基于Hadoop框架與用戶行為特征感知的智能圖書推薦系統設計
2022-12-23 12:03:02花維
電子設計工程 2022年24期
花維
(西安外事學院,陜西西安 710077)
互聯網技術的普及與發展改變了人們的生活、生產方式,互聯網技術已經滲透進了生活的各種場景,如購物、娛樂、社交通信等,人們充分享受著互聯網帶來的便利。但另一方面,互聯網上信息的極度豐富也使人們面臨著信息過剩的問題,大量沒有價值的不良信息占據著人們寶貴的接受信息時間。搜索引擎的出現使得人們可以根據其意愿進行信息篩選,限制用戶獲取信息的范圍,較大程度地緩解無用信息的干擾。近年來,推薦系統的出現更是使得互聯網可以根據用戶的興趣進行信息推送,大幅度提升了用戶獲取信息的效率與用戶體驗。推薦系統的本質也是一個搜索系統,在人們享受便利的同時也在互聯網上留下了自身的各種“活動軌跡”。通過這些軌跡提取用戶標簽,結合用戶信息構建用戶畫像。然后,將不同用戶的不同畫像輸入到網頁的搜索框,即可獲得該用戶感興趣的信息,達到個性化匹配的目的[1-4]。
為了提升讀者獲取其感興趣圖書的效率并提升閱讀體驗,該文對圖書的推薦系統進行了研究。通過引入系統工程理論指導設計,梳理圖書推薦的主要流程,確定系統的軟件架構;引入Hadoop 大數據處理框架,基于MapReduce 編程模式,實現了推薦算法的并行化處理,提升推薦系統的計算效率。
1 系統設計
1.1 系統需求分析與結構設計
圖書在線推薦系統的研究與設計是一項龐大的軟件工程任務,為達到該目的,需要有科學的理論指導。在軟件工程理論中,系統的需求分析是軟件設計的第一步。通過需求分析可以明確系統設計的目標,同時在這一過程中將目標進行逐級拆解,轉換為計算機容易實現的功能模塊,逐步轉化為最終的軟件系統[5-9]。
圖書在線推薦系統可以實現高效、精準的書籍推薦。精準的推薦對于互聯網企業增加用戶粘性,提升電子商務網站的轉化率具有重要意義。高效性的特點,要求推薦系統必須具有較強的實時性,具體體現在當用戶特征、圖書信息等要素發生變化時,推薦的內容也可以及時、快速地更新。精準性要求推薦的書籍對于用戶有較好的接受度,推薦書籍應當具有一定的點擊率。基于以上的目的及相關分析,設計系統的相關功能模塊,如圖1 所示。
