支持系統,該系統可以持續監測患者的生命體征參數,并在幾個級別上計算風險分級,結合知識圖譜識別患者存在的風險,以便醫護人員及時做出干預。除了此類面向醫護人員的決策支持研究,也有學者在其研究中考慮了患者的需求。武家偉等利用互聯網開放數據構建了“疾病-癥狀”知識圖譜,并融合深度學習技術設計實現了問診推薦系統,在患者查詢疾病相關問題時可以為其推薦合適的醫生和醫院,以便患者做進一步的診斷和治療。
此外,中文醫學知識圖譜在醫療突發事件應急響應方面的應用也有研究。根據醫療突發事件知識圖譜可以推理實際救援的資源調配方案,輔助應急決策者做出更高效的決策措施。
3.3 智能問答
智能問答系統可以通過自然語言處理技術理解用戶的提問,從海量數據中查詢用戶所需的答案并反饋給用戶。基于醫學知識圖譜開發智能問答系統可以幫助患者實現自查自診,緩解醫護人員人手不足的壓力。
Watson 機器人是最早在醫學領域應用的智能問答平臺,而后諸多學者開始對醫學智能問答系統展開研究。鄭懿鳴等構建了中醫藥知識圖譜,并基于自然語言處理技術開發了智能問答系統,然而該系統僅針對疾病和癥狀提供用藥推薦,問答類型過于單一。王繼偉等在其開發的智能問答系統中使用了基于共享層的卷積神經網絡與詞頻-逆文本頻率(term frequency-inverse document frequency,TF-IDF)結合的混合算法,以保證系統能準確地獲取用戶輸入的問句類型并匹配最接近的模板,從而實現更豐富的問答交互。此外,針對單病種的智能問答系統也有學者研究,如田迎等從抑郁癥論文摘要中抽取其知識三元組,構建了抑郁癥知識圖譜,并采用模板匹配的方法開發了抑郁癥智能問答系統。在新冠肺炎持續肆虐的當下,也有學者開發了新冠肺炎智能問答系統,既有助于民眾獲取最新疫情信息以避免恐慌,也能幫助疫情防控相關部門的咨詢人員緩解壓力。
除以上應用場景之外,Gopez等還基于醫保政策構建了知識圖譜,用于輔助醫保審查,減少醫保欺詐事件的發生。黃智生等還將知識圖譜用于微博平臺進行自殺監控預警。也有學者對臨床指南的圖譜化表示進行了嘗試。
4 總結與展望
醫學知識圖譜的研究將不斷推進海量醫學數據的智能化處理,推動醫學智能化的腳步。本文通過對醫學知識圖譜的關鍵技術、構建及應用進行分析,發現中文醫學知識圖譜的研究存在醫學術語標準化程度不高、標注語料缺乏、技術研究不夠深入以及應用場景有局限性等問題,現對中文醫學知識圖譜未來的研究方向做出以下展望。
(1)中文醫學術語的標準化問題需進一步研究。標準的醫學術語不僅能從模式層上指導醫學知識圖譜的構建,還能促進現有醫學知識圖譜的融合,以實現醫學知識的互聯互通,這對中文醫學知識圖譜的研究和應用有著重要意義。其次,中文醫學標注語料的研究及共享將成為新的發展方向。醫學領域語料標注需要耗費大量的人力、物力,而醫學知識圖譜的研究又依賴高質量的標注語料。在保證數據質量的前提下,未來學界和業界應該更注重中文醫學標注語料的研究和共享,以減少研究成本,提升研究效率。
(2)人工智能技術在醫學知識圖譜構建中的應用需更加深入,特別是加強深度學習在中文醫學知識融合和知識推理方面的研究,通過提升模型的性能及泛化能力,形成中文醫學知識圖譜構建的技術體系或通用平臺,以滿足更多研究工作的需要。此外,在知識表示和知識抽取方面,不同語種在語言結構和表達上的差異理論上會對深度學習模型的效果造成一定的影響,未來可以從語言學的角度對中文特征進行深入分析,探索針對中文醫學知識表示和抽取的新技術。
(3)中文醫學知識圖譜未來需要探索更廣闊的應用前景。隨著互聯網中醫學數據的不斷積累,醫學知識圖譜的可用價值已經遠遠超出了疾病知識的查詢和輔助診斷,藥物研發、臨床指南的圖譜化以及突發公共衛生事件的應對等都將是未來醫學知識圖譜值得探索的應用場景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
