車貨匹配中考慮注意力機制的基于SENet雙塔模型的司機點擊率預測模型
2022-11-02 02:55:22王成浩合肥工業大學管理學院安徽合肥230009
物流科技 2022年10期
方 芳,王成浩 (合肥工業大學 管理學院,安徽 合肥 230009)
0 引 言
車貨信息不對稱的問題在車貨匹配平臺出現后得到了有效的緩解,但是貨源和車源數量在不斷增加,因此車貨匹配平臺也承受著越來越大的壓力。然而,隨著機器學習和深度學習的發展,大量的車貨源數據也為車貨匹配帶來了新的機會,通過對數據的分析處理,可以實現更加精準的車貨匹配。因此,越來越多的研究人員開始從大規模數據的角度去探索新的車貨匹配方法。
在大數據時代,伴隨著機器學習和深度學習的浪潮,研究人員進行了以下探索。黃美華等人通過網頁爬蟲采集到車貨匹配平臺中真實的歷史數據,并利用C4.5決策樹算法建立車貨匹配模型,所建模型能夠達到較高的匹配精確度;在此基礎上,黃美華等人運用最小二乘支持向量機建立車貨信息匹配模型,在保持匹配精確度的同時,縮短了一半的計算時間。Tian等考慮到目前研究理想環境、小數據集、靜態匹配和匹配效率低等方面的局限,提出了一種基于改進動態貝葉斯網絡的車貨匹配算法,并利用從物流行業大數據平臺中獲得的數據進行驗證,證明了該方法能夠提高車貨匹配的效率,同時為中小型物流企業的車貨匹配提供理論參考。周夏考慮了“滴滴打車”的模式,在不平衡數據的二分類問題的實驗背景下,利用集成學習的方法建立車貨匹配預測模型,并利用P平臺的大規模數據進行驗證,為車貨匹配的預測研究提供參考與借鑒價值。肖斌在虛擬環境中具體定義了車貨匹配問題的半馬爾科夫過程,并基于深度前饋網絡設計了深度Q網絡算法,有效地提高了車貨匹配的效率。從這些研究中可以看出,機器學習和深度學習方法逐漸被應用于車貨匹配中,并且具有很好的效果。
推薦系統中常用的模型之一就是雙塔模型,其運用了深度學習的方法,具有快速篩選海量數據和準確度較高的優勢,因此被廣泛地應用在搜索、廣告等領域。DSSM(Deep Structured Semantic Model)模型由微軟于2013年提出,這便是最早的雙塔模型,其通過搜索引擎里文檔和查詢的海量點擊曝光日志,用DNN深度網絡將文檔和查詢表達為低維語義向量,并通過余弦相似度來計算兩個語義向量的距離,最終訓練出語義相似度模型。視頻召回雙塔模型是YouTube于2019年提出的,通過計算用戶和候選視頻的相似度,為用戶推薦其可能感興趣的視頻。莫比烏斯模型是由百度在2019年提出的,通過計算用戶查詢和廣告之間的相似度,生成推薦序列。統一嵌入模型是Facebook在2020年提出的,通過計算查詢和文檔之間的相似度,為用戶提供準確的搜索結果。雙塔模型之所以受歡迎有以下兩個原因,一是雙塔分離的結構使其可以快速篩選海量數據,二是其本身是一個監督學習的過程,能夠提供良好的結果。
