一種改進密度峰值聚類的欠采樣算法
2022-11-03 07:52:22李鑫
現代信息科技 2022年18期
李鑫
(首都經濟貿易大學,北京 100026)
0 引言
作為數據挖掘領域的研究熱點之一,分類問題的研究已發展得非常成熟,諸多的分類算法被提出,如:決策樹、支持向量機、邏輯回歸等。這些算法在傳統的分類問題中通常都具有良好的表現效果。在實際應用中,數據不平衡現象出現的頻率越來越高,很多情況下少數類樣本具有更高的研究價值。比如在癌細胞檢測、信用卡欺詐檢測、網絡入侵檢測等領域都存在著數據不平衡問題,如果錯分少數類將帶來嚴重的后果。而傳統的分類方法很少顧及少數類的分類精度。因此,針對不平衡數據研究如何提高少數類樣本的分類精度具有重要的意義。目前,針對不平衡數據分類問題的研究主要分為數據層面和算法層面兩大方向。數據層面是通過對數據集進行重抽樣來構建平衡數據集,主要有欠采樣和過采樣兩大類。算法層面主要是通過改變少數類樣本的權重來提高分類器對少數類樣本預測的精度。本文基于數據層面的欠采樣方法開展研究,提出了一種新穎的平衡數據集獲取方法以提高分類器對少數類的預測精度。
最簡單的欠采樣方法是隨機欠采樣(RUS),它是在多數類數據集中隨機地刪除一部分樣本。編輯最近鄰規則(ENN)考慮了樣本重要性,在少數類的鄰近樣本中刪除一部分多數類;壓縮最近鄰規則(CNN)在ENN 的基礎上對決策邊界上的樣本點給予了更多地關注。后來又有學者提出TomekLinks算法,利用Tomek 對來識別數據集中對分類造成干擾的噪聲點。聚類算法能夠根據相似性對樣本進行劃分,YEN 等將K-means 聚類算法應用到欠采樣中,先對多數類樣本進行聚類,再從每個簇中按照一定比例進行抽樣,從而減少冗余樣本。由于K-means 算法假設較強,僅適用于超球形簇,并且對異常值敏感,崔彩霞等將密度峰值聚類應用到欠采樣并取得了良好的效果。密度峰值聚類算法是一種基于密度的聚類方法,它根據樣本的密度分布來進行聚類,不僅可以檢測到噪聲點而且適用于任意形狀的簇。
基于以上研究,本文提出一種改進密度峰值聚類的欠采樣算法(Udersamp lingbasedon Density Peak Entropy Clustering,DPEC),首先利用信息熵對密度峰值聚類算法進行改進,優化聚類效果;然后用改進算法對多數類聚類,將少數類樣本數量作為聚類中心數,并選取密度距離較大的樣本點作為聚類中心;最后用所有聚類中心代替原始多數類數據集,既保留了樣本重要信息又可以消除噪聲樣本從而提高數據集的質量,優化不平衡數據的分類性能。
1 改進密度峰值聚類的欠采樣方法
1.1 密度峰值聚類
密度峰值聚類算法(Density Peak Clustering,DPC)是利用樣本的密度分布來進行聚類,適用于任意形狀的簇,該算法的核心思想建立在兩個假設上:簇類中心的局部密度大于其鄰近樣本點的局部密度;簇類中心點之間有著相對較大的距離。通過計算每個樣本的局部密度和偏移距離對每個點進行簇的劃分,聚類中心的選取通常通過繪制以局部密度為橫軸,偏移距離為縱軸的決策圖來人為主觀選取。當聚類中心后,剩余樣本點將分配給與其最近且具有更高密度的簇中。假設數據集為={,,…,x}T,其中為數據集的樣本數,對于每一個樣本x,其局部密度ρ為:

其中d是樣本x與樣本x的歐氏距離;d為截斷距離,需要人為事先設定,通常d設置為將樣本點間距離進行降序后排列在2%的值。
樣本點x的偏移距離δ被定義為該樣本點到具有更高局部密度的點的最小距離:

