基于改進殘差網絡的低空無人機聲音識別方法
2022-11-15 03:45:04薛珊衛立煒顧宸瑜孟憲宇賈冰
長春理工大學學報(自然科學版) 2022年4期
薛珊,衛立煒,顧宸瑜,孟憲宇,賈冰
(1.長春理工大學 機電工程學院,長春 130022;2.長春理工大學 重慶研究院,重慶 400000;3.西安交通大學 信息與通信工程學院,西安 710049)
隨著現代科技的快速發展,無人機的使用門檻變得越來越低,無人機越來越普遍。由于缺乏統一的行業標準和規范,無人機“黑飛”問題日益嚴重,使得無人機被濫用的可能性大大增加。無人機在低空空域的非合作入侵飛行事件在國內外屢見不鮮,不僅傷害了公民的隱私和生命財產安全,更對公共安全和國家安全構成了極大威脅[1]。因此,對無人機的檢測和識別就顯得尤為重要。
目前為止,無人機的識別方法多種多樣,包括圖像識別[2-3]、雷達數據分析[4-6]以及無線電信號識別[7-9]等方面。圖像識別無人機時,無人機在遠距離上的視覺特征較弱,尺寸較小,易受到遮擋,并且容易受到外在環境的影響。雷達探測主要是運用雷達信號的回波來探測目標,但存在固有的探測盲區,而且價格昂貴、體積大、放射性強,不適合城市環境。出于便利性和經濟性考慮,運用麥克風陣列,這種基于聲學的低空無人機探測識別方法[10-12]正在被越來越多地研究,它不取決于無人機的大小和位置,而是取決于螺旋槳的聲音,可以有效地探測識別無人機[13-15]。如何運用聲音識別無人機,如何能夠更準地識別無人機成為了研究的熱點。
基于此,提出了一種基于殘差網絡改進的低空民用無人機聲音識別方法(Improved Residual Block Network,IRBNet),旨在更準地識別無人機。
1 無人機聲音數據集的建立及特征提取
1.1 無人機聲音數據集的建立
