基于ADASYN與改進殘差網絡的入侵流量檢測識別
2022-11-19 08:12:38唐璽博張立民鐘兆根
系統工程與電子技術 2022年12期
唐璽博, 張立民, 鐘兆根
(1. 海軍航空大學信息融合研究所, 山東 煙臺 264001; 2. 海軍航空大學航空基礎學院, 山東 煙臺 264001)
0 引 言
入侵檢測是指在計算機及數據網絡正常開放運行的同時,對其進行的一種安全監測和保障。入侵檢測的目標是實時識別系統內部人員及外部入侵人員對計算機系統未經授權的使用[1]。迅速發展的互聯網技術在給予人們便利生活的同時,也使得計算機系統面臨著惡意攻擊、網絡病毒等安全威脅,這使得入侵檢測技術日益成為保證網絡信息安全的重要技術手段。目前,與防火墻等傳統網絡防御技術相比,網絡入侵檢測系統(network intrusion detection system, NIDS)能夠更好地對網絡異常流量進行檢測識別,從而防止網絡受到可能的入侵,以確保其機密性、完整性和可用性[2]。
隨著互聯網技術的巨大發展,網絡節點與規模在全球范圍內迅速擴張,網絡需處理的數據信息量呈爆炸式增長,同時大量新出現的協議均使用動態端口分配技術,端口易被重定向,這使傳統的流量監測技術如基于端口的流量檢測方法[3]對于入侵流量的檢測效果較差。為了有效滿足入侵檢測技術的需求,人們廣泛嘗試采用機器學習與深度學習技術對網絡流量進行處理。其中,基于機器學習的入侵檢測系統需依靠特征工程對網絡流量進行特征的篩選與剔除,從而實現對入侵流量的特征學習以完成檢測識別。文獻[4]提出基于支持向量機的螞蟻系統(ant system with support vector machine, ASVM)模型,采用蟻群算法對特征進行過濾選擇,而后利用支持向量機(support vector machine, SVM)對縮減的特征集進行訓練和測試,在規范化的KDD99數據集上對正常流量與入侵流量進行二分類的準確率達到84.28%。文獻[5]提出一種自學習入侵檢測系統對數據集進行特征學習和降維,提升了SVM對攻擊的預測精度,在NSL-KDD數據集進行流量監測分類實驗,其二分類準確率達到84.96%,五分類準確率達到80.48%。文獻[6]提出一種自適應集成學習模型,通過構造多決策樹以提升入侵檢測性能,在NSL-KDD數據集的檢測準確率達到85.2%。機器學習技術在網絡流量監測上的應用廣泛,但依賴于特征降維和篩選,對于原始形式的自然數據處理能力有限,需要利用其他方法先對數據集進行特征預處理,否則難以對入侵流量達到較好的識別效果。同時,上述機器學習技術提出的模型存在識別準確率較低、泛化性不強的問題。
深度學習通過對非線性模塊的組合應用,能夠學習高維數據中的復雜結構[7],因此具備處理原始數據集的能力,無需采用其他算法構建特征處理器。文獻[8]提出多卷積層的雙向長短時記憶與注意機制(bi-directional long short-term memory and attention mechanism with multiple convolutional layers, BAT-MC)模型,結合了雙向長短時記憶(bi-directional long short term memory, BLSTM)和注意機制,采用卷積層對數據集進行處理,能夠自動完成網絡流量層次結構的學習,在NSL-KDD數據集上進行流量檢測分類實驗,其五分類準確率為84.25%。文獻[9]提出一種基于長短時記憶(long short term memory, LSTM)與改進殘差網絡優化的異常流量檢測方法,提高了LSTM層的特征適應性,在NSL-KDD與來自Fsecrurify開源網站應用防火墻(Web application fivewall, WAF)混合數據集上二分類和五分類的準確率分別為92.3%和89.3%。文獻[10]提出一種帶邏輯回歸的稀疏自動編碼器,通過堆疊自動編碼器創建深度網絡,在NSL-KDD數據集二分類準確率達到84.6%。文獻[11]提出一種基于自動編碼器和變分自動編碼器及單類支持向量機(one-class support vector machine, OCSVM)的半監督深度學習入侵檢測方法,對CICIDS2017數據集進行檢測識別,結果顯示變分自編碼器(variational auto-encoder, VAE)的分類效果最佳,接受者操作特性曲線(receiver operating characteristic curve, ROC)下面積值(area under the curve of ROC, AUC)達到0.759 6。
