改進(jìn)的輸出誤差法用于不穩(wěn)定飛機(jī)參數(shù)辨識
2022-12-14 07:08:26汪志剛李愛軍王力浩孫小鋒
哈爾濱工業(yè)大學(xué)學(xué)報(bào) 2022年12期
汪志剛,李愛軍,2,王力浩,孫小鋒
(1.西北工業(yè)大學(xué) 自動化學(xué)院,西安 710072; 2.陜西省飛行控制與仿真技術(shù)重點(diǎn)實(shí)驗(yàn)室(西北工業(yè)大學(xué)),西安 710072)
系統(tǒng)辨識技術(shù)基于飛行試驗(yàn)中飛行運(yùn)動和控制變量的測量值,建立輸入輸出量間的關(guān)系。飛機(jī)系統(tǒng)辨識是飛機(jī)研發(fā)過程中的一個(gè)重要環(huán)節(jié),對控制律的設(shè)計(jì)、飛行模擬器的設(shè)計(jì)和飛行包線的擴(kuò)展都有重要的意義[1]。飛機(jī)系統(tǒng)辨識技術(shù)分為頻域辨識和時(shí)域辨識,頻域辨識方法建立系統(tǒng)的線性模型,時(shí)域識別方法可用于提取線性模型和非線性模型[2]。目前最常用的時(shí)域飛機(jī)系統(tǒng)辨識方法是方程誤差法以及輸出誤差法。方程誤差法是一種直接方法,受自變量中的測量噪聲影響,其估計(jì)結(jié)果是有偏差的。輸出誤差法基于極大似然原理,通過最小化測量值和模型輸出的均方差來估計(jì)參數(shù),其估計(jì)結(jié)果是漸近無偏的。針對穩(wěn)定飛機(jī),輸出誤差法是最常用的參數(shù)辨識方法之一[3]。
不穩(wěn)定飛機(jī)的主要特點(diǎn)為:1)飛行試驗(yàn)過程中需要引入控制器;2)求解不穩(wěn)定飛機(jī)的模型輸出時(shí),若參數(shù)選取稍有不適,求解過程將發(fā)散。如圖1所示,針對不穩(wěn)定飛機(jī),系統(tǒng)辨識有兩種可能的方法,即閉環(huán)辨識和開環(huán)辨識[4]。經(jīng)典的閉環(huán)辨識方法建模飛行員輸入δp與測量值z之間的動力學(xué)關(guān)系,不會產(chǎn)生任何數(shù)值問題,因?yàn)檎麄€(gè)系統(tǒng)是穩(wěn)定的。此方法的局限是只能得到閉環(huán)系統(tǒng)的等價(jià)模型,若要從中推導(dǎo)出開環(huán)動力學(xué)模型,還需要精確的控制器回路動力學(xué)模型,而這通常是不容易得到的。
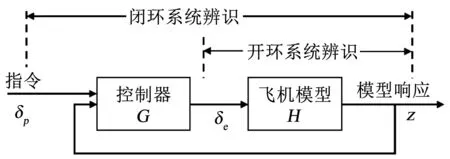
圖1 不穩(wěn)定飛機(jī)的閉環(huán)與開環(huán)辨識
開環(huán)辨識方法直接建模飛機(jī)舵面輸入δe與測量值z之間的動力學(xué)關(guān)系。然而,輸出誤差法不能直接應(yīng)用于不穩(wěn)定飛機(jī)。輸出誤差法需要求解待辨識系統(tǒng)的運(yùn)動方程,應(yīng)用于不穩(wěn)定的飛機(jī)時(shí),會產(chǎn)生數(shù)值發(fā)散問題,導(dǎo)致參數(shù)估計(jì)過程失敗[4]。