由于目前并沒有開源且成熟的無人機數據集供使用,因此需要建立無人機聲音數據集。
運用聲音采集設備,在現實環境中對實驗無人機聲音進行錄制采集,保證獲得的聲音信號都是真實數據。然后對采集到的音頻數據進行濾波、預加重、分幀、加窗等預處理。將較長的聲音信號分割為4 s的聲音片段,保持50%的重疊,保證最后的無人機聲音片段全部有4 s的持續時間[16]。最終,得到將近600個長度為4 s的無人機聲音片段。之后對聲音樣本進行人工標記,獲得標簽數據。
Urbansound8K 數據集[17]是由 8 732個帶標簽的聲音片段組成的數據集,每個聲音片段具有最大4 s的持續時間。8 732段錄音來自十個聲音類別,它們是汽車喇叭、狗吠、發動機空轉、風鉆、空調、街頭音樂、兒童玩耍、鉆探、槍聲和警笛。
Urbansound8K數據集中的汽車喇叭和兒童玩耍兩種聲音數據被調用以充當無人機數據集中的負樣本。然后把處理過的無人機聲音片段加入其中,構成最終的數據集。數據集中的所有樣本長度都小于等于4 s,共3類。在三類樣本信號中隨機各選取一個片段,其語譜圖及波形圖如圖1所示。
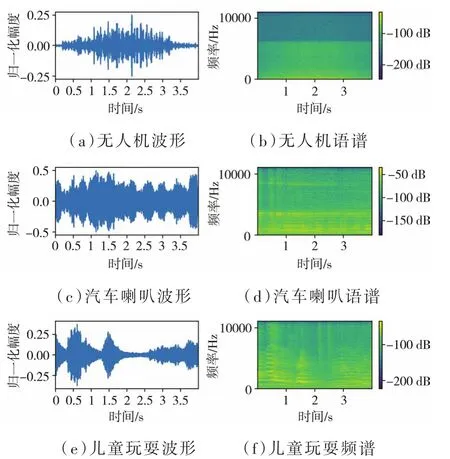
圖1 三類音頻的語譜圖及波形圖
1.2 音頻特征提取
卷積神經網絡識別模型需要輸入選定的特征進行訓練和測試,預測結果。合適的特征不僅可以以非常緊湊的方式模擬信號的屬性,降低運算維度,還可以更精準地表征聲音信號。因此,特征的好壞對網絡模型有著很重要的影響。
常用的表征聲音信號的特征有線性預測倒譜 系 數(Linear Prediction Cepstral Coefficients,LPCC)[18-19]、Log-Mel[20]、MFCC[21-22]以 及 小 波(Wavelet)[23]等。本文研究并比較了 MFCC 和Log-Mel及其一階差分特征,最終采用最合適的提取特征。
