面向在線教育的同伴互評技術綜述
2022-12-18 08:11:34楊攀原
計算機應用 2022年12期
許 嘉,劉 靜,于 戈,呂 品*,楊攀原
(1.廣西大學 計算機與電子信息學院,南寧 530004;2.廣西多媒體通信與網絡技術重點實驗室(廣西大學),南寧 530004;3.東北大學 計算機科學與工程學院,沈陽 110169)
0 引言
近年來,隨著大數據、人工智能和互聯網技術的不斷發(fā)展,以中國大學MOOC(Massive Open Online Courses)[1]、學堂在線[2]、Coursera[3]和edX[4]等為代表的在線教育平臺讓人們能夠隨時隨地訪問優(yōu)質的教育資源,極大促進了在線教育的發(fā)展。在線教育的興起同時也給平臺上的任課教師帶來了嚴峻的教學挑戰(zhàn)。一門熱門的在線課程的選課學習者人數可高達上萬人,因此批改大規(guī)模學習者提交的主觀題作業(yè)(例如寫作題、程序設計題、簡答題等)是平臺教師所面臨的最大教學挑戰(zhàn),這是因為主觀題沒有唯一的標準答案,很難基于計算機技術實現自動批改[5]。考慮到主觀題比客觀題(例如選擇題、填空題、判斷題等)更能考察學習者的語言表達能力、思辨能力和創(chuàng)新能力[6],因此如何有效進行在線教育平臺上大規(guī)模主觀題作業(yè)的批改是當下需要研究和解決的重要問題。
同伴互評(peer grading/peer assessment/peer review),又被稱為“同伴評估”[7-8]“同行互評”[8-10]和“同儕互評”[11-12],是指學習者以教師制定的統(tǒng)一評估標準為指導對同一學習環(huán)境中其他同伴的學習成果進行評價,即學習者彼此之間評估與被評估的過程[11,13-14]。同伴互評是當下應對大規(guī)模主觀題作業(yè)批改問題的主流技術,已被成功運用到國內外多個代表性的在線教育平臺中,例如中國大學MOOC、學堂在線、Coursera 和edX。同伴互評的實施不但能夠減輕平臺任課教師的主觀題作業(yè)批改負擔,而且還給參與互評學習者帶來了諸多益處,具體表現在以下幾個方面。
1)讓學習者評判同伴的主觀題作業(yè),不但能夠幫助他們鞏固作業(yè)涉及的知識點,還能使他們學習到不同的解題思路,提高他們的課程參與度[13,15-17]。
2)同伴互評過程一般要求學習者參與批判性思考、監(jiān)控和反思等一系列認知活動[14],因此有助于提升學習者的學習動機,增強學習者的社會存在感,發(fā)展學習者的高階思維能力、元認知能力以及提升學習者的反思與批判性思考能力等[18-19]。
3)鑒于任課教師教學精力有限,學習者從同伴處獲得反饋往往比從教師處獲得反饋更及時[20]。
4)學習者在同伴互評中同時扮演了教師和學習者兩種角色,不但有利于促進他們進行評價與反思,還有利于培養(yǎng)他們的責任意識[21]。
鑒于此,本文總結了面向在線教育的同伴互評技術的研究進展,以期為正在從事或打算從事同伴互評研究的人們提供借鑒與參考。本文各個章節(jié)之間邏輯關系的文章結構如圖1 所示。
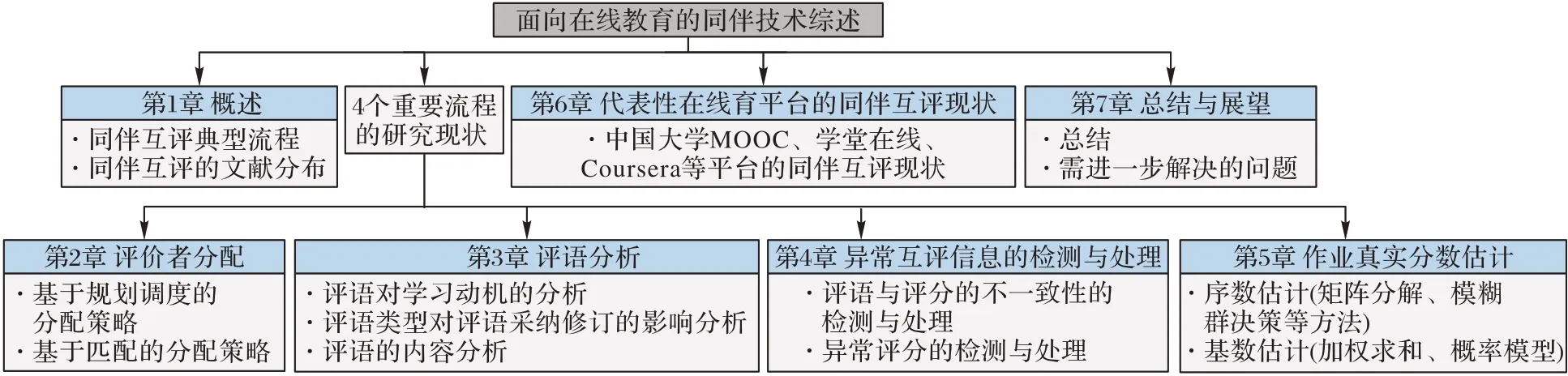
圖1 文章結構Fig.1 Article structure
1 概述
1.1 同伴互評典型流程
基于對同伴互評領域大量研究工作的調研,同伴互評的實施流程如圖2 所示,包括10 項活動。

圖2 同伴互評的流程Fig.2 Process of peer grading
1)教師布置作業(yè)并設置互評規(guī)則與評價量規(guī)。教師通過教學平臺或系統(tǒng)布置主觀題作業(yè)并設置供學習者互評時參考的互評規(guī)則和評價量規(guī)。
2)學習者提交作業(yè)。學習者需在教師設定的時間內提交主觀題作業(yè)的答案。
3)系統(tǒng)分配評價者。教學平臺或系統(tǒng)按照一定的分配算法為學習者提交的主觀題作業(yè)分配教師預設數目的評價者。隨機分配是最常用的分配算法。系統(tǒng)為每份作業(yè)分派的評價者數目通常為不小于3 的奇數[22]。
4)學習者完成互評訓練(可選流程)。在正式開始互評作業(yè)之前,學習者需要按照教師在活動1)中預設的評價量規(guī)對不同質量等級的作業(yè)樣例進行評價。教學平臺或系統(tǒng)根據學習者評分與教師評分之間的吻合程度判定學習者是否具有評價資格,只有通過互評訓練的評價者才能參與接下來的互評作業(yè)活動。
