結合分層深度網絡與雙向五元組損失的跨模態異常檢測
2022-12-15 13:19:04彭淑娟王楠楠
計算機研究與發展 2022年12期
范 燁 彭淑娟 柳 欣 崔 振 王楠楠
1(華僑大學計算機科學與技術學院 福建廈門 361021)2(廈門市計算機視覺與模式識別重點實驗室(華僑大學) 福建廈門 361021)3(南京理工大學計算機科學與工程學院 南京 210094)4(綜合業務網理論及關鍵技術國家重點實驗室(西安電子科技大學) 西安 710071)(fanye@stu.hqu.edu.cn)
異常檢測是開放場景中機器學習和數據分析的一項重要技術,旨在挖掘出數據集中與大多數其他數據具有顯著區別的對象,已廣泛應用于如網絡垃圾郵件檢測[1]、信息差異管理[2]、網絡入侵與故障檢測[3]、信息竊取[4]、圖像/視頻監控[5]等實際應用領域中.近年來,國內外研究學者針對異常檢測已經提出了許多有效的解決方法,包括基于數據分布的方法[6]、基于距離的方法[7-10]、基于密度的方法[11]和基于聚類的方法[12-14].然而,這些異常檢測的方法主要針對的是單一視圖數據.在眾多的實際場景中,數據往往來源多樣,并且具有多種表現形式.近年來,研究人員發現對單個視圖數據進行異常檢測時常常存在著漏檢問題,究其原因在于當查看某個實例每個單獨視圖中的大部分數據時,它們通常不是異常的,但當聯合考慮多個視圖時,它們就可能會呈現異常狀態.然而,由于多視圖數據復雜的組織結構和分布差異性,傳統的異常檢測方法常常無法滿足對多視圖數據進行異常樣本檢測的需求.
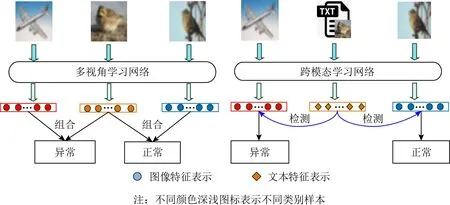
Fig. 1 Difference between multi-view anomaly detection and cross-modal anomaly detection圖1 多視角異常檢測與跨模態異常檢測的區別
據文獻研究[5],在實際場景中多視圖數據常常包括了2類數據:一類是來自同一實例的不同視角數據,如來自同一人臉的左側部分與右側部分;另一類是源自同一實例的不同模態數據,如反映同一語義信息的圖片與文本等.針對多視圖樣本點的異常檢測問題,近年來研究人員提出并嘗試了一些多視圖異常檢測的方法,然而這些方法主要專注于檢測多視圖數據中屬于同一實例的不同視角異常樣本信息,鮮有相關研究專注于檢測多視圖數據中屬于同一實例的不同模態異常信息.在實際場景中,多視角異常檢測可能難以完成不同模態的檢測問題.例如,自閉癥患者的行為在平時與常人無異,但在一些表述中會表現出與常人不同的行為.因此,可以利用這些表述對患者所對應的行為進行檢測.為有效檢測來源多樣的多視圖異常數據,研究人員提出了基于多模態數據的跨模態異常檢測概念,如圖1所示,多視角異常檢測旨在通過結合不同視角的數據進行檢測,而跨模態異常檢測旨在利用一個模態數據樣本去檢測屬于同一實例的其他模態樣本異常信息.盡管屬于同一實例的不同模態數據具有較高的語義關聯性,然而不同模態數據樣本呈現分布復雜、特征異構并且具有明顯的語義鴻溝,因此從不同模態數據中進行有效的異常檢測仍是一個極其挑戰性的課題.
據文獻[15]可知,目前多視圖數據中的樣本異常主要可以分為3類:1)類別異常;2)屬性-類別異常;3)屬性異常.這3類異常的形式化定義如1)~3):
1) 類別異常.在不同視圖中表現出不一致特征的異常值,即該數據樣本在不同的視圖中表現出不同的類別特征,如圖2空心圓形所示.
2) 屬性-類別異常.在某些視圖中表現出正常的特征值,而在其他視圖中表現出不一致的異常值,即該數據樣本在某些視圖中沒有表現出異常,而在其余視圖中表現出異常,如圖2空心三角形所示.
3) 屬性異常.在每個視圖中都表現出不一致的異常值,即該數據樣本在不同的視圖中都表現出異常,如圖2五邊形所示.