MFCC提取過程為:首先對信號進行預加重、分幀、加窗和傅里葉變換;然后計算功率譜,并將功率譜通過三角帶通濾波器進行濾波,輸出結果運用Mel域頻率與線性域頻率間的關系轉換為對數形式;最后進行離散余弦變換(DCT),得到MFCC[24]。其提取流程如圖2所示。
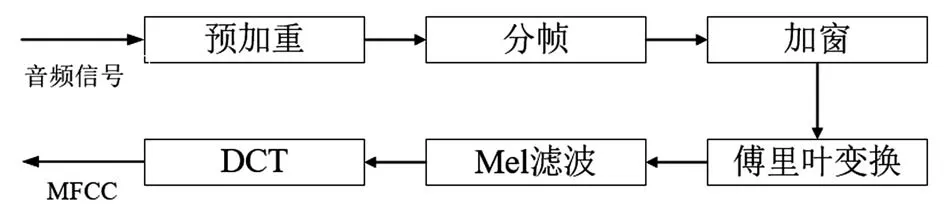
圖2 MFCC提取流程示意圖
Log-Mel特征與MFCC的計算步驟基本一致,區別在于前者少進行一步DCT操作。從計算量上看,MFCC是在Log-Mel特征的基礎上進行的,所以MFCC的計算量更大。從特征區分度上看,Log-Mel特征相關性更高。高斯混合模型(GMM)由于忽略了不同特征維度的相關性,MFCC更適用。而卷積神經網絡(CNN)可以更好地利用這些相關性,使用Log-Mel特征可以更多地降低錯誤指標。故最終采用Log-Mel特征。
由于聲音信號在時域中是連續的,因此通過分割幀提取的特征信息僅反映了該幀信號中聲音的特性。為了使特征更好地反映信號的時域連續性,通常選擇加入其差分特征。本文選擇一階差分作為補充。分別提取Log-Mel特征和MFCC及其一階差分特征矩陣一起作為雙通道提供給網絡。汽車喇叭、兒童玩耍以及無人機信號的其中一個片段的log-Mel譜圖及一階差分譜圖如圖3所示,MFCC及其一階差分的表示見圖4。從特征譜圖中看出每個信號的特征都是特定的,可以被區分。
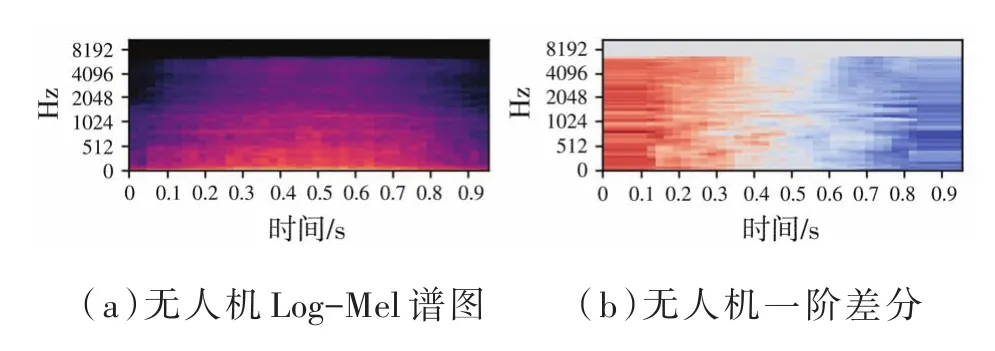
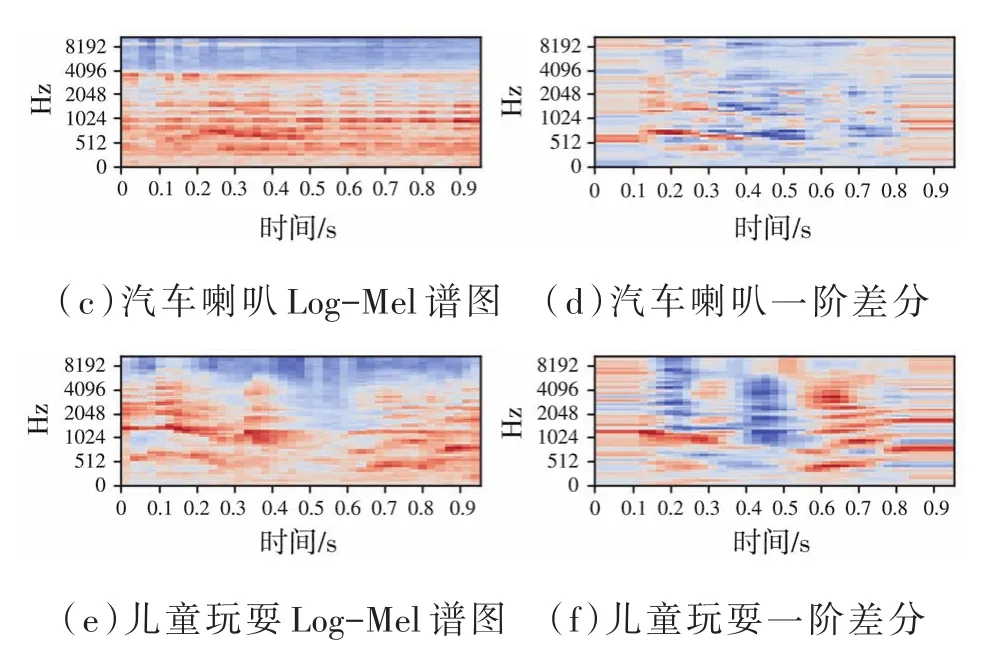
圖3 三類音頻的Log-Mel譜圖及一階差分

圖4 三類音頻的MFCC及一階增量