5)學習者(評價者)互評作業(yè)。學習者按照教師發(fā)布的評價量規(guī)評閱系統(tǒng)分配給他的主觀題作業(yè)。在評閱過程中,學習者需要給出同伴主觀題作業(yè)的評分反饋和評語反饋。根據形式的不同,評分可分為基數(cardinal)評分和序數(ordinal)評分,前者為單個作業(yè)的數值型分數,后者則是多個作業(yè)間基于質量的高低排序。兩種評分反饋各具優(yōu)勢:一方面基數評分比序數評分更能準確地量化作業(yè)間的質量差距[23-24];另一方面序數評分比基數評分對非專家的評價者更為友好,因為非專家的評價者更容易對作業(yè)進行相對排序而不是直接給出每份作業(yè)的分數[25-26]。
6)學習者(被評價者)互評反饋(可選流程)。在學習者互評作業(yè)活動結束后,一些教學平臺或系統(tǒng)設置了作業(yè)申訴期。在作業(yè)申訴期內,被評價者可針對其所收到的同伴針對其作業(yè)給出的評價分數和評語進行反饋,若被評價者對同伴給出的評價結果有異議,可以在平臺或系統(tǒng)中提交異議內容并申請由教師對其主觀題作業(yè)進行評價。
7)系統(tǒng)分析評語(可選流程)。評價者給出的評語中包含評價者對被評價作業(yè)的總結、分析和建議等信息,是對其所給評分的進一步解釋。因此,分析評語能夠探索評語類型與學習者采納之間的關系,挖掘評語中隱含的學習者學習情緒,檢測評語中包含的問題性或建議性信息等,這對主觀題作業(yè)評估具有重要指導意義。
8)檢測與處理異常互評信息(可選流程)。在互評過程中,存在由于評價者的惡意或不當行為導致的異常互評信息,包括異常評分或異常評語,因此需要及時對這類異常互評信息進行檢測與處理,以保證同伴互評的質量。
9)估計作業(yè)真實分數。即基于收集到的評分數據和評語數據估計每個學習者提交的主觀題作業(yè)的真實分數。取多個評價分數的平均數或中位數是常用的估計一份作業(yè)真實分數的方法。除此之外,其他估計方式還包括貝葉斯概率建模、因子分解以及加權求和等。
10)教師微調作業(yè)分數。獲得對作業(yè)真實分數的估計值之后,教師可以著重關注那些多個同伴給出的評價分數中偏差較大的作業(yè)、學習者申請申述的作業(yè)或者已檢測出存在反饋信息異常的作業(yè),通過人工微調的方式為這些作業(yè)確定最終分數。
由于評價者分配、評語分析、異常互評信息的檢測與處理以及作業(yè)真實分數估計4 個流程所涉及的研究成果豐富,本文將在第2~5 章分別進行分析總結;而其他流程的研究工作側重于互評模式的研究,比如關注評價細則設置、互評前是否需要互評訓練、學習者是否是匿名互評等,本文僅在此簡略闡述。對于評分細則的設置,研究發(fā)現良好的評價量規(guī)不僅可以為學習者完成互評任務提供針對性的指導,還有助于學習者更好地理解學習目標,從而降低評價的主觀隨意性[27-29]。對于互評訓練,研究人員指出它不僅幫助學習者熟悉評估流程和評價量規(guī),還有助于提高評分準確性的外在介入因素[30-32]。Li 等[33]還發(fā)現采用游戲式的互評訓練比傳統(tǒng)的互評訓練更能提高學習者參與同伴互評活動的內在動機。另外,評價者與被評價者雙方匿名能夠減少學習者評價作業(yè)的壓力和其評價不被對方認可的恐懼感,增加互評雙方的舒適感和提升雙方參與互評的積極性[34-38],同時使評價者更愿意針對作業(yè)提出批評性反饋[35],從而進一步保證互評活動結果的客觀性和有效性。
1.2 同伴互評的文獻分布
本文對2010 年以來同伴互評領域的研究成果進行了統(tǒng)計分析。在Elsevier ScienceDirect、ACM Digital Library、IEEE Xplore Digital Library、Springer Link Online Library、Wiley Online Library、中國知網等文獻數據庫中進行搜索,統(tǒng)計公開發(fā)表在計算機領域或計算機教育領域的國內外相關會議、期刊中的高水平文獻。其中,英文檢索關鍵字為“peer assessment”“peer review”“peer grading”,中文關鍵字為“同伴互評”“同行互評”“同儕互評”和“同伴評估”。涉及的會議期刊主要包括SIGCSE、WWW、L@S、SIGKDD、Computers &Education 等。經過仔細閱讀篩選,最終確定了54 篇研究文獻(截至2021 年5 月)。
