編碼-解碼技術的圖像標題生成方法研究綜述
2022-10-16 05:50:42耿耀港梅紅巖張興李曉會
計算機與生活 2022年10期
耿耀港,梅紅巖,張興,李曉會
遼寧工業大學 電子與信息工程學院,遼寧 錦州121000
隨著多媒體技術和計算機網絡的快速發展,數據的多模態性日顯突出,數據量爆發式增長,學術界和企業界對多模態數據處理的需求也日益迫切。另一方面,深度學習技術的日益成熟,給處理多模態數據提供了強有力的技術支持。
圖像標題生成任務由Farhadi 等人在2010 年提出,其任務是通過模型實現從圖像模態到文本模態的模態轉換,具體化表示為二元組(,),模型完成圖像模態(image)到文本模態(sentence)的模態轉換。圖像標題生成任務是計算機視覺領域(computer vision,CV)和自然語言處理領域(natural language processing,NLP)的交叉任務。這項任務對有一定生活經驗的人類來說非常簡單,但是對于計算機來說卻有著巨大的挑戰性,這不僅要求計算機能夠理解圖像的內容,而且還要求計算機能夠生成符合人類語言習慣的句子。圖像標題生成任務,在圖像理解、人機交互和視覺障礙患者輔助和新聞等領域有著重要的作用,由于任務的重要性和挑戰性,逐漸成為人工智能領域研究的一個重要方面,越來越多的研究者們投身到了這個領域的研究,提出了一系列效果顯著的算法和模型框架。
從Farhadi 等人提出的基于模板的方法,到Kuznetsova 等人提出的基于檢索的方法,再到現在主流的基于編碼-解碼的方法,圖像標題生成技術不斷革新,圖像標題的質量也越來越高。目前基于編碼-解碼的圖像標題生成方法在圖像生成質量和模型性能方面取得了較好的效果,備受關注。本文基于編碼-解碼圖像標題生成方法整體流程,分別從圖像理解和標題生成兩方面對該方法的研究進展進行了相關的研究與闡述。
1 圖像標題生成方法概述
目前圖像標題生成領域中主要有三種圖像標題生成方法,分別是基于模板的方法、基于檢索的方法和基于編碼-解碼的方法。本章簡要介紹三種方法的代表工作和各自的優缺點。
1.1 基于模板的方法
基于模板的方法(template-based method)是一種依賴人工設計語言模板和目標檢測技術的圖像標題生成方法。首先由人工設計語言模板,然后通過目標檢測技術檢測圖像中的對象、對象屬性、對象之間的相互關系等信息;最后使用這些信息將模板填充完整,生成圖像標題,其代表性研究是Farhadi 等人在2010 年提出的基于模板的圖像標題生成方法和模型。該模型首先按照語法規范人工設定句型模板和<對象,動作,場景>三元組,然后使用計算機視覺中目標檢測的方法檢測圖像中的場景、對象、對象的屬性及動作所有可能的值,并使用條件隨機場算法(conditional random field,CRF)預測正確的三元組填入模板,組成標題的基本結構;最后使用相關算法填充模板中的其他部分,生成圖像標題,其流程如圖1所示。Kulkarni 等人在此基礎上提出了Baby talk 模型。該模型通過目標檢測技術,檢測多組對象及其相關信息,使用分類器對其分類。然后使用CRF 對三元組的值進行預測,最后填充模板,生成完整的標題。該模型中使用了更多的對象及其相關信息驅動標題的生成,為此獲得了更為詳細、質量更好的圖像標題。

圖1 基于模板的方法流程Fig.1 Template-based method flow
基于模板的方法的優點是生成的標題符合語法規范,但該方法需要人工設計句法模板,依賴于硬解碼的視覺概念,受到圖像檢測質量、句法模板數量等條件的限制,且該方法生成的標題、語法形式單一,標題的多樣性不足。
1.2 基于檢索的方法
基于檢索的方法是一種依賴大型圖像數據庫和檢索方法的圖像標題生成方法。該方法首先檢索數據庫中與給定圖像相似度高的圖像作為候選圖像集,從候選圖像集中選取最相似的幾個圖像,利用它們的圖像標題,組合成給定圖像的標題,其代表性研究是Kuznetsova 等人在2012 年提出的基于檢索方法的圖像標題生成模型。該模型由整體的數據驅動生成圖像標題,基于輸入圖像,在數據庫中檢索相似圖像以及描述該圖像的人工合成短語,然后有選擇地將這些短語組合起來,生成圖像標題,其示意圖如圖2 所示。Ordonez 等人基于對圖像數據庫規模的擴充和相似度計算方法的改進對該模型進行了優化。數據庫包括從網絡上收集的100 萬張帶有標題的圖片。該模型獲取到輸入圖像后,在數據庫中檢索相似的圖像作為候選,通過目標檢測技術檢測候選圖像中的對象、動作、場景和TF-IDF(term frequencyinverse document frequency)權重,計算候選圖像與輸入圖像的相似度,取相似度前四的圖像標題組合成輸入圖像的標題。在一定程度上提高了標題質量。

圖2 基于檢索的方法流程Fig.2 Retrieval-based method flow
基于檢索的方法是由現有的圖像標題驅動生成新的圖像標題,對輸入圖像與數據庫圖像的相似度有較強的依賴性,即若給定的圖片與數據庫中的圖像相似度高,生成的圖像標題質量就高;若相似度低,結果就不盡人意,且圖像標題的形式也受到數據庫中標題形式的限制,不會產生數據庫以外的單詞,標題生成局限性較大。