2 基于殘差網絡改進的卷積神經網絡IRBNet的設計
進行音頻特征提取后,需要設計用于聲音識別無人機的網絡,也就是設計一種聲音識別的算法。目前,在環境聲音識別任務中,運用卷積神經網絡進行識別的方法比較流行[25-26]。基于此,本文基于遠跳連接構建IRTBlock,設計了基于殘差網絡的改進的卷積神經網絡IRBNet,對無人機進行聲音識別。
2.1 設計遠跳連接IRTBlock
輸入x,經過若干層卷積和激活后,得到的輸出F(x),再加上原來的輸入,最終輸出為F(x)+x,這就是遠跳連接(Skip Connection)[27]。它可以解決由于網絡深度增加而導致的網絡退化問題,使得深層網絡的表現優于淺層網絡。基于此,本文構建了如下兩種模塊:IRTBlock-A和IRTBlock-B。這兩種模塊的結構示意圖如圖5所示。其中num_filtes代表設置的過濾器數量;CONV表示卷積層;BN表示批歸一化(Batch Normalization)層[28],它能夠減少內部變量偏移從而加速深度神經網絡的訓練。
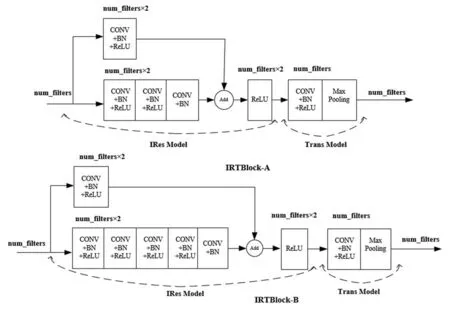
圖5 設計的IRTBlock的結構示意圖
IRTBlock-A:主通路為 1×1 Conv+BN+Re-LU+3×3 Conv+BN+ReLU+3×3 Conv+BN(其 中 1×1 Conv表示核大小為1×1的卷積層);遠跳連接通路為1×1 Conv+BN+ReLU,通過1×1卷積來調整大小,使得維度相等;然后,把兩者的輸出進行逐元素相加(Add)融合,并通過ReLU激活函數來引入非線性,這一部分被稱為IRes-Model;最后,把融合結果在輸入匯聚層之前,運用1×1卷積進行降維,這一部分記作Trans-Model,用于連接各個IRes-Model以及進行特征降維。
