粒子群優化神經網絡研究生就業質量評價模型
2023-01-06 03:45:30聶子一焦夢青賈子純
宜賓學院學報 2022年12期
趙 楠,聶子一,焦夢青,賈子純
(1.河北地質大學研究生學院,河北石家莊 050031;2.河北地質大學信息工程學院,河北石家莊 050031;3.河北地質大學水資源與環境學院,河北石家莊 050031)
促進高校畢業生就業,特別是按照高層次人才培養的研究生就業,是實施“科技興國、人才強國”戰略的重要舉措,也是全面建成小康社會的重要推力[1],當前促進高校畢業生的政策導向也十分鮮明[2].近年來,我國研究生招生人數在陸續增加,研究生及其家長對就業的關注點逐漸從“能否就業”轉向“就業質量”,就業質量評價受到國家體制、經濟發展水平、高校層次差異及個體能力等因素的影響,不同高校因其辦學特色、學科布局及人才培養方案不同,就業質量評價體系也有所差異[3].一些高水平的綜合類大學如中國人民大學、南開大學、西南大學等已逐步探索建立了本校的就業質量評價指標體系[4].一些具有一流學科的財經類、醫藥類、農林類高校也針對本校的就業質量評價制定了特色化的指標體系.
在就業質量評價體系指標研究方面,使用頻度較高的指標為就業率、畢業生就業滿意度、用人單位滿意度、工作穩定性和社會認可度五項[5].張文锍[6]分別從大學生個體、學校、用人單位、家庭和社會五個維度構建指標體系,采取主客觀相結合、定性定量相互補充、以及宏觀微觀相互交叉的方法評價就業質量.呂欽[7]在對國內外就業質量評價指標充分調研的基礎上,將評價指標概括為五大類:薪酬狀況、客觀工作條件、工作與生活的平衡、工作滿意度和發展情況.
在就業質量評價模型研究方面,張淼[8]以陜西省高校畢業生作為研究樣本,制定了穩定與公平、安全與健康、報酬與提升3個一級指標,9個二級指標以及13個三級指標,通過結合層次分析法、實證調研法、專家打分法3種基本方法,確定了三級指標的不同權重,以及加權求和的計算公式.劉永平[9]、齊鵬等[10]、尹曉菲等[11]、劉敏等[12]在充分進行文獻調研的基礎上,基于滿意度的視角下,構建涵蓋工作單位滿意度、就業指導滿意度、個人滿意度的就業評價指標體系,并采用模糊數學理論方法確定每個指標的模糊綜合評價值.童娟[13]把畢業生就業質量劃分為優、良、一般、差4個等級,建立神經網絡模型,通過對就業數據的訓練學習獲得指標權重,避免人為規定權重的主觀性.
智能預測就業質量模型屬于非線性的評價技術,其預測結果明顯優于層次分析法、模糊數學理論等傳統方法.但是單一的智能算法在迭代尋求最優解時會有一個明顯的問題,即傳統BP神經網絡算法應用于就業質量評價易陷入局部最優、泛化能力不足.為解決這一問題,本文提出基于粒子群改進神經網絡的混合算法評價研究生就業質量,以期改善當前模型不足,提高評價精度,獲得更可靠的評價效果.
1 粒子群改進神經網絡的研究生就業質量評價模型
1.1 研究生就業質量評價體系
對于研究生就業質量評價,存在大量不同指標的評價模型,也不可能將全部指標均納入研究生就業質量評價體系.本文建立的研究生就業質量評價體系考慮以下特點:(1)針對性更強,研究生具有高層次人才的特性,篩選的評價指標更能突出研究生的特性,減少對于本科生、研究生均適用的普適標準;(2)主客觀相結合,既反映就業者的主觀感受,同時兼顧工作單位的客觀滿意度;(3)可操作性強,評價指標體系具有實用和可推廣的特點.構建的研究生就業質量評價體系如表1所示.

表1 研究生就業質量評價指標體系
1.2 BP神經網絡
BP神經網絡是一種前饋神經網絡,即它的傳播方向是從后向前反向傳播,它通常具有三層拓撲結構,即輸入層、隱含層和輸出層,如圖1所示.BP神經網絡通過不斷更新傳播過程中的權值和閾值來逐步完善網絡,最終達到實際輸出值和期望輸出值誤差均方差最小的目的.

圖1 BP神經網絡拓撲結構
設第m個研究生就業質量評價樣本的期望輸出結果為Em,BP神經網絡的實際輸出結果記為Om,那么訓練樣本的結果應輸出誤差計算公式為:

式中n為訓練樣本數.
隱含層與輸出層間的權重為Wxy、輸入層與隱含層間的權重為Wyz,其中,y代表隱含層節點、x為輸出層節點、z為輸入層節點,權值的更新方式如下:

