基于記憶網絡的知識感知醫療對話生成
2022-12-15 13:19:18張曉宇李冬冬任鵬杰陳竹敏任昭春
計算機研究與發展 2022年12期
張曉宇 李冬冬 任鵬杰 陳竹敏 馬 軍 任昭春
(山東大學計算機科學與技術學院 山東青島 266237)(xiaoyu.zhang@mail.sdu.edu.cn)
醫療是人們生活中不可少的組成部分,但是部分患者的就醫條件受到制約.一方面,醫療資源稀缺,醫生供不應求;另一方面,患者受時空限制,無法抽出時間或行程不便,導致許多患者無法及時得到診斷和治療.
基于患者需求與客觀條件制約之間的沖突,我們希望模擬醫生對用戶的詢問作出回答,且為用戶提供更便利的在線咨詢方式,從而解決時空沖突問題.本文提出了一種基于記憶網絡的知識感知醫療對話生成模型(memory networks based knowledge-aware medical dialogue generation model, MKMed).
記憶網絡主要解決任務的知識源多、需要容納大量信息和進行復雜推理等需求,且能夠使長期記憶得到更好的保存.Weston等人[1]在2014年首先提出了記憶網絡的結構體系,該網絡包含4個模塊,“input feature map”用于編碼知識、“generalization”用于更新舊記憶、“output feature map”用于產生新的輸出向量、“response”用于將上一模塊的輸出轉換為回復.Sukhbaatar等人[2]在2015年擴展了這項工作,使得記憶網絡可以被端到端的訓練.Kumar等人[3]在2016年提出了動態記憶網絡,使其在Face-book的bAbI數據集上進行的“Counting and Lists/Sets”任務中得到了很大的改進.Xu等人[4]在2016年通過在最后一層推理中加入復制機制,解決了超出詞匯表單詞如電話號碼、航班號等的問題.
本文提出的基于記憶網絡的知識感知醫療對話生成模型恰好面臨著記憶網絡針對的難點,因為需要同時處理醫患的對話歷史信息以及醫療數據庫中的知識信息,即信息源多且復雜,需要多步的推理,所以模型采用了記憶網絡的基本理念,將各信息源進行編碼,寫入記憶存儲單元,然后結合記憶網絡中存儲的向量進行解碼,生成最終回復.
根據生活常識,為了給出正確的診斷和適當的治療,醫生通常考慮癥狀和疾病.如果該醫生以前遇到過相同的癥狀和疾病,則會通過經驗給出答案,如果出現的是罕見的疾病,該醫生通常會查閱相關的醫學文獻.醫學文獻和醫生的經驗可以被視為醫療知識.總結上述過程,我們發現:醫學知識是生成回復不可缺少的一部分.因此本文提出的模型將外部知識納入醫學對話的生成.
知識感知生成任務指的是根據準確的外部知識生成回復.根據知識的結構進行劃分,目前此類任務可以被分為2類,分別是結構化知識感知生成以及非結構化知識感知生成任務,前者主要利用三元組知識[5-6]或者知識圖譜[7-8],后者多基于非結構化文本知識[9-10].本文提出的模型MKMed利用三元組知識優化回復生成.Liu等人[5]在2018年提出了NKD模型,該模型設計了實體匹配和實體發散模塊,直接結合對話歷史的編碼向量,使用多層感知機等抽取并預測相關三元組知識.2019年Liu等人[7]提出的AKGCM模型根據對話歷史擴充知識圖譜,以便在開放域對話任務中與對話歷史更好地結合.2019年Lian等人[9]提出了PostKS模型,該模型利用非結構化知識的后驗分布來指導回復生成時知識的選擇,從而優化基于知識的對話回復生成.目前存在的大多數知識感知生成方法無法應用于醫療場景,如只針對從開放域知識庫中選擇知識;或者無法處理規模龐大醫療有關的外部數據庫;又或無法解決醫療對話任務中需要根據對話歷史多步推理進行診斷的問題等.因此本文提出的MKMed模型引入專用的醫學領域三元組知識進行知識實體追蹤以及2階段的預測,從而多步篩選,并使用記憶網絡以及多跳注意力機制進行推理.
