基于機器學習的公司特有風險預測方法研究
2022-10-21 02:22:56王傳軍王鄭毅
中國資產評估 2022年6期
■ 王傳軍 王鄭毅 周 越
(1. 坤元資產評估有限公司,浙江杭州310007;2. 湘財證券股份有限公司,上海200120)
一、項目背景
折現率在企業價值評估中發揮著至關重要的作用,其可能直接影響并購重組的定價,進而影響交易的成敗。遺憾的是,對于折現率的重要組成部分——特有風險,國內實證研究成果不甚理想,未能形成被廣泛接受的測算方法。基于此,本文嘗試多維度地提取樣本的有效屬性(特征),利用多種獨立的模型捕獲特征間關系,輔以網格搜索方法和遞歸特征消除特征法,以期生成一套較為高效、科學的特有風險測算模型。
二、機器學習概述
(一)機器學習簡介
機器學習是一種利用計算機就已知數據構建概率統計模型,再運用該模型開展后續數據分析(學習)進而預測未知數據的數學建模方法。機器學習由模型、策略和算法構成,即學習器=模型+策略+算法。
其中,模型指的是某種函數的集合;策略作為從函數的集合中選擇最優函數的準則;而算法則是根據策略從模型中選擇最優函數的具體計算方法。①李航,統計學習方法. 清華大學出版社,2012.為了便于區分,我們將學習器從數據中學習得到的最優函數稱為預測模型。
(二)機器學習的一般流程
機器學習一般包含以下5個步驟:數據收集、數據準備、學習器選擇、特征選擇、預測模型評估,具體如圖1所示。

圖1 機器學習的一般流程
(三)機器學習的一般工具
基于Python等各類語言的數據分析和學習庫成為當今機器學習的主流之一。其中,(簡單高效的學習工具)Scikit-Learn、(科學和工程領域較常用的)SciPy、(用于存儲和處理大量矩陣的)Numpy和(常用于金融分析的)Pandas較為常用。①https://blog.csdn.net/a673519020/article/details/112471996用于進行深度學習的TensorFlow、PyTorch、Keras,用于處理自然語言的NLTK,用于機器視覺訓練的OpenCV等學習庫亦不乏應用場景。
通過將各種機器學習庫進行整合和優化,結合大數據技術和用于發布服務的API發布工具,諸如阿里PAI、星環Sophon、百度BML、4Paradigm Sage Studio等全流程、低門檻AI應用開發與上線平臺應運而生。這些平臺通過可視化的開發界面,使用戶通過選擇并連接相應組件的方式,實現導入數據、訓練模型、發布服務全流程的低代碼開發,大大降低了機器學習的應用門檻。
本文基于Jupyter Notebook開發、展示窗口,以及Scikit-Learn開發工具開展研究。其中,開發工具可以通過安裝Anaconda3獲取,或在安裝Python程序后通過“Pip3 install scikit-learn”等命令進行自定義安裝。
三、數據收集
本文以通過證監會并購重組委審核的近年128宗案例數據為基礎開展研究。數據來源包括交易報告書、審計報告、評估報告及說明、反饋意見、其他公開數據等。通過文獻研究、財務評價體系參考、并購重組定價和風險影響因素描述性分析,筆者建立了研究的指標體系,由28項屬性構成,涵蓋行業、標的公司歷史、股權、經營、技術、財務等風險驅動的重要屬性。