1.3 基于編碼-解碼的方法
基于編碼-解碼的方法是一種依賴深度學習技術的圖像標題生成方法。該方法使用兩組神經網絡分別作為編碼器和解碼器。編碼過程是使用編碼器提取圖像的特征,解碼過程是對圖像的特征進行解碼,按照時間順序生成單詞,最終組合成圖像標題。其代表性工作源于Cho 等人在2014 年提出的解決機器翻譯(machine translation,MT)任務的編碼器-解碼器模型,該模型使用兩個遞歸神經網絡(recursive neural network,RNN)分別作為編碼器和解碼器,模型使用編碼器對源語言進行編碼,再使用解碼器解碼成目標語言,該模型在機器翻譯任務中取得了令人鼓舞的效果。2015年,Vinyals等人將編碼-解碼的思想引入圖像標題生成領域中,提出NIC(neural image caption)模型。該模型采用卷積神經網絡(convolutional neural network,CNN)作為編碼器,長短期記憶網絡(long short-term memory networks,LSTM)作為解碼器。模型獲取到輸入圖像后,首先使用CNN提取圖像的全局特征,使用圖像的全局特征初始化解碼器,然后解碼器按時刻生成單詞,最終組合成圖像標題,其流程如圖3 所示。~S代表圖像標題中的單詞,和S為標題的開始標志和結束標志,代表生成單詞的概率。
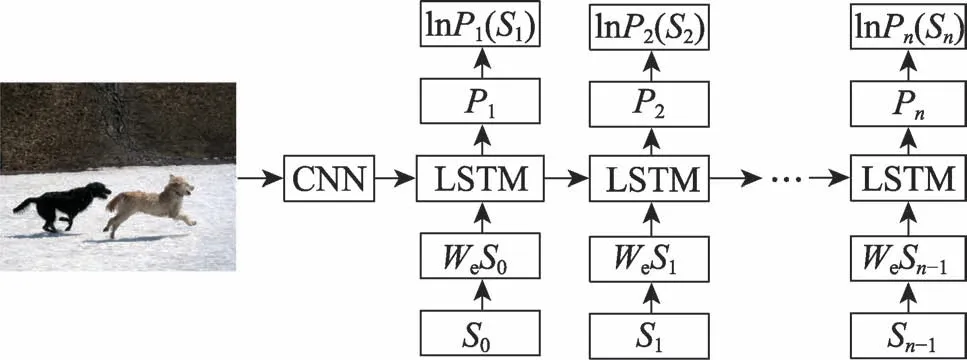
圖3 基于編碼-解碼方法流程Fig.3 Method flow based on encode-decode
基于編碼-解碼的方法擺脫了對模板和數據庫的依賴,生成的標題具有前兩種方法不具有的高靈活性、高質量和高擴展性。但該種方法依然存在一些問題需要深入研究,如視覺特征的提取問題、語義鴻溝問題、模型復雜度高等問題。
圖像標題生成方法均有其各自的優缺點,其中基于編碼-解碼的方法憑借其生成標題不受模板和數據庫容量限制,具有高多樣性、高靈活性等優點,目前已經成為圖像標題生成領域的主流生成方法。針對基于編碼-解碼方法的研究也不斷深入,本文將在第2 章深入介紹基于編碼-解碼的圖像標題生成方法的研究現狀。
2 基于編碼-解碼的圖像標題生成方法研究現狀
隨著深度學習技術的快速發展和針對圖像標題生成任務研究的不斷深入,研究者們提出了一系列優秀的模型和算法。本章按照圖像標題生成流程將這些模型和算法分類為圖像理解階段的研究和標題生成階段的研究,闡述相關研究的思路、優勢以及存在的問題。本章采用NIC 模型作為基線進行對比。
2.1 圖像理解階段的研究
圖像理解階段工作為完成對圖像內容的理解,提取圖像特征。作為本節的基線,NIC 模型在圖像理解階段存在以下兩個主要缺陷:
(1)模型直接使用圖像的全局特征指導解碼器生成標題,因此模型沒有關注圖像重點區域的能力。
(2)圖像的全局特征中只含有圖像的高層語義,其感受野較大,對圖像中對象的位置和相互關系感知能力較差,不足以支撐模型生成高質量的標題。
根據解決這兩個問題的方法,本文將相關研究分類為注意力機制的研究和語義獲取的研究。
注意力機制在機器翻譯領域廣泛應用的背景下,研究者們針對模型生成標題關注不到圖像重點的問題,提出使用注意力機制解決此問題。2015 年,Xu 等人首次將注意力機制應用到圖像標題生成領域,提出基于注意力機制的圖像標題生成模型,其中包括基于“軟”注意力機制(soft attention)的模型和基于“硬”注意力機制(hard attention)的模型。“軟”注意力每次解碼會將權重分配到所有區域,權重取值在0 到1 之間,采用后向傳播進行訓練。“硬”注意力機制每次解碼只關注圖中的一個區域,采用one-hot 編碼,花費時間較少,但是不可微分,一般采用蒙特卡洛采樣方法先對梯度進行估計,然后進行后向傳播訓練。目前圖像標題生成領域常用的注意力機制,以“軟”注意力機制為主。注意力機制模型將CNN 提取的圖像特征由全局特征優化為區域特征。模型在生成單詞之前都會通過注意力機制計算要生成的單詞與圖像中各區域的相關度,選取相關度高的區域的區域特征,傳入解碼器,指導解碼器生成圖像標題。注意力機制的引入使圖像標題生成模型有了關注重點區域的能力。但這種注意力機制會將單詞與去向區域強制對應,像“of”“the”這種虛詞也會強制對應圖像中的區域造成算力浪費。因此,Lu等人提出一種自適應注意力機制。該注意力機制引入“視覺前哨(visual sentinel)”向量,此向量表示生成單詞與視覺信息的相關性取值在0 和1 之間,當單詞與圖像直接相關時,取值為1,模型會關注圖像的區域并生成單詞。當生成“of”“the”這種與圖像相關性低的單詞時,則直接通過語言模型推測。該模型解決了虛詞強制對應圖像區域的問題,并且有良好的泛化性,改善了原有的注意力機制的算力浪費的問題。Huang 等人提出了一種AOA(attention on attention)模塊。AOA 是針對注意力機制設計的一種擴展模塊,AOA 能夠更加精確地計算向量和注意力查詢的相關性,避免了即使無關也產生加權平均值的問題。該模塊相當靈活,可以對任何模型和任何注意力機制進行擴展。