因此,考慮到雙塔模型的優勢和車貨平臺中大量的車貨數據,本文將雙塔模型應用到車貨匹配中,提出了一種考慮注意力機制的基于SENet雙塔模型的司機點擊率預測模型——A-SENet雙塔模型。A-SENet雙塔模型主要包括貨物塔、Attention模塊、司機塔和點擊率輸出模塊。在貨物塔中,對貨物的多個特征進行嵌入處理,并進一步通過SENet和DNN計算貨物隱向量。在Attention模塊中,將與司機相關的所有貨物通過Attention機制進行加權求和,為得到更加準確的司機隱向量做準備。在司機塔中,對司機的多個特征進行嵌入處理,并通過SENet進一步處理,與Attention模塊的輸出拼接,一起輸入DNN中計算司機隱向量。最后,通過計算司機隱向量和貨物隱向量的點積,預測司機點擊貨物的概率。基于某車貨匹配平臺的數據集,最終的實驗結果證明了A-SENet雙塔模型的有效性和優越性。
1 基于A-SENet雙塔模型的司機點擊率預測
面對車貨匹配平臺中的大規模車源和貨源數據,雙塔模型在保持匹配精準度的同時,也能提高匹配效率,可以快速篩選數據。當面對司機和貨物大量的特征時,不同特征對點擊率預測的重要性不同,而SENet可以動態地增加重要特征的權重,降低不重要特征的權重。在表示司機向量時,除了利用常規的司機特征,也可以利用歷史點擊貨物的特征,通過Attention機制對點擊過的貨物隱向量進行加權求和,得到更加準確的司機隱向量。下面首先對車貨匹配問題進行形式化描述,然后詳細介紹基于A-SENet雙塔模型的司機點擊率預測。
1.1 車貨匹配問題描述
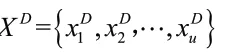
通過司機塔和貨物塔對司機特征和貨物特征加以處理,可以得到司機隱向量和貨物隱向量,從而計算出司機點擊貨物的概率。此時司機點擊貨物的標簽用y表示,其中,y=1意為司機點擊了的貨物,y=0表示司機未點擊的貨物。綜上所述,實驗的最終目標便是預測司機點擊貨物的概率。
1.2 基于A-SENet雙塔模型的司機點擊率預測框架
基于A-SENet雙塔模型的司機點擊率預測框架(如圖1所示),共由四個模塊組成,分別是貨物塔、Attention模塊、司機塔和點擊率輸出模塊。首先,貨物塔通過SENet和DNN得到貨物隱向量。然后,將貨物塔中與司機相關的貨物隱向量通過Attention機制進行加權求和。司機塔中通過SENet對司機特征進行處理。處理后的特征向量與Attention機制加權求和后的向量進行拼接,共同輸入DNN中,得到司機隱向量。最后,司機隱向量和貨物隱向量通過點乘和Sigmoid激活函數,計算出司機點擊貨物的概率。
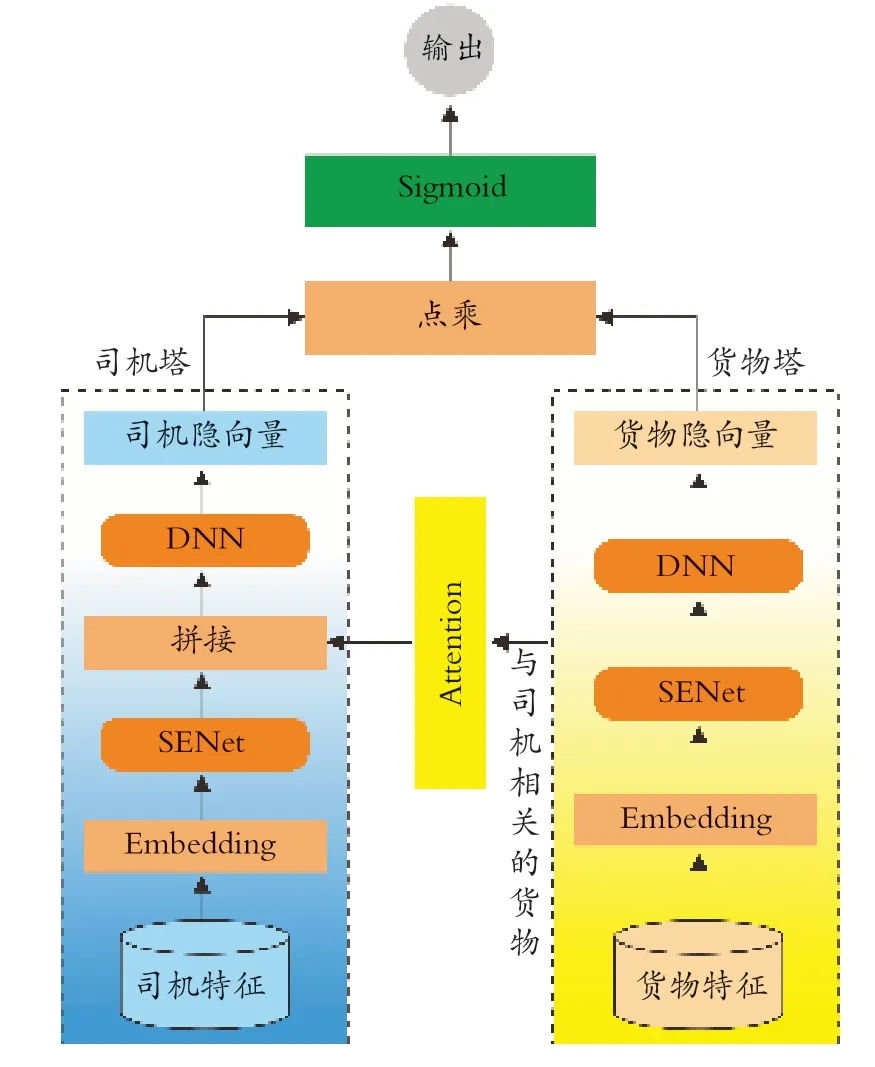
圖1 基于A-SENet雙塔模型的司機點擊率預測框架Fig.1 Click-through rate prediction framework of drivers based on A-SENet two-tower model
1.2.1 貨物塔