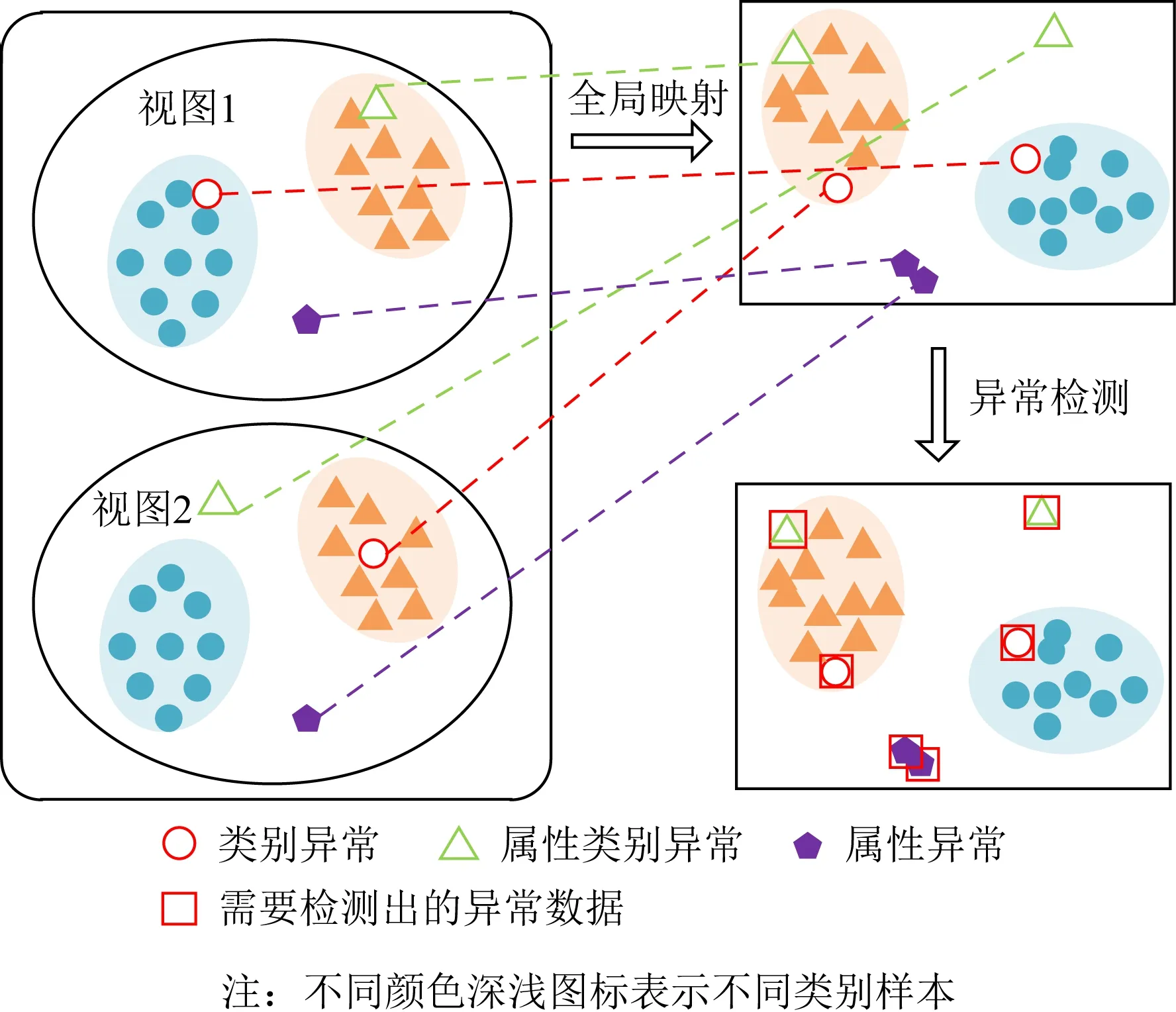
Fig. 2 Classfication and detection of three types of outliers圖2 3類異常樣本的分類及檢測
有效的多視圖異常檢測方法需要對上述3類異常樣本進行檢測.然而,由于同一實例不同模態的數據也屬于多視圖數據,傳統的多視圖異常檢測無法有效處理此類問題.為有效檢測來源多樣的多模態異常數據,近年來提出的跨模態異常檢測方法仍然需要對以上述3類異常進行檢測.據文獻[14],現有的跨模態異常檢測框架主要采用雙分支模型將不同模態中的數據投影到共同語義嵌入空間進行差異化分析.然而,若一個實例中的多個模態數據同時出現異常且數據結構特征相似時,該框架會將該組數據投影到相似的位置,從而常常存在漏檢現象.因此,現有的跨模態異常檢測方法不能同時有效滿足對3類不同類型異常值進行全面檢測,并且有益于訓練的樣本沒有實際參與模型訓練,數據利用不夠充分.針對上述問題,本文提出了一種結合分層深度網絡與相似度雙向五元組的跨模態異常檢測方法,旨在全面檢測出不同模態中所有的異常類型樣本點.具體地,以圖片和文本為例,本文將圖片與文本數據輸入到框架之中,使用單視圖異常檢測層對其中一個模態進行檢測,判斷檢測數據樣本中是否存在屬性異常與部分屬性-類別異常點.若檢測出該數據沒有此類異常,則該數據進入跨模態檢測層,對該數據的圖片以及文本描述進行進一步檢測,該部分采用相似度雙向五元組損失的雙分支深度網絡用于檢測數據中的類別異常與其余部分的屬性-類別異常.該損失讓不同屬性之間的數據正交化,相同屬性之間的數據線性相關,從而不同屬性數據的特征相關性降低,相同屬性數據的特征相關性提高,并且通過模態間雙向約束和模態內的鄰域約束,極大提高了數據利用率,進而獲得更好的訓練效果.本文工作的主要貢獻主要包括3個方面:
1) 提出一種新的跨模態異常檢測框架.該框架結合分層深度網絡進行跨模態異常檢測,使得該框架可以完整檢測出3類不同類型異常值,為跨模態異常檢測提供一種新的研究思路.
2) 提出一種相似度雙向五元組損失的異常檢測方案,該損失使得不同屬性數據正交化,相同屬性數據線性相關,有效加大了不同屬性數據間的特征差異性;增加了相同屬性數據之間的特征相關性,并通過雙向約束極大提高了模型的泛化能力.