傳統模型采用CNN 的高層卷積層提取的圖像特征作為輸出,這種特征圖丟失了很多圖像信息并且較大的感受野會影響注意力機制的性能。于是研究者們提出使用注意力機制融合高層特征圖中的高級特征與低級特征圖中的低級特征。Chen 等人提出空間和通道注意力機制模型(spatial and channel-wise attention,SCA),融合了通道注意力機制和空間注意力機制的SCA 可以同時關注多層的圖像特征圖,即在使用低層特征圖保留的圖像信息的同時關注高層特征圖提取的圖像的高層語義,避免了傳統注意力機制使用高層空間特征圖造成的空間信息丟失和注意力機制功能受限的問題。Ding 等人模仿人類視覺系統的感官刺激理論,提出自底向上的注意力機制算法,對圖像區域的低級特征,如對比度、銳度、清晰度,高級特征,如人臉影響進行評分,并將評分進行綜合,以此來決定注意力應該關注的區域。You 等人則是融合自頂向下和自底向上方法。該模型獲取到圖片后,通過CNN 獲取其視覺特征,同時檢測圖像中的視覺概念,如對象、區域、屬性等。然后通過一個語義注意力模塊將圖片的視覺特征和視覺概念融合,并使用LSTM 生成單詞。該模型能夠處理圖像中語義上重要的概念或感興趣的區域,加權多個概念所關注的相對強度和根據任務狀態動態地在概念之間切換注意力。以上幾項研究,選擇使用注意力機制算法融合高級特征和低級特征的方式,彌補了只使用高級特征造成的信息丟失,獲取了更多的圖像信息。其中,文獻[10]直接使用完整圖像的特征圖作為圖像的高級特征,文獻[10-11]則是使用Faster RCNN(faster region convolutional neural network)檢測后的區域特征作為高級特征。這兩種方式在圖像方面都有一定的局限性,文獻[10]使用整張圖像的特征,提取的為圖像的粗粒度語義。文獻[11-12]提取的則是區域級的細粒度語義,會造成一定的區域外的語義丟失問題。而這一問題,也是未來需要研究的問題。
語義作為計算機視覺和自然語言處理領域的常見概念,其對于圖像標題生成領域也是及其重要的。圖像理解階段其實就是獲取的圖像特征和語義的過程,這個階段獲取的圖像特征和語義越多,解碼器生成標題時獲得的指導也就更多,而NIC 模型的全局圖像特征對對象屬性、位置和相互關系等語義反映不足。圖像標題生成模型中語義獲取方面的問題,研究者們也進行了相應的探索。
Wu 等人首先對圖像標題生成任務中是否需要圖像的高級概念(對象屬性)進行了探究,方法是CNN和LSTM 之間加入了一層屬性預測層,構成基于屬性的卷積神經網絡(attribute convolutional neural network,att-CNN)模型。該模型是一種基于屬性的神經網絡模型,att-CNN 模型中的編碼器在提取了圖像特征后,對圖像中的對象屬性進行預測,獲取圖像的高級概念,將其構造成向量,并指導LSTM 生成圖像標題。經過實驗對比發現,模型獲取了圖像的高級概念之后,模型在標準數據集和評價指標下的評分均顯著高于以NIC 模型為代表的傳統編碼器-解碼器模型。證明了圖像標題生成模型中圖像高層語義的必要性和重要性。在此基礎上,Yao 等人探究了五種不同的將圖像特征和語義注入LSTM 的方式,分別是:(1)只注入語義特征;(2)先注入圖像特征再注入語義特征;(3)先注入語義特征再注入圖像特征;(4)先注入語義特征,將圖像特征伴隨詞嵌入注入;(5)先注入圖像特征,將語義特征伴隨詞嵌入注入。最終得出結論第五種方式是五種方式中語義特征和圖像特征結合最好的方式。文獻[13-14]為圖像標題生成領域語義獲取方面的研究奠定了基礎,文獻[13]證明了模型需要圖像的對象屬性指導標題生成。而文獻[14]則是對語義注入解碼器的最優方式進行了探究。不同于將編碼器優化為屬性預測器,Tanti等人在獲取語義方面采取了雙編碼器策略。一個CNN 提取圖像特征,一個RNN 提取標題特征,特征融合后輸入前饋神經網絡,生成標題。該模型同時對圖像和標題進行特征提取,獲取圖像特征及圖像語義,指導模型生成標題。該方法優點是更加適合遷移學習,兩個編碼器都可以進行遷移學習。
自編碼器-解碼器模型提出以來,由于技術條件所限,對圖像的高層語義提取的研究進展較為緩慢。直到Kipf 等人提出圖卷積神經網絡(graph convolutional network,GCN)。GCN 在提取圖結構這種非歐式數據的特征時,表現出了極高的性能,而且其在未經過訓練時的性能也保持較高的性能。而圖結構在表達圖像中的語義信息方面有著其他數據結構無法比擬的優勢,其可以表達出圖像中的對象、對象的屬性以及對象間的相互關系這種圖像的高層語義。
