基于值分解的多目標(biāo)多智能體深度強(qiáng)化學(xué)習(xí)方法
2023-01-27 08:27:28宋健王子磊
計(jì)算機(jī)工程 2023年1期
宋健,王子磊
(中國科學(xué)技術(shù)大學(xué)自動(dòng)化系,合肥 230027)
0 概述
隨著深度學(xué)習(xí)技術(shù)的發(fā)展,強(qiáng)化學(xué)習(xí)方法的聚焦問題逐步從單智能體領(lǐng)域轉(zhuǎn)移到多智能體領(lǐng)域。在現(xiàn)實(shí)世界中,許多需要多個(gè)智能體協(xié)作的場(chǎng)景都是多目標(biāo)多智能體決策問題:每個(gè)智能體都需要實(shí)現(xiàn)自己的目標(biāo),但是只有當(dāng)智能體協(xié)作并允許其他智能體成功時(shí),才能獲得所有智能體成功的全局最優(yōu)解[1]。例如:在自動(dòng)駕駛中,當(dāng)多輛車的目標(biāo)位置和預(yù)計(jì)軌跡發(fā)生沖突時(shí),它們必須執(zhí)行協(xié)同機(jī)動(dòng);在社交環(huán)境中,人們相互合作一般可以獲得更高的全局回報(bào),只局限于自身利益而不顧大局的個(gè)體往往成為害群之馬,適得其反。一個(gè)環(huán)境即便只涉及合作任務(wù),即所有個(gè)體目標(biāo)是一致的,環(huán)境仍可以被表述為多目標(biāo)場(chǎng)景。例如在星際爭(zhēng)霸2 中,一個(gè)收集資源的單位也需要小心行動(dòng),以免暴露正在執(zhí)行秘密偵查任務(wù)的單位。
多智能體強(qiáng)化學(xué)習(xí)廣泛應(yīng)用了深度學(xué)習(xí)方法,且被使用在各種復(fù)雜場(chǎng)景中,但多目標(biāo)多智能體場(chǎng)景中的最優(yōu)決策仍面臨重大挑戰(zhàn)。文獻(xiàn)[2]提出的IQL(Independent Q-Learning)假設(shè)場(chǎng)景中的各智能體是相互獨(dú)立的,其決策是互不影響的,分別使用Q-Learning 方法訓(xùn)練每個(gè)智能體;文獻(xiàn)[3]提出的MADDPG(Multi-Agent Deep Deterministic Policy Gradient)和文獻(xiàn)[4]提出的M3DDPG(Multi-Agent Minmax Deep Deterministic Policy Gradient)考慮到了具有不同獎(jiǎng)勵(lì)、不同目標(biāo)的多智能體場(chǎng)景;文獻(xiàn)[5]提出的QMIX(Q-Mixer Network)模型將全局動(dòng)作值函數(shù)分解為每個(gè)智能體的動(dòng)作值總和。然而,多目標(biāo)多智能體場(chǎng)景中往往涉及合作和競(jìng)爭(zhēng)并存的混合關(guān)系,這些模型只考慮了全局獎(jiǎng)勵(lì)或動(dòng)作值函數(shù)由所有智能體共同作用而成,卻沒有充分探究智能體之間的關(guān)系,不能區(qū)分合作和競(jìng)爭(zhēng)動(dòng)作,也就不能精準(zhǔn)地衡量各智能體對(duì)全局獎(jiǎng)勵(lì)的貢獻(xiàn)高低。
為提高強(qiáng)化學(xué)習(xí)方法在混合關(guān)系場(chǎng)景中的性能,本文針對(duì)多目標(biāo)多智能體場(chǎng)景,提出一種多目標(biāo)值分解強(qiáng)化學(xué)習(xí)方法MG-QMIX(Multi-Goal QMixer Network)。將智能體的目標(biāo)信息引入單調(diào)性值分解方法,提出并實(shí)現(xiàn)一種二級(jí)分解方法,在目標(biāo)完成度-智能體動(dòng)作值融合階段使用注意力機(jī)制分析智能體的群體影響力,并選取一些代表性的實(shí)驗(yàn)場(chǎng)景,使用MG-QMIX 和其他主流的多智能體強(qiáng)化學(xué)習(xí)方法分別訓(xùn)練各場(chǎng)景的智能體,以證明MGQMIX 方法在多目標(biāo)多智能體場(chǎng)景的有效性。
1 相關(guān)研究
文獻(xiàn)[2-6]主要研究一些具有離散狀態(tài)和動(dòng)作空間場(chǎng)景,這些較為簡(jiǎn)單的場(chǎng)景一般可以建模為單智能體的馬爾可夫最優(yōu)決策過程。其中的智能體可以獲得環(huán)境的全部狀態(tài)信息,并且環(huán)境的狀態(tài)轉(zhuǎn)移一般只受到智能體自身決策的影響,也即環(huán)境的狀態(tài)以及狀態(tài)的變換在智能體的角度看來是相對(duì)穩(wěn)定、可學(xué)習(xí)的,那么使用馬爾可夫過程建模是恰當(dāng)?shù)摹=诘难芯浚?-8]則逐漸將視角轉(zhuǎn)移到一些更復(fù)雜的場(chǎng)景上,這些場(chǎng)景具有更高維的信息和更復(fù)雜的智能體交互。
多智能體合作問題是當(dāng)前領(lǐng)域內(nèi)的熱點(diǎn)課題。在場(chǎng)景中,每個(gè)時(shí)刻都存在智能體與環(huán)境、智能體與智能體之間的交互。文獻(xiàn)[9]指出,為了獲得全局的成功,可以使用分布式智能體框架學(xué)習(xí)協(xié)作策略。但如果假設(shè)所有智能體相互獨(dú)立,在理論上可以直接對(duì)每個(gè)智能體應(yīng)用單智能體算法。這樣的假設(shè)讓每個(gè)智能體把其他智能體視作了環(huán)境的一部分,環(huán)境也就失去了穩(wěn)定性,不符合之前提到的馬爾可夫過程的建模前提,與單智能體強(qiáng)化學(xué)習(xí)方法相矛盾。但是在實(shí)際應(yīng)用中,這樣的方法有時(shí)也是可行的,文獻(xiàn)[2]提出的IQL 方法使用了Q-Learning 獨(dú)立地訓(xùn)練了每個(gè)智能體,文獻(xiàn)[7]在此基礎(chǔ)上運(yùn)用了文獻(xiàn)[10]提出的DQN(Deep Q-Network)模型。這種方法有著明顯的收斂問題,所以文獻(xiàn)[11-12]也針對(duì)性地提出了一些加速收斂的方法。
