基于CatBoost機器學習模型的風電機組機艙溫度異常預警研究
2023-02-09 06:43:26張惠強高娟娟任曉旭陶永剛趙禹茗黃劍鋒
太陽能 2023年1期
張惠強,高娟娟*,任曉旭,陶永剛,趙禹茗,黃劍鋒
(1.國電電力內蒙古新能源開發有限公司,呼和浩特 010020;2. 華風數據(深圳)有限公司,深圳 518110)
0 引言
溫度作為機械部件是否正常工作的重要標志,具有較大的研究意義。目前對于風電機組的研究多為小部件研究,缺少對于風電機組機艙環境的整體研究。機艙內部各個機械部件都會對整個機艙溫度變化產生影響。機艙溫度變化是風電機組運行正常與否的一個關鍵指標。
文獻[1]提出采用非線性狀態估計(nonlinear state estimation,NSET)技術結合反向傳播神經網絡 (back propagation neural network,BPNN)模型建立了風電機組發電機前軸承溫度的預測模型,同時使用模糊綜合評價判斷風電機組的運行狀態;文獻[2]基于數據采集與監視控制(supervisory control and data acquisition,SCADA)系統獲取數據融合稀疏自編碼器及深度神經網絡,提出了風電機組在線監測方法;文獻[3]使用有限元分析,提出了自適應比例積分微分(proportional integral derivative,PID)算法,實現了對機艙內部的控制;文獻[4]針對超溫的故障模式、影響及重要度分析(failure mode,effects and criticality analysis,FMECA),提出了超溫FMECA的分析表及危害性矩陣圖,從而找出最嚴重的故障影響因素;文獻[5]提出了基于最大信息系數 (maximal