圖3(a)統(tǒng)計了面向在線教育的同伴互評領域從2010 年1 月至2021 年5 月每年的文獻發(fā)表數量。由圖3(a)可知,隨著Coursera[3]、edX[4]等慕課平臺的成立,自2013 年來面向在線教育的同伴互評領域的文獻數目呈穩(wěn)步上升的趨勢。將相關文獻按圖2 所示的同伴互評流程中的活動進行分類并統(tǒng)計每個活動對應的文獻數量,詳見圖3(b)所示。圖3(b)顯示作業(yè)真實分數估計的相關工作占比最多,為35%;評語分析、異常互評信息檢測與處理和評價者分配的研究工作分別占17%、15%和11%,還有22%的文獻關注于探索互評訓練或在互評作業(yè)時是否需要匿名等問題。后文將對重要流程中的主要研究成果進行闡釋和分析。
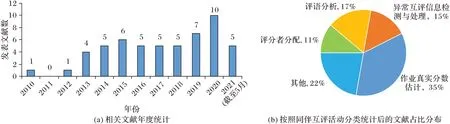
圖3 面向在線教育的同伴互評相關文獻統(tǒng)計結果Fig.3 Statistics of peer grading related literatures for online education
2 評價者分配
在同伴互評流程中,分配評價者是極其重要的環(huán)節(jié)。現有的教學平臺或系統(tǒng)通常采用隨機分配的方式為待評估的作業(yè)答案分配評價者。雖然隨機分配能一定程度上保證分配的公平,但是考慮到不同學習者的知識水平、評估能力、評估態(tài)度等存在差異,隨機分配并不能完全保證每份待評作業(yè)都能得到合理的評判以及互評結果的準確性和有效性。鑒于此,研究學者對評價者分配進行了深入探究,相關研究可以分為基于規(guī)劃調度[39-41]和基于匹配兩種分配策略[42-44]。
基于規(guī)劃調度的分配策略依據評價者的知識能力水平進行評價者分配,以減少不可靠評價者給同伴互評帶來的影響。Han 等[39]考慮不同學習者間知識水平的差異性,基于并行系統(tǒng)中常用的最長處理時間(Longest Processing Time,LPT)算法,提出了一種改進的最長處理時間(Modified Longest Processing Time,MLPT)方法,將不同知識水平的學習者平均分配到各個評分小組中,使各組間平均知識水平差異最小,從而提高了評價者分配的有效性。Capuano 等[40]基于圖挖掘技術平衡知識水平能力高的優(yōu)秀評價者的分配,以避免不可靠評價者帶來的影響。Ohashi 等[41]則提出了一種新穎的自適應評價者分配算法及其擴展算法,這兩種算法都能保證只有在評價者需要時才分配評價任務給評價者,而不是強制給評價者分配評價任務;此外,擴展算法考慮了評價者評價能力,避免了只為同一個作業(yè)分配評價能力高(或低)的評價者。
基于匹配的分配策略是同時基于評價者特性以及互評雙方的作業(yè)相似度來為每份作業(yè)匹配合適的評價者。文獻[42]中整合了評價者的知識背景、互評經驗(互評次數與訓練次數)和作業(yè)相似度等信息實現作業(yè)評價者的推薦。文獻[43]中則在綜合考慮評價者的評閱意愿、評閱能力和評閱雙方作業(yè)相似度等多種因素的基礎上,建立了評價者的推薦模型;同時利用二部圖匹配理論求解評價者間的匹配問題,設計了最優(yōu)均衡匹配算法。此外,Anaya 等[44]考慮了學習者受歡迎程度、主動性和親密性等社會因素對其在同伴互評參與度的影響,提出了一種新的分配方法。
3 評語分析
同伴互評中評價者給出的作業(yè)評語蘊含著評價者對作業(yè)答案的總結、分析和建議等豐富信息,能夠體現學習者的認知體系;因此,評語分析對于主觀題作業(yè)評估有重要指導意義。目前學者對評語分析的工作主要涉及探索評語對學習者的學習動機的影響[45-48]、分析評語類型對學習者理解評語與實施修訂的影響[49-51]和自動檢測評語中是否包含問題性或建議性信息[52-53]。
由于計算機無法直接對文本評語進行計算,目前將評語轉換為數值型數據的處理方式主要有兩種:內容分析編碼和自然語言處理技術。內容分析編碼依據評語的內容從不同維度對其進行分類后映射數值編碼,不同文獻采用不同維度構建評語內容分析框架,并且每個維度下的類型也略有差異。例如文獻[46]中主要分為情感、認知和元認知維度,情感維度細分為支持贊揚和反對批評類型,認知維度則分為直接修改、個人觀點和指導建議類型,元認知維度則分為評估和反思類型。自然語言技術則有One Hot、TF-IDF(Term Frequency-Inverse Document Frequency)和Word2vec 等方法。除此之外,評語長度、是否含有表情符號也是評語分析中常考慮的因素。