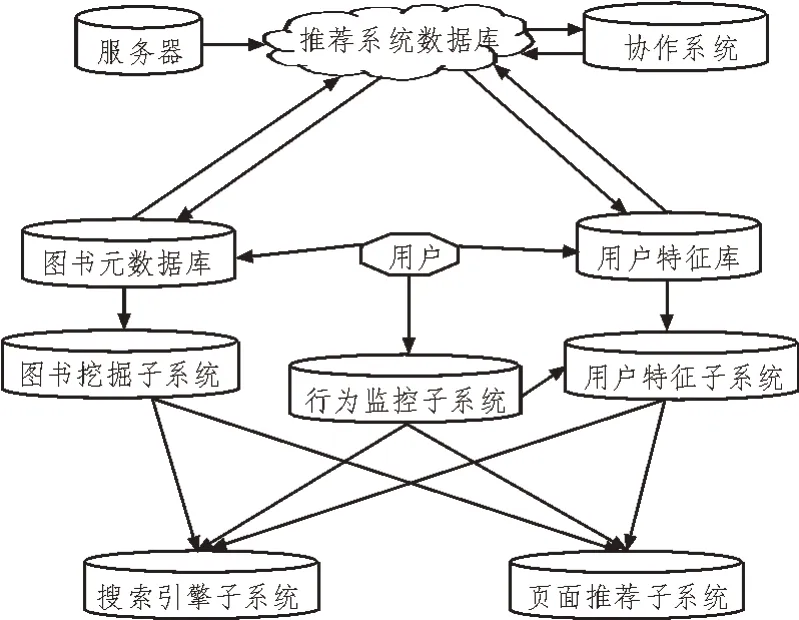
圖1 圖書推薦系統功能模型
在圖1中,圖書推薦系統包含圖書元數據庫、用戶特征庫、圖書挖掘子系統、行為監控子系統、用戶特征子系統、搜索引擎子系統、頁面推薦子系統。從圖1 可以看出,推薦系統的設計與實現重點在于各項數據特征的搜集,其實質在于讀者特征與圖書特征間的精準匹配。想要達到該目的,既需要通過搜集讀者的相關歷史數據建立精準的用戶畫像,也需要建立圖書的相關數據庫,然后找到二者間的聯系[10-15]。
對于用戶特征庫,主要依靠用戶注冊時的相關基礎信息,如性別、年齡、職業、興趣等作為推薦的冷啟動。當用戶有瀏覽記錄、收藏記錄時,逐步增加這些對于推薦的權重。
對于圖書元庫的建立,該文主要根據圖書類別進行分類,同時記錄相關的用戶瀏覽信息。
基于以上的系統功能分析,建立如圖2 所示的系統推薦流程[16]。
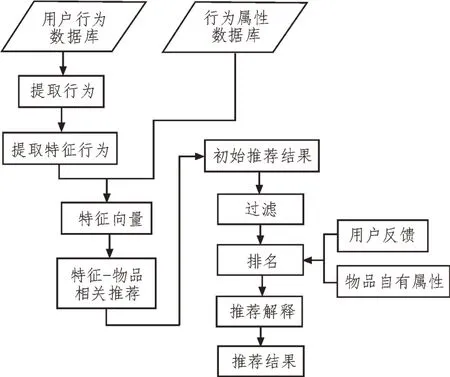
圖2 系統推薦流程
在圖2中,結合用戶的行為數據庫,從中提取特征行為,其次結合行為屬性形成特征向量。然后利用特征向量,從數據庫中篩選符合相關約束的圖書元作為初始的推薦結果。隨后,通過系統內置的相關規則進行過濾,再結合用戶反饋以及書籍的自有屬性進行排名。最終附加上推薦的原因,給出推薦結果。
圖3 給出了系統的軟件架構,為了提升系統推薦的實時性,系統采用分層架構。
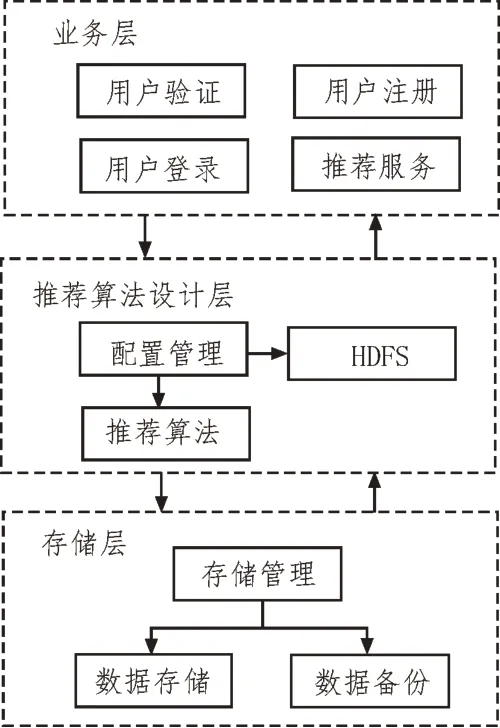
圖3 圖書推薦系統的軟件架構
通過分層,可以降低業務層、推薦算法層與存儲層間的耦合程度,每個層間只需給其余層次提供合適的軟件接口即可。該種設計使得系統的軟件結構更清晰,提升了系統后期的可維護性。
1.2 推薦算法
對于推薦系統而言,其核心在于推薦算法的設計。文中推薦系統使用的算法主要包括基于內容的推薦算法與系統過濾算法。
基于內容的推薦算法,需要依靠內容特征的提取,文中主要是對書籍特征的提取。由于該方法不需要用戶信息,適用于新用戶注冊時進行系統冷啟動。內容推薦的關鍵在于對系統內m本書建立p維的空間,然后基于用戶的愛好與興趣,利用用戶與書本間的鄰近度進行推薦。當基于內容進行推薦時,系統鄰近度的計算方式如式(1)所示:
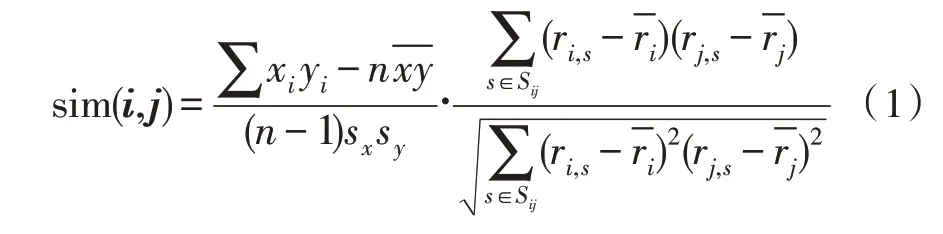
其中,i、j分別代表了用戶向量與書本向量,這兩個向量將書本、用戶的特征作為向量的元素。
當系統內產生用戶的日志信息后,系統將使用過濾規則進行書籍的推薦。該規則采用與目標相似度較高的用戶或書籍進行推測,推斷出用戶對于某些書籍的潛在興趣。在推斷過程中,主要借助夾角的余弦值衡量該種相似性,其計算方法如式(2)所示:
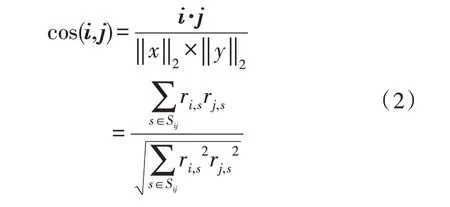
2 算法實現
2.1 基于Hadoop的平臺部署
由于圖書推薦系統的推薦涉及了大數據的處理與挖掘,因此,需要數據密集型分布式計算框架的支持。該文選取的計算框架為Hadoop,該框架可以通過多個基礎計算機集群的聯合獲得超高的計算能力,且具備良好的擴展性。在Hadoop 中包含了Pig、Chukwa、Hive 等多個項目結構,文中涉及的主要有分布式文件系統HDFS 與Hadoop 的編程模式MapReduce。對于HDFS,通過表1 的環境部署了七個節點的分布式存儲系統。其中,一個是Master 節點,六個是Slaver 節點。

表1 仿真環境
對于Hadoop 的編程模式,其實現了計算過程中動態的控制計算節點,保證了Hadoop 系統的靈活性與可擴展性。在編程中,MapReduce 只受數據當前行的影響,其過程包括Map 與Reduce 兩個節點。實現過程如式(3)所示:

圖書的推薦高度依賴于圖書度的統計,圖書度反映了圖書瀏覽或被購買的頻次,是圖書熱門程度的重要體現,通過MapReduce 實現圖書度的統計方法如下文所述。
在該系統中,讀入用戶日志文件,基礎的存儲格式為:<用戶ID,商品ID,用戶評分,時間戳>。在圖4中,給出了用戶ID 為1、2、3 的用戶日志文件。經過Map后,系統得到的結果為<商品ID,所有用戶的購買頻次>。隨后,利用Reduce 函數合并結果,以商品ID 為主鍵將相同商品的購買次數相加,最終得到<商品ID,商品度>作為MapReduce 的輸出結果。
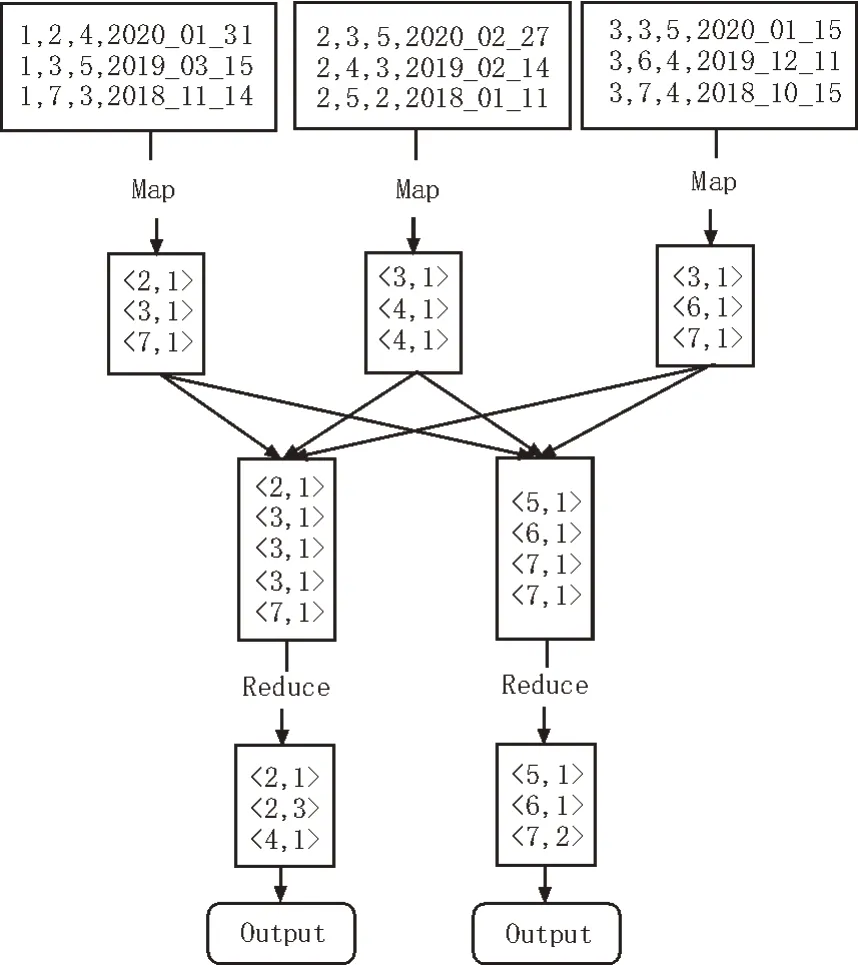
圖4 MapReduce編程模式
通過引入MapReduce 編程模式,該系統可以靈活地定義Map 與Reduce 中的主鍵進行計算,統計各項數據作為系統的推薦依據。
