用于復(fù)雜場景裂縫分割的多層次特征提取算法
2022-10-24 04:48:28劉清華呂偉才韓雨辰徐錦修
無線電工程 2022年10期
劉清華,呂偉才*,仲 臣,韓雨辰,徐錦修
(1.安徽理工大學(xué) 空間信息與測繪工程學(xué)院,安徽 淮南 232001;2.安徽理工大學(xué) 礦區(qū)環(huán)境與災(zāi)害協(xié)同監(jiān)測煤炭行業(yè)工程研究中心,安徽 淮南 232001;3.安徽理工大學(xué) 礦山采動災(zāi)害空天地協(xié)同監(jiān)測與預(yù)警安徽普通高校重點實驗室,安徽 淮南 232001)
0 引言
裂縫是結(jié)構(gòu)最常出現(xiàn)的病害之一,且為結(jié)構(gòu)的安全性和耐久性提供了重要的信息,因此對于裂縫的檢測具有重要意義。目前,對于結(jié)構(gòu)表面裂縫主要依靠人工肉眼識別記錄,人工方法存在著諸如人力成本高、危險系數(shù)大、效率較低和受人為影響大等弊端[1]。因此,借助計算機視覺技術(shù)實現(xiàn)對于裂縫的自動識別有著較大的實際需要。
目前,基于計算機視覺的裂縫識別算法主要分為2類:一類基于傳統(tǒng)圖像處理技術(shù);另一類基于卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)。
傳統(tǒng)圖像處理需要先對圖像進行預(yù)處理,即對輸入的圖像進行灰度化處理后通過濾波和增強等操作使圖像特征較為明顯平滑后,借助圖像分割或邊緣檢測來進行裂縫的識別。Wu等[2]提出了基于小波變換的提取方法,相比于以往方法可以更好地獲取裂縫的信息,但由于小波變換的各向異性,無法很好地處理斷裂較多或曲率較大的裂紋。李海豐等[3]設(shè)計了一種基于動態(tài)閾值的機場路面裂縫識別算法,主要依據(jù)裂縫的深度與形態(tài)信息進行提取,克服了機場存在的震動強烈導(dǎo)致噪聲較多的情況。傳統(tǒng)圖像處理方法雖然也能獲得較高的準確度,但往往只適用于特定情況,在更換場景或數(shù)據(jù)集后檢測效果很差。
基于CNN進行檢測是現(xiàn)在較為熱門的方向,相較于傳統(tǒng)方法,CNN抗噪聲能力較強,且由于其多層次卷積學(xué)習的特性使得其適用性較強。王丹等[4]通過將FCN-8s網(wǎng)絡(luò)原有的dropount層刪除,添加BN層及PReLu層,與條件隨機場(CRF)結(jié)合實現(xiàn)了多尺度的裂縫感知并獲得了較為理想的結(jié)果,平均交并比(mean Intersection over Union,mIoU)達到80.3%。Qiao等[5]改進了U-Net的初始模塊且增加了空間金字塔池化模塊,使得其在自有數(shù)據(jù)集上進行訓(xùn)練后對混凝土橋梁裂縫的識別準確率較U-Net有11%的提升。Wu等[6]提出了多形狀對象分割的網(wǎng)絡(luò)模型,通過對全卷積神經(jīng)網(wǎng)絡(luò)(Fully Convolutional Network,F(xiàn)CN)結(jié)構(gòu)進行改良,使其對圖像的底部細節(jié)獲取增強,能更好地識別細小物體的裂縫情況。Dais等[7]將FCN[8]結(jié)合遷移學(xué)習,將U-Net與MobileNet結(jié)合后在復(fù)雜場景下的識別準確率可以達到95%。但由于各類結(jié)構(gòu)裂縫產(chǎn)生原理不一、形態(tài)多樣,目前采用CNN進行裂縫識別的方法大多只針對于單一類型,在更換不同數(shù)據(jù)集進行測試后結(jié)果往往達不到最優(yōu)理想狀態(tài)。
綜上所述,本文提出了一種能夠提取多層次特征并與引導(dǎo)濾波(Guided Filter,GF)[9]相結(jié)合的算法對裂縫進行識別與分割,通過實驗對比驗證了改進后算法相對于經(jīng)典CNN算法精度有較大提高。
1 算法框架
本文算法流程如圖1所示,對輸入圖像進行圖像預(yù)處理,未進行標注的圖像進行手動標注生成Ground Truth后進入網(wǎng)絡(luò)進行分割;網(wǎng)絡(luò)每個卷積層生成特征圖,各側(cè)輸出層將生成的特征圖保留并輸出;將上采樣獲得的各層特征映射通過Concat融合獲得融合特征,再應(yīng)用引導(dǎo)濾波進行去噪細化,通過Softmax層預(yù)測得到對每個像素按固定閾值預(yù)測的標簽,最終輸出預(yù)測結(jié)果圖。