Lu 等[45]對評語從認知和情感維度進行編碼,研究了評語對評價者和被評價者的影響;他們發(fā)現評價者提供建議性評語有助于促進自身對知識的認知,提供積極情感評語則有助于提高被評價者的學習動機。Cheng 等[46]探索了三類評語(即情感、認知與元認知)對寫作學習的作用;他們研究發(fā)現認知類評語(如直接糾正)比情感類評語(如表揚)和元認知類評語(如評價知識技能)更利于寫作學習。然而隨著同伴互評活動的進行,學習者更傾向于提供情感類評語,而不是提供認知類評語。Zong 等[47]則發(fā)現評語長度與互評質量顯著相關,包含觀點的長評論不僅能夠幫助同伴,還能幫助評價者在提供評論過程中強化對內容的理解。另外,Moffitt等[48]發(fā)現在評語中使用表情符號能夠增強互評樂趣,為學習者帶來良好的情感體驗,進一步提高學習者的參與積極性。
文獻[49-51]采用對評語內容分析編碼的方法探索了不同評語內容對學習者理解及采納評語的影響;其次分析了在該影響下學習者根據評語進行作業(yè)修訂的情況。具體而言,文獻[49]中將評語內容分為表揚、問題解釋、解決方案、本地化(系統(tǒng)是否支持在待批改處進行評語注釋)和關注點類型進行編碼,然后利用邏輯回歸模型分析特征的重要性,其中,關注點包括低階關注點(例如語法或拼寫)、高階關注點(例如過渡或論證)以及實質關注點(即內容準確性);文獻[49]發(fā)現只有表揚和本地化這兩個特征對學習者基于評語實施作業(yè)修訂有效,且學習者一般不會修訂評語中指出的高階關注點方面的內容。文獻[50]中分析發(fā)現直接明確的評語比含蓄性的評語更容易讓被評者接受,并且評語中包含明確性變更和重復被指出(多個評價者對同一個作業(yè)相同或相似的評語)等特征更有助于學習者基于評語實施作業(yè)修訂。文獻[51]則認為評語特征包括四個認知特征(即問題識別、問題解釋、解決方案、建議性意見)和兩個情感特征(減輕表揚、模糊限制語),其中,減輕表揚(mitigating praise)是指通過將正面反饋添加到負面反饋中來弱化批評;模糊限制語則是指評價者在評語中添加了“可能”“或許”等詞對評語進行了模糊限制。作者基于邏輯回歸分析發(fā)現:學習者對評語的理解和認同能夠預測學習者是否根據評語實施修訂;具備問題詳細解釋、解決方案和模糊限制語等特征的評語更有助于學習者基于評語實施作業(yè)修訂。
此外,Xiao 等[52]采用自然語言處理技術將文本評語進行編碼,對評語中建議性表述的自動檢測問題開展了研究,構建了邏輯回歸、隨機森林、樸素貝葉斯、支持向量機等分類器并取得了良好的分類效果,能夠自動判別出包含建議性表述的評語。同時,還利用多種機器學習模型對評語中是否指出了作業(yè)存在的問題進行了深入研究[53]。
總之,通過對互評評語進行分析,能夠更好地輔助教師有針對性地調整教學方案和優(yōu)化互評效果,從而有助于學習者提高學習積極性、提升情緒體驗、改善學習成效和改進認知方式,最終達到以評促教和以評促學的雙重目的。
4 異常互評信息檢測與處理
同伴互評過程中由于評價者的惡意或不當行為所導致的一些異常的互評信息直接影響互評結果的準確性和有效性。文獻[54]中提出了利用機器學習方法檢測評語與互評分數之間的不一致性,保證評語及評分數據的有效性。這種方式使教師不必逐一監(jiān)控和檢查每一份作業(yè)的互評信息,從而讓教師只需聚焦處理被檢測出的評語與分數不一致的作業(yè),極大減輕了教師的作業(yè)評判負擔。具體而言,他們嘗試使用多種文本表示方式對評語進行編碼表征,并利用k近鄰、支持向量機、決策樹、隨機森林、長短期記憶(Long Short-Term Memory,LSTM)網絡等算法構建回歸模型預估與評語相匹配的分數;之后比較基于作業(yè)評語預估的分數與作業(yè)真實互評分數之間的差異,差異越大則說明評語與互評分數越不一致。