3) 提出的學習框架可以有效檢測不同模態中的異常樣本點,相比于現有的跨模態異常檢測的方法,本文所提出的框架幾乎取得了全面的提升.
1 背景和相關工作
隨著多視角數據在實際應用中的普及,研究者針對多視圖數據的異常檢測進行了諸多實驗與探究,并提出了一些代表性的多視角異常檢測方法.例如,Gao等人[16]提出的水平異常檢測(horizontal anomaly detection, HOAD)是第1個解決多視圖異常檢測的有效方法,該算法首先構造一個相似矩陣并進行譜嵌入,然后利用不同嵌入之間的相似度來對每個實例的異常得分進行異常檢測計算.Marcos等人[17]提出了一種基于親和矩陣(affinity propagation, AP)的異常檢測方法,該方法通過分析不同視圖中每個實例的鄰域來檢測異常樣本點.Alexander等人[18]提出了一種基于共識聚類(consensus clusters, CC)的多視圖異常檢測方法,旨在通過多個視圖聚類結果的不一致性來檢測異常樣本點.然而,這些方法都僅用于檢測類別異常,并未考慮其他異常類別.針對這個問題,Zhao等人[19]首先提出了多視圖數據中樣本屬性異常與類別異常的概念,接著使用低秩子空間與K-means聚類方法(dual-regularized multi-view outlier detection, DMOD)對2類不同異常值進行同時檢測.然而,基于聚類的檢測方法對數據集中的異常樣本點比較敏感,常常導致聚類中心的偏差高,從而導致低檢測率.Li等人[20]將數據投影到低秩子空間進行學習(multi-view low-rank analysis, MLRA),然而該方法要求不同視圖有著相同的維度,因此在許多多模態應用場景中受到限制.
近年來,Li等人[15]深入總結多視角異常樣本的各種情況,并提出了第3類屬性-類別異常概念.為了檢測3類不同的異常,Sheng等人[21]提出了使用KNN(K-nearest neighbor)對不同視圖進行檢測的方法MUVAD(multi-view anomaly detection),該方法通過單個視圖對應的其余視圖數據近鄰關系進行相似度異常檢測,取得了在低維數據中很好的效果.然而該方法在高維數據樣本中的異常檢測效果欠佳.隨著神經網絡的發展,Ji等人[22]首次使用神經網絡對多視圖進行異常檢測(multi-view outlier detection in deep intact space, MODDIS),該方法利用神經網絡將各自視圖與融合視圖的特征進行提取疊加,取得了較好的多視角異常檢測效果.然而,在多模態數據中,不同模態數據樣本分布復雜、特征異構并且具有明顯的語義鴻溝,因此,該方法不適用于特征異構的多模態數據異常檢測.據文獻查證,針對多視圖數據中跨模態數據的異常檢測是一項較為嶄新的課題,有關此類問題的方法較少.Li等人[23]針對跨模態異常檢測問題,提出了基于深度網絡的跨模態異常檢測方法(cross-modal anomaly detection, CMAD),該方法首先使用單向三元組對跨模態數據進行訓練,然后通過相似度度量判斷不同模態之間的異常,可以有效地突破不同模態的語義鴻溝,進行跨模態異常檢測.然而,該方法僅僅只關注不同模態之間的相似性,從而會對具有相似性的不同模態異常樣本進行漏檢.同時,由于該方法使用單向的三元組損失函數,該損失函數忽略了許多其他有益于訓練的樣本,其訓練效果還有所欠缺.
2 研究方法
針對來源不同的多視圖異構數據,本文以圖像和文本為例介紹跨模態異常檢測學習框架.同時,針對現有跨模態異常檢測框架對3類異常值檢測不夠全面的問題,如圖3所示,本文提出的異常檢測框架采用了分層深度網絡結構.具體地,學習框架首先引入一個單視圖異常檢測網絡層,通過深層特征和模態內近鄰樣本相似度判斷來檢測數據樣本中是否存在屬性異常與屬性-類別異常點.若檢測出該數據沒有此類異常,進一步采用相似度雙向五元組損失的雙分支深度網絡用于檢測跨模態數據中的類別異常與屬性-類別異常,該損失使得不同屬性數據正交化、相同屬性數據線性相關,加大了不同屬性之間的特征的差異性,并同時提高了相同屬性之間的特征相關性.此外,學習框架通過模態間雙向約束和鄰域約束來提高樣本數據的利用率和增強模型的泛化能力.