2018 年,Yao 等人提出了GCN-LSTM 架構的圖像標題生成模型,首次將GCN 應用到圖像標題生成領域。模型依賴目標檢測技術(如Faster R-CNN)。該模型首先通過目標檢測技術檢測出圖像中的對象、對象屬性和對象之間的關系,然后構造圖結構。使用GCN 提取圖結構的特征,使用該特征指導LSTM生成標題。目前圖卷積神經網絡被廣泛地使用在圖像標題生成模型中。值得一提的是配合圖卷積神經網絡的出現,圖像的特征由原來的直接提取網格級(grid)特征變成了先由目標檢測技術提取圖像的區域級(region)特征。Yao等人提出了層次分析法體系結構(hierarchy parsing,HIP),該結構通過Faster RCNN 和Mask R-CNN(mask region convolutional neural network)技術對圖像進行區域級和實例級分割,將圖像構造成樹結構={,,,,其中代表圖像,代表區域級對象,代表實例級對象,代表樹結構中的關系,然后采用GCN 提取樹結構的特征,將特征傳入Up-to-down 注意力機制進行計算,計算出最相關的幾個對象,通過對象特征指導Tree-LSTM 生成圖像標題。HIP 層次分析法,模型能夠提取到圖像的三級語義,獲取的語義更加豐富,產生的標題質量更高且模型泛化能力較強。但是樹結構在表達圖像中對象的復雜關系時,有一定的局限性。因此,Shi等人提出了一種標題引導的視覺關系圖(captionguided visual relationship graph,CGVRG)的框架。該框架首先通過Faster R-CNN 獲取圖像中的對象,文本場景圖解析器從標題中提取關系三元組。然后將對象和謂語動詞通過弱監督學習對應起來,構造CGVRG。將CGVRG 輸入GCN,通過GCN 提取CGVRG 的特征和上下文向量,該模型使用圖結構的特征和上下文向量指導解碼器生成標題,因此模型具有更好的語義信息。與之類似的,Chen 等人提出了一種ASG2Caption(abstract scene graph to caption),該模型通過一種名為抽象場景圖的有向圖結構驅動模型生成標題。ASG 中包含三種抽象節點,對象節點、屬性節點以及關系節點。模型首先通過目標檢測技術構建ASG,然后使用GCN 對ASG 進行編碼,最后通過ASG 和圖像特征指導解碼器生成標題。以上幾項研究總體上概括了圖卷積神經網絡在圖像標題生成領域應用的現狀。首先使用Faster R-CNN 對圖像進行目標檢測,生成區域級的圖像特征。然后使用區域級的圖像特征和語義,如對象、對象屬性和對象關系等,構造成不同的數據結構(大部分是各種圖結構)。最后將生成的圖結構傳入GCN,通過解碼器生成標題。
圖卷積神經網絡高度依賴目標檢測技術提取的區域級描述特征,這種特征本身存在缺乏上下文信息和細粒度信息的缺點。傳統卷積提取的網格特征不存在這兩種缺點,但語義并不如區域級特征豐富。Luo 等人針對這個問題提出了雙極協同的Transformer 架構,這種架構可以通過注意力機制運算選取并融合兩種級別的特征,并傳入Transformer解碼器中生成圖像標題。該架構生成的標題,具有豐富的細節和語義信息。Li等人則是通過兩個Transformer構成一個Entangle-Transformer 結構,分別對文本和圖像進行特征提取并通過Entangle-Transformer 融合,緩解了語義鴻溝問題。
以上針對圖像理解階段的研究模型的性能表現如表1 所示(實驗數據均源自相關文章,只統計在Karpathy 分割下MSCOCO 數據集上的實驗結果),優勢及缺陷如表2 所示,具體數據集和評測指標相關內容見第3章。由以上研究可以看出,目前在圖像理解階段的研究依然圍繞兩個方面。一方面通過各種技術獲取圖像中更豐富的語義信息,比如將屬性預測器添加進CNN-LSTM,使用各種圖結構表達圖像中的語義信息。另一方面則是獲取到豐富的信息之后,使用各種不同的注意力機制方法,使模型能夠在生成單詞時“關注”到正確且豐富的信息。
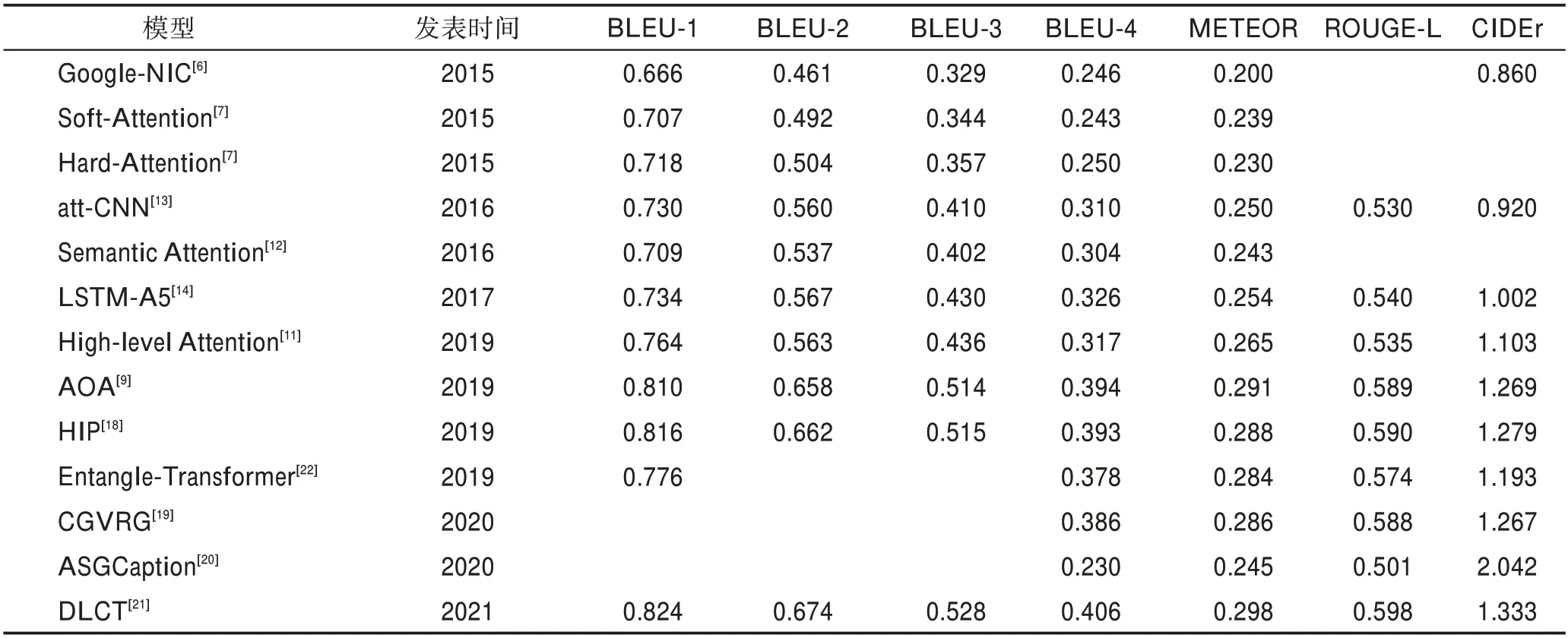
表1 圖像理解模型在MSCOCO 數據集上的性能表現Table 1 Performance of image understanding models on MSCOCO dataset
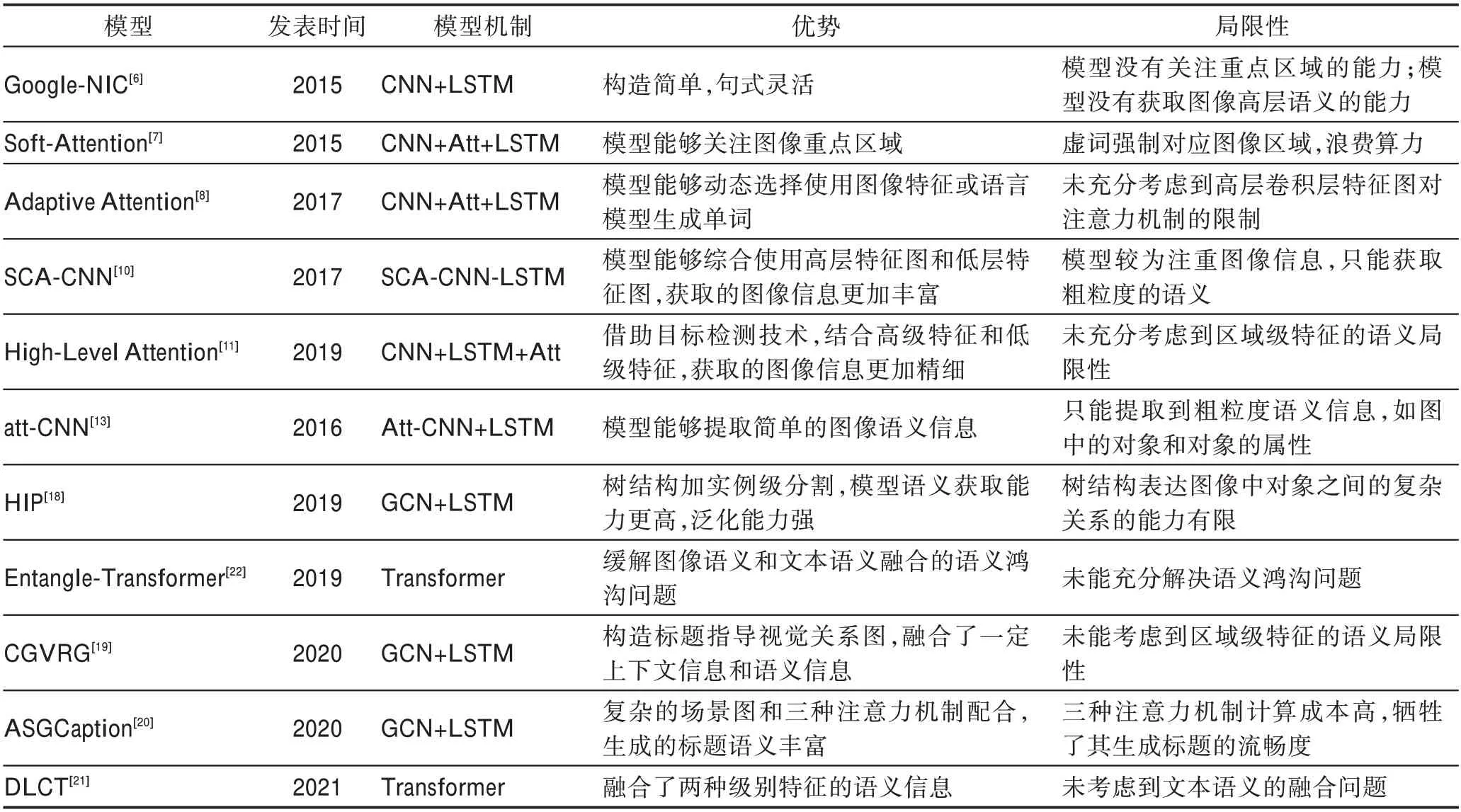
表2 圖像理解模型優勢及局限性Table 2 Advantages and limitations of image understanding models
圖像理解階段的主流編碼器已經完成了從CNN到GCN 的更迭,但正如文獻[21-22],Transformer和BERT及其相關變體模型,也逐步應用到圖像標題生成領域。相對于CNN 對整張圖片進行特征提取,GCN 則是依賴目標檢測技術中的Faster R-CNN 先對圖像進行目標檢測,再提取區域級特征。目前對于GCN 的研究主要集中在構造各種類型的圖結構,表達更多的圖像語義。這方面的研究的確取得了卓越的表現。但其依然存在一些問題值得未來深入研究:一方面,區域級特征和傳統網格特征融合的問題;另一方面,目前的針對圖像理解的研究還是處于割裂的階段,很少能有模型注意到標題中的文本語義對模型的影響。因此,如何融合圖像語義和文本語義也是未來需要深入研究的一個問題。
2.2 標題生成階段的研究
標題生成階段的工作為解碼器根據編碼器提取的圖像特征和語義信息生成圖像標題。解碼器主要采用長短時記憶神經網絡。本節根據生成標題的類型,將近年來針對標題生成階段的研究分為三類:生成傳統標題的研究、生成密集標題的研究和生成個性化標題的研究。