在Jupyter NoteBook界面,通過“import pandas as;import numpy as;import matplotlib.pyplot as plt;unique_risk=pd.read_csv(‘unique_risk.cvs’);unique_risk[‘審核結果’]=unique_risk[‘審核結果’].map({‘發行股份購買資產獲無條件通過’比‘發行股份購買資產獲有條件通過’:0});unique_risk.head(5)”等代碼導入數據,通過descrbie()函數對各屬性進行了統計。結果顯示,實踐中特別風險的最大取值為5%,最小為0.5%,主要集中于[1.5%,3%]區間內,數據集不存在缺失值,但部分屬性離散程度較大。
由于共選擇了28個屬性進行研究,因此需通過降維的方法進行數據可視化處理。考慮到常用的PCA(Principal Component Analysis)主成分分析算法為線性算法,難以解釋屬性間的復雜多項式關系,不能將相似數據點放置一起展示,因此筆者選取t-SNE算法進行數據降維。
t-SNE(t-distributed stochastic neighbor embedding,T-分布鄰域嵌入算法)是一種用于挖掘高維數據的非線性降維算法,適用于將高維數據降維到二維或三維后進行可視化處理。該算法核心思想是將歐幾里得距離轉換為服從t分布的條件概率來表達點與點間的相似度,能較好地描述點之間的相似度。
本次研究數據存在異常值,筆者將其定義為離群點(outlier),即遠離具有相同分布的內點(inlier)的樣本。由于離群點會影響模型擬合的效果,因此需要對其進行檢測和剔除。常用的異常值檢測方法如表1所示。
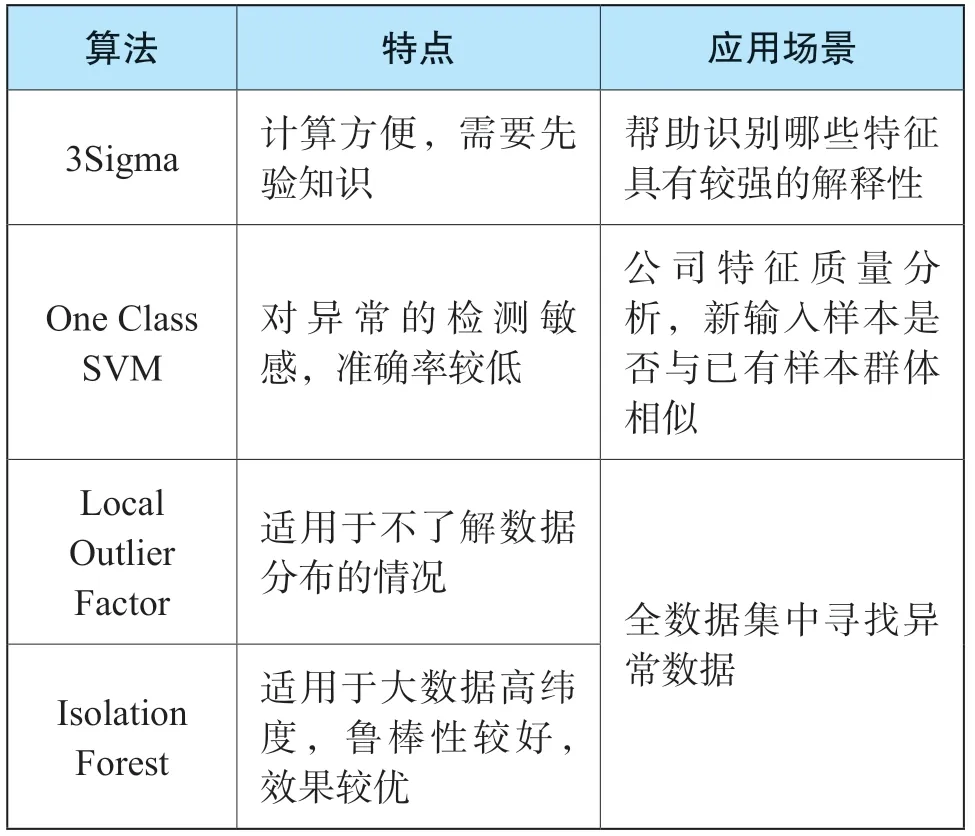
表1 異常值檢測的常用方法
本次使用Local Outlier Factor和Isolation Forest方法對離群點進行檢測。以前者為例,通過“from sklearn.neighbors import LocalOutlierFact or;clf=LocalOutlierFactor(n_neighbors=2);res=clf.fit_transform(unique_risk)”等代碼輸入,形成Local Outlier Factor及Isolation Forest離群點檢測圖。結果顯示,Local Outlier Factor在離群點的檢測上更敏感,可視化后也更符合直觀感受,因此,筆者選擇其結果作為后續訓練的數據集。
四、數據準備
由于原始數據集內存在不可量化數據,且各屬性口徑存在較大差異,因此需要對數據進行編碼和標準化,以增強數據的可用性。此外,為便于對生成的預測模型進行評估,本次將數據分為訓練集和測試集兩部分。
(一)特征構建
對于“審核結果”屬性,原始數據集內表現為“發行股份購買資產獲無條件通過”和“發行股份購買資產獲有條件通過”兩個字符串,鑒于無法直接輸入到模型中,考慮到“發行股份購買資產獲無條件通過”比“發行股份購買資產獲有條件通過”更優,故分別將“發行股份購買資產獲有條件通過”“發行股份購買資產獲無條件通過”編碼為0和1。