式中η為學習速度,E為真實值與預測值的誤差.
BP神經網絡的學習過程實際就是權值和閾值更新的過程,傳統更新規則為梯度下降法,權重的初始值主要依據個人經驗所得.權重初值的選取直接影響BP神經網絡學習性能,進而影響模型的評價效果.因此,本文采用粒子群算法對神經網絡的權重賦初始值.
1.3 粒子群算法
粒子群算法用一種粒子來代表鳥群中的鳥,這種粒子是無質量的,僅具有兩個屬性:速度和位置.各粒子在空間中單獨搜尋最優解,將其記為當前個體極值pbest,并將個體極值與整個粒子群的其他粒子共享,找到最佳的個體極值作為整個粒子群的當前全局最優解gbest.在每一次迭代中,粒子通過跟蹤這兩個極值更新自己的速度和位置,即:

式中:i表示粒子的數目,νi表示粒子的速度,rand()是介于(0,1)之間的隨機數,xi是粒子當前的位置,c1、c2是學習因子,ω為權值系數.
1.4 粒子群優化BP神經網絡評價研究生就業質量步驟
傳統BP神經網絡算法容易陷入局部最優問題的原因是在更新過程中單純利用誤差反向傳播調整權值和閾值.通過粒子群算法可拓展搜索權值、閾值的范圍和深度,優化BP神經網絡的權值和閾值,實現全局最優.具體實施步驟如下:
(1)根據表1的評價指標內容,采集歷史數據,組成研究生就業質量評價樣本集合;
(2)歸一化處理的樣本數據作為BP神經網絡的輸入向量,研究生就業質量評分值作為輸出向量,確定算法的拓撲結構;
(3)設置種群規模,初始化種群位置和速度,并將研究生就業質量評價誤差作為適應度函數值;
(4)計算粒子適應度函數,更新個體最優位置pbest和群體最優位置gbest;
(5)根據式(4)調整粒子速度和位置;
(6)產生(0,1)范圍隨機數,如果小于變異系數,則隨機初始化種群,否則,獲得最優Wxy和Wyz的初始值;
(7)根據最優的Wxy和Wyz初始值,進行研究生就業質量評價神經網絡訓練,并采用測試集對訓練好的網絡進行仿真測試.
通過粒子群改進BP神經網絡模型的研究生就業質量評價流程如圖2所示.

圖2 粒子群改進BP神經網絡算法流程
2 仿真測試
2.1 測試環境
為了測試粒子群改進BP神經網絡的研究生就業質量評價效果,采用Python 3.8作為開發工具編程實現研究生就業質量評價程序.研究生就業質量評價結果采用百分制進行描述,共收集2500條研究生就業質量評價數據.使用留出法將樣本數據隨機分為訓練集(2000條)和測試集(500條),統計研究生就業質量評價精度.
2.2 測試結果與分析
為顯示出優化后的算法的優勢,將單一算法與粒子群優化后的算法進行對照.為了分析的準確性,本文從3個角度,即平均絕對誤差(AAD)、平均絕對百分誤差(RAAD)、均方根誤差(RMSE),對仿真效果進行對比,預測結果如圖3所示.
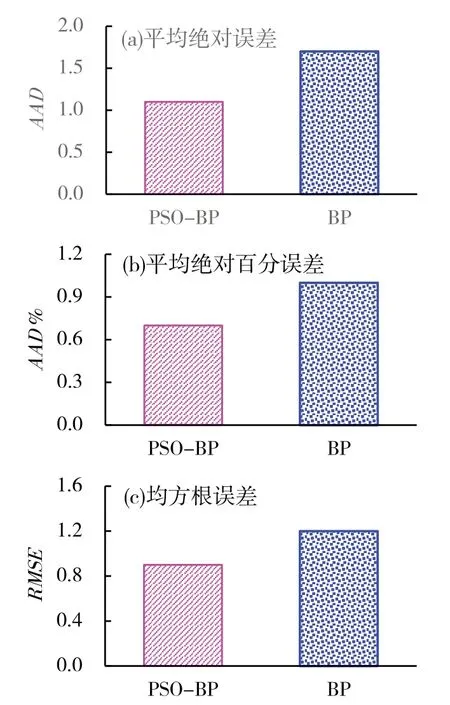
圖3 預測結果對比


其中N表示測試樣本數量.
從圖3可以看出,無論是AAD、RAAD還是RMSE,粒子群改進的BP神經網絡顯示出的優勢十分顯著,改進后的算法預測誤差均低于傳統算法的預測誤差.
3 結論
為了改善研究生就業質量評價效果,本文引入了基于大數據挖掘技術的研究生就業質量評價模型,采用粒子群算法和BP神經網絡建模對研究生就業質量進行評價.仿真結果表明,智能混合算法優化了BP神經網絡權重、閾值的初始值,避免了傳統BP神經網絡算法陷入局部最優的情況,且精度更高,預測值更接近真實值,評價結果更可靠,為研究生就業質量評價提供了一種更好的方法.
猜你喜歡
工會博覽(2023年3期)2023-04-06 15:52:34
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
石油瀝青(2021年4期)2021-10-14 08:50:44
小康(2021年7期)2021-03-15 05:29:03
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
活力(2019年19期)2020-01-06 07:34:38
雜文月刊(2019年15期)2019-09-26 00:53:54
中國生殖健康(2019年2期)2019-08-23 08:12:08
汽車觀察(2016年3期)2016-02-28 13:16:26
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