上述模型相比于機器學習方法,在識別準確率上均有所提升,但仍具備提升空間。大部分研究對于數據都未進行合理的預處理,尤其對于不平衡數據集,直接采用歸一化處理,這直接導致神經網絡忽略對小樣本的特征學習,進而導致小樣本的識別率低下,特征選擇出現偏差,泛化性不強。基于以上問題,本文采用了自適應合成(adaptive synthetic, ADASYN)采樣方法在預處理階段對NSL-KDD數據集中的小樣本數據(如來自遠程主機的未授權訪問(unauthorized access from a remote machine to a local machine, R2L)、未授權的本地超級用戶特權訪問(unauthorized access to local superuser privileges by a local unprivileged user, U2R)類型)進行過采樣,使經過上采樣之后的攻擊類型流量及正常流量在數據集中各自占比相差不大,將不平衡數據集采樣成為平衡數據集,再輸入到深度學習網絡中使神經網絡能夠對5種流量類型都進行充分的學習,避免小樣本的數據特征被淹沒在數據集中。采用改進的殘差網絡作為訓練模型,有效地解決了常用深度學習網絡在訓練過程中出現的過擬合以及梯度消失的問題,并且在二分類及多分類的情況下,均取得了較高的分類準確率,在精確率、召回率等指標上誤報率低,具備較強的泛化性,有較高的工程應用價值。
1 入侵流量檢測模型與處理
本節介紹卷積神經網絡(convolutional neural networks, CNN)等網絡。
1.1 CNN
CNN是由卷積層、池化層以及全連接層等通過交叉堆疊構成的一種前饋神經網絡。CNN具有局部連接、權重共享的特性,與全連接的網絡相比使用的參數更少,并在一定程度上具有平移、縮放和旋轉不變性[12]。基本結構是包含卷積層、池化層、全連接層等。
卷積層的作用是依照卷積核的大小對圖像進行相應的局部特征提取。卷積層的神經元是一維的,但是一維的卷積層難以對二維圖像進行特征提取。為了提高圖像區域信息的利用率,卷積層的神經元通常搭建為三維結構,其大小為高度M×寬度N×深度D,由D個M×N大小的特征映射構成。如果特征映射的圖像為彩色圖像,則輸入層深度D=3;如果輸入為灰度圖像,則輸入層深度D=1。本文將協議數據處理成二維矩陣后,即相當于灰度圖像輸入。卷積層的運算過程可表示為
(1)
式中:Wp為卷積核;X為輸入特征映射;bp為標量偏置;f(·) 為非線性激活函數;Yp為輸出特征映射。卷積層通過對輸入特征進行卷積運算并引入非線性,從而實現局部特征的提取。
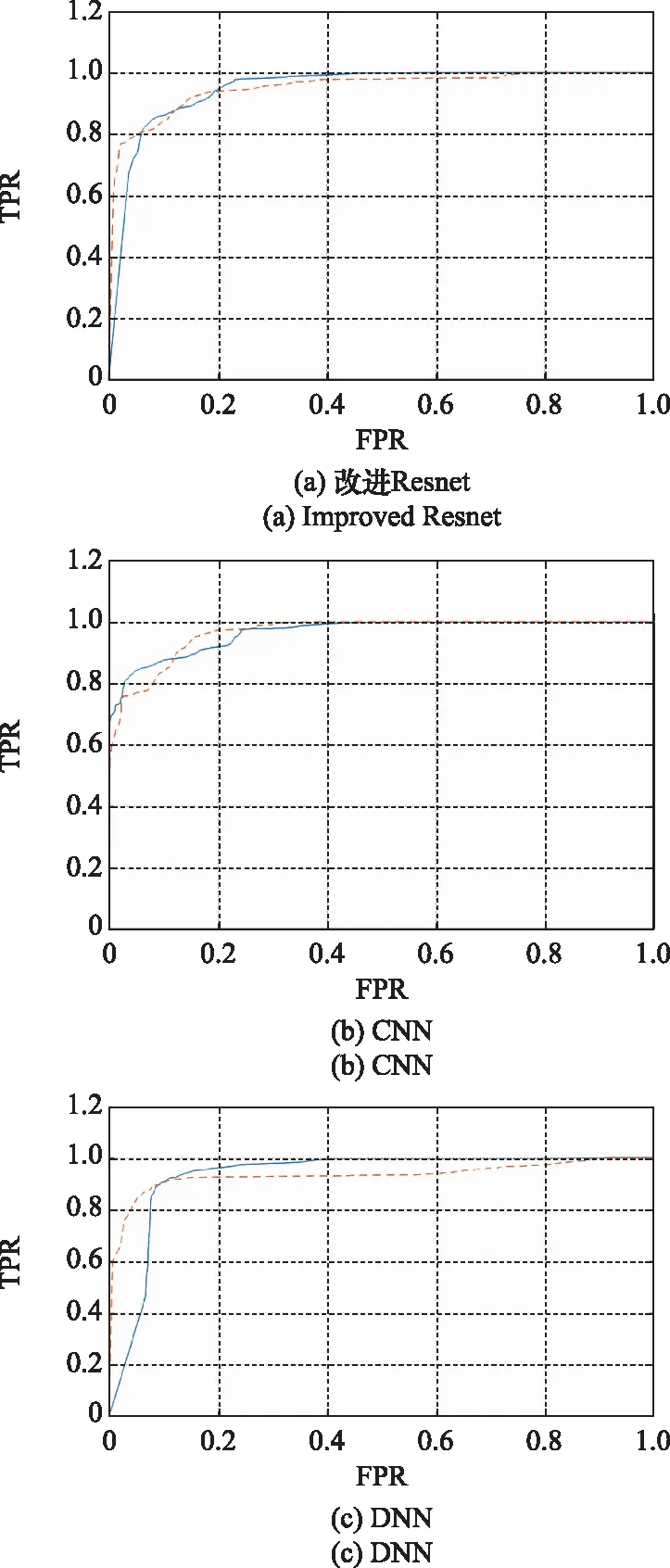
池化層能夠有效減少網絡中神經節點的數量,對局部連接產生的大量特征信息進行采樣,對高維數據進行降維,方法包括進行最大池化和平均池化,通過對特征信息進行據合同及處理,可以降低算法運行耗時,保留重要特征信息,防止訓練產生過擬合現象。全連接層一般處于交替堆疊的卷積層和池化層之后,一般有0~2層,作用是調整特征輸出數量,神經元數等于分類數。
1.2 LSTM網絡
循環神經網絡(recurrent neural network, RNN)具備短期記憶能力,對于處理具有序列關系的信息十分有效。但是當輸入序列比較長時,將出現梯度爆炸或梯度消失的問題,即長程依賴問題[13]。LSTM網絡通過引入門控機制的方法來解決此問題,通過信息的有用程度進行權重確定,包括向神經元中引入新信息、遺忘、輸出的權重,以此來控制信息的累積速度。LSTM網絡引入了3種門,分別是輸入門it、遺忘門ft、輸出門ot。其中,ft表示上一個時刻的內部狀態遺忘信息權重;it表示當前時刻候選狀態保存信息權重;ot表示當前時刻輸出給外部狀態信息權重。3個門均以一定比例允許信息通過,其計算方式為
(2)
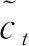
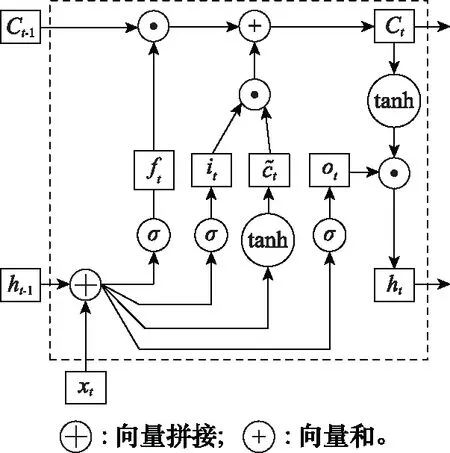
圖1 LSTM網絡的循環單元結構圖
LSTM單元可以使網絡建立一種長時序依賴關系,各計算狀態為