2.2 算法仿真與系統實現
為了評估文中推薦算法在Hadoop 上的部署效果,使用Amazon 的開放數據集。在該數據集中,包含了581 921 位用戶對于187 213 部圖書的共112 340 015 次的圖書打分記錄。
圖5 給出了算法在表1 Hadoop 集群上的運行時間。其中,橫軸代表Hadoop 集群中計算機的數量,縱軸代表算法的運算時間,圖例代表了一次性推薦不同數量的圖書M。可以看出,推薦算法的運行效率受到推薦圖書數量與Hadoop 節點數兩個方面的影響。值得注意的是,對于文中的推薦算法而言,當推薦的圖書種類數較少時(M為100 或200),集群大小對于算法計算時間的影響并不顯著。當推薦的圖書種類數較大時(M為3 000 或5 000),算法計算的時間隨著集群數量增加呈線性減小的趨勢。當M=5 000時,使用七個節點計算的時間約為890 s,而單節點的計算時間為4 400 s,時間約為單節點的1/5。因此對于Hadoop 平臺,需要初始化足夠數目的Mapper 文件才能充分發揮其大數據處理的優勢。
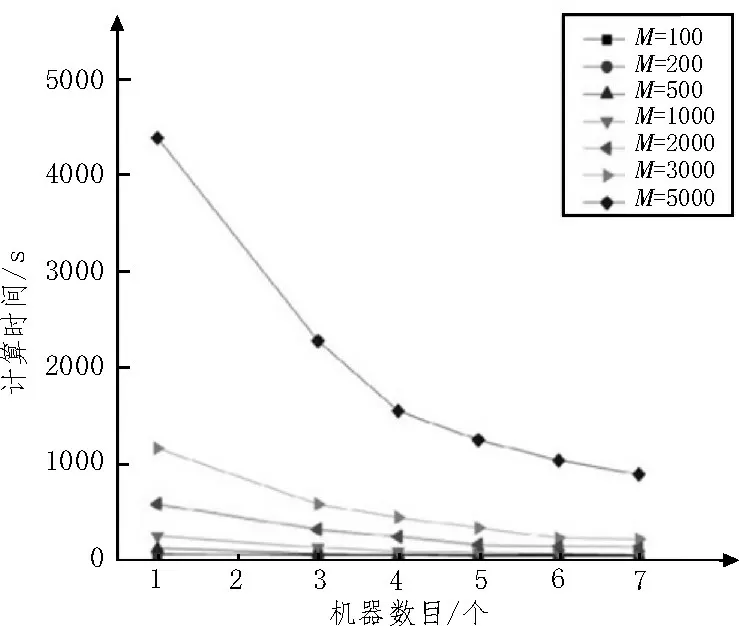
圖5 基于Hadoop的算法運行效率
最終,結合圖3 給出的系統軟件框架實現系統功能。在實現過程中,用戶對于圖書的打分信息使用JSP 調用JDBC后,通過數據存儲模塊寫入數據庫。系統內的推薦業務借助Hadoop 平臺,結合圖4的MapReduce 編程模式進行實現。在最終實現的系統個人主頁的界面中,共包含了四個功能模塊,系統界面通過JSP 調用相關的數據接口實現。個人主頁界面上展示了用戶的個人信息,且提供了搜索功能。系統會結合當前的讀書熱點給出“每日一薦”,根據用戶的歷史讀書行為以及用戶信息給出“猜你喜歡”的相關推薦。
3 結束語
文中對圖書推薦的相關方法進行了研究,通過Hadoop 部署了系統中用戶特征、用戶行為日志等特征庫,實現了用戶特征到圖書內容特征的匹配。Hadoop 大數據計算框架的引入提升了系統的計算能力與數據存儲能力,對于系統后續的擴展、升級也具有較高的實用價值。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