information coefficient,MIC)的變量篩選方法,基于長短時記憶網絡(long short term memory,LSTM)建立了多變量的機艙溫度預測模型;文獻[6-7]基于計算流體動力學(computational fluid dynamics,CFD)分析方法,對機艙內部進行了分析;文獻[8-9]通過建立風電機組機艙仿真模型,對機艙進行了模擬計算;文獻[10]采用多項式回歸擬合方法,使用時間滑動窗口,建立了數學模型,根據概率值來確定是否預警。
本文對風電機組機艙溫度進行分析,選取正常運行狀態下的機艙溫度數據,使用Pearson相關系數和Spearman相關系數,以及輕型梯度增強學習器 (light gradient boosting machine,LightGBM)[11]、CatBoost(gradient boosting with categorical features support)算法[12]對特征重要性排序,篩選出對機艙溫度影響較大的特征變量;然后采用LightGBM、CatBoost和隨機森林(Random Forest)[13-14]算法分別建立模型,基于評價指標選取最優模型作為風電機組機艙溫度異常預警模型[15-17]。該模型在機艙溫度的預測值和真實值相差較大時,會發出預警,專業檢修人員可以根據模型輸出的特征變量重要性排序,優先檢修相關性較高的部件。
1 方法體系
1.1 建模方法
CatBoost算法[18]是一種基于對稱決策樹(oblivious trees)的基學習器,從而實現參數較少、支持類別型變量和高準確性的梯度提升樹(gradient boosting decision tree,GBDT)框架。