(3)
(4)
ht=ot⊙tanh(ct)
(5)
式中:⊙表示向量元素相乘。
1.3 殘差神經網絡
在深度學習網絡中,層數越多,對數據特征的提取就會越細致全面,但當深層次的網絡收斂時再增加網絡層數,神經網絡將會出現退化現象:隨著網絡的深度不斷增加,網絡訓練的精度先上升達到飽和,然后出現下降。這種現象不是由過擬合產生,而是因為多余的網絡對非恒等映射的參數進行學習造成的。而殘差神經網絡通過在深層網絡中增加跳躍連接,構成殘差塊,能夠起到優化訓練、解決退化問題的效果。殘差塊的結構如圖2所示。
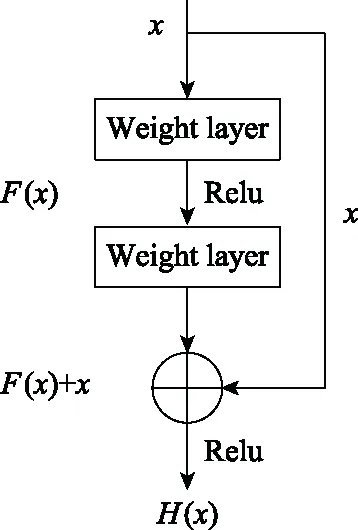
圖2 殘差塊結構
將期望的底層映射設為H(x),將堆疊的非線性層擬合的映射表示為F(x)。此時映射關系為
H(x)=F(x)+x
(6)
式中:x為輸入;F(x)為殘差函數。由文獻[14]可知,當H(x)為恒等映射時,信號可由一個單元直接傳遞到其他任何單元,此時模型的訓練損失和測試誤差達到最小。在恒等映射為算法參數最優的情況下,相比于用堆疊非線性層來擬合恒等映射,令殘差函數F(x)為0來構造恒等映射更加容易,算法難度更低[15]。
殘差網絡采用恒等變換和跳躍連接的方式解決了深度學習網絡的層數退化問題,跳躍連接保護了信息的完整性,網絡只需學習輸入與輸出的差別部分,復雜度降低;恒等變換有效拓展了網絡深度,能夠避免因為深度增加導致的梯度消失和訓練難度提升,隨著層數增加,殘差網絡的性能不會下降,而是會有一定程度的提升[16],這提升了網絡的性能與可遷移性。
1.4 不平衡數據集及處理方法
不平衡數據集指各個類別數據的樣本數目相差巨大的數據集。以二分類問題為例,假設數據集為Q,S1和S2為數據子集,且S1∪S2=Q、S1∩S2=?,此時可通過不平衡比率IBR=S1/S2的取值來界定數據集的不平衡程度。IBR的取值越接近1,則不平衡程度越小;IBR的取值越接近0和∞,則不平衡程度越大[17]。
訓練集數據不平衡是實際應用問題中的常見情況,例如在信用欺詐交易識別中,所收集的數據絕大部分是正常交易,只有極少數交易是不正常的。在二分類數據集中,若樣本比例大于10∶1,則很難建立起有效的深度學習分類器,大部分算法將忽略少數數據集的特征數據,而大多數的不平衡數據集的少數樣本才是數據集的關鍵樣本,此時準確率這一評價指標將失效。
對于不平衡數據集的處理方法,可以采用擴充數據集、重采樣、屬性值隨機采樣等手段對數據集進行改善。在固定使用NSL-KDD數據集的情況下,難以在相同情況下進行數據集的擴充;重采樣可以分為過采樣與欠采樣,過采樣即對小類樣本進行上采樣,使采樣個數大于樣本個數,欠采樣則是減少大類樣本的個數,采樣算法容易實現,但可能會增大模型偏差,并對于不同類別的數據需要采用不同的比例;屬性值隨機采樣在樣本的每個屬性空間都隨機取值組合成為一個新樣本,能夠有效增加小樣本的數量,但引入隨機性易打破樣本原有的線性關系,并且需要增設限定條件以防產生現實中不存在的數據。
2 基于ADASYN與改進殘差網絡(residual network, ResNet)的入侵流量檢測模型
2.1 數據集分析與采樣
1999年舉辦的KDD杯數據挖掘工具競賽以收集流量記錄為目的,以建立一個可區分攻擊流量和正常流量的網絡入侵檢測模型,大量互聯網流量記錄被KDD99數據集收錄,該數據集包括了41個特征指標,共5類數據[18],而后經過新布倫瑞克大學進行修訂和清理產生了NSL-KDD數據集[19]。相比于KDD99數據集,NSL-KDD數據集訓練集中不含冗余記錄,測試集中無重復數據[20],對于算法性能的檢測更加準確,訓練集和測試集的數據量設置合理,無需進行篩選和選擇,更適合作為入侵流量檢測模型的訓練數據集。
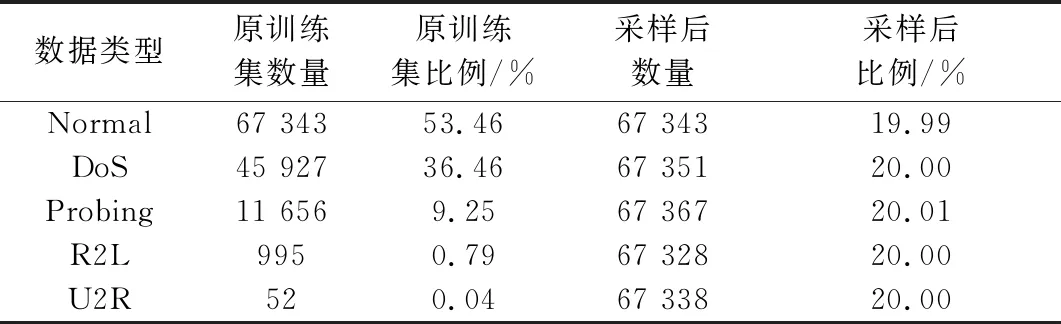
NSL-KDD數據集由正常流量及4種攻擊流量組成,攻擊流量類型分別為:DoS、Probing、R2L、U2R。每種攻擊類型下又細分有若干小類別的攻擊流量,為了統計識別便利,采用數據集給出的5個大類進行分類識別。測試集的部分流量屬于未在訓練集中出現的小類別,將這一部分流量進行剔除。本文采用數據集的KDDTrain+作為訓練集,KDDTest+作為測試集,各數據類型的分布如表1所示[21]。
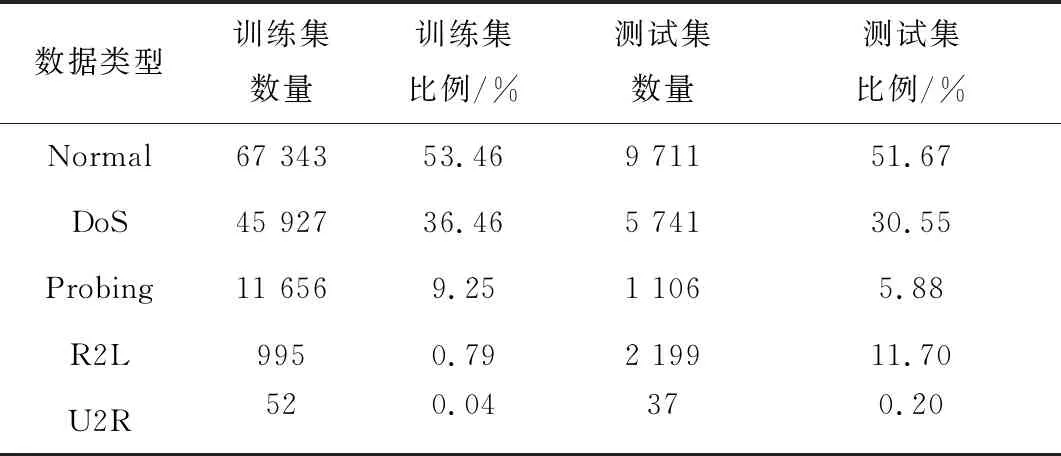