圖1是一組醫患對話的例子,圖1(a)是對話歷史,圖1(b)是出現在對話歷史中有助于診斷和醫療推薦的實體與外部知識.患者和醫生的對話歷史中可能出現許多疾病、癥狀,我們可以通過直接精確詞匹配從對話歷史中提取這些實體.圖1(b)部分顯示了出現在對話中的疾病和藥品部分的實體以及對應的癥狀、病原和治療方法等三元組知識.我們發現圖1(b)展示的三元組知識,如〈過敏性鼻炎;癥狀;流鼻涕,打噴嚏,鼻子發癢〉和〈丙酸氟替卡;適用;鼻炎〉,有助于診斷和推薦藥物.因此可以佐證:理解對話歷史中的實體對于生成正確的回復至關重要.

Fig. 1 Example of multi-turn doctor-patient dialogue圖1 醫患多輪對話示例
我們把這些從對話歷史中抽取的實體對應的知識命名為追蹤知識.考慮到如果僅匹配出癥狀等實體可能導致缺乏治療信息,又部署了知識預測器來篩選出可用于回復生成的實體對應的知識,這些知識被稱為預測知識;然后,知識寫入模塊將追蹤知識和預測知識的三元組編碼成向量表達,并分別寫入對應的記憶網絡存儲單元;最終,回復生成模塊通過整合在記憶網絡中保存的信息生成回復.
本文在帶有外部知識的大規模醫療對話數據集KaMed[11]上進行了相關實驗,該數據集中的醫療對話收集來自在線中文醫療咨詢平臺“春雨醫生”[12],醫學知識爬取來自最大的中文醫學知識平臺“中文醫學知識圖譜”[13],皆為真實數據.實驗結果表明基于記憶網絡的知識感知醫療對話生成模型在回復生成的流暢性、多樣性、正確性和專業性等方面顯著優于大部分基準模型.
1 相關工作
現有的醫學對話回復生成模型大多是任務導向型對話類型,患者表達癥狀,對話系統將其分類為相應的疾病.最初醫療診斷任務多是基于電子健康記錄進行自動診斷[14],如2018年Tou等人[15]發表的論文中提出的感染檢測系統.但是電子健康記錄需要通過復雜專業的醫療診斷程序來獲得,信息獲取的代價很高.為了解決這個問題,Wei等人[16]在2018年的論文中提出了利用病人自述以及自動識別對話歷史信息中出現過的癥狀,然后通過強化學習和模板來產生回復的方法.在此基礎上,Lin等人[17]在2019年的論文中通過從數據集語料庫中抽取癥狀圖來對癥狀之間的關系進行建模,以提高癥狀提取識別的性能.Xu等人[18]在2019年的論文開發了一個對話系統,引入外部知識圖譜,結合已經標注好的患者對話信息,顯示考慮癥狀與疾病的概率,結合強化學習做出決策概率,最后依然用模板生成回復.雖然以上工作都致力于研究醫療對話生成這一課題,但不能應用于真實的醫療場景.一方面對話歷史中出現的癥狀和疾病等需要大量的人工標注,是勞動密集型的,并且醫療診斷任務被視為分類問題,隨著疾病和癥狀對的增加,模型的學習復雜度會變得很高.另一方面,醫學領域知識通常是動態變換和大規模的,現有的方法只處理有限的特定疾病,這導致它們不適用于疾病和癥狀多的場景.最后上述模型都使用給定的模板生成回復,不能同時給出診斷和醫療建議,用戶使用體驗不佳.因此本文將外部知識融入醫學對話生成,使用精確詞匹配自動識別醫療實體并可動態擴展外部實體知識庫.
2 研究方法
2.1 問題定義
醫療對話生成任務需給定醫患對話歷史,對話歷史由多輪句子組成,可表示為H={S1,S2,…,S|H|}.
給定外部實體知識數據庫,醫療實體集合用E={e1,e2,…,e|E|}來表示.根據Bordes等人[19]在2015年提出的方法,將事實定義為包含頭實體h、關系r和與頭實體h具有關系r的尾實體集合t的三元組.本文中每條知識以(頭實體h,關系r,尾實體集合t)的三元組形式來組織,表示為τi,j.所有以ei為頭實體的三元組知識集合表示為G(ei)={τi,1,τi,2,…,τi,|G(ei)|}.每條知識經分詞后由一系列詞組成,可表示為τi,j={Wi,j,1,Wi,j,2,…,Wi,j,|τi,j|}.
模型需要根據對話歷史H生成回復,表示為Y={y1,y2,…,yi,…,y|Y|},yi代表Y中的第i個詞.
2.2 模型結構
本文提出了基于記憶網絡的知識感知醫療對話生成模型.模型需要在與用戶的交互過程中收集用戶信息,模擬醫生在外部數據庫中進行搜索并預測實體知識,最后結合信息,生成一個通順回復.模型框架如圖2所示,主要包含4個模塊:對話歷史編碼模塊、知識實體追蹤與預測模塊、知識寫入模塊和回復生成模塊.