傳統標題作為最常見的標題,多為陳述性句子。按照主謂賓經典結構,再加以適當的修飾,能夠言簡意賅地描述出圖像的核心內容。然而,作為主流解碼器的LSTM 存在明顯的局限性,主要有以下幾點:
(1)LSTM 作為一種序列型語言模型,傾向于預測語料庫中出現頻率高的語料,造成標題多樣性低。
(2)序列模型在逐字預測過程中,對象、對象的屬性和對象的關系的混合會影響訓練的效果。
(3)LSTM 作為循環神經網絡的一種變體,具有高復雜度的遞歸單元,且其固有時間順序,無法并行訓練,訓練成本較高。
因此,針對傳統標題的研究熱點主要是站在語言模型的角度,優化解碼器的結構。目的是生成更流暢、更多樣以及更符合邏輯的句子。2016 年,Wang等人對LSTM 結構進行了調整,提出了雙向深層LSTM,這種模型將LSTM 由單向構造為雙向,并通過堆疊多層LSTM,相較于原始LSTM,雙向深層LSTM能夠更好地表達圖像以及上下文語義。值得一提的是,該模型在未引入注意力機制的情況下,表現出的性能在當時也具有很強的競爭力。但其缺點也很明顯,雙向深層LSTM 具有更高的復雜度,需要更多的訓練時間。
Wang 等人針對序列模型的局限性,提出了組合型LSTM,該組合型LSTM 由一個骨架LSTM 和一個屬性LSTM 組成,使用含有高級語義的圖像特征的骨架LSTM 指導生成句子的基本骨架,然后通過屬性LSTM 生成句子的定語部分,最終組合成句子。Dai等人同樣針對此問題提出了不同的解決方法,模型首先從圖像中提取各種名詞-屬性的短語,組成初始短語池。然后遞歸地使用一個連接模塊將兩個短語組合成一個較長的短語,直到評估模塊確定獲得了一個完整的標題。以上兩種模型都通過組合的思想,改善序列模型的問題,能夠更準確、更具體地生成分布外的圖像標題,因此該模型在SPICE 指標上表現優越,但是犧牲了一定的句子流暢度(BLEU 評分較低)。為了調節序列模型和組合模型的缺陷,Tian等人提出了一種組合神經模塊網絡的序列模型,該模型結合了序列模型和組合模型的優點。該模型首先提出感興趣的區域,根據上下文計算要關注的區域;然后所選區域的區域特征和整個圖像特征被輸入到一組模塊中,其中每個模塊負責預測對象的一個方面,如數量、顏色和大小;最終將這些模塊的結果動態組合,并在多次預測后組合成標題。該模型產生的標題既擁有序列模型產生標題沒有的靈活性,也比組合型模型產生的標題流暢度更高。
為了增強LSTM 長序列依賴性,Ke 等人提出反射解碼網絡(reflective decoding network,RDN),該網絡通過反射注意力模塊(reflective attention module,RAM)和反射位置模塊(reflective position module,RPM)的協作,增強了解碼器的長序列依賴性和位置感知能力,有效地提高了解碼器的長序列建模能力。該網絡生成的圖像標題能關注到“更早”之前生成的單詞,并且具有了聯想的能力,例如模型可以通過圖中的“火車”“鐵軌”推斷出所在的地點為車站。Wang 等人在解碼器上引入了一種召回機制,模仿人類進行圖片描述時會思考過去的經驗的行為,提出了基于召回機制的圖像標題生成模型。召回機制由召回單元(recall unit,RU)、語義指南(semantic guide,SG)和召回詞槽(recalled-word slot,RWS)組成。模型首先通過計算圖像特征和單詞特征映射在同一空間,然后語義指南模塊通過注意力機制計算圖像與召回詞之間的相關度,獲得召回詞權重,選擇召回詞。召回詞槽負責將被召回的單詞復制到標題中。該模型生成的標題更加符合人類語言邏輯,增加了模型的長依賴性。
LSTM 的遞歸性和時序性,造成其高復雜度和無法并行訓練的固有局限。因此,Aneja 等人開創性提出了一種卷積解碼結構,該結構將模型中的解碼器替換成了一組掩碼卷積神經網絡。該網絡通過掩碼的操作能夠完成并行訓練,且沒有任何遞歸單元,節省了模型訓練的時間,且不受梯度消失的影響。Transformer 和BERT 近年來也開始逐漸被應用在標題生成階段,Cornia 等人提出了一種MTransformer(meshed-memory transformer)結構,該體系結構改進了圖像編碼和語言生成步驟:它整合學習到的先驗知識,學習圖像區域之間關系的多層次表示,并在解碼階段使用類似網格的連接來利用低級和高級特征,在降低模型復雜度的同時,緩解了語義鴻溝問題。Hosseinzadeh 等人則是使用Transformer模型完成了描述圖像細微差別的任務,該模型通過與圖像檢索技術相結合,能夠對兩張只有細微差別的圖片進行差別描述。
密集標題(dense caption)是標題生成模型功能的一種擴展。其功能是為所有檢測到的對象生成描述。具體標題形式見圖4。

圖4 密集標題Fig.4 Dense caption
2013 年,Kulkarni 等人在基于模板的模型上進行了密集標題,提出了一個能夠生成密集標題的模型。該模型檢測到圖像中的對象后,對圖像的屬性和關系進行推理,生成一個詳細的描述,然后通過條件隨機場生成具有一定邏輯性的段落。該模型雖然一定程度上完成生成密集的任務,但是由于當時技術限制,以及基于模板方法手動提取特征的缺陷,導致該模型魯棒性較差。