1.2 信息熵
熵是信息論中量化系統信息含量的指標,熵越大,系統的不確定性越大。信息熵通常用來衡量數據所含信息量的大小,事件發生的概率越高,其攜帶的信息量越低。信息熵定義為:
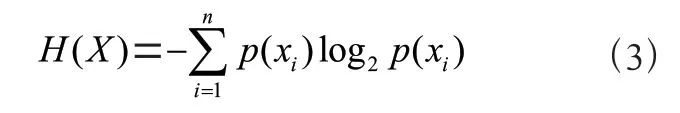
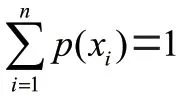
1.3 改進密度峰值聚類的欠采樣算法
聚類算法能夠將相似樣本盡可能地分在同一個簇,且不同簇的差異性盡可能大。將聚類算法應用到不平衡數據集的欠采樣中,能夠抽取到更具有代表性的樣本,消除冗余樣本。密度峰值聚類算法利用數據集的密度分布進行聚類,該算法思想簡單,算法復雜度低,并且不易受異常值的干擾。但其截斷距離和聚類中心都需要人為主觀選取,聚類效果還有待提升。本文對其進行優化,使其應用在能夠在不平衡數據集上取得更好的效果,提出了改進密度峰值聚類的過采樣算法(Udersamplingbasedon Density Peak Entropy Clustering,DPEC)。
本文將信息熵與DPC 算法相結合,使算法能夠自動尋找最優截斷距離。信息熵越大,數據分布越混亂,故聚類的效果越差;相反,信息熵越小,聚類效果就越好。因此,使信息熵(d)達到最小時的d就是最優截斷距離,此時的局部密度和偏移距離達到最優值,聚類效果最好。最優截斷距離定義如下:
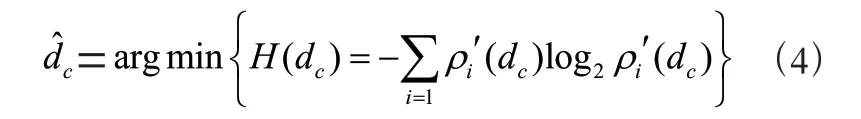


其 中,ρ和δ是ρ和δ歸一化后的值,

1.4 方法步驟
我們將本文提出的改進密度峰值聚類的欠采樣算法(DPEC)的具體步驟總結為算法1,具體為:
算法1 DPEC
輸入:原始數據集;
輸出:新的平衡數據集′。
步驟1:將數據集分為多數類和少數類,計算少數類樣本個數=||;
步驟2:計算每個多數類樣本點x的局部密度ρ和偏移距離δ;



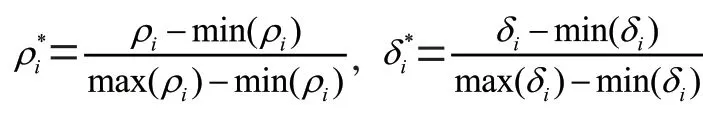

步驟8:將γ最大的前(=||)個樣本點作為聚類中心,選取這些樣本作為新的多數類樣本,并與少數類數據集合并構成平衡數據集′。
2 對比實驗
2.1 性能評估指標
對于二分類問題,通常用混淆矩陣來作為進行評估,其表示如表1所示。