1) 對話歷史編碼模塊讀取給定的對話歷史H并編碼成句子級別表示,寫入“歷史記憶”存儲單元.
2) 知識實體追蹤部分追蹤對話歷史中出現過的實體及對應知識,知識實體預測部分搜索外部數據庫,預測可能出現在生成的回復里的實體,并且輸出其在數據庫內對應的知識.
3) 知識寫入模塊依賴知識實體追蹤與預測模塊,以它輸出的知識集合作為輸入,將三元組進行編碼,然后寫入“追蹤記憶”存儲單元和“預測記憶”存儲單元.
4) 回復生成模塊依賴對話歷史編碼模塊和知識寫入模塊,集成它們寫入的4個記憶網絡存儲單元:追蹤記憶、注意力記憶、預測記憶和歷史記憶,生成目標回復.
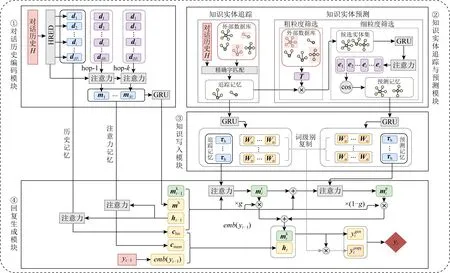
Fig. 2 Framework of MKMed圖2 基于記憶網絡的知識感知醫療對話生成模型框架
2.3 對話歷史編碼模塊
為了解決句子信息稀釋問題,更好地進行信息傳遞,本模塊使用分層循環神經網絡編碼解碼結構(hierarchical recurrent encoder-decoder, HRED).
給定對話歷史H={S1,S2,…,S|H|},首先利用HRED的編碼器循環神經網絡對句子Si進行編碼,得到句子級別表達{So,1,So,2,…,So,|H|},So,i∈h,h是門控循環單元(gate recurrent unit, GRU)的隱狀態維度.然后依次向HRED的上下文循環神經網絡輸入{So,1,So,2,…,So,|H|},得到帶有上下文信息的句子級別表達D={d1,d2,…,d|H|},最后時刻的隱層輸出記為dh,并將D寫入“歷史記憶”存儲單元.
根據Sukhbaatar等人[2]在2015年發表的端到端記憶網絡工作里提到的多跳注意力機制方法,本文對歷史記憶存儲器中D進行k跳注意力運算.第t跳運算使用的query記為mt,D內向量作為key和value,特別地,dh作為初始querym0.具體公式描述如式(1)所示:
(1)
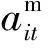
進行k跳運算后,得到“注意力記憶”存儲單元Mh的內容,記作Mh={m1,m2,…,m|k|}.最后,用基于GRU的循環神經網絡編碼Mh內向量,最后時刻輸出的隱狀態向量聚合了Mh的所有信息,記為mh.
2.4 知識實體追蹤與預測模塊
患者希望得到更專業的醫療建議,僅從對話歷史中獲取信息是不可行的,因此本文引入了額外信息:外部實體知識數據庫.因為庫中包含所有搜集到的醫療實體及對應知識,數據量龐大,且絕大部分數據與當前對話無關,所以將其全部編碼存入記憶網絡是不可行且非必要的.為了解決此問題,本文設計了知識實體追蹤與預測模塊.
知識實體追蹤與預測模塊分為2個部分:一部分負責追蹤對話歷史中出現過的實體,這些實體與當前醫療對話密切相關,對應的知識是生成與上下文一致的回復的關鍵;另一部分進行實體預測,保證回答的多樣性和專業性,為推理出沒有出現在對話歷史的實體和知識提供基礎.
2.4.1 知識實體追蹤
知識實體追蹤部分需要跟蹤在對話歷史中出現過的實體.通過精確詞匹配,該部分將分詞后的對話歷史H與數據庫中的實體名進行匹配,如果匹配到實體e,我們則稱e為追蹤實體,并將其對應的三元組知識集合G(e)存儲在“追蹤記憶”存儲單元內.本文把追蹤實體的集合命名為Etracker,對應三元組知識集合命名為Gtracker={G(e);e∈Etracker}.
2.4.2 知識實體預測
知識實體預測部分期望從數據庫中篩選出從未出現在對話歷史,卻需在回復中使用的實體和知識.知識預測部分又分為粗粒度篩選和細粒度篩選2個階段.