在理論上,集中式地學(xué)習(xí)各智能體的聯(lián)合動(dòng)作策略,既可以保證環(huán)境穩(wěn)定性,也可以從源頭實(shí)現(xiàn)合作的決策。但是集中式學(xué)習(xí)意味著聯(lián)合動(dòng)作空間會(huì)隨著智能體數(shù)量增長(zhǎng)呈指數(shù)增長(zhǎng),不易實(shí)現(xiàn)。文獻(xiàn)[13]提出了集中式學(xué)習(xí)的經(jīng)典方法Co-Graph(Coordination Graphs),將全局獎(jiǎng)勵(lì)函數(shù)分解為智能體局部項(xiàng)的總和。文獻(xiàn)[14]使用了一種拓?fù)涞腝-Learning 合作方法,它僅在需要決策的狀態(tài)下學(xué)習(xí)一組合作動(dòng)作,并將這些依賴項(xiàng)編碼在Co-Graph中。但上述方法都需要預(yù)先提供或?qū)W習(xí)智能體之間的依賴關(guān)系。
如果可以從環(huán)境中獲取每個(gè)智能體的個(gè)體回報(bào)值,就可以使用這個(gè)回報(bào)值作為個(gè)體對(duì)環(huán)境的貢獻(xiàn),那么以上提到的問題就可以使用貢獻(xiàn)分配方法來解決[15]。貢獻(xiàn)分配是指在復(fù)雜的學(xué)習(xí)系統(tǒng)中如何分配系統(tǒng)內(nèi)部成員對(duì)結(jié)果的貢獻(xiàn)。然而,文獻(xiàn)[16]指出,在完全合作的場(chǎng)景中,智能體只基于個(gè)體回報(bào)學(xué)習(xí)的策略不盡如人意,反而是基于其他智能體的回報(bào)學(xué)習(xí)的策略會(huì)實(shí)現(xiàn)得分更高的全局回報(bào)。因此,貢獻(xiàn)分配的依據(jù)不能只從個(gè)體回報(bào)值出發(fā),還需考慮到個(gè)體與環(huán)境、個(gè)體與個(gè)體之間的利害關(guān)系。
最近的研究則使用集中式學(xué)習(xí)、分布式執(zhí)行的結(jié)構(gòu)。文獻(xiàn)[17]提出的模型COMA(Counterfactual Multi-Agent Policy Gradients)使用集中式的評(píng)判網(wǎng)絡(luò)來評(píng)價(jià)分布式執(zhí)行的策略網(wǎng)絡(luò),為每個(gè)智能體估計(jì)了一個(gè)基于“反事實(shí)基線”的優(yōu)勢(shì)函數(shù),以解決多智能體貢獻(xiàn)分配問題。類似地,文獻(xiàn)[18]提出一種對(duì)應(yīng)于每個(gè)智能體的多評(píng)判網(wǎng)絡(luò)的集中式演員評(píng)論算法,該算法可以隨著智能體數(shù)量的增加而擴(kuò)展,但降低了集中式方法的優(yōu)勢(shì)。文獻(xiàn)[3]為每個(gè)智能體學(xué)習(xí)了一個(gè)集中的評(píng)判網(wǎng)絡(luò),并將其應(yīng)用于具有連續(xù)動(dòng)作空間的競(jìng)爭(zhēng)性游戲。這些方法使用策略梯度學(xué)習(xí)方法,樣本學(xué)習(xí)效率低,容易陷入次優(yōu)局部極小。
如果將全局目標(biāo)視作所有個(gè)體目標(biāo)的總和,那么可以使用值分解方法優(yōu)化集中式的評(píng)判函數(shù),同時(shí)保持分布式執(zhí)行。文獻(xiàn)[19]提出一種價(jià)值分解網(wǎng)絡(luò)(Value Decomposition Network,VDN),該網(wǎng)絡(luò)同樣使用了集中價(jià)值函數(shù)的學(xué)習(xí)和分散執(zhí)行的框架,將全局狀態(tài)動(dòng)作值函數(shù)視為每個(gè)智能體的動(dòng)作值的線性加和。這種方法類似退化的、完全斷開的協(xié)調(diào)圖,但該模型在訓(xùn)練期間不使用額外的全局狀態(tài)信息,沒有利用集中式學(xué)習(xí)的優(yōu)勢(shì),線性加和的分解形式對(duì)動(dòng)作值函數(shù)的刻畫能力也有限。文獻(xiàn)[5]提出的QMIX 方法針對(duì)上述問題,在分解中加入非線性度,并在集中式學(xué)習(xí)過程中使用全局狀態(tài)信息,提升了模型性能。但使用的單調(diào)性值分解方法仍然限制在完全合作的場(chǎng)景中,對(duì)具有混合關(guān)系的多目標(biāo)場(chǎng)景性能不佳。
對(duì)于智能體目標(biāo)存在差異的場(chǎng)景,雖然文獻(xiàn)[3]提出的MADDPG 和文獻(xiàn)[4]提出的M3DDPG 適用于具有不同獎(jiǎng)勵(lì)的智能體,但智能體從根本上無法區(qū)分合作和競(jìng)爭(zhēng)動(dòng)作,不能解決多目標(biāo)合作問題。文獻(xiàn)[20]提出一種多目標(biāo)多智能體強(qiáng)化學(xué)習(xí)方法,并分析了完全分布式訓(xùn)練網(wǎng)絡(luò)的收斂性。文獻(xiàn)[1]設(shè)計(jì)的CM3(Cooperative Multi-Goal Multi-Stage Multi-Agent Reinforcement Learning)模型類比動(dòng)作值方程,提出一種目標(biāo)-動(dòng)作值方程,根據(jù)該方程實(shí)現(xiàn)了一種多目標(biāo)多智能體貢獻(xiàn)分配方法,并使用了分散執(zhí)行、集中訓(xùn)練框架[21]。盡管這些方法或多或少地考慮到了智能體的目標(biāo)差異,但它們的貢獻(xiàn)分配仍然是以智能體個(gè)體回報(bào)或個(gè)體目標(biāo)為依據(jù)的。如何在不穩(wěn)定的環(huán)境狀態(tài)下評(píng)估每個(gè)智能體對(duì)于環(huán)境及其他智能體的影響,是多目標(biāo)多智能體合作場(chǎng)景的一大難題。
2 數(shù)學(xué)背景
2.1 多目標(biāo)馬爾可夫決策過程