另外,一些研究者從其他角度檢測和處理異常互評分數。例如,Rico-Juan 等[55]利用基于箱型圖的統(tǒng)計方法分析發(fā)現可能與作業(yè)真實分數存在偏差的異常互評分數,此時教師只需對被視為異常互評分數的作業(yè)進行判定即可。趙鳴銘等[56]提出了利用哨兵機制的評價者信譽度生成算法過濾異常的惡意評分。該方法以少量教師預評分的作業(yè)作為哨兵,并利用評價者信譽度算法基于評價者對哨兵的評分情況量化評價者的信譽值,再利用閾值挑選出高信譽度評價者的評分和評語估計作業(yè)的真實分數,從而實現對惡意的高評分或低評分的隔離。Han 等[25]提出了一種人機混合評估框架檢測和處理異常的互評信息。該框架首先以學習者提交的作業(yè)文本為輸入,基于卷積神經網絡的自動評分器預測作業(yè)得分;其次,比較評分器所得分值與互評分數,從而過濾那些兩種分值間存在較大差異的異常互評分數;隨后以合理的互評分數為輸入并利用貝葉斯同伴評分模型[57-58]推斷作業(yè)的最終真實分數,同時提示教師評價那些互評分數異常的作業(yè)。此外,Xiong 等[59]基于評價者、作業(yè)和評閱這3 個層次的特征檢測評價者在評分過程中是否存在打分過于嚴厲或打分過于寬容的問題;通過實驗發(fā)現不同層次的特征對發(fā)現互評分數的過于嚴厲或過于寬容的情況具有不同程度的作用,為教學平臺或系統(tǒng)自動識別同伴互評中不準確的評分以及激勵和干預不準確評價者提供了思路。
以上介紹的關于檢測和處理異常反饋信息的方法在教學實踐中取得了良好效果,然而這些方法均需要設定閾值識別異常信息;因而,如何根據應用的上下文設計閾值進而自適應地調整策略是需要進一步研究的問題。除此之外,James 等[60]提出了用于評估評價者可靠性的多個指標,并且通過在模擬數據集上的實驗驗證了估計評價者可靠性指標的有效性。Lin 等[61]提取了有助于評估評價者可信度的相關特征,并基于這些特征構建C5.0 決策樹分類器自動判別同伴互評記錄是否可信。Stelmakh 等[62]設計了一個測試規(guī)則用于檢測評價者在序數同伴互評中是否采取了有利于提高自己作品排序的戰(zhàn)略行為。
5 作業(yè)真實分數估計
同伴互評的核心問題是依據評價者反饋的評分和評語信息估計每份主觀題作業(yè)的分數。目前在同伴互評領域已有許多估計主觀題作業(yè)真實分數的研究工作,根據評價者反饋的評分內容的不同,可將它們分為序數(Ordinal)估計方法和基數(Cardinal)估計方法。
5.1 序數估計
序數估計方法要求每名評價者對分配給其的作業(yè)答案給出作業(yè)質量高低的排名,然后基于所有評價者給出的作業(yè)間的偏序排名信息推斷所有作業(yè)的最終排名。現有的序數估計方法主要利用矩陣分解[63-64]、模糊決策[65-66]、貝葉斯[67]、基于配對比較[23,68-69]等方法估計主觀題作業(yè)的質量。
Díez 等[63]基于矩陣分解方法學習了一個效用函數,這個函數估計所有作業(yè)的共識排序,并且這個排序很容易轉換為每個作業(yè)的絕對分數。Luaces 等[64]則基于矩陣分解方法在基數估計和序數估計之間尋求一種折中的方法。該方法在評估過程中考慮了作業(yè)或學習者的特征,并且能夠以較快速度處理大量作業(yè)互評數據。
Capuano 等[65]提出了一種基于模糊群決策原理的有序同儕評估模型FOPA(Fuzzy Ordinal Peer Assessment),來降低不可靠性評價者帶來的影響。在該模型中,評價者對作業(yè)的排序被轉換成模糊偏好關系,并通過有序加權幾何平均算子對其進行聚合;然后使用聚合關系生成作業(yè)之間的全局排名,并估計其絕對分數。在后續(xù)研究中,他們引入了多重評價準則對FOPA 模型進行擴展以提高模型可靠性[66]。在擴展模型中,評價者不僅參與根據定義的評價準則對同伴提交的作業(yè)答案進行排名,而且還參與對標準本身的重要性進行排名。
Waters 等[67]提出了基于貝葉斯方法的BayesRank 模型解決以往同伴互評序數估計工作未對評價者可靠性建模的問題,并提出了一種新的馬爾可夫鏈蒙特卡羅方法簡化推斷ByaseRank 中的變量。該方法不僅能夠推斷學習者的作業(yè)質量,還能顯式推斷每個評價者評分的可靠性。