2.1 形式化定義

2.2 結合深層特征與近鄰樣本的單視圖異常檢測
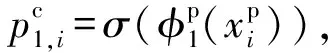
(1)
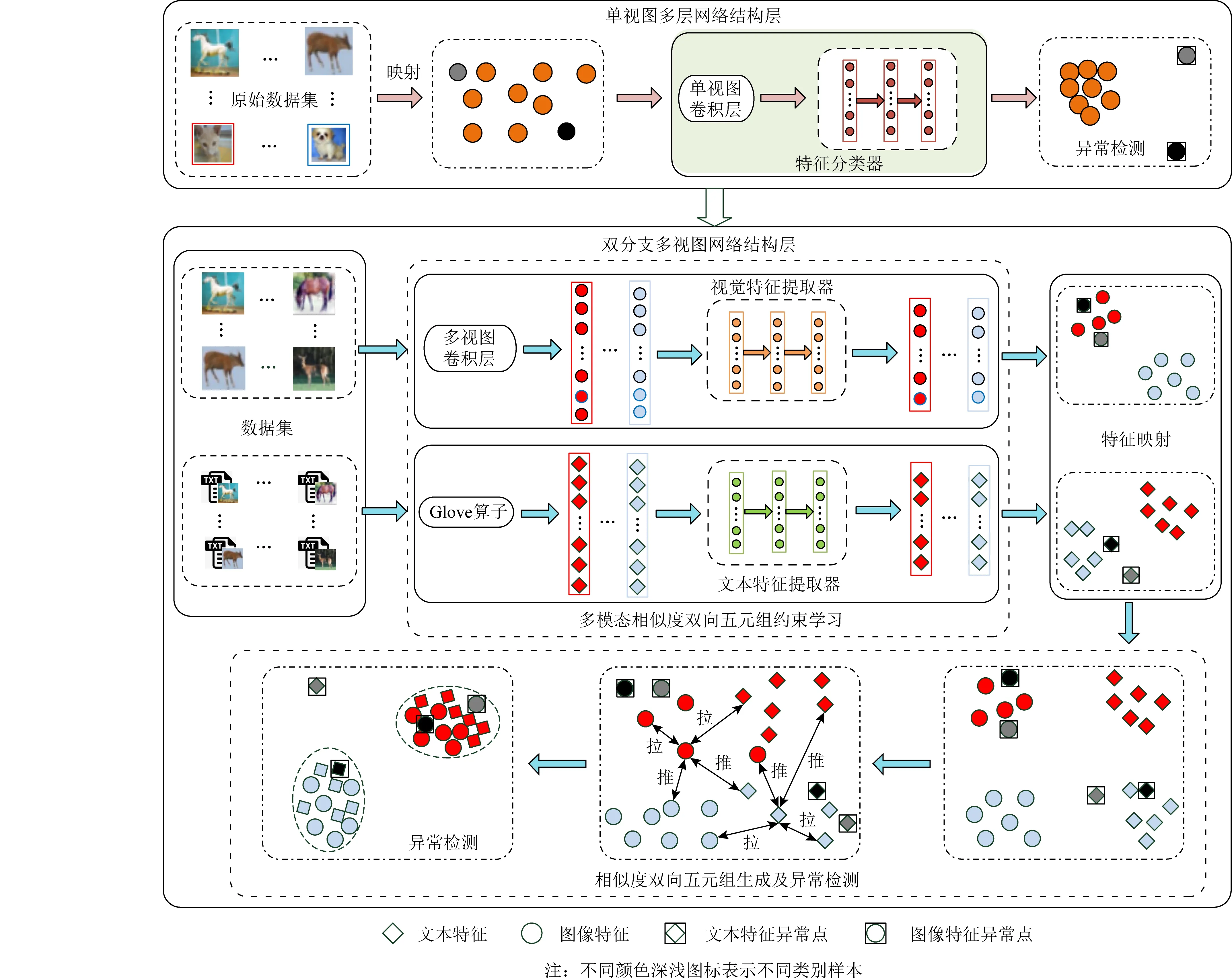
Fig. 3 The proposed cross-modal anomaly detection framework圖3 本文提出的跨模態異常檢測框架

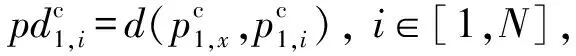
(2)
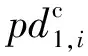
(3)
2.3 結合雙分支深度網絡與相似度雙向五元組的跨模態異常檢測

(4)
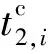
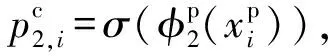
(5)
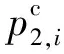
屬于同一樣本的多模態數據具有語義一致性.為刻畫圖片和文本的語義關聯性,本文采取相似度雙向五元組損失函數進行圖片文本的語義關聯性學習約束,該損失由多個相似度三元組損失構成,該損失函數使得不同屬性數據得以正交化,相同屬性數據線性相關,相似度三元組損失其形式化定義為
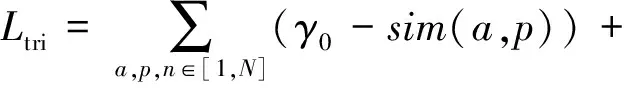
(6)
其中,a表示固定樣本,p表示與a屬于同一類別的正樣本,n表示與a屬于不同類別的負樣本,sim(a,p)表示固定樣本a與正樣本p對應的特征表達式之間的相似度;sim(a,n)表示固定樣本a與負樣本n對應的特征表達式之間的相似度,當sim(a,n)=0時固定樣本a與負樣本n正交.為了使得該損失函數收斂效果更好,本文在該損失函數中增加了一個松弛γ,γ表示sim(a,n)之間的相似度松弛.針對每個三元組(a,p,n),三元組損失的優化目標是讓sim(a,n)盡可能小于γ,sim(a,p)盡可能接近γ0,當sim(a,p)=1時,固定樣本a與正樣本p線性相關,并且該損失保證各個向量不為零向量,因此本文使用的γ0=1,且γ<γ0.