在普通的雙塔模型中,將處理后的貨物特征輸入DNN中,可以得到表示該貨物的貨物隱向量。在選取具體特征時,一般是根據相關知識和經驗進行選取,但無法判斷特征的重要性。因此,為了判斷不同特征的重要性,引入SENet機制,可以動態地增加重要特征的權重,降低不重要特征的權重,從而獲取更加準確的貨物隱向量。

不同的貨物特征向量對于貨物隱向量的表示具有不同的重要性,所以引入SENet機制動態地增加重要貨物特征向量的權重,降低不重要貨物特征向量的權重,對嵌入后的貨物特征向量做進一步的更新。SENet機制共分為三步:擠壓階段(Squeeze)、激勵階段(Excitation)、再稱重階段(Re-Weight),接下來描述貨物特征向量通過SENet機制更新的具體過程。
1.2.1.1 擠壓階段

1.2.1.2 激勵階段

1.2.1.3 再稱重階段

通過上述操作,可以得到貨物i的貨物隱向量,同理,可以得到由n個貨物的貨物隱向量構成的貨物塔。
1.2.2 Attention模塊本研究認為司機歷史點擊過的貨物可以表示司機的興趣,所以將貨物塔中與司機相關的貨物抽取出來。但是,點擊貨物的重要性并不完全相同,為了更好地表示不同貨物的權重,利用Attention機制對相關貨物的貨物隱向量分配不同的權重,并進行加權求和,為司機塔中的拼接操作提前做好準備。

α為司機j第c個相關貨物隱向量的權重,S為司機j相關貨物隱向量的綜合表示。
通過上述操作,可以得到司機j相關貨物隱向量的綜合表示,同理,我們可以得到m個司機的相關貨物隱向量的綜合表示。
1.2.3 司機塔
司機塔的操作與貨物塔的操作基本相同,目的是得到司機的隱向量表示。上一節中已經提到,為了得到更加準確的司機隱向量表示,考慮了司機的歷史點擊貨物,并通過attention機制為不同的相關貨物賦予不同的權重,得到相關貨物隱向量的綜合表示。在司機塔中,將其與SENet操作后的司機特征向量進行拼接共同輸入DNN中,得到司機隱向量。

1.2.3.2 激勵階段

1.2.3.3再稱重階段
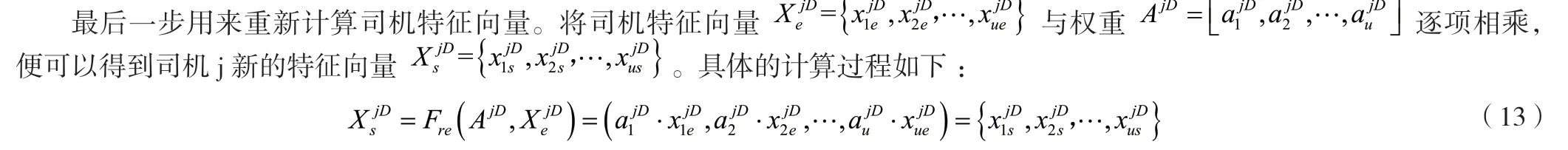

通過上述操作,可以得到司機j的司機隱向量,同理,可以得到由m個司機的司機隱向量構成的司機塔。
1.2.4 點擊率輸出模塊

通過上述操作,可以得到司機j點擊貨物i的概率,同理,可以得到司機塔中任意一個司機點擊貨物塔中的任意一個貨物的概率。
因為司機是否點擊貨物屬于二分類問題,所以選擇負對數似然函數作為目標函數,具體公式如下:
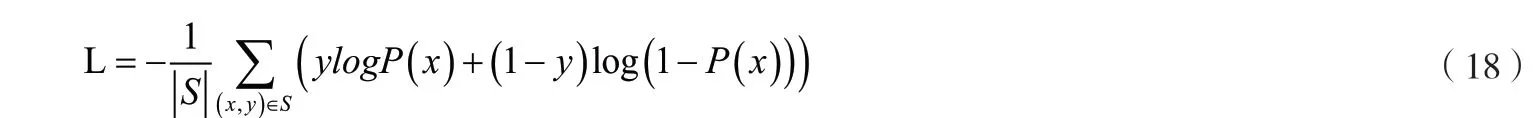
其中S表示總訓練集,x和y分別是網絡的輸入和標簽,()是網絡的輸出,表示司機點擊貨物的概率。
2 實 驗
本節描述了為評估A-SENet雙塔模型的性能而進行的實驗設計,其中包括實驗使用的數據集、評價指標、對比方法和實驗流程。
2.1 數據集