基于配對比較方法指評價者對需評判的作業(yè)進行兩兩比較來估計全局排名和評價者的可靠性。Shah 等[23]基于經典配對比較模型BTL(Bradley-Terry-Luce)[70-71]引入同伴評價者評估能力得到擴展的序數估計模型RBTL(Refereed Bradley-Terry-Luce),從有序的配對比較中推斷評價者潛在的作業(yè)評估能力和其完成的作業(yè)的質量。Raman 等[68]引入評價者的可靠性擴展了一些不同概率分布的經典排名聚合模型,包括MAL(MALlows)[72]、BT(Bradley-Terry)[70]、THUR(THURstone)[73]和PL(Plackett-Luce)[74],并使用迭代交叉最大似然估計策略估計作業(yè)真實分數和評價者的評分可靠性。Lin 等[69]則提出了一種新穎的基于配對比較的排名聚合方法,該方法利用譜算法(Spectral algorithm)來估計每份作業(yè)的真實分數以及每位評價者的評分可靠性。
5.2 基數估計
與序數估計方法不同,基數估計方法要求每名評價者對被分配的每份主觀題作業(yè)給出一個數值型評價分數,然后利用不同評價者給出的評價分數估計作業(yè)的真實分數。目前主流的基數估計方法有兩種:基于加權求和的估計方法和基于概率圖模型的估計方法。
基于加權求和的估計方法的思想是根據評價者的準確性和信任度的差異賦予不同的權重,然后加權求和評價者對同一主觀題作業(yè)答案的評分,估計該作業(yè)答案的真實分數;并且,隨著同伴互評的開展,可以根據評價者在新作業(yè)的評判表現迭代更新其準確性和信任度的權重信息。De Alfaro等[75]提出了Voncouver 算法,該算法通過比較不同評判者對同一份作業(yè)答案的評分衡量每個評價者的評分準確性,并賦予準確性更高的評價者評分更高的權重,然后加權求和得到該作業(yè)答案的一致分數。對比直接將互評評分求平均,該方法可取得更高的準確度。Walsh[76]提出了另一種迭代加權算法PeerRank,該算法的設計受到Google 的網頁排序PageRank算法[77]的啟發(fā)。他們假設一個評價者的作業(yè)分數反映了其評價能力,基于評價者的作業(yè)分數對每一份提交作業(yè)的多個同伴評價者的評判分數進行加權求和。García-Martínez 等[78]則基于評價者的學習參與度(例如是否觀看學習視頻、是否完成相關章節(jié)測驗)提升估計作業(yè)真實分數的準確性。Darvishi 等[79]提出了一種基于圖的信任傳播方法,該方法將評價者(包括學生和教師)和作業(yè)作為圖中的節(jié)點,評價者的評分可靠性設置為評價者節(jié)點的權重、作業(yè)的質量設置為作業(yè)節(jié)點的權重、評價關系作為連接兩種不同類型節(jié)點之間的邊;其后提出了基于圖結構的作業(yè)分數更新策略以及評價者可靠性的傳播策略,從而可以推斷作業(yè)真實分數以及評價者的評分可靠性。此外,Li 等[80]基于評價者在完成作業(yè)過程中的行為特性(例如答題時間)和評價者給出的評語信息對評價者的評分可靠性進行建模,然后以量化得到的評分者的評分可靠性為權值對他們給出的評分進行加權求和,從而得到對目標作業(yè)真實分數的估計值。Yuan 等[81]則提出了一種結合評語文本信息的半自動同伴評分方法SABTXT(Semi-Automated peer Bias grading approach with TeXTual reviews)。該方法通過兩種機制提升了估計主觀題真實分數的準確性,首先基于教師與評價者對以往主觀題作業(yè)的評分差異對評價者的偏見進行建模和糾正;其次基于評語文本內容對評價者的評價仔細度進行建模。評價者的評價仔細度越高,其給出的評分越值得信賴,則給該評價者所打的評分賦予更高的權重以期提升對主觀題作業(yè)真實分數估計的準確性。
基于概率圖模型的估計方法通過構建概率圖模型來估計主觀題作業(yè)的真實分數。這類方法將待估作業(yè)的真實分數(Su隱含變量)、互評分數(觀測變量)、評價者的可靠性及偏見(τv,bv隱含變量)都建模為服從一定概率分布(設N 表示正態(tài)分布,Γ 表示伽馬分布)的隨機變量,并且變量之間存在一定的關聯關系,然后基于可觀測評價者的互評分數推斷隱含隨機變量的值。Piech 等[57]首次提出了3 個概率圖模型(PG1、PG2和PG3)估計作業(yè)真實分數,其中:PG1建模時考慮了評價者當前的可靠性和偏見這兩個因素;PG2在PG1的基礎上考慮了評價者的歷史偏見;PG3則在PG1的基礎上將評價者當前可靠性設定為依賴于評價者當前作業(yè)真實分數的線性函數的隨機變量,詳見圖4(a)所示的PG3模型的數學定義的第2 行。Mi 等[58]也認為評價者的可靠性與其自身真實分數相關,但是認為PG3中兩者之間的線性關系過于嚴格,因此弱化了此線性關系。