圖1 算法流程Fig.1 Algorithm flow chart
VGG[10]網(wǎng)絡(luò)有著優(yōu)異的特征提取能力,本文算法采用以VGG16為主體框架的HED[11]作為基礎(chǔ),對其進行一定改進來提高分割精準度及適用性,具體改進如下:
(1) 在基礎(chǔ)VGG16的基礎(chǔ)上添加3個卷積層改為VGG19,提升網(wǎng)絡(luò)深度,在計算量相差不大的情況下獲取更為詳細的細節(jié),卷積核尺寸為3×3,最大池化層核尺寸為2×2。
(2) 在卷積單元與線性修正單元(Rectified Linear Unit,ReLU)[12]間添加批歸一化(Batch Normalization,BN)[13]單元,BN單元可以加快模型的收斂速度,且可以緩解深層網(wǎng)絡(luò)中梯度彌散的問題,提高模型的精度。
(3) 在學(xué)習階段改良損失函數(shù),以緩解負像素數(shù)量遠大于正像素數(shù)量的情況。
(4) 將引導(dǎo)濾波層與CNN進行端到端的連接,采用引導(dǎo)濾波對分割結(jié)果進行去噪細化,獲取更為精確的邊緣信息及分割結(jié)果。
本文采用了多場景不同分類數(shù)據(jù)集進行訓(xùn)練,其中包括:① 路面[14-15]和橋梁[16]裂縫的開源數(shù)據(jù)集;② 單反、手機拍攝的墻體裂縫數(shù)據(jù)集,并在多數(shù)據(jù)集上獲得了較為理想的結(jié)果。
2 HED網(wǎng)絡(luò)改進算法
2.1 HED網(wǎng)絡(luò)模型
整體嵌套邊緣檢測(Holistically-nested Edge Detection,HED)網(wǎng)絡(luò)由Xie等[11]在2015年提出,以VGG16網(wǎng)絡(luò)為基礎(chǔ)(VGG16結(jié)構(gòu)如圖2所示),保留VGG網(wǎng)絡(luò)出色的特征提取能力的同時去除全連通層及第5池化層,并將輸出層與卷積層相連,對獲取的各層特征進行輸出,HED網(wǎng)絡(luò)示意如圖3所示。

圖2 VGG16網(wǎng)絡(luò)結(jié)構(gòu)Fig.2 VGG16 network structure
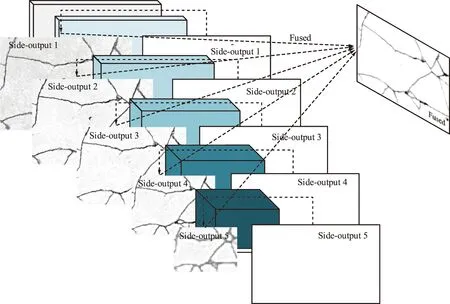
圖3 HED網(wǎng)絡(luò)示意Fig.3 HED network structure
全連通層的去除使模型可以對任意大小的圖片進行訓(xùn)練和預(yù)測,同時減少了訓(xùn)練所需的參數(shù),顯著降低了訓(xùn)練所需的時間以及模型的大小和計算量,且對精度影響忽略不計。去除最后一個最大池化層增大了特征圖的感受野,使得特征圖分辨率較低的問題得到了改善。
由于CNN的特性,低層卷積所獲取的特征具有更高的分辨率以及更清晰的邊緣細節(jié),但由于經(jīng)過的卷積較少,其噪聲更多且分割性不足;高層特征具有更強的語義分割信息且抗噪能力更強,但由于經(jīng)過多層池化后分辨率較低,分割細節(jié)不足。HED網(wǎng)絡(luò)通過將每層卷積獲取的特征圖輸出,并在側(cè)輸出層對特征信息加以深度監(jiān)督,在最后以Concat融合,使最后得到的結(jié)果與不同層的結(jié)果連接起來,低層信息與高層信息實現(xiàn)互補,達到優(yōu)化邊緣的目的。
2.2 改進模型結(jié)構(gòu)
本文算法結(jié)構(gòu)如圖4所示,算法以VGG19網(wǎng)絡(luò)作為基礎(chǔ),使用VGG19的前16個卷積層作為基礎(chǔ)卷積層,增加BN單元,去除全連通層及第5池化層。去除全連通層可以使模型訓(xùn)練所需的參數(shù)及訓(xùn)練時間顯著降低,且對精度的影響可以忽略不記;第5層池化后輸出面太小,輸出的預(yù)測特征圖過于模糊,無法生成精細的預(yù)測結(jié)果,不利于邊緣的定位。每個卷積層由卷積單元、BN單元及ReLU組成,卷積單元產(chǎn)生特征映射;ReLU計算激活函數(shù)Max(0,x)使網(wǎng)絡(luò)可以學(xué)習非線性任務(wù)。去除第5池化層后,池化由4個最大池化層完成,每個階段的最大池化都在部分卷積層(包括Conv1_2,Conv2_2,Conv3_4和Conv4_4)之后進行,通過2 pixel×2 pixel的最大池化來減小平面的大小,這樣可以減少網(wǎng)絡(luò)的參數(shù)且可以提高平移不變性。側(cè)輸出層為每層卷積層所得到的特征圖組成,除第一側(cè)輸出層外,其余側(cè)輸出層后均添加反卷積層對特征圖的平面大小進行上采樣,使其與輸入圖像相同。隨著側(cè)輸出層變小、接收場尺寸變大,最終輸出層獲得多尺度、多層次的特征。

