MC-Q強化學習的PHEV能量管理策略
2023-01-06 09:21:56王惠慶
汽車實用技術 2022年24期
王惠慶
MC-Q強化學習的PHEV能量管理策略
王惠慶
(長安大學 汽車學院,陜西 西安 710064)
插電式混合動力汽車具有節能的特點,而多動力源之間的能量管理策略對混合動力汽車能耗有很大的影響,故文章以一款在固定線路上運行的串聯插電式混合動力城市客車為例,基于以往的行駛工況,根據馬爾科夫理論,把需求功率隨時間的變化轉換為狀態轉移矩陣,用概率矩陣生成符合實際使用條件的隨機功率序列。建立Q強化學習模塊,使用得到的隨機功率序列進行訓練,實現城市客車能量分配的實時優化控制。仿真結果表明,文章所提出的強化學習能量管理算法相比于規則控制算法能明顯的優化能耗,對比動態規劃全局優化策略總能耗僅輕微增長,控制策略可實現實時應用。
插電式混合動力汽車;能量管理;強化學習;轉移概率矩陣
能量管理策略對插電式混合動力汽車(Plug- in hybrid electric vehicle, PHEV)的能耗效率有很大的影響,各國研究人員已經提出了很多的能量管理策略,包括基于規則的消耗-維持(Charge Depletion-Charge Sustaining, CD-CS)策略,基于全局優化的動態規劃和龐特里亞金最大化原理(Pontryagin's Maximum Principle, PMP)控制策略,和可實時應用的等效燃油最小化策略等。近年來,針對強化學習的研究越來越多[1],而Q學習算法作為一種用于機器學習,基于數據的與模型無關的強化學習算法,被越來越多用于混合動力汽車的能量管理策略當中[2]。但針對插電式混合動力汽車強化Q學習算法的能量管理策略研究較少,而且強化學習要求的樣本量較大,使用實際工況很難訓練出較好結果。
針對以上問題,本文基于一款固定路線運行的插電式混合動力城市客車,在傳統的Q學習算法的基礎上,用實測西安工況得到關于功率的馬爾科夫狀態轉移矩陣,生成隨機功率序列訓練Q學習矩陣,得到MC-Q能量管理算法。最終實現針對插電式混合動力汽車能量管理的實時控制,并把仿真結果與動態規劃(Dynamic Programming, DP)算法和CD-CS算法相比較。