(二)數據標準化處理
由于不同變量間的量級存在較大差異,學習器的算法往往會被數值大的屬性所主導,因此需對數據進行標準化處理。考慮到原始數據不完全符合正態分布,本次選用Min-Max標準化方法進行數據處理。Min-Max標準化公式如下:
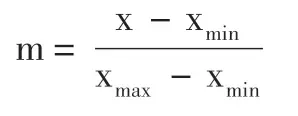
式中:m是新值;x是單元格原始值;xmin及xmax分別是該列的最小和最大值。
標準化后各屬性取值位于[0,1]區間內,規避了算法受數據尺度影響的不利情形,結果更為精準。
(三)分離訓練集和測試集
由于機器學習的復雜性,預測模型有時會過于緊密或精確地匹配已知數據集,以致缺乏泛化能力,無法很好地預測未來的觀察結果,即出現過擬合。因此,筆者將數據集的90%部分用于生成預測模型,其余部分作為測試集,用于后續評估預測模型對于未知數據的預測能力。具體輸入代碼為“from sklearn.model_selection import train_test_split;train,test=train_test_split(unique_risk,test_size=0.1,random_state=22)”“train_X=train.drop(labels=[“Rc”],axis=1);train_y=train[‘Rc’];test_X=test.train.drop(labels=[“Rc”],axis=1);test_y=test[‘Rc’]”“ss=M inMaxScaler();train_X=ss.fit_transform(train_X);test_X=ss.transform(test_X)”。
五、學習器選擇
由于數據集輸出數據的連續性,因此特有風險的預測屬于機器學習中的回歸問題。機器學習的回歸模型可以分為廣義線性、樹、支持向量機、K近鄰、Bagging集成、Boosting集成、多層感知機(神經網絡)回歸等七類模型。此次研究中,我們選擇最小化模型在訓練集上的R2作為學習策略,使用Scikit-Learn中的算法選擇最優模型。
(一)模型介紹
1.嶺回歸
嶺回歸在最小二乘法的基礎上,利用添加L2范數對系數進行懲罰的方法,對屬性間具有完全共線性或高度相關性的情形進行優化。
2. K近鄰回歸
K近鄰回歸屬于懶惰模型,其并不從訓練數據中生成判別函數,而是基于某種距離度量找出訓練集中最靠近待預測樣本的k個訓練樣本,將這k個鄰居的輸出值的平均值標記為待預測樣本的預測結果。
3.多層感知機回歸
多層感知機回歸即按照每層感知機與下一層感知機的全連接,感知機間以不存在同層或者跨層連接的方式構建一個多層前饋神經網絡,通過誤差逆傳播算法不斷調整感知機之間的權值,最終獲得一個復雜的非線性預測模型。
4. Boosting類回歸
Boosting類回歸的核心思想是通過增大錯誤樣本的權重,將多個弱預測模型組合成一個強預測模型進而實現回歸。其中比較常用的模型有AdaBoost(Adaptive Boosting,自適應增強模型)、XGBoost(eXtreme Gradient Boosting,極限梯度提升模型)、LGBM(Light Gradient Boosting Machine,輕量級的高效梯度提升模型),其主要區別在于如何識別模型和權重的調整方法上。
