通信信號調(diào)制識別綜述
2022-11-16 16:26:10張海燕閆文君張立民李忠超
海軍航空大學(xué)學(xué)報 2022年1期
張海燕,閆文君,張立民,李忠超
(1.海軍航空大學(xué),山東 煙臺 264001;2. 73022部隊,廣東 惠州 516000)
0 引言
在通信發(fā)展初期,信號調(diào)制方式的種類只有固定的幾種,且信號的收發(fā)雙方多是合作方,他們會提前商定所要使用的調(diào)制樣式,不需要對接收到的信號進行識別。隨著網(wǎng)絡(luò)通信技術(shù)的快速發(fā)展,通信管理系統(tǒng)往往會采用多種調(diào)制方案,從而可以使我們更好地利用頻譜資源,滿足爆發(fā)式增長的通信市場需求。對于非合作通信方來說[1-2],要想獲取有用信息,就需要進行調(diào)制識別。如今,無論在軍用還是民用領(lǐng)域,該技術(shù)的應(yīng)用范圍都十分廣泛,如電子對抗、戰(zhàn)時通信偵察、信號干擾、頻譜監(jiān)測等。
通信信號的調(diào)制識別是介于信號檢測和信號解調(diào)之間的1 項技術(shù),本質(zhì)上是1 個模式識別問題。調(diào)制識別最早起源于軍事通信領(lǐng)域,信號的識別大多依靠人工來完成,耗時費力、識別率低。直到1969 年,C.S.weaver等人在斯坦福大學(xué)的某項技術(shù)報告中發(fā)表了首篇關(guān)于研究調(diào)制方式自動識別的論文,從此打開了自動調(diào)制識別(Automatic Modulation Recognition,AMR)的大門。2017 年,美國的國防高級研究計劃局DARPA 資助了“調(diào)制識別之戰(zhàn)”的項目,探索無線電頻譜領(lǐng)域新問題的解決和發(fā)展之道,提出調(diào)制識別是實現(xiàn)“無線態(tài)勢感知”的關(guān)鍵問題,這種發(fā)展態(tài)勢感知可用來預(yù)測頻譜使用的不同情況,實現(xiàn)對稀缺的頻譜資源更為有效地利用[3]。
目前,調(diào)制識別從是否運用深度學(xué)習(xí)的角度可分為經(jīng)典調(diào)制識別和基于深度學(xué)習(xí)的調(diào)制識別。
1 經(jīng)典調(diào)制識別
1.1 基于最大似然函數(shù)的調(diào)制識別
首先,根據(jù)信號模型的統(tǒng)計特征建立最大似然函數(shù),推導(dǎo)出信號的最佳判決門限;然后,將待識別系統(tǒng)信號的似然比與門限值要求進行分析比較,確定信號的調(diào)制類型。基于最大似然函數(shù)的調(diào)制識別的基本原理如圖1所示。

圖1 基于似然函數(shù)的調(diào)制識別方法流程圖Fig.1 Flow chart of modulation recognition algorithm based on likelihood function
該研究方法主要分為:平均似然比檢測(Average Likelihood Ratio Test,ALRT)[4]、廣義似然比檢測(Generalized Likelihood Ratio Test,GLRT)[5]和混合似然比檢測(Hybrid Likelihood Ration Test,HLRT)[6]。但該類算法需要的先驗知識信息較多,計算量大,普適性差,對于非合作通信方,需要對每1種可獲得的參數(shù)進行概率密度函數(shù)的計算,耗時較長,因此,研究該方法的學(xué)者逐漸減少。
為了進一步展示基于似然函數(shù)的信號調(diào)制識別方法,表1 從分類器、候選調(diào)制類型、信道以及未知參數(shù)方面對該方法進行了總結(jié)。

表1 基于似然函數(shù)的信號調(diào)制識別方法Tab.1 Signal modulation recognition method based on likelihood function
1.2 基于特征提取的調(diào)制識別
利用不同調(diào)制方式之間的頻譜特性的差異提取不同特征,再構(gòu)造分類器對這些特征信息進行分類,達到對未知調(diào)制方式準確識別的目的,其原理如圖2所示。

圖2 基于特征提取的識別方法流程圖Fig.2 Flow chart of recognition method based on feature extraction
此算法具有不同算法復(fù)雜度低、易于仿真實現(xiàn)的特點,但對提取到的特征有很高的要求,其計算量較似然函數(shù)的方法要小。
當前,特征提取的識別方法中使用的特征主要包括:
1)瞬時幅度、相位、頻率的時域特征;
2)循環(huán)譜、功率譜和高階累積量的頻域特征;
3)星座圖、小波變換的變換域特征。
表2對當前基于特征進行提取方法的調(diào)制識別系統(tǒng)研究問題進行了列舉。