該算法支持類別型變量,對于非數據型變量也可以進行預處理,主要考慮的是快速有效地處理類別型特征。此外,CatBoost算法還解決了梯度偏差(gradient bias)及預測偏移 (prediction shift)的問題,從而減少了過擬合的發生,提高了算法的準確性和泛化能力。
CatBoost算法原理包括以下5個方面:
1)處理類別型特征,統計某個或某些特征出現的頻率值,通過對數據的隨機排列生成樹,并將類別型特征進行多組組合;
2)解決梯度偏差,采用梯度步長的無偏估計,使用傳統的GBDT方案來解決梯度偏差;
3)將不同類別型特征的組合作為新的特征,以此來獲得高階依賴;
4)采用對稱樹作為基預測器,將所有浮點特征、統計信息和獨熱編碼特征進行二值化,并使用二進制特征來計算模型的預測值;
5)搜索最佳分割方法,該算法采用了不依賴于原子操作的直方圖計算法。
1.2 參數調優
網格搜索(GridSearchCV)[19]是在指定范圍內尋找在驗證集上精度最高的超參數組合,網格搜索會遍歷給定范圍內所有超參數組合,由于沒有錯過任何超參數,搜索效果很好。因此,本研究選用網格搜索方法確定最優參數組合。
1.3 評價指標
本文采用風電機組機艙溫度的預測值與實測值之間的均方誤差 (mean squared error,MSE)、均方根誤差 (root mean square error,RMSE)、平均絕對誤差 (mean absolute error,MAE)、判定系數R2,作為判斷模型預測效果可靠性的評價指標。
MSE的計算式為:

式中:i為采樣點;n為采樣點個數;yi為風電機組機艙溫度的實測值;為風電機組機艙溫度的預測值。
RMSE的計算式為:
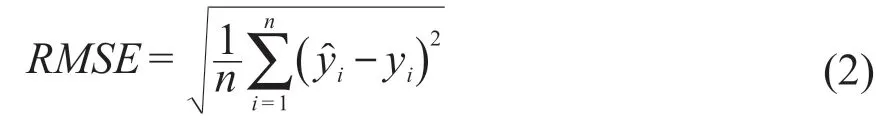