IRes-Model中所有卷積層的步長均為1,卷積核數目相同,使用“SAME”填充。因此,各層輸出具有相同尺寸,可以進行Add運算,構成深度融合層(add layer)。模塊中所有卷積層都加入了BN層,用于加快收斂速度。把IRes-Model和Trans-Model統稱為IRTBlock-A.
IRTBlock-B:先進行 1×n卷積再進行 n×1卷積,與直接進行 n×n卷積的結果是等價的[29]。非對稱卷積可以減少網絡參數,降低運算量,加快訓練,而且可以進一步增加網絡的非線性。本文頂層模塊運用非對稱卷積來代替IRTBlock-A中的 3×3對稱卷積,即3×3卷積變為1×3和 3×1的順序堆疊;其余結構不發生改變,與IRTBlock-A一致,被記作IRTBlock-B。
2.2 設計IRBNet網絡
基于IRTBlock-A和IRTBlock-B,構建基于殘差網絡改進的卷積神經網絡IRBNet。其中所有卷積層都加入BN層,來加快收斂速度。除輸出層使用Softmax激活函數外,所有隱藏層都采用整流線性單元(ReLU)激活函數。所有填充均設為“SAME”。網絡結構示意圖如圖6所示,框圖上方數字代表輸出特征圖尺寸大小。“Conv”表示卷 積 層 ;“s”代表 步 長 ;“num_filters”表示 設定的濾波器數量,“FC”表示全連接層。網絡結構參數如表1所示(其中,Maxpool表示最大池化;s表示步長)。詳細結構如下:
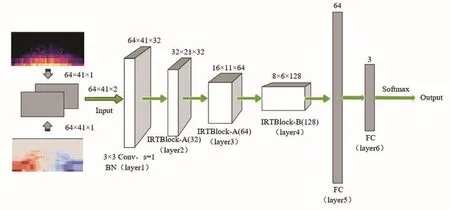
圖6 IRBNet結構示意圖
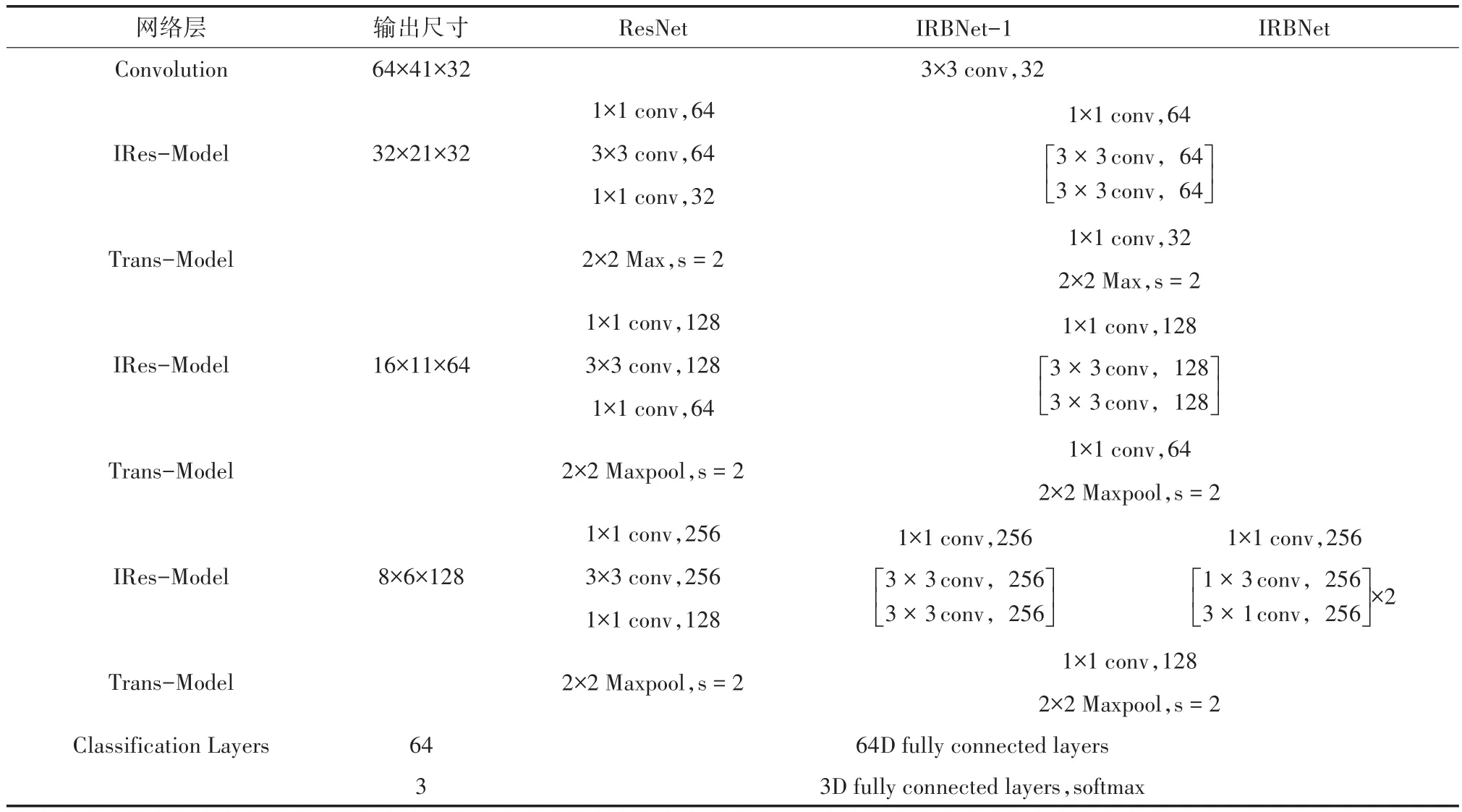
表1 包含IRBNet在內的幾種網絡的結構和參數表