表2 基于特征提取的信號調(diào)制識別方法Tab.2 Signal modulation recognition method based on feature extraction
2 基于深度學(xué)習(xí)的調(diào)制識別
2.1 常用數(shù)據(jù)集
為便于評估和對比不同的調(diào)制識別方法的性能,研究者們創(chuàng)建了一些公開的數(shù)據(jù)集,其中最為流行的是 RadioML 數(shù) 據(jù) 集 ,包 括 RML2016.10a、RML2016.10b和RML2018.01a,如表3所示。
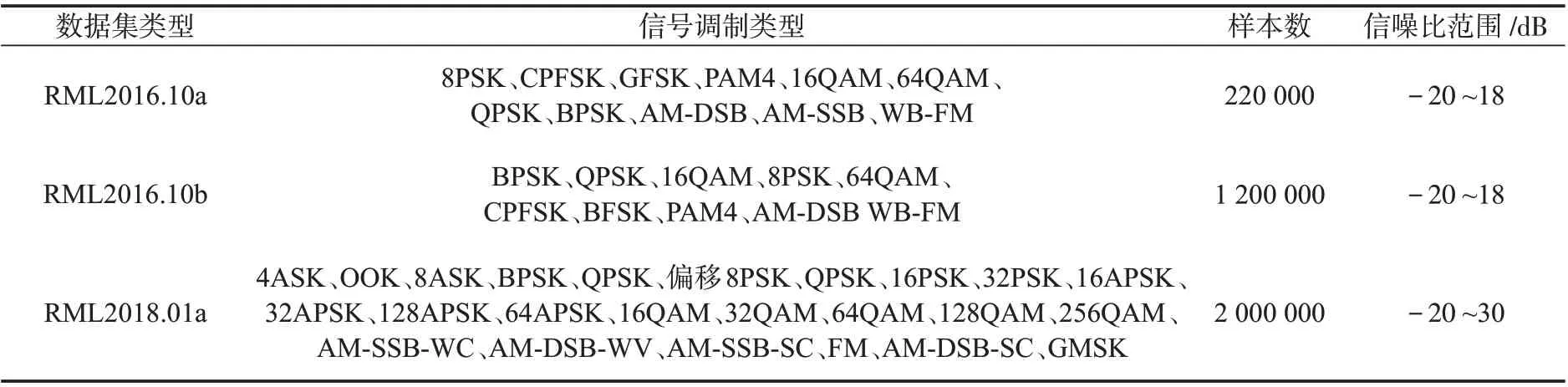
表3 常用RadioML數(shù)據(jù)集Tab.3 Commonly used RadioML data sets
2.2 深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN)
深度學(xué)習(xí)以其強大的學(xué)習(xí)能力,被廣泛應(yīng)用于語音、醫(yī)療和圖像處理等方面,將其與調(diào)制識別相結(jié)合,在短短幾年里就取得了識別領(lǐng)域的重大突破。
2.2.1 卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)
CNN 通過卷積核自動學(xué)習(xí)圖像在各個層次上的關(guān)聯(lián)性,基本結(jié)構(gòu),如圖3所示。
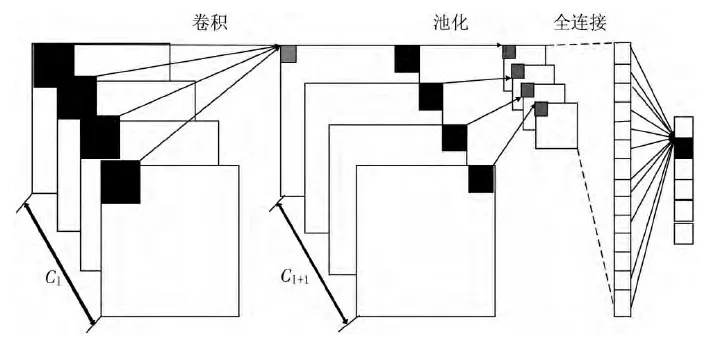
圖3 卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)Fig.3 Basic structure of convolutional neural network
1)卷積層
卷積層是通過卷積核的滑動對輸入的圖像做卷積操作,其中每層卷積層都需要多個卷積核,對特征圖分別進行卷積來提取到多個特征,每個特征中都包含輸入圖像的部分特征。卷積層的計算公式如下:

2)池化層
池化層主要是通過對卷積得到的特征圖進行下采樣,以達到對輸出特征進行選擇和降維的目的。應(yīng)用較廣泛的池化操作有最大池化和平均池化2 種,如圖4所示。