圖4 算法結(jié)構(gòu)Fig.4 Algorithm structure diagram
對于CNN所獲取的特征圖,低層特征對裂縫邊緣的分割更為清晰,但對噪聲很敏感;高層特征抗噪能力較強,但分割邊緣較模糊。每層卷積層輸出圖像如圖5所示。本文通過線性融合不同階段的特征來解決這個問題,以第一側(cè)輸出層(Conv1_2所輸出的側(cè)輸出層)為導(dǎo)向圖,結(jié)合Concat融合后獲取融合特征圖進行引導(dǎo)濾波,去除了低層特征中含有的噪聲且良好地保留了識別的裂縫區(qū)域,實現(xiàn)較為精細的預(yù)測。

圖5 各卷積層輸出圖像示例Fig.5 Output images of each convolution layer
模型結(jié)構(gòu)的各層細節(jié)如圖6所示,各卷積層核大小均為3,步數(shù)為1;最大池化層核大小為2,步數(shù)為2;側(cè)輸出層核大小為1,步數(shù)為1;接收場核大小為2n+1,步數(shù)為2n。

圖6 卷積網(wǎng)絡(luò)模型細節(jié)Fig.6 Details of convolutional network model
2.3 損失函數(shù)
對于本文模型,S={(In,Yn),n=1,2,…,N}為輸入訓(xùn)練集,圖像樣本In={ij(n),j=1,2,…,|In|}為原始輸入圖像,Yn={yj(n),j=1,2,…,|In|},Yj(n)∈{0,1},由于本文獨立考慮每個圖像,在隨后的公式中刪除了下標n使表示更為簡單。目標是建立一個可以生成接近于Ground Truth的裂縫特征圖,使用DSN監(jiān)督側(cè)輸出層,每個側(cè)輸出層與一個分類器相關(guān)聯(lián),權(quán)重w={w(1),w(2),…,w(M)}(M為側(cè)輸出層的層數(shù),本文取M=4),W為網(wǎng)絡(luò)所有參數(shù)。側(cè)輸出層損失函數(shù)Lside:
(1)
式中,P(m)為第m側(cè)輸出層的預(yù)測結(jié)果;αm為各側(cè)輸出層的損失權(quán)值,依據(jù)訓(xùn)練效果進行調(diào)整。
在模型訓(xùn)練中,設(shè)定的交叉熵函數(shù)Δ為:
(2)