L1:第一層,包含32個核大小為3×3的卷積核,填充設為“SAME”。不使用最大池化。運用ReLU作為激活函數。
L2:第二層,IRTBlock-A,其中“num_filters”設置為32。
L3:第三層,IRTBlock-A,其“num_filters”設置為64。
L4:第四層,IRTBlock-B,其“num_filters”設置為128。
L5:第五層,也是第一個全連接層,由64個隱藏單元組成,其激活函數為ReLU。使用值為0.4的丟棄率來防止過擬合。
L6:第六層,是第二個全連接層,也被稱為輸出層。它的數量等于數據集中的類別總數。該層中使用的激活函數為Softmax。
3 實驗與分析
本研究設置了兩個實驗。第一個實驗重點比較幾種特征的優劣,網絡模型保持一致,均選用設計的IRBNet,旨在找出適合的特征;另一個實驗為了對比本文設計的基于殘差網絡改進的卷積神經網絡IRBNet與其他網絡的優劣性,輸入特征保持一致。
3.1 實驗準備
所有的實驗都是在Python語言環境下完成的,版本為3.7.6。主要運用Keras庫從頭開始訓練網絡,運用Librosa庫實現各種特征提取操作。采用的是Windows10平臺。運行設備CPU型號為i7-9750H,顯卡為GTX1660TiMQ。
實驗中,幾種網絡的優化方法都使用帶有動量的小批量隨機梯度下降(SGD),歷元數設為150,批次大小設為128,動量設為0.9。損失函數均采用交叉熵損失函數。采用指數衰減學習率來提高模型的收斂速度及其泛化能力,以此來獲得更好的效果。加入Dropout層來減輕因數據集小而網絡模型層數較多帶來的過擬合問題。
3.2 幾種特征的對比實驗