2.3.1 模態間的雙向約束
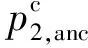

(9)
因此損失定義為

(10)
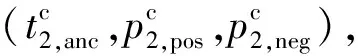
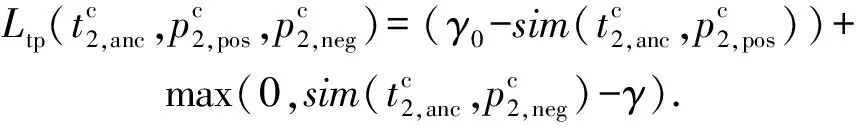
(11)
因此上述損失函數可以表示為
(12)

該損失函數對圖像-文本和文本-圖像數據進行了雙向語義關聯約束,使得不同模態間相同屬性的特征相關性增大,不同屬性的特征相關性減少.
2.3.2 模態內的鄰域約束
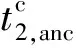

(14)
因此文本模態內鄰域損失定義為
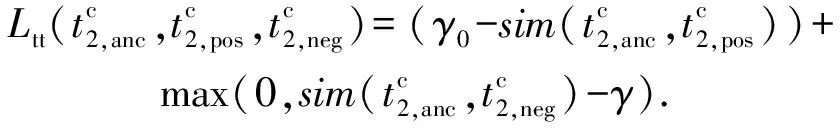
(15)
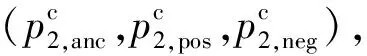
(16)
對相同模態之間進行鄰域約束,可以使得在相同模態之間不同屬性的數據特征相關性減少,相同屬性的數據特征相關性增大,不僅增加了數據的使用率,而且可以增大不同屬性數據的區分度.
2.3.3 訓練策略
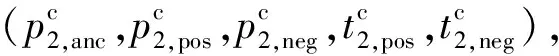
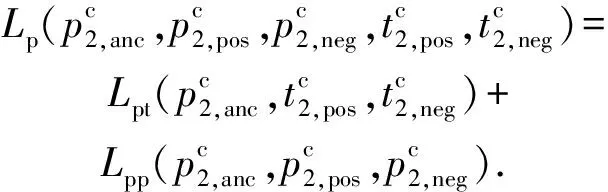
(17)
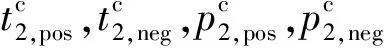
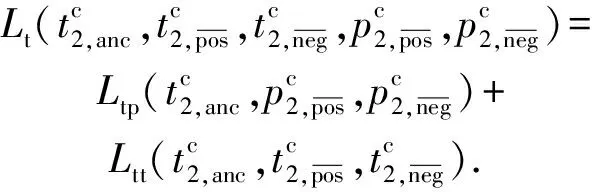
(18)
整個的相似度雙向五元組損失函數為
(19)
本文采用結合權重衰減和動量技術的隨機梯度下降方法(stochastic gradient descent, SGD)來優化模型.
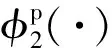
3 實驗與結果
為了充分評估本文所提出算法的有效性和魯棒性,本節進行了大量實驗來進行驗證.
3.1 數據集
本文采用3個公開的MNIST,FashionMNIST,CIFAR10數據集進行異常檢測算法性能評估,數據集的詳細信息描述為:
MNIST[24]數據集由7萬張原始圖像來代表1×28×28像素的10個不同數字.整個MNIST數據集分為6萬個訓練集和1萬個實例的測試集.
FashionMNIST[25]數據集是一個替代MNIST手寫數字集的圖像數據集,其涵蓋了來自10種類別標簽的共7萬個不同商品圖片.該數據集的大小以及訓練集/測試集劃分與MNIST數據集一致.
CIFAR10[26]數據集是一個用于普適物體識別的計算機視覺數據集,該數據集包含6萬張3×32×32的RGB彩色圖片,總共10個分類.其中,包括5萬張用于訓練集,1萬張用于測試集.
3個數據集同時包含圖片數據信息和類別標簽信息,因此本文參照文獻[23]的方法,根據類別標簽信息自動為每張圖像中添加文本標簽語義描述信息,并通過GLOVE詞嵌入方法將文本標簽信息嵌入到100維向量中,使得數據集綜合生成與圖片語義相對應的文本描述信息.本文從3個數據集中的訓練集分別取出5 000個實例作為驗證集,并確保其訓練集與驗證集不相交.
針對多視角數據存在3類異常樣本的問題,本文生成一定比例的跨模態3類異常數據.具體地,本文將一定比例的文本進行修改以及隨機注入其他類型的文本數據來生成文本屬性異常與屬性-類別異常的數據;同時,本文將一定比例圖片中的維度數據進行隨機生成來構建圖片屬性異常數據與屬性-類別異常,并選取一定比例文本和圖片進行隨機打亂來生成類別異常.
3.2 基線算法
本文采用了4種近3年來可用于跨模態異常檢測的算法進行比較:基于雙分支深度神經網絡嵌入的學習框架[27](embedding network, EN),通過測量不同模態之間的歐氏距離來區分跨模態異常;基于特征融合的深度神經網絡的學習框架(MODDIS);基于相似度的跨視圖KNN框架(MUVAD);以及深度網絡跨模態異常檢測的方法(CMAD).在實驗中,這些基線方法的參數設置與論文中描述一致.本文算法實驗中對L與Linter損失函數進行了對比實驗和分析,其損失函數中的超參數γ值設置為0.4.