MAE的計算式為:

判定系數值越接近1,說明模型的預測效果越好。判定系數的計算式為:
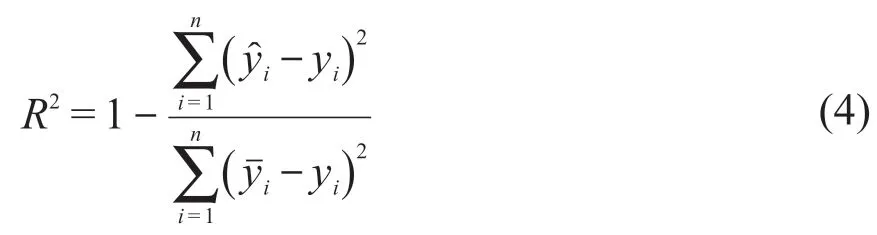
2 模型預警實施
2.1 數據處理及特征工程
本文基于SCADA系統,采集了威海文登風電場中編號為A01的風電機組在2018年1月—2020年12月時間段內的分鐘級歷史數據[20],并使用控制狀態列刪除待機、檢查、維修等不健康運行狀態時間點的樣本數據及故障前后24 h的樣本數據后,剩余的正常運行狀態的樣本數據量中記錄數為892794條,特征(測點)為73個。由于數據量較大,數據缺失的占比較小,直接刪除缺失數據所在行,剩余數據量中記錄數為876852條,特征(測點)為46個。
數據量過大,特征變量過多,往往會給機器學習算法帶來維度災難,并且在現實應用中,時間消耗也是需要考慮的重要因素。選擇部分重要特征變量,在確保一定精度條件下降低學習任務的難度,從而提升模型的效率,減少算法學習時間,增加模型的可解釋性,使模型泛化能力更強。
針對46列特征變量,首先,計算每一列特征變量自身方差,方差大表明該列特征變量的變化較大,含有可能影響機艙溫度的信息;對于方差為零的列,說明該列數據為常數,不含對于機艙溫度有價值的信息,因此直接刪除。然后采用Pearson相關系數和Spearman相關系數、LightGBM算法[21]和CatBoost算法計算特征變量的重要性并排序。其中,相關系數法是根據特征變量自身屬性(連續或離散)計算其與機艙溫度相關系數,對于連續型特征變量使用Pearson相關系數,對于離散型特征變量使用Spearman相關系數;然后根據上述相關系數大小排序得到本算法的特征變量重要性排序。