表1 各類型數據分布
由表1可知,訓練集和測試集都存在明顯的數據不平衡現象,最小的樣本僅占比0.04%,樣本比例高達1 336.5∶1,需要對數據集進行平衡化的處理。R2L數據的特點在于,測試集的數量大于訓練集數量,這說明檢測模型在訓練集上將難以充分學習R2L的特征并在測試集中準確分類。基于以上問題,本文采用ADASYN方法進行升采樣,對訓練集中的小樣本數據進行擴充。ADASYN算法步驟如下[22]。
步驟 1數據集小樣本選擇,對Normal、DoS、Probing、R2L、U2R進行樣本編號,將小樣本數據相加得到總數ms,大樣本數據數量為ml。
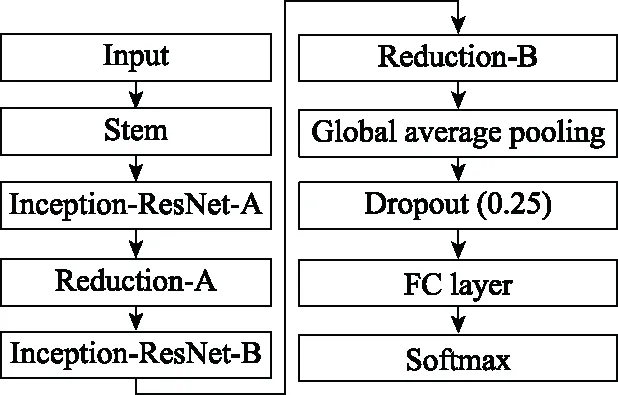
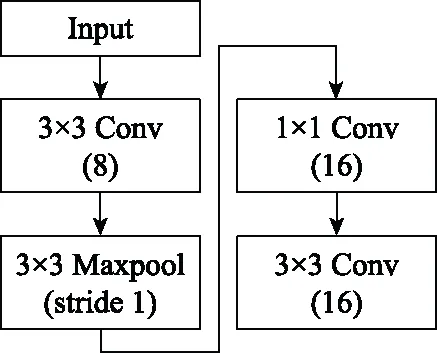
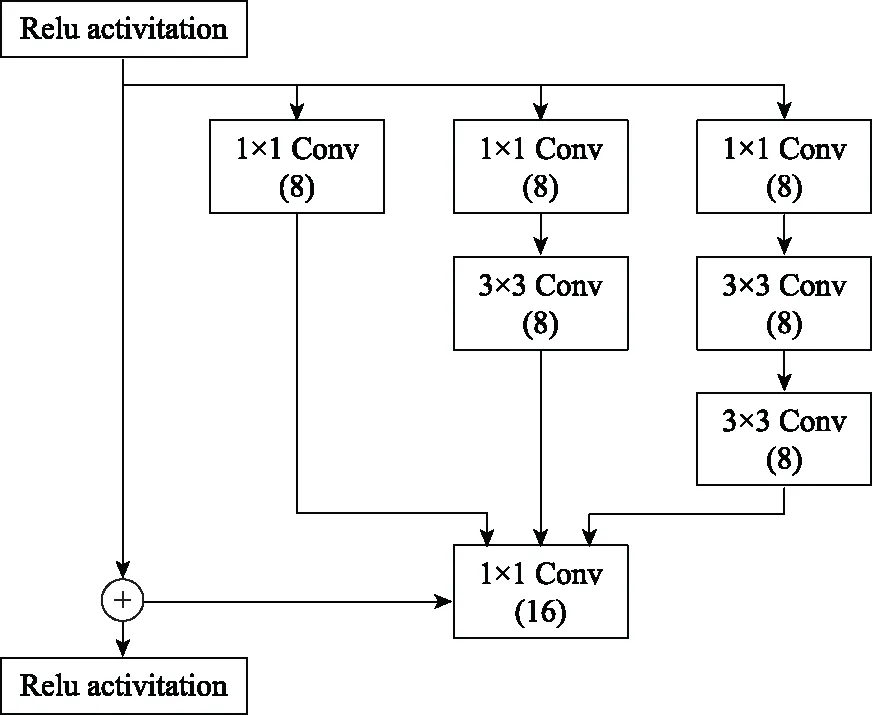
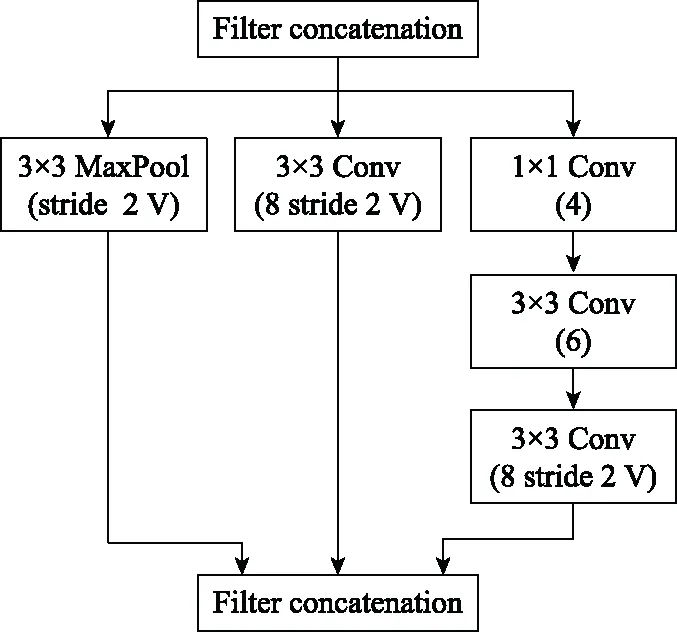
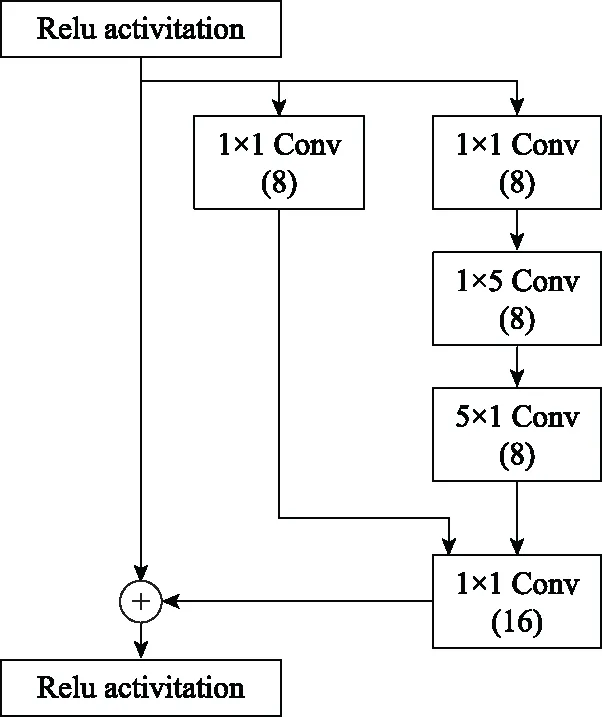
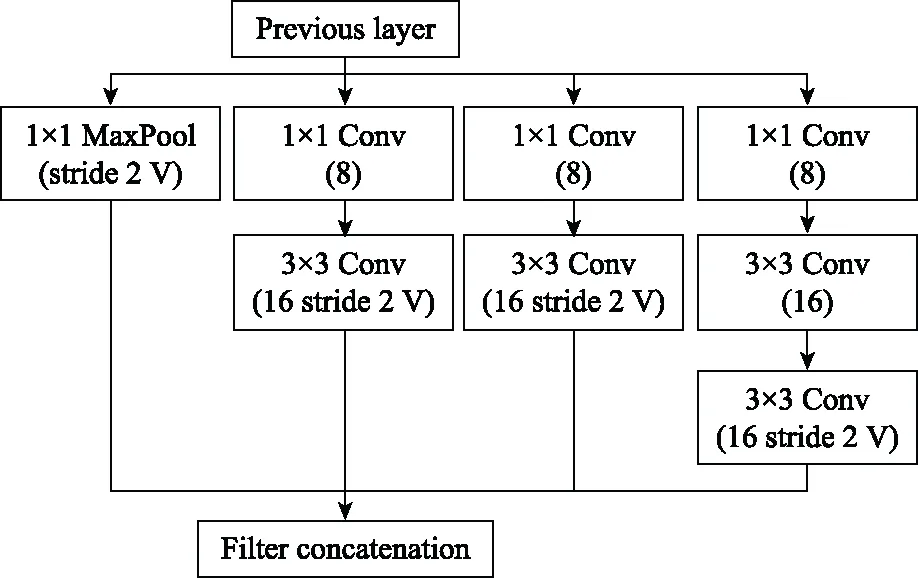
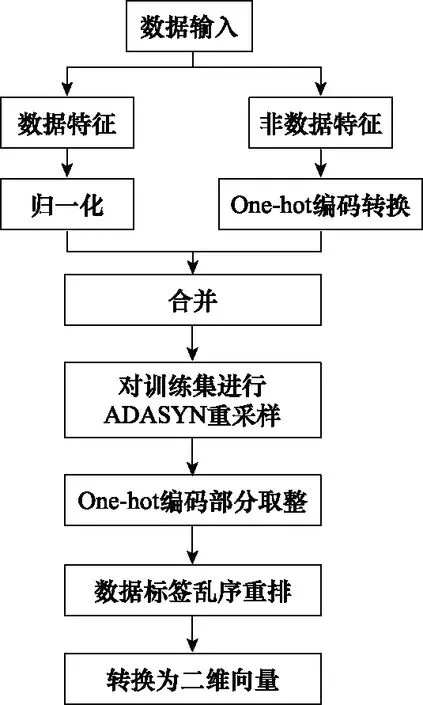
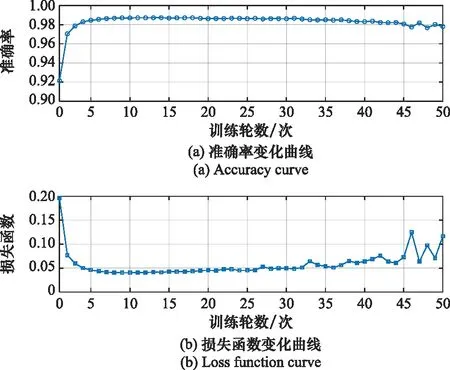
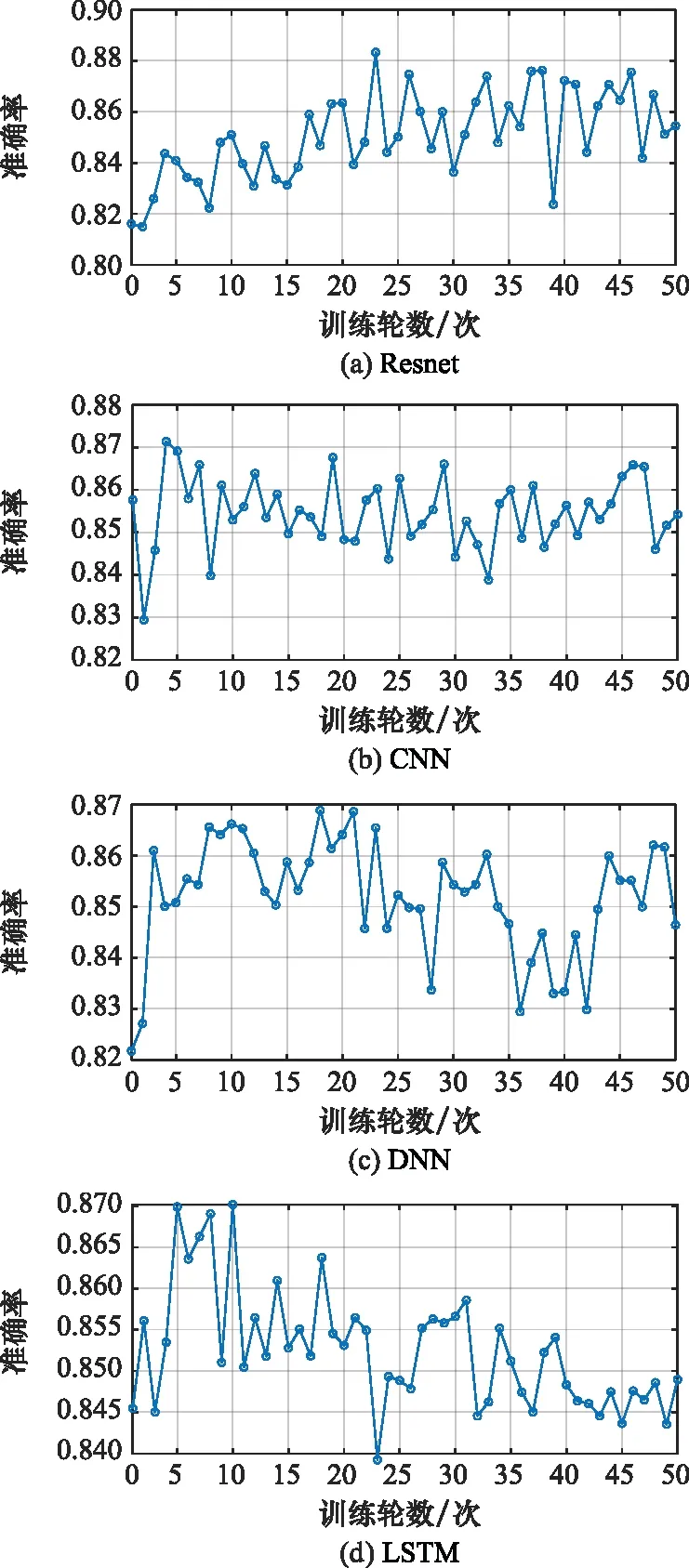
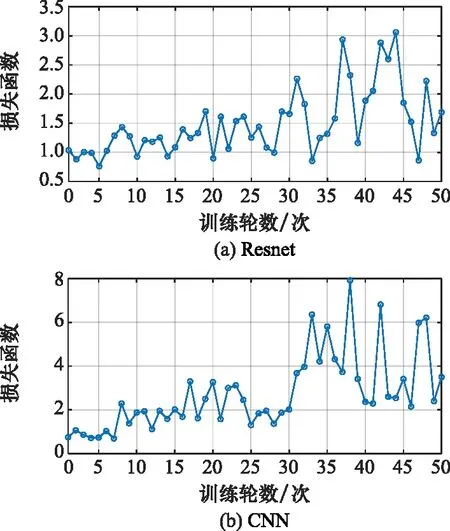
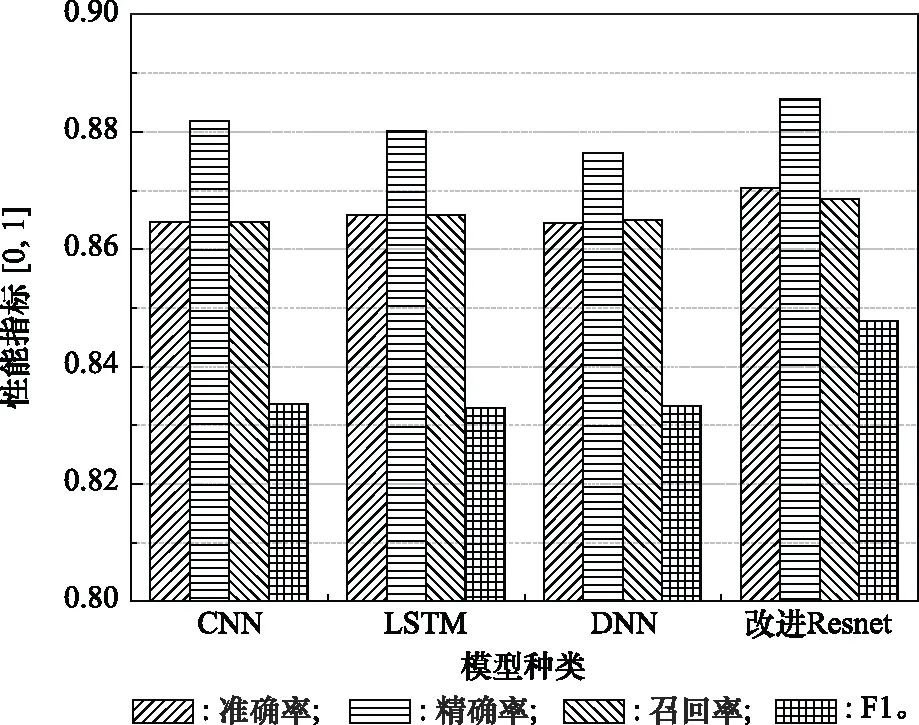
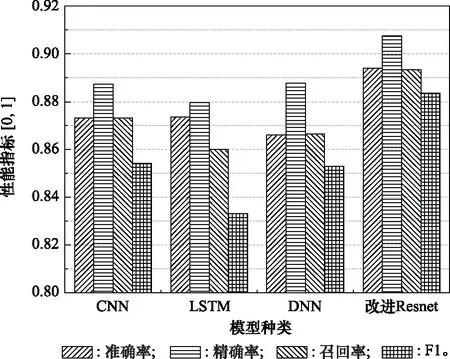
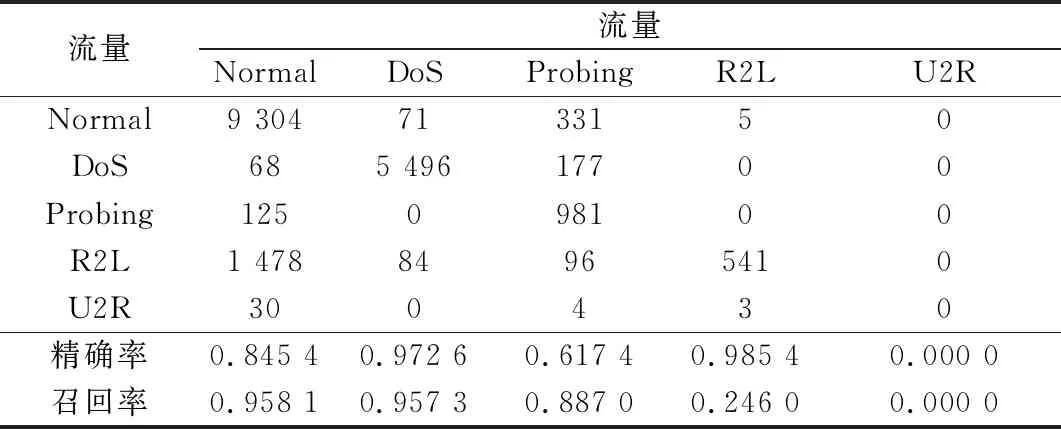
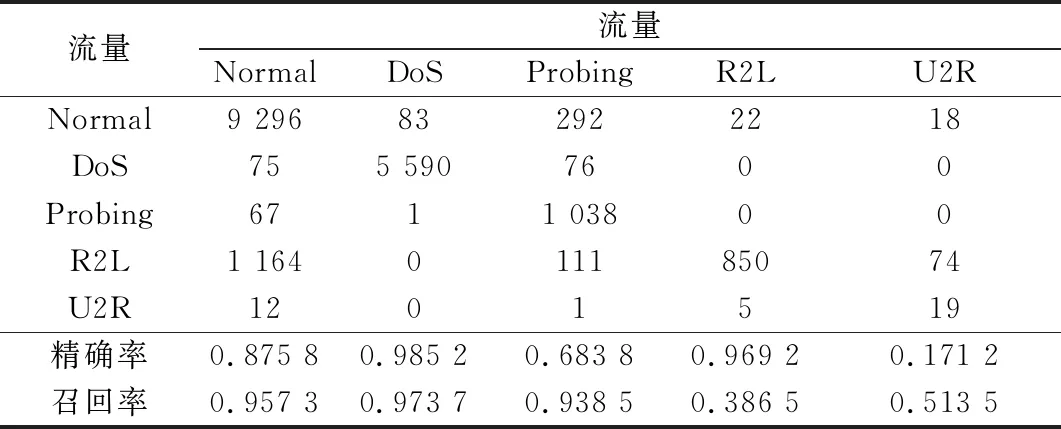
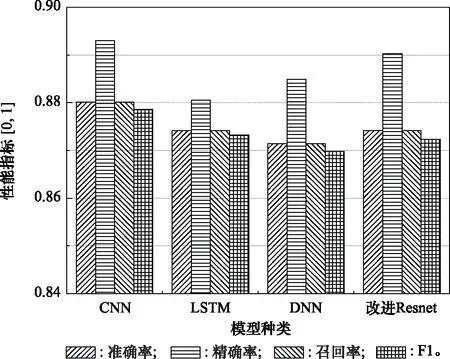
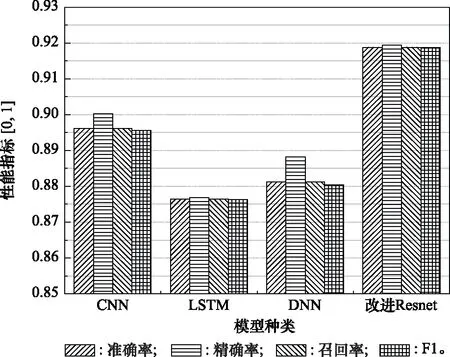
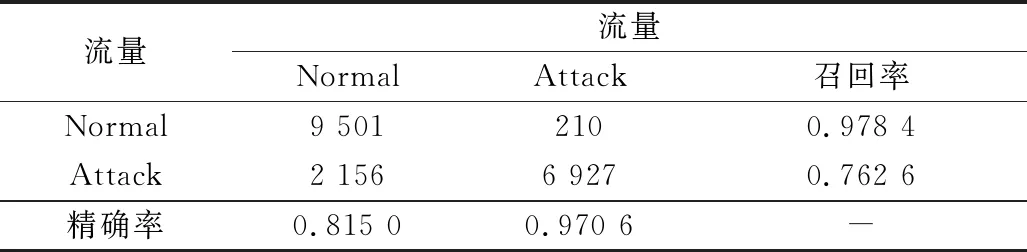
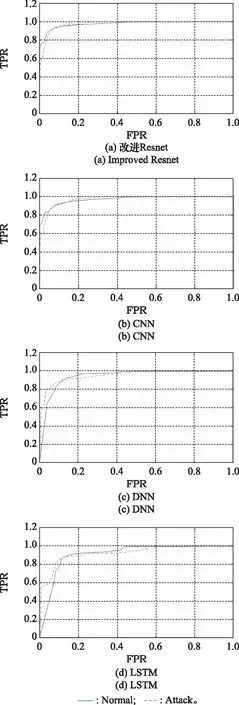
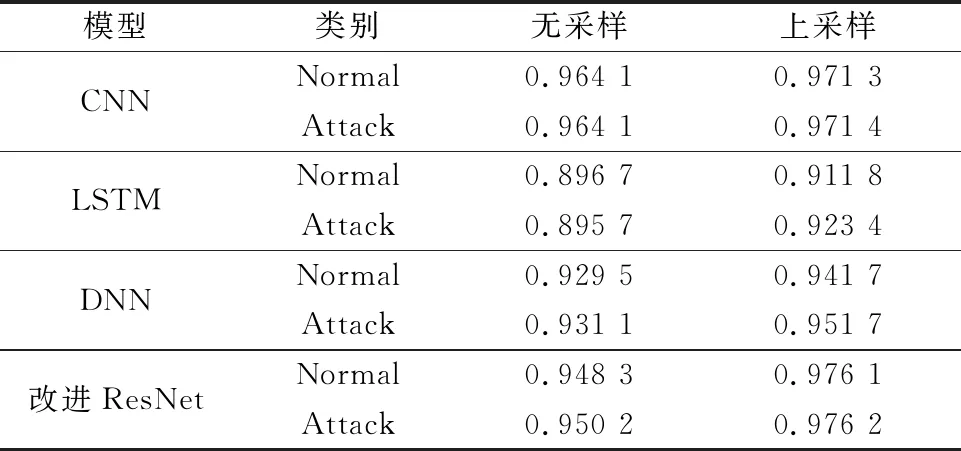
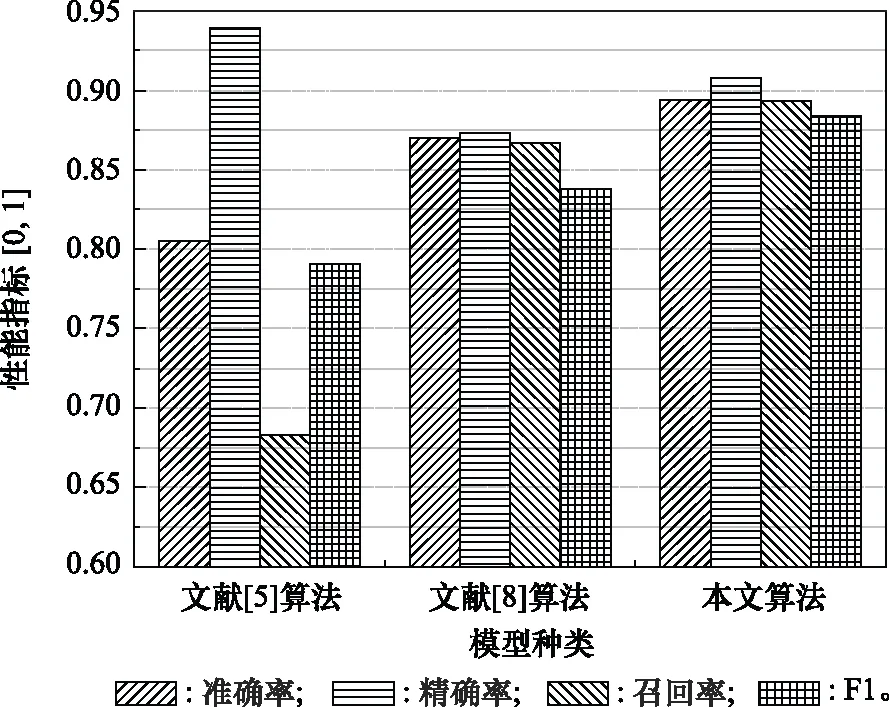
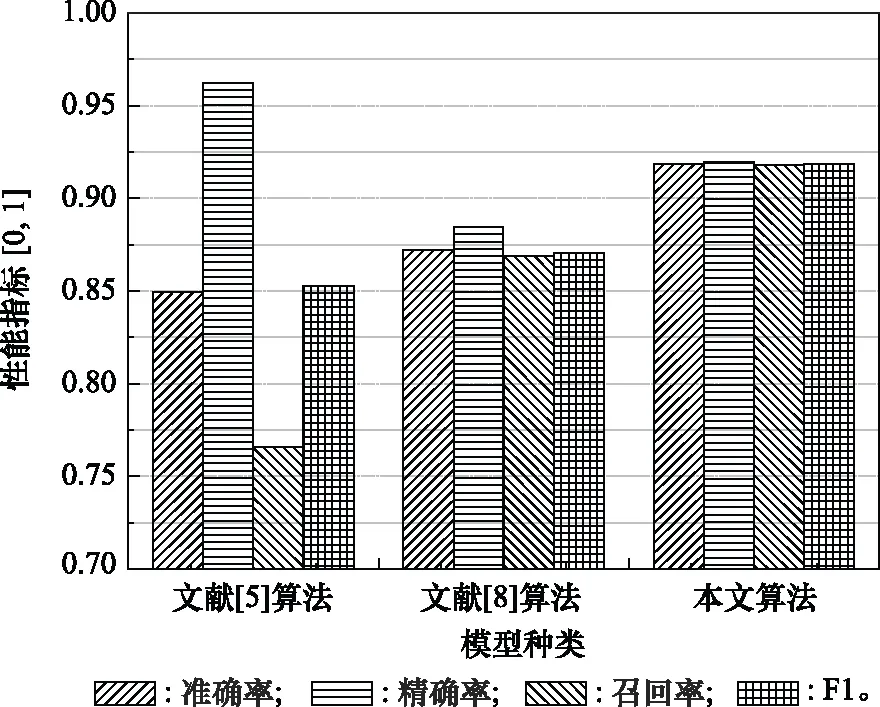
步驟 2計算樣本間的不平衡程度d=ms/ml,其中d 步驟 3計算待合成的樣本Q=β(ml-ms),其中參數β∈(0,1],表示新樣本的不平衡程度。 步驟 6合成新樣本,對于小樣本的n維向量xi的k個鄰近樣本中隨機選取一個小樣本xzi,新合成樣本為:Li=xi+λ(xzi-xi),其中λ∈(0,1]為隨機數。 和CNN一次僅進行一種尺寸的卷積核運算相比,Inception模塊使用多尺寸卷積,有1×1,3×3和5×5共3種卷積核[23],能夠同時進行多個卷積路徑,增加了網絡的寬度,可以使網絡同時對稀疏和非稀疏特征進行學習,獲得一個強相關的特征集合。而添加了殘差網絡的Inception網絡,通過跳躍連接使Inception塊得到簡化,并加深了網絡層數[24],獲得了更好的泛化性和準確度。文章引入Inception-ResNet的部分模塊,并針對NSL-KDD數據集對參數進行優化改進,構建進行分類識別的殘差網絡模型,圖3為模型結構示意圖。 圖3 改進殘差網絡結構 Stem模塊由卷積層和池化層堆疊構成,在Inception模塊之前引入,能夠加深網絡結構,擴充數據維數。卷積層采用padding=same形式,濾波器數量標注在卷積層的括號中。Stem結構如圖4所示。 圖4 Stem模塊結構 Inception-ResNet-A模塊的主要作用是提取淺層特征信息,輸入特征尺寸為11×11,所有卷積核都采用padding=same形式,1×1卷積核的作用為調整濾波器輸出維數,以減少計算復雜度、匹配輸入和輸出維度。Inception-ResNet-A結構如圖5所示。 