類比于一般的馬爾可夫決策過程以及狀態(tài)部分可觀測(cè)的馬爾科夫決策過程[22],本文將多目標(biāo)多智能體強(qiáng)化學(xué)習(xí)場(chǎng)景建模為多目標(biāo)馬爾可夫決策過程[1]。每個(gè)智能體基于有限的觀測(cè)值和源于一個(gè)有限集合的目標(biāo)獨(dú)立決策,總體上與其他智能體相互合作獲得全局的成功。多目標(biāo)馬爾可夫決策過程可以用式(1)的元組描述:

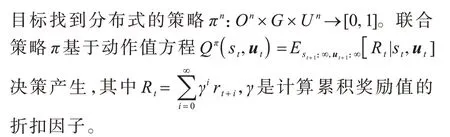
建模以狀態(tài)部分可觀測(cè)為前提,即每個(gè)智能體會(huì)根據(jù)一個(gè)觀測(cè)方程得到個(gè)體觀測(cè)值,再合并該智能體的歷史決策動(dòng)作序列,兩者記為τ∈(O×U)。
本文模型采用集中式學(xué)習(xí)分布式執(zhí)行的網(wǎng)絡(luò)結(jié)構(gòu)。該網(wǎng)絡(luò)結(jié)構(gòu)一般由集中式的評(píng)判網(wǎng)絡(luò)和分布式的策略網(wǎng)絡(luò)構(gòu)成。評(píng)判網(wǎng)絡(luò)可以使用完整的全局動(dòng)作、狀態(tài)信息以加快訓(xùn)練收斂速度,但是策略網(wǎng)絡(luò)只能使用智能體的自身局部信息,以還原真實(shí)場(chǎng)景的限制因素。
2.2 主要模型
文獻(xiàn)[10]提出的深度Q 網(wǎng)絡(luò)(DQN)方法通過神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)Q-Learning 中的動(dòng)作價(jià)值函數(shù),并且使用了經(jīng)驗(yàn)回放池策略和target 網(wǎng)絡(luò)軟更新策略。經(jīng)驗(yàn)回放池策略可以減弱樣本之間的相關(guān)性,具體操作是將歷史的環(huán)境交互<s,u,r,s′>存入緩存池中,其中s′是采取動(dòng)作u后的轉(zhuǎn)移狀態(tài)。模型在訓(xùn)練過程中使用從緩存池中采樣的若干批次數(shù)據(jù)樣本,通過最小化式(2)的TD(Time Difference)誤差函數(shù)來學(xué)習(xí)最優(yōu)策略。
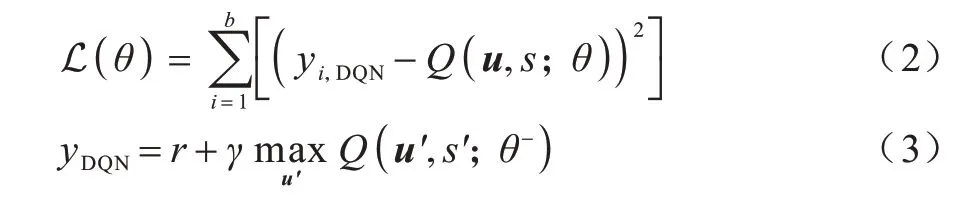
式(3)中的yDQN是基于target 網(wǎng)絡(luò)生成的動(dòng)作值,θ-是該網(wǎng)絡(luò)參數(shù)。基于target 網(wǎng)絡(luò)的更新方式將target 網(wǎng)絡(luò)擬合的動(dòng)作值作為“真實(shí)”值,相較于一般的更新方式,參數(shù)更新更加平滑,提升了收斂性能,可稱為軟更新。
在部分可觀測(cè)的前提下,智能體往往能從一些歷史動(dòng)作和觀測(cè)信息中學(xué)習(xí)到更多的特征。文獻(xiàn)[23]提出的DRQN(Deep Recurrent Q-Learning Network)利用RNN(Recurrent Neural Networks)[24]試圖從歷史信息中提取特征。在一些時(shí)間序列較長(zhǎng)的場(chǎng)景中可以使用文獻(xiàn)[25]提出的LSTM(Long Short-Term Memory)或文獻(xiàn)[26]提出的GRU(Gated Recurrent Units)網(wǎng)絡(luò)。
文獻(xiàn)[19]提出的VDN 通過使用值分解方法優(yōu)化集中式的動(dòng)作值函數(shù),同時(shí)使用分布式執(zhí)行的框架。該方法將全局目標(biāo)視作所有個(gè)體目標(biāo)的總和,學(xué)習(xí)式(4)的聯(lián)合動(dòng)作值函數(shù)。
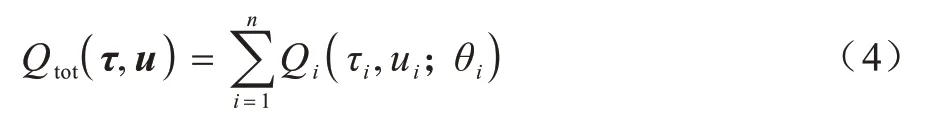
聯(lián)合動(dòng)作值是每個(gè)智能體的動(dòng)作值的總和。狀態(tài)部分可觀測(cè)和分布式執(zhí)行框架要求每個(gè)智能體的動(dòng)作值只依賴于其個(gè)人的動(dòng)作與觀測(cè)值的歷史序列。
VDN 的值分解采用了線性加和的方式,這樣的分解形式使其使用場(chǎng)景有著極大的限制。文獻(xiàn)[5]提出的QMIX 為解決該問題,在分解過程中引入了非線性成分。具體是用一個(gè)融合網(wǎng)絡(luò)將各智能體的動(dòng)作值融合為全局動(dòng)作值,將非線性度引入融合過程,聯(lián)合動(dòng)作值函數(shù)如式(5)所示:
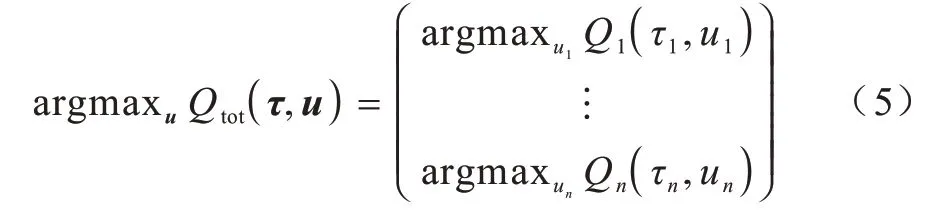
注意力機(jī)制經(jīng)常用來提取輸入特征中的關(guān)鍵信息,有很多不同的變種和可選的網(wǎng)絡(luò)形式。鍵值對(duì)注意力機(jī)制用鍵值對(duì)格式來表示輸入信息,其中,“鍵”用來計(jì)算注意力分布,“值”用來生成選擇的信息。多頭注意力是利用多個(gè)查詢來平行地計(jì)算從輸入信息中選取多個(gè)信息。每個(gè)注意力關(guān)注輸入信息的不同部分,硬注意力即基于注意力分布的所有輸入信息的期望,結(jié)構(gòu)化注意力要從輸入信息中選取出和任務(wù)相關(guān)的信息,主動(dòng)注意力是在所有輸入信息上的多項(xiàng)分布,是一種扁平結(jié)構(gòu)。如果輸入信息本身具有層次結(jié)構(gòu),比如文本分為詞、句子、段落、篇章等不同粒度的層次,可以使用層次化的注意力來進(jìn)行更好的信息選擇。此外,還可以假設(shè)注意力上下文相關(guān)的兩項(xiàng)分布,用一種圖模型來構(gòu)建更復(fù)雜的結(jié)構(gòu)化注意力分布。
3 MG-QMIX 方法
3.1 融合機(jī)制
本文提出一種基于QMIX 和注意力機(jī)制的多目標(biāo)注意力動(dòng)作值分解與融合的方法MG-QMIX。該方法相比于QMIX,加入了目標(biāo)信息,擴(kuò)展了動(dòng)作值方程的擬合方式,并使用注意力機(jī)制分析智能體群體影響力,提升模型對(duì)復(fù)雜的多智能體交互關(guān)系的理解能力與動(dòng)作值估計(jì)的精度。