2016 年,Johnson等人首次引入了密集的標題任務概念,即為圖像生成更多條語句,多條語句之間有一定的相關性,能夠更加詳細地描述圖像的內容。其還提出了一個全卷積定位網絡(fully convolutional localization network,FCLN)架構,該架構由一個卷積網絡、一種密集定位層和生成標簽序列的遞歸神經網絡語言模型組成,密集定位層即對圖像分塊定位、分塊描述。密集定位層的加入使得圖像能夠被更精細地描述,生成更加詳細的標題。雖然取得了令人印象深刻的結果,但這種方法沒有考慮到突出的圖像區域之外的上下文。為了解決這個問題,Yang 等人提出了使用Faster R-CNN 進行目標檢測,并提取區域圖像特征后,將整個圖像的特征傳入解碼器中作為上下文使用。而Kim 等人提出使用POS(part of speech)標簽指導生成標題。該模型使用一個多任務三重流網絡預測各個對象的POS,然后使用POS 作為上下文指導標題生成。以上的工作只能針對2D圖像無法捕捉到3D 圖像。Chen 等人使用commodity RGB-D 傳感器的三維掃描密集標題任務。該模型通過三維掃描,能夠更加精準地捕獲對象的定位,以及對象的特征及屬性,使模型能夠完成3D 圖像的密集標題生成任務。
通過以上研究可以看出,針對生成圖像密集標題的任務,研究重心主要集中在對象定位的準確性上,一般來說目標檢測越精準,生成的密集標題質量也越高。
傳統的圖像標題生成模型生成的標題大多數都是陳述性句子,基本不帶有感情色彩。隨著圖像標題生成模型在日常生活中的應用,人們發現了讓生成句子帶有情感的必要性,具體標題形式見圖5。

圖5 個性化標題Fig.5 Stylish caption
Mathews 等人提出了具有開關式RNN 的模型。這種模型實際上是在傳統RNN 上添加了一個“情感門”,“情感門”通過函數來控制生成句子中的積極情感(positive)和消極情感(negative),從而生成帶有情感色彩的文本描述。但是該模型對于積極情感和消極情感的區分過于粗糙,并且無法生成帶有復雜情感的句子。Chen 等人提出了Style-Factual LSTM,通過對抗性訓練的方法來訓練程式化的圖像標題生成模型。該模型可以生成積極、消極、浪漫和幽默風格的標題。以上這兩種方法很大程度上依賴于成對圖像的程式化句子來訓練程式化圖像標題生成模型。
Gan 等人提出一種StyleNet 框架,該框架使用未配對的程式化語料庫生成具有浪漫、幽默風格的圖像標題。該框架中使用了一種可以自動提取文本語料庫中的樣式風格的Factored-LSTM,可以通過對圖像數據集和帶有風格的文本數據集的聯合訓練,生成帶有風格的標題。張凱等人提出了一種雙解碼器的雙語圖像標題生成模型,該模型使用雙解碼器,對同一圖像生成兩種語言的標題,這種方法雖然有效地利用了兩門語言特征,但是由于不同語種的語序有所不同,兩種語言的聯合方法可能存在融合噪聲的問題。Chen 等人提出了一種可控的時尚圖像描述生成模型。使用兩種訓練集和兩種編碼器——傳統訓練集(源訓練集)和帶有目標風格的文本訓練集(目標訓練集),傳統編碼器CNN 和文本編碼器(skip-thought vectors,STV),通過對兩種數據集的聯合訓練,可以生成帶有寫作風格的圖像標題,句子的靈活性有了極大的提高。Zhao 等人提出了一種新的程式化圖像字幕方法MemCap。MemCap 使用記憶模塊記憶語言風格,并在解碼階段使用注意力機制關注標題和語言風格來生成標題。因此,該方法能夠準確地描述圖像的內容,并適當地反映出圖像所期望的語言風格。另外,該方法能夠同時執行單風格和多風格標題,泛化性強。
以上針對圖像理解階段的研究模型的性能表現如表3所示(實驗數據均源自相關文章,只統計在Karpathy 分割下MSCOCO 數據集上的實驗結果),優勢及缺陷如表4 所示,具體數據集和評測指標相關內容見第3章。由以上研究可以看出,相較于圖像理解階段的圍繞大方面進行研究,標題生成階段的研究更加多樣。傳統標題生成、密集標題生成和個性化標題生成的研究重點各有側重。傳統標題生成較為依賴目標檢測技術,因此其研究重點主要是優化解碼器局限性,提高標題的流暢性、邏輯性、長依賴性等質量指標。密集標題生成的研究主要圍繞著如何對圖像中的對象進行精準定位,獲取更多的對象信息,如位置、屬性和相對關系等。而個性化標題的生成研究焦點則是使用不同風格的語料庫和配對方式,生成不同風格的標題。
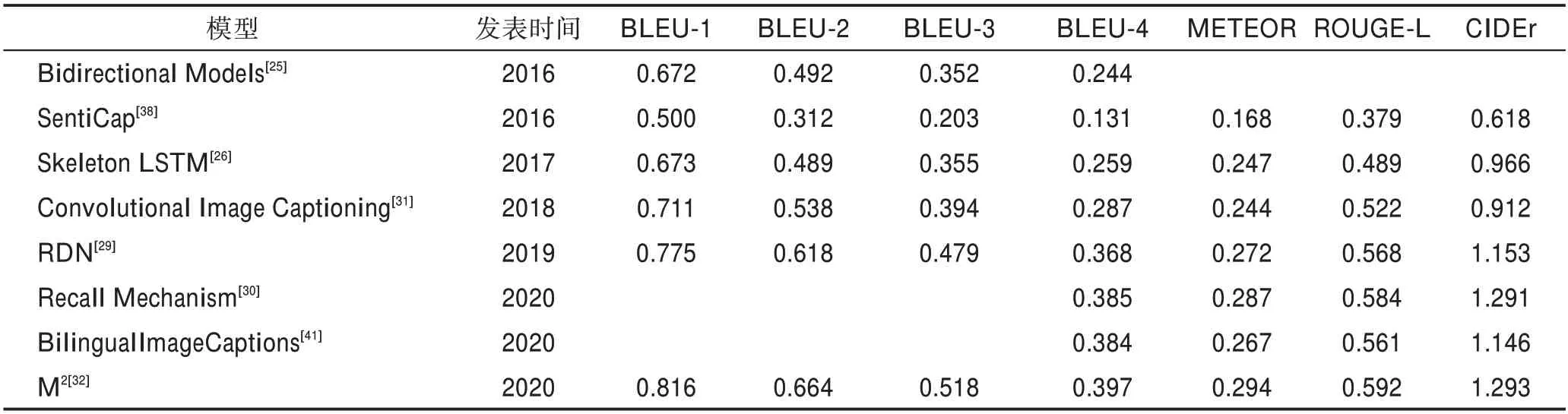
表3 標題生成模型在MSCOCO 數據集上的表現Table 3 Performance of caption generation models on MSCOCO dataset
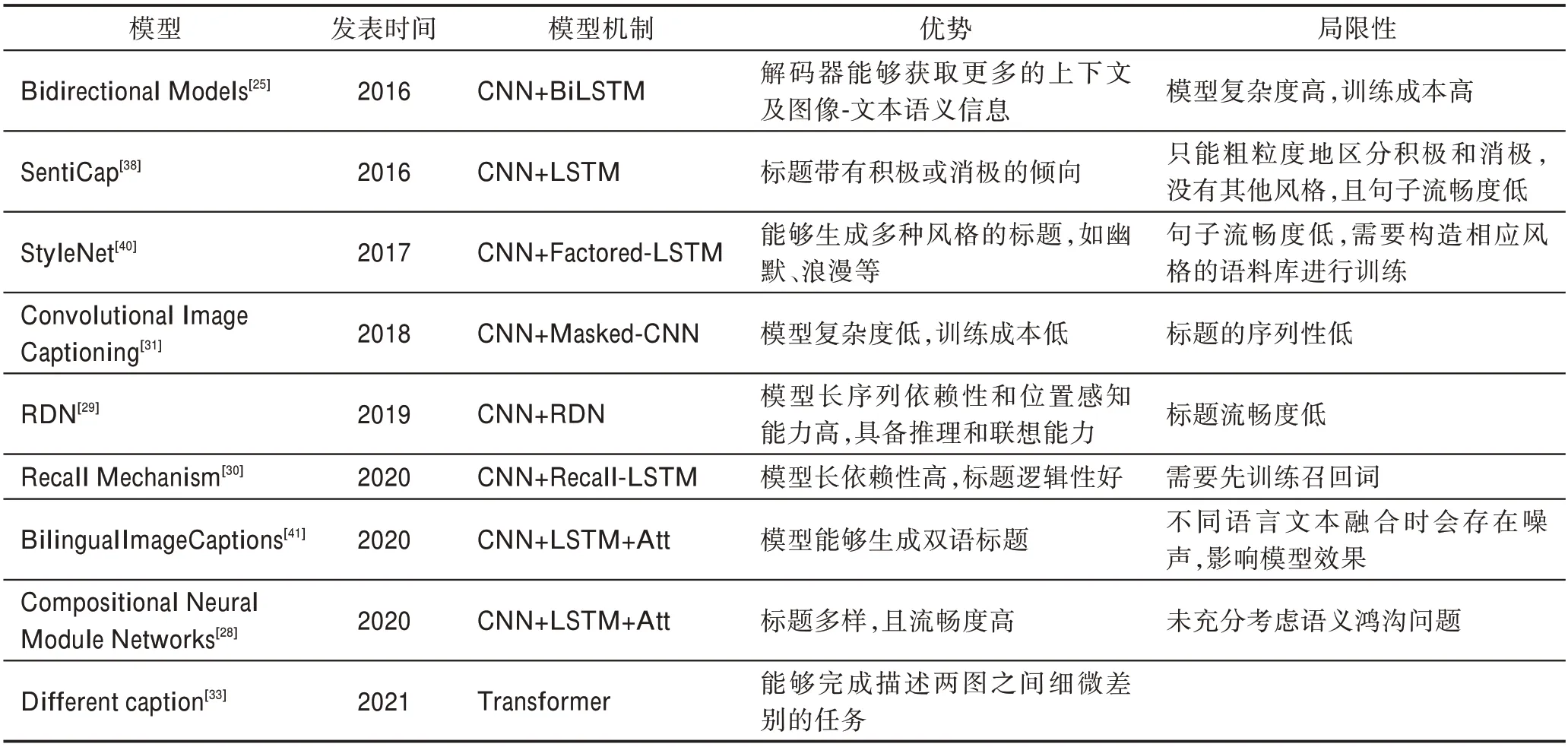
表4 標題生成模型優勢及局限性Table 4 Advantages and limitations of caption generation models
3 圖像標題生成數據集與評測指標
3.1 圖像標題生成數據集
圖像標題生成領域,目前有多個常用的數據集,如MSCOCO、Flickr30K、Flickr8K 等,其信息如表5所示。