近年來,隨著神經(jīng)網(wǎng)絡(luò)學(xué)科的發(fā)展,神經(jīng)網(wǎng)絡(luò)方法逐漸應(yīng)用于飛機(jī)系統(tǒng)辨識領(lǐng)域[5-7]。Hess[8]通過神經(jīng)網(wǎng)絡(luò)直接建模飛機(jī)的氣動系數(shù)。Ghosh等[9]基于前向神經(jīng)網(wǎng)絡(luò),使用Delta法和Zero法提取飛機(jī)的氣動導(dǎo)數(shù)。Peyada等[10]提出了一種新的思想——將神經(jīng)網(wǎng)絡(luò)與輸出誤差法相結(jié)合,以神經(jīng)網(wǎng)絡(luò)代替飛機(jī)動力學(xué)模型,并采用高斯-牛頓法最小化網(wǎng)絡(luò)輸出與試驗(yàn)測量值間的均方差,從而進(jìn)行參數(shù)估計(jì)。隨后多位學(xué)者[11-13]遵循類似的思路,應(yīng)用不同的網(wǎng)絡(luò)或者對不同的對象進(jìn)行辨識。但是,這些文獻(xiàn)都是基于高斯-牛頓法來最小化代價(jià)函數(shù)的。高斯-牛頓法具有固有的缺陷,即容易陷入局部最小值[2]。本文基于粒子群優(yōu)化對LM (levenberg-marquardt)方法進(jìn)行了改進(jìn),以改進(jìn)的LM算法代替高斯-牛頓法,并與神經(jīng)網(wǎng)絡(luò)方法相結(jié)合,形成一種改進(jìn)的輸出誤差法,用于不穩(wěn)定飛機(jī)的參數(shù)辨識。
1 神經(jīng)網(wǎng)絡(luò)建模
神經(jīng)網(wǎng)絡(luò)由于其強(qiáng)大的非線性映射能力,可以直接應(yīng)用于對非線性動力學(xué)特性建模。網(wǎng)絡(luò)輸入向量選取為動力學(xué)系統(tǒng)第k時(shí)刻的輸入量以及狀態(tài)量,網(wǎng)絡(luò)輸出向量選取為第(k+1)時(shí)刻的輸出量,經(jīng)過大量樣本訓(xùn)練后,神經(jīng)網(wǎng)絡(luò)可以依據(jù)第k時(shí)刻(當(dāng)前時(shí)刻)的狀態(tài)和輸入,對第k+1時(shí)刻(下一時(shí)刻)的狀態(tài)量進(jìn)行預(yù)測。換句話說,神經(jīng)網(wǎng)絡(luò)用于近似系統(tǒng)的動力學(xué)特性,其作用相當(dāng)于線性或者非線性動力學(xué)系統(tǒng)的運(yùn)動方程。
本文選擇了常用的BP神經(jīng)網(wǎng)絡(luò)[4],其網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。

圖2 BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
BP神經(jīng)網(wǎng)絡(luò)分為輸入層、隱含層和輸出層。W1、W2分別為輸入層到隱含層和隱含層到輸出層的權(quán)重以及偏差矩陣,網(wǎng)絡(luò)的傳播遵循式(1)~(4),其中f(x)為非線性S形激活函數(shù)。xr為網(wǎng)絡(luò)輸入向量,x1、x2分別為隱含層和輸出層的輸入向量,xh、xo分別為隱含層和輸出層的輸出向量。
x1=W1xr+W1b
(1)
xh=f(x1)