圖5 Inception-ResNet-A模塊結構 特征降維Reduction模塊也是由Inception模塊修改而來,在其基礎上減少了卷積運算,增加池化運算。相比于單獨的池化層,并行的卷積運算能夠引入額外的特征以彌補池化壓縮維度的過程中丟失的特征信息。Reduction-A模塊的輸入尺寸為11×11,輸出尺寸為5×5,運算模塊中標注“V”的表示padding=valid,否則表示padding=same。Reduction-A的結構如圖6所示。 圖6 Reduction-A模塊結構 Inception-ResNet-B模塊可以提取數據深層的特征信息,輸入、輸出尺寸均為5×5,所有卷積核都采用padding=same形式,模塊結構如圖7所示。 圖7 Inception-ResNet-B模塊結構 Reduction-B模塊的輸入尺寸為5×5,輸出尺寸為2×2,對特征進行了進一步壓縮,模塊結構如圖8所示。經過以上處理后,對數據進行全局池化處理,將特征向量壓縮為1×1的尺寸輸出,相比于直接添加全連接能夠減少計算量,避免過擬合的發生。在經過全局池化后添加參數為0.25的Dropout層,降低神經元之間的相互耦合,減少過擬合情況的發生。之后,將數據輸入到全連接層,利用Softmax函數完成對分類類別的輸出。 圖8 Reduction-B模塊結構 NSL-KDD數據集中每個樣本均有42維特征和一個標簽class組成,其中accuracy特征表示21種機器學習模型中能成功識別該樣本的個數,對于模型的訓練無實際意義,因此舍去。數據集預處理的步驟如圖9所示。 圖9 數據預處理 在剩余的41維特征中有3類非數據類型的特征,分別是protocol_type、service、flag。針對非數據類型的特征,應當按照每種特征的類型數設置one-hot編碼,將非數據特征轉換為數據特征。同時,對數據類型的特征需要進行歸一化處理以減少不同維度特征的數據差異,文章采用min-max歸一化,其表達式為 (7) 數據經過ADASYN升采樣后,新產生的小樣本數據其One-hot編碼部分為連續型小數,需要進行取整以獲取貼近實際的數據。采樣完畢后訓練集的數據分布如表2所示,觀察可知升采樣后攻擊流量及正常流量的占比基本相同,數據集各樣本達到平衡。為保證數據的隨機性,需要對數據進行隨機亂序排列。經統計發現,數據中特征num_file_creations在訓練集、測試集的所有樣本中的取值均為0,為無效特征,故將其剔除。3種非數據類型的特征protocol_type、service、flag分別轉化為3、70、11位的One-hot編碼,與數據特征進行組合得到121維的特征向量,為了更好發揮卷積層的運算效果,將其轉換成尺寸為11×11的二維特征向量。 表2 升采樣后的訓練集數據 模型架構采用圖3的結構,為確定模型最佳訓練輪數,從訓練集中按數據類型隨機抽取20%的數據作為驗證集,進行輪數epoch=50次的訓練,得到的準確率及損失函數如圖10所示。由變化曲線可知,在訓練輪數為0~30輪時,驗證集的分類準確率先升高,后保持穩定;當訓練輪數epoch>30時,驗證集的分類準確率開始下降并在epoch>45輪后出現明顯振蕩,相應的損失函數取值上升并且在epoch>45輪后出現明顯振蕩,這說明模型在訓練后期出現了過擬合現象,算法性能開始下降。因此,本文將實驗模型的訓練輪數設置為30輪。 圖10 驗證集準確率及損失函數變化曲線 此外,模型采用的優化器類型為Adam優化器,具備快速收斂、自適應學習率的能力,參數設置為β1=0.9,β2=0.99。批處理大小設置為64,算法使用categorical-crossentropy作為損失函數。 實驗采用準確率Accuracy、精確率Precision、召回率Recall、調和平均值F1對多分類中各算法的性能進行評價,各性能指標的計算公式[25]為 (8) 式中:TP表示被正確分類的正例數量;FN表示被錯分為負例的正例數量;TN表示被正確分類的負例數量;FP表示被錯分為正例的負例數量。 在二分類的評估中,還使用AUC值及ROC曲線作為評價指標。其中準確率值越高,算法的總體性能就越好;精確率和召回率值高,算法的誤報率越低。AUC值是ROC曲線下的面積大小,對于二分類問題而言,AUC取值越大,模型預測的準確率越高。 為了與實驗模型產生對照,本文還設計了3種由經典深度學習方法構成的算法進行對比實驗,各網絡結構如表3所示。 