他們將評價者的可靠性建模為滿足形狀參數為其真實分數的伽馬分布或均值為其真實分數的高斯分布,分別得到了PG4模型(圖4(b))和PG5模型(圖4(c))。考慮到一名同伴評價者的評分偏見會受到其朋友的評分偏見的影響[82],Chan 等[83]利用學堂在線平臺上收集到的學習者間的社交關系信息提高對評價者偏見建模的準確性,擴展了PG1、PG4和PG5這三個概率圖模型。然而上述概率圖模型均認為評價者給不同主觀題作業(yè)的評分之間是相互獨立的,存在局限性。因此,Wang 等[84]引入評價者的相對分數信息(為觀測變量,即同一個評價者對不同作業(yè)評分之間的差值),基于PG4和PG5模型分別構建了PG6模型(圖4(d))和PG7模型(圖4(e))。這兩個概率圖模型有效解決了因數據稀疏性帶來的參數估計問題,提高了對主觀題真實分數的估計準確性。在此基礎上,Xu 等[85]還考慮了評價者對主觀題作業(yè)中的掌握程度對評價者可靠性的影響。他們利用評價者的歷史答題信息,基于DINA(Deterministic Inputs,Noisy “And”gate model)認知診斷模型[86]計算得到評價者對主觀題作業(yè)的掌握程度信息,基于該掌握程度信息優(yōu)化建模PG6和PG7模型中的可靠性,分別提出了CD-PG1(Cognitive Diagnosis-Peer Grading)和CD-PG2模型,進一步提升了估計作業(yè)真實分數的準確性。表1 中對現有的概率圖模型進行了對比分析。表2 則對現有主觀題作業(yè)真實分數的估計方法進行了比較,√表示模型在設計時考慮了該因素。

表1 不同概率圖模型的比較Tab.1 Comparison of different probability graph models

表2 主觀題作業(yè)真實分數估計方法或策略比較Tab.2 Comparison of methods or strategies of true grade estimation for subjective assignments

圖4 典型的概率圖模型Fig.4 Typical probability graph models
6 代表性在線教育平臺的同伴互評現狀
近年來,得益于大數據、云計算、人工智能等技術的發(fā)展,新興在線教育平臺的功能更加全面和智能化。目前,雖然大多數平臺都已支持基于同伴互評的主觀題作業(yè)批改模式,但它們在同伴互評的流程與功能方面略有差異。表3 詳細對比分析了當下國內外具有代表性的在線教育平臺或系統(tǒng),包括中國大學慕課iCourse[1]、學堂在線XuetangX[2]、好大學在線 CNMOOC[87]、Coursera[3]、edX[4]、Moodle[88]、CrowdGrader[89]和Peerceptiv[90]等。因上述所有教學平臺或系統(tǒng)均支持教師布置作業(yè)、學習者提交作業(yè)、學習者互評作業(yè)、教師調整互評分數等功能,本章主要比較不同教學平臺或系統(tǒng)的評分者分配、互評活動設置和作業(yè)真實分數估計這幾個維度的差異性。值得一提的是,在國際上流行的三大MOOC平臺(即Coursera、edX 和Udacity[91])中,Coursera 是最早引入同伴互評功能的MOOC 平臺;而截至目前,Udacity 仍未引入同伴互評功能。

表3 代表性在線教育平臺或系統(tǒng)的同伴互評模塊的對比Tab.3 Comparison of peer grading modules of representative online education platforms or systems
7 結語
同伴互評作為一種解決大規(guī)模主觀題作業(yè)評價問題的重要方式具有重要的實用價值與研究意義,受到來自計算機界、教育界、心理學界等不同學科領域研究者的共同關注。本文對近10 年來面向在線教育的同伴互評技術進行了深入調研并總結了該領域的研究進展,希望能夠為正在從事或打算從事該領域研究的人員提供借鑒與參考。目前,面向在線教育的同伴互評領域已經取得了一定的進展,但仍存在以下需要進一步解決的問題。
1)缺乏高質量的公開數據集。