1) 粗粒度篩選階段
粗粒度篩選使用統計實體之間共現概率的方法.該階段首先利用模型訓練時使用的全部醫患對話記錄數據集,統計出所有實體間的共現概率,記共現概率矩陣為T,T∈b×b,這里b為外部數據庫中的實體數目,Ti,j為實體ei和實體ej同時出現的概率.接著該階段將Etracker轉換為one-hot向量表示vtracker∈b,如果實體ei為追蹤實體,則否則在粗粒度篩選階段,任意實體被選為預測實體的概率vpredictor∈b用vtracker與T相乘得到,因此未在對話歷史中出現的實體也有被選中概率,如式(2)所示:
vpredictor=vtracker×T.
(2)
又因為本文希望增加回復的多樣性,避免預測實體與追蹤實體的重疊度過大,所以從實體全集中過濾掉追蹤實體的部分,剩余部分記為Eglobal,如式(3)所示:
Eglobal={e;e∈E∧e?Etracker}.
(3)
我們在Eglobal中根據vpredictor選擇概率最高的c個候選實體,對應集合記為Ecandidate,這里c是候選實體數量的超參.
2) 細粒度篩選階段
細粒度篩選階段旨在從Ecandidate的c個候選實體中篩選出標準預測實體.主要用到余弦相似度來表示實體被選中的匹配度.
實體e的表示向量用它的三元組知識集合G(e)編碼而來,如式(4)所示:
ti=BiGRU(τi),
(4)
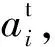
(5)
(6)
使用式(4)~(6),我們可以計算得到Ecandidate和Etracker中各實體對應的向量表達,分別記為ec和et.
在此基礎上,與式(5)(6)的計算過程相似,本文使用式(7)得到追蹤實體集合Etracker的表達向量htc:
(7)
htc+dh包含對話歷史和追蹤實體集合的信息,本文計算它與候選實體集合Ecandidate中實體的表達向量ec的余弦相似度s,如式(8)所示:
s=cos(ec,htc+dh).
(8)
本文選擇s最高的f個實體為預測實體,記集合為Epredictor,其中f是超參,是目標預測實體個數.又將Epredictor在外部數據庫中對應的三元組知識集合存放在“預測記憶”存儲單元內.
2.5 知識寫入模塊
本模塊將“預測記憶”和“追蹤記憶”存儲單元中每條知識τ用雙向門控循環單元編碼,最后時刻隱層輸出的向量τh記為知識的向量表達.如式(9)所示:
τh=Wτ×BiGRU(τ),
(9)
其中Wτ是可訓練矩陣,記編碼后的“追蹤記憶”存儲單元為Mt,記編碼后的“預測記憶”存儲單元為Mp.另外,我們把雙向門控循環單元編碼過程中每時刻輸出的詞級別向量表達,即“追蹤記憶”和“預測記憶”存儲單元中所有知識分詞{W1,W2,…,W|B|}的表示,記為{Wo,1,Wo,2,…,Wo,|B|}.
2.6 回復生成模塊
回復生成模塊利用在對話歷史編碼模塊中生成的“歷史記憶”存儲單元內D,dh;“注意力記憶”存儲單元內Mh,mh;知識實體追蹤與預測模塊中生成的“追蹤記憶”存儲單元Mt;“預測記憶”存儲單元Mp生成回復.
本文在此模塊中也引入注意力機制,運算過程與式(7)相同.為了方便描述,將回復生成模塊在時刻t-1預測出目標詞時產生的狀態向量記為ht-1,作為注意力運算的query,另記作Q,而D和Mh內向量分別作為key和value,另記作K與V,運算得到的輸出向量O分別記作“歷史記憶”的表示向量chis和“注意力記憶”的表示向量cmem,運算過程如式(10)所示:
(10)
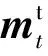
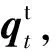
(11)
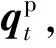
(12)
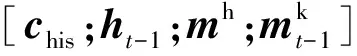
(13)
(14)
將時刻t-1生成詞對應的詞嵌入與cmem和chis拼接,用門控循環單元編碼,可得時刻t的第1個狀態向量,記作ht,如式(15)所示:
ht=GRU([emb(yt-1);cmem;chis]).
(15)

(16)
(17)
其中Wtrans∈h×2h和Wgen∈sizevocab×h是可訓練參數,sizevocab是字典大小.