(2)
x2=W2xh+W2b
(3)
xo=f(x2)
(4)
S形激活函數(shù)選擇雙曲正切函數(shù):
(5)
如上所述,網(wǎng)絡(luò)輸入向量U選取為動力學(xué)系統(tǒng)k時(shí)刻的輸入以及狀態(tài)量,網(wǎng)絡(luò)輸出Z選取為k+1時(shí)刻的狀態(tài)向量。即
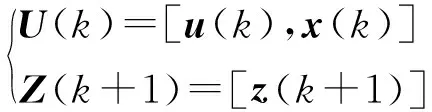
(6)
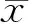
(7)
通過連續(xù)調(diào)整網(wǎng)絡(luò)參數(shù)W1和W2,可以最大程度地減小網(wǎng)絡(luò)輸出和測量值之間的誤差。在第k個(gè)離散數(shù)據(jù)點(diǎn)上,將成本函數(shù)選擇為第k步的局部輸出誤差,即
(8)
基于最速下降法,網(wǎng)絡(luò)參數(shù)W1,W2通過式(9)、(10)進(jìn)行調(diào)整:
(9)

(10)
激活函數(shù)的導(dǎo)數(shù)為
(11)
網(wǎng)絡(luò)參數(shù)W1,W2通過迭代更新之后,網(wǎng)絡(luò)將具有滿意的擬合性能,網(wǎng)絡(luò)的最終擬合性能通過均方差(MSE)進(jìn)行衡量,即
(12)
2 基于粒子群優(yōu)化改進(jìn)的輸出誤差法
本文詳細(xì)陳述基于粒子群優(yōu)化改進(jìn)的輸出誤差法,以及應(yīng)用神經(jīng)網(wǎng)絡(luò)和改進(jìn)的輸出誤差法進(jìn)行參數(shù)辨識的算法流程。
2.1 粒子群優(yōu)化
粒子群優(yōu)化算法(Particle swarm optimization,PSO)最初是由Eberhant等[14]于1995年提出的一種基于直接搜索的優(yōu)化算法。此算法基于個(gè)體粒子之間的協(xié)作與競爭,經(jīng)過數(shù)次迭代后實(shí)現(xiàn)復(fù)雜空間中最優(yōu)解的搜索。PSO算法是一種有記憶能力的算法,對于低維優(yōu)化問題十分有效[15]。粒子群中的每個(gè)粒子,都是所求優(yōu)化問題的一個(gè)潛在的解。而粒子的品質(zhì)由事先設(shè)定好的適應(yīng)度函數(shù)來評價(jià)。假設(shè)在n維搜索空間中,有m個(gè)粒子,第h個(gè)粒子的位置表示為xh=(xh1,xh2,…,xhn)T,速度表示為vh=(vh1,vh2,…,vhn)T,將xh代入適應(yīng)度函數(shù)中計(jì)算出其適應(yīng)度值,以評價(jià)其優(yōu)劣。ph表示第h個(gè)粒子的歷史最佳位置,pg表示整個(gè)粒子群經(jīng)歷過的最優(yōu)位置。在標(biāo)準(zhǔn)粒子群算法中,粒子的速度和位置更新如式(13)、(14),其中下標(biāo)d表示vh、xh、ph和pg的第d個(gè)分量,t為迭代次數(shù),ω、ξ1、ξ1分別為3個(gè)可調(diào)參數(shù),r1,r2,r3為 (0, 1)之間的3個(gè)隨機(jī)數(shù)。
vhd(t+1)=ωr1vhd(t)+ξ1r2(phd(t)-xhd(t))+