由于可能涉及個人隱私信息,目前面向在線教育的同伴互評領域只有少量的公開數據集[92-94]。Vozniuk 等[92]公開的同伴互評數據集包含60 名碩士研究生參與同伴互評后得到的評分數據以及4 名教師對學習者作業(yè)的評分數據。Tenório 等[93]組織30 名高中生參與游戲化的同伴互評活動并公開了其收集的同伴互評數據集。Ashenafi[94]公開的同伴互評數據集則涉及五門計算機課程,包含800 多名學習者參與互評活動后所收集到的與5 000 多份作業(yè)答案相關的互評信息,然而該數據集不包含教師針對作業(yè)給出的評分信息。雖然以上公開數據集為同伴互評技術的研究提供了一定的支持保障,但是這些公開數據集存在數據量較少、數據有缺失、或采集的信息不夠豐富等問題。因此,為推動面向在線教育的同伴互評技術的進一步發(fā)展,急需相關學校、研究機構提供公開的、高質量的同伴互評數據集。
2)缺乏評價者的激勵機制。
在多次同伴互評活動實施之后評價者可能會進入互評疲憊期,即不再愿意付出過多努力提供高質量的個人觀點、指導建議、能力評估等認知型的評語[12],而認知型評語對于被評價者往往更有幫助。為解決上述問題,研究人員在設計同伴互評技術時應該結合恰當的外在或內在激勵機制[95],從而激勵評價者以較高的熱情繼續(xù)參與到同伴互評的活動中來。
3)缺乏對學習者在同伴互評過程中認知水平的追蹤。
在同伴互評過程中,學習者認知能力可能在同伴評估之前、期間或之后發(fā)生變化,而追蹤學習者在不同互評階段的認知狀態(tài)變化可以有效評估其學習成效以及預測其未來學習表現,這無疑有助于教師確定需特殊監(jiān)督的學習者和劃分出合理的學習小組[94,96-97];然而,目前鮮有對學習者在同伴互評過程中認知能力變化進行跟蹤建模的研究工作。因此可以借鑒流行的知識追蹤模型,例如貝葉斯知識追蹤(Bayesian Knowledgeable Tracing,BKT)模型[98],深度知識追蹤(Deep Knowledge Tracing,DKT)模型[99]和動態(tài)鍵值記憶網絡(Dynamic Key-Value Memory Network,DKVMN)[100]等對同伴互評過程中學習者認知水平的追蹤。
4)同伴互評活動的智能化程度還需進一步加強。
同伴互評領域目前已在評價者分配、評語分析、異常互評信息檢測處理和作業(yè)真實分數估計這4 個方面取得了較大研究進展,所發(fā)表的研究工作通過在計算機上構建和運行智能化模型簡化了同伴互評的實施過程,優(yōu)化了同伴互評的實施質量。然而,為了使同伴互評能在更多場景下得到推廣和應用,其實施過程的智能化程度還需進一步加強。例如,可以針對“布置作業(yè)并設置互評規(guī)則與評價量規(guī)”流程研究互評規(guī)則與評價量規(guī)的自動生成方法,以期進一步降低同伴互評活動中教師的參與工作量,從而讓教師將更多精力用于教學內容的設計和改進。又如,可以針對“互評作業(yè)”流程研究如何為學生提供有效的評價建議和評價模板,以期提升學生的同伴互評質量和收獲感。
5)同伴互評平臺和系統(tǒng)還需進一步優(yōu)化。
目前同伴互評活動的開展主要依托于在線教育平臺或系統(tǒng),因此如何進一步優(yōu)化在線教育平臺或系統(tǒng)的同伴互評功能非常重要。一方面,平臺和系統(tǒng)可以進一步提高同伴互評活動在設置以及數據收集和統(tǒng)計方面的易用性,例如可嘗試引入簡短、可定制且能夠直接勾選的評語詞條,提高評價者對作業(yè)的評判效率和用語規(guī)范性;另一方面,平臺和系統(tǒng)需要提供比中位數、均值和加權求和方法精度更高的基于概率圖模型[57-58,83-85]的作業(yè)真實分數估計功能,從而提高基于同伴評分估計作業(yè)真實分數的準確性。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
四川文學(2020年11期)2020-02-06 01:54:52
故事大王(2016年7期)2016-09-22 17:30:08
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
散文百家(2014年11期)2014-08-21 07:16:36
兒童故事畫報(2013年3期)2013-06-24 05:40:30
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
體育師友(2012年4期)2012-03-20 15:30:10
小哥白尼·軍事科學畫報(2009年9期)2009-09-14 03:18:56