針對LightGBM和CatBoost算法重要性取值較大的問題,用各個特征變量的重要性數值與所有特征變量的重要性總和值相除,對得到的比值進行加權,得出綜合排名,最終選擇綜合排名前20位的特征變量(如表1所示)作為最終風電機組機艙溫度異常預警模型的輸入特征變量,以減少數據冗余,降低時間消耗。
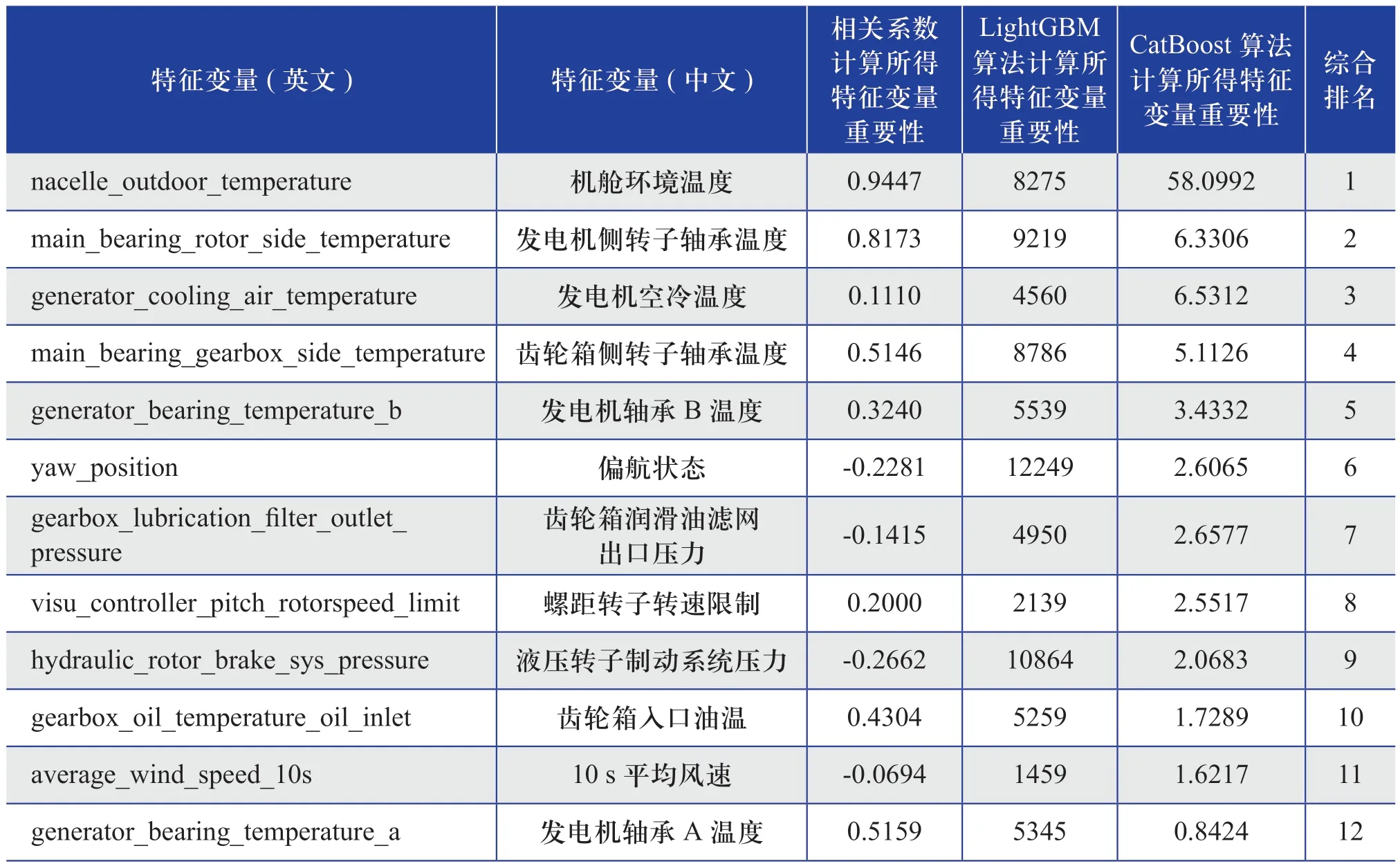
表1 綜合排名前20位的特征變量Table 1 Characteristic variables of top 20 comprehensive ranking
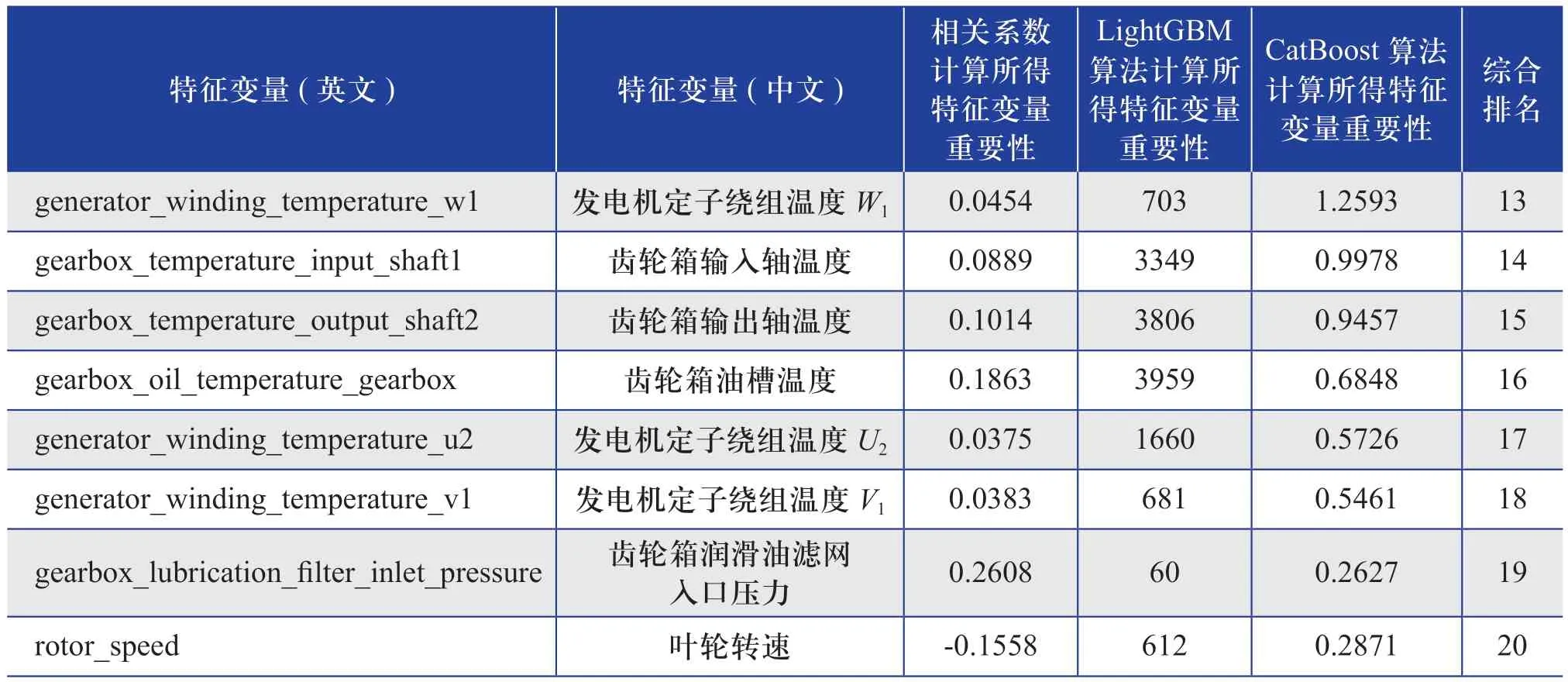
(續表)
2.2 建模與參數調優
選擇CatBoost、LightGBM和Random Forest[22]互為對照算法,使用表1得到的20個特征變量,分別建立了3個風電機組機艙溫度模型(下文分別簡稱為“CatBoost模型”“LightGBM模型”“Random Forest模型”);然后使用網格搜索,查找出每個算法建立的風電機組機艙溫度模型的最優超參數組合,具體如表2所示。對不同模型的評價指標值進行綜合比較,結果如圖1所示。
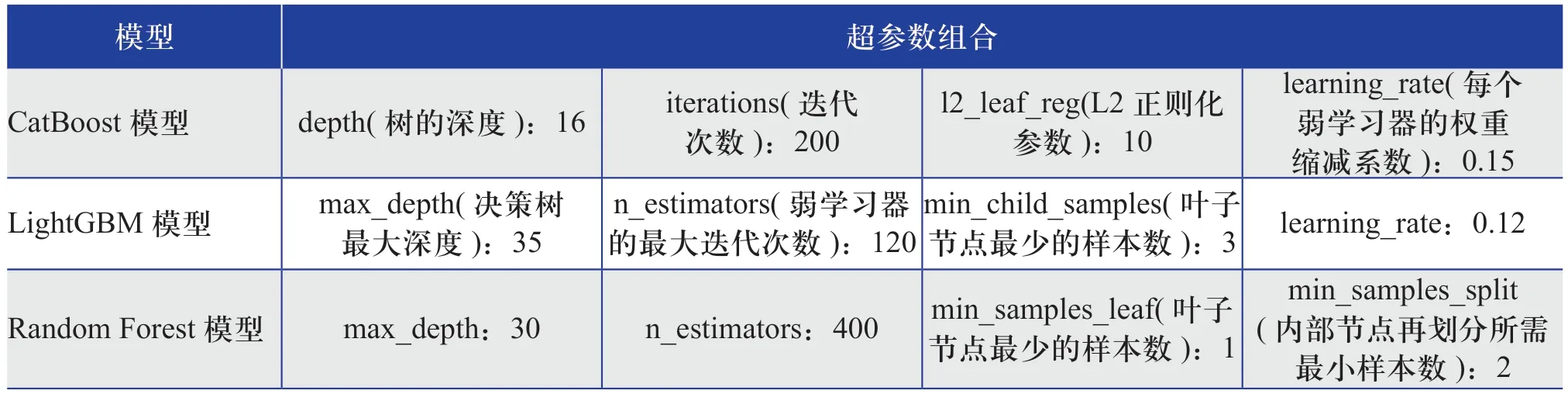
表2 采用不同算法建立的風電機組機艙溫度模型的最優超參數組合Table 2 Optimal super parameter combination of wind turbine nacelle temperature models established by different algorithms
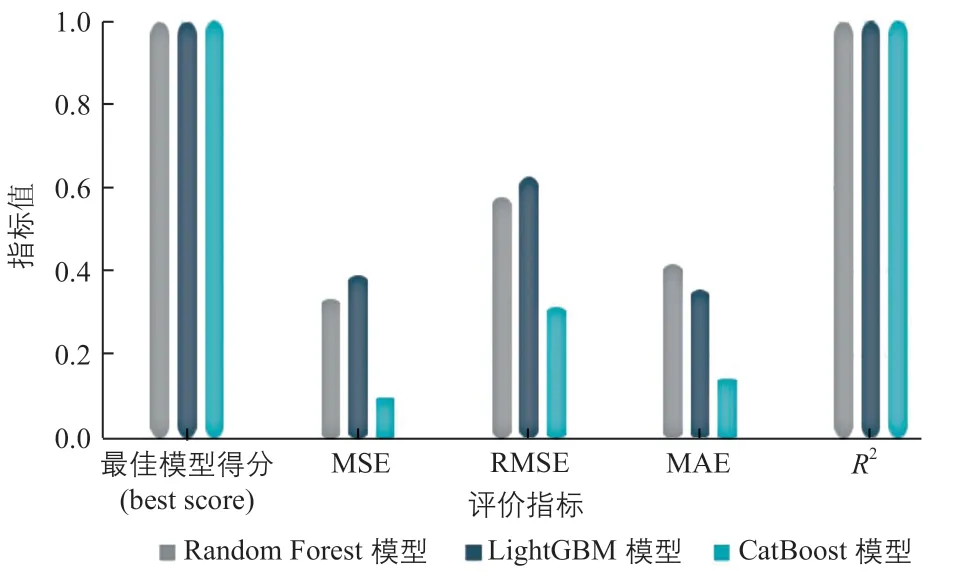