ξ2r3(pgd(t)-xhd(t))
(13)
xhd(t+1)=xhd(t)+vhd(t+1)
(14)
2.2 傳統(tǒng)輸出誤差算法
神經(jīng)網(wǎng)絡(luò)訓(xùn)練完成后,基于LM算法對代價(jià)函數(shù)進(jìn)行優(yōu)化,使得網(wǎng)絡(luò)輸出和測量輸出的均方差最小,從而對未知參數(shù)進(jìn)行辨識。LM算法是對高斯-牛頓法的改進(jìn),為解釋LM算法,首先簡要介紹基于高斯-牛頓法的傳統(tǒng)輸出誤差算法[3]。
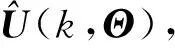
(15)
(16)
式中R為協(xié)方差矩陣,R的極大似然估計(jì)如式(17)所示。高斯-牛頓法通過式(18)、(19)求解未知參數(shù)。
(17)
Θi+1=Θi+ΔΘ
(18)
FΔΘ=-G
(19)
其中F、G分別為Hessian矩陣和梯度向量,即:
(20)
(21)
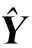
(22)
2.3 粒子群改進(jìn)的LM算法
LM算法由Levenberg[16]和Marquardt[17]提出,其結(jié)合了高斯-牛頓法和最速下降法,LM算法在兩個(gè)梯度方向上優(yōu)化代價(jià)函數(shù),因此包含更寬的收斂范圍[4]。與高斯-牛頓法相比,LM算法中添加了一個(gè)非負(fù)阻尼因子λ,其參數(shù)迭代計(jì)算如式(23)、(24)所示,其中,Hessian矩陣F和梯度向量G按照式(20)、(21)計(jì)算,與高斯-牛頓法一致。當(dāng)阻尼因子接近于0時(shí),LM算法的性能與高斯-牛頓法一致;而當(dāng)阻尼因子充分大時(shí),LM算法的性能接近于最速下降法。
Θi+1=Θi+ΔΘ
(23)
(F+λI)ΔΘ=-G
(24)
傳統(tǒng)的LM算法根據(jù)代價(jià)函數(shù)的增減對阻尼因子進(jìn)行某種調(diào)整,例如通過對阻尼因子乘以10或除以10以保證代價(jià)函數(shù)的下降[4]。然而這種調(diào)整得到的阻尼因子并不是最佳的,從而限制了算法性能提升的效果。在本文中,LM算法的每次迭代時(shí)采用粒子群算法來求解最佳阻尼因子,即,基于粒子群算法最小化代價(jià)函數(shù)(25),以確保求解的阻尼因子是局部最優(yōu)的,或者說是次最優(yōu)的。需要指出的是,增加粒子群算法的粒子數(shù)以及搜索次數(shù)后,還可以找到最優(yōu)的阻尼因子,但是這樣會增加計(jì)算代價(jià),這是非必要的。本文設(shè)置了20個(gè)粒子,最多搜索5次。結(jié)果表明這樣的設(shè)置對于改善LM算法的性能是足夠的。
J(Θi+1)=J(Θi+ΔΘ)=J1(Θi,λi,F,G)=J2(λi)
(25)
2.4 神經(jīng)網(wǎng)絡(luò)LM(NN-LM)算法流程
最終的神經(jīng)網(wǎng)絡(luò)LM(NN-LM)參數(shù)辨識算法包含了兩部分:神經(jīng)網(wǎng)絡(luò)訓(xùn)練以及參數(shù)估計(jì)。整個(gè)算法的流程如圖3所示。