前述模型的優劣勢可以通過表2進行描述。
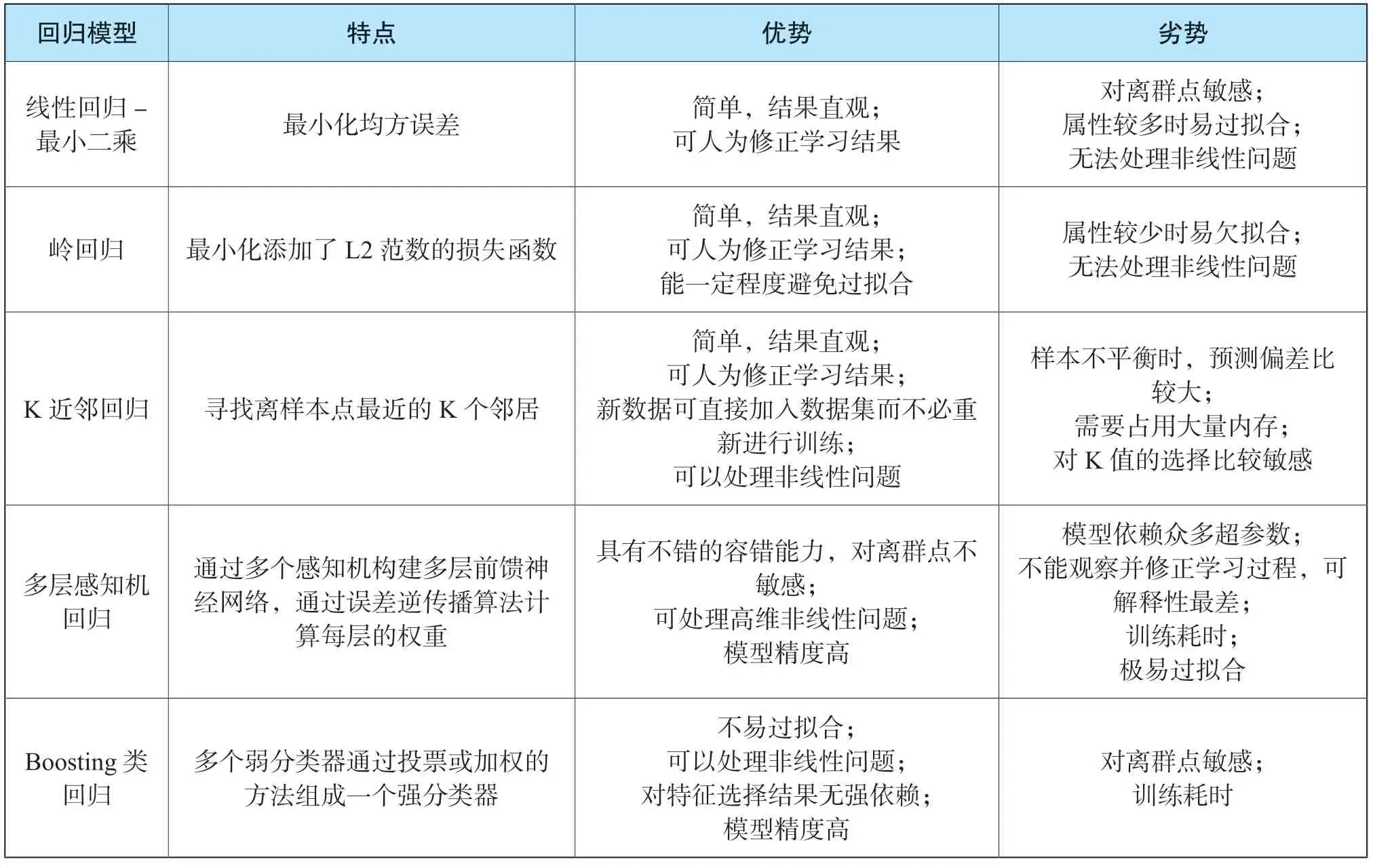
表2 各類回歸模型對比
(二) 模型超參數選擇
機器學習中,超參數系在學習開始之前需要為模型設置值的參數。與之對應,其他參數的值是通過訓練得出的。實際應用中,Scikit-Learn中各模型默認的超參數組合(詳見表3)往往并不適合訓練集的數據模式,需要進行優化。
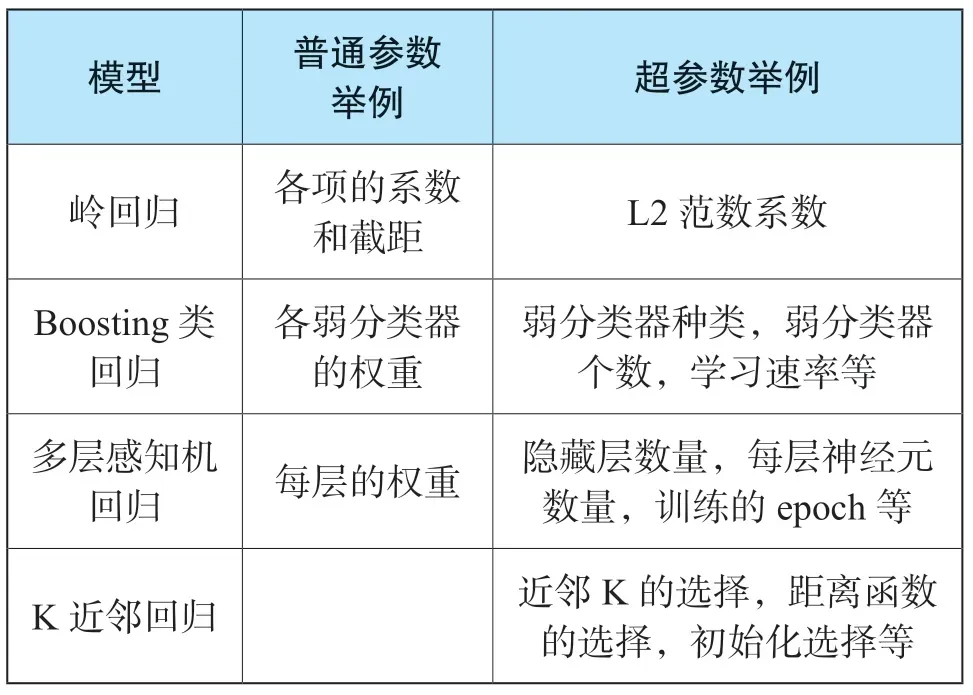
表3 各模型普通參數和超參數對比
參數網格搜索是一項超參數優化技術,常用于三個及以下超參數的優化,其本質屬窮舉法范疇。對于每個超參數,使用者創建一個較小的有限集合,作為該超參數的備選項。然后,從各項超參數備選項的笛卡爾乘積中得到若干組不同的超參數組合。網格搜索使用每組超參數訓練模型,挑選驗證集誤差最小的超參數組合作為模型最好的超參數組合。
由于樣本容量較小,按照常規70%的訓練集,20%驗證集和10%測試集的樣本劃分方法,從數據集中取出20%的驗證集對超參數進行選擇的話,會存在訓練集樣本容量和驗證集樣本容量都不夠大的問題。而通過交叉驗證的方法對訓練集上的數據進行循環使用,可以使預測模型在訓練集的多個而非單個子數據集上實現優異表現,增強預測模型的泛化能力。由此,筆者選擇了10折交叉驗證后各預測模型在驗證集上R2的平均值對模型進行評價,并作為該模型的基礎性能。
K折交叉驗證(K-fold cross validation)的核心思想是把訓練數據D分為K份,其中(K-1)份用于訓練模型,剩余1份用于評估預測模型的準確率。前述過程在K份數據依次循環,最終得到K個評估結果。①周志華,機器學習. 清華大學出版社,2016.
通過“from sklearn import linear_model;model_LinearRegression=linear_model.LinearRegression()”等代碼構建基礎的學習器。之后依據相關代碼(略)對每個學習器中模型的超參數予以調優,通過“from sklearn.model_selection import cross_val_score”進行交叉驗證。
多輪迭代后,各模型在超參數優化前后驗證集上的R2平均值如表4所示。
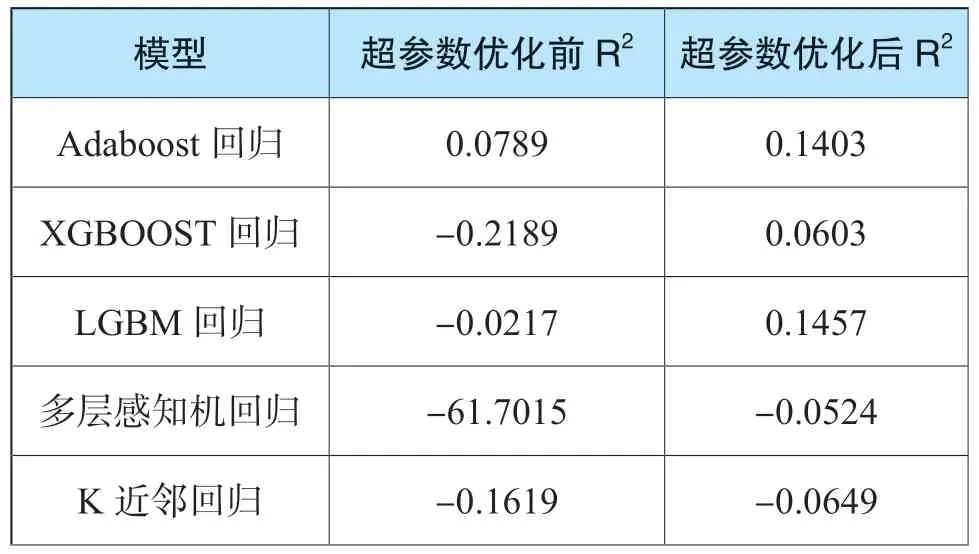
表4 模型在原始測試集上調參前后對比
六、特征選擇
(一)特征選擇概述
數據集內的各屬性對預測結果提供的信息增益各異。鑒于此,往往需要通過特征選擇,于給定的所有屬性中選取相關屬性作為樣本的特征,去除掉無關和冗余屬性,從而達到降低擬合風險,提高訓練速度的目的。②Ozdemir, S. Susarla, D. Feature engineering made easy. Birmingham, UK: Packt Publishing. 2018.