3.3 評價指標
本文實驗中,使用Accuracy,FPR,TPR,AUC作為評價指標.AUC為ROC曲線面積,AUC值越高,該方法的性能越好;TPR為真正例率;FPR為假正例率.TPR的值越高,FPR的值越低,該方法性能越好,FPR,TPR公式為
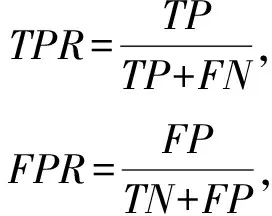
(20)
其中TP,FN,TN,FP分別代表真陽性、假陰性、真陰性和假陽性的數量.Accuracy為檢測準確率,公式為

(21)
3.4 性能對比
表1~3顯示了3種不同數據集異常檢測的Accuracy,FPR,TPR,AUC的平均值.

Table 1 Results on MNIST Anomaly Detected by Each Framework
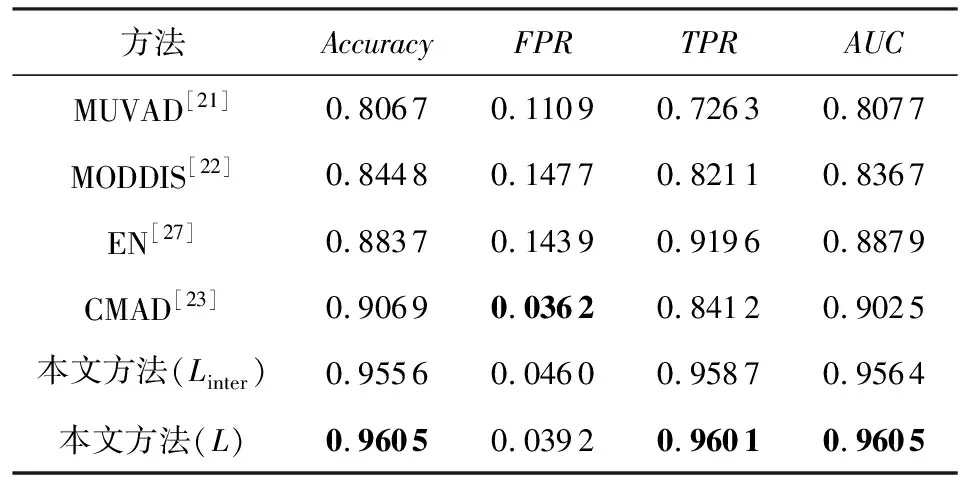
Table 2 Results on FashionMNIST Anomaly Detected by Each Framework
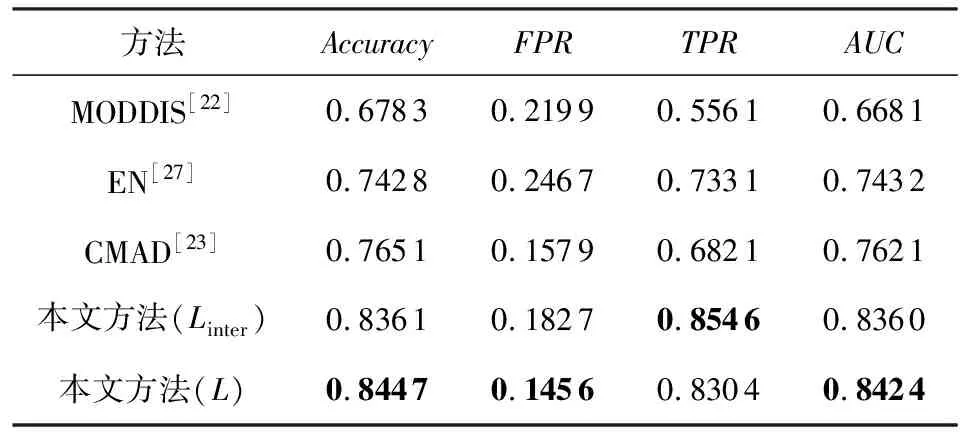
Table 3 Results on CIFAR10 Anomaly Detected by Each Framework
可以看出,本文所提出的方法優于所有的基線方法,相較于多視角異常檢測的方法,本文的方法有著很大的優勢.由于本文使用的數據集維度相較于文獻[21]中所使用的維度更大,MUVAD算法中所使用的KNN算法存在維度災難,因此,該算法在低維數據中性能較好,而在本文所使用的數據集中的準確率較低.由于不同模態的數據維度差距較大,基于特征融合的MODDIS算法在融合過程中會出現圖片數據起主要作用的情況.由于CIFAR10數據集中的圖片數據維度的占比相比于其他數據集更高,因此,該算法在CIFAR10數據集中的準確率相比與其余數據集更低.CMAD算法在較為簡單的MNIST數據集上可以達到與本文方法相當的性能,但在相對語義多樣的FashionMNIST與CIFAR10數據集中表現出低于本文提出的方法的性能.在表1與表4中可以看出在MNIST數據集中,Linter損失相比于L損失時的表現更好,其原因在于使用Linter損失函數時,該損失關注不同模態間的學習,L損失關注不同模態間學習的同時也進行模態內的學習,增加了學習復雜度,而MNIST數據集相對于其他數據集模態內的區分度較高,即模態內不同屬性的數據區分明顯,導致L損失相對于Linter損失沒有優勢,因此L損失在MNIST數據集中的表現比Linter損失差.圖4顯示了不同方法在相同指標下的對比曲線圖,可以看出本文提出的方法在相同指標下始終優于其余基線方法,實驗證明了本文方法的有效性.
此外,實驗同樣在FshionMNIST與CIFAR10數據集上進行驗證和測試.從表5和表6實驗結果可以看出準確率在不同異常比情況下屬性異常數據/屬性-類別異常數據的變化情況.特別地,在MNIST數據集中表現良好的CMAD學習框架,在FshionMNIST與CIFAR10數據集異常比例上升中異常檢測效果表現出整體下降的趨勢比較顯著.