1 整車建模及仿真工況
1.1 整車參數
本文所選取的PHEV動力系統結構如圖1所示,發動機和集成式智能啟動驅動(Integrated Starter Generator, ISG)電機共同組成發動機驅動型發電機(Engine Generator Unit, EGU)單元,與驅動電機串聯,把發動機提供的機械能轉換為電能,驅動車輛行駛,車輛可以通過外接電源為磷酸鐵鋰電池充電,該款車型整備質量為13 500 kg,輪邊減速器減速比為13.9,采用雙電機驅動,單體電池電壓為3.2 V,電池總電壓為537.6 V,總容量為180 Ah。
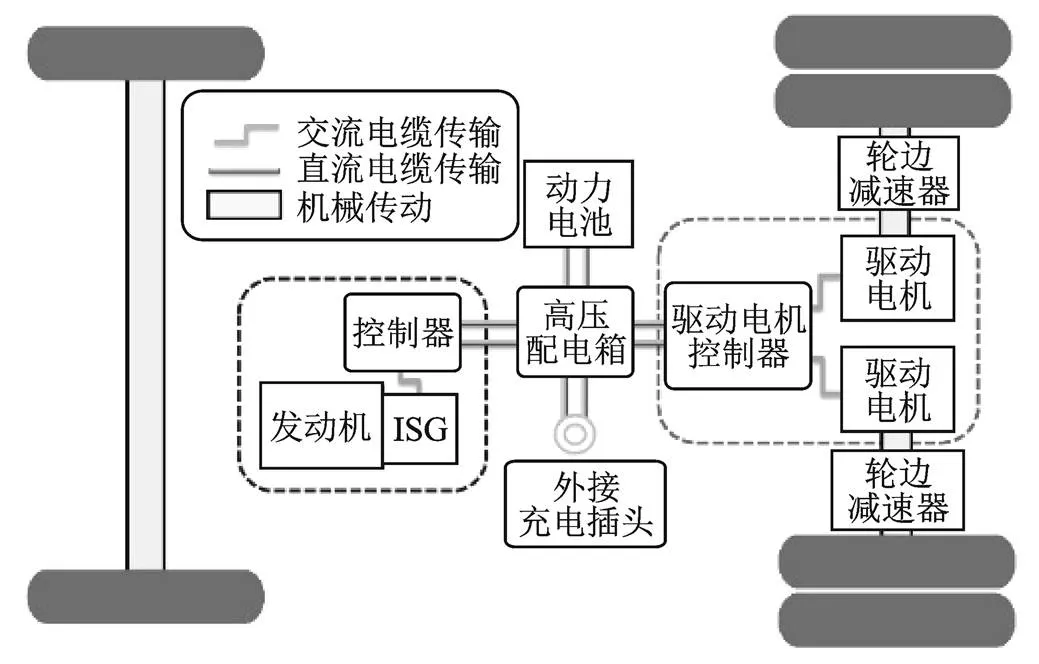
圖1 PHEV動力系統結構
1.2 車輛縱向動力學模型
根據汽車理論汽車行駛平衡方程[5],車輛縱向動力學模型可以表示為
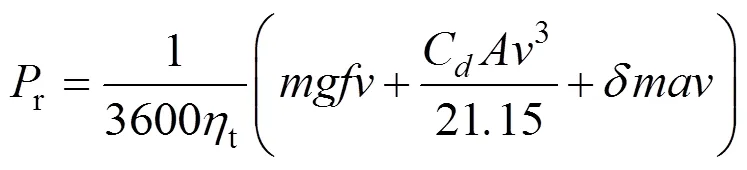
式中,為總質量;為重力加速度;為滾動阻力系數;為車速;d為空氣阻力系數;為車輛迎風面積;為汽車旋轉質量換算系數;為加速度;t為傳動系統機械效率;r為車輛行駛的需求功率。
車輛需求功率和電池輸出功率b和EGU輸出功率的egu關系為
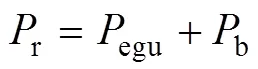
1.3 動力部件模型
對于發動機和驅動電機,根據穩態實驗建模數據,可以把它們的效率或者油耗表示為隨轉矩和轉速改變的函數,它們的效率如圖2和圖3所示。

圖2 發動機萬有特性圖
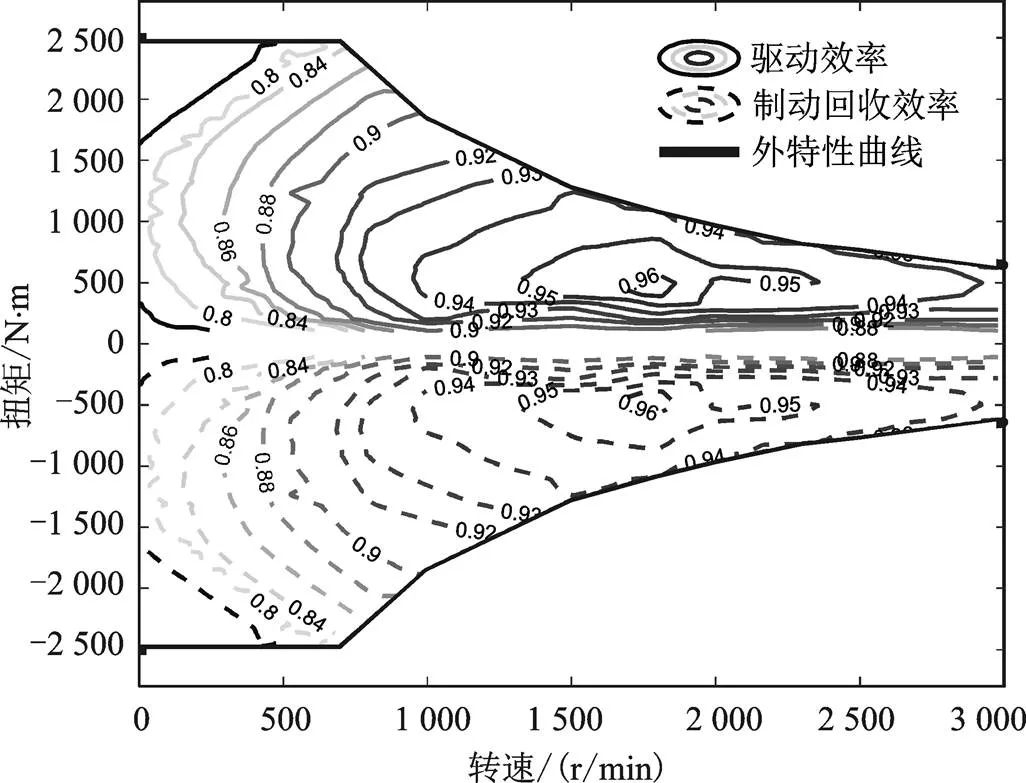
圖3 電機效率圖
1.4 仿真工況
本文依據實測得到的西安市城市工況,選擇了同一公交路線下同一時段不同日期測得的兩條速度譜,分別作為訓練工況和測試工況,兩個工況的總長度都是140.15 km,速度譜如圖4所示。