圖1 不同模型的評價指標對比Fig. 1 Comparison of evaluation indicators of different models
從圖1可以看出:3個模型的最佳模型得分(best score)均較高;而CatBoost模型的判定系數最大,達到了0.9989,且3個誤差值均為最小,說明其評價指標值最優。因此,本文選擇CatBoost模型作為風電機組機艙溫度異常預警模型。
2.3 模型驗證
為了驗證風電機組機艙溫度異常預警模型的預警效果,篩選威海文登風電場的故障記錄,查找風電機組機艙溫度異常故障,發現2018年1月15日的10:00~14:00機艙溫度異常。篩選此故障時段及其前后一段時間內的數據記錄,調用訓練完成的CatBoost模型,利用風電機組機艙溫度的預測值與真實值作圖,對比結果如圖2所示。圖中:紅色方框內為真實故障時段。
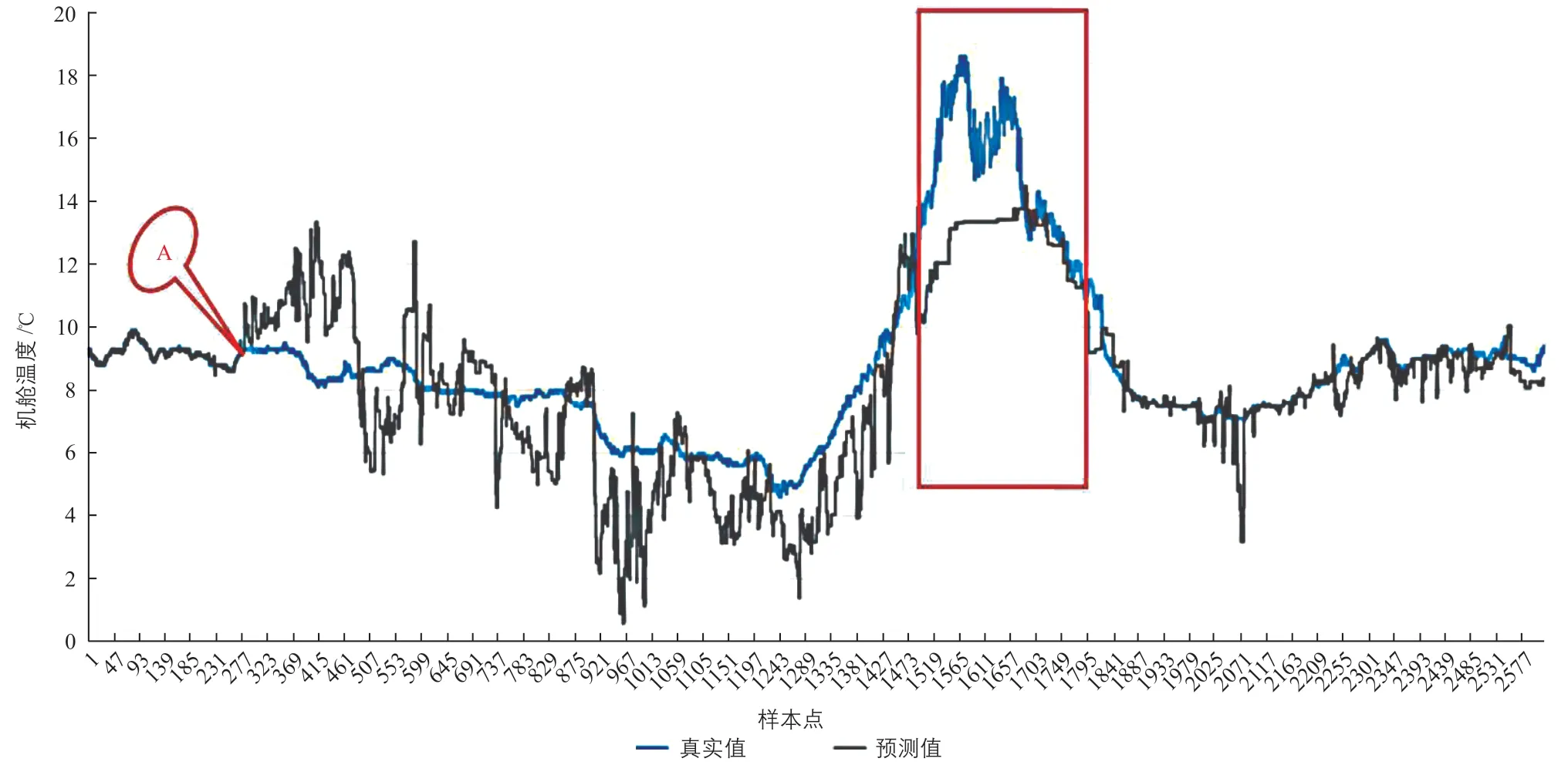
圖2 風電機組機艙溫度的預測值與真實值的對比Fig. 2 Comparison between predicted value and real value of nacelle temperature of wind turbine
從圖2可以明顯看出:在真實故障時段,風電機組機艙溫度的預測值和真實值之間有較大的偏離趨勢[22]。同時,由于采用的是分鐘級數據,即在發生故障之前約18 h(即圖中A點)時,機艙溫度的預測值和真實值就已經產生了偏離,此時就可以對機艙溫度進行溫度異常預警。維修人員可以根據預警提示檢修機艙內部的部件,但是由于機艙內部的機械部件較多,逐一檢修會消耗大量時間,此時可以根據風電機組機艙溫度異常預警模型輸出的特征變量重要性排序,優先檢修重要性排名靠前的部件,以節省檢修消耗的時間,提高工作效率。風電機組機艙溫度異常預警模型輸出的特征變量重要性排序如圖3所示。圖中,特征變量名稱為預警模型中標準名稱,與表1對應。