將環(huán)境各智能體的目標(biāo)信息引入到動(dòng)作值函數(shù)和融合過程中,是本文模型的關(guān)鍵思想之一,也是模型能夠應(yīng)對(duì)更為復(fù)雜的多智能體場(chǎng)景關(guān)系的數(shù)據(jù)基礎(chǔ)。基于值分解方法的多智能體強(qiáng)化學(xué)習(xí)模型,從VDN 到QMIX,基本是以全局的獎(jiǎng)勵(lì)可以視作所有個(gè)體貢獻(xiàn)價(jià)值的總和為前提的,這樣的前提從根本上忽略了各智能體之間的相互影響。所以,QMIX可以在一些完全合作的場(chǎng)景中發(fā)揮作用,但在一些涉及多智能體協(xié)作與利益沖突并存的混合關(guān)系場(chǎng)景中性能受限。
本文的值分解方法可以分為動(dòng)作值融合和多目標(biāo)融合兩個(gè)階段。在一個(gè)時(shí)刻下,多目標(biāo)融合是將所有智能體目標(biāo)完成程度融合為全局的回報(bào)值Qtot,如式(6)所示:
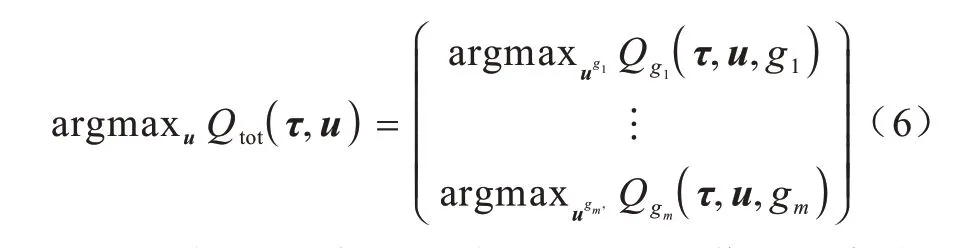
一個(gè)目標(biāo)gi的完成程度可以視作所有智能體對(duì)這一目標(biāo)貢獻(xiàn)的融合,也即動(dòng)作值融合,如式(7)所示:
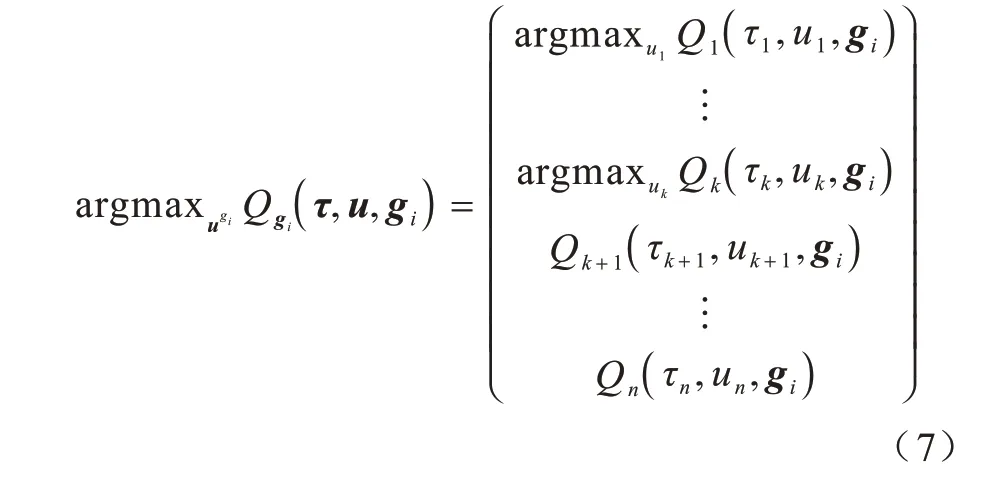
其中:Q1~Qk代表以gi為目標(biāo)的智能體(下文稱為主體智能體)的動(dòng)作值;Qk+1~Qn則是其余的智能體(下文稱為他體智能體)的動(dòng)作值;τj、uj分別表示相應(yīng)智能體的動(dòng)作-觀測(cè)值歷史紀(jì)錄和當(dāng)前時(shí)刻決策動(dòng)作,滿足uj∈,?j=1,2,…,k。
這樣的區(qū)分主要是因?yàn)橐粋€(gè)智能體aj只需根據(jù)自身目標(biāo)gi,依據(jù)貪心策略選取使Qj(τj,uj,gi)值最大的動(dòng)作決策,然后再用這個(gè)決策動(dòng)作計(jì)算其他目標(biāo)下的動(dòng)作值,所以式(7)中的Qk+1~Qn并不涉及最大值選擇。這也意味著一個(gè)智能體在策略決策階段只需要自己的歷史紀(jì)錄和觀測(cè)信息,不需要全局的狀態(tài),保證了分布式?jīng)Q策執(zhí)行的框架實(shí)現(xiàn)。但同時(shí),使用到的貪心策略要求模型必須采用離線學(xué)習(xí)方式。
另外,為了限制分解關(guān)系的單調(diào)性,需要滿足式(8):

文獻(xiàn)[27]證明了這樣的限制條件允許融合網(wǎng)絡(luò)擬合某種單調(diào)函數(shù)。需要注意的是,單調(diào)性在融合過程中是局部的,只在多目標(biāo)融合階段體現(xiàn)。在動(dòng)作值融合階段,不同目標(biāo)的智能體之間需要考慮到競(jìng)爭(zhēng)關(guān)系的影響,那么對(duì)于融合過程中的他體智能體,其影響權(quán)重的正負(fù)應(yīng)由該智能體的群體影響力決定。所謂的群體影響力是指他體智能體的決策趨勢(shì)是否會(huì)對(duì)主體智能體基于自身目標(biāo)的最優(yōu)決策產(chǎn)生正面或負(fù)面的影響,以及影響的大小,可以從主體智能體狀態(tài)smain和所有智能體全局狀態(tài)s的比較分析中計(jì)算得出。目標(biāo)信息和群體影響力兩者的作用是相輔相成的,群體影響力的生成需要借助目標(biāo)信息,而由目標(biāo)信息引入的第一階段的融合需要群體影響力引導(dǎo)生成融合權(quán)重。
在多目標(biāo)融合階段,各目標(biāo)完成程度對(duì)于全局的回報(bào)值Qtot的貢獻(xiàn)則可以通過全局狀態(tài)s分析計(jì)算得出。
3.2 神經(jīng)網(wǎng)絡(luò)模型的實(shí)現(xiàn)
上述的QMIX等分解方法由圖1所示的MG-QMIX模型實(shí)現(xiàn),模型由策略網(wǎng)絡(luò)和融合網(wǎng)絡(luò)兩部分構(gòu)成。
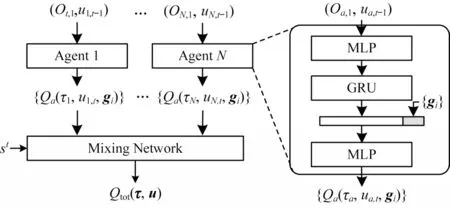
圖1 MG-QMIX 模型結(jié)構(gòu)Fig.1 Structure of MG-QMIX model
一個(gè)策略網(wǎng)絡(luò)學(xué)習(xí)了一個(gè)智能體a的多目標(biāo)動(dòng)作值函數(shù){Qa(τa,·,gi)|i=1,2,…,m}。如圖1 所示,網(wǎng)絡(luò)采用DRQN 結(jié)構(gòu),以智能體當(dāng)前時(shí)刻觀測(cè)值oa,t和上一時(shí)刻歷史動(dòng)作ua,t-1為輸入,輸出的中間特征za,t與不同的目標(biāo)向量{gi|i=1,2,…,m}結(jié)合后通過后續(xù)的全連接層生成對(duì)應(yīng)目標(biāo)下的動(dòng)作值{Qa(τa,·,gi)|i=1,2,…,m}。智能體會(huì)基于自身目標(biāo)ga下的動(dòng)作值Qa(τa,·,ga),以貪心策略選取使動(dòng)作值最大的動(dòng)作ua,t,并輸出最優(yōu)動(dòng)作下的多目標(biāo)動(dòng)作值{Qa(τa,ua,t,gi)|i=1,2,…,m}。需要指出的是,在訓(xùn)練過程中,智能體并不會(huì)直接選擇最優(yōu)動(dòng)作ua,t,而是以一個(gè)自適應(yīng)的?概率選擇隨機(jī)動(dòng)作,目的是增強(qiáng)訓(xùn)練過程中策略的探索能力。