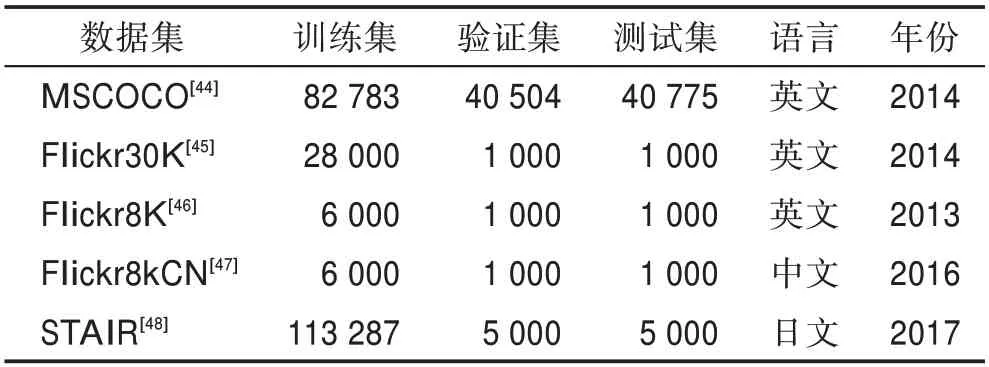
表5 圖像標題生成數據集信息Table 5 Information of image captions generation datasets
(1)MSCOCO 數據集是目前最大的圖像標題生成數據集,適用于各種計算機視覺任務,如目標檢測、圖像分割、圖像標題生成等。在圖像標題部分,包括訓練集82 783 張圖像,驗證集40 504 張圖像。MSCOCO 數據集對圖像標題生成模型和算法具有極高的挑戰性,因為大多數圖像中都包含復雜場景下的多個對象,每張圖像都包括5 個人工標注的圖像標題。模型評估時,一般采用Karpathy 等人的劃分標準,即從驗證集中取出10 000 張圖像,其中5 000 張圖像用于驗證,另外5 000 張用于最終測試。由于MSCOCO 數據集的專業性及挑戰性,MSCOCO 數據集目前是圖像標題生成領域的主流評測標準數據集,各種模型和方法在該數據集上的評分是評價模型和算法性能的重要指標。
(2)Flickr30K 數據集由Young 等人提出,其數據量相對較小,包括31 783 張日常活動、事件和場景的照片,每張圖像對應5 條人工標注的描述句子。在線評估是采用Karpathy 等人的劃分標準,取其中29 000 張圖像及其標題作為訓練集,1 000 張圖像及其標題作為驗證集,其余樣本作為測試集。Flickr30K也是圖像標題生成領域的一個重要評測標準數據集,一般和MSCOCO 數據集一起評測模型和算法的性能,作為MSCOCO 的補充。
(3)Flickr8K 數據集,由Hodosh 等人提出,其樣本量更少,共包含8 091 張圖像。同樣地,每張圖像對應5 條參考句子。在具體使用時,一般選取其中的6 000 張圖像及其參考句子用于模型訓練,另外1 000張圖像與參考句子用于模型驗證,其余1 091 張圖像用于最終的模型測試。
(4)其他數據集基本都是在以上三種數據集基礎上擴展而來,如Flickr8kCN 是由Li等人對Flickr8K進行了中文標注,STAIR 數據集是Yoshikawa 等人對MSCOCO 數據集進行了日文標注。
3.2 圖像標題生成評價指標
圖像標題生成任務的研究多采用生成的標題和參考標題之間的匹配程度來評價生成標題的質量。常用的評價指標有BLEU(bilingual evaluation understudy)、METEOR(metric for evaluation of translation with explicit ordering)、ROUGE-L(recall-oriented understudy for gisting evaluation)、CIDEr(consensusbased image description evaluation)和SPICE(semantic propositional image caption generation evaluation)。其中BLEU、METEOR 和ROUGE-L 是機器翻譯的評測標準,CIDEr 和SPICE 是圖像標題生成任務專用的評測標準。
BLEU 指標主要用于衡量句子的準確性和連貫性,它通過計算生成句子與參考句子-gram 的匹配程度對生成句子進行打分,其中的取值為{1,2,3,4},指幾個連續的單詞分為一個元組。當確定時,BLEU 的值越高,生成的句子就越連貫,其計算公式如下:
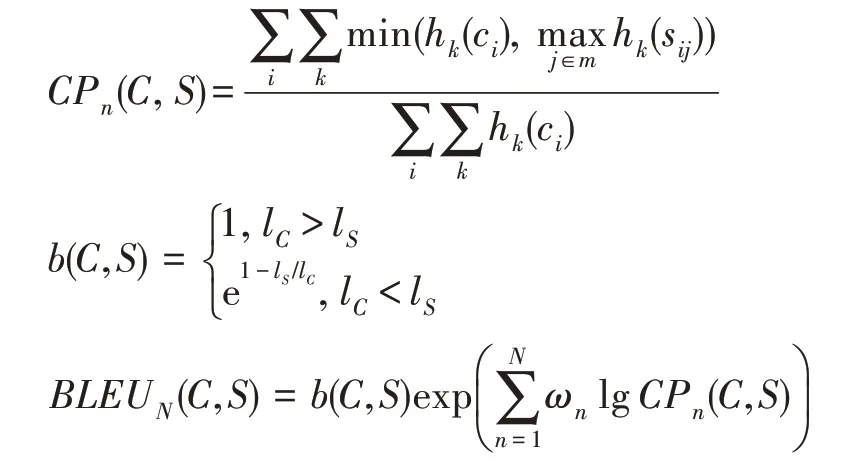
其中,每一個語句用元組ω來表示,元組在人工標注語句S中出現的次數記作h(S),元組ω在待評價語句c中出現的次數記作h(c),l是待評價語句的總長,l是人工標注語句的總長度。BLEU 得分越高,性能也就越好。BLEU 指標對句子的長度也有一定的要求,若句子過短,便會使用懲罰因子降低句子的分數。BLEU 關注的是-gram 而不是單個單詞,考慮了更長的匹配信息。但是由于BLEU 提出的時候,研究者們還沒有發現召回率這個因素對評價指標的影響,BLEU 并沒考慮到召回率這個因素。
METEOR 則是研究者們發現在評價指標加入召回率之后,評測的結果和人工評測的結果相似度提高之后提出的評價指標。METEOR 提出時就是為了解決BLEU 的固有缺陷,因此METEOR 指標考慮了召回率的影響,并且該指標可以計算同義詞、詞根、詞綴之間的匹配關系,評測結果與人工評測的結果相關度更高,其計算公式如下:

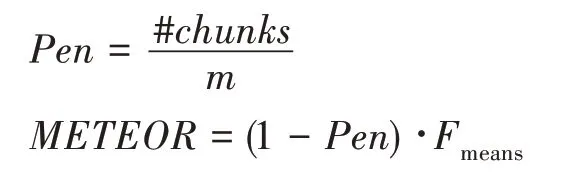
其中,為召回率,為準確率,為匹配的總對數,為候選標題的長度,為參考標題的長度,為懲罰因子,是為了考慮詞之間的順序,如果兩句子中,互相匹配的單詞都是相鄰的,那么就將它們定義為同一個,總數為。
ROUGE 是由Lin 提出的一組評價指標,主要包括ROUGE-N、ROUGE-L、ROUGE-S、ROUGE-W、ROUGE-SU,使用者可以根據需要選擇合適的評價指標,圖像標題生成領域一般采用ROUGE-L 評價指標來評價模型的性能。ROUGE-L 主要針對BLEU 評價指標忽視了召回率的問題做出了優化,與BLEU 類似,ROUGE-L 也是基于-gram 的評價指標,計算生成標題與參考標題之間的元組重合度來衡量標題的質量,其思路與BLEU 基本一致,只是在算法中增加了召回率因素,其計算公式如下:
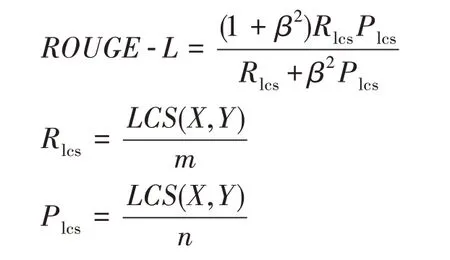
其中,表示候選標題,表示參考標題,(,)表示候選標題和參考標題的最長公共子序列長度,表示參考標題的長度,表示候選標題的長度。
CIDEr 是圖像標題生成任務提出后,專門為圖像標題生成任務設計的評價主表,避免了前幾種指標只在自然語言的角度評價句子質量的缺陷。CIDEr是一種對BLEU 評價指標的改進,首先計算生成標題和參考標題的TF-IDF 向量,然后計算它們的余弦相似度,通過余弦相似度來衡量生成標題與參考標題之間的相關性,其計算公式如下:
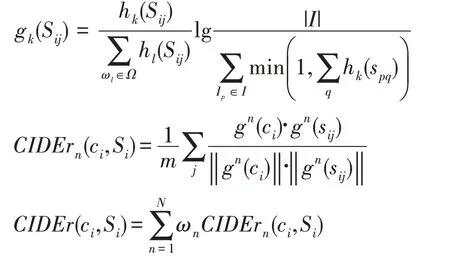
其中,一個元組ω在人工標注語句S中出現的次數記作h(S),在待評價語句中出現的次數記作h(C),元組的TF-IDF 權重g(S),是所有元組的個數,是數據集中所有圖像的集合。CIDEr 的得分越高,生成的語句的質量也就越好。
SPICE 指標也是針對圖像標題生成領域設計的評價指標。與CIDEr 不同的是,SPICE 更加關注語義命題內容。SPICE 認為圖像標題中應該包括圖像中存在的各個語義命題,SPICE 將生成標題和參考標題均轉化為場景圖的形式,場景圖中表示了圖像中的對象、屬性和關系,通過對比場景圖來生成標題評分,其計算公式如下:
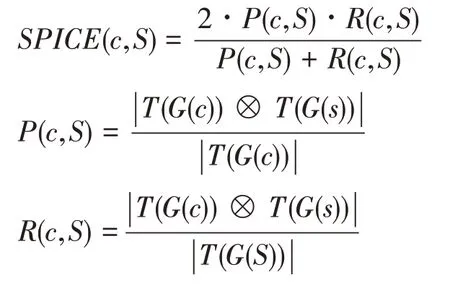
其中,為候選標題,為參考標題集合,(·)表示轉換場景圖的方法,(·)表示元組轉換方法,?表示匹配運算。
以上幾個指標均為標題工作中進行語義相關性評估的指標,而個性化標題生成任務評價指標比較特殊。個性化標題的評價分為兩個方面:一方面是語義相關性的評估,采用的評分標準為以上幾個評分指標,而其中SPICE 指標在個性化標題生成中更關鍵;另一方面是標題的個性化評估,這方面由于其構造數據集和評估的復雜性,目前沒有明確統一的評估指標,一般是采用語言風格遷移的評價指標或采用人工評估的方式進行評估。
4 研究難點與熱點
目前,經過近幾年的研究工作,圖像標題生成領域的工作已經有了顯著的進展。但其在語義融合、模型的高復雜度以及數據集的標注及規模方面仍然存在諸多問題需要深入研究。
語義融合問題:目前大部分圖像標題生成的研究圖像和文本的割裂感較為嚴重,容易出現語義鴻溝問題。如何將圖像語義和標題的文本語義結合起來,關注到圖像模態和文本模態,是未來值得研究的問題。
模型復雜度問題:LSTM 作為圖像標題生成模型的解碼器,盡管一定程度上解決了RNN 網絡梯度消失、梯度爆炸和長依賴性等問題,表現出了較高的性能。但隨著自然語言處理領域的研究愈加深入,生成的文本越來越長,越來越復雜,LSTM 的缺陷也暴露出來,如訓練開銷巨大,在處理長文本時性能會降低等問題。因此,解決解碼器的自身缺陷,也是圖像標題生成領域的難點。目前解決這個問題的思路是采用2017 年Vaswani 等人提出的Transformer 模型,該模型是一種利用純注意力機制計算的神經網絡模型,在處理序列數據上表現出了很好的性能,目前其各種變體已經廣泛應用在了自然語言處理領域和計算機視覺領域。因此,使用或改進Transformer 模型,將其應用在圖像標題生成領域將是熱門問題。
數據集的構建:圖像標題生成領域的數據集在構建時需要專業人員為每張圖片標注五條或以上不同表達形式的標題,構建成本高昂。隨著研究的不斷深入,高性能模型層出不窮,現有的數據集規模已經很難滿足訓練需求。另外如中文、德語、日語等數據集規模較小,難以訓練出高性能模型,限制了圖像標題生成模型的跨語言能力。這方面的解決思路一般是通過半監督學習去訓練圖像標注的模型作為數據集。
5 結束語
圖像標題生成任務作為一種融合了計算機視覺和自然語言處理的多模態任務,打破了視覺與文本之間的界限,在人工智能領域引起了廣泛關注。自其被提出以來,經歷了基于模板的方法、基于檢索的方法和基于編碼器-解碼器的方法。而基于編碼器-解碼器的方法中又經歷了從CNN 到GCN,從LSTM到目前逐漸被應用的Transformer 和BERT 的技術革新。可以發現圖像標題生成領域的研究與計算機視覺技術和自然語言處理技術之間的關系越來越密切。諸如目標檢測、圖像檢索、機器翻譯等任務的思路和技術都逐漸被應用在了圖像標題生成領域,可見其研究思路的開闊性和巨大的可能性。近年來,研究者們不斷提出高性能的圖像標題生成模型及其相關算法。本文在廣泛閱讀國內外文獻的基礎上,對圖像標題生成的概念和三種方法進行了闡述。其次本文按照圖像標題生成的流程,將近年來的研究分為圖像理解階段的研究及標題生成階段的研究并詳細介紹了各項研究的模型內容及優缺點。最后,介紹了圖像標題生成領域的經典數據集和評價指標,討論了圖像標題生成領域目前的研究難點與熱點。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