本實驗旨在找出合適的特征,故均使用IRBNet作為基準網絡,只改變輸入網絡的音頻特征。方法一:輸入Log-Mel特征及一階差分(雙通道);方法二:輸入Log-Mel特征;方法三:輸入MFCC特征;方法四:輸入MFCC特征及一階差分(雙通道)。實驗結果如表2所示,識別準確率曲線如圖7所示。
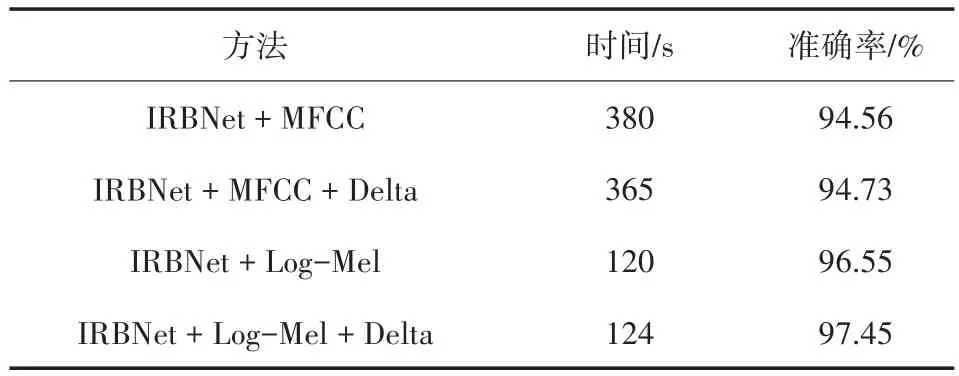
表2 幾種方法的識別精度比較表
從表2和圖7可以看出,選擇Log-Mel特征及一階差分輸入IRBNet時,準確率最高,可以達到97.45%。在時間上,Log-Mel以及其差分組合特征和Log-Mel特征用時少,雖然前者時間略高于后者,但前者準確率要比后者高很多。實驗結果表明,Log-Mel特征及一階差分組合特征的性能最好,故本文選取Log-Mel特征及其一階差分來表征無人機聲音。
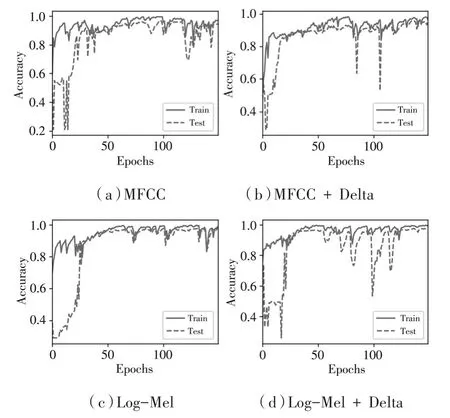
圖7 IRBNet上幾種特征的準確率曲線
3.3 幾種網絡的對比實驗
本實驗旨在驗證本文設計的IRBNet和其他幾種基準網絡的優劣性,輸入特征保持一致。網絡的詳細介紹如下。
3.3.1 基準網絡
設計IRBNet-1作為一種基準網絡,比較兩種IRTBlock對網絡性能的影響。IRBNet-1是把IRBNet的第四層模塊IRTBlock-B用IRTBlock-A代替,其余與IRBNet一致。搭建ResNet作為一種基準網絡,來比較IRBNet與殘差網絡的性能優劣。IRBNet-1和ResNet的結構參數如表1所示。
除此之外,還設計了兩個卷積神經網絡CNN-1、CNN-2作為基準網絡。CNN-1由2個卷積層、2個最大池化層和2個全連接層構成。兩個卷積層中卷積核大小均為5×5,步長為1;池化核大小為2×2,步長為2。第一個全連接層有64個神經元,且使用值為0.4的Dropout來減輕過擬合現象。第二個全連接層即為輸出層。所有填充均設為“SAME”。除輸出層使用Softmax激活函數外,其他層都采用ReLU激活函數。CNN-2只是把CNN-1中5×5大小的卷積變為兩個3×3大小卷積的堆疊,其余結構不進行改變。兩個網絡的結構參數如表3所示。