具有注意力的超網(wǎng)絡(luò)為融合過程提供相應(yīng)的融合權(quán)重和偏置,如圖2 所示。因?yàn)榭紤]到無論在動(dòng)作值融合階段還是多目標(biāo)融合階段,融合方程的非線性度并不強(qiáng),融合關(guān)系是有跡可循的,所以沒有直接用融合網(wǎng)絡(luò)完成兩階段的融合過程。另外,如果直接將全局狀態(tài)s和策略網(wǎng)絡(luò)輸出的多目標(biāo)動(dòng)作值交由一個(gè)神經(jīng)網(wǎng)絡(luò)處理,無疑會(huì)增加學(xué)習(xí)難度,甚至出現(xiàn)欠擬合的情況,故而選擇借助超網(wǎng)絡(luò)生成融合參數(shù)。超網(wǎng)絡(luò)可以使用神經(jīng)網(wǎng)絡(luò)處理狀態(tài)信息并輸出相應(yīng)的融合參數(shù),可以對(duì)融合參數(shù)選擇性地做一些額外處理,比如通過絕對(duì)值激活實(shí)現(xiàn)單調(diào)性限制,或者在融合中加入線性成分。
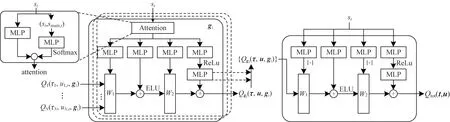
圖2 融合網(wǎng)絡(luò)框架Fig.2 Framework of converged network
在動(dòng)作值融合階段,融合參數(shù)需要衡量主體智能體和他體智能體對(duì)融合目標(biāo)的影響,MG-QMIX模型采用注意力機(jī)制。如3.1 節(jié)所述,群體影響力是指他體智能體的決策趨勢(shì)是否會(huì)對(duì)主體智能體基于自身目標(biāo)的最優(yōu)決策產(chǎn)生正面或負(fù)面的影響,以及影響的大小。全局狀態(tài)包含了所有智能體的當(dāng)前狀態(tài)(包含目標(biāo))和環(huán)境狀態(tài),狀態(tài)和目標(biāo)信息其實(shí)也蘊(yùn)含了智能體在整體環(huán)境中所處地位、決策趨勢(shì)等關(guān)鍵信息,將主體智能體狀態(tài)與全局狀態(tài)各部分作比較分析,在理論上可以評(píng)估每個(gè)他體智能體對(duì)于主體智能體決策的影響。注意力機(jī)制經(jīng)常用來提取輸入特征中的關(guān)鍵信息。群體影響力可以看作依據(jù)主體智能體的狀態(tài),提取全局狀態(tài)中的對(duì)主體智能體行動(dòng)影響較大的部分,以相關(guān)性權(quán)重輸出。在合成過程中,大小不一的權(quán)重表示了各智能體對(duì)當(dāng)前目標(biāo)的貢獻(xiàn)程度。與鍵值對(duì)注意力機(jī)制相吻合,全局狀態(tài)和主體智能體狀態(tài)分別視作“鍵”和“值”,用鍵值對(duì)格式來表示輸入信息,其中“鍵”用來計(jì)算注意力分布,“值”用來生成選擇的信息。融合網(wǎng)絡(luò)對(duì)比了主體智能體狀態(tài)smain和所有智能體全局狀態(tài)s之間的關(guān)聯(lián)程度,如式(9)所示計(jì)算得到aattention向量:
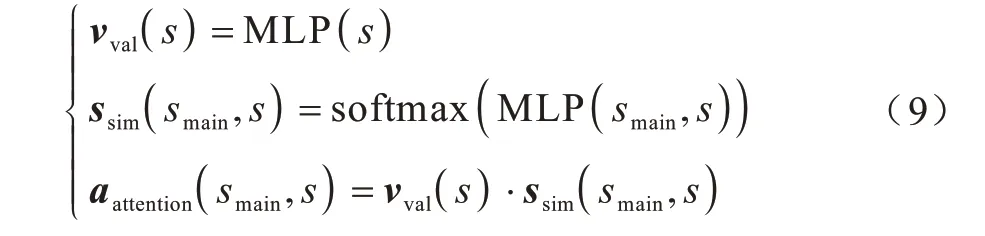
然后利用aattention計(jì)算權(quán)重和偏置,模型使用了兩對(duì)參數(shù)(W11,b11)、(W12,b12)提高融合刻畫能力和精度。如式(10)所示,將aattention分別輸入到一個(gè)全連接層得到這些參數(shù),b12需要額外經(jīng)過一層ReLu 激活函數(shù)和另一層全連接層。

之后利用這組參數(shù)完成各目標(biāo)下動(dòng)作值{Qa(τa,ua,t,gi)|i=1,2,…,m,a=1,2,…,n}到目標(biāo)完成度的融合。為引入一定的非線性度,第1 組參數(shù)計(jì)算的結(jié)果經(jīng)過一層ELU 激活函數(shù),再利用第2 組參數(shù)計(jì)算得到最終的目標(biāo)完成度,如式(11)所示:
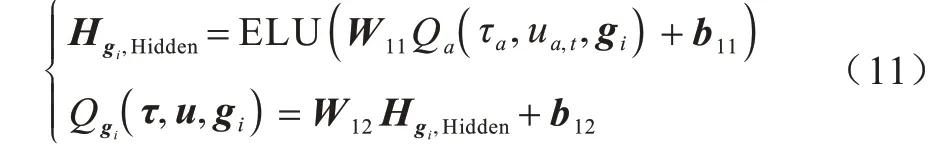
在多目標(biāo)融合階段,融合參數(shù)(W21,b21)、(W22,b22)直接由全局狀態(tài)s生成,計(jì)算方式與第1 階段相似,但是需要額外滿足單調(diào)性要求,所以對(duì)兩個(gè)權(quán)重取絕對(duì)值激活,如式(12)所示:

類似地,模型利用這組參數(shù)完成各目標(biāo)完成度{Qgi(τ,u,gi)|i=1,2,…,m}到全局的回報(bào)值Qtot(τ,u)的融合,如式(13)所示:
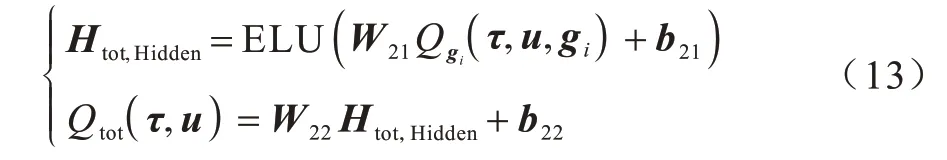
模型整體是端到端訓(xùn)練的,最小化如式(14)所示的損失函數(shù):

算法1MG-QMIX 算法


4 實(shí)驗(yàn)設(shè)置
4.1 實(shí)驗(yàn)環(huán)境
為驗(yàn)證本文模型的性能效果和魯棒性,在一些具有離散動(dòng)作狀態(tài)場(chǎng)景上進(jìn)行數(shù)組實(shí)驗(yàn)。第1 部分是在單目標(biāo)、純粹合作場(chǎng)景星際爭(zhēng)霸2 平臺(tái)選取若干個(gè)對(duì)抗模式,訓(xùn)練紅方多個(gè)單位對(duì)抗電腦固定策略,主要是驗(yàn)證本文模型是否保留了QMIX 模型對(duì)于合作關(guān)系的學(xué)習(xí)能力;第2 部分是一些多目標(biāo)、混合關(guān)系場(chǎng)景,選取了checker、多粒子導(dǎo)航場(chǎng)景,主要是驗(yàn)證本文模型在多目標(biāo)混合場(chǎng)景中的性能。
4.1.1 星際爭(zhēng)霸2
強(qiáng)化學(xué)習(xí)領(lǐng)域常使用即時(shí)策略游戲作為實(shí)驗(yàn)平臺(tái),星際爭(zhēng)霸2 是目前最常使用的即時(shí)策略游戲平臺(tái)之一。通過對(duì)地圖、部隊(duì)兵種等的設(shè)置,可以滿足合作、競(jìng)爭(zhēng)、多智能等多種環(huán)境需求。游戲中的作戰(zhàn)單位擁有龐大且復(fù)雜的微觀動(dòng)作空間,多個(gè)智能體的環(huán)境交互也足夠復(fù)雜。本文選取了由文獻(xiàn)[29]提出的星際爭(zhēng)霸2 微觀操控平臺(tái)作為本文的實(shí)驗(yàn)平臺(tái)。