我們通過觀察標準回復發現,目標回復大概率帶有選中實體對應的知識中的分詞,故而為了生成更接近標準的回復,本文引入復制網絡,設計時刻t輸出詞yt的復制概率為pcopy(yt),計算過程如式(18)所示:
(18)
其中Wo,j是“追蹤記憶”和“預測記憶”存儲單元內第j個知識分詞Wj的向量表示,I(x,y)為判斷目標x是否等于y的指標函數,即相等則返回1,否則返回0,Z是歸一化因子.
時刻t生成詞yt的概率分布為歸一化后的復制概率pcopy(yt)與生成概率pgen(yt)的和,記為p(yt),如式(19)所示:
p(yt)=softmax(pcopy(yt)+pgen(yt)).
(19)
2.7 模型訓練
模型有2個訓練目標,分別是正確預測實體以及生成與標準一致的回復,所以本文分別在知識實體追蹤與預測模塊以及回復生成模塊內計算損失.
在知識實體預測部分的粗粒度篩選過程中,由于非標準預測實體個數過多,即僅極少數實體出現在標準回復中,計算每個實體的余弦相似后求負對數似然損失會使計算量超負荷,所以本文使用Max-margin損失來計算實體預測損失Lpred,如式(20)所示:
(20)
其中epos和eneg為我們利用式(4)~(6)運算得出的標準預測實體和從數據庫中采樣出的非標準預測實體得到的向量表示.受Lin等人[20]在2017年提出方法的啟發,我們用因子α來緩解類間不平衡,σ是sigmoid函數,K是超參.
回復生成模塊內的生成損失Lgen計算如式(21)所示,即計算交叉熵損失函數:
(21)
總的損失函數由實體預測損失Lpred和生成損失Lgen根據超參λ加權求和構成,如式(22)所示:
L=Lgen+λ×Lpred.
(22)
3 實驗結果與分析
3.1 實驗數據
為了評估本文提出的基于記憶網絡的知識感知醫療對話生成模型,本文在帶有外部知識的大規模醫療對話數據集KaMed(knowledge-aware medical dialogue dataset)[11]上進行實驗.它主要由2部分組成:對話部分、知識部分,包含超過60 000個醫療對話和5 682個實體.對話部分是從中文在線醫療咨詢平臺“春雨醫生”上爬取的網頁解析而來的.知識部分收集自最大的中文醫學知識平臺“中文醫學知識圖譜”,包含了疾病、藥物以及治療技術和設備的結構化知識描述.其中對話部分分別取3 000輪對話用于驗證和測試,其余用于訓練.
3.2 實驗設置
實驗的代碼是在pytorch-1.2.0深度學習框架上實現的.為了緩解計算壓力,只提取要預測的醫療信息的前10句話作為對話歷史信息輸入到模型里.字典中分詞個數限制為30000,詞嵌入維數設置為300,且模型中所有的編碼解碼器的隱層以及輸出層維數設置為512.另外在外部知識預測的粗粒度篩選中,Ecandidate的實體個數c=200,Epredicator的實體個數f=5.在實體預測損失部分中K=10.0,總損失函數的λ=1.0.實驗使用的參數優化器為Adam,初始學習率設置為exp(-4),隨著訓練進行以0.1的比率衰減,逐漸下降到exp(-5).數據集分詞使用北京大學開源分詞工具pkuseg[21].在測試過程使用的束搜索中束寬設置為5.
3.3 評價標準
本文使用了自動評價以及人工評價2種評估方式對模型進行評價.
自動評價主要采用BLEU@N[22]來衡量生成的回復與標準回復之間的重疊度,另外采用了Distinct@N指標,如式(23)所示:
(23)
其中,Count(unique_n_gram)表示回復中不重復的n_gram分詞數量,Count(n_gram)表示回復中n_gram分詞的總數.Distinct@N用于計算生成回復的全集內的多樣性,檢測模型是否產生了安全回復.BLEU和Distinct指標內N皆取1~4.為了衡量模型引入外部知識后生成回復的正確性,本文還使用了回復中生成的實體的F1指標,即利用精確詞匹配方法從標準回復和生成回復中分別抽取出現的實體,以標準回復的實體集合為基準,計算得到生成回復的實體集合的F1指標.其中,為了防止模型重復生成對話歷史中出現過的醫療實體詞從而達到較高的F1指標,防止缺乏實際應用價值的情況出現,進而確保獲得高F1指標的模型生成用戶真正需要的回復,我們對標準和生成回復的實體集合都進行了篩選,刪除了在對話歷史中出現過的實體,僅利用回復中創新性提出的醫療實體來計算F1指標.為了驗證模型是否能夠充分利用外部知識,本文還加入了計算生成回復的全集中實體密度的指標,如式(24)所示:
E@d=|{r;r∈R;r∈B}|/|R|,
(24)
這里R表示生成的回復的集合,B代表外部數據庫中實體的集合,公式目標是計算同時出現在生成回復和實體集合中的詞的比例.本文把生成回復的全集中出現的實體種類數量也作為一個重要指標,顯而易見,出現的實體種類數量越多,回復的多樣性也就越高,實體種類記為E@c.