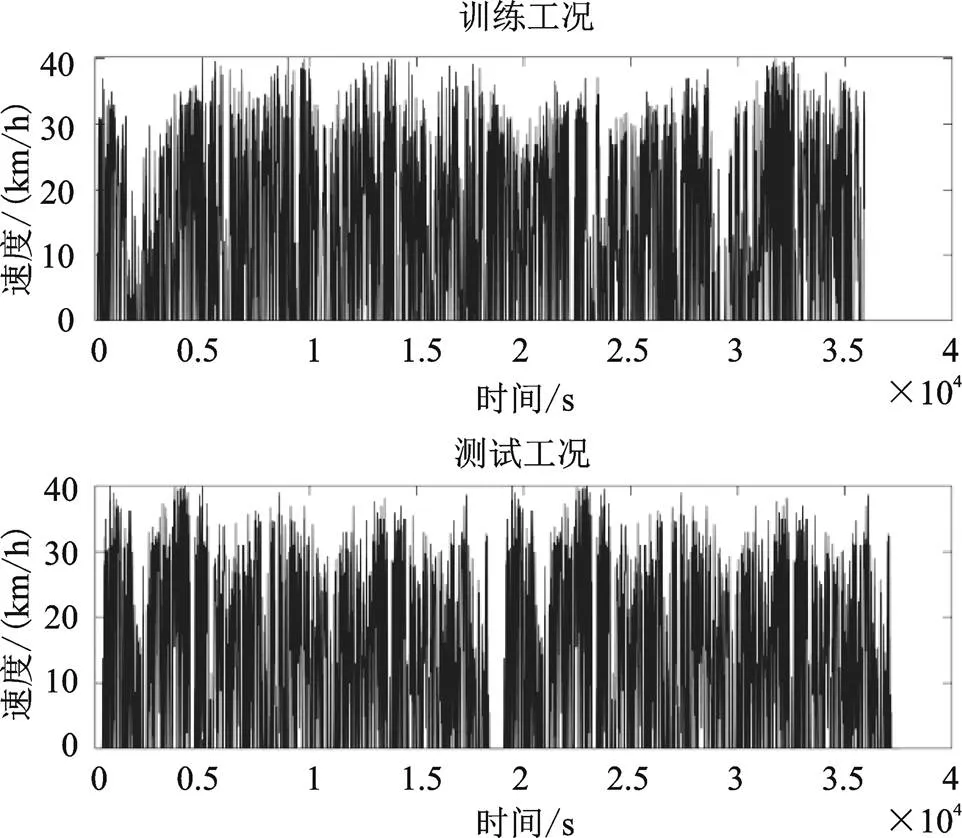
圖4 仿真工況
2 MC-Q學習算法能量管理策略構建
相比于傳統的基于Q學習算法能量管理策略,本文所提出的MC-Q學習能量管理控制算法,創新點在于訓練工況不是直接使用實測工況,而是把實測工況根據馬爾科夫理論轉換為概率轉移矩陣,依據得到的概率矩陣生成隨機工況序列,這樣可以在每一個訓練循環當中,使用符合目標車輛實際使用情況,但又完全不同的需求功率序列進行訓練,大大豐富了樣本的復雜程度,防止訓練結果過早的陷入局部收斂當中。
2.1 需求功率轉移概率矩陣
根據選擇的測試工況,基于車輛的動力學方程(1),可以計算出需求功率,而需求功率可以看成是一個馬爾科夫過程[1],后一時刻的功率只與當前時刻有關,與以往無關。對需求功率進行離散化,用最大似然法和最鄰近法求轉移概率[2]
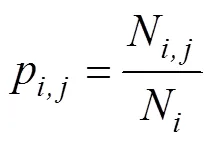

式中,N表示離散的需求功率從P轉移到P的次數;而N表示需求功率P出現的總次數;N為下一時刻狀態數量;得到的狀態轉移概率矩陣如圖5所示。
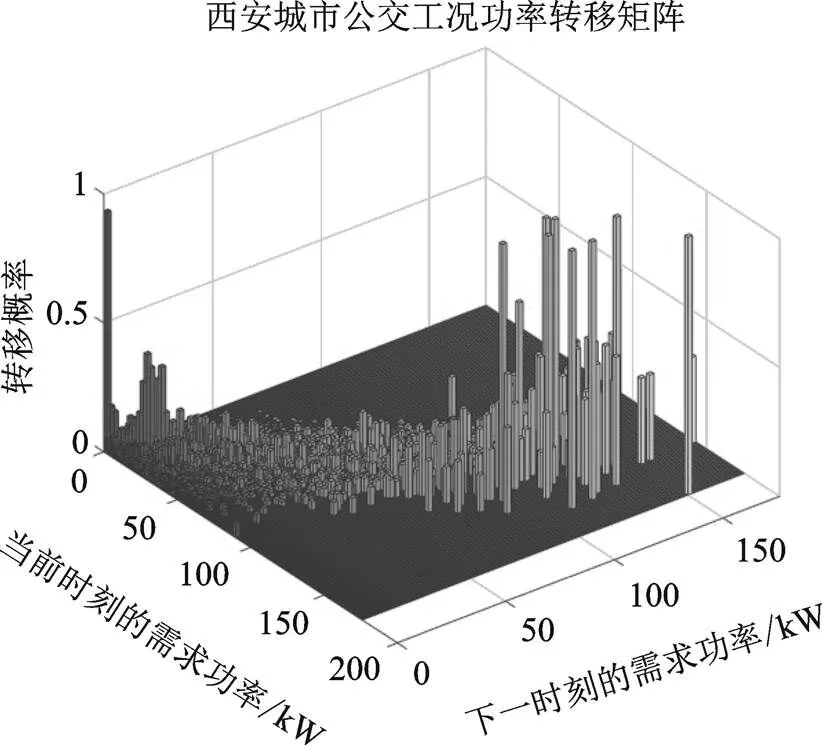
圖5 功率轉移概率矩陣
利用Matlab使用蒙特卡洛模擬法,基于得到的轉移概率矩陣,在每一輪訓練之前生成與訓練工況長度相等的隨機功率序列,用于訓練強化學習值函數,從而大大的豐富樣本量,改善訓練結果。
2.2 Q學習算法模型
Q學習是與環境無關的基于數值迭代的動態規劃算法,把被控對象看成智能體,創建表示值函數的表,根據此時的狀態,在表中找到所對應最大值的最優動作,并計算得到下一時刻狀態s+1和與環境進行交互得到的獎勵值,之后對表進行更新。Q學習算法的核心是構建表,本文針對能量管理策略研究,以EGU單元輸出功率egu為控制變量,以需求功率r和電池荷電狀態為狀態變量
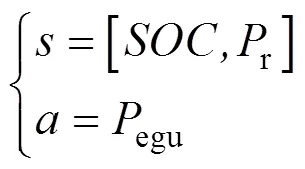