經(jīng)過各側(cè)輸出層預(yù)測圖進行Concat融合生成最終特征圖,其融合損失Lfuse為:
(3)
綜上,總損失函數(shù)L為:
L=Lside(I,Y,W,w)+Lfuse(I,Y,W)。
(4)
3 多數(shù)據(jù)集對比實驗
實驗用GPU為Nvidia RTX 2070,系統(tǒng)環(huán)境為Windows10,Python3.6,Pytorch1.8.1。
3.1 數(shù)據(jù)集
實驗采用了多場景不同分辨率的RGB圖像作為數(shù)據(jù)集進行訓(xùn)練,圖像由手工標注分割為二值圖像,用以評測精準度指標。墻面表面材質(zhì)光滑,混凝土及瀝青等材料表面較為粗糙且裂縫較大時往往伴隨有坑洞,所以多樣性的數(shù)據(jù)集可以增強模型的適用能力,在多方面的識別中取得較好的結(jié)果。
本文所采用數(shù)據(jù)集來自于路面、橋梁以及墻體裂縫等多個場景,包括混凝土、瀝青以及水泥等不同材質(zhì),如圖7所示。各類裂縫分辨率及數(shù)量等具體數(shù)據(jù)如表1所示。

圖7 數(shù)據(jù)集樣圖Fig.7 Sample dataset diagram
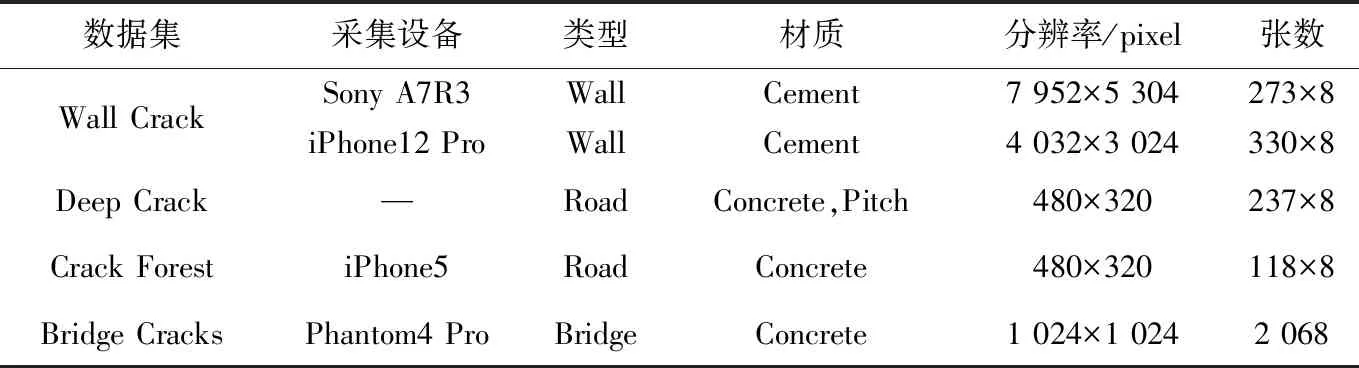
表1 數(shù)據(jù)集統(tǒng)計詳情Tab.1 Dataset statistics details
由于部分數(shù)據(jù)集圖片數(shù)量較少,故采用數(shù)據(jù)增強的辦法,每張圖片每旋轉(zhuǎn)45°即可將數(shù)據(jù)集增加一倍,翻轉(zhuǎn)7次后可以得到比原先擴大8倍的數(shù)據(jù)集以滿足模型需要。將數(shù)據(jù)集以6∶2∶2分為訓(xùn)練集、測試集和驗證集用于識別模型訓(xùn)練和測試。
3.2 評價指標
3.2.1 模型評價指標
針對模型預(yù)測精準度的評價,本文選取語義分割模型常用的精準率-回歸率曲線(Precision-Recall Curve)作為評價指標,其計算方式為:
(5)
(6)
式中,TP為正確分類的正像素;FP為錯誤分類的正像素;FN為錯誤分類的負像素。
精準率-召回率曲線如圖8所示,多用于在深度學(xué)習中評判模型的性能。
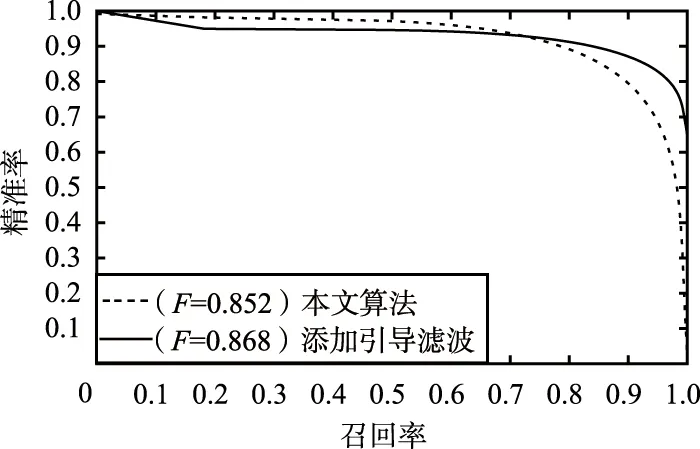
圖8 精準率-召回率曲線Fig.8 Precision-Recall (PR) curve
由圖8可以看出,隨著召回率的增加,添加引導(dǎo)濾波的模型在后期優(yōu)于未添加濾波的模型,且添加引導(dǎo)濾波后的加權(quán)調(diào)和平均值F也大于未添加濾波的原模型,證明了添加引導(dǎo)濾波對模型性能的提升。
3.2.2 分割結(jié)果評價
針對分割結(jié)果的評價,選取mIoU和每秒鐘可處理幀數(shù)(Frames Per Second,F(xiàn)PS)這2種指標作為評價標準,同時這2種指標也是當前語義分割方向較常采用的標準度量指標。
mIoU通過計算真實值和預(yù)測值的交并集之比來評價算法精度,即:
(7)
式中,k為類別個數(shù);θij為原本屬于第i類結(jié)果卻被分到第j類的像素的數(shù)量。
FPS用于評價算法計算的速度,計算公式為:
(8)
式中,N為圖像數(shù)量;Tj為處理第j張圖像的時間。
3.3 實驗結(jié)果及精度分析
為了驗證深度學(xué)習算法對傳統(tǒng)計算機視覺算法的優(yōu)越性,選取AutoCrack[17]網(wǎng)絡(luò)作為對比算法之一;為了驗證本文算法在精度及運算速度上的優(yōu)越性,選取U-Net[18]和SegNet[19]網(wǎng)絡(luò)加以優(yōu)化后作為對比算法;同時,為了驗證引導(dǎo)濾波對計算的優(yōu)化,將算法原始結(jié)果及加入引導(dǎo)濾波后的結(jié)果也作為對比之一加入對比評價。各算法預(yù)測結(jié)果對比如圖9所示。