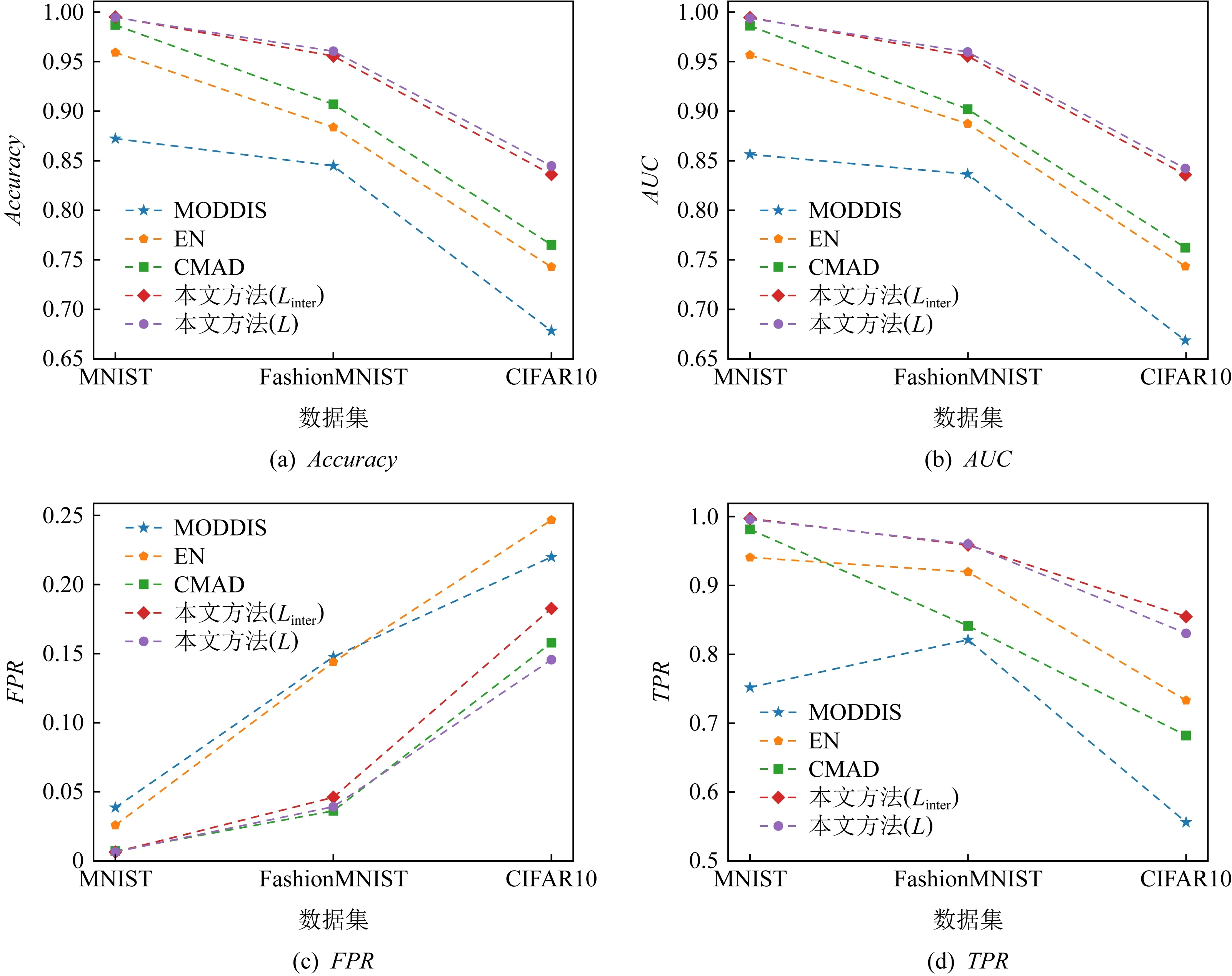
Fig. 4 Performance comparison of each method on different datasets圖4 各個方法在不同數據集中性能比較
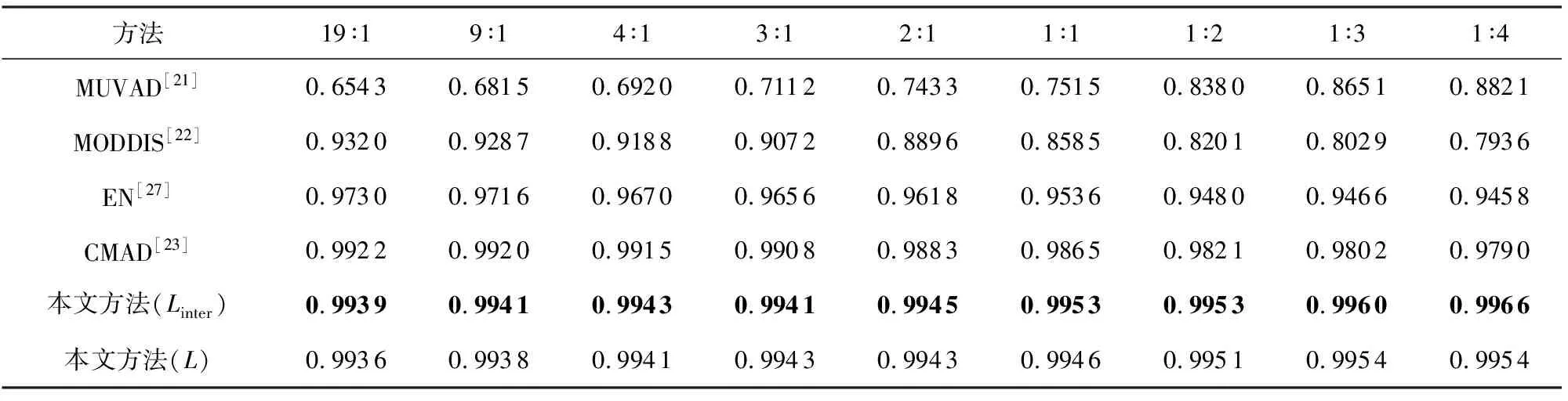
Table 4 Accuracies Obtained by Different Frameworks with Diverse Abnormal Proportions (MNIST)表4 各框架對比不同異常比例的準確率(MNIST)
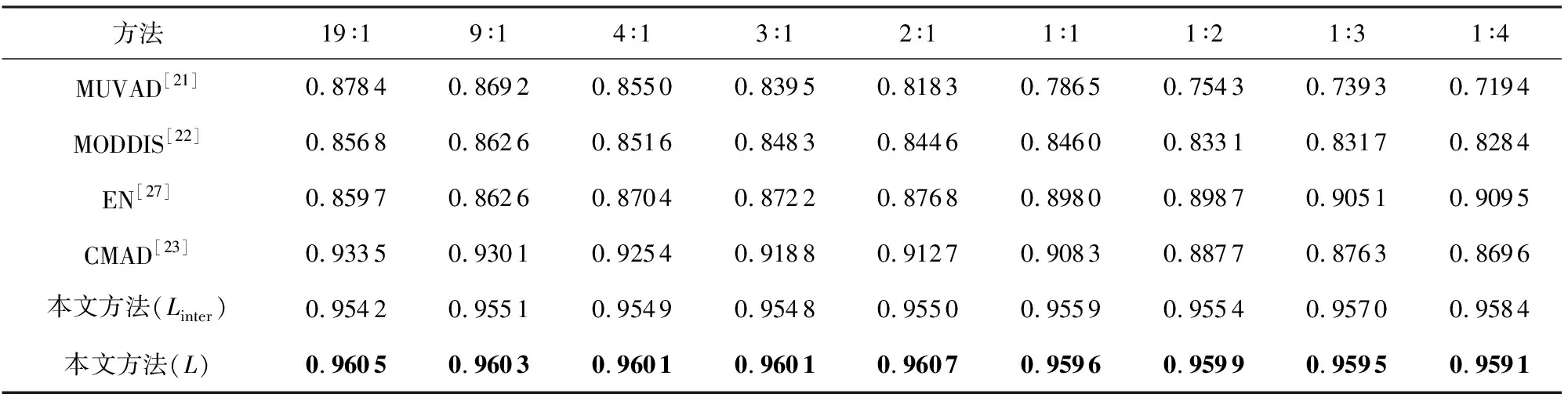
Table 5 Accuracies Obtained by Different Frameworks with Diverse Abnormal Proportions (FashionMNIST)表5 各框架對比不同異常比例的準確率(FashionMNIST)

Table 6 Accuracies Obtained by Different Frameworks with Diverse Abnormal Proportions (CIFAR10)表6 各框架對比不同異常比例的準確率(CIFAR10)
相比較而言,本文提出的跨模態異常學習框架同樣保持著在不同異常比例下較高情況下較好的準確率,并在不同占比的異常數據中保持著穩定的檢測精度.