結構表中各層命名及變量說明如下:FC(X)中X表示全連接層中包含的節點數目,取值為m表示該值等于分類數;DR(X)中X表示dropout層中隨機將神經元輸出置零的比例;LSTM(X)中X表示輸出空間的維數;Conv(X,Y,Z,N,M)中各個參數的含義為:X表示該卷積層中用到的過濾器個數,Y、Z分別表示卷積核的寬度和高度,N表示步長,M表示padding的狀態,如果寫成“V”則表示設置為“Valid”,如果寫成“S”則表示設置為“Same”;MaxPool(X,Y,N,M)中各個參數的含義為:X、Y分別表示池化層的寬度和高度,N表示步長,M表示padding的狀態,命名規則同上。 為了進一步確定經典深度學習算法及本文實驗算法對測試集進行分類識別的最佳訓練輪數,本文利用KDDTrain+對4種算法進行訓練,然后使用4種算法對測試集KDDTest+內的數據進行分類識別,觀察不同訓練輪數下各算法的識別準確率和損失函數,以研究每種算法取得最佳效果時對應的訓練輪數。訓練總輪數設為50輪,圖11和圖12分別為4種算法在不同訓練輪數下對測試集數據識別的準確率及損失函數曲線。 圖11 各算法準確率變化曲線(測試集) 圖12 各算法損失函數變化曲線(測試集) 從圖11和圖12的變化曲線可以發現,4種算法對測試集的識別準確率呈現快速收斂的特點,在5輪以內的訓練輪數就能夠達到較高的性能指標,并且隨著訓練輪數增加,準確率和損失函數呈現振蕩的特點,這與算法采用的Adam優化器特征相一致,即Adam優化器采用自適應學習率設置,在優化后期對于學習率的調節會導致模型收斂結果的振蕩。由圖11可知,4種算法均在30輪內取到了準確率最大值,即Resnet算法在第23輪、CNN算法在第4輪、DNN算法在第18輪、LSTM算法在第10輪實現了模型的最佳分類效果。在訓練輪數epoch>30輪后,4種算法準確率處于較低水平,損失函數振蕩幅度加大且取值逐步上升,這說明訓練輪數大于30輪后,算法均出現了不同程度的過擬合狀態,這與模型在驗證集上的表現相吻合。 在這種情況下,為了取到經典深度學習算法及改進Resnet模型的最佳識別效果,文章采用Keras框架中的callbacks.EarlyStopping進行訓練的提前終止,以保證在節約內存的條件下輸出模型不會錯過最佳訓練效果。以圖11和圖12各算法的振蕩情況為參考,將提前終止的耐心度設置為8,即當模型輸出的準確率連續8輪都小于之前能達到的最大值時,模型將終止訓練并輸出之前訓練的最佳模型。同時為了避免各算法出現過擬合現象,將訓練輪數上限設置為30輪。為了對比模型的性能差異,經典深度學習模型的訓練輪數、優化器、損失函數類型與改進的Resnet模型保持一致。 3.3.1 多分類性能對比分析 本節分別使用CNN、LSTM、DNN、改進Resnet模型對原數據訓練集KDDTrain+和經過ADASYN采樣的新訓練集進行學習,以測試集KDDTest+作為兩次學習的測試集,分別在有重采樣和無重采樣的情況下對比各模型對攻擊流量的分類識別性能,并對重采樣前后各模型自身的性能變化進行比較以驗證ADASYN重采樣的有效性。圖13和圖14分別為各模型在原訓練集和重采樣訓練集下學習后的性能評估圖。可以看出,各模型的性能指標均是精確率最高、準確率和召回率次之,調和平均值最小。無論是否進行ADASYN采樣,改進的Resnet網絡的4項性能指標均高于經典的深度學習網絡,并且在新訓練集上兩者的差異更加明顯。 圖13 各模型性能評估(原訓練集) 圖14 各模型性能評估(新訓練集) 由于實驗中測試集不變,因此該組實驗結果說明了在多分類問題的情況下,改進Resnet模型的各性能均優于CNN、DNN、LSTM等經典深度學習網絡,驗證了模型解決多分類問題的有效性和泛化性。殘差網絡的設計是基于堆疊卷積池化層并添加跳躍連接,提升了網絡深度,本文的模型又向其中添加Inception模塊使模型網絡寬度變寬,最終使得改進的Resnet網絡在特征提取、分類識別方面性能獲得提升。 為了驗證多分類情況下ADASYN采樣的有效性,將基于原訓練集和新訓練集得到的模型性能指標進行對比,如表4所示。由表4可知,除了LSTM模型的精確率、召回率在過采樣后出現了極小的下降,其余的模型在采樣后的新訓練集下得到的所有性能指標均高于原訓練集,這驗證了ADASYN過采樣的有效性。其中改進的Resnet網絡在采樣前后性能提升的最大,采樣前后的混淆矩陣如表5所示。 