而值函數的更新公式如式(6)所示[4]

式中,為學習率,決定了此次訓練的誤差有多少要被學習,本文選擇0.012;是未來的獎勵對現在的影響因子,越大表示越注重未來的利益,本文選擇0.9。
為了防止訓練過早的陷入局部最優,使用貪心策略選擇動作,智能體以1-的概率選擇最大化值的動作,而以的概率選擇隨機動作,開始訓練時較大,之后不斷減小直到為0。
獎勵函數是衡量每一步動作優劣的關鍵,PHEV能量管理的目的,是使綜合能耗最小化,所以使用的電耗成本和油耗成本組成目標函數,獎勵函數為目標函數的倒數[7]

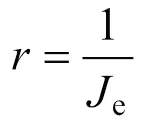
式中,bat為電池實際消耗的功率,因為內阻的存在,實際消耗的功率要大于需求電池功率b;f為燃氣價格,取3.7元/m3;e為電價,取0.8元/kWh;為氣體密度,取0.717 kg/m3;為重力加速度;ref是期望末值,取0.3;為權重系數,取1。
仿真過程中還要考慮動力系統物理限制,如式(9)所示
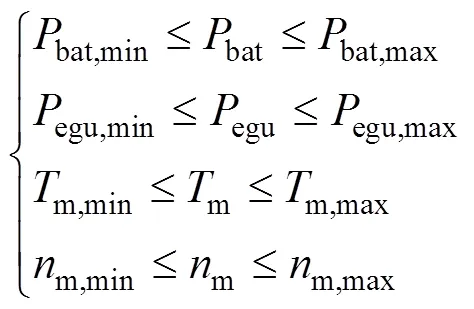
式中,m為電機輸出轉速;m為電機輸出轉矩,max和min分別對應了上下邊界。
最終,當值平均誤差收斂到期望值,或達到最大訓練循環后,訓練結束,用得到的表對測試工況進行能量分配仿真,得到最優控制序列
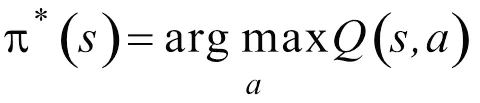
3 CD-CS策略與DP策略構建
3.1 CD-CS策略
CD-CS策略是一種根據工程師經驗提出的基于規則的控制策略[8],算法簡單,控制速度快,可以實現實時應用,但因為策略過于簡單,能耗效果差。
具體的控制過程為,根據電池荷電狀態來控制發動機的啟動與停止,當較高時,發動機關閉,所有的需求功率均由電池提供,直到電池的降低到最低閾值0.3,為了保證電池不要過放電,發動機啟動,按照恒定的70 kW向外輸出功率,當上升至設定的閾值上限0.35以后,發動機關閉,功率繼續由電池提供。