綜上所述,本文所提出的方法相較于基線算法有著更好的魯棒性以及更高的準確率,究其原因在于:1)本文算法首先使用單視圖網絡檢測結構可以有效檢測出數據中的屬性異常,以降低屬性-類別異常的漏檢性,初步增加了檢測的準確率;2)本文算法使用相似度雙向五元組損失,加大了不同屬性數據之間的特征差異性,同時增加了相同屬性之間的特征相關性;3)提出的雙向約束框架在相同數量的數據集下可以得到充分的訓練,數據利用率高,從而使得訓練的模型泛化能力較強,可適用于不同類型的異常樣本檢測.實驗結果表明了提出方法的有效性.
4 總結與展望
針對極具挑戰性的多源異構數據的跨模態異常檢測問題,本文提出了一種結合分層深度網絡與相似度雙向五元組的跨模態異常檢測方法,該方法充分考慮模態內和模態間的各種異常差異,并采用單視圖網絡和雙分支網絡相結合的方法,可以有效適用于不同類型的跨模態異常檢測,在不同數據集中均獲得了顯著的效果,并且在3類不同類型的跨模態異常檢測情況下的表現幾乎全面超過了現有的方法,有效地提高了檢測的準確率,相關實驗驗證了本文提出方法的有效性.在下一階段的研究工作中,本學習框架將進一步探究不同參數的搭配對不同多模態數據集運行結果的影響,盡可能挖掘一種自適應參數的選擇方法用來適配形式各異的多模態異常數據集.
作者貢獻聲明:范燁負責算法設計與論文撰寫;彭淑娟負責模型優化和論文撰寫;柳欣負責模型可行性分析;崔振負責算法優化;王楠楠負責實驗的多樣性分析.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