本研究中所使用的數據集是某車貨匹配平臺提供的非公開的司機行為數據集,該數據集包括667名司機和2 208 579個貨物,在這2 208 579個貨物中,包括了與667名司機發生過交互的1 751 673個貨物,而司機的交互行為包括瀏覽貨物、點擊貨物和打電話,由于瀏覽貨物的行為占司機行為中的絕大多數,所以認為瀏覽貨物屬于未點擊行為,即負樣本;點擊貨物和打電話屬于點擊行為,即正樣本。在貨物塔中所使用的也是這1 751 673個貨物。為了保證實驗的真實性,還進行了數據處理工作。具體來說,就是刪除歷史行為不超過100次和點擊行為次數不超過10次的司機。因此,最終的實驗數據集包括582名司機和1 105 719個貨物。
2.2 評價指標
本研究選擇了兩種評價指標來評估我們的方法,如下所示:
AUC(Area Under Curve)是點擊率預測領域常用的評價指標,將樣本根據預測點擊率由大到小排列,然后隨機抽取一個正樣本和一個負樣本,正樣本排在負樣本前的概率即為AUC。計算公式如式(19)所示,表示從正樣本集合中隨機抽取的樣本,表示從負樣本集合中隨機抽取的樣本,和分別表示正負樣本的數量, ()表示樣本i的預測點擊率的排名。AUC的上限是1,結果越大表示性能越好。
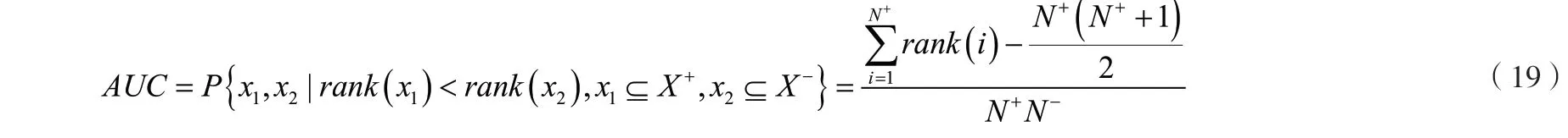
LogLoss(Log-likelihood Loss)用交叉熵來度量每個樣本的預測概率和實際標簽之間的距離。計算公式如式 (18)所示,LogLoss值越低,表明與實際標簽的偏差越小,性能越好。
2.3 對比方法
為了驗證所提出的A-SENet雙塔模型的性能,與LR、雙塔模型、DNN、SENet雙塔模型、DeepFM方法進行了比較。其中,LR是非DNN方法,其他是基于DNN的方法。具體來講,DNN是單模型,雙塔模型、SENet雙塔模型和DeepFM是雙組合模型。每個方法的介紹如下:
LR (Logistic Regression,邏輯回歸)是用于點擊率預測的多字段分類數據的最廣泛使用的模型,它執行基本形式的邏輯函數來模擬二元因變量。
雙塔模型是在推薦系統召回和粗排環節中廣泛應用的模型,雙塔的結構使其能夠快速篩選海量數據。
DNN是一個標準的深度神經網絡,只包括用于預測的嵌入層和MLP層。
SENet雙塔模型在雙塔模型的基礎上,在左右雙塔均添加了SENet模塊,動態地表示不同特征的重要性,在不影響雙塔模型速度的前提下,增加了雙塔模型的準確度。
DeepFM由Deep部分和FM部分組成,能夠同時學習低階和高階特征的交互。
2.4 實驗流程
使用PyTorch實現本文提出的方法和所有的對比方法。采用60%的數據集作為訓練集來學習參數,20%的數據集作為驗證集來調整超參數,20%的數據集作為測試集來評估性能。對于所有的實驗模型,默認使用Adam作為優化器,學習率初始為0.001。神經網絡的隱藏層設定為與嵌入維度相同,Batch size設為64。使用Dropout來防止神經網絡中的過擬合。根據經驗,設置如下超參數:在{32,64,128,256,512}中測試嵌入維度,在{0.1,0.3,0.5,0.7,0.9}中測試Dropout比率。