表4 各模型性能指標對比 表5 無上采樣的改進Resnet混淆矩陣(多分類) 表5數據由兩部分構成,第一部分是由預測類型與實際類型相構成的混淆矩陣,為表格內容前5行,其中行表頭表示將測試集樣本預測為該類型流量,列表頭表示測試集樣本的實際類型;第二部分是5種類型流量在測試集預測的精確率與召回率,為表格內容的后2行。表5是模型在無ADASYN上采樣的原訓練集下訓練,并在測試集上得到的預測結果,表6是在新訓練集上得到的相應測試結果。 表6 含上采樣的改進Resnet混淆矩陣(多分類) 對比表5和表6可得出以下結論: (1) 在新訓練集上得到的模型,對測試集正確預測分類的結果更好。除Normal流量的預測數量有極小的減少外,其余4種攻擊流量在新訓練集的模型下正確預測的數量都得到了較大提升,其中R2L的正確預測數量增加的最明顯,數量由541增加至850,增加了36.35%。 (2) U2R類型流量在不進行上采樣時的模型上正確分類的個數為0,精確率和召回率值都為0,因為在原訓練集中U2R的樣本數量極少,不平衡的數據分布導致算法在學習過程中直接忽略了U2R的特征信息,導致模型不具備檢測U2R類型流量的能力,這說明了采用殘差網絡進行入侵檢測時,解決數據集不平衡問題的必要性。在進行了上采樣后,各類數據分布變得平衡,算法在學習過程中所有類型的特征信息都可學習提取,因此對于5種流量類型都可進行有效的分類,算法的泛化性和可靠性得以提升。其中U2R的召回率的上升最明顯,增加了51.35%。 (3) 兩種情況下算法都將大部分R2L類型的流量誤判為Normal類型,其原因在于R2L流量在訓練集中的數量少于在測試集的數量,因此算法在學習中無法完全掌握測試集中R2L的特征信息。這說明NSL-KDD數據集存在一定的數據劃分不合理性。 3.3.2 二分類性能對比分析 在入侵流量檢測的實際應用中,通常也使用二分類的手段對流量進行劃分,從而方便快捷地篩選找出入侵流量并進行處理。為了檢驗在二分類情況下ADASYN采樣及改進Resnet網絡的分類性能,將4種攻擊流量標簽進行合并,統一改寫為“Attack”類型,便得到了用于二分類檢測識別的訓練集和測試集。圖15和圖16為4種算法模型在二分類情況下的,分別在沒有ADASYN采樣的原訓練集和有上采樣的新訓練集下訓練的測試集評估結果。 圖15 二分類模型性能評估(原訓練集) 圖16 二分類模型性能評估(新訓練集) 由圖可知,在原訓練集下得到的模型中,CNN在測試集中的性能最優,準確率為88.01%,精確率達到89.30%,改進Resnet網絡的性能其次;而在新訓練集下得到的模型中,改進Resnet網絡的性能得到了明顯提高,性能為4種模型中最優,性能的提高程度比多分類情況下的上采樣還要大,其中準確率達到91.88%,提升了4.47%,精確率達到91.94%,提升了2.92%。 經過上采樣后,4種模型在測試集的性能均得到不同程度的提高,這說明了在二分類情況下,ADASYN上采樣的方法依舊能夠有效改善數據的不平衡性,使算法對特征信息的提取更加全面,提升了算法的分類準確率和泛化性。而改進的Resnet網絡在各項指標上都優于其他模型,這體現出改進殘差網絡對于二分類的流量檢測識別具有更好的適應性,算法結構和參數設計合理。 表7和表8給出了在二分類的情況下改進Resnet網絡在原訓練集和新訓練集下的測試集預測混淆矩陣。表格數據由兩部分組成,第1部分是由預測類型與實際類型相構成的混淆矩陣,其中行表頭表示將測試集樣本預測為該類型流量,列表頭表示測試集樣本的實際類型;第2部分為Normal流量與Attack流量在測試集上預測的精確率和召回率。由表可知,在新訓練集下得到的改進Resnet模型對Attack流量的正確分類數量明顯提升,Attack流量的TN樣本數量上升、FN樣本數量下降也使得Normal流量的精確率及Attack流量的召回率提升,這充分說明了在經過ADASYN采樣后,模型對于Attack流量的特征信息學習更加充分,算法的總體分類能力得到提升。 表7 無上采樣的改進Resnet混淆矩陣(二分類) 表8 含上采樣的改進Resnet混淆矩陣(二分類) 通過比較表7和表8,發現在二分類的情況下,測試集的TN樣本數量更多,FP、FN樣本數量更少,整體的分類性能也是二分類情況優于多分類情況,這說明在二分類情況下,改進Resnet網絡的分類效果更好,對入侵流量有更準確的檢測能力,缺點在于二分類無法對入侵流量的類型進行細化區分。 