具體地,本文使用該平臺(tái)的一些分布式微觀操控場(chǎng)景。場(chǎng)景中有紅藍(lán)兩方隊(duì)伍,通過操控紅方的各個(gè)作戰(zhàn)單位與藍(lán)方對(duì)抗攻擊。按照模型的分布式策略方法,每個(gè)智能體操控紅方中的一個(gè)單位。場(chǎng)景中所有單位無論歸屬紅藍(lán)何方,其兵種決定了它的動(dòng)作空間和狀態(tài)屬性,即同一個(gè)種類的單位具有一樣的動(dòng)作和狀態(tài)。藍(lán)方的隊(duì)伍的單位數(shù)量和單位種類與紅方保持一致,并且由平臺(tái)的AI 策略操控,共有7 種難度等級(jí),由低到高代表了藍(lán)方AI 的智能等級(jí)從低到高,本文選取了等級(jí)3 的難度。具體場(chǎng)景包含“3 個(gè)槍手(3m)”“8 個(gè)槍手(8m)”和“2 個(gè)獵人3 個(gè)狂熱者(2s3z)”,以上均為游戲內(nèi)的作戰(zhàn)單位種類名稱。
環(huán)境建模方面類似于文獻(xiàn)[17]的實(shí)驗(yàn)部分。智能體微觀動(dòng)作操控可以概括為移動(dòng)-攻擊模式。每個(gè)智能體的動(dòng)作包含移動(dòng)、攻擊、停止和無動(dòng)作。其中,移動(dòng)動(dòng)作需要給出東南西北四個(gè)方向之一的參數(shù),攻擊動(dòng)作需要給出在其攻擊范圍內(nèi)的敵方單位編號(hào)。需要注意的是,場(chǎng)景并不會(huì)讓智能體自動(dòng)攻擊范圍內(nèi)的敵方單位,而是強(qiáng)迫智能體學(xué)習(xí)攻擊策略,自行選擇攻擊的對(duì)象和時(shí)機(jī)。環(huán)境的狀態(tài)空間對(duì)于每個(gè)智能體是部分可觀測(cè)的,其狀態(tài)觀測(cè)值取決于智能體的視力范圍。對(duì)于視力范圍之外的單位,無論是友方還是敵方,智能體都無法知曉其任何狀態(tài)。環(huán)境的獎(jiǎng)勵(lì)值由我方造成傷害和敵方傷亡情況兩部分構(gòu)成。每個(gè)回合,我方造成的傷害值的總和作為獎(jiǎng)勵(lì)的第1 個(gè)部分;如果當(dāng)前回合造成一名敵方陣亡,則有10 得分,如果使得全部敵方陣亡還會(huì)額外獲得200 得分,這是獎(jiǎng)勵(lì)值的第2 個(gè)部分。每個(gè)回合的獎(jiǎng)勵(lì)值都會(huì)歸一化得到一個(gè)0~20 范圍的分值。
與原平臺(tái)不同,本文模型需要一個(gè)目標(biāo)信息來表示每個(gè)智能體的關(guān)注點(diǎn)。在星際爭(zhēng)霸2 平臺(tái)上,由于我方的每個(gè)單位的目標(biāo)都是統(tǒng)一的對(duì)抗敵方,不存在內(nèi)部的資源等的競(jìng)爭(zhēng),因此是一個(gè)單純合作的場(chǎng)景。實(shí)驗(yàn)中將所有智能體的目標(biāo)都設(shè)置為同一個(gè)特征向量,即單目標(biāo)場(chǎng)景。這組實(shí)驗(yàn)的目的也是為了與QMIX 表現(xiàn)較好的實(shí)驗(yàn)平臺(tái)上做直觀的對(duì)比。
4.1.2 棋盤游戲
棋盤游戲環(huán)境來自文獻(xiàn)[1],是一種目標(biāo)信息比較關(guān)鍵的場(chǎng)景。如圖3 所示,場(chǎng)景包含兩個(gè)智能體,要在分布著紅藍(lán)點(diǎn)的棋盤上移動(dòng),每次只能移動(dòng)一格,且不能移動(dòng)到棋盤外或者被其他智能體占領(lǐng)的棋盤格。每當(dāng)一個(gè)智能體移動(dòng)到一個(gè)具有紅點(diǎn)或者藍(lán)點(diǎn)的格子上時(shí),便會(huì)吃掉該點(diǎn)并獲得相應(yīng)的得分,但是其中一個(gè)智能體吃掉紅點(diǎn)會(huì)獲得更多的得分,另一個(gè)智能體則是吃掉藍(lán)點(diǎn)會(huì)獲得更多的得分。場(chǎng)景的總體獎(jiǎng)勵(lì)由兩方得分的和構(gòu)成。所以,若要獲得盡可能高的總體得分,兩智能體需要相互配合,盡可能只吃自己獲益更多的得分點(diǎn),并且要為另一個(gè)智能體向目標(biāo)點(diǎn)移動(dòng)清除途中的低分障礙。場(chǎng)景的狀態(tài)同樣是部分可觀測(cè)的,一個(gè)智能體只能獲取自身的狀態(tài)信息和周圍指定格數(shù)的棋盤信息,以及視野內(nèi)的另一智能體位置信息。

圖3 棋盤游戲樣式Fig.3 Board game style
4.1.3 多粒子運(yùn)動(dòng)環(huán)境
多粒子環(huán)境由文獻(xiàn)[8]提出,可以在二維空間中模擬操控具有碰撞體積的粒子上下左右移動(dòng),并根據(jù)不同的任務(wù)目標(biāo)設(shè)立了一系列的地圖。本文使用了變道(merge)和交叉(cross)兩種地圖,如圖4 所示。較大的粒子代表粒子的初始位置,同花紋的較小粒子代表了操控該粒子移動(dòng)的期望目標(biāo)位置。不同的粒子由不同的智能體策略操控,動(dòng)作空間共有上下左右四個(gè)固定速度的移動(dòng)和停止等指令,環(huán)境同樣是狀態(tài)部分可觀測(cè)的,各智能體的觀測(cè)狀態(tài)包括自身的位置、運(yùn)動(dòng)和目標(biāo)信息,以及觀測(cè)范圍的其他粒子的位置信息。場(chǎng)景的總體獎(jiǎng)勵(lì)反饋分為兩部分:一部分是根據(jù)每個(gè)智能體相對(duì)于目標(biāo)位置的距離設(shè)定的,為一個(gè)負(fù)值;另一部分是根據(jù)粒子之間的碰撞次數(shù)生成的懲罰。因此,整體的獎(jiǎng)勵(lì)值始終是負(fù)數(shù),值越大代表策略性能越好。
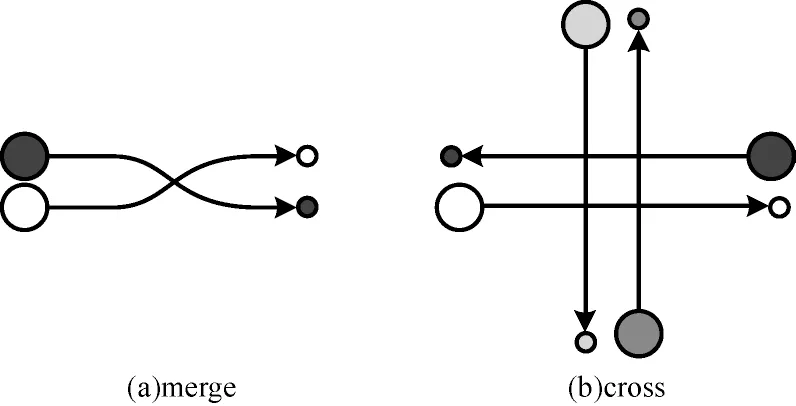
圖4 多粒子運(yùn)動(dòng)環(huán)境Fig.4 Multi-particle motion environment
4.1.4 目標(biāo)信息設(shè)置