圖3 神經(jīng)網(wǎng)絡(luò)LM(NNLM)算法流程圖
算法的求解步驟如下:
1)從飛行試驗(yàn)數(shù)據(jù)中提取狀態(tài)量和輸入量,構(gòu)成神經(jīng)網(wǎng)絡(luò)的輸入向量U(k);從飛行試驗(yàn)數(shù)據(jù)中提取輸出量,構(gòu)成神經(jīng)網(wǎng)絡(luò)的輸出向量Z(k+1),例如本文的應(yīng)用算例中,U(k),Z(k+1)分別為式(31)、(32);并按照式(9)~(11)進(jìn)行網(wǎng)絡(luò)訓(xùn)練。

3)基于傳統(tǒng)輸出誤差法,分別根據(jù)式(22)計(jì)算靈敏度矩陣?Y(k)/?Θ,式(20)計(jì)算Hessian矩陣F,以及式(21)計(jì)算梯度向量G。
4)將粒子群中每個(gè)粒子的適應(yīng)度函數(shù)取為代價(jià)函數(shù)(25),基于粒子群優(yōu)化過程,即式(13)、(14)求解局部最優(yōu)阻尼因子λ。
5)基于LM算法,根據(jù)式(23)、(24)更新待辨識參數(shù)Θi。
重復(fù)步驟2)~5),直至算法收斂。
3 不穩(wěn)定飛機(jī)模型與仿真試驗(yàn)數(shù)據(jù)
本文應(yīng)用了De Havilland DHC-2 “BEAVER“測試機(jī)[4,18]的不穩(wěn)定短周期模型。“BEAVER“飛機(jī)的短周期狀態(tài)方程為:
(26)
式中:w為縱向速度,q為俯仰角速率,az為縱向加速度,δe為升降舵偏轉(zhuǎn)量。
模型的觀測方程為:
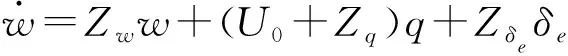
(27)
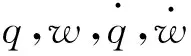
在本文的研究中,這些模型參數(shù)構(gòu)成了待辨識的未知參數(shù)向量,即
Θ=[Zw,Zq,Zδe,Mw,Mq,Mδe]T
(28)
式中Zw,Zq,Zδe,Mw,Mq,Mδe為模型參數(shù),其標(biāo)稱值見表1。
系統(tǒng)矩陣A如式(29)所示,將U0和表1中模型參數(shù)的標(biāo)稱值Θ代入系統(tǒng)矩陣A,可計(jì)算出其兩個(gè)特征值分別為0.693 4和-5.825 0,其中正的特征值對應(yīng)著不穩(wěn)定模態(tài)。這種不穩(wěn)定飛機(jī)的仿真飛行試驗(yàn)只能在引入控制器后(閉環(huán)條件下)進(jìn)行。文獻(xiàn)中對此模型引入了垂直速度比例反饋控制器(30),并進(jìn)行了閉環(huán)機(jī)動試驗(yàn),其中δp為飛行員輸入[4]。
(29)
δe=δp+Kw
(30)

表1 模型參數(shù)的標(biāo)稱值以及基于3種方法的估計(jì)結(jié)果
盡管仿真飛行試驗(yàn)是在閉環(huán)條件下進(jìn)行的,本文對模型參數(shù)的估計(jì)在開環(huán)條件下進(jìn)行,將升降舵偏轉(zhuǎn)量δe視為模型輸入,進(jìn)行開環(huán)辨識,在辨識過程中并未使用飛行員輸入δp的信息。使用JATEGAONKAR[4]設(shè)計(jì)的輸入信號激勵(lì)仿真模型,模型的試驗(yàn)數(shù)據(jù)如圖4所示。