考慮到客觀指標的局限性,本文在實驗中進行了人工評價.考慮了4個指標,分別是:1)流利度,即生成的回答語法是否正確,句子是否通順.2)相關性,生成的回復與上下文是否一致.3)知識性,回復中包含有關實體知識的信息量的多少.4)正確性,推薦的治療方法或藥物及診斷是否正確,雖然本文已經對模型的正確性進行了自動評價,但是考慮到正確答案并非局限于標準回復中出現過的醫療實體,因此通過引入正確性的人工評價來鑒別出多樣的正確回復.
3.4 結果分析
為了評價基于記憶網絡的知識感知醫療對話生成模型的性能,本文選擇了以下10個合適的基準模型與它進行對比,這10個基準模型分別是:
1) 帶有注意力機制的Seq2Seq模型[23].此基線模型由編碼器和解碼器構成,將輸入序列轉換為輸出序列.這里將對話歷史H作為輸入,用循環神經網絡進行編碼,提取H的信息.將最后時刻輸出的隱層向量輸入到解碼器內生成回復.
2) HRED[24]模型.用分層編碼器建模對話歷史H,得到帶上下文信息的句子級別表達,最后解碼出回復.
3) Transformer模型[25].它摒棄了傳統的序列模型,用自注意力機制建模對話歷史H,可以并行處理序列中的數據且同時產生帶有上下文信息的表達,并生成回復.
為了對比公平,在上述3個基準模型的基礎上,本文在對話歷史H后拼接追蹤實體對應的知識作為輸入,又得到3個基準模型:
4) Seq2Seq-k模型.
5) HRED-k模型.
6) Transformer-k模型.
本文還引入了另外4個基準模型,分別是:
7) Copynet[26]模型.類似地,以對話歷史H后拼接追蹤實體對應的知識作為基線模型的輸入.
8) CCM[8]模型.此對話模型同樣基于外部知識,利用知識圖譜生成回復的在CCM中以對話歷史H為輸入,同時傳入KaMed的外部知識.
9) PostkKS[9]模型.此模型利用后驗信息來指導知識選擇,從而優化回復生成.在此模型中也以對話歷史H和KaMed的知識部分為輸入.
10) MOSS[27]模型.此模型的對話動作模塊預測回復中存在的實體,結合對話歷史以及此模塊的輸出,端到端的生成回復,這里以對話歷史H和KaMed的實體部分為輸入.
3.4.1 自動評價
從表1中可以得出觀察結果:首先,本文提出的MKMed模型在F1,E@d,E@c指標上遠優于所有基準模型,這表明基于記憶網絡的知識感知醫療對話生成模型可以在回復中生成更多樣且更正確的醫療專業知識相關信息,通過直接觀察各模型生成的結果,也發現MKMed生成的回復與醫生真實的專業標準回復更加相似.同時MKMed模型在BLEU度量上優于大部分基準模型,這說明了MKMed模型在高知識性和專業性的基礎上也保證了流暢性.其次,在Distinct指標上,CopyNet和MOSS比MKMed模型表現更好,通過對生成結果的分析,我們發現CopyNet和MOSS傾向于復制輸入的對話歷史或知識中的分詞,即使這些詞與上下文并不一致,這可能是造成它們產生的回復更加多樣性的原因.總的來說,MKMed模型在Distinct和實體指標上遠優于大部分基準模型.另外,PostKS模型雖然利用外部數據庫生成回復,但是在實體指標上表現不佳,我們考慮這是因為PostKS無法從大規模的候選知識庫中找到合適的知識,故而效果不好,這也說明了MKMed利用實體的共現矩陣進行一步篩選的優越性.最后,通過實驗結果觀察到,HRED,Transformer,Seq2Seq基準模型的性能隨著知識的融入,在某些指標上反而更差了,可以推理出,將外部知識信息整合到會話生成任務中時,需要針對附加的信息設計融入的方案,否則會干擾原始信息.

Table 1 Automatic Evaluation Results
表示每種實驗設置下的最佳結果.