3 討 論
本節將A-SENet雙塔模型與對比方法進行比較以評估性能,同時探討了嵌入維度和Dropout比率對模型的影響。因為在對比方法中有雙塔模型和SENet雙塔模型兩種,關于SENet模塊和Attention模塊的必要性可以根據實驗結果證明,所以在本節中沒有做消融實驗。
3.1 結 果
實驗結果如表1所示,所有實驗結果都是通過5次實驗以平均值報告的。從表1中可以發現,不論是AUC指標,還是LogLoss指標,A-SENet雙塔模型是優于其他對比方法的。具體來說:
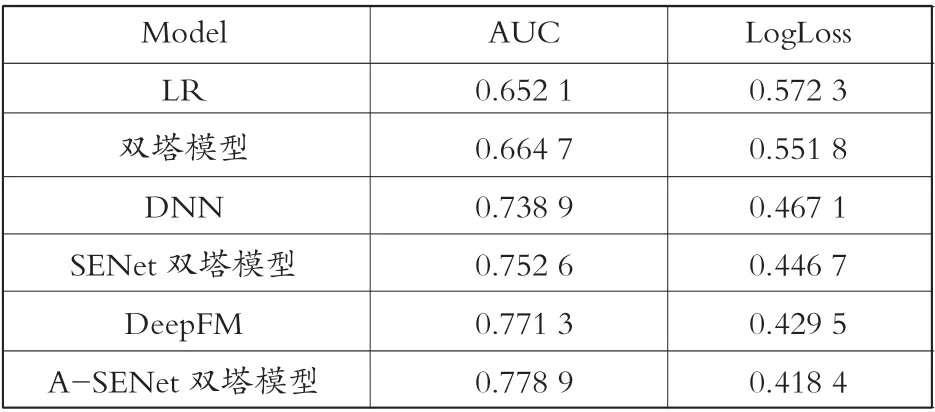
表1 AUC和LogLoss下的方法性能比較Table1 Performance comparison of methods by AUC and LogLoss
LR的結果最差,說明非DNN的方法相比DNN的方法還是要差一些,即使在準確度上不占優勢的雙塔模型,其AUC和LogLoss結果相比LR也分別有1.26%和2.05%的改進,這也表明深度學習模型的非線性泛化能力有助于預測司機點擊貨物的概率。
DNN的AUC和LogLoss結果要優于雙塔模型,雖然雙塔模型包含兩個DNN模塊,但是每個DNN模塊只服務于司機特征或貨物特征,而DNN輸入的為司機特征和貨物特征,能夠捕捉到司機和貨物交互的特征,這表明司機特征和貨物特征的交互有助于預測司機點擊貨物的概率。
SENet雙塔模型的AUC和LogLoss結果要優于DNN,雖然沒有融合司機特征和貨物特征,但SENet模塊的添加使司機特征和貨物特征的權重進行了動態調整,增加了重要特征的權重,能夠得到更加準確的司機隱向量和貨物隱向量,這表明SENet的使用有助于預測司機點擊貨物的概率。
DeepFM的AUC和LogLoss結果要優于SENet雙塔模型,DeepFM實現了司機特征和貨物特征的低階和高階交互,相比之前增加了特征的低階交互,這表明同時進行高階和低階特征的交互有助于預測司機點擊貨物的概率。
A-SENet雙塔模型的AUC和LogLoss結果要優于DeepFM,因為A-SENet雙塔模型通過Attention機制將司機的相關貨物加權求和,加強了司機隱向量的表示,這表明Attention和SENet的同時使用有助于預測司機點擊貨物的概率。
僅從雙塔模型的角度考慮,即同時考慮雙塔模型、SENet雙塔模型和A-SENet雙塔模型這三種方法。首先,從結構方面,雖然對普通的雙塔模型進行了結構的調整,但整體思路不變,仍是得到司機隱向量和貨物隱向量,這表明結構復雜度的增加并沒有影響模型處理數據的效率。其次,從結果來看,相比雙塔模型,SENet雙塔模型在AUC和LogLoss方面分別獲得了8.79%和10.51%的改進,這表明了SENet模塊的必要性。同理,A-SENet雙塔模型相比SENet雙塔模型也有一定的改進,這也表明了Attention模塊的必要性。綜上所述,融合了SENet和Attention的雙塔模型不僅保留了處理車貨數據的高效率,還提高了預測司機點擊貨物概率的準確度。