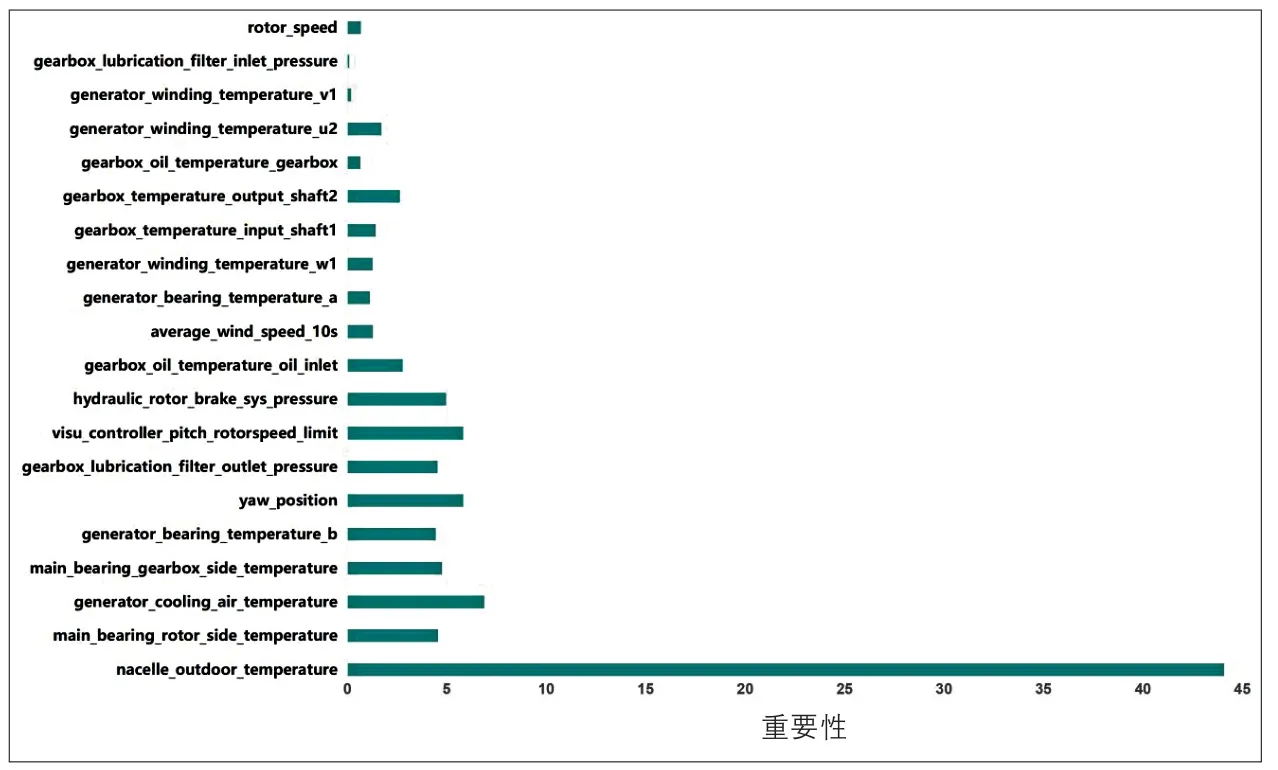
圖3 風電機組機艙溫度異常預警模型輸出的特征變量重要性排序Fig. 3 Importance ranking of characteristic variables output from early warning model of abnormal wind turbine nacelle temperature
3 結論
本文選取正常運行狀態下的風電機組機艙溫度數據,同時使用Pearson相關系數和Spearman相關系數,以及LightGBM、CatBoost算法的特征變量重要性等權重加權,篩選出對機艙溫度影響較大的特征變量,得到綜和排名前20位的特征變量作為風電機組機艙溫度的特征變量集合;然后,選擇CatBoost、LightGBM、Random Forest算法分別建立3個模型,根據評價指標選出最優模型作為風電機組機艙溫度異常預警模型,并使用實際的風電機組機艙溫度故障的歷史數據進行了驗證分析。該模型可以在風電機組機艙溫度預測值與真實值之間偏離程度較大時發出預警,專業檢修人員可以根據模型輸出的特征變量重要性排序,優先檢修相關性較高的部件,實用性較強。
實現風電機組故障預警可在故障發生前提醒工作人員檢修關鍵部件,從而減少停機頻率。目前風電機組的運行和維護還處于發展階段,本文對于風電機組機艙溫度異常預警的研究極具現實意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年6期)2015-04-17 03:31:50