3.4.2 人工評價
考慮到語言生成任務中客觀評測指標的局限性,采用人工評測來驗證基于記憶網絡的知識感知醫療對話生成模型的優越性.具體來說,從測試集合中隨機抽取了200個樣例,使MKMed及2個最具競爭力的基準模型:Copynet和CMM,基于樣例生成回復.
隨后將MKMed生成的回復分別與Copynet和CMM 的回復進行組合,由3 名醫學研究生進行人工評價,從流利度、相關性、知識性和正確性4個角度判斷MKMed與對比模型相比生成回復的質量為勝、平手或是負,最終得出了各對比結果數在樣例總數中的比例,同時使用Kappa系數來判斷3名醫學研究生人工評估的一致性.
結果如表2所示,本文提出的模型在所有指標中都達到了最好的性能.但是考慮到相關性指標上Kappa系數很小,可能得出結論相關性指標太主觀,所有評測人員很難達成一致.基于記憶網絡的知識感知醫療對話生成模型在知識性、正確性和流利度上以較高的Kappa系數優于2個對比模型,其中在正確性和知識性上有顯著優勢,驗證了該評價的可靠性和本文提出的模型的優越性.
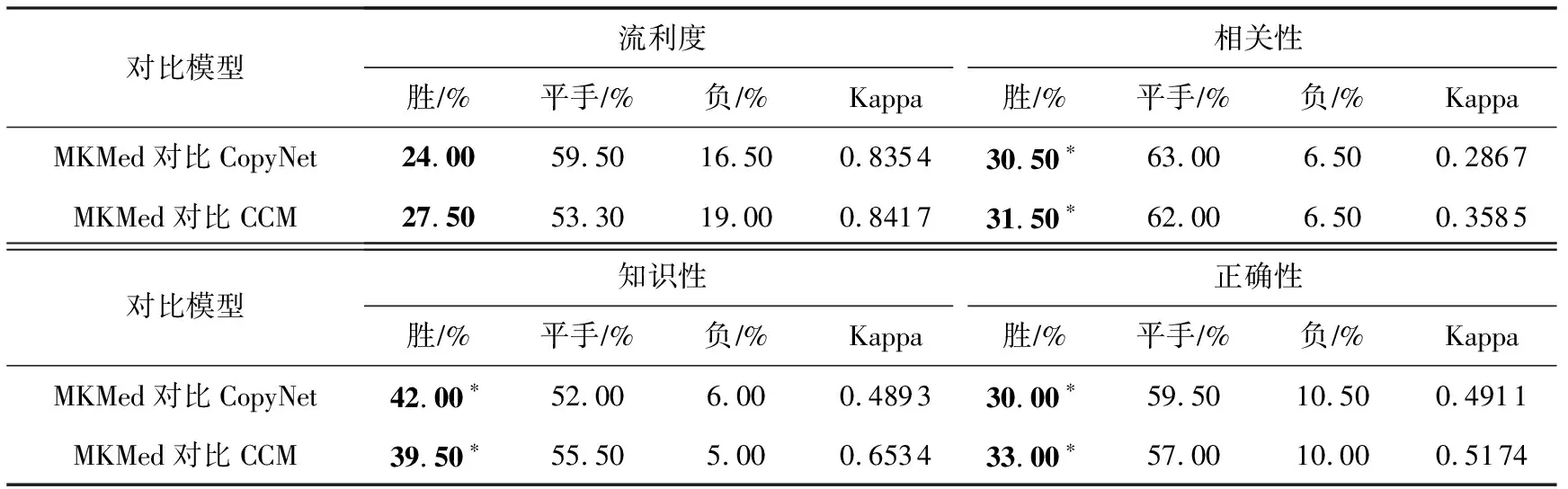
Table 2 Manual Evaluation Results
3.4.3 消融實驗
本節進行了消融實驗,來驗證模型中每個模塊的重要性和有效性.實驗結果如表3所示.考慮了3種設置:1)去掉復制網絡(即表3中的no-c),2)去掉知識實體預測部分(即表3中的no-p),3)去掉知識實體追蹤與預測模塊(即表3中的no-t).