3.2 嵌入維度的影響
在這一小節,研究嵌入維度對模型性能的影響。具體來說,在保持其他參數固定的情況下,嵌入維度在{32,64,128,256,512}的集合中搜索。圖2顯示了不同嵌入維度下雙塔模型、SENet雙塔模型和A-SENet雙塔模型在AUC和LogLoss方面的比較結果。從圖2中可以看到,隨著嵌入維度的增加,方法性能呈現先上升后下降的趨勢,嵌入維度為128時AUC和LogLoss取得最好的結果。這一結果表明較大的嵌入維度可以包括更多有用的特征,然而嵌入維度如果設置得過大,整個模型會更加復雜,容易遭受過擬合問題,從而導致模型性能下降。因此,選取嵌入維度為128。
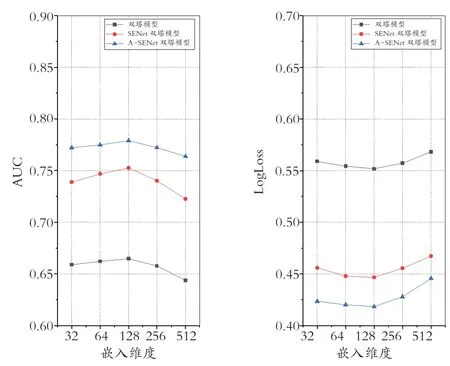
圖2 不同嵌入維度下的方法比較結果Fig.8 The comparison results of methods at different embedding size
3.3 Dropout比率的影響
深度學習方法總在遭受擬合問題的困擾。Dropout是一種通過在訓練過程中隨機丟棄神經元來緩解過擬合問題的有效策略。所以,在這一小節來研究Dropout比率對模型性能的影響。具體來說,在保持其他參數固定的情況下,Dropout比率在{0.1,0.3,0.5,0.7,0.9}的集合中搜索。圖3中展示了不同Dropout比率下雙塔模型、SENet雙塔模型和A-SENet雙塔模型在AUC和LogLoss方面的比較結果。從圖3中可以看到,方法性能呈現先上升后下降的趨勢,Dropout比率為0.3時AUC和LogLoss取得最好的結果。這一結果表明丟棄較多的神經元會損失過多的信息,導致模型的性能降低,而丟棄較少的神經元又無法有效地解決過擬合問題。因此,選取Dropout比率為0.3。

圖3 不同dropout比率下的方法比較結果Fig.9 The comparison results of methods at different dropouts
4 結 語
文章以車貨匹配平臺中的大規模數據為切入點,結合深度學習,提出了考慮注意力機制的基于SENet雙塔模型的司機點擊率預測模型——A-SENet雙塔模型。在雙塔模型的大框架下,利用Attention和SENet對司機特征和貨物特征進行處理,得到司機隱向量和貨物隱向量,進一步計算司機點擊貨物的概率。在某車貨匹配平臺數據集的支持下,經實驗結果證明了該方法的有效性和優越性,也證明了利用深度學習方法進行車貨匹配的可行性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