特征選擇方法可分為過濾法、包裹法、嵌入法三類。
過濾法運用統計指標來為每個特征打分并篩選特征,其聚焦于數據本身的特點。其優點是計算快,不依賴于具體的模型,缺點是選擇的統計指標不是為特定模型定制的,因而最終準確率可能不高。此外,由于采取的是單變量統計檢驗手段,故未考慮特征間的相互關系。
包裹法使用模型來篩選特征,通過不斷地增加或刪除特征,在驗證集上測試模型的準確率,尋找最優的特征子集。包裹法因為有模型的直接參與,因而準確性較高,但是計算成本高,容易出現過擬合。
嵌入法利用了模型本身的特性,將特征選擇嵌入到模型構建過程中。典型的如 Lasso 和樹模型等。其準確率較高,計算復雜度介于過濾式和包裹式方法之間,但缺點是僅部分模型適用此方法。①A review of feature selection techniques in bioinformatics[J]. Bioinformatics(19):2507-2517.具體方法如表5列示。
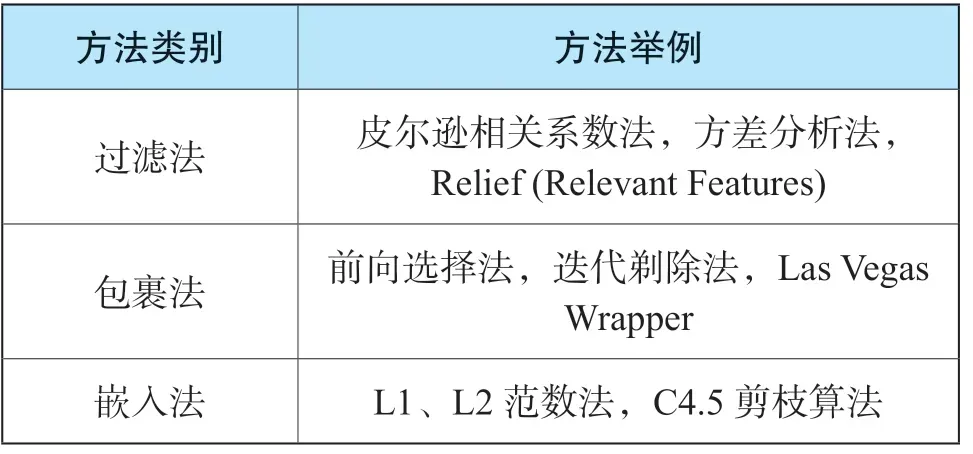
表5 特征選擇方法列舉
(二)過濾法
過濾法最常用的方法是SelectKBest()。顧名思義,該方法就是根據傳入的評分函數,從所有特征中挑選出最好的K個特征組成新的特征集。由于本次研究的問題屬于回歸問題范疇,因此選擇了f-regression方法對各屬性進行線性相關分析,并根據得到的F值計算出相應的p值。本次研究結果見表6。
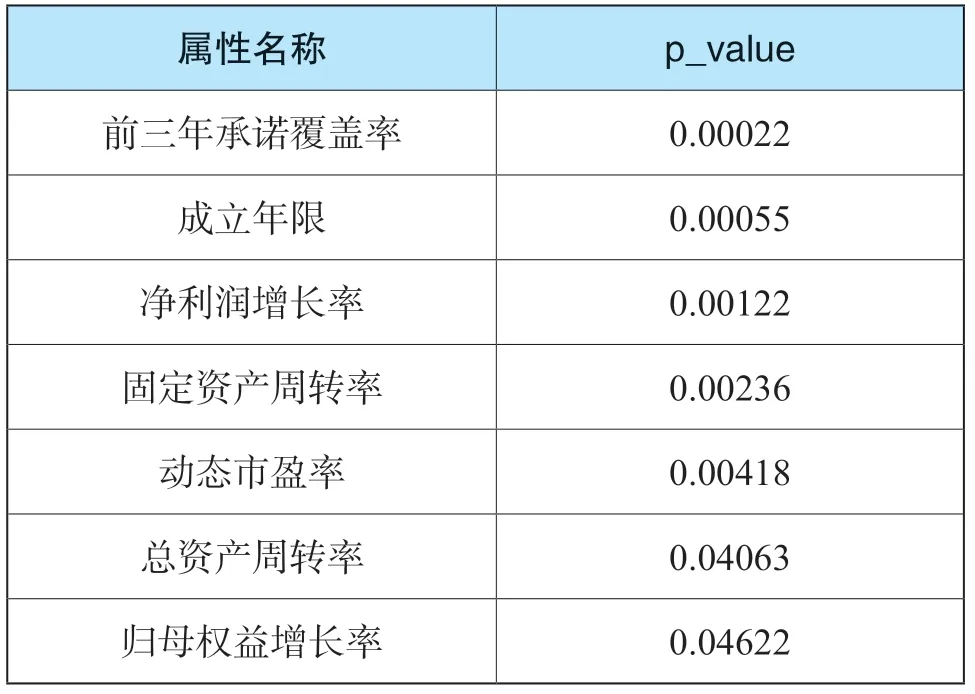
表6 各屬性顯著性分析
表格顯示,前三年承諾覆蓋率、成立年限兩個指標對特有風險有非常顯著的影響;凈利潤增長率、固定資產周轉率、動態市盈率、總資產周轉率、歸母權益增長率對特有風險有顯著影響。但是由于F檢驗屬于線性回歸測試,因此存在部分和特有風險呈非線性關系的特征未被選取的可能。
(三)遞歸式
遞歸特征消除法(RFE, Recursive feature elimination)是一種常用的包裝法特征選擇方法。其核心思想系通過不斷地迭代訓練模型,每次刪除若干重要性較低的特征,直到最新刪除特征造成總體性能損失時結束。
通過代碼調用RFECV函數,對每種模型進行特征選擇,根據特征選擇結果重新訓練模型。
(四)結果對比
對各模型通過10折交叉驗證法,生成的預測模型在原始數據驗證集及通過不同特征選擇方法生成的驗證集上的R2的平均值如表7所示。
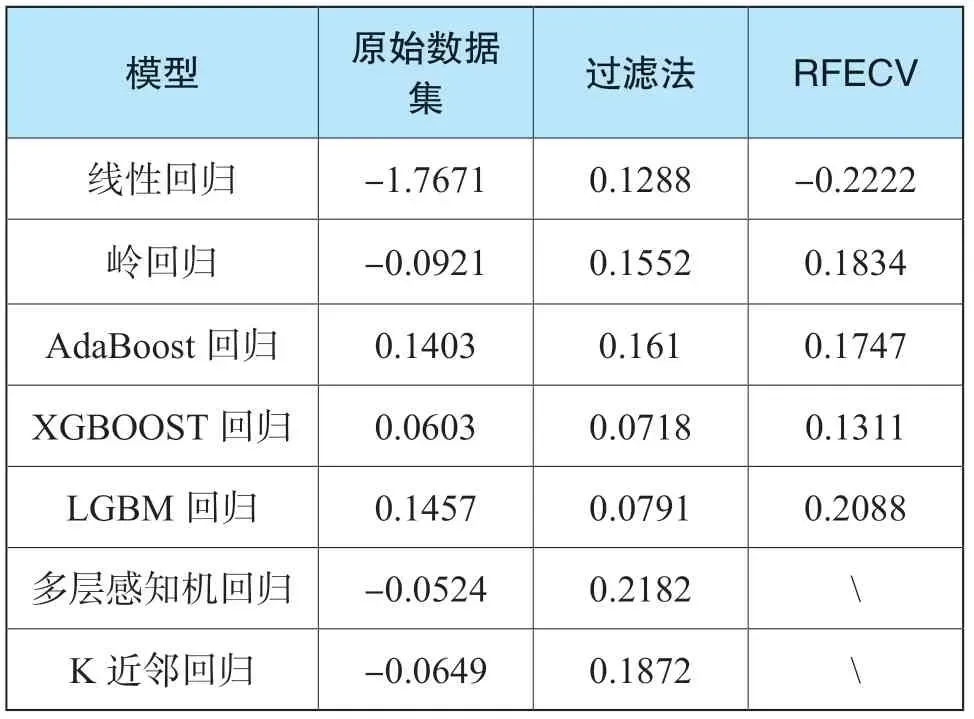
表7 預測模型在不同特征方法上的表現