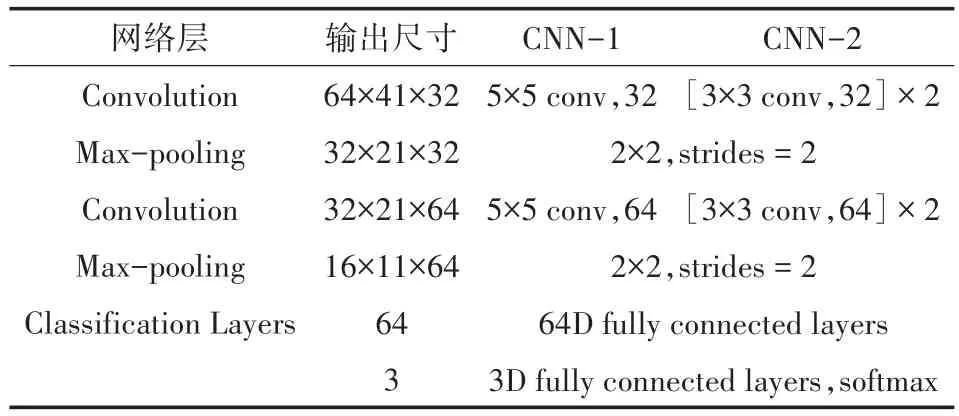
表3 兩個CNN的結構及參數表
3.3.2 實驗結果與分析
本實驗的主要目的是比較幾種基準網絡與IRBNet的性能優劣。幾個網絡同時輸入相同音頻特征(Log-Mel特征及一階差分)。實驗比較了幾種基準網絡與IRBNet在無人機聲音數據集上的識別準確率,其對比統計結果如表4所示。幾種方法的準確率曲線如圖8所示。

表4 幾種方法的識別精度比較表
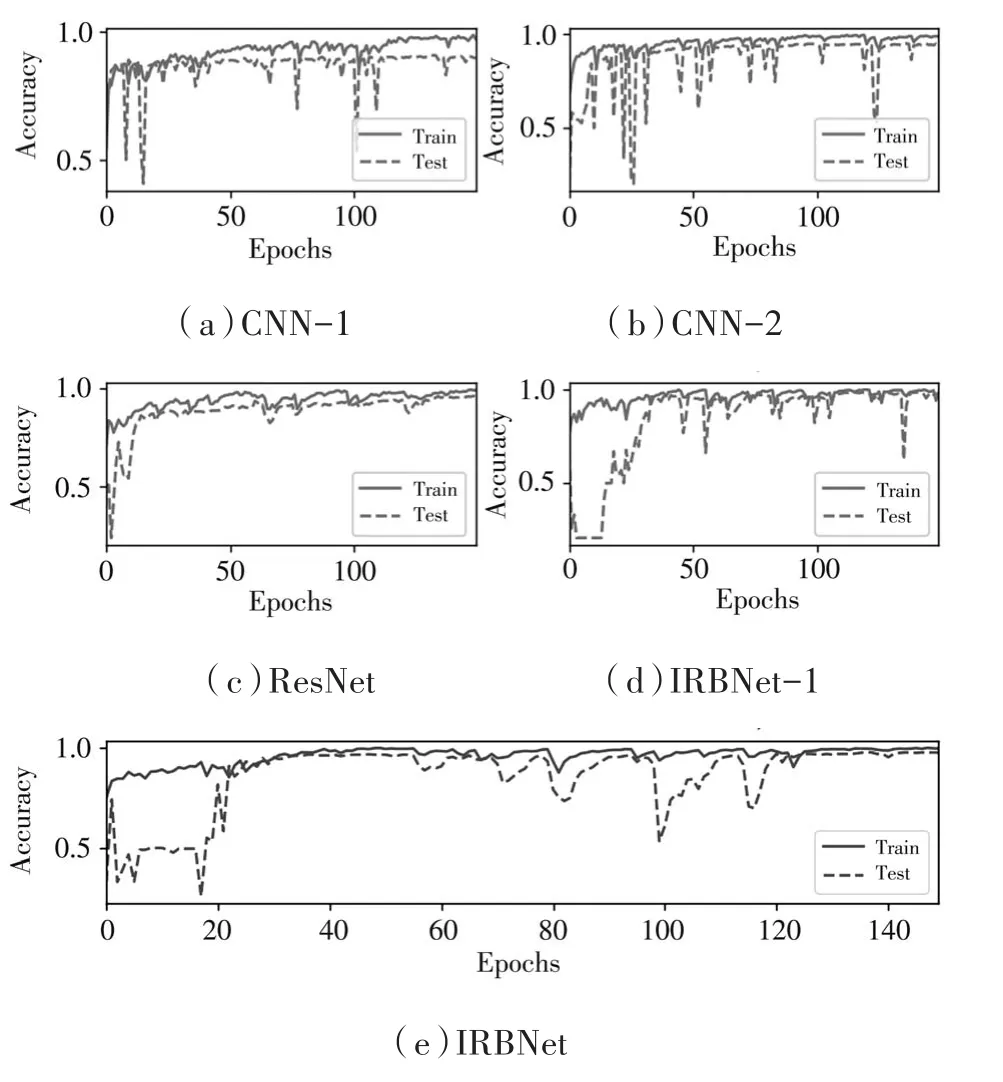
圖8 幾個方法的準確率曲線
從圖8以及表4可以看到,相同特征輸入IRBNet和幾種基準網絡,設計的IRBNet和IRBNet-1準確率更高。其中,IRBNet的準確率最高,可達97.45%。結果表明,非對稱卷積使得網絡的非線性特性增強,使得信息的流通得到了優化,可以學習音頻信號中更多的局部特征,使得對于特征的學習能力增強,從而提高了實驗效果。實驗結果表明,IRBNet的識別準確率最高,性能更好。
4 結論
(1)針對無人機分類識別問題,提出了一種基于殘差網絡改進的卷積神經網絡的低空民用無人機聲音識別方法,即IRBNet。
(2)采集低空無人機聲音數據并進行預處理,得到低空無人機聲音數據集,提取特征參數輸入IRBNet進行識別,實驗結果表明所設計的網絡能夠更準確地識別無人機,其識別精度可以達到要求。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