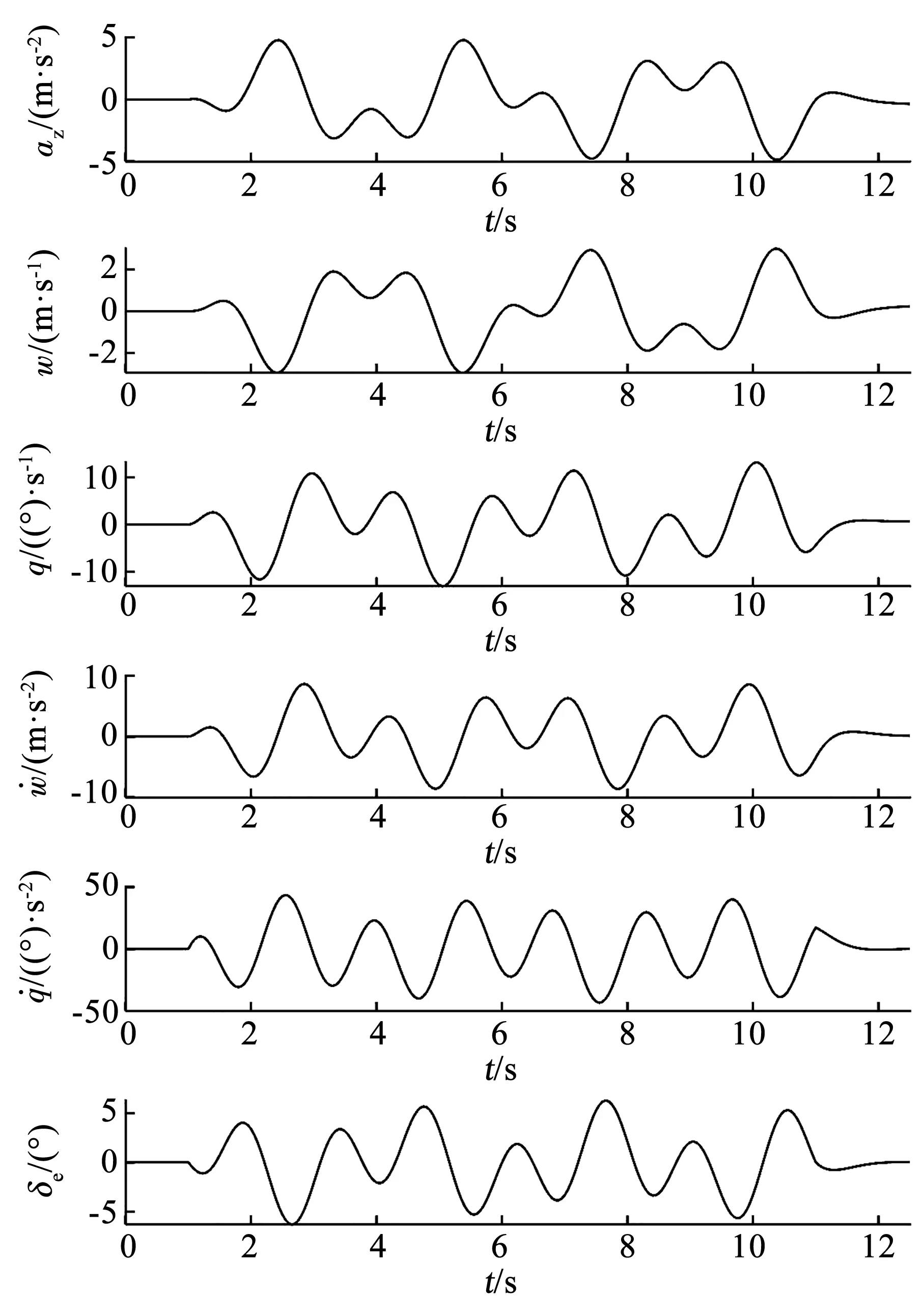
圖4 “BEAVER“飛機(jī)短周期模型的仿真試驗(yàn)數(shù)據(jù)
4 參數(shù)辨識結(jié)果
本文基于NN-LM方法,從仿真數(shù)據(jù)中提取模型參數(shù)。首先,選取神經(jīng)網(wǎng)絡(luò)輸入向量為仿真模型第k時(shí)刻的狀態(tài)及輸入為
(31)
式中w(k)為k時(shí)刻的縱向速度采樣值。
選取網(wǎng)絡(luò)輸出向量為仿真模型第k+1時(shí)刻的輸出Z(k+1)為
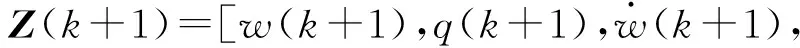
(32)
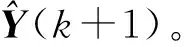
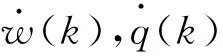
(33)
綜上所述,傳統(tǒng)的輸出誤差法需要參數(shù)的先驗(yàn)信息,將參數(shù)初值設(shè)置在標(biāo)稱值附近,否則算法將發(fā)散或者收斂至局部極小值點(diǎn)。而改進(jìn)的LM算法具有更寬的收斂范圍,即不需要參數(shù)的先驗(yàn)信息。本文參數(shù)估計(jì)過程中,所有的未知參數(shù)向量Θ均以[-2,2]范圍內(nèi)的隨機(jī)數(shù)初始化,從不同的初始值開始迭代時(shí)算法均可以收斂。圖5、6為選取不同隨機(jī)初始值時(shí),參數(shù)Zδe和Mw的收斂過程。可以看出,參數(shù)初值選取不同時(shí),算法均可在7步內(nèi)收斂,參數(shù)初始值離標(biāo)稱值較遠(yuǎn)時(shí),算法收斂較慢,參數(shù)初始值離標(biāo)稱值較近時(shí),算法收斂較快。

圖5 參數(shù)Zδe收斂過程以及對應(yīng)的標(biāo)準(zhǔn)差

圖6 參數(shù)Mw收斂過程以及對應(yīng)的標(biāo)準(zhǔn)差
將3種方法估計(jì)的參數(shù)代入運(yùn)動方程(26),得到3種估計(jì)模型,并且由仿真試驗(yàn)中的升降舵偏轉(zhuǎn)驅(qū)動3種模型,模型的輸出如圖7所示。并結(jié)合Theil不等系數(shù)(Theil’s inequality coefficient,TIC)[19]來評價(jià)3種模型的輸出量對試驗(yàn)值的擬合效果。輸出量的TIC定義如式(34),其中zi為仿真試驗(yàn)測量值,yi為模型的輸出值,N為離散測量數(shù)據(jù)點(diǎn)的個(gè)數(shù)。TIC值越低表示模型輸出與試驗(yàn)測量值符合度越高,TIC值低于0.25~0.30代表了較好的擬合效果[4]。3種模型的各個(gè)輸出量的TIC值見表2。

(34)
由圖6可以看出,基于NN-LM方法辨識的模型可以很好地?cái)M合仿真試驗(yàn)數(shù)據(jù),效果優(yōu)于傳統(tǒng)的最小二乘法(LS)和人工穩(wěn)定的輸出誤差方法(SOEM)。由表2中的TIC值可以看出,對于NN-LM辨識出的模型,其各個(gè)輸出量的TIC值均低于LS方法和SOME方法,且遠(yuǎn)小于0.25,說明了此模型的輸出對試驗(yàn)測量值的擬合效果更好。