3.2 DP能量管理策略
動態規劃算法理論上能夠得到全局最優的控制效果,但是需要預先知道工況,所以無法實時應用,本文使用先逆向求解,在正向尋優的方法來實現。結果用來評估提出的MC-Q算法的優劣。
把電池作為狀態變量,離散化之后逆向求解每個時刻不同對應的最優控制變量egu,最后正向獲得最優控制序列,逆向遞歸方程如式(11)所示。
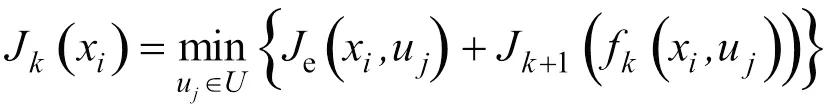
式中,為當前時刻;u為第個EGU功率點;x為第個離散點;為egu的集合;f(x.u)為當前狀態變量為x且控制變量為u時得到的第+1步的;e為式(7)所示的目標函數;J(x)是為x時由第步到最后一步的累計最小成本。優化過程同樣需要滿足如式(9)所示的物理約束。
4 仿真分析
圖6是仿真過程中每一輪循環后表與前一輪的偏差值,體現了訓練的收斂過程,可以看出在前100輪循環中,表的差值快速下降,即模型快速趨于收斂,又因為訓練工況是根據概率矩陣隨機生成的,所以表不會完全收斂,而是在較低的水平上下波動,防止了訓練過早的陷入局部最優,豐富了訓練結果。
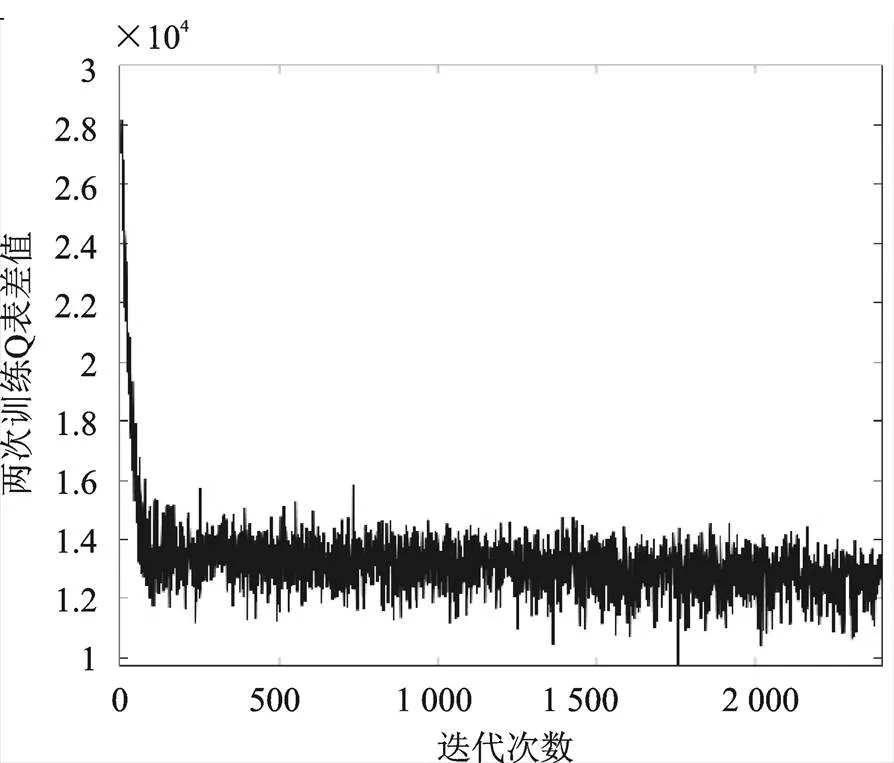
圖6 Q表差值
基于前文給出的測試工況,分別使用CD-CS策略、DP策略和所提出的基于馬爾科夫鏈的Q強化學習(MC-Q)策略進行仿真比較,初始值取0.9。變化曲線如圖7所示,EGU單元輸出功率如圖8所示,表1為三種控制策略的成本對比。
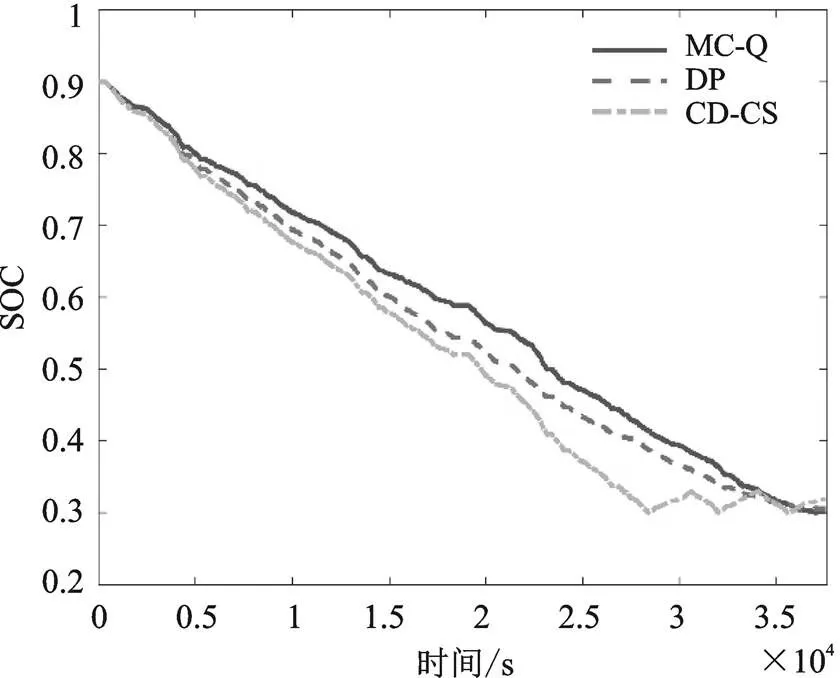
圖7 SOC變化曲線對比
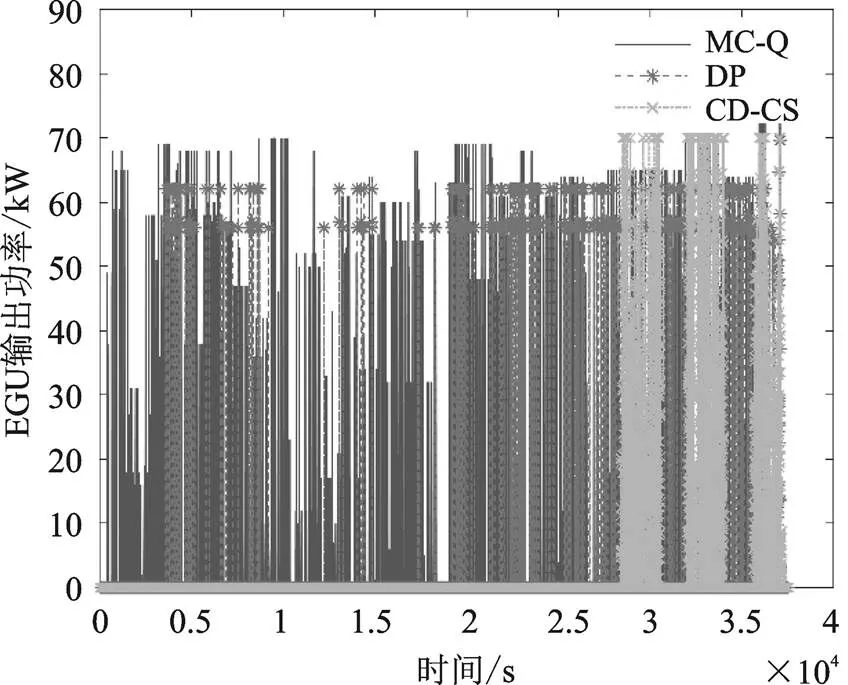
圖8 EGU輸出功率
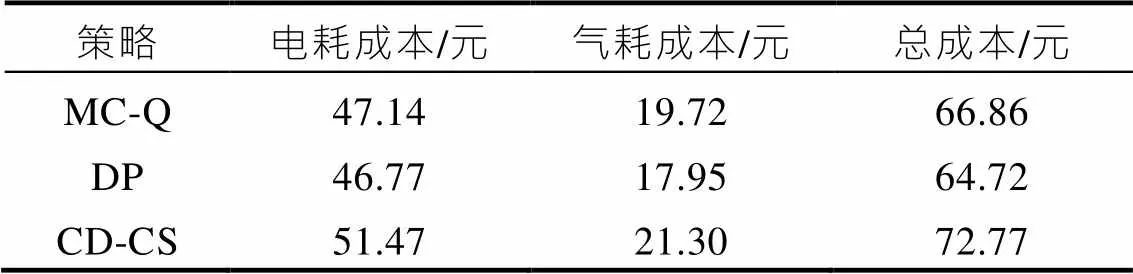
表1 不同策略能耗成本對比