由上表顯示,除了多層感知機回歸和K近鄰回歸沒有權值系數屬性(coef或feature_importances)而無法進行迭代外,遞歸特征消除法相比過濾法在驗證集上能有更好的表現。
七、預測模型評估與分析
(一)預測模型評估
根據上述特征選擇和超參數調優的結果,筆者選出各模型在10折交叉驗證中具有最高R2的特征及超參數組合,在之前分離的90%的訓練集上根據選出的特征生成新的訓練數據,利用超參數組合輸入到模型中,得到最終的預測模型。
然后,將之前分離出的10%的數據集輸入到預測模型中,對預測值和實際值進行對比,得到折線圖2-1至圖2-7。
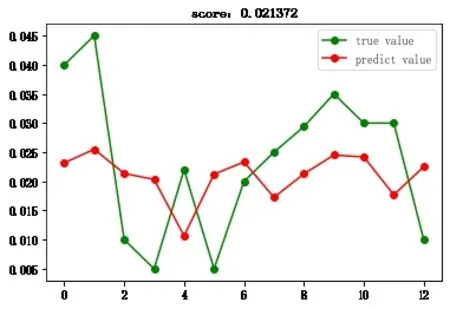
圖2-1 線性回歸
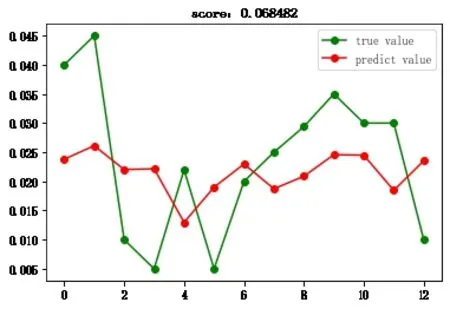
圖2-2 嶺回歸
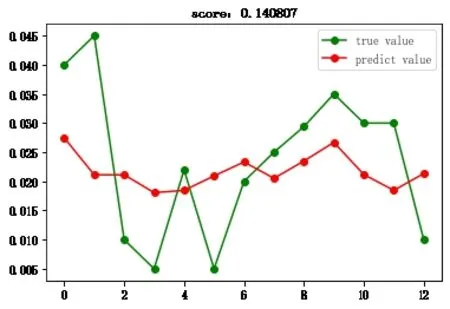
圖2-3 AdaBoost回歸
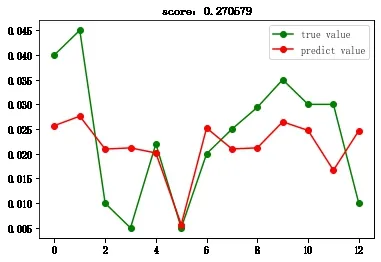
圖2-4 多層感知機回歸
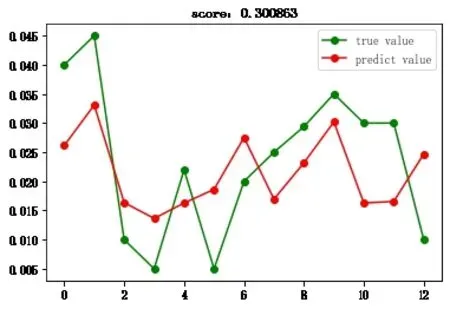
圖2-5 XGBoost回歸
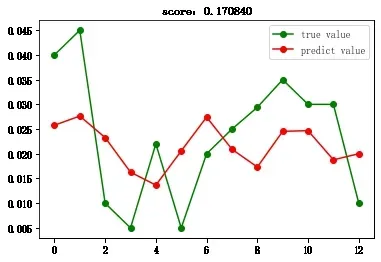
圖2-6 LGBM回歸
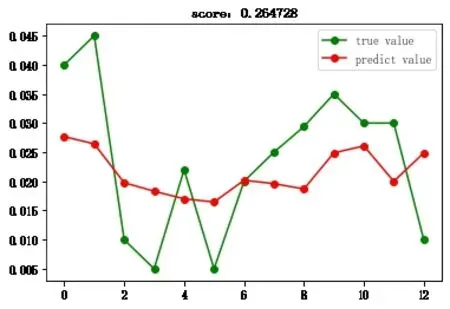
圖2-7 K近鄰回歸
對比預測模型在10折交叉驗證及在測試集上的R2,具體見表8。
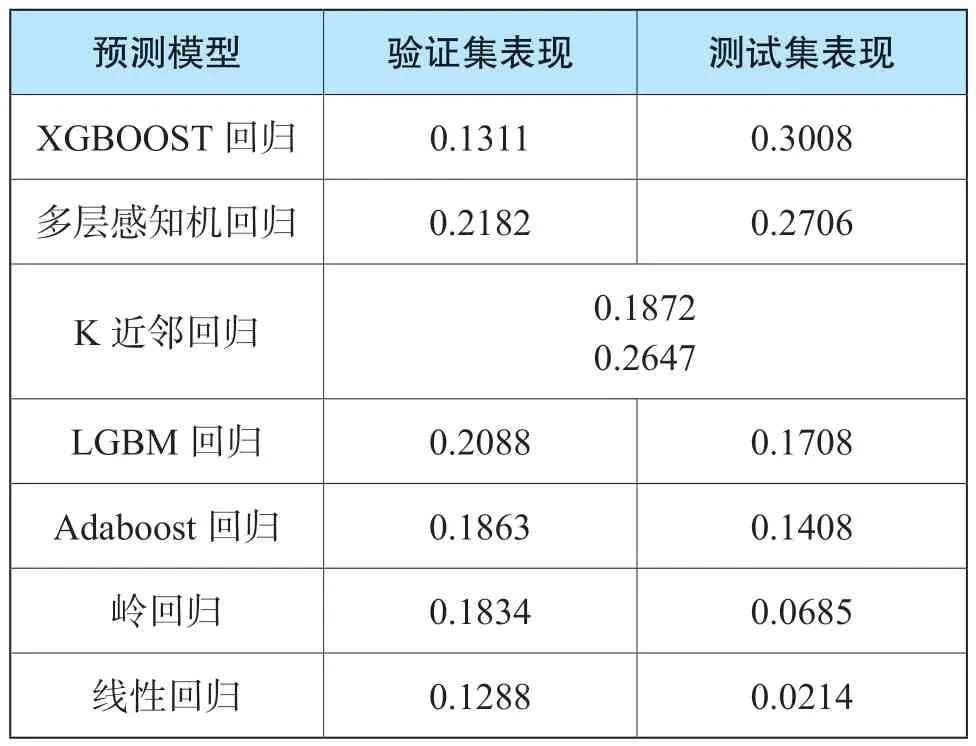
表8 預測模型在驗證集和測試集表現
其中,每個模型選用的特征如表9所示:
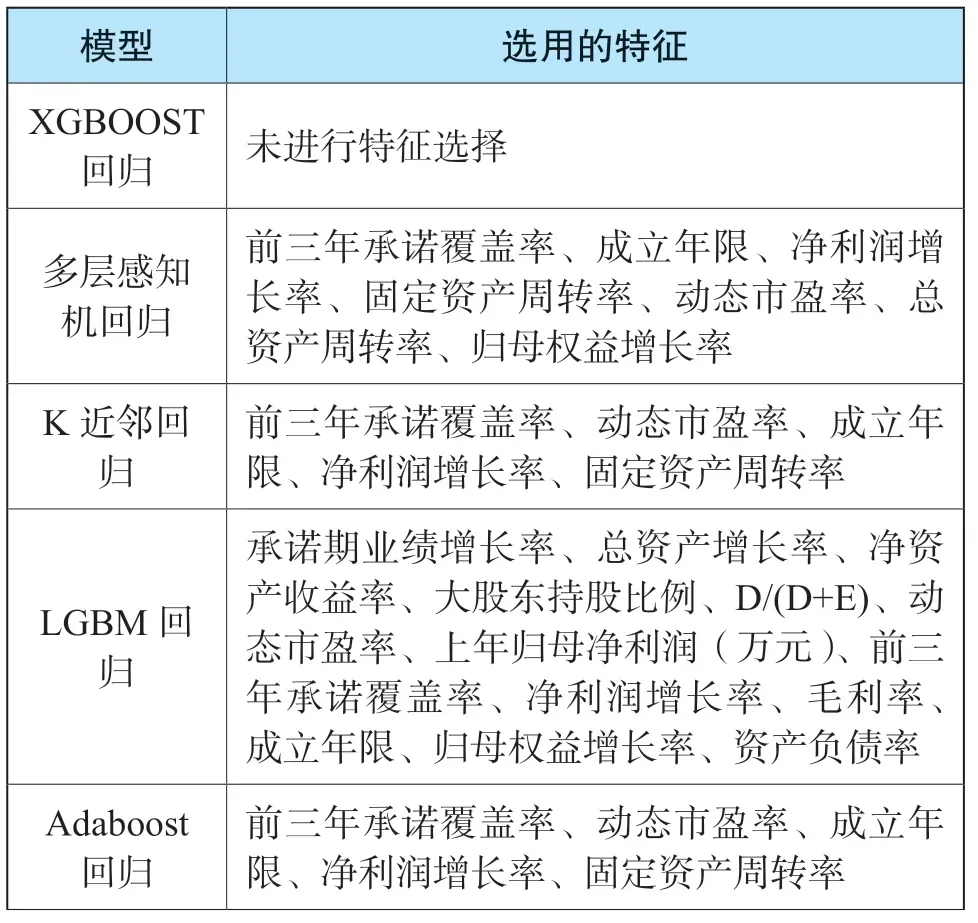
表9 各模型選用的特征

續表
(二)模型結果與分析
從結果上看,模型在訓練集和測試集上的多折交叉驗證表現有一定差別。通過測試集確定模型的參數,驗證集確定模型的超參數后,筆者通過獨立的測試集來評估預測模型的最終性能,以決定預測模型的選擇結果。
通過配對樣本的t檢驗,筆者對不同預測模型的均方誤差(MSE)是否存在顯著差異進行了檢驗。通過檢驗發現,線性回歸預測模型和嶺回歸預測模型的MSE相比XGBoost預測模型有顯著差異;AdaBoost預測模型和LGBM預測模型的MSE相比XGBoost預測模型有一定差異,但并不顯著;K近鄰回歸預測模型和多層感知機預測模型MSE相比XGBoost預測模型幾乎不存在差異。
由于模型的復雜度差異,非線性模型預測準確率相對更高。XGBoost回歸模型具有最好的表現,但距離對特有風險進行精準定量測算的初衷仍有差距。