圖7 3種估計(jì)模型的升降舵驅(qū)動結(jié)果
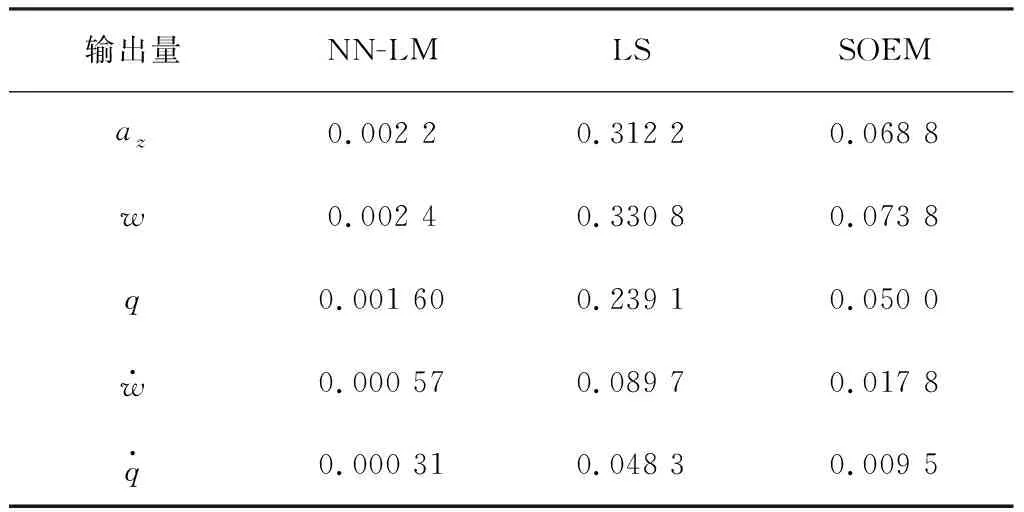
表2 3種模型各個(gè)輸出量的TIC值
5 結(jié) 論
1)基于飛行試驗(yàn)數(shù)據(jù)訓(xùn)練前向神經(jīng)網(wǎng)絡(luò),以神經(jīng)網(wǎng)絡(luò)代替飛機(jī)的運(yùn)動方程來預(yù)測飛機(jī)響應(yīng),從而避免了輸出誤差法中求解運(yùn)動方程的要求。因而可以應(yīng)用于不穩(wěn)定飛機(jī)以及大迎角飛行條件下的飛機(jī)參數(shù)辨識。同時(shí),相比于求解運(yùn)動方程,計(jì)算網(wǎng)絡(luò)輸出的運(yùn)算成本更小,因此NN-LM算法對于穩(wěn)定飛機(jī)的參數(shù)辨識也具有一定的優(yōu)勢。
2)NN-LM算法基于粒子群優(yōu)化,求解LM算法的最佳阻尼因子,放寬了高斯-牛頓法對參數(shù)初值的依賴,待辨識參數(shù)的初值可隨機(jī)選取。本文的算例中,未知參數(shù)向量均以隨機(jī)數(shù)初始化,從不同的初始值開始迭代時(shí)算法均可以收斂。
3)NN-LM算法保留了輸出誤差法的精確性。仿真結(jié)果表明,改進(jìn)后的算法可以成功辨識出不穩(wěn)定飛機(jī)的參數(shù)。與傳統(tǒng)算法相比,NN-LM算法得到的TIC值更低,說明NN-LM算法辨識出的模型可以更好地?cái)M合試驗(yàn)測量值,估計(jì)效果有明顯改善。
4)NN-LM算法本質(zhì)上是對高斯-牛頓法的改進(jìn),因此還適用于其他的非線性方程求解問題。接下來將進(jìn)一步圍繞穩(wěn)定以及不穩(wěn)定飛機(jī)的氣動系數(shù)建模來開展研究。基于NN-LM算法,從真實(shí)以及仿真的飛行試驗(yàn)數(shù)據(jù)中提取氣動導(dǎo)數(shù),與風(fēng)洞試驗(yàn)結(jié)果進(jìn)行對比和補(bǔ)充。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小哥白尼(軍事科學(xué))(2022年3期)2022-06-09 03:11:24
環(huán)球時(shí)報(bào)(2022-05-30)2022-05-30 15:16:57
民用飛機(jī)設(shè)計(jì)與研究(2020年4期)2020-11-27 17:34:02
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
當(dāng)代陜西(2019年11期)2019-06-24 03:40:28
作文周刊·小學(xué)一年級版(2017年9期)2017-06-20 00:19:33
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小學(xué)生導(dǎo)刊(低年級)(2016年8期)2016-09-24 22:09:04