二分類問題中,ROC曲線及其下面積AUC值可以用作衡量分類器的分類效率及平衡性,因為AUC不受先驗概率及閾值的影響[26],AUC取值為[0,1],取值越大,算法的預測準確率越高;ROC曲線的變化不受正負樣本數據分布的影響,能夠客觀反映出模型的分類性能。圖17、圖18分別給出了4種算法在原訓練集、新訓練集下得到的模型在測試集中的ROC曲線圖,其中實線代表將Normal流量作為正例繪制的ROC曲線,虛線代表將Attack流量作為正例繪制的ROC曲線。 圖17 模型測試集ROC曲線(原訓練集) 圖18 模型測試集ROC曲線(新訓練集) 表9表示使用ADASYN采樣前后的各模型測試集預測的AUC值。 表9 模型測試集AUC值 結合觀察圖17、圖18和表9,可以得出如下結論: (1) 4種算法在經過上采樣的訓練集中得到的模型AUC值均大于在原訓練集中得到的模型,而ROC曲線基本不受測試集數據不平衡的影響,導致AUC值提高的根本原因就是模型的分類能力提高,因為在經過ADASYN采樣的訓練集上,大幅提高了小樣本數量,使模型在訓練過程中不會忽略小樣本的特征信息,提高了模型識別的泛化性和準確性。 (2) 在上采樣后的ROC曲線中,改進的Resnet模型AUC值高于其他3種模型,ROC曲線更加飽滿,貼近左上角。這表明改進Resnet模型的分類效果優于其他模型,這一結論與圖15、圖16和表7的結果相一致,充分說明了本文提出的算法在二分類的情況下能夠獲得最高的準確率和AUC,并且誤報率低,具備良好的入侵流量檢測能力。 本節為驗證算法模型的實際性能和應用價值,采用文獻[5,9]提出的算法與本文算法進行性能對比,分別在多分類和二分類的情況下針對準確率、精確率、召回率和F1值進行評估。其中,文獻[5,9]采用NSL-KDD的原始KDDTrain+作為訓練集,本文提出的改進Resnet算法采用經ADASYN采樣后的數據集作為訓練集進行訓練。結果如圖19和圖20所示。 圖19 算法性能比較(多分類) 圖20 算法性能比較(二分類) 由圖可知,文獻[5]采用的STL-IDS進行特征降維,并使用SVM進行分類識別,雖然具備較高的精確率,但是在多分類和二分類情況下均存在準確率、召回率低下的問題,尤其是多分類情況下算法的召回率只有68.29%,這表明算法在查全率上存在較大缺陷,各性能指標效果差異大。文獻[9]算法采用堆疊LSTM和空洞殘差網絡進行構建,和本文的改進殘差網絡具備一定相似性,在多分類情況下F1值取值較低,整體各個性能指標表現均衡,在查準率和查全率上都具備較好的性能。 相比于兩種文獻算法,本文提出的改進Resnet算法在經ADASYN上采樣的訓練集上得到的模型在多分類和二分類情況上都具備最高的準確率和最低的誤報率。這充分說明了算法設計的合理性,模型分類識別具備較高的準確性和泛化性,可靠性良好。 本文提出了一種基于Inception-ResNet模塊改進的殘差神經網絡模型,算法通過添加跳躍連接的方式增加了網絡深度,解決了網絡過深導致性能下降的問題,同時使用Inception-ResNet模塊拓寬了網絡寬度,利用特征降維模塊有效減少了池化過程中的特征丟失。通過ADASYN對數據訓練集進行上采樣,改善小樣本在不平衡數據集中的分布,解決了深度學習網絡在不平衡數據集的學習中易忽略小樣本特征信息的問題,通過采樣前后的對比說明了自適應合成采樣對于算法性能提高的重要作用。 文章最后在多分類、二分類情況下分別對經典深度學習算法和改進Resnet算法進行性能評估,并進行算法的效能對比,使用的指標包括準確率、精確率、召回率、調和平均值、ROC曲線和AUC值。實驗結果表明,在多分類的情況下,改進的Resnet算法在上采樣訓練集下得到的模型準確率可達到89.40%,二分類時為91.88%,均在所有算法中達到最高,同時算法的誤報率低、泛化性好,具備較高的可靠性和工程應用價值。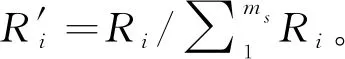
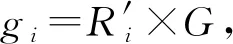
2.2 殘差網絡構建
3 實驗分析
3.1 數據預處理
3.2 模型參數與評估指標
3.3 模型性能對比驗證


3.4 算法性能驗證
4 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