此外,應關注到,對于XGBoost回歸和多層感知機回歸模型而言,我們無法給出明確的解析解來說明預測值生成的原因。當部分預測值存在偏差時,我們只能通過有傾向性地輸入新的訓練集來糾正偏差。而K近鄰回歸模型則可以通過構建KD樹來明確每個樣本的范圍,并輸出相應用于預測的K個最近鄰居,使得模型具有更強的解釋性。因此,就實踐而言,K近鄰回歸具有更大的應用價值,表現也更優秀。
在特征選擇上,總體來看,各模型使用的頻度較高的特征為前三年承諾覆蓋率、成立年限、凈利潤增長率、動態市盈率、固定資產周轉率、歸母權益增長率等,且該等特征的影響程度逐項遞減。
筆者認為,這些特征對于特有風險的確定,確實存在很強的因果關聯。
一是,通常來說,前三年承諾覆蓋率、凈利潤增長率、動態市盈率、歸母權益增長率越高,則企業特有風險越大。當企業處于高速增長階段之時,表明其需要更多的資源予以支持,很可能在人員、技術、產能及營運資金等方面存在大量缺口;高速增長期間,企業面臨的自身文化、組織結構、外部認同及管理者能力不足問題尤為突出,資金流、人力資源、營銷部門及管理能力等往往相對薄弱。另外,不排除部分企業為凸顯高速增長的市場形象,進行不恰當的會計估計、會計政策改變甚至財務造假的可能,易造成后續風險的集中爆發。凈利潤增長率、歸母權益增長率為歷史靜態性特征,而前三年承諾覆蓋率、動態市盈率屬于預測期動態性特征,均屬于增長率范疇,由前文可知,該等指標與特別風險成正比,且動態特征影響力大于靜態特征。
二是成立年限越長,企業特有風險越小。企業成立年限越長,表明其極有可能占領市場先機,掌握更為充足的原材料、技術、渠道等關鍵資源,通過多年的經營和多輪優勝劣汰,擁有更豐富的經驗,具備一定的競爭優勢,贏得長期的市場優勢。另外,企業經營多年,也表明其所處行業存續時間較久,產業普遍較為成熟,行業的不確定性較小。
三是固定資產周轉率越高,則企業特有風險越大。這個結論與增長率結論相似。高周轉的企業往往處于某一個爆發式發展階段,但難以長期維持,就像一臺高速運轉的機器、一根緊繃的弦,需要外部資源的不斷支持。而縱觀國內外市場和企業發展歷程,從中、長期而言,良性的發展大部分是細火慢燉的,符合市場整體發展趨勢的周轉率更為適宜。
鑒于機器學習方法生成的預測模型往往具有“黑盒”特征,因此,本研究未能生成定量公式。但我們可以將相關數據輸入預測模型得出結論,隨著數據數量與質量的不斷提升,預測數據將更為準確。
八、總結與展望
本文通過回歸分析和遞歸特征消除法,建立了一套涵蓋6個主要指標的特有風險評價體系,并在體系基礎上利用機器學習方法對特有風險進行了預測。