圖4 最大池化和平均池化Fig.4 Max pooling and average pooling
3)全連接層
最大池化是在選取的2×2的卷積核的范圍內(nèi)找到最大值作為下1 層的輸入;平均池化則是在所選的2×2 的卷積核區(qū)域求出平均值作為下1 層的輸入,步長則是卷積核每次移動的距離。
每個輸出節(jié)點與全部的輸入節(jié)點相連接,這種網(wǎng)絡(luò)層被稱為全連接層,如圖5 所示。該層一般位于CNN最后一部分,w11、w12等所構(gòu)成的w矩陣叫作全連接層的權(quán)值矩陣,b是偏置向量。
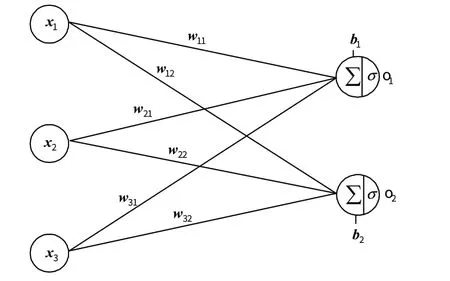
圖5 全連接層Fig.5 Full connection layer
4)激活函數(shù)
激活函數(shù)加入神經(jīng)網(wǎng)絡(luò)后,可以給網(wǎng)絡(luò)添加非線性因素,更好地優(yōu)化了網(wǎng)絡(luò)的性能。常用的激活函數(shù)有Sigmoid、ReLU和Tanh等,其數(shù)學(xué)公式如下。
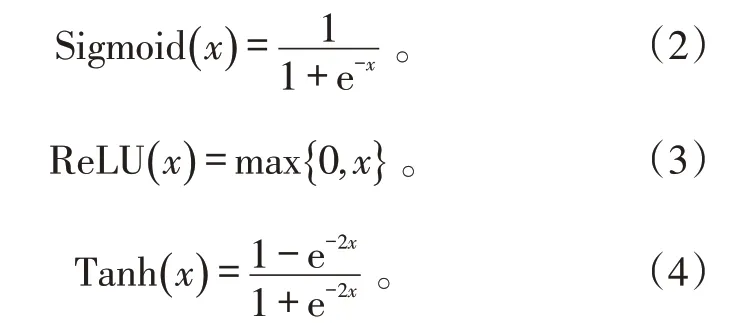
2.2.2 循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)
RNN主要處理序列值數(shù)據(jù),它可以處理類似于局部不相關(guān)的數(shù)據(jù),或者時間維度上長度可變的數(shù)據(jù)。它是由輸入層、隱藏層和輸出層組成,隱藏層中的指向數(shù)據(jù)循環(huán)更新的箭頭,實現(xiàn)了時間記憶功能。基本結(jié)構(gòu),如圖6所示。
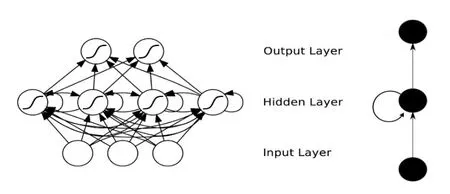
圖6 RNN的基本結(jié)構(gòu)Fig.6 Basic structure of RNN
2.3 識別算法
DNN可以對信號深層特征進行深度提取和挖掘,實現(xiàn)對信號特征的精細化表達,應(yīng)用在調(diào)制識別方面已經(jīng)取得了一定的成果。在對大量文獻進行研究后,列舉了基于深度學(xué)習(xí)的比較有代表性的識別方法,如表4所示。

表4 基于深度學(xué)習(xí)的調(diào)制識別方法Tab.4 Modulation recognition method based on deep learning
3 未來發(fā)展方向
基于目前的研究可以看出,調(diào)制識別已經(jīng)取得一定成果,但仍存在一些不足。
首先,現(xiàn)有算法大多對特定幾種或者十幾種調(diào)制方式進行閉集識別,而現(xiàn)實情況是一旦出現(xiàn)了新的調(diào)制方式,直接利用現(xiàn)有的方法進行識別,定會導(dǎo)致錯誤的分類,最終影響對信號后續(xù)處理。因此,對開集識別的研究十分重要。
其次,目前國內(nèi)外學(xué)者大多偏向于有監(jiān)督深度學(xué)習(xí)算法的研究,研究依賴大量有對應(yīng)標簽樣本,但實際上卻存在大量無標簽的數(shù)據(jù),因此,基于大量無標簽的數(shù)據(jù)的調(diào)制識別算法值得研究。
最后,現(xiàn)有的識別算法大都處于仿真階段,很多調(diào)制識別算法為了提高識別準確率,往往需要大量數(shù)據(jù)和強大的硬件平臺計算資源,特別是基于深度學(xué)習(xí)的調(diào)制識別方法,大都需要高性能顯卡的計算機長時間訓(xùn)練網(wǎng)絡(luò),這樣才能得到較好的結(jié)果。如何完成算法的工程實現(xiàn)是我們下一步努力的方向。
4 結(jié)束語
本文首先從定義、原理和現(xiàn)有識別方法等角度入手,對經(jīng)典調(diào)制進行了總結(jié);然后,分析了深度學(xué)習(xí)的方法,給出了常用數(shù)據(jù)集,著重分析了深度學(xué)習(xí)網(wǎng)絡(luò),包括CNN 和RNN,列舉了大量的深度的學(xué)習(xí)識別方法;最后,展望了調(diào)制識別技術(shù)的發(fā)展方向,為接下來的研究打下基礎(chǔ)。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
電子制作(2018年11期)2018-08-04 03:25:42
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