表1 混淆矩陣
對于不平衡數據分類問題,將少數類記為正類,多數類記為負類。本文用F1-score和AUC兩個指標來評估算法效果。


2.2 實驗設置與結果分析
為驗證DPEC 欠采樣算法效果,本文采UCI 數據庫的Abalone 數據集進行實驗。該數據集是UCI 數據庫提供的標準機器學習分類問題數據集,通過利用鮑魚的長度、直徑、內臟重量等屬性來預測鮑魚的性別。該數據集共含有4 177 個樣本,特征數為8 個,其中多數類樣本量為2 870 個,少數類樣本量為1 307 個,不平衡比率為2.2。選擇DPC、K-means、TomekLinks、CNN、NearMiss、RUS 六種欠采樣算法與本文算法進行對比,并在決策樹(CART)、邏輯回歸、支持向量機三種單分類器,隨機森林、Adaboost 兩種集成算法上進行實驗測試其提升效果。本文實驗的運行環境為Jupyter Notebook 軟件,選擇75%為訓練集,選擇25%為測試集進行模型訓練,參數均使用默認參數設置,選擇F1-score 和AUC 值作為評價指標來判斷模型效果。表2 是不同欠采樣方法在各個分類器上模型訓練得出的F1-score 和AUC 值。
表2 DPEC 與其他采樣方法在不同分類器上的效果對比
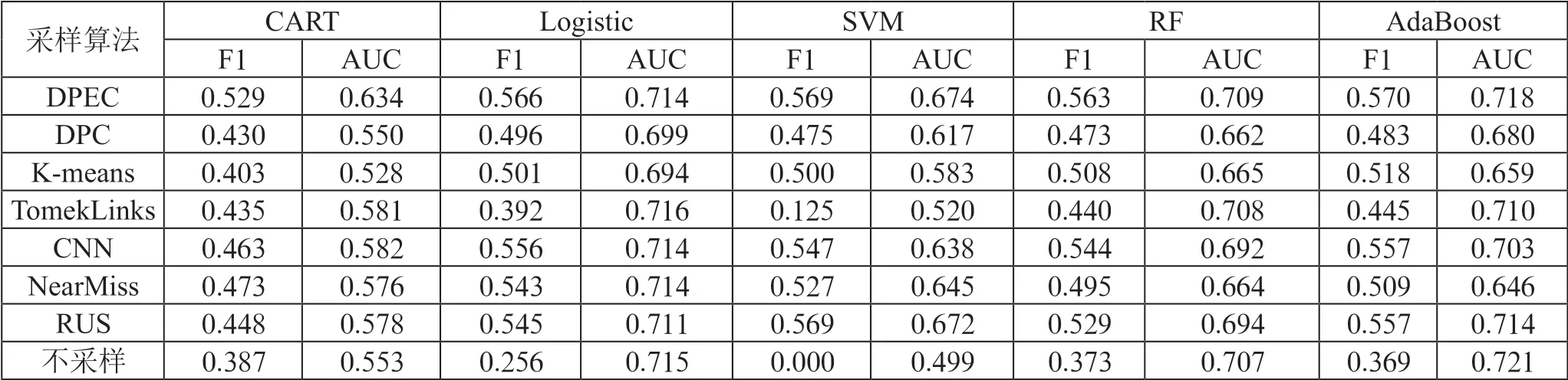
采樣算法 CART Logistic SVM RF AdaBoost F1 AUC F1 AUC F1 AUC F1 AUC F1 AUC DPEC 0.529 0.634 0.566 0.714 0.569 0.674 0.563 0.709 0.570 0.718 DPC 0.430 0.550 0.496 0.699 0.475 0.617 0.473 0.662 0.483 0.680 K-means 0.403 0.528 0.501 0.694 0.500 0.583 0.508 0.665 0.518 0.659 TomekLinks 0.435 0.581 0.392 0.716 0.125 0.520 0.440 0.708 0.445 0.710 CNN 0.463 0.582 0.556 0.714 0.547 0.638 0.544 0.692 0.557 0.703 NearMiss 0.473 0.576 0.543 0.714 0.527 0.645 0.495 0.664 0.509 0.646 RUS 0.448 0.578 0.545 0.711 0.569 0.672 0.529 0.694 0.557 0.714不采樣 0.387 0.553 0.256 0.715 0.000 0.499 0.373 0.707 0.369 0.721
從表2 可以看出,相比于用原始的密度峰值聚類算法(DPC)進行欠采樣,本文改進后的算法(DPEC)在F1 和AUC 值上都有明顯提高。相比于不對數據進行任何處理,本文提出的欠方法(DPEC)顯著提高了少數類的F1 值。與K-means、TomekLinks、CNN、NearMiss 和隨機欠采樣五種常用的欠采樣方法相比,本文算法也有著不錯的效果。總體而言,DPEC 有效提升了不平衡數據集的分類性能。
3 結論
欠采樣是不平衡數據分類常用的重采樣方法之一。本文提出了一種改進密度峰值聚類的不平衡數據欠采樣算法。該算法利用信息熵確定全局最優截斷距離,為克服量綱影響,對局部密度和偏移距離進行歸一化后相乘并進行排序,將少數類數據集的樣本數量作為多數類聚類的聚類中心數,選擇密度距離較大的點作為聚類中心。用這些聚類中心樣本代表整個多數類數據集,從而去除冗余數據保留多數類數據集的重要信息。將本文算法與其他欠采樣算法進行對比實驗,并在決策樹(CART)、邏輯回歸、支持向量機三種單分類器,隨機森林、Adaboost 兩種集成算法上進行實驗測試其提升效果,結果表明,本文算法在一定程度上提高了少數類樣本的預測精度。后續可考慮與過采樣結合對不平衡數據集的混合采樣展開研究。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中華詩詞(2018年11期)2018-03-26 06:41:34
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年8期)2016-10-09 02:11:50
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