幾種預測模型的表現總體差強人意,R2均不甚理想,筆者認為原因有以下幾點:一是本次研究的數據來源于過往實踐,鑒于實務中評估專業人員過度依賴主觀判斷致結果偏差,甚至根據結果導向確定特別風險,因此實證數據質量欠佳;二是樣本容量相對較小,無法完全滿足機器學習對數據規模的要求。
筆者曾采用傳統統計學路徑研究了同樣的樣本數據,生成了回歸預測模型,認為資產負債率、研發支出占比、歸母權益增長率、凈利潤增長率、總資產周轉率、應收賬款周轉率及上一年歸母凈利潤與特有風險呈正相關關系;經營性現金流/收入、成立年限呈負相關關系。前次與本次研究結果有一定的共同點,均認為特別風險與歸母權益增長率、凈利潤增長率呈正比,與成立年限成反比,且兩次研究分別提及的總資產周轉率與固定資產周轉率有共通之處。但筆者以為,本研究中多個模型都一致認可了前三年承諾覆蓋率、動態市盈率的重要性,這與并購重組定價邏輯及博弈重點不謀而合,具有合理性。從定性角度來看,本次研究結果更具溫度。此外,前次研究的擬合優度R2(分別為0.210和0.189)亦較低(略低于本次研究),兩次研究均表明自變量對因變量的解釋力度不足。
雖然在現有實證數據基礎上,特別風險的準確厘定較難實現。但對數據進行特征工程并構建非線性模型的思路,具有一定的借鑒價值。
首先,由于機器學習模型的復雜性,一方面其在處理海量、多屬性的數據集時具有不錯表現,另一方面也會產生黑盒的可解釋性問題。因此,可以從獲取數據的數量與質量,以及結論的可解釋性需求兩個角度綜合分析評估是否要引入機器學習。一般而言,當可獲取的數據多且全面,能對預測結果給出充分反饋,且無需作出完整解時,則適合引入機器學習方法。
其次,在具體模型的選擇上,雖然機器學習構建的非線性模型的預測準確率往往好于線性模型,但沒有一個模型能在所有問題上都優于其他模型。如果兩模型表現接近,那么選擇相對簡單的線性回歸模型,不失為明智的選擇。
再次,需要關注的是,機器學習方法的實質是對變量和因變量的相關性進行數理分析并得出答案。其分析結果只能說明因變量和變量間存在一定的相關性,并不能說明兩者間是否存在因果關系。因此,在機器學習的同時,不可忽視專業知識的重要性。
最后,對于本次研究,還可以在特征選擇方法上做進一步探索。由于特征選擇不是具有貪心選擇性質的組合最優化問題,無法在多項式時間內直接計算得到最優解。因此除了通過用如遞歸特征消除法這種貪心算法得到近似解外,也可以考慮采取諸如模擬退火、遺傳算法、蟻群算法等啟發式算法予以優化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