在各個(gè)場(chǎng)景中,目標(biāo)信息的形式可以分為兩種:一是與環(huán)境狀態(tài)相關(guān)的特征量,比如位置、ID 標(biāo)識(shí)、速度等;二是抽象為獨(dú)熱編碼形式。在星際爭(zhēng)霸2的各地圖中,所有智能體的目標(biāo)是相同的,所以用“1”指代,這是因?yàn)檫@部分實(shí)驗(yàn)設(shè)置是為了驗(yàn)證本文模型是否保留了QMIX 模型對(duì)合作關(guān)系的學(xué)習(xí)能力。在棋盤場(chǎng)景中,兩個(gè)智能體分別對(duì)紅藍(lán)點(diǎn)敏感,所以其目標(biāo)設(shè)置為二維的獨(dú)熱編碼“01”和“10”。在多粒子運(yùn)動(dòng)場(chǎng)景中,每個(gè)智能體要從起始位置移動(dòng)到終點(diǎn)位置,所以目標(biāo)信息可以設(shè)置為終點(diǎn)位置的二維坐標(biāo)數(shù)據(jù)。
4.2 消融實(shí)驗(yàn)
為驗(yàn)證本文方法和模型使用的幾種關(guān)鍵技術(shù)對(duì)模型性能的影響,在實(shí)驗(yàn)設(shè)置中加入了兩組消融實(shí)驗(yàn)。
首先,在融合網(wǎng)絡(luò)中,模型使用ReLU、ELU 等激活函數(shù)實(shí)現(xiàn)非線性的值融合。在理論上,場(chǎng)景中各智能體對(duì)于各目標(biāo)的貢獻(xiàn),以及各目標(biāo)對(duì)全局動(dòng)作值的貢獻(xiàn)分配是較復(fù)雜的映射關(guān)系,非線性的擬合方式在理論上會(huì)提升網(wǎng)絡(luò)對(duì)于各變量之間的關(guān)系的刻畫能力。因此,基于線性融合方式的模型可以作為一組消融實(shí)驗(yàn),即去掉原模型的融合網(wǎng)絡(luò)中的非線性激活函數(shù),并在多粒子運(yùn)動(dòng)環(huán)境中的merge 地圖上訓(xùn)練該模型。
其次,在動(dòng)作值融合階段,模型使用注意力機(jī)制學(xué)習(xí)智能體的群體影響力,為后續(xù)的融合參數(shù)的生成提供了更為豐富的特征信息。為證明注意力機(jī)制對(duì)于動(dòng)作值融合階段的關(guān)鍵性作用,不使用注意力機(jī)制的模型作為另一組消融實(shí)驗(yàn),即在值融合網(wǎng)絡(luò)的第一階段中,全局狀態(tài)st不經(jīng)過注意力模塊,直接作為超網(wǎng)絡(luò)的輸入。同樣地,這組消融實(shí)驗(yàn)也在多粒子運(yùn)動(dòng)環(huán)境中的merge 地圖上訓(xùn)練了該模型。
5 實(shí)驗(yàn)結(jié)果與分析
為了驗(yàn)證MG-QMIX 的各種性能,本文在星際爭(zhēng)霸2 微觀操控平臺(tái)、棋盤游戲和多粒子運(yùn)動(dòng)環(huán)境分別訓(xùn)練、測(cè)試了模型,并將結(jié)果與文獻(xiàn)[5]提出的QMIX 模型和文獻(xiàn)[17]提出的COMA 模型進(jìn)行對(duì)比。在每個(gè)場(chǎng)景中,每種模型獨(dú)立訓(xùn)練10 次,圖5 所示的訓(xùn)練曲線是10 次獨(dú)立訓(xùn)練的平均值結(jié)果,每種模型訓(xùn)練完成后的100 局測(cè)試實(shí)驗(yàn)的平均得分如表1 所示(粗體表示結(jié)果最優(yōu))。從綜合結(jié)果可以看出:本文模型在星際爭(zhēng)霸2 這樣的單純合作場(chǎng)景中與QMIX 的得分持平,比COMA 性能更好;在具有混合關(guān)系的場(chǎng)景中,MG-QMIX 得分最高,性能優(yōu)于QMIX 與COMA。
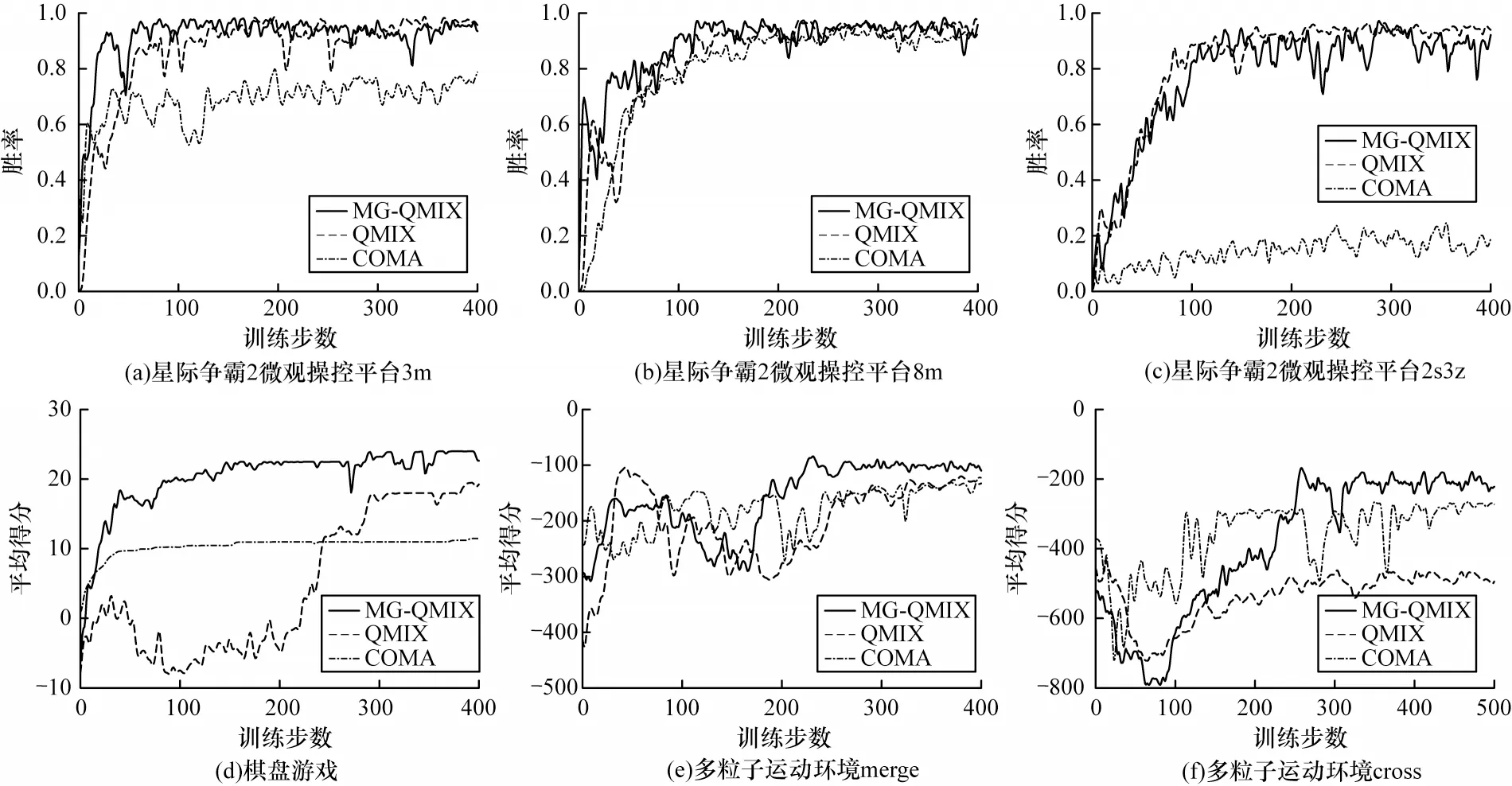
圖5 3 種模型在各場(chǎng)景的訓(xùn)練得分曲線Fig.5 Training score curves of the three models in each scenarios
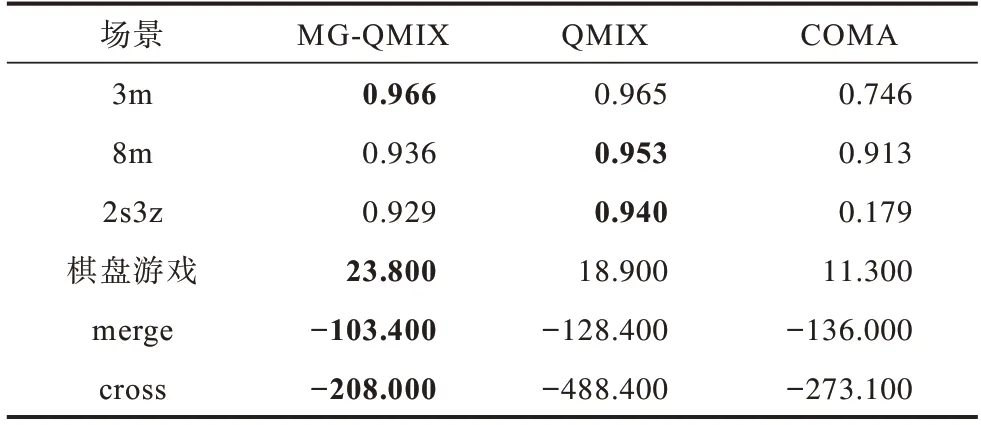
表1 3 種模型在各場(chǎng)景中的測(cè)試平均得分Table 1 Average test scores of the three models in each scenarios
5.1 結(jié)果分析
在星際爭(zhēng)霸2 微觀操控平臺(tái)中,由于我方每個(gè)單位的目標(biāo)都是統(tǒng)一的對(duì)抗敵方,不存在內(nèi)部資源的競(jìng)爭(zhēng),因此是一個(gè)單純合作的場(chǎng)景。實(shí)驗(yàn)中將所有智能體的目標(biāo)都設(shè)置為同一個(gè)特征向量,也就是單目標(biāo)場(chǎng)景。QMIX 模型是目前在該平臺(tái)性能最好的強(qiáng)化學(xué)習(xí)模型之一。各模型訓(xùn)練超參數(shù)設(shè)置如表2 所示,在3m、8m、2s3z 地圖的勝率對(duì)比結(jié)果見圖5。在智能體構(gòu)成較為簡(jiǎn)單的3m、8m 地圖中,MG-QMIX 和QMIX 模型都表現(xiàn)出較好的性能,兩者勝率基本持平。在智能體數(shù)量略多的8m 地圖中,各模型的策略穩(wěn)定性相比3m 地圖有所降低。COMA模型在兩個(gè)地圖中勝率略差一些。在智能體種類有較大的差異的2s3z 地圖中,COMA 模型無法學(xué)習(xí)得到一個(gè)成功的模型。MG-QMIX 和QMIX 仍有較好的表現(xiàn),穩(wěn)定性上QMIX 更好一些,因?yàn)镸G-QMIX的網(wǎng)絡(luò)要比QMIX 更為復(fù)雜。
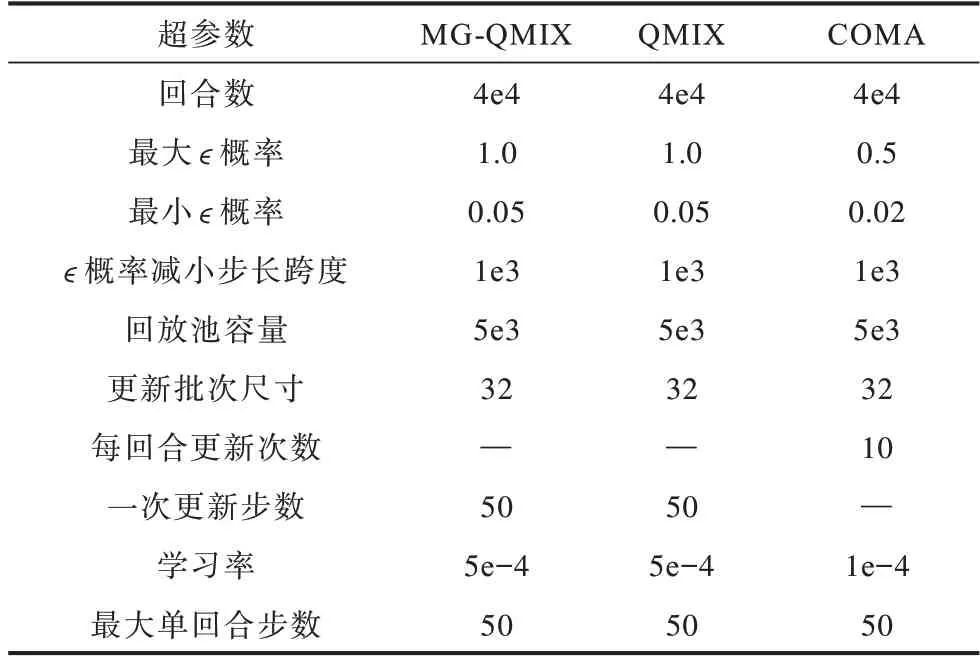
表2 各模型在星際爭(zhēng)霸2 微觀操控平臺(tái)中的訓(xùn)練超參數(shù)Table 2 The training hyper parameters of each models in the StarCraft 2 micro-control platform