從變化曲線可以看出,三種控制策略最終都達到了期望的最低值0.3左右,但路徑不同。結合圖5可知,三種控制策略能量的分配過程完全不同,而DP策略因為是全局優化策略,理論上能得到最優的能量分配結果,所以能耗成本最低。而本文所提出的MC-Q策略能耗明顯的優于傳統的基于規則的CD-CS策略,總成本降低了8.1%,而相比DP策略總成本只略微增長也保持了線性下降,且可實現實時應用。
5 結論
根據仿真結果可知,本文所提出的基于馬爾科夫鏈的Q強化學習能量管理算法,相比傳統基于規則的控制策略,在140 km的西安市城市工況下,可以使電耗和能耗組成的總成本降低8元,而相比動態規劃得出的全局最優結果,能耗成本只提升了1.9元,且具有一定的魯棒性,可以根據以往工況訓練并且實現在固定線路上實時應用,具有一定的推廣意義。
[1] 尹燕莉,張劉鋒,周亞偉,等.基于Q學習的純電動重型商用車智能換擋控制策略研究[J].重慶理工大學學報(自然科學),2021,35(9):73-82.
[2] 解少博,劉通,李會靈,等.基于馬爾科夫鏈的并聯PHEB預測型能量管理策略研究[J].汽車工程,2018, 40(8):871-877,911.
[3] LIU T,WANG B,YANG C L.Online Markov Chain- based Energy Management for a Hybrid Tracked Vehicle with Speedy Q-learning[J],Energy,2018(7): 544-555.
[4] 劉騰.混合動力車輛強化學習能量管理研究[D].北京:北京理工大學,2017.
[5] 張劉鋒.基于強化學習的混合動力系統智能化控制方法研究[D].重慶:重慶交通大學,2021.
[6] 張盟陽.基于動態規劃的PHEV能耗分析[J].汽車實用技術,2021,46(16):130-133.
[7] 解少博,羅慧冉,張乾坤,等.智能網聯混合動力車輛速度規劃的多目標協同控制研究[J].汽車工程,2021, 43(7):953-961.
[8] 張思雨,史珊珊.PHEV能量管理策略研究[J].汽車實用技術,2022,47(1):186-188.