圖9 算法預(yù)測結(jié)果對比Fig.9 Comparison of algorithm prediction results
由于本文數(shù)據(jù)集場景復(fù)雜,實驗檢驗精度時將數(shù)據(jù)集圖片分開檢測后混合檢測,以獲得每種算法在獨立數(shù)據(jù)集及混合數(shù)據(jù)集上的檢測精度,具體精度評價如表2所示。由于本文數(shù)據(jù)集分辨率差異較大,導(dǎo)致識別時所耗費時間差異較大,故在計算處理速度時將不同數(shù)據(jù)集分開評價后混合評價,處理速度對比評價如表3所示。
由圖9、表2和表3可以看出,本文算法相較目前其余算法具有一定的優(yōu)越性。相較于傳統(tǒng)視覺方法精度及處理速度有明顯提升,且分割的連續(xù)性有較大優(yōu)勢;相較于U-Net算法,本文算法在處理速度相近的同時分割精度提升較大,對噪聲的抵抗性更好;相較于SegNet算法,本文算法在處理速度及分割精度方面均有較大提升,且分割邊緣更為明確;對于未進行濾波的分割結(jié)果,僅犧牲了很少的效率就得到了更為精準且貼近Ground Truth的分割圖像,且邊緣更為清晰。

表2 分割精度評價表Tab.2 Segmentation precision evaluation sheet

表3 處理速度評價表Tab.3 Processing speed evaluation sheet
4 結(jié)束語
本文通過對HED網(wǎng)絡(luò)進行改進,在多個數(shù)據(jù)集上進行訓(xùn)練及測試,最終在單獨數(shù)據(jù)集和混合數(shù)據(jù)集上均驗證了本文算法在分割精準度和速度上的優(yōu)勢。由對比結(jié)果可以看出,本文算法在針對高分辨率的圖像時有明顯的精度優(yōu)勢,并且引導(dǎo)濾波的加入可以在處理速度影響不大的情況下將分割精度提升約6%。綜上所述,本文算法在多種數(shù)據(jù)集上的處理結(jié)果都具有優(yōu)勢,可以適用于多種場景下裂縫分割任務(wù),尤其適用于高分辨率圖像進行分割識別;且由于算法特性,日后可將其應(yīng)用于高分辨率的遙感影像中,可以在保證較快處理速度的同時取得較高的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