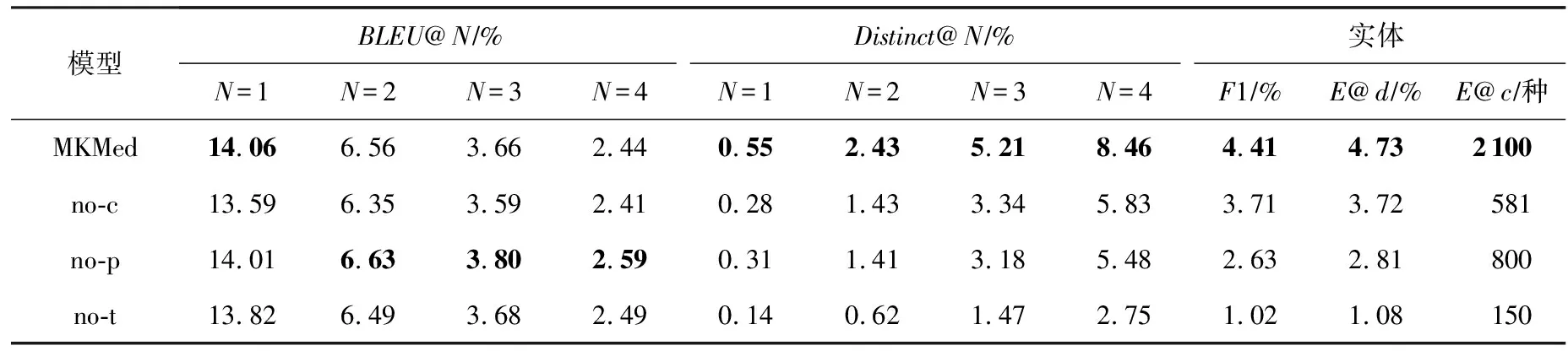
Table 3 Ablation Study Results

Fig. 3 Case study圖3 樣例研究
結果表明,所有模塊都有助于Distinct、F1、知識密度以及實體個數指標的提升,移除任意模塊都會使指標降低.我們認為,這是因為知識實體追蹤與預測模塊中的任意一個部分都會增加輸入到模型中的知識信息,從而增加了回答的多樣性;在此基礎上,通過篩選得到的輸入知識,使模型更有機會接觸到正確信息.增加復制機制,會增加相關性更大且更有可能是正確的知識復制到回答中的概率.但是我們還觀察到,移除了知識實體預測部分后BLEU指標最高,合理的解釋是基于記憶網絡的知識感知醫療對話生成模型沒有加入預測實體時會偏向生成一些安全詞匯,這樣恰好匹配到標準答案的概率更高,且傾向生成更短的回復,使BLEU的指標增大,但是這樣會帶來回復多樣性減少、正確性下降的問題,E@d,F1,Distinct指標值急劇減少與前述解釋吻合.
3.4.4 樣例展示
圖3展示的對話發生在骨科和創傷科,從圖3中可以看出,MKMed可以提供適當的藥物建議,生成回復中包含的實體“塞來昔布膠囊”是適用于緩解骨關節炎,治療急性疼痛和滑膜炎的藥物.但是CopyNet和CCM生成的回復缺乏有用的專業信息,因為他們沒有預測知識的能力,不能將外部專業知識融入回復生成.
從樣例展示中我們可以得出結論,MKMed模型生成的回復與真實回復仍有很大差距,但是已經有了預測知識這個質的進展,讓回復更加專業性、正確且有實際用處,實現一些傳統的生成模型所不能及的效果.
4 結論與展望
本文提出了一個基于知識和記憶網絡的醫療對話系統模型,模型開創性的結合了外部知識,通過知識實體追蹤和2階段的知識實體預測來改進醫療回復生成任務.在KaMed上的大量實驗證明,基于記憶網絡的知識感知醫療對話生成模型在BLEU,Distinct和實體指標上優于絕大部分基線模型,表明外部知識有助于更專業、正確、多樣且流暢的醫療回復的生成.
未來工作中計劃通過加入減小專業醫學知識與患者話語之間語義差距的方法,來使模型能夠更好地理解患者口語化表達的句子,希望生成的回復更個性化和有針對性,進一步提高模型生成回復的性能.
作者貢獻聲明:張曉宇負責代碼運行編寫、論文撰寫與校對;李冬冬負責模型構思、代碼編寫與運行、論文撰寫;任鵬杰、陳竹敏、馬軍負責論文撰寫指導;任昭春負責對模型構思、代碼編寫與運行、論文撰寫進行全程指導.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
光學精密工程(2016年6期)2016-11-07 09:07:19
全體育(2016年4期)2016-11-02 18:57:28
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
海外文摘(2016年4期)2016-04-15 22:28:55
科普童話·百科探秘(2015年6期)2015-10-13 07:21:18