星際爭(zhēng)霸2 平臺(tái)的實(shí)驗(yàn)結(jié)果表明,MG-QMIX 相比QMIX 使用的目標(biāo)主導(dǎo)的值分解方法對(duì)于多智能體合作場(chǎng)景依舊適用,且有優(yōu)秀表現(xiàn)。
在棋盤游戲中,各模型訓(xùn)練超參數(shù)設(shè)置如表3所示,3 種模型的得分對(duì)比結(jié)果見圖5。MG-QMIX在訓(xùn)練中學(xué)習(xí)到了最高24 分的策略,而QMIX 和COMA 模型不能在10 次獨(dú)立訓(xùn)練中每次都學(xué)習(xí)到最優(yōu)策略。實(shí)驗(yàn)結(jié)果表明了MG-QMIX 在處理混合關(guān)系的多目標(biāo)多智能體合作場(chǎng)景中的優(yōu)勢(shì),可以有效利用各智能體目標(biāo)信息獲得更優(yōu)的全局成功。
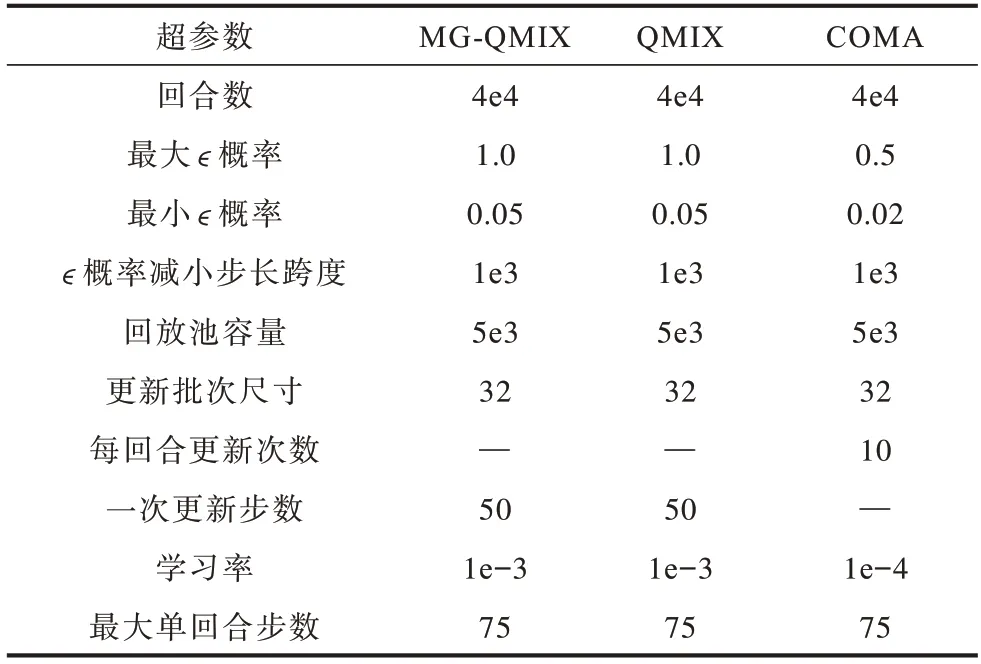
表3 各模型在棋盤游戲中的訓(xùn)練超參數(shù)Table 3 Training hyper parameters of each models in board game
在多粒子運(yùn)動(dòng)環(huán)境中,各模型訓(xùn)練超參數(shù)設(shè)置如表4 所示,由于cross 地圖的環(huán)境更為復(fù)雜,為得到更直觀的結(jié)果,延長(zhǎng)了訓(xùn)練回合數(shù)。各模型在merge和cross 地圖上的得分比較結(jié)果見圖5。在較為簡(jiǎn)單的merge 地圖中,3 種模型都學(xué)習(xí)到了較高得分的穩(wěn)定策略,MG-QMIX 的得分最高,并且收斂速度也是最快的。在更為復(fù)雜的cross 地圖中,COMA 模型的得分表現(xiàn)較差,QMIX 模型得分略好但穩(wěn)定性較差,MG-QMIX 在得分和穩(wěn)定性方面都是表現(xiàn)最好的。實(shí)驗(yàn)結(jié)果體現(xiàn)了MG-QMIX 模型基于目標(biāo)和注意力機(jī)制的值分解方法可以更好地應(yīng)對(duì)多目標(biāo)多智能體合作場(chǎng)景。
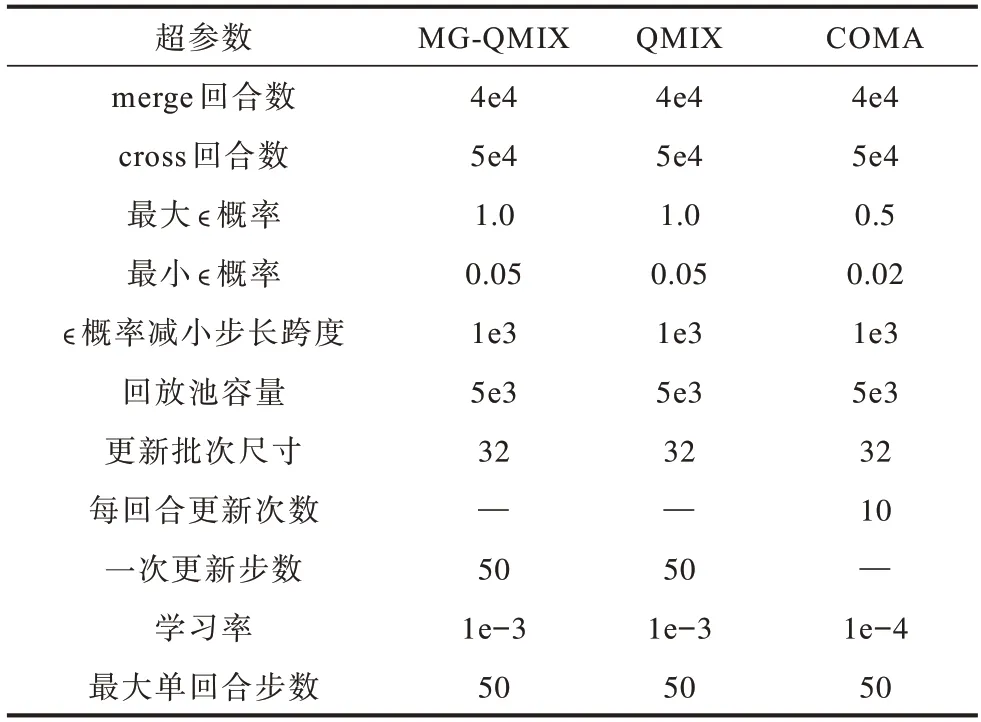
表4 各模型在多粒子運(yùn)動(dòng)環(huán)境中的訓(xùn)練超參數(shù)Table 4 Training hyper parameters of each models in multi-particle motion environment
5.2 消融實(shí)驗(yàn)結(jié)果
為驗(yàn)證本文方法和模型使用的關(guān)鍵技術(shù)的有效性,設(shè)置兩組消融模型,線性(Linear)模型和無注意力(No Attention)模型。消融模型和本文MG-QMIX在多粒子運(yùn)動(dòng)環(huán)境merge 地圖中的得分對(duì)比結(jié)果如圖6 所示。相較于本文提出的模型,兩組消融模型都沒有可觀的性能表現(xiàn)。
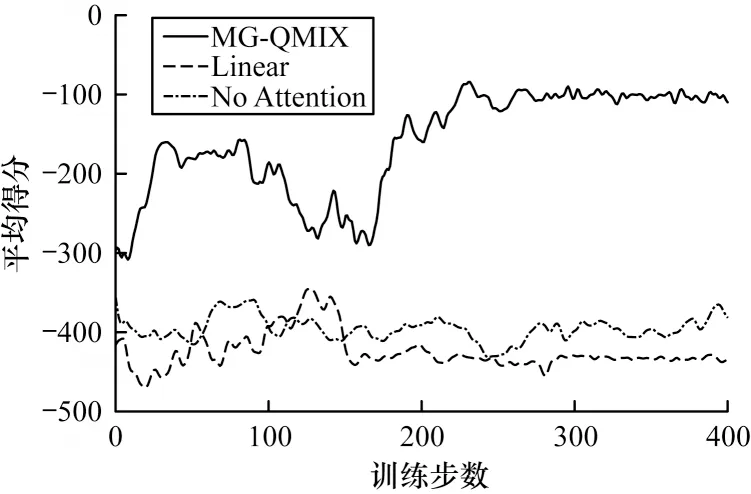
圖6 不同模型在多粒子運(yùn)動(dòng)環(huán)境merge 地圖的訓(xùn)練得分曲線Fig.6 Training score curves of different models on merge map in multi-particle motion environment
本文模型的非線性融合方式擴(kuò)展了對(duì)智能體之間的關(guān)系模式,提高了值分解的精確程度。然而,線性模型對(duì)于智能體關(guān)系和值分解的刻畫能力有限,只能收斂到一個(gè)較低得分的策略,遠(yuǎn)低于MGQMIX的收斂得分。
本文模型的注意力機(jī)制主要用來提取群體影響力特征,該特征在利用目標(biāo)信息以及完成第一階段值融合中起到了關(guān)鍵性的引導(dǎo)作用。從無注意力模型的訓(xùn)練曲線中可以看出,智能體策略始終沒有收斂,這說明無注意力模型沒有群體影響力的引導(dǎo),無法完成值融合網(wǎng)絡(luò)中的動(dòng)作值融合階段,證明了群體影響力對(duì)于值融合的關(guān)鍵作用,也說明了本文選取的鍵值對(duì)于注意力網(wǎng)絡(luò)可以有效地提取群體影響力這一特征。
上述兩組消融實(shí)驗(yàn)證明了模型的非線性分解形式和注意力機(jī)制對(duì)于模型性能的正面作用和必要性。
6 結(jié)束語
本文提出一種基于目標(biāo)信息和注意力機(jī)制的多智能體值分解強(qiáng)化學(xué)習(xí)方法MG-QMIX。為提升強(qiáng)化學(xué)習(xí)方法在多目標(biāo)多智能體場(chǎng)景中的性能,采用集中式學(xué)習(xí)、分布式策略的框架,利用智能體的目標(biāo)信息實(shí)現(xiàn)兩階段的值分解方法,并通過注意力機(jī)制提取智能體群體影響力特征,促使網(wǎng)絡(luò)訓(xùn)練學(xué)習(xí)。在星際爭(zhēng)霸2、棋盤游戲和多粒子運(yùn)動(dòng)環(huán)境等6 種場(chǎng)景地圖上對(duì)比了該模型與其他多智能體強(qiáng)化學(xué)習(xí)方法的表現(xiàn),結(jié)果表明,MG-QMIX不僅保留了QMIX在合作場(chǎng)景中的優(yōu)勢(shì),而且在具有混合關(guān)系的多目標(biāo)場(chǎng)景中仍有優(yōu)秀性能,消融實(shí)驗(yàn)結(jié)果也證明了該方法非線性分解和注意力機(jī)制的有效性。下一步將考慮增強(qiáng)該方法在更多智能體數(shù)量的場(chǎng)景中的拓展性,探索適用于無顯式目標(biāo)或動(dòng)態(tài)目標(biāo)環(huán)境中的強(qiáng)化學(xué)習(xí)方法。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學(xué)生作文(低年級(jí)適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學(xué)低年級(jí)(2017年4期)2017-06-09 16:22:28