Energy Management Strategy of PHEV Based on MC-Q Reinforcement Learning
WANG Huiqing
( School of Automotive Engineering, Chang’an University, Xi’an 710064, China )
The plug-in hybrid is energy efficient, and the energy management strategy among multiple power sources has a great impact on the energy consumption of hybrid vehicles.Taking a run on a fixed line series plug-in hybrid city bus as an example, based on the previous cycles, according to markov theory, the demand for power transformation along with the change of time for the state transition matrix, the random power sequence is generated by probability matrix. Module Q reinforcement learning and training, by using the random power sequenceto realize the energy distribution of the city bus real-time optimization control. Simulation results show that the proposed reinforcement learning energy management algorithm can significantly optimize energy consump- tion compared with the rule control algorithm, and can greatly improve the time efficiency compared with dynamic programming and other global optimization strategies, and realize real-time control.
Plug-in hybrid electric vehicle; Energy management; Reinforcement learning; Transition probability matrix
U469.7
A
1671-7988(2022)24-28-05
U469.7
A
1671-7988(2022)24-28-05
10.16638/j.cnki.1671-7988.2022.024.005
王惠慶(1997—),男,碩士研究生,研究方向為新能源汽車能量管理策略與控制算法,E-mail:2421353 871@qq.com。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
能源工程(2020年6期)2021-01-26 00:55:22
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
山東冶金(2019年3期)2019-07-10 00:54:04
消費導刊(2018年10期)2018-08-20 02:57:02
數學大世界(2018年1期)2018-04-12 05:39:14
通信電源技術(2016年1期)2016-04-16 04:57:26
電測與儀表(2016年20期)2016-04-